Python应用随笔3——pyspark读写数据库
本文围绕Zeppelin中使用pyspark读写MySQL、PG(PostgreSQL)/GP(Greenplum)展开
·
零、前言
本文围绕Zeppelin中使用pyspark连接MySQL、PG(PostgreSQL)/GP(Greenplum)展开,简单教程,欢迎大佬评论补充。
PS: Zeppelin中需指定%pyspark对应解释器后再进行Python代码编写,见每个代码块首行
一、pyspark读取MySQL表
0. 此处使用zeppelin自带的连接方式,需在zeppelin服务器中安装好对应驱动,读取数据后转换为DataFrame格式展示;
1. MySQL连接信息配置(主机、端口、库名、用户名、密码)
%pyspark
# MySQL连接信息
my_host = 'XXXXXXX' # 主机
my_post = 'XXXX' # 端口
my_database = 'XXXXXX' # 数据库名
my_user = 'XXXXX' # 用户名
my_password = 'XXXXXXXXXX' # 密码
my_url = "jdbc:mysql://{host}:{post}/{database}?user={user}&password={password}".format(host=my_host, post=my_post, database=my_database, user=my_user, password=my_password)
2. 读取全表
%pyspark
# 城市信息表
# 读取全表
## .option(url, dbtable)参数说明:
## url为上述配置好的MySQL链接(此处为url=my_url)
## dbtable可以是表名,亦可以是sql查询语句(此处为表名,即读取全表)
dim_city = spark.read.format("jdbc").options(url=my_url, dbtable="dim_city").load().toPandas()
print(dim_city.info())
dim_city
输出:
3. 读取表的部分数据
- 方法1
%pyspark
# 简单sql语句读取表的部分信息
# 注意:dbtable参数输入的sql语句编写完后需要加括号并赋值表名,格式如“(···sql···) tbx”
dim_city_zj = spark.read.format("jdbc").options(url=my_url, dbtable="(select * from dim_city where province='浙江') tb").load().toPandas()
print(dim_city_zj.info())
dim_city_zj
输出: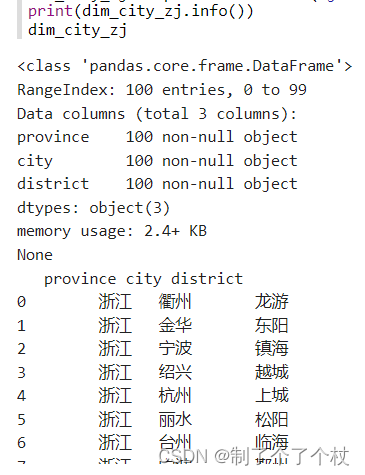
- 方法2
%pyspark
# 复杂一些的sql可使用多行文本形式进行编写,可进行表连接
sql_city = '''
(select tb1.city,
tb1.district,
tb2.city_level
from dim_city tb1
left join dim_city_info tb2
on tb1.city = tb2.city
where tb1.city = '杭州'
) tb
'''
dim_city_hz = spark.read.format("jdbc").options(url=my_url, dbtable=sql_city).load().toPandas()
print(dim_city_hz.info())
dim_city_hz
输出:
二、pyspark读取PostgreSQL/Greenplum表
0. 此处涉及psycopg2、pandas两个包,直接使用pd.read_sql()方法读表,读取数据后为DataFrame格式;
1. 工具包、PG/GP连接信息配置
%pyspark
import psycopg2
import pandas as pd
# PG/GP连接信息
host = "XXXXXXX" # 主机
port = "XXXX" # 端口
user = "XXXXX" # 用户名
password = "XXXXXXXXXX" # 密码
database = "XXXXXX" # 数据库名
conn = psycopg2.connect(database=database, host=host, port=port, user=user, password=password)
2. sql取数
%pyspark
# 此处正常写入sql语句即可,无需像上述连接MySQL方法中额外加括号起表名
sql_city = '''
select tb1.city,
tb1.district,
tb2.city_level
from public.dim_city tb1
left join public.dim_city_info tb2
on tb1.city = tb2.city
where tb1.city = '杭州'
'''
dim_city_hz = pd.read_sql(sql_city, conn)
print(dim_city_hz.info())
dim_city_hz
输出:
三、拓展:pyspark数据写入(导出)到MySQL
此处使用上述结果表dim_city_hz
%pyspark
from pyspark.sql.types import *
# MySQL连接信息(同上文)
my_host = 'XXXXXXX' # 主机
my_post = 'XXXX' # 端口
my_database = 'XXXXXX' # 数据库名
my_user = 'XXXXX' # 用户名
my_password = 'XXXXXXXXXX' # 密码
my_url = "jdbc:mysql://{host}:{post}/{database}?user={user}&password={password}".format(host=my_host, post=my_post, database=my_database, user=my_user, password=my_password)
# 参数:用户名、密码
auth_mysql = {'user': my_user, 'password': my_password}
# 输出后的表名
table_name = 'dim_city_hz'
# 表结构定义
schema = StructType([StructField("city", StringType(), True),
StructField("district", StringType(), True),
StructField("city_level", StringType(), True)
])
''' PS:
- 每个StructField()中传入3个参数值,分别为:表名、数据类型、是否可为空;
- 其他常用数据类型有:
data_type = {'整型': 'IntegerType()',
'浮点型': 'DoubleType()',
'日期': 'DateType()'}
'''
# 将pandas中的DF转换为spark中的DF
tmp_dim_city_hz = spark.createDataFrame(dim_city_hz, schema)
# 写入MySQL
print('数据正在写入MySQL……')
tmp_dim_city_hz.write.jdbc(my_url, table_name, mode='overwrite', properties=auth_mysql) # mode='append'可追加写入
print('写入MySQL完毕!')
输出:
MySQL中输出后的表: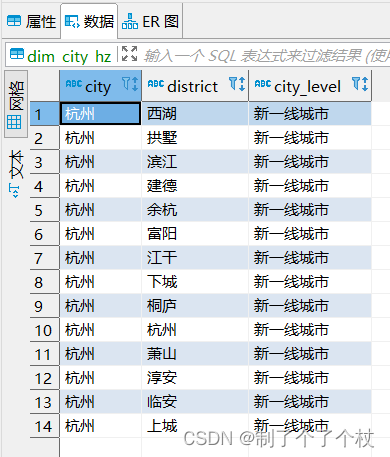
四、结语
pyspark连接数据库的方法众多,本文仅以个人常用方法为示例,希望能给大家提供参考和帮助~

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐



 2
2 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)