腾讯云 Finops Crane 开发者集训营 - 让云不再“钱”途无量
通过对几次的CSDN的培训发现,对腾讯云有很大的改观,也是一个非常不错的选择,有些方面甚至做的更好。在后续的工作中,也会大量给公司推荐腾讯云的一些有效的方案,用于公司降本增效。公司在最开始的单体架构,为了应付各种公司商业模式快速上线,采用了全栈PHP开发模式,相对于公司的成本考虑,可以快速的满足业务的需求外,还能在一定程度上控制成本的增长。随着公司的业务发展,单体架构暴露的问题越来越多,公司内部逐
前言:
Finops Crane集训营主要面向广大开发者,旨在提升开发者在容器部署、K8s层面的动手实践能力,同时吸纳Crane开源项目贡献者,鼓励开发者提交issue、bug反馈等,并搭载线上直播、动手实验组队、有奖征文等系列技术活动。既能让开发者通过活动对 Finops Crane 开源项目有深入了解,同时也能帮助广大开发者在云原生技能上有实质性收获。
一、 背景:
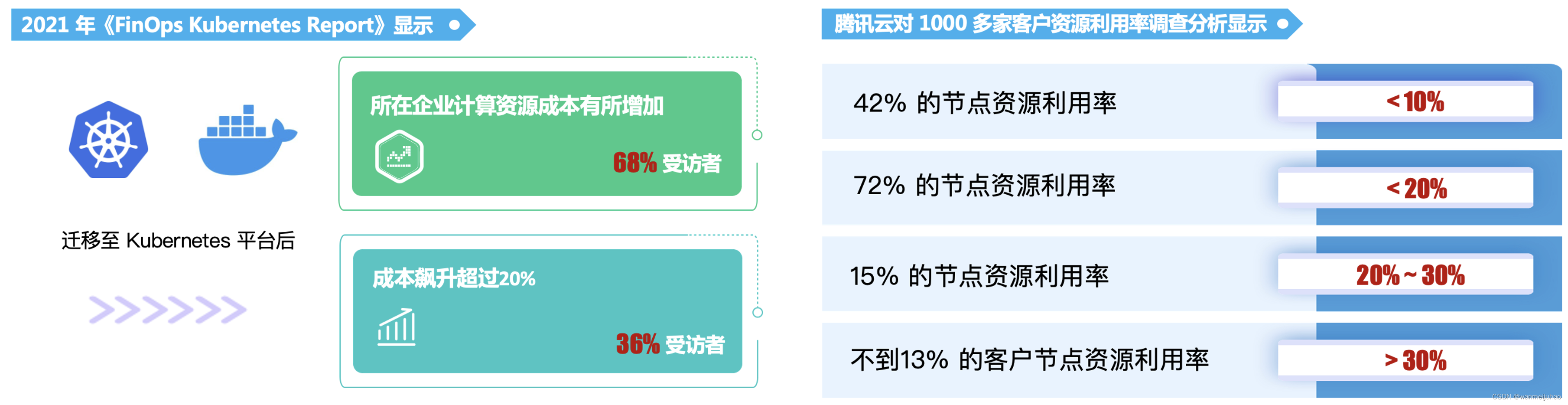
CNCF 云原生计算基金会 2021 年《FinOps Kubernetes Report》显示,迁移至 Kubernetes 平台后, 68% 的受访者表示所在企业计算资源成本有所增加,36% 的受访者表示成本飙升超过 20%。
附:相关数据参考《云原生.降本增效电子书》
1.云支出浪费成为企业用云普遍现象:
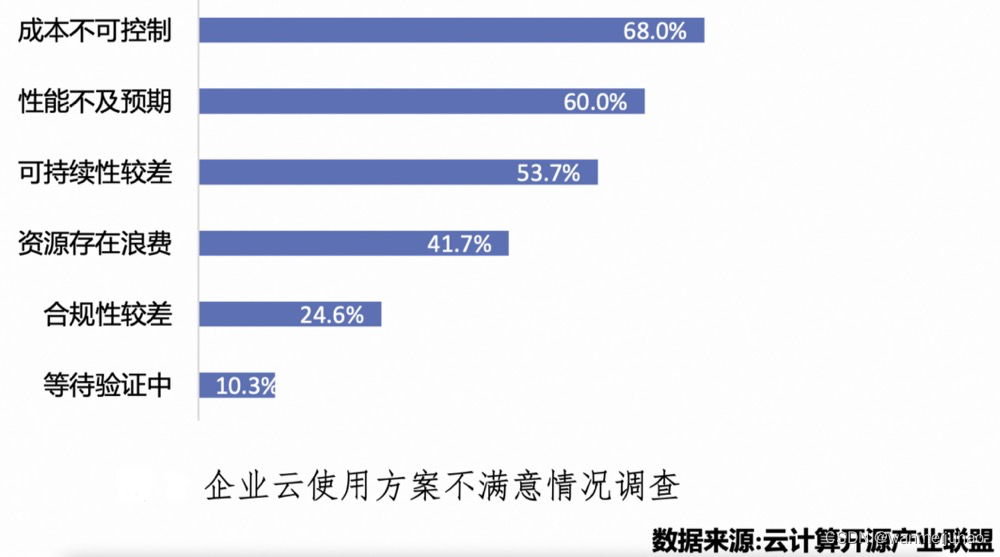
2.企业云上成本管理面临诸多挑战:
从以上数据可以看出,企业云原生应用带来好处的同时,也会造成云资源巨大的投入成本和浪费,大家对《如何提升资源利用率,实现降本增效》的需求愈发迫切。
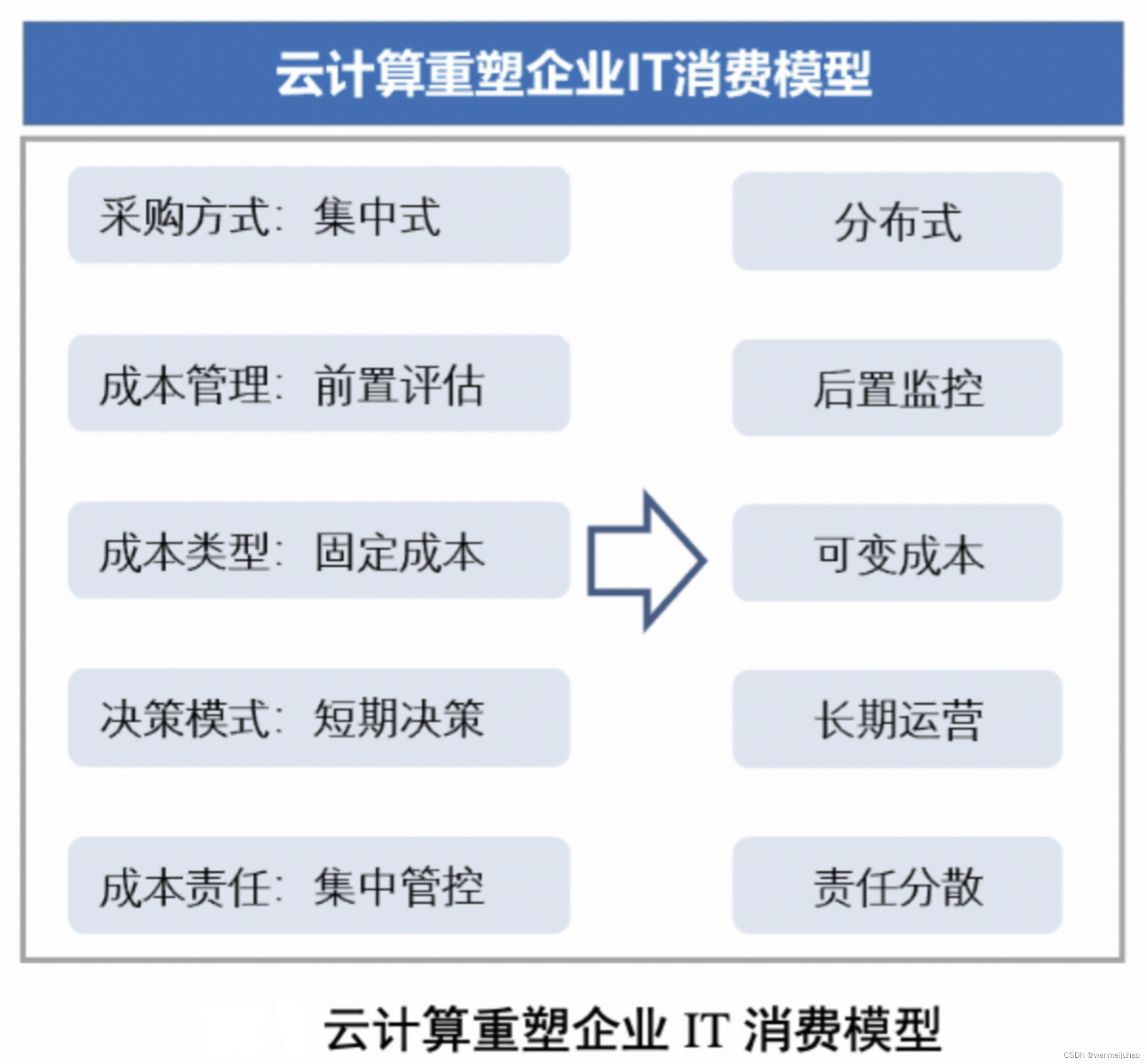
为了应对在后云原生时代,成本管理面临的诸多挑战,FinOps理念应运而生。
二、FinOps:
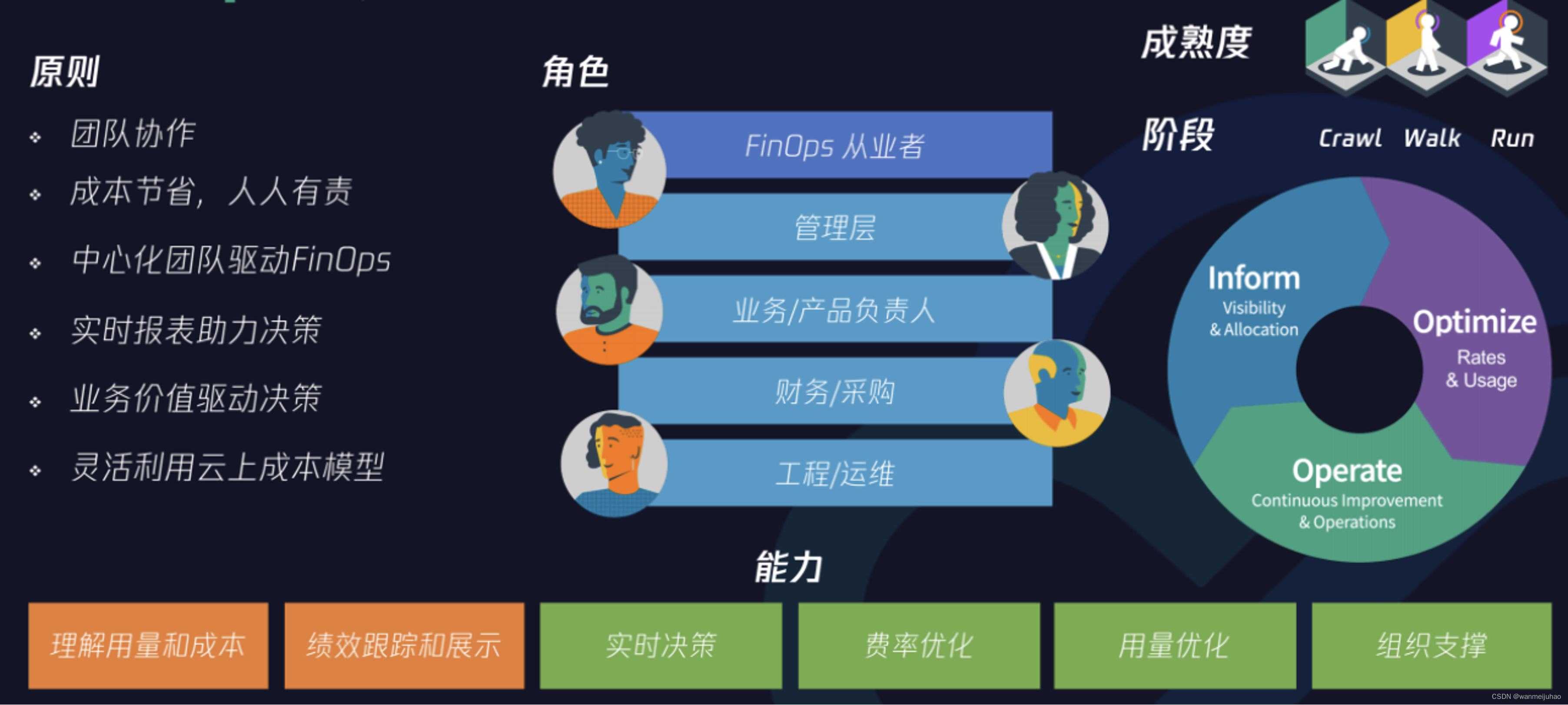
FinOps 定义了一系列云财务管理规则和最佳实践,通过助力工程和财务团队、技术和业务团队彼此合作, 进行数据驱动的成本决策,使组织能够获得最大收益。其原则、角色、成熟度、阶段、能力如下图所示。
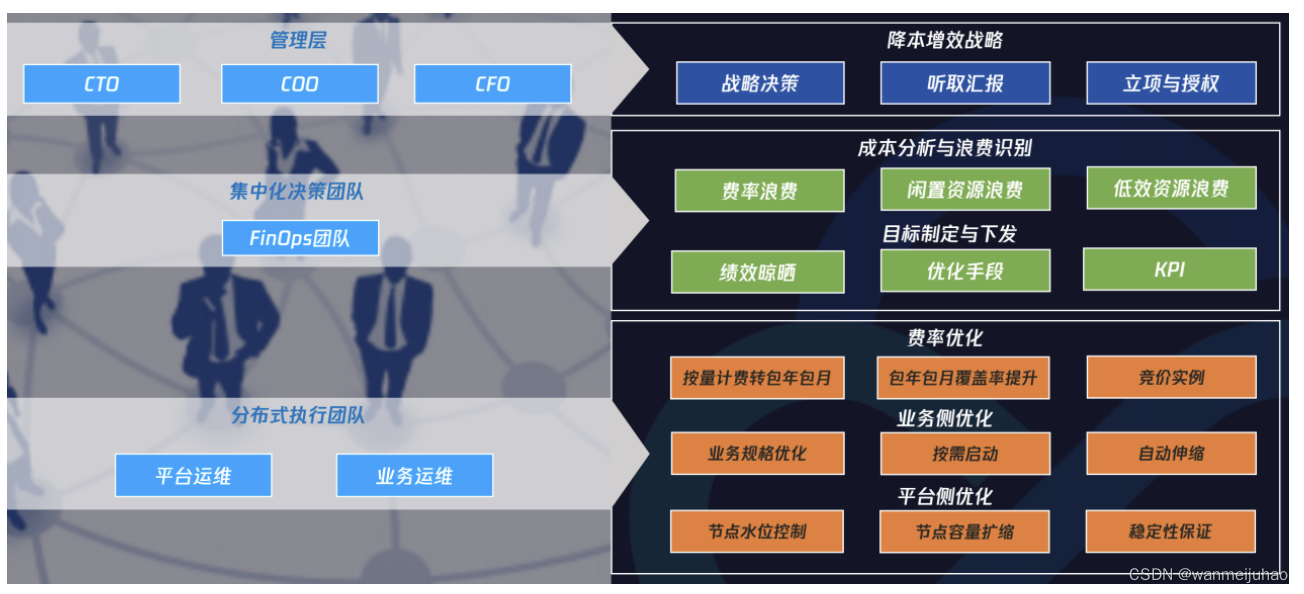
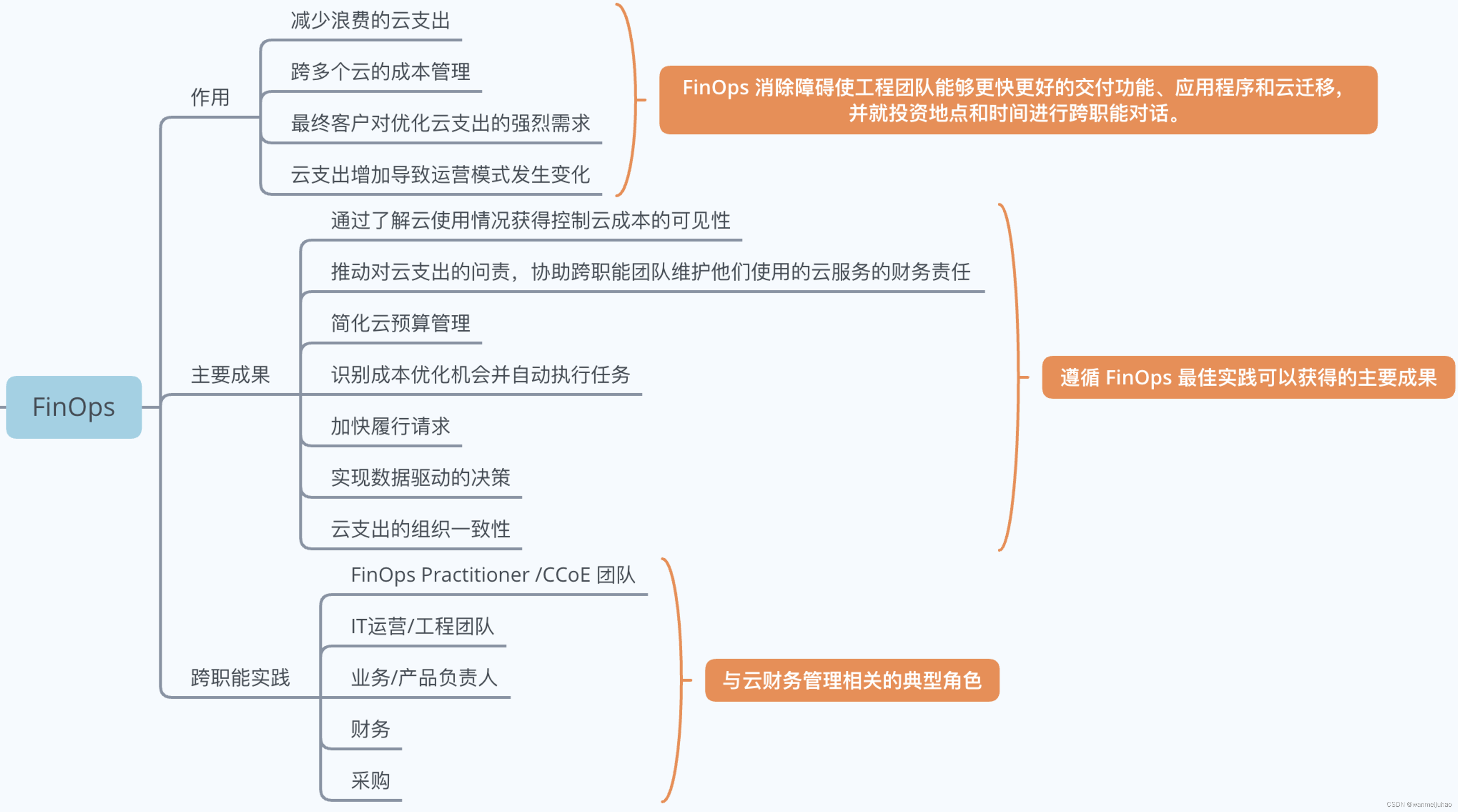
腾讯的云原生降本增效最佳实践是基于 FinOps 框架开展的。
Crane是一个基于 FinOps 的云资源分析与成本优化平台。它的愿景是在保证客户应用运行质量的前提下实现极致的降本。
三、 Crane:
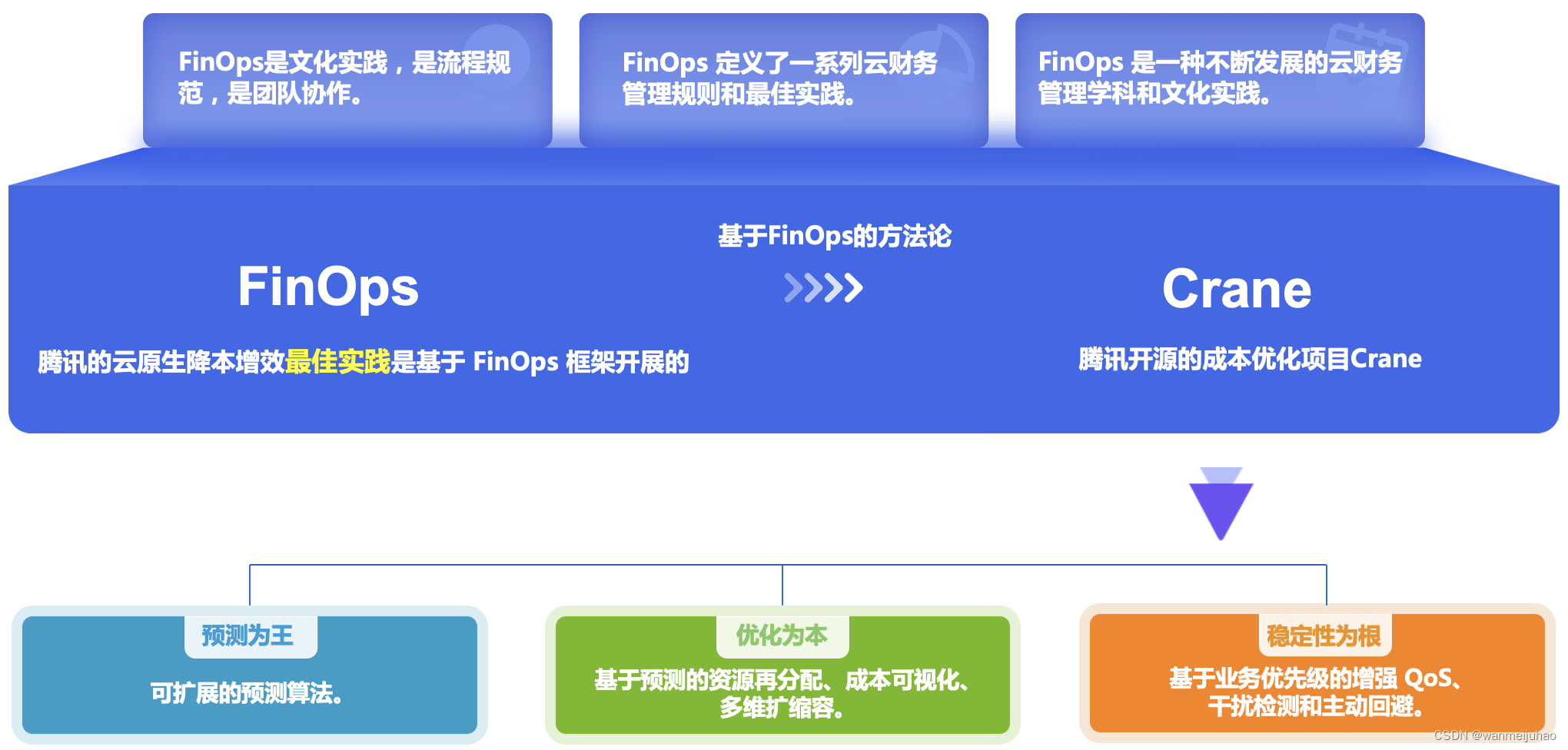
1.开源地址:
- GitHub - gocrane/crane: Crane (FinOps Crane) is an opensource project which manages cloud resource on Kubernetes stack, it is inspired by FinOps concepts.(Crane Github链接)
- Crane 官网:Introduction - Crane - Cloud Resource Analytics and Economics(中文官网链接)
- Crane 核心模块:(中文官网链接)
- Crane成本优化方向与核心功能:

