
论文阅读:Preference-based evolutionary algorithm for airport surface operations
该文章引入了一个EMO框架,并设计了新的拥挤距离,有效地控制了兴趣区间(RoI)的范围,直接影响算法的性能。该EMO的主要思想是,使用区间偏好信息来定义兴趣区间(RoI)的范围会比使用用户自定义参数的算法得到更好的解决方案。除此之外,该文章还提出了一种新的过滤方法来寻找具有代表性的均匀分布解子集,进一步提高了决策者选择具有成本效益的解的能力。
这篇文章中使用的进化多目标算法与自己的研究方向相关,仅对算法部分进行阅读梳理总结。
介绍
本文引入了一个多目标进化优化(EMO)框架来解决问题,本研究的新颖性可以总结如下:
- 引入了一个EMO框架,可以处理近似的偏好。标度函数及其相应的参数指定了兴趣区间(RoI)。针对EMO框架的替换过程,专门设计了新的拥挤距离,有效地控制了兴趣区间(RoI)的范围,直接影响算法的性能。其主要思想是,使用区间偏好信息来定义兴趣区间(RoI)的范围会比使用用户自定义参数的算法得到更好的解决方案。
- 提出了一种新的过滤方法来寻找具有代表性的均匀分布解子集,进一步提高了决策者选择具有成本效益的解的能力。
- 本文提出的EMO算法和滤波过程应用于地面运动和跑道调度综合问题,并附加了与排放对应的目标。
本次求解的问题可以分为地面运动问题(Ground movement problem)和跑道调度问题(Runway scheduling problem)。地面运动问题的优化目标为总滑行时间 t t a x i t^{taxi} ttaxi,滑行期间总油耗 f t a x i f^{taxi} ftaxi,滑行期间总排放量 ε t a x i ε^{taxi} εtaxi;跑道调度问题的优化目标为总跑道调度延迟时间 t r w y t^{rwy} trwy,跑道调度总油耗 f r w y f^{rwy} frwy,跑道调度总排放量 ε r w y ε^{rwy} εrwy。
将地面运动问题和跑道调度问题整合为一个多目标优化问题之后,考虑的优化目标为:
- 总时间 g 1 = t t a x i + t r w y g_1=t^{taxi} + t^{rwy} g1=ttaxi+trwy;
- 总油耗 g 2 = f t a x i + f r w y g_2=f^{taxi}+f^{rwy} g2=ftaxi+frwy;
- 总排放量 g 3 = ε t a x i + ε r w y g_3=ε^{taxi}+ε^{rwy} g3=εtaxi+εrwy。
在该多目标优化问题中,决策变量为
- 离港飞机的起飞时间 x i , i ∈ D x_i,i∈D xi,i∈D;
- 每架航班的速度轮廓
y
i
,
i
∈
H
y_i,i∈H
yi,i∈H。
其中D为离港航班的集合,H为所有航班的集合,所以决策向量可表示为 { x 1 , x 2 , … , x ∣ D ∣ , y 1 , y 2 , … , y ∣ H ∣ } \{x_1,x_2,…,x_{|D|} ,y_1,y_2,…,y_{|H|} \} {x1,x2,…,x∣D∣,y1,y2,…,y∣H∣}。
针对机场现实问题,论文还考虑了现实中的经济效益。由于某些单位成本往往是难以确定的,只有近似可用。本文使用一个标量化函数
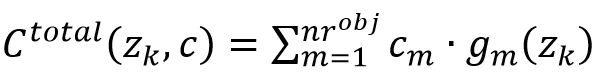
来评估搜索过程中发现的解决方案 z k z_k zk 的总货币成本, n r o b j {nr}^{obj} nrobj是解决方案的目标数量, c m > 0 c_m>0 cm>0,是每个目标对于货币成本的权重,可以被重写。
EMO框架

- 在整个EMO框架中,初始种群的解决方案的决策向量随机获取,并计算种群中每个解决方案的目标值 g 1 g_1 g1, g 2 g_2 g2, g 3 g_3 g3。
- 在种群中选择目标函数值较好的解决方案进行遗传操作,以给定的概率,对两个父代解进行两点交叉。
- 根据变异概率对种群中的每个解的决策向量进行变异操作,并重新计算解决方案的目标值 g 1 g_1 g1, g 2 g_2 g2, g 3 g_3 g3。
- 使用替换程序选择下一代的解决方案替换当前种群。
- 重复执行选择、交叉、变异、替换程序,直到满足指定数量的迭代次数。
- 最终使用过滤程序选择出解决方案的一个有代表性的子集供决策者进行选择。
P-EMOA的替换程序
