实施工程师在数据库方面要掌握的技能
实施工程师在数据库中要掌握的技能
一、数据库的备份以及导入
1.**关键字备份:mysqldump
备份(导出)SQL文件:
-
打开命令行窗口(Windows)或终端(Linux/Mac)。
-
输入以下命令,其中
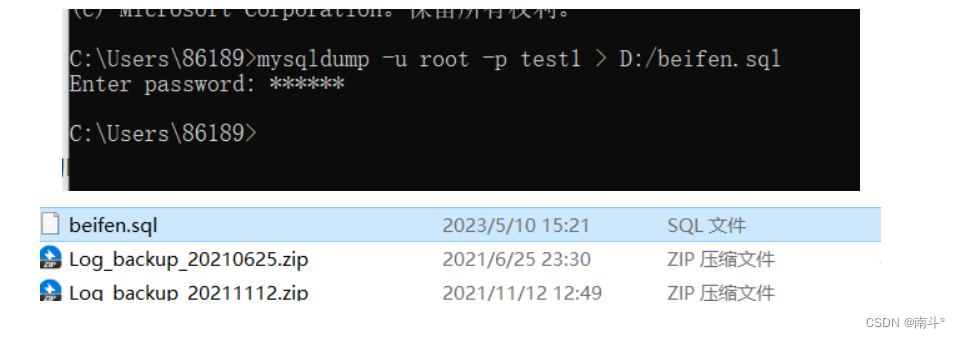
username是你的MySQL用户名,-p是你的MySQL密码,database_name是要备份的数据库名称,backup_file.sql是要保存的备份文件名。mysqldump -u username -p database_name > backup_file.sql -
按下回车键后,系统会提示你输入MySQL密码,输入密码后备份过程会开始。备份完成后,你会在当前目录下找到一个名为
backup_file.sql的文件,这个文件就是你的MySQL数据库备份文件。
举例:
mysqldump -u root -p test1 > D:/beifen.sql

ok
这样已经备份成功
还原(导入)SQL文件:
-
打开命令行窗口(Windows)或终端(Linux/Mac)。
-
输入以下命令,其中
username是你的MySQL用户名,password是你的MySQL密码,database_name是要导入的数据库名称,backup_file.sql是要导入的备份文件名。mysql -u username -p database_name < backup_file.sql -
按下回车键后,系统会提示你输入MySQL密码,输入密码后导入过程会开始。导入完成后,你的MySQL数据库就已经恢复到备份时的状态了。
举例:
mysql -u root -p test1 < D:/beifen.sql
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-b8we8qFN-1683723173307)(C:\Users\86189\Desktop\assets\image-20230510152530224.png)]](https://i-blog.csdnimg.cn/blog_migrate/a1d99397031d09c767edbdb5b2271e12.png)
ok!
2.*使用navicat工具进行备份
数据库的备份(导出)

数据库的还原(导入)


如果想更高级的导出/备份文件的话,可以使用导出向导
二、数据库函数补充
0.常见函数类别
数据库中常用的函数可以分为以下几类:
- 数学函数:如 ABS、CEILING、FLOOR、ROUND、TRUNCATE、POWER、SQRT、LOG、EXP、SIN、COS、TAN 等。
- 字符串函数:如 CONCAT、SUBSTRING、LENGTH、LOWER、UPPER、TRIM、REPLACE、REVERSE 等。
- 日期和时间函数:如 NOW、CURDATE、CURTIME、DATE、TIME、YEAR、MONTH、DAY、HOUR、MINUTE、SECOND、DATE_FORMAT 等。
- 聚合函数:如 COUNT、SUM、AVG、MAX、MIN 等。
- 条件函数:如 IF、CASE WHEN、COALESCE、NULLIF 等。
- 类型转换函数:如 CAST、CONVERT 等。
- 加密函数:如 MD5、SHA1 等。
- 其他函数:如 RAND、SLEEP、USER、DATABASE、VERSION 等。
以上是常用的数据库函数类型和一些具体函数示例,具体应用需要根据具体情况进行调整。
比较重要的函数类型:
1.字符串拼接函数concat
CONCAT 函数是MySQL中用于连接两个或多个字符串的函数。它可以将多个字符串连接成一个字符串,并且可以在连接过程中添加分隔符或其他字符。
以下是一个使用 CONCAT 函数的示例:
假设我们有一个 users 表,其中包含用户的姓名、姓氏和电子邮件地址。我们想要创建一个新的列,该列包含用户的全名和电子邮件地址,中间用逗号分隔。
我们可以使用以下SQL语句:
ALTER TABLE users ADD COLUMN full_name_email VARCHAR(255);
UPDATE users SET full_name_email = CONCAT(first_name, ' ', last_name, ', ', email);
上述SQL语句通过 CONCAT 函数将 first_name、last_name 和 email 字段连接起来,并使用逗号分隔。然后将连接后的字符串插入到 full_name_email 列中。
假设 users 表中有以下数据:
| id | first_name | last_name | |
|---|---|---|---|
| 1 | John | Smith | john.smith@example.com |
| 2 | Jane | Doe | jane.doe@example.com |
| 3 | 伟 | 刘 | 54287@qq.com |
执行上述SQL语句后,users 表将包含以下数据:
| id | first_name | last_name | full_name_email | |
|---|---|---|---|---|
| 1 | John | Smith | john.smith@example.com | John Smith, john.smith@example.com |
| 2 | Jane | Doe | jane.doe@example.com | Jane Doe, jane.doe@example.com |
| 3 | 伟 | 刘 | 54287@qq.com | 伟 刘,54287@qq.com |
在上述示例中,我们使用了 CONCAT 函数将 first_name、last_name 和 email 字段连接起来,并使用逗号分隔。然后将连接后的字符串插入到 full_name_email 列中。
举例:

2.*字符串截取函数substring
SUBSTRING 函数是MySQL中用于截取字符串的函数。它可以从一个字符串中截取一部分字符,并返回截取后的子字符串。
以下是一个使用 SUBSTRING 函数的示例:
假设我们有一个 users 表,其中包含用户的姓名和电话号码。我们想要创建一个新的列,该列包含用户的电话号码后4位。
我们可以使用以下SQL语句:
ALTER TABLE users ADD COLUMN last_4_digits VARCHAR(4);
UPDATE users SET last_4_digits = SUBSTRING(phone_number, -4);
上述SQL语句通过 SUBSTRING 函数从 phone_number 字段中截取后4位,并将截取后的子字符串插入到 last_4_digits 列中。
假设 users 表中有以下数据:
| id | name | phone_number |
|---|---|---|
| 1 | John Smith | 555-123-4567 |
| 2 | Jane Doe | 555-987-6543 |
执行上述SQL语句后,users 表将包含以下数据:
| id | name | phone_number | last_4_digits |
|---|---|---|---|
| 1 | John Smith | 555-123-4567 | 4567 |
| 2 | Jane Doe | 555-987-6543 | 6543 |
在上述示例中,我们使用了 SUBSTRING 函数从 phone_number 字段中截取后4位,并将截取后的子字符串插入到 last_4_digits 列中。
以下是另外两个使用 SUBSTRING 函数的示例:
-
截取字符串中的一部分
SELECT SUBSTRING('Hello, World!', 1, 5);上述示例中,使用
SUBSTRING函数从字符串'Hello, World!'中截取前5个字符,返回结果为'Hello'。 -
截取日期中的年份
SELECT SUBSTRING('2022-08-01', 1, 4);上述示例中,使用
SUBSTRING函数从日期字符串'2022-08-01'中截取前4个字符,即年份,返回结果为'2022'。
在上述示例中,我们使用了 SUBSTRING 函数从字符串或日期中截取一部分字符,并返回截取后的子字符串。
需要注意的是,第二个参数表示开始截取的位置,第三个参数表示截取的字符个数。如果第三个参数为空,则截取到字符串的末尾。
类似于limit
例子:

3.字符串长度函数length
LENGTH 函数是MySQL中用于获取字符串长度的函数。它可以返回一个字符串中字符的个数(包括空格和标点符号)。
以下是两个使用 LENGTH 函数的示例:
-
获取字符串长度
SELECT LENGTH('Hello, World!');上述示例中,使用
LENGTH函数获取字符串'Hello, World!'的长度,返回结果为13。注意,空格,符号也计入字符串长度
-
获取列中字符串的最大长度
SELECT MAX(LENGTH(name)) AS max_length FROM users;上述示例中,使用
LENGTH函数获取users表中name列中字符串的长度,并使用MAX函数获取最大值,返回结果为10。
在上述示例中,我们使用了 LENGTH 函数获取字符串的长度。
需要注意的是,LENGTH 函数返回的是一个字符串中字符的个数,而不是字节数。如果需要获取字符串的字节数,请使用 CHAR_LENGTH 函数。
例子:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-p01BgPxt-1683723173311)(C:\Users\86189\Desktop\assets\image-20230510162410990.png)]](https://i-blog.csdnimg.cn/blog_migrate/36dc903db3d76c2c52c411186a0ee59d.png)
4.*条件判断函数case when
当需要根据不同的条件对数据进行分类或者计算时,可以使用MySQL中的 CASE WHEN 函数。以下是一些常见的用法示例:
-
对数据进行分类
SELECT name, CASE WHEN score >= 90 THEN '优秀' WHEN score >= 80 THEN '良好' WHEN score >= 70 THEN '中等' WHEN score >= 60 THEN '及格' ELSE '不及格' END AS grade FROM xuesheng;上述示例中,根据学生的成绩进行分类,得到每个学生的等级。
例子:

-
对数据进行统计
SELECT COUNT(*) AS total, SUM(CASE WHEN score >= 60 THEN 1 ELSE 0 END) AS pass, SUM(CASE WHEN score < 60 THEN 1 ELSE 0 END) AS fail FROM xuesheng;上述示例中,统计了学生总数、及格人数和不及格人数。
例子:

-
对数据进行计算
SELECT name, score, CASE WHEN score >= 90 THEN score * 4 WHEN score >= 80 THEN score * 3 WHEN score >= 70 THEN score * 2 ELSE score END AS credits FROM xuesheng;上述示例中,根据学生的成绩计算每个学生的学分。
例子:

4.对多个条件进行判断
SELECT
name,
CASE
WHEN score >= 90 AND gender = '男' THEN '优秀男生'
WHEN score >= 90 AND gender = '女' THEN '优秀女生'
WHEN score >= 80 AND gender = '男' THEN '良好男生'
WHEN score >= 80 AND gender = '女' THEN '良好女生'
ELSE '其他'
END AS category
FROM
xuesheng;
上述示例中,根据学生的成绩和性别进行分类,得到每个学生的类别。
例子:

以上是 CASE WHEN 函数的一些常见用法示例,具体应用需要根据具体情况进行调整。
5.类型转化函数convert
CONVERT函数是一种用于将一个数据类型转换为另一个数据类型的函数。
在数据库中,不同的数据类型有不同的表示方式和存储方式,有时候需要将一个数据类型转换为另一个数据类型才能进行操作或比较。
例如,假设一个数据库中有一个字段存储了一个日期,但是它的数据类型是字符串类型。如果我们想要对这个日期进行排序或比较,就需要将它转换为日期类型。这时候就可以使用CONVERT函数将字符串类型转换为日期类型。
举个例子,假设数据库中有一个表格,其中有一个字段存储了一些日期,但是这些日期的数据类型是字符串类型。
我们想要对这些日期进行排序,就需要将它们转换为日期类型。可以使用如下的SQL语句:
SELECT date_field FROM table_name ORDER BY CONVERT(date_field, DATE);
这里的CONVERT函数将date_field字段从字符串类型转换为日期类型,然后使用ORDER BY子句对结果进行排序。这样就可以对日期字段进行排序了。
假设数据库中有一个表格,其中有一个字段存储了一些货币金额,但是这些金额的数据类型是字符串类型。我们想要对这些金额进行加法运算,就需要将它们转换为数字类型。可以使用如下的SQL语句:
SELECT SUM(CONVERT(money_field, DECIMAL)) FROM table_name;
这里的CONVERT函数将money_field字段从字符串类型转换为数字类型,然后使用SUM函数对结果进行求和。这样就可以对货币金额进行加法运算了。
补充:
CAST和CONVERT函数都是用于数据类型转换的函数,它们的作用是将一个数据类型转换为另一个数据类型。但是它们之间也有一些区别:
- 语法不同:CAST函数的语法为CAST(expression AS data_type),而CONVERT函数的语法为CONVERT(data_type, expression, [style])。
- 可以转换的数据类型不同:CAST函数可以将一个数据类型转换为另一个数据类型,但是只能转换为一些特定的数据类型,例如整数、浮点数、日期和时间等。而CONVERT函数可以将一个数据类型转换为另一个数据类型,可以转换的数据类型更多,还可以指定转换的格式。
- 转换效率不同:CAST函数的转换效率比CONVERT函数高,因为CAST函数只进行简单的数据类型转换,而CONVERT函数需要进行更多的转换操作,例如格式转换等。
总的来说,
CAST函数和CONVERT函数都是用于数据类型转换的函数,使用时需要根据具体情况选择合适的函数。如果只是简单的数据类型转换,建议使用CAST函数,如果需要进行格式转换等更复杂的操作,则可以使用CONVERT函数。
三、数据库补充知识
1.*存储过程是什么?
简单理解:就是一堆sql语句,组成的一个sql文件
这个sql文件里面有判断,循环,定义方法等等
一堆的linux 放在一起叫做shell脚本
数据库中的存储过程是一段预先编写好的可重用的程序代码,它可以在需要时被多次调用。存储过程通常用于执行一些常见的数据库操作,比如插入、更新或删除数据,或者进行复杂的数据处理和计算。
换句话说,存储过程是一种封装好的数据库操作,可以方便地重复使用,并且可以提高数据库操作的效率。
类似于python里面的函数
以下是一个使用存储过程的示例:
假设我们有一个 users 表,其中包含用户的姓名、姓氏和电子邮件地址。我们想要创建一个存储过程,该存储过程可以根据用户的姓氏查询用户的信息。
我们可以使用以下SQL语句创建一个存储过程:
CREATE PROCEDURE get_name (IN name VARCHAR(255))
BEGIN
SELECT * FROM xuesheng WHERE name = name;
END;
例子:

上述SQL语句创建了一个名为 get_name 的存储过程,它接受一个参数 name,并根据用户的姓氏查询用户的信息。
假设我们想要查询姓氏为 Smith 的用户信息,我们可以使用以下SQL语句调用存储过程:
CALL get_name('张三');
执行上述SQL语句后,将返回张三的 的用户信息。
上述语句,他的作用跟下面是一样
SELECT * FROM xuesheng WHERE name =’张三‘;
在上述示例中,我们使用存储过程来封装一个常见的数据库操作,并可以在需要时方便地重复使用。存储过程可以提高数据库操作的效率,减少代码的重复性,并且可以更好地管理和维护数据库。
存储过程的创建
当创建存储过程时,需要使用 CREATE PROCEDURE 语句,然后在 BEGIN 和 END 之间编写存储过程的代码。存储过程可以包含输入参数、输出参数和局部变量。以下是存储过程的基本语法结构:
CREATE PROCEDURE procedure_name (IN input_parameter1 data_type, IN input_parameter2 data_type, ..., OUT output_parameter data_type)
BEGIN
-- 存储过程的代码
END;
其中,
procedure_name 是存储过程的名称,可以自定义
input_parameter1、input_parameter2 等是输入参数的名称和数据类型,可以自定义
output_parameter 是输出参数的名称和数据类型,也可以自定义
在存储过程的代码中,可以使用 SELECT、INSERT、UPDATE这些sql语法
2.*数据库的触发器是什么?
触发器是与表有关的命名数据库对象,当表上出现特定事件时,将调用该对象。
创建的语法是create trigger 触发器名称 时间 类型 触发语句
比如当每天中午12点时候,执行一个新增客户的一条sql语句
比如每次删除一个客户信息,就在客户表里面插入一个历史客户信息
数据库中的触发器是一种特殊的存储过程,它是在数据库表中的数据发生改变时自动触发执行的一段代码。
当某个条件被满足时,触发器会自动执行一些操作,比如插入、更新或删除数据,或者记录日志等。
换句话说,触发器是一种自动化的反应机制,当某些事情发生时,它会自动执行一些操作,以便保证数据的一致性和完整性。
以下是一个使用触发器的示例:
假设我们有一个 orders 表,其中包含订单的信息,包括订单号、客户名称、订单日期和订单金额。
我们想要在插入新订单时自动计算订单总额,并将其存储在 total_amount 列中。
我们可以使用以下SQL语句创建一个触发器:
CREATE TRIGGER calculate_total_amount
AFTER INSERT ON orders
FOR EACH ROW
BEGIN
UPDATE orders SET total_amount = (quantity * price) WHERE order_id = NEW.order_id;
END;
上述SQL语句创建了一个名为 calculate_total_amount 的触发器,它会在 orders 表中插入新数据时自动触发。
触发器会计算订单总额,并将其存储在 total_amount 列中。
假设我们插入以下数据:
INSERT INTO orders (order_id, customer_name, order_date, quantity, price) VALUES (1, 'John Smith', '2022-08-01', 2, 10);
执行上述SQL语句后,orders 表将包含以下数据:
| order_id | customer_name | order_date | quantity | price | total_amount |
|---|---|---|---|---|---|
| 1 | John Smith | 2022-08-01 | 2 | 10 | 20 |
| 2 | zhangsan | 2023-05-10 | 3 | 20 | 60 |
在上述示例中,我们使用了触发器来自动计算订单总额,并将其存储在 total_amount 列中。
当插入新订单时,触发器会自动执行计算操作,以保证数据的一致性和完整性。
2.union跟join的区别?