- Crane 的整体架构:
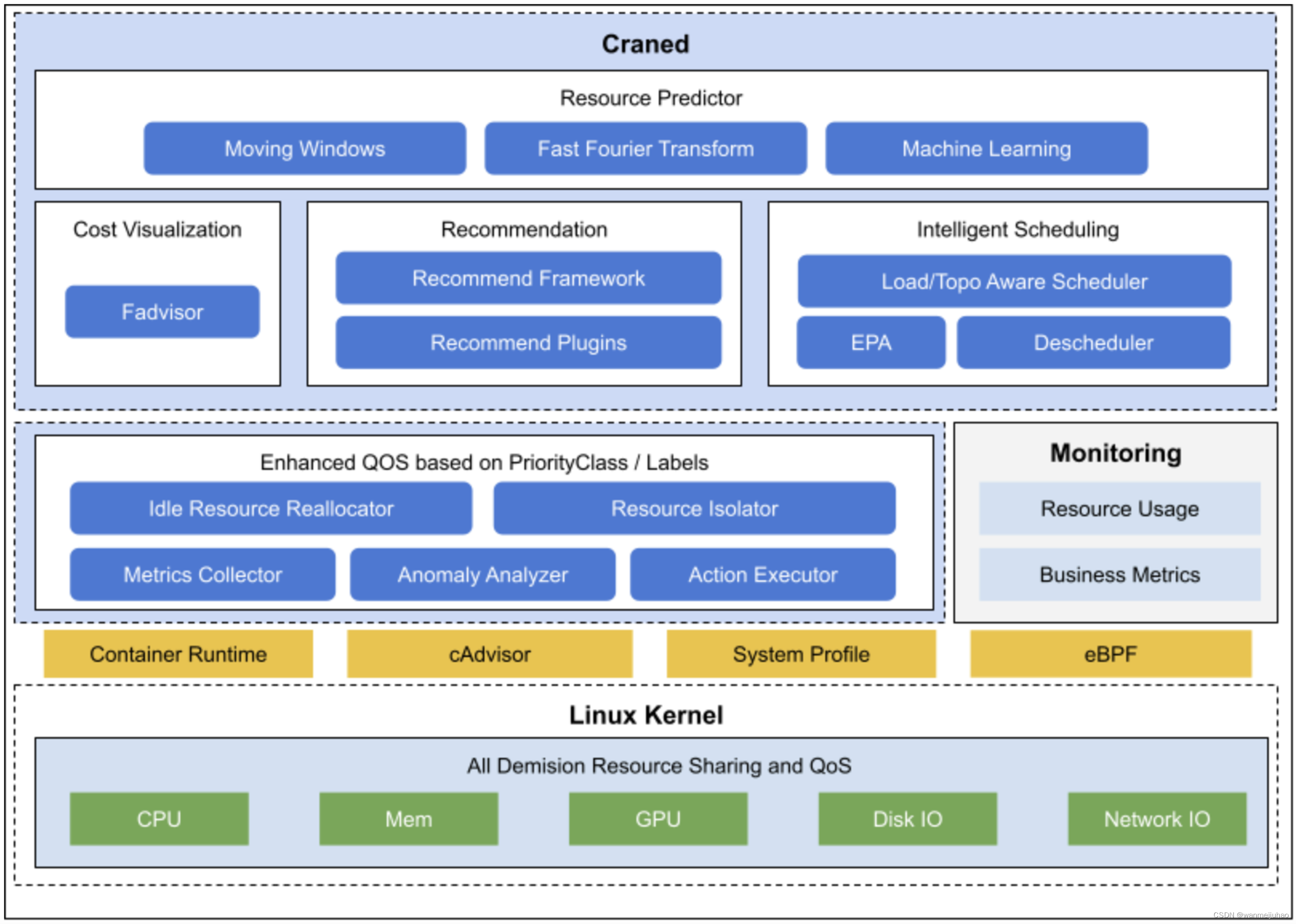

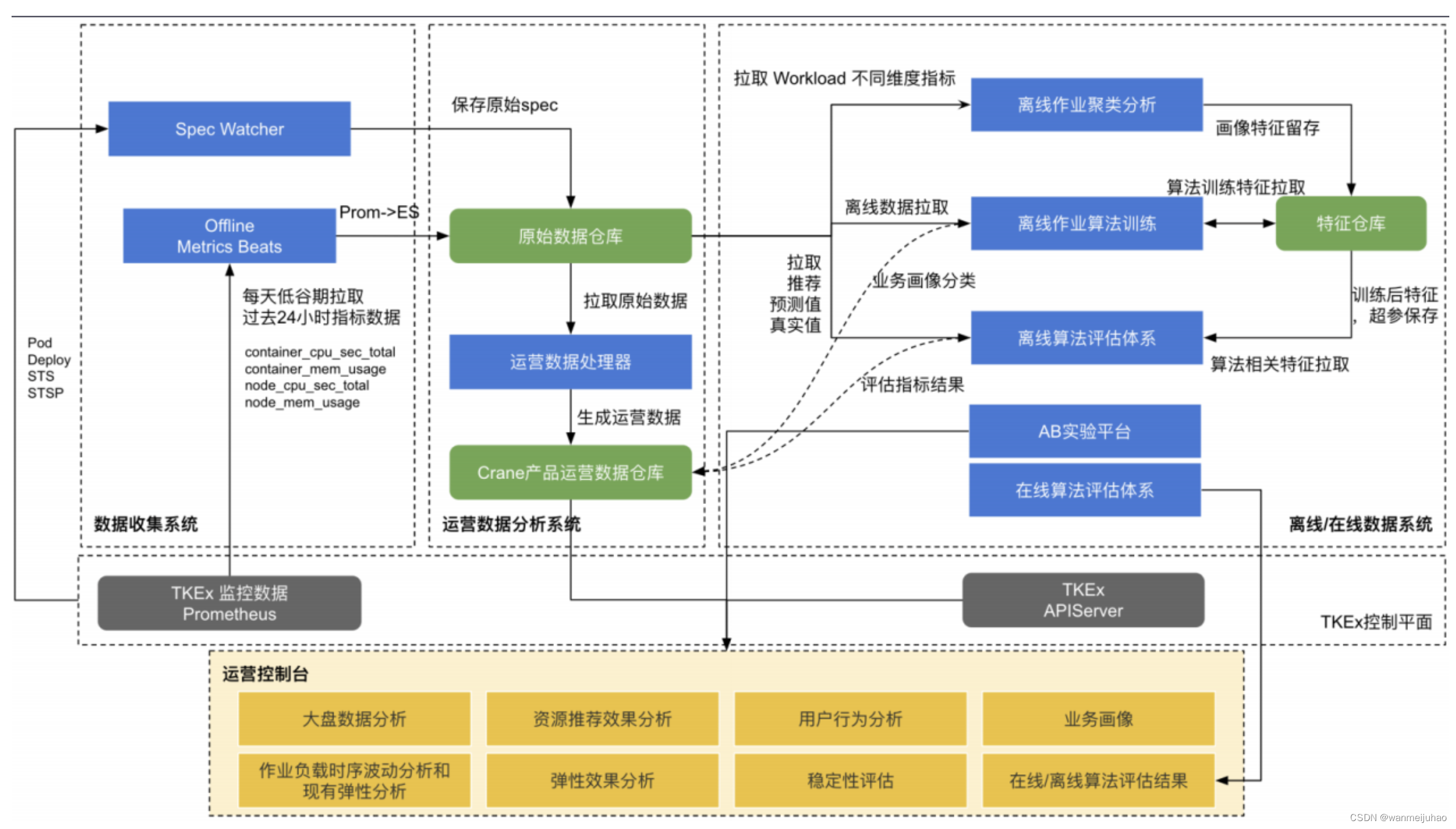
- Crane 不断迭代和优化大盘数据分析系统,满足各式运营数据需求:

5. 更多的了解参考视屏回播:
四、 公司技术架构演变:
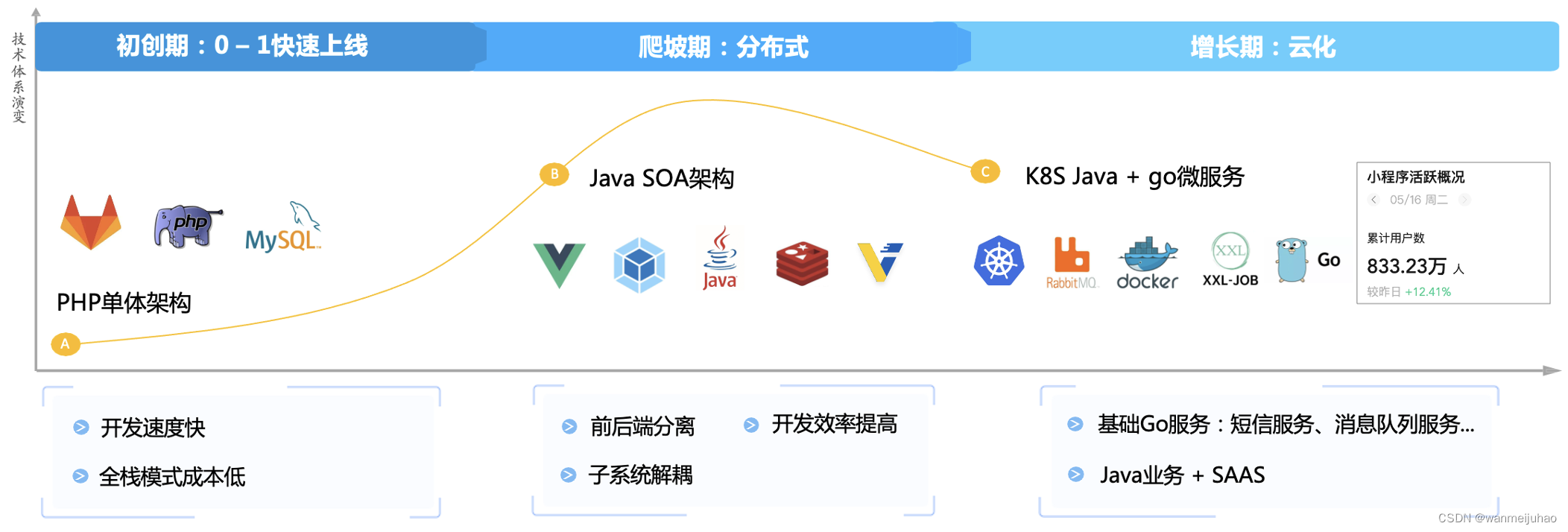
公司在最开始的单体架构,为了应付各种公司商业模式快速上线,采用了全栈PHP开发模式,相对于公司的成本考虑,可以快速的满足业务的需求外,还能在一定程度上控制成本的增长。
随着公司的业务发展,单体架构暴露的问题越来越多,公司内部逐渐向微服务云化进行过渡,可以看出,公司随着业务体量的增长,对应的技术研发费用越来越庞大了,几乎是暴增式正比。
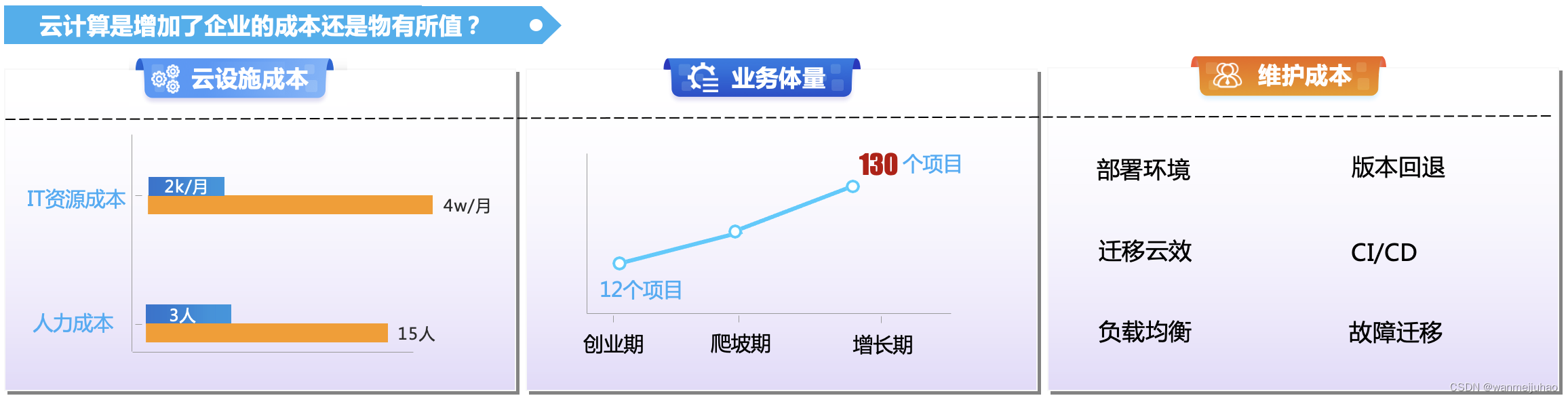
技术团队也是在配合公司的CostDown原则,也是做出一些降本提效的措施,比如通用性业务的SaaS化,抽离公共基础服务,减少重复开发。以下也可以看出技术部也仅仅是在建设工程化能力的方向上进行努力产出量化的成果。
如何将目标从如何使用云,转变为如何用好云?
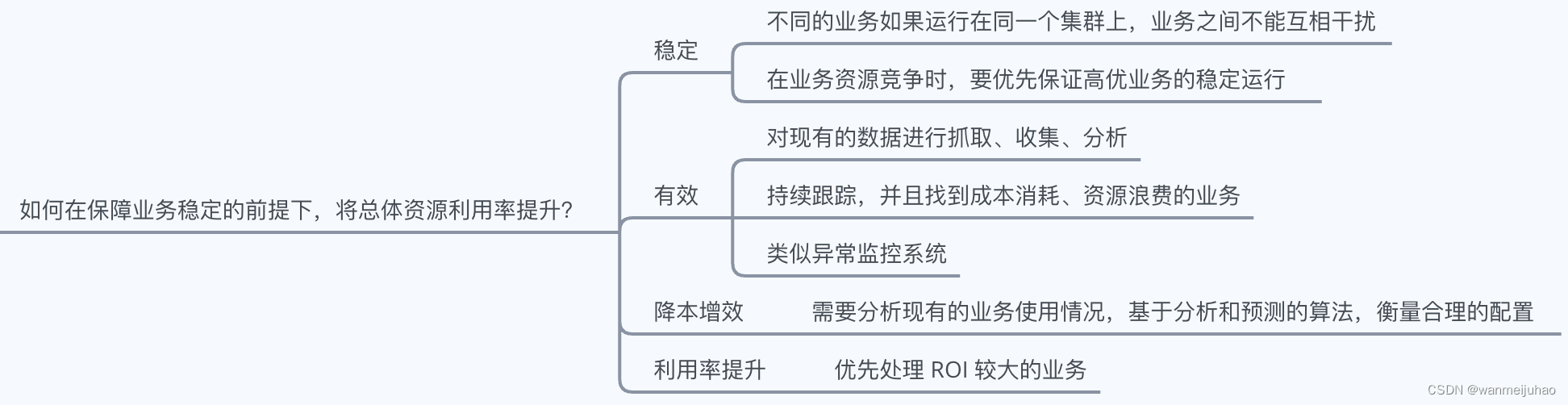
希望结合Finops的方案给创造核心价值赋能:
五、公司云服务面临的困境:
在k8s集群方案的优化上,目前也只是停留在探索期,目前在工作中发现的一些业务瓶颈:
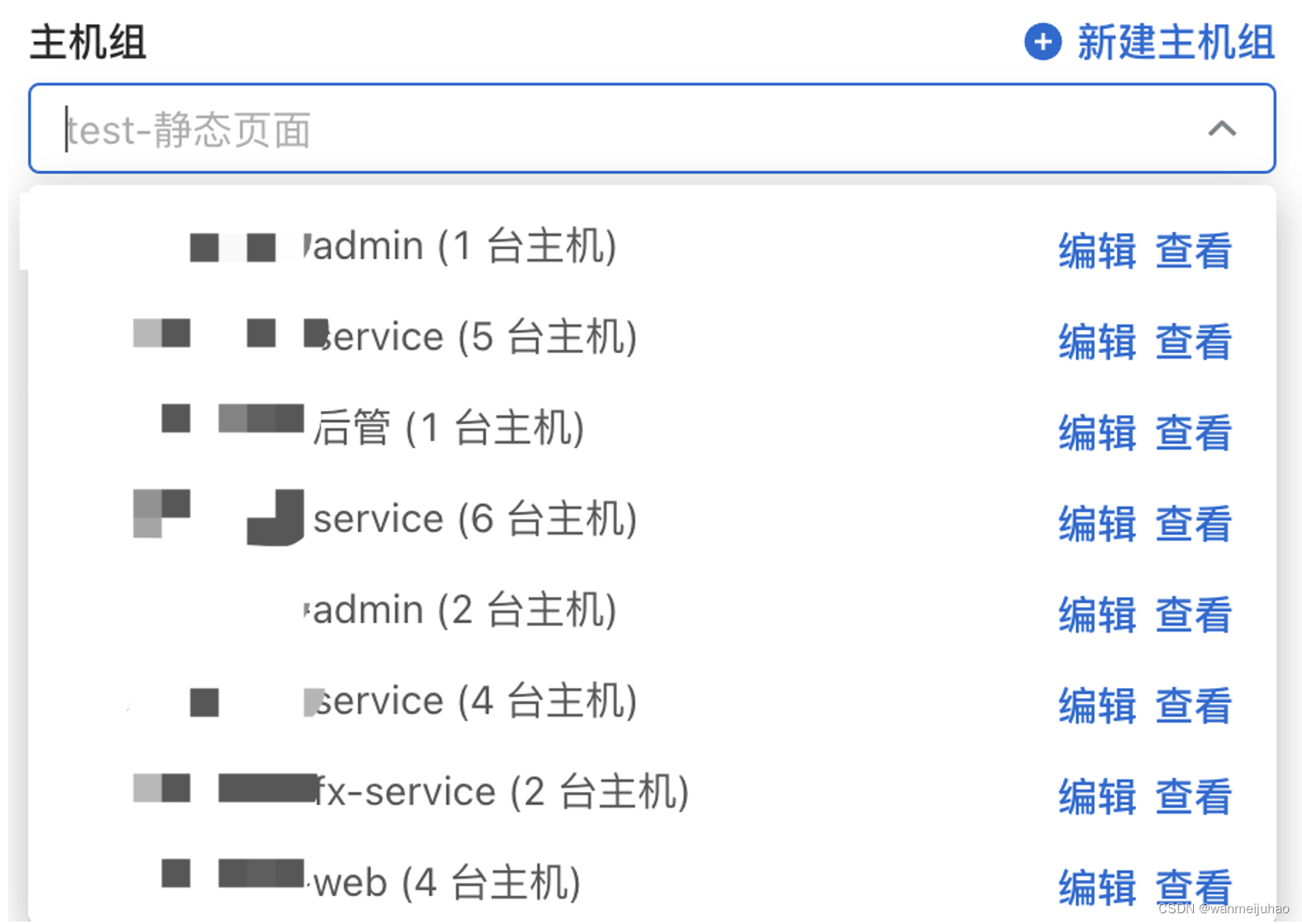
- 为了确保项目集群的稳定,可以看到以下资源分配:
- 后管服务一般是1台主机
- web服务按业务访问量,在业务前端会负载到2-6台服务器上,后续分析使用量再适当的降低
- 第三方合作公司服务器预算超限:
- 软件列表:包含数据库、中间件、开发语言及版本、nginx、httpd等相关软件
- 服务列表:包含有自开发或基于开源等开发应用服务
- 硬件列表:包含需要的硬件列表,如ECS、rds、polardb、NAS等基础设置
为了保证服务的稳定性,一般都是让第三方按最大配置进行开启,再部署相关服务。
- 目前自动扩容服务器比较原始:
经常是手动调配服务器的资源不足,不能动态的扩展,如果遇到双11这种大型活动,基本上要线上待命,保证系统的稳定性。
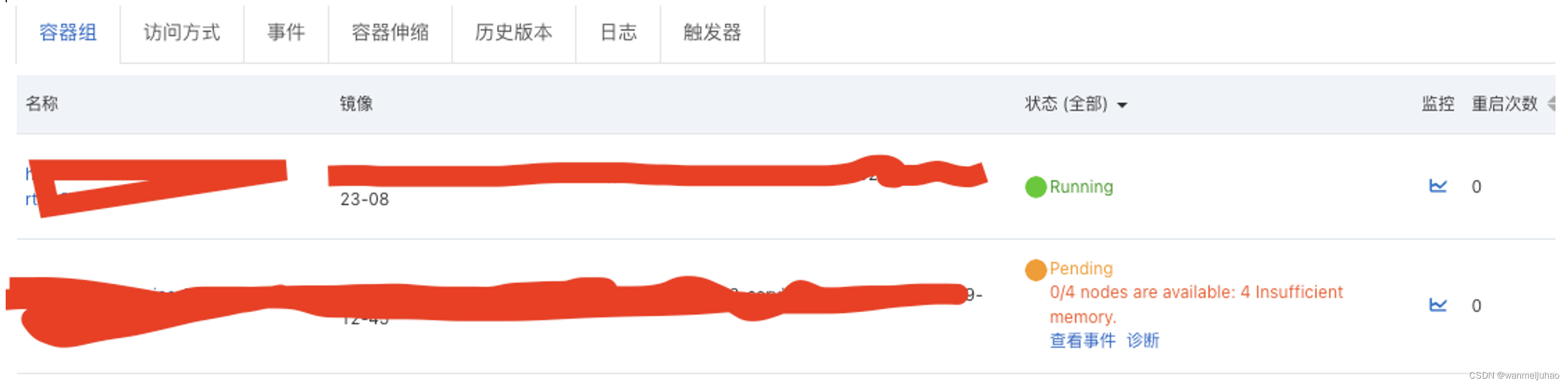
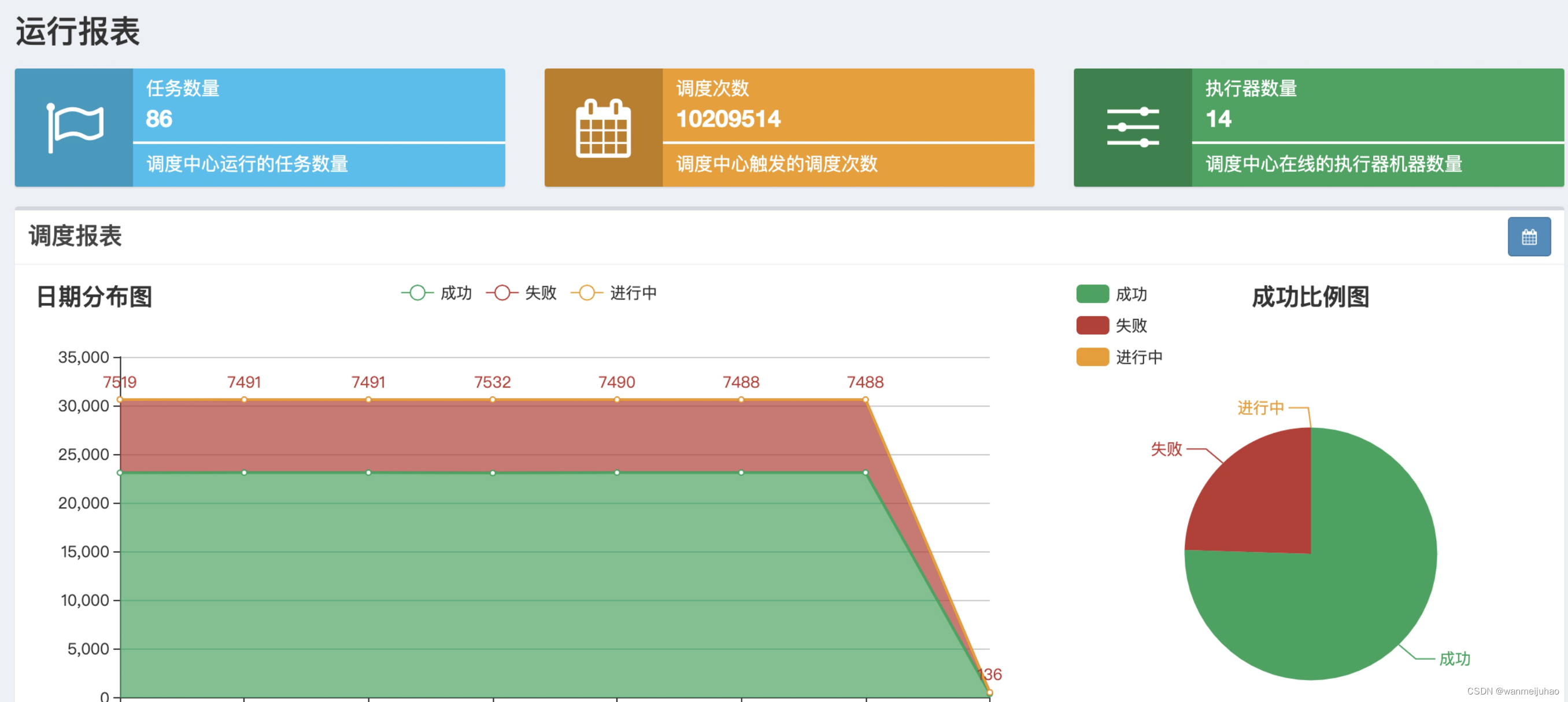
上图可以看到,xx-job的计划任务,失败率占了1/3,而且还会引起慢SQL占用资源,虽然做了MySQL主从。
是否可以使用Crane的混部方案?