在每一代中,替换程序进行非支配排序以识别非支配前沿。在每一个前沿中,根据目标空间中解的Pareto前沿的优选区域选择生存解。优选区域定义如下:
- 前沿中最优的解决方案定义为中心点 z k z_k zk;
- 被称作特征领域的边界解决方案 z a B z_a^B zaB以至于为每个目标 g m g_m gm定义如图2所示的区间 [ v m m i n , v m m a x ] [v_m^{min},v_m^{max}] [vmmin,vmmax];
- 中心点和边界解指定了兴趣区间。

决策者可以通过涂刷技术交互地选择中心点和边界解。标量化函数 C t o t a l C^{total} Ctotal可以用来寻找中心点和边界解,决策者需要提供 c ˉ m l o w e r \bar{c} _m^{lower} cˉmlower, c ˉ m \bar{c} _m cˉm, c ˉ m u p p e r \bar{c} _m^{upper} cˉmupper。中心点 z k z_k zk相对于单位成本向量 c ˉ \bar{c} cˉ具有最小标量函数值: z C = arg min z k ( C t o t a l ( z k , c ˉ ) ) z^C=\argmin_{z_k}{(C^{total}(z_k, \bar{c}))} zC=argminzk(Ctotal(zk,cˉ))。
对于边界解,定义边界单位成本向量 c ˉ B \bar{c} ^{B} cˉB, c ˉ B \bar{c} ^{B} cˉB中使用边界单位成本值,即 c m = c ˉ m l o w e r c_m=\bar{c} _m^{lower} cm=cˉmlower或者 c m = c ˉ m u p p e r c_m=\bar{c} _m^{upper} cm=cˉmupper,这导致上界、下界的组合包含了 n r B = 2 n r o b j {nr}^B=2^{{nr}^{obj}} nrB=2nrobj个边界单位成本向量 c ˉ B \bar{c} ^{B} cˉB。第 a a a个 c ˉ B \bar{c} ^{B} cˉB对应一个使用 c ˉ B \bar{c} ^{B} cˉB得到最小标量函数的解决方案 z k z_k zk的特征邻居 z a B = arg min z k ( C t o t a l ( z k , c ˉ a B ) ) z_a^B=\argmin_{z_k}{(C^{total}(z_k, \bar{c}_a^B))} zaB=argminzk(Ctotal(zk,cˉaB))。
所有的 z B z^B zB定义了兴趣区间,这个区间包含了对于 c ˉ m l o w e r \bar{c} _m^{lower} cˉmlower 和 c ˉ m u p p e r \bar{c} _m^{upper} cˉmupper 之间的任何单元成本向量来说都有最小 C t o t a l ( z k , c ˉ m ) C^{total}(z_k, \bar{c}_m) Ctotal(zk,cˉm) 的解决方案。在每一代中,决策者可以更改有标量化函数得到兴趣区间。
新设计的拥挤距离 c d k cd_k cdk

- 如果解决方案 z k z_k zk是中心点,则 c d k = ∞ cd_k=∞ cdk=∞以确保它总是被选择进入下一代;否则需要根据 z k z_k zk和 z C z^C zC的关系决定。
如果 v m m i n ≤ g m ( z k ) ≤ v m m a x v_m^{min}≤g_m (z_k)≤v_m^{max} vmmin≤gm(zk)≤vmmax,则 z k z_k zk支配 z C z^C zC,记做 z k S z C z_k Sz^C zkSzC。所有支配 z C z^C zC的解 z k z_k zk形成了支配邻域。拒绝域 [ v m m i n , v m m a x ] [v_m^{min},v_m^{max}] [vmmin,vmmax]由特征领域决定: v m m i n = min g m ( z a B ) v_m^{min}=\min{g_m(z_a^B)} vmmin=mingm(zaB), v m m a x = max g m ( z a B ) v_m^{max}=\max{g_m (z_a^B )} vmmax=maxgm(zaB)。
- 属于支配邻域的解
z
k
z_k
zk的
c
d
k
{cd}_k
cdk为
c
d