简单来说:一个是连接查询,一个是关联查询
UNION和JOIN都是用于查询数据库中的数据的操作,但它们有不同的作用和使用场景。
1.UNION:
UNION操作用于将两个或多个SELECT语句的结果集合并成一个结果集,合并后的结果集中的行数等于所有结果集中的行数之和。UNION操作的结果集中不包含重复的行。UNION操作要求两个或多个SELECT语句的列数和列的数据类型必须相同。
例如,假设有两个表格A和B,它们的结构相同,都有两个字段name和age。现在我们想要将这两个表格的数据合并成一个结果集,可以使用如下的SQL语句:
SELECT name, age FROM A
UNION
SELECT name, age FROM B;
2.JOIN:
JOIN操作用于将两个或多个表格中的数据进行关联查询,将符合条件的数据行合并成一个结果集。JOIN操作要求关联的表格必须存在相同的列或者有关联关系。
例如,假设有两个表格A和B,它们都有一个字段id,现在我们想要将这两个表格中的数据按照id字段进行关联查询,可以使用如下的SQL语句:
SELECT A.name, B.age FROM A JOIN B ON A.id = B.id;
总的来说,UNION和JOIN都是非常常用的数据库操作,但是它们的作用和使用场景不同。
UNION用于将多个结果集合并成一个结果集,而JOIN用于将多个表格中的数据进行关联查询。
备注:join默认使用的就是inner join
补充: Join连接查询如果不跟关联条件查询的结果是什么样的?
查询结果是两张表数据的笛卡尔乘积
比如A表5条数据,B表6条,那么就最终会出现30条数据
select * from A,b
3.union与union all的区别:
①对重复结果的处理:union会去掉重复记录,union all不会;
②对排序的处理:union会对结果排序,union all只是简单地将两个结果集合并;
③效率方面的区别:因为union 会做去重和排序处理,因此union效率比union all慢很多;
④UNION操作要求两个或多个SELECT语句的列数和列的数据类型必须相同,而UNION ALL则没有这个限制;
4.多表联查有哪几种?
内连接查询,左右连接查询,联合查询union
UNION操作符,则是可以将多个查询结果,按行进行纵向合并
5.*数据库给用户授权访问:grant
【grant】
GRANT语句:专门用来设置数据库用户的访问权限。
当指定的用户名不存在时,GRANT语句将会创建新的用户;当指定的用户名存在时,GRANT 语句用于修改用户信息。
数据库中给用户授权访问的命令是GRANT。
GRANT命令用于向用户或用户组授予某些权限,使其能够访问数据库中的对象(例如表、视图、存储过程等)或执行某些操作(例如SELECT、INSERT、UPDATE、DELETE等)。
GRANT命令的语法为:
GRANT permission ON object TO user;
其中,permission表示授予的权限,可以是SELECT、INSERT、UPDATE、DELETE等;
object表示授权的对象,可以是表、视图、存储过程等;
user表示被授权的用户或用户组。
例如,假设有一个数据库mydb,其中有一个表格users,现在我们想要授予用户tom访问users表格的权限,可以使用如下的SQL语句:
GRANT SELECT, INSERT ON users TO tom;
这里使用了GRANT命令,将SELECT和INSERT权限授予给用户tom,使其能够访问users表格。
如果需要授予更多的权限,可以在GRANT命令中添加更多的权限,例如:
GRANT SELECT, INSERT, UPDATE, DELETE ON users TO tom;
这里将SELECT、INSERT、UPDATE和DELETE权限授予给用户tom,使其能够对users表格进行更多的操作。
6. * count(*)与count(列名)的区别
简单来说:会不会统计空行
count(列名)会更好用,且不会统计空行,
但是count(*)的效率会更高
COUNT(*)和COUNT(列名)都是用于统计数据行数的函数,它们的作用是计算一个表格中的数据行数或满足条件的数据行数。它们之间的区别在于:
- COUNT(*)会统计所有的数据行数,包括NULL值,而COUNT(列名)只会统计指定列中非NULL值的数据行数。