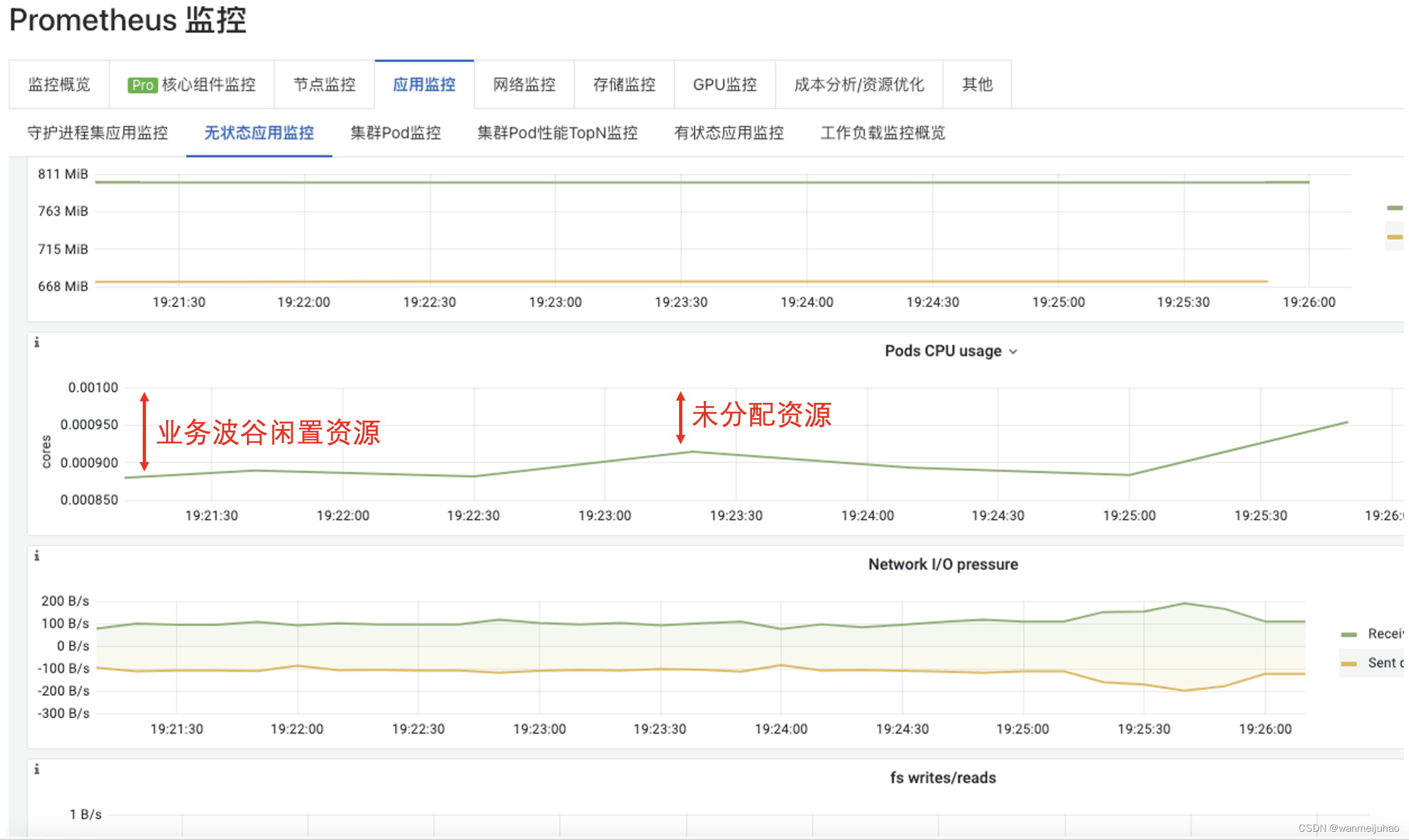
上图展示为生产系统的CPU资源等其它各种现状,从图中分析浪费的几个原因:

综合上面场景分析,可以看到在很多时候,其实云资源利用率不够灵活,大多数资源利用率不高。资源配置策略都是按最大预估量设置可能会导致资源浪费。

在参加由腾讯云联合 CSDN 推出的《云原生.降本增效电子书》、《腾讯云 Finops Crane 开发者集训营》线上培训后,了解一些通过云原生技术进行成本优化的方案,同时也学习了很多优秀实践方法论、资源与弹性、架构设计。
六、 测试环境实践Crane:
推荐测试的机器最好内存大于8G,否则会比较吃力,推荐linux/mac环境。测服已经有kubectl、docker软件

腾讯云 Finops Crane开发者集训营实验回播链接
测服机器配置:

- 安装Helm:
curl https://baltocdn.com/helm/signing.asc | gpg --dearmor | sudo tee /usr/share/keyrings/helm.gpg > /dev/null
sudo apt-get install apt-transport-https --yes
echo "deb [arch=$(dpkg --print-architecture) signed-by=/usr/share/keyrings/helm.gpg] https://baltocdn.com/helm/stable/debian/ all main" | sudo tee /etc/apt/sources.list.d/helm-stable-debian.list
sudo apt-get update
sudo apt-get install helm
- 安装Crane:
先将脚本下载下来:
https://raw.githubusercontent.com/gocrane/crane/main/hack/local-env-setup.sh
修改相关代码:
# 将以下名称修改为测服实际的集群名称
CRANE_CLUSTER_NAME="crane"
# 将以下代码注释
echo "Step1: Create local cluster: " ${CRANE_KUBECONFIG}
kind delete cluster --name="${CRANE_CLUSTER_NAME}" 2>&1
kind create cluster --kubeconfig "${CRANE_KUBECONFIG}" --name "${CRANE_CLUSTER_NAME}" --image kindest/node:v1.21.1
export KUBECONFIG="${CRANE_KUBECONFIG}"
echo "Step1: Create local cluster finished."
执行代码:
./ local-env-setup.sh
- 启动并确保所有 Pod 都正常运行:
export KUBECONFIG=${HOME}/.kube/config_crane # 建议写到环境变量文件,否则每开一个窗口就要初始化
kubectl get pod -n crane-system

- 访问 Crane Dashboard:
kubectl -n crane-system port-forward service/craned --address 0.0.0.0 9090:9090
开启测服9090端口:
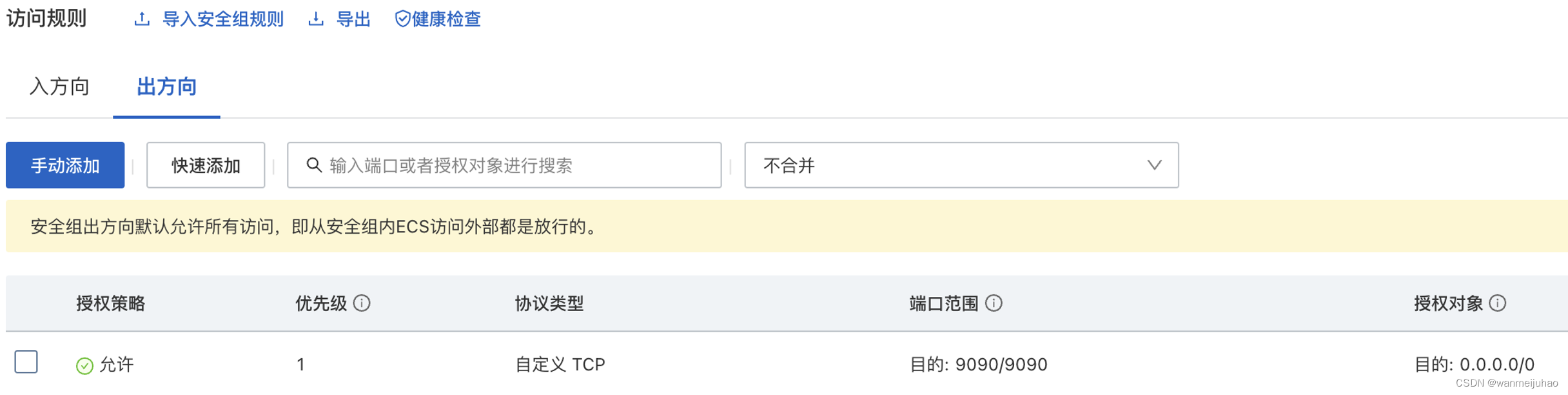

偶尔会出现失败的情况
- Crane页面:
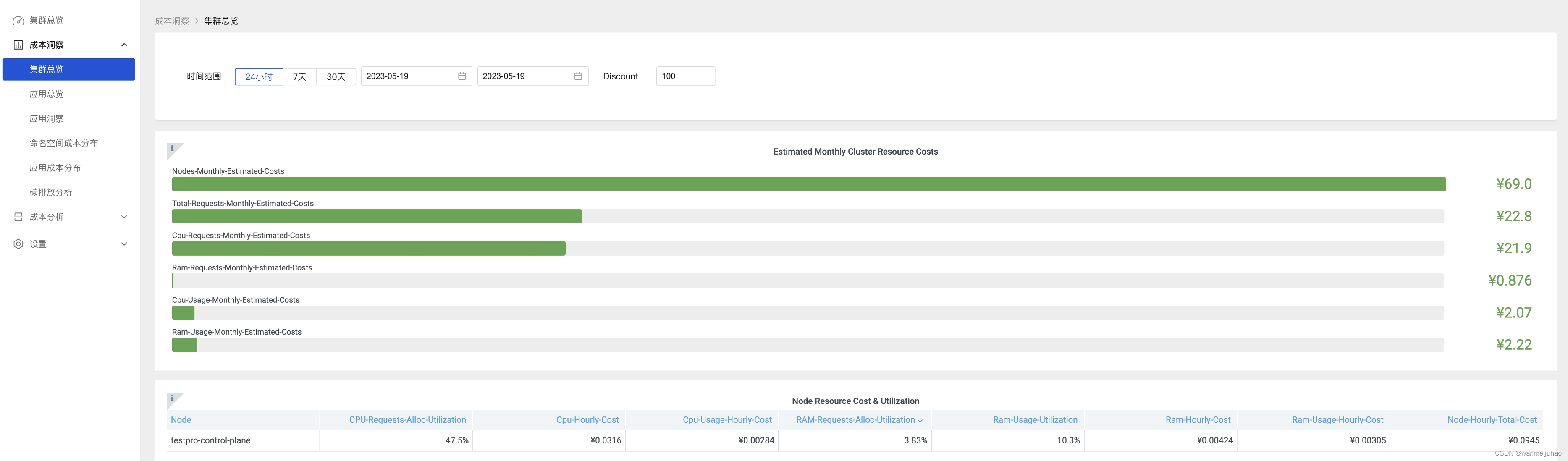
Crane Dashboard 提供了各式各样的图表展示了集群的成本和资源用量
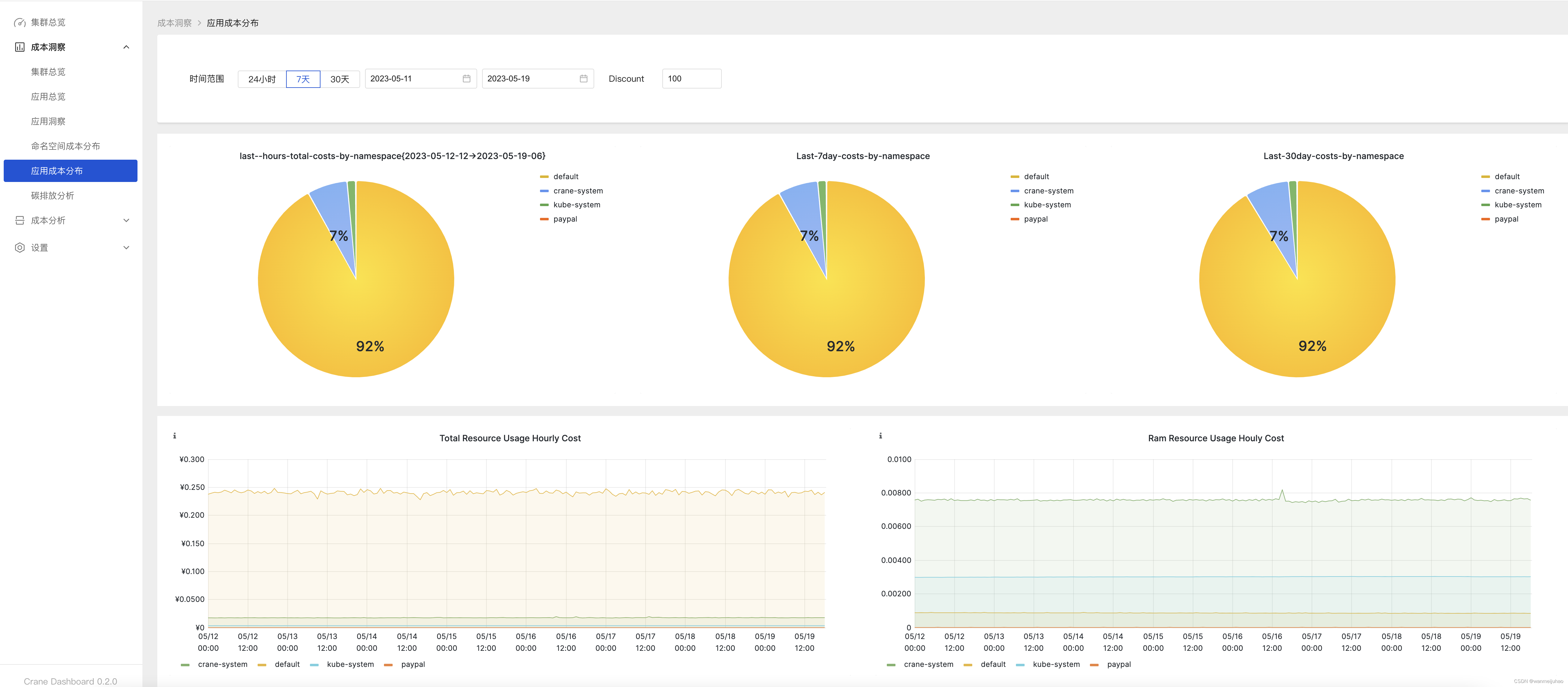
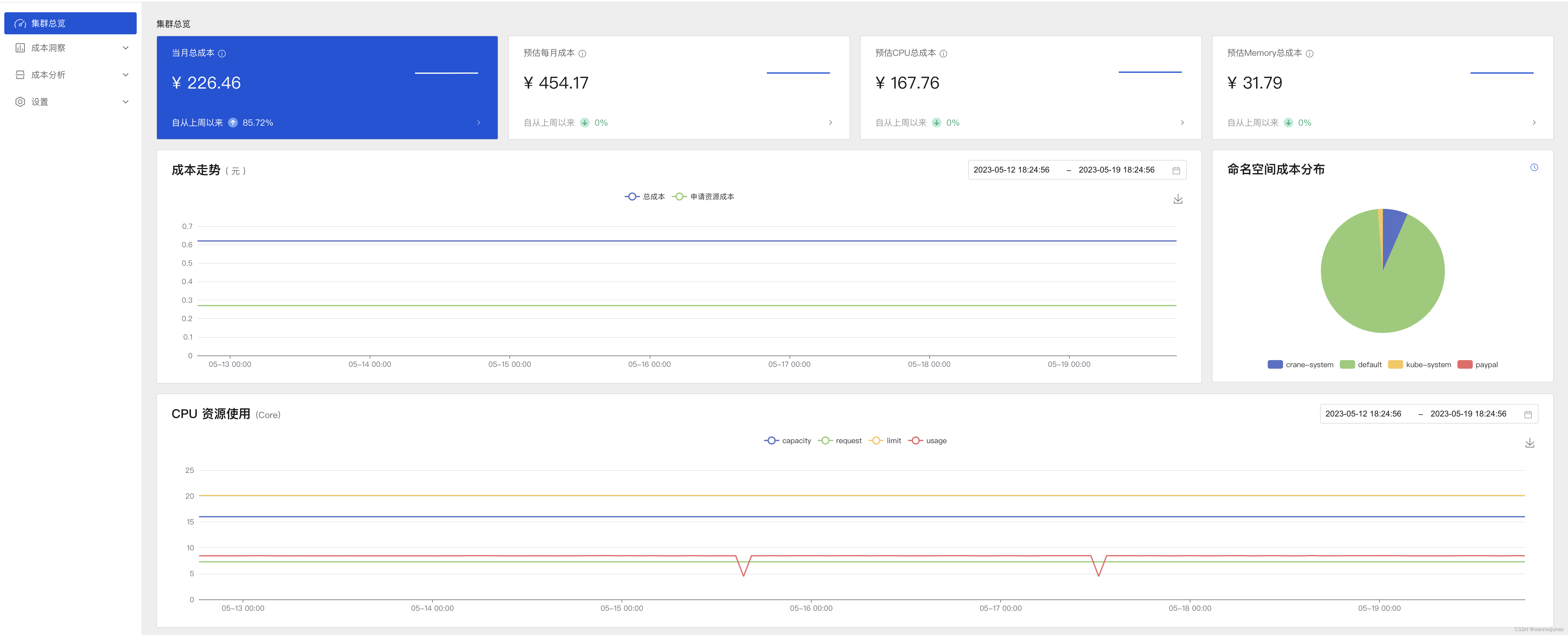
集群总览可以按照维度成本、集群成本和利用率指标以及命名空间成本来展示成本的分布情况:

该图中是运行 CPU 等资源持续一周的真实用量情况,评估资源利用率可以通过以下的纬度进行统计:
- 业务周峰值:每周最高的资源用量
- 日均峰值:每日峰值用量的均值
- 平均利用率:所有采样点的平均值
根据这些值的变化率,方便进行提升资源利用率,常见的手段包括:
- 业务优化:优化业务资源申请规格以及弹性扩缩容提升以缩减已申请但未使用的资源
- 调度优化:通过调度优化提升装箱率
- 混部:回收节点的闲时资源
Crane 会自动分析集群的各种资源的运行情况并给出优化建议,会定期检测发现集群资源配置的问题,并给出优化建议。不过,推荐应用在监控系统(比如 Prometheus)中的历史数据越久,推荐结果就越准确。
资源推荐页面也能查看到优化建议Recommendation 对象列表,根据配置定期运行推荐任务,给出优化建议来供系统调整资源配置:

查看闲置节点:

查看集群成本:

- Effective HPA基于社区 HPA 做底层的弹性控制:
Effective HPA(简称 EHPA)是开源项目 Crane 中的弹性伸缩产品,它基于社区 HPA 做底层的弹性控制,支持更丰富的弹性触发策略(预测,监控,周期),让弹性更加高效,并保障了服务的质量。
| 类型 | 利用率 | 管理配置类型 | 变更类型 |
|---|---|---|---|
| 社区 HPA | 平均利用率 | 副本数 | 自动变更 |
| 社区 VPA | 近似峰值利用率 | 资源 Request | 自动变更/建议 |
| Crane 推荐框架 | 周峰值利用率 | 副本数+资源 Request | 自动变更/建议 |
| 推荐框架的优势 | 虽然周峰值利用率带来的降本空间较小,但是配置简单,更加安全,适用更多应用类型 | 可以同时推荐副本数+资源 Request,按需调整 | 提供CRD/Metric方式的推荐建议,方便集成用户的系统,未来支持通过CICD实现自动更新 |