- COUNT()的效率比COUNT(列名)高。因为COUNT()不需要判断NULL值,只需要统计数据行数,因此效率比COUNT(列名)高。
- COUNT(*)可以用于统计所有的数据行数,而COUNT(列名)只能用于统计指定列中的数据行数。
例如,假设有一个表格students,其中有一个字段score,现在我们想要统计students表格中所有的数据行数,可以使用如下的SQL语句:
SELECT COUNT(*) FROM students;
这里使用了COUNT(*)函数,统计了students表格中所有的数据行数。
如果我们想要统计students表格中score字段非NULL值的数据行数,可以使用如下的SQL语句:
SELECT COUNT(score) FROM students;
这里使用了COUNT(score)函数,统计了students表格中score字段非NULL值的数据行数。
总的来说,COUNT(*)和COUNT(列名)都是用于统计数据行数的函数,但是它们之间的区别在于COUNT()会统计所有的数据行数,包括NULL值,而COUNT(列名)只会统计指定列中非NULL值的数据行数。同时,COUNT()的效率比COUNT(列名)高,可以用于统计所有的数据行数。
7.复制表数据的语法
复制旧表的数据到新表
INSERT INTO 新表名 SELECT * FROM 旧表名
其中,新表名为目标表的名称,旧表名为原始表的名称。
这条语句将会把旧表中的数据逐行复制到新表中。
注意,新表的列名和数据类型必须与旧表一致,否则会出现错误。
复制表数据,只复制表结构:
CREATE TABLE 新表名 LIKE 旧表名;
其中,新表名为目标表的名称,旧表名为原始表的名称。
这条语句将会创建一个与旧表结构完全相同的新表,但是不会复制旧表中的数据。
如果需要复制数据,则需要使用 INSERT INTO SELECT 语句将旧表中的数据逐行复制到新表中。
8.*索引的优缺点有哪些?
提高数据的查询的效率(类似于书的目录)
可以保证数据库表中每一行数据的唯一性(唯一索引)
减少分组和排序的时间(使用分组和排序子句进行数据查询)
被索引的列会自动进行分组和排序
占用磁盘空间
降低更新表的效率(不仅要更新表中的数据,还要更新相对应的索引文件)
9.*数据库里面的慢查询是什么?
数据库中的慢查询指的是执行时间比较长的SQL查询语句,通常是指执行时间超过一定阈值(比如1秒钟)的查询语句。
慢查询通常是由于以下原因导致的:
- 数据库表中数据量过大,导致查询效率低下;
- 查询语句中使用了复杂的表连接、子查询等操作;
- 数据库缺乏必要的索引;
- 数据库服务器硬件性能不足,无法满足高并发查询的需求。
慢查询会导致数据库性能下降,影响系统的响应速度和用户体验。因此,对于慢查询需要进行优化,常用的优化方法包括:
- 使用索引优化查询语句;
- 对查询语句进行重构,减少复杂度;
- 对数据库服务器硬件进行升级,提高性能;
- 对数据库表进行拆分或分区,提高查询效率;
- 使用缓存技术,减少数据库访问次数。
通过对慢查询的优化,可以提高数据库的查询效率,提升系统的响应速度和用户体验。
10.**数据库性能优化的方法以及策略?
数据库里如何优化查询速度
1.select查询的时候,尽量不用* ,使用比较精准的列名,不用返回那些不必要的列
2.可以对经常查询的列增加索引,通过索引去查
3.在使用count查询的时候,如果没有空数据的话,可以使用count(*),加快了查询速度
4.使用limit控制分页来减少一次要查询的数据过多
5.有索引,调用索引去查询,创建索引时选择不常更新,但是经常要查询的列
6.尽量避免触发死锁,多个人同时操作一个字段,一个列
7.日志快满了,也会导致查询慢
8.数据库连接池满了,同时连接人数过多
9.合理的拆分表,进行业务分离
10.少用嵌套跟子查询
11.减少逻辑计算,少用函数
12.减少跨库查询操作
13.增加硬件的配置(内存,带宽,cpu)
14.使用缓存数据库,比如中间件redis(redis存放一些不重要,但是经常用的数据)
15.多表联查的时候,小表在前,大表在后。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐

 7
7 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)