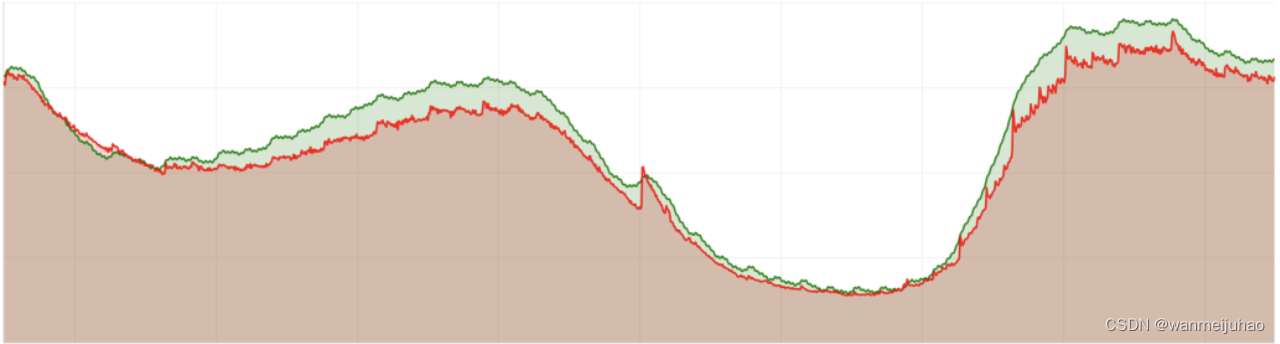
红色曲线是实际使用量,绿色曲线是算法预测出的使用量,可以看到算法可以很好的预测出使用量的趋势,并且根据参数实现一定的偏好(比如偏高)。
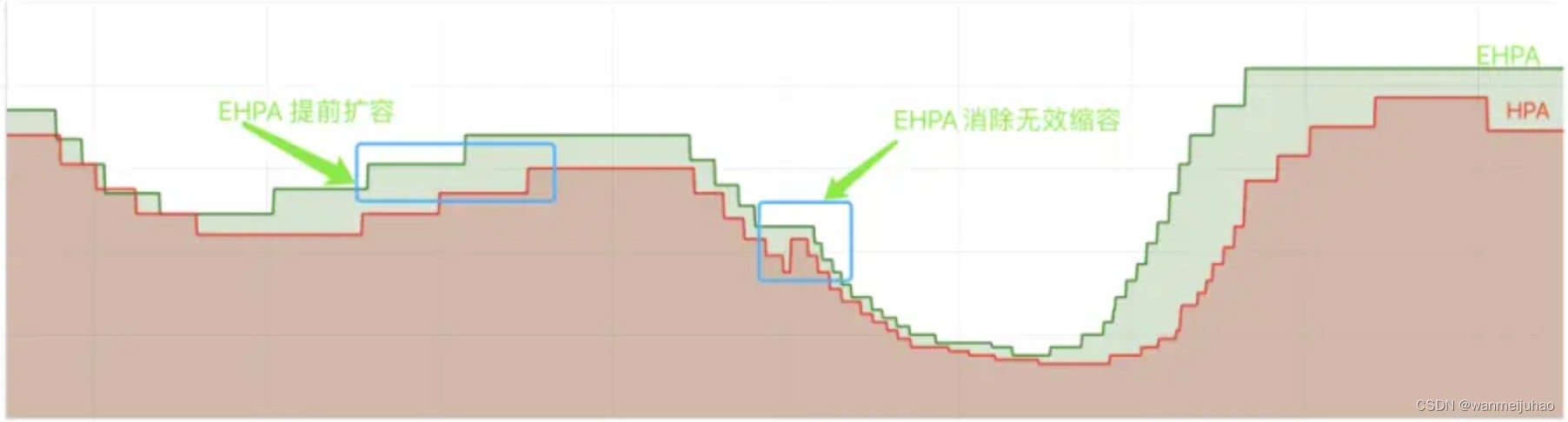
红色曲线是通过原生的 HPA 自动调整的副本数,而绿色曲线是通过 EHPA 自动调整的副本数,可以看到 EHPA 的弹性策略更加合理:提前弹和减少无效弹性。
七、参考实际优化成果:
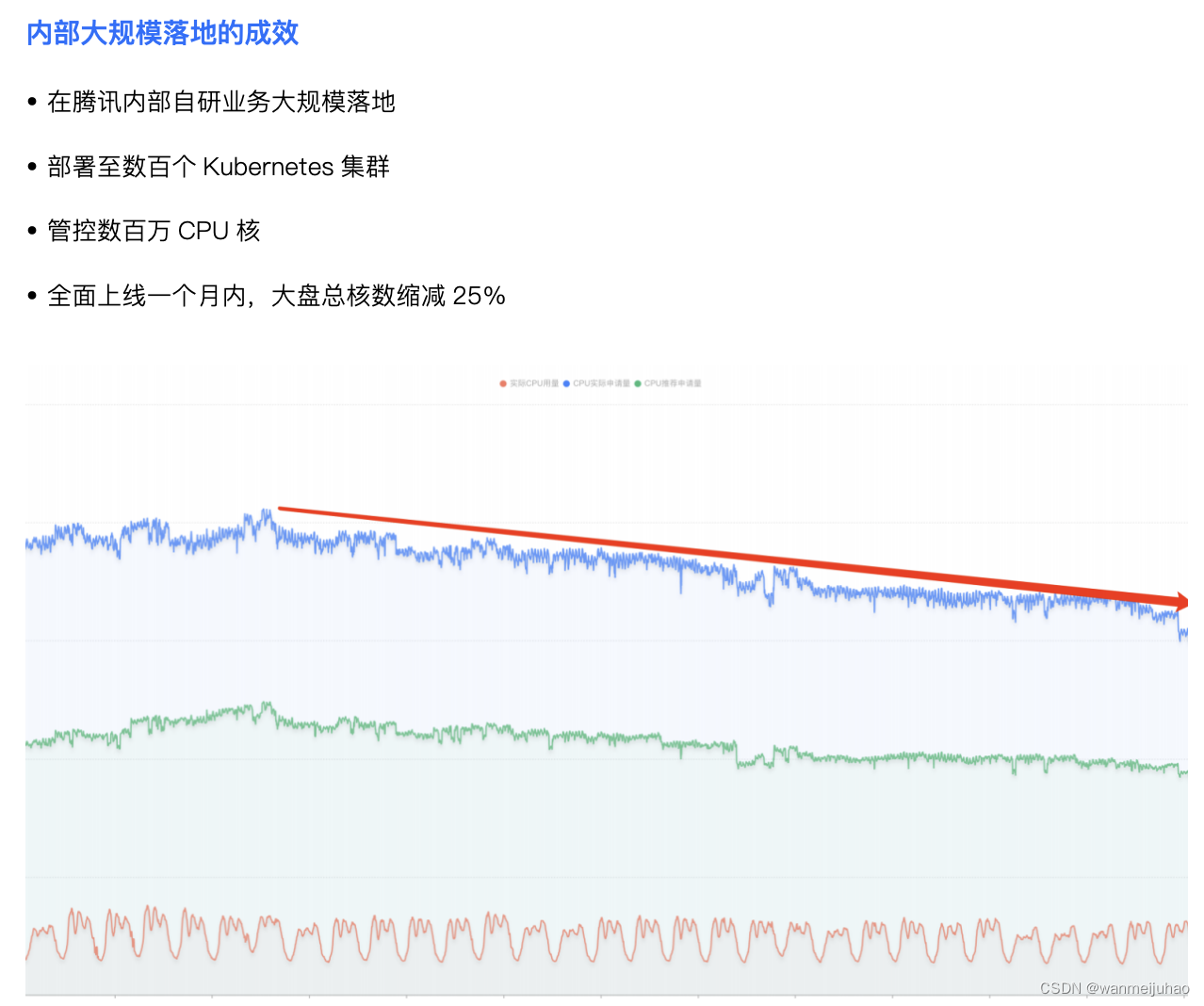
将 Crane 的各项能力落地到腾讯内部自研业务部门,管理数百个集群,十数万 Workload,数百万 Pod,充分的也体现了技术的可行性。
以腾讯内部部门集群优化为例,通过使用FinOps Crane,该部门在保障业务稳定的情况下,资源利用率提升了3倍;腾讯另一自研业务落地FinOps后,在一个月内实现了总CPU规模40万核的节省量,相当于每月成本节约超千万元。

其它知名的大公司也在生产系统中部署使用,有丰富的落地经验。
八、对公司落地的提案改善方案思考:
1.优化方案实现前的思考准备:
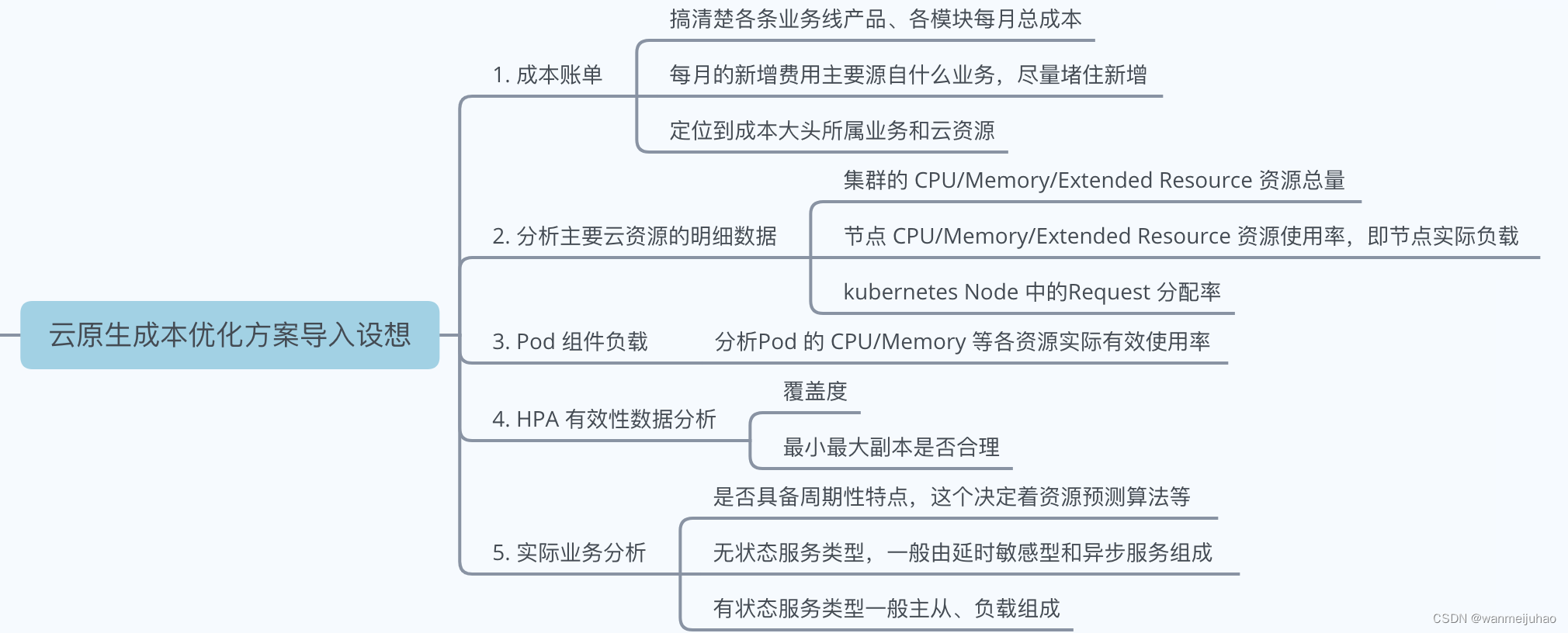
2.对公司落地的提案改善方案思考

九、对标其它云的产品:
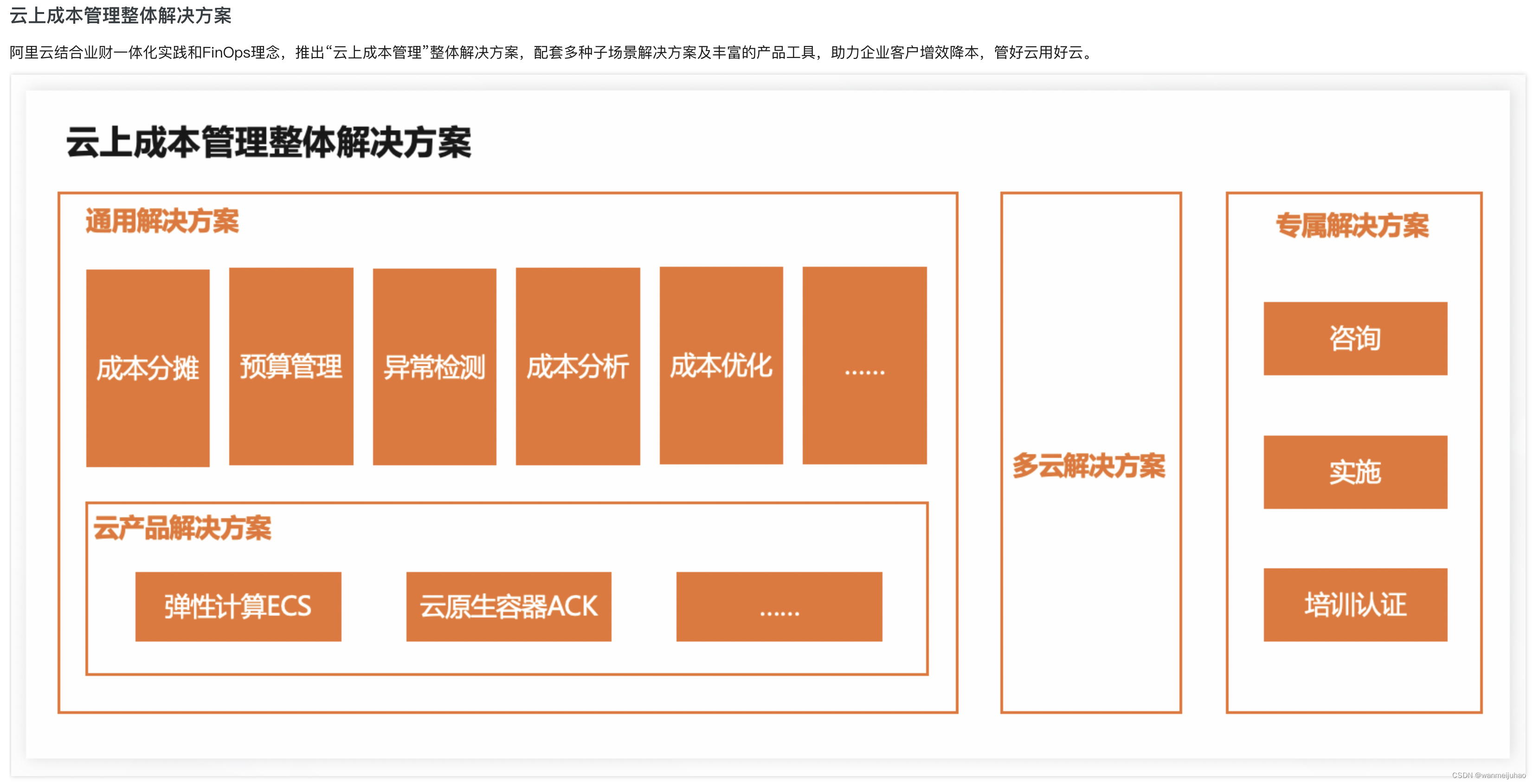
1.查看提供的“运维管理”工具:
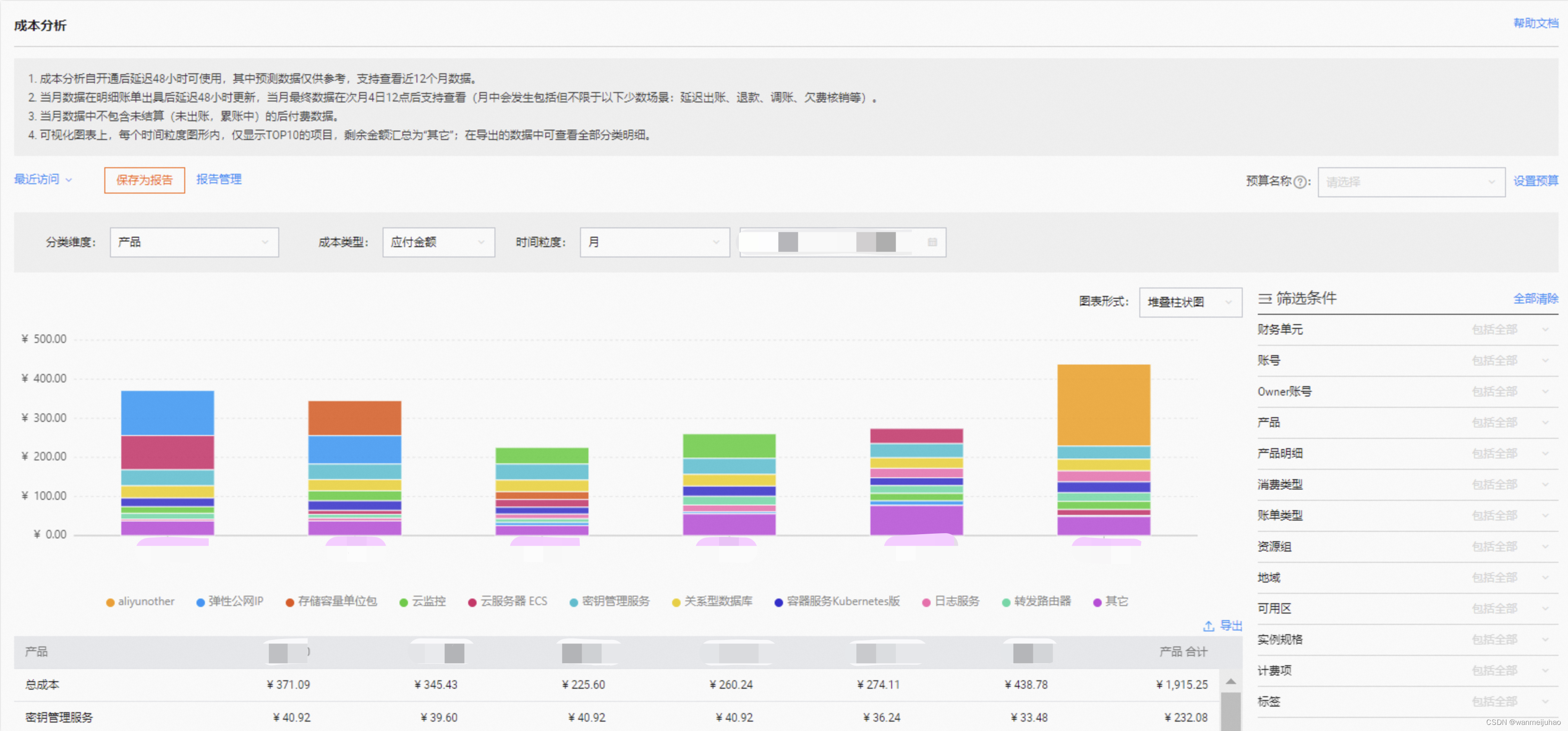
2.“成本分析”中,在费用趋势板块,可查看多类维度下的费用变化趋势:
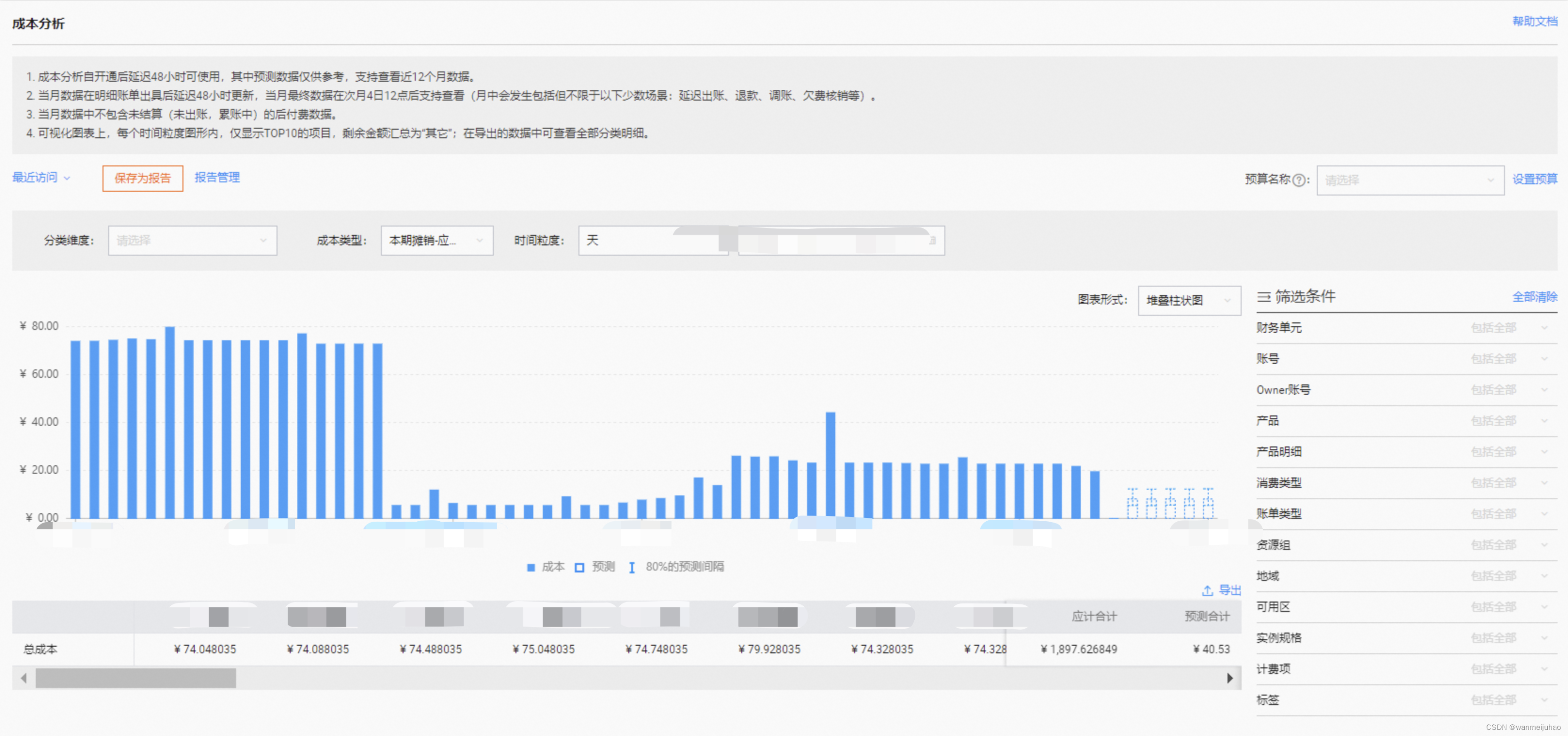
3.“成本分析”中,查看预测趋势:开启后可查看最大未来12个月的预测趋势数据:
个人感觉云成本这块,Crane这块做的还是比较好,可以结合上面的描述自行进行对比,仅代表个人观点。
十、源码分析:
- 技术栈体系:
go、react、typesrcipt
- 大体目录结构:
├─cmd
│ ├─craned
│ └─main.go # 入口文件,对应实际的pkg有许多功能代码,这里的思想有点类似于vue源码,比如web端、weex端
│
├─deploy # 部署相关yaml文件
│
├─doc # 文档相当
│
├─examples # 示例
│
├─pkg # 示例
│ ├─web # 前端相关代码
│ | agent
│ │ autoscaling
│ │ ...
│ └─webhooks # go代码
- 本地搭建并开发:
如果后端开发,需要一些前置条件,如docker、go环境、shell、make命令,推荐使用linux或mac
$ make Makefile
- 本地后端项目开发:
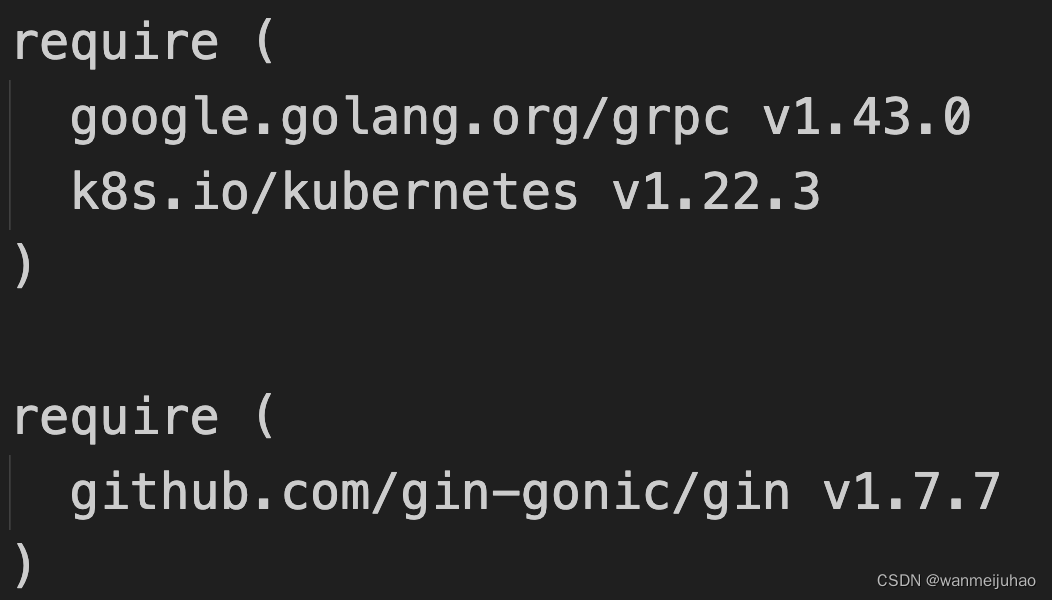
后端是使用了gin + grpc
- go代码中定义了大量了的interface接口,再去实现接口
- 代码中也含有不少单元测试的代码,提高项目的稳定性
4.1 入口文件:
crane/cmd/craned/main.go:
import (
"github.com/gocrane/crane/cmd/craned/app"
)
func main() {
...
# NewManagerCommand创建一个具有默认参数的*cobra.Command对象,再去执行一个Execute方法
# app是对应目录下的craned/app/manager.go文件
if err := app.NewManagerCommand(ctx).Execute(); err != nil {
fmt.Fprintf(os.Stderr, "%v\n", err)
os.Exit(1)
}
}
注:
1. 项目中使用了 cobra 库,"github.com/spf13/cobra"这个包来进行 cmd 的标准输入输出解析。
2. 个人在项目中比较常用的是 viper 包,"github.com/spf13/viper"
3. 入口文件比较简洁,一个日志初始化,一个获取 ctx 标准输入输出的上下文,一个是初始化应用
crane/cmd/craned/app/manager.go:
import {
# 这里引了很多pkg下面的go功能代码,可以在这里全部加载进来
"github.com/gocrane/crane/pkg/features"
"github.com/gocrane/crane/pkg/known"
"github.com/gocrane/crane/pkg/metrics"
...
}
func NewManagerCommand(ctx context.Context) *cobra.Command {
# 初始化options,对应文件`craned/app/options/options.go`
opts := options.NewOptions()
# 负责管理所有的controllers业务功能代码
cmd := &cobra.Command{
Use: "craned",
Long: `The crane manager is responsible for manage controllers in crane`,
Run: func(cmd *cobra.Command, args []string) {
...
# 解析cmd标准输入输出,并进行一些初始化工作,启动应用(主要逻辑块)
if err := Run(ctx, opts); err != nil {
klog.Exit(err)
}
},
}
cmd.Flags().AddGoFlagSet(flag.CommandLine)
# 添加一些默认参数,比如没有传的参数,会在这里做一些初始化操作
opts.AddFlags(cmd.Flags())
utilfeature.DefaultMutableFeatureGate.AddFlag(cmd.Flags())
return cmd
}
4.2 业务主函数逻辑:
func Run(ctx context.Context, opts *options.Options) error {
config := ctrl.GetConfigOrDie()
config.QPS = float32(opts.ApiQps)
config.Burst = opts.ApiBurst
# 1. 将传参和自定义初始化的默认参数进行合成为一个ctrlOptions
ctrlOptions := ctrl.Options{
Scheme: scheme,
MetricsBindAddress: opts.MetricsAddr,
Port: 9443,
HealthProbeBindAddress: opts.BindAddr,
LeaderElection: opts.LeaderElection.LeaderElect,
LeaderElectionID: "craned",
LeaderElectionNamespace: known.CraneSystemNamespace,
}
if opts.CacheUnstructured {
ctrlOptions.NewClient = NewCacheUnstructuredClient
}
mgr, err := ctrl.NewManager(config, ctrlOptions)
if err != nil {
klog.ErrorS(err, "unable to start crane manager")
return err
}
# 2. 设置健康检查
if err := mgr.AddHealthzCheck("healthz", healthz.Ping); err != nil {
klog.ErrorS(err, "failed to add health check endpoint")
return err
}
# 设置就绪检查
if err := mgr.AddReadyzCheck("readyz", healthz.Ping); err != nil {
klog.ErrorS(err, "failed to add health check endpoint")
return err
}
# 3. 将一些metricserver、grpc、mock、prometheus、prom信息放到map切片中
# 并返回3个值realtimeDataSources, historyDataSources, hybridDataSources
realtimeDataSources, historyDataSources, dataSourceProviders := initDataSources(mgr, opts)
# 时间序列预测的 Controller 的对象,与 EHPA 有关,下面会分析
predictorMgr := initPredictorManager(opts, realtimeDataSources, historyDataSources)
# 4. 启动features配置项,可以定义是否开启
# 比如:Autoscaling、Analysis、NodeResource、NodeResourceTopology、PodResource、ClusterNodePrediction、CraneCPUManager等。
# 对应文件:`crane/pkg/features/features.go`
initScheme()
# 注册nodeName indexer
initFieldIndexer(mgr)
# 初始化webhook服务
# 对应`crane/pkg/webhooks`下面文件
initWebhooks(mgr, opts)
# 5. 内存配置过低,配置并管理 pod oom event 相关逻辑
# 对应文件`crane/pkg/oom/recorder.go`
podOOMRecorder := &oom.PodOOMRecorder{
Client: mgr.GetClient(),
OOMRecordMaxNumber: opts.OOMRecordMaxNumber,
}
if err := podOOMRecorder.SetupWithManager(mgr); err != nil {
klog.Exit(err, "Unable to create controller", "PodOOMRecorder")
}
go func() {
if err := podOOMRecorder.Run(ctx.Done()); err != nil {
klog.Warningf("Run oom recorder failed: %v", err)
}
}()
# 6. 多种 Recommender 来实现面向不同资源的优化推荐,下面会分析
recommenderMgr := initRecommenderManager(opts)
initControllers(podOOMRecorder, mgr, opts, predictorMgr, recommenderMgr, historyDataSources[providers.PrometheusDataSource])
// initialize custom collector metrics
initMetricCollector(mgr)
runAll(ctx, mgr, predictorMgr, dataSourceProviders[providers.PrometheusDataSource], opts)
return nil
}
注:
1. kubectl -n crane-system port-forward service/craned 9090:9090初始化项目时的传参解析
2. 大多数pkg中的业务代码在Run函数中都有使用
4.3 Recommender:
crane/pkg/recommendation/recommender/interfaces.go:
type Recommender interface {
Name() string
framework.Filter
framework.PrePrepare
framework.Prepare
framework.PostPrepare
framework.PreRecommend
framework.Recommend
framework.PostRecommend
framework.Observe
}
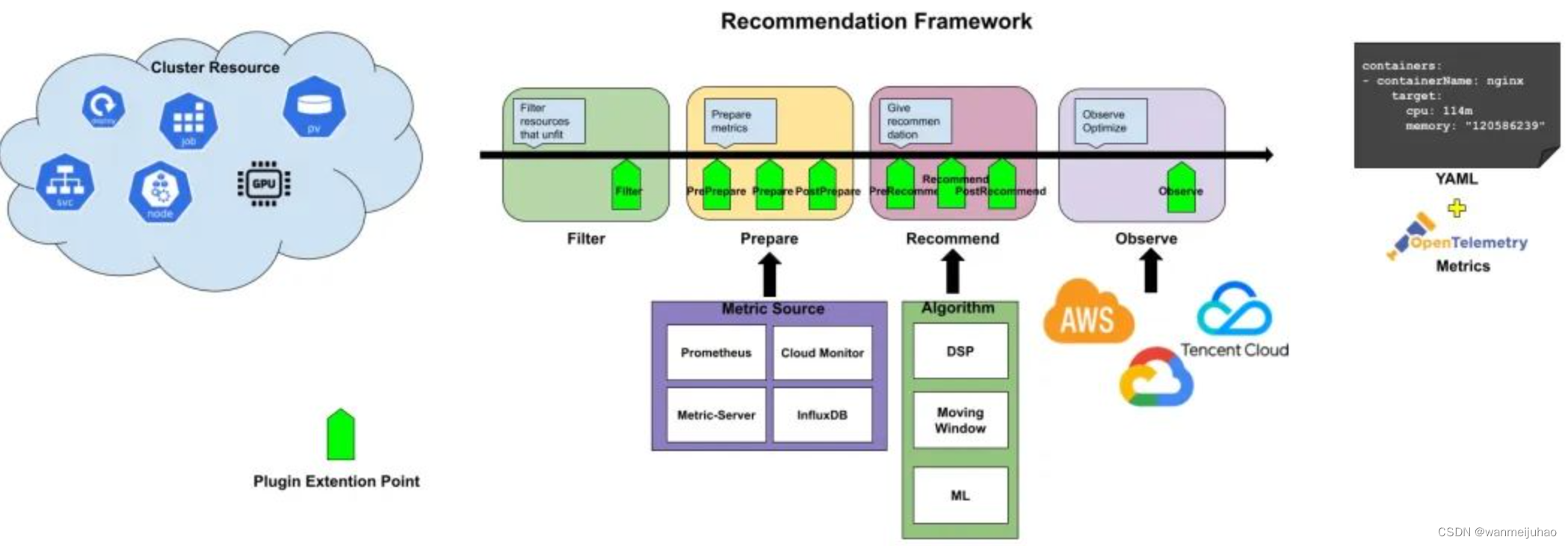
比如资源推荐就实现了 Recommender 接口,主要做了下面 3 个阶段的处理:
- Filter 阶段:过滤没有 Pod 的工作负载
- Recommend 推荐:采用 VPA 的滑动窗口算法分别计算每个容器的 CPU 和内存并给出对应的推荐值
- Observe 推荐:将推荐资源配置记录到 crane_analytics_replicas_recommendation指标
crane/pkg/recommendation/manager.go:
func NewRecommenderManager(recommendationConfiguration string) RecommenderManager {
m := &manager{
recommendationConfiguration: recommendationConfiguration,
}
m.loadConfigFile() // nolint:errcheck
go m.watchConfigFile()
return m
}
# 对应上面图 Filter、Prepare、Recommend、Observe 几个阶段
func Run(ctx *framework.RecommendationContext, recommender recommender.Recommender) error {
klog.Infof("%s: start to run recommender %q.", ctx.String(), recommender.Name())
// 1. Filter phase
err := recommender.Filter(ctx)
if err != nil {
klog.Errorf("%s: recommender %q failed at filter phase: %v", ctx.String(), recommender.Name(), err)
return err
}
// 2. PrePrepare phase
err = recommender.CheckDataProviders(ctx)
if err != nil {
klog.Errorf("%s: recommender %q failed at prepare check data provider phase: %v", ctx.String(), recommender.Name(), err)
return err
}
// 3. Prepare phase
err = recommender.CollectData(ctx)
if err != nil {
klog.Errorf("%s: recommender %q failed at prepare collect data phase: %v", ctx.String(), recommender.Name(), err)
return err
}
// 4. PostPrepare phase
err = recommender.PostProcessing(ctx)
if err != nil {
klog.Errorf("%s: recommender %q failed at prepare data post processing phase: %v", ctx.String(), recommender.Name(), err)
return err
}
// 5. PreRecommend phase
err = recommender.PreRecommend(ctx)
if err != nil {
klog.Errorf("%s: recommender %q failed at pre commend phase: %v", ctx.String(), recommender.Name(), err)
return err
}
// 6. Recommend phase
err = recommender.Recommend(ctx)
if err != nil {
klog.Errorf("%s: recommender %q failed at recommend phase: %v", ctx.String(), recommender.Name(), err)
return err
}
// 7. PostRecommend phase, add policy
err = recommender.Policy(ctx)
if err != nil {
klog.Errorf("%s: recommender %q failed at recommend policy phase: %v", ctx.String(), recommender.Name(), err)
return err
}
// 8. Observe phase
err = recommender.Observe(ctx)
if err != nil {
klog.Errorf("%s: recommender %q failed at observe phase: %v", ctx.String(), recommender.Name(), err)
return err
}
klog.Infof("%s: finish to run recommender %q.", ctx.String(), recommender.Name())
return nil
}
4.3 结合源码与图进行EHPA分析:
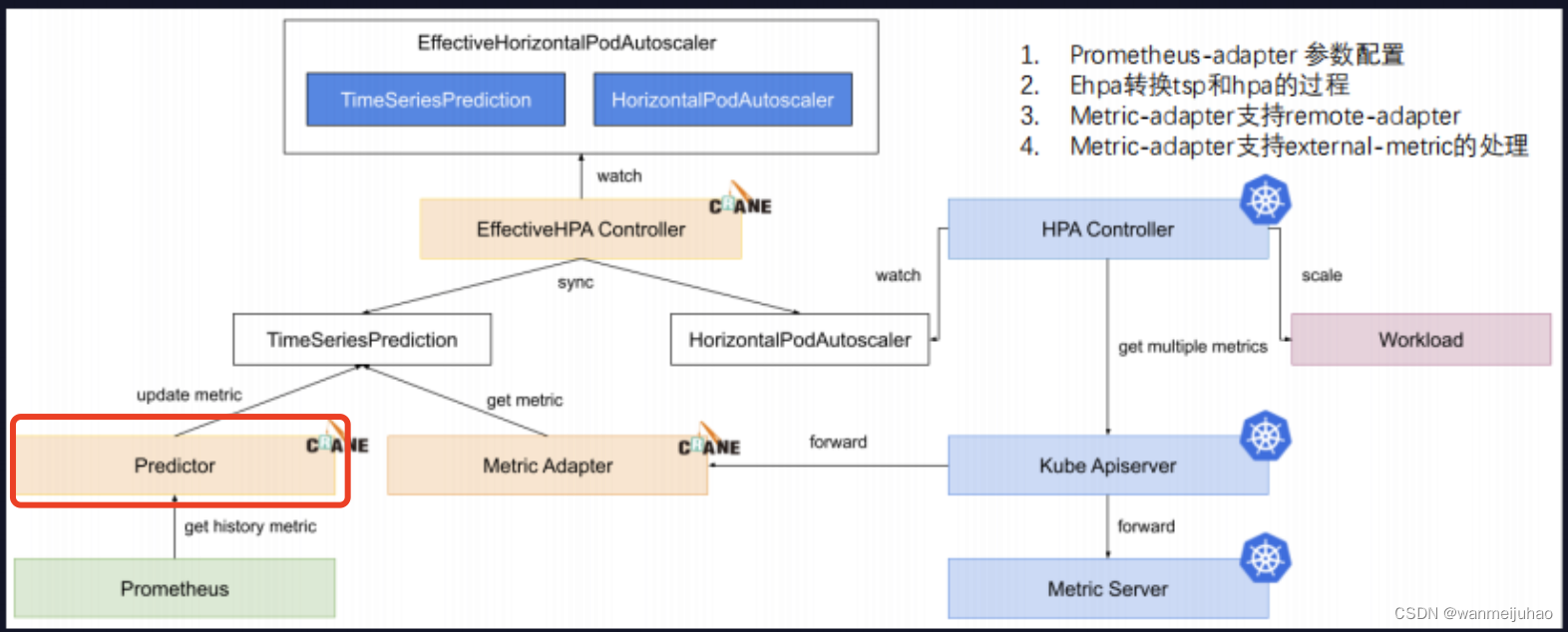
1. 用户创建 Effective HPA 的对象后会生成两个资源对象,其中一个是一个是 TimeSeries Prediction。
2. TimeSeries Prediction 是时间序列预测的 Controller 的对象:
(1). 创建后有一个组件叫 Predictor 开始(对应函数 initPredictorManager)从 Prometheus 中拿取应用历史数据。
(2). 并且通过预测算法得到未来持续预测,把预测结果更新到 TimeSeriesPredicton 中。
3. get history metice 对应到 initDataSources 函数中
4. 从 Prometheus 获取历史 metric 通过预测算法计算,将结果记录到 TimeSeriesPrediction。
5. HPA Contoller 调用 scale API 对目标应用扩/缩容,对应在 initMetricCollector 函数。
6. 在文件 crane/pkg/metrics 中,包含以下逻辑:
(1). HPAController 通过 metric client 从 KubeApiServer 读取 metric 数据
(2). KubeApiServer 将请求路由到 Crane 的 Metric-Adapter。
(3). HPAController 计算所有的 Metric 返回的结果得到最终的弹性副本推荐。
- 本地前端项目开发:
前端是使用的是vite + react + react-redux + typescript + less + axios + tdesign-react + echarts + react-i18等技术开发的
以下为主要的技术栈版本:

$ git clone https://github.com/gocrane/crane.git
$ cd pkg/web
$ yarn install
$ yarn dev:mock
- 本地调试proxy代理:
-
在vite.config.js文件中设置proxy代理
-
在crane/pkg/web/nginx/default.conf文件中也可以看到nginx反向代理的配置信息。如果想要配置https,可以在这里自定义进行扩展。可以使用web/Dockerfile文件直接docker build。
7.前端源码分析:
1. react是用hook写法,并非react Class写法。
2. 项目中自定义的hooks:crane/pkg/web/src/hooks。
3. crane/pkg/web/src/pages 下面是主要的业务逻辑代码。
4. crane/pkg/web/src/components 下面是组件代码,其中看了 BoardChart、PieChart、SeriesLineChart 等图表组件写的不错,通用性比较强。
7.1自定义hook,crane/pkg/web/src/hooks/useIsNeedSelectNamespace.ts:
import { grafanaApi } from 'services/grafanaApi';
export const useIsNeedSelectNamespace = ({ selectedDashboard }: { selectedDashboard?: any } = {}) => {
const dashboardDetail = grafanaApi.useFetchDashboardDetailQuery(
{ dashboardUid: selectedDashboard?.uid },
{ skip: !selectedDashboard?.uid },
);
return (dashboardDetail?.data?.dashboard?.templating?.list ?? []).find(
(item: { name: string }) => item.name === 'namespace' || item.name === 'Namespace',
);
};
注:
1. 还可以将一个请求封装为一个hook,让我对万物皆可hook,有了新的思路的理解。
2. 按以前想法是将这个封装为一个函数使用。
3. 最后一行代码 find 函数中,是否可以使用['namespace', 'Namespce'].includes(item.name)更为简洁呢?
8.前端相关项目的问题点:
8.1 目录结构,建议使用alias别名管理,否则层级混乱时,极不方便维护:


8.2 建议使用一些按需引入的类库,比如lodash可以换成lodash-es:


8.3 当echarts没有数据时,可以建议用div渲染一个空白块,而不是echarts去画图,相较性能来说,还是有点浪费:

8.4 文中typescript部分,使用了不少any数据类型:

8.5 在数据量比较大的页面,多个request同时请求,导致页面渲染比较慢,可以推荐一些兼容性比较好的数据压缩工具,之前做可视化大屏也遇到过类似问题。
8.6 建议有一个登陆页面,否则暴露出去,服务器的资源就可能会泄露信息。
8.7 在crane/pkg/web/src/router/index.ts文件中,可以使用路由自动加载方式动态引入:

8.8 建议安装一个stylelint进行格式化css代码,用自己开发的公共脚手架工具扫了一下,发现还是有不少错误:

8.9 接口返回值总是感觉怪怪的,最好可以加业务状态码
8.10 是否可以增加一些预警的机制,发送短信、机器人等
8.11 services中的API请求,个人感觉封装的不是太好,可能也是由于自身水平没能理解。
8.12 命名觉得统一一点好点:
8.13 crane/pkg/web/src/configs/host.ts 文件,最好是写在.env文件这些,可以做.gitignore忽略提交,不然合作中,冲突较为频繁。
export default {
mock: {
// 本地mock数据
API: '',
},
development: {
// 开发环境接口请求
API: '',
},
...
};
十一、总结:
-
为推进云原生用户在确保业务稳定性的基础上做到真正的极致降本,腾讯云率先在国内推出了第一个基于云原生技术的成本优化开源项目 Crane。
-
Crane 遵循 FinOps 标准,旨在为云原生用户提供云成本优化一站式解决方案,旨在助力企业和生态更良性发展和应用先进技术,达成降本增效。
-
Crane 依托于云原生技术,结合监控预测、调度增强、业务混部等多项硬核科技,将优化措施应用到了云成本优化的多个关键环节,从而辅助用户决策、简化运维效率、提升系统稳态、全面降本增效。
总体来说,在腾讯云大规模的实践案列下,我们也可以自己在 K8s 集群中安装 crane 来获取这些相关功能,用于帮助企业像管理 Workload 一样声明式管理 Node 节点,高效解决节点维护、资源规划等各种各样的运维问题。
在降本增效方面上,腾讯的云原生降本增效最佳实践是基于 FinOps 框架开展的。可以帮助更多企业通过云原生全面释放生产力,加速实现数字化和绿色化双转型。
号外:
通过对几次的CSDN的培训发现,对腾讯云有很大的改观,也是一个非常不错的选择,有些方面甚至做的更好。在后续的工作中,也会大量给公司推荐腾讯云的一些有效的方案,用于公司降本增效。
经过二期的培训,讲师胡老师也是会细心的给我们讲解,举出很多案列结合场景,深入易懂,答疑环节也是会认真的给我们解答问题,给出具体的实案,CSDN的老师们也是很耐心的回答我们的提问,比如网络超时,等的比较慢,也是会比较耐心的跟我们讲解。非常感谢腾讯云联合CSDN的活动,也希望国内云计算相关行业第一个开源的项目能够普及到更多公司,帮助企业降本增效。
另外,也推荐官方可以出一些其它云的对接教程,如阿里云、华为云、微软云,这样可以做更多、更好的推广。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐

 24
24 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)