k
=
M
+
d
k
c
d
{cd}_k=M+d_k^{cd}
cdk=M+dkcd,
d
k
c
d
d_k^{cd}
dkcd是解
z
k
z_k
zk到领域解集的距离
d
k
c
d
d_k^{cd}
dkcd:

当 M M M设为较大的正数时, c d k {cd}_k cdk能够确保替换程序按照预期执行。 - 对于特征邻域之外的解决方案, c d k {cd}_k cdk 与 C t o t a l ( z k , c ˉ ) C^{total}(z_k, \bar{c}) Ctotal(zk,cˉ) 成反比。最终,兴趣区间内被选择的解决方案的 c d k {cd}_k cdk 与 C t o t a l ( z k , c ˉ ) C^{total}(z_k, \bar{c}) Ctotal(zk,cˉ) 都要小。
最终,按照 c d k {cd}_k cdk降序选择解决方案去填充种群。然而,可能有大量的解决方案,而且它们的分布不均匀,使决策局难以作出决定,特别是在目标数目较多的情况下。因此,再次使用填充数据库的相同过滤过程,从 R R R 中获得具有代表性的均匀分布解子集。
Pareto最优解的筛选程序
解决方案的代表性子集能够在选择阶段对决策者有所帮助,并且减少存储在数据库中的解决方案。该过滤程序的主要步骤为:
- 使用邻域概念: R → R ∗ R→R^* R→R∗;
- 使用ξ-启发式方法: R ∗ → R ∗ ∗ R^*→R^{**} R∗→R∗∗。
首先,使用区域概念对R进行筛选得到初始集合 R ∗ R^* R∗。然而,第一步筛选后的解之间的距离可能仍然是不均匀的。因此,在第二步中,利用均匀度测量将 R ∗ R^* R∗进一步细化为 R ∗ → R ∗ ∗ R^*→R^{**} R∗→R∗∗。
在第一步中,只有邻域内没有其他解决方案的解
z
k
z_k
zk被接受。解
z
k
z_k
zk的邻域被定义为每个目标上距离为
τ
\textbf{τ}
τ的区域,在该区域内没有支配
z
k
z_k
zk或被解
z
k
z_k
zk支配的解。第一步的步骤如下:
对于R中的每一个解决方案
z
k
z_k
zk:
- 如果 R ∗ R^* R∗为空, z k z_k zk被加入到 R ∗ R^* R∗中;否则,进行下一步;
- z k z_k zk的目标值 g m g_m gm按照 g m ˉ = ( g m − g m m i n ) ( g m m a x − g m m i n ) \bar{g_m} =\frac{(g_m-g_m^{min})}{(g_m^{max}-g_m^{min})} gmˉ=(gmmax−gmmin)(gm−gmmin)进行归一化, g m m a x g_m^{max} gmmax, g m m i n g_m^{min} gmmin分别为 R R R中第 m m m个目标最大值和最小值;
- z k z_k zk到 R ∗ R^* R∗中每一个解决方案 z l z_l zl的线性距离 d k l r e c t = ∑ m = 1 n r o b j ∣ g m ˉ ( z k ) − g m ˉ ( z l ) ∣ d_{kl}^{rect}=\sum_{m=1}^{{nr}^{obj}}{ | \bar{g_m}(z_k) - \bar{g_m}(z_l)|} dklrect=m=1∑nrobj∣gmˉ(zk)−gmˉ(zl)∣
- 距离 z k z_k zk的线性距离最小的解决方案 z l ∗ z_l^* zl∗: l ∗ = arg min l ( d k l r e c t ) l^*=\argmin_l{(d_{kl}^{rect})} l∗=largmin(dklrect)
- z k z_k zk和 z l z_l zl之间的目标值最大差别 δ = max m = 1 , 2 , . . . , n r o b j ∣ g m ˉ ( z k ) − g m ˉ ( z l ∗ ) ∣ δ=\displaystyle\max_{m=1,2,...,{nr}^{obj}}{| \bar{g_m}(z_k) - \bar{g_m}(z_l^*)}| δ=m=1,2,...,nrobjmax∣gmˉ(zk)−gmˉ(zl∗)∣
- 如果 δ≥τ \textbf{δ≥τ} δ≥τ,接受 z k z_k zk并移入到 R ∗ R^* R∗;否则拒绝 z k z_k zk。
过滤过程的第一步依赖于 τ τ τ的值,有效地控制了存档种群的大小。有两种策略设置 τ τ τ:
- 如果固定偏好的解决方案的数量 N R N^R NR,则 τ = 1 ( N R n r o b j − 1 + o ) τ=\frac{1}{(\sqrt[{nr}^{obj}-1]{N^R}+o)} τ=(nrobj−1NR+o)1初始时 ο = 0 ο=0 ο=0。如果使用初始的τ获得的解少于 N R N^R NR,可以逐步地增加 ο ο ο以至于选够 N R N^R NR个解;
- 如果给出了两个解决方案在 m m m个目标上最小差异 i n c m inc_m incm,则 τ = i n c m ‾ τ=\overline{inc_m} τ=incm, i n c m ‾ \overline{inc_m} incm和 g m ‾ \boldsymbol{\overline{g_m}} gm的归一化方式相似。
第一步中的筛选提供了一个良好的初始集合 R ∗ R^* R∗。然而,在某些方面, R ∗ R^* R∗中的解决方案可能比 τ τ τ更接近,因为只考虑了最大距离。此外,由于 δ δ δ不需要严格等于 τ τ τ,实际上它可以是任何比 τ τ τ更大或等于 τ τ τ的值,因此解之间有很大的距离是可能的。因此,在第二步中,需要基于均匀度度量的 ξ ξ ξ-启发式方法对 R ∗ R^* R∗进行再次筛选。
均匀度的定义如下:对于每个
R
∗
R^*
R∗中的解决方案
z
k
z_k
zk,构造两个球体(两个目标时为圆形,或超过3个目标时为超球体),如图4所示。
第一个球体是在
z
k
z_k
zk和
R
∗
R^*
R∗中任何其他解决方案之间构建的最小球体。这个球体的直径表示为
d
k
l
d_k^l
dkl。
第二个球体是可以在
z
k
z_k
zk和
R
∗
R^*
R∗中任何其他解决方案之间构建的内部不包含其他解决方案的最大球体。这个球体的直径表示为
d
k
u
d_k^u
dku。
直径用相应点之间的欧氏距离来计算。
R ∗ R^* R∗的均匀度 ξ = σ d d ^ ξ=\frac{σ_d}{\hat{d}} ξ=d^σd ,其中 σ d σ_d σd, d ^ \hat{d} d^分别为 R ∗ R^* R∗中所有解决方案的所有直径 { d 1 L , d 2 L , … , d k L } ⋃ { d 1 U , d 2 U , … , d k U } \{d_1^L,d_2^L,…,d_k^L\}⋃\{d_1^U,d_2^U,…,d_k^U\} {d1L,d2L,…,dkL}⋃{d1U,d2U,…,dkU}的标准差和均值。当 ξ = 0 ξ=0 ξ=0时,解决方案服从均匀分布,即所有直径相等。
ξ ξ ξ-启发式方法使用 R R R中较好的解决方案 z l z_l zl替换 R ∗ R^* R∗中的解决方案 z k z_k zk来重新定义 R ∗ R^* R∗。 ξ ξ ξ-启发式方法基于差异的绝对值 ∣ d i L − d ^ ∣ |d_i^L-\hat{d}| ∣diL−d^∣和 ∣ d i U − d ^ ∣ |d_i^U-\hat{d}| ∣diU−d^∣来替换解决方案。 ∣ d i L − d ^ ∣ |d_i^L-\hat{d}| ∣diL−d^∣和 ∣ d i U − d ^ ∣ |d_i^U-\hat{d}| ∣diU−d^∣越小,代表着 d i L d_i^L diL和 d i U d_i^U diU越接近近似 d ^ \hat{d} d^的理想值。对于R中的每一个解决方案 z k z_k zk, ξ ξ ξ-启发式方法步骤如下:
- 由欧氏距离得出 R ∗ R^* R∗中距离 z k z_k zk最近的解决方案 z l z_l zl;
- z k z_k zk暂时加入 R ∗ R^* R∗, z l z_l zl暂时从 R ∗ R^* R∗中移除;
- 计算 z k z_k zk和相关点之间的直径 d k L d_k^L dkL, d k U d_k^U dkU;
- 如果 ∣ d k L − d ∣ < ∣ d l L − d ∣ ∧ ∣ d k U − d ∣ < ∣ d i U − d ∣ |d_k^L-d |<|d_l^L-d |∧|d_k^U-d |<|d_i^U-d | ∣dkL−d∣<∣dlL−d∣∧∣dkU−d∣<∣diU−d∣,则 z k z_k zk被接受加入 R ∗ R^* R∗, z l z_l zl被移出;否则 z k z_k zk被拒绝, z l z_l zl重新加入 R ∗ R^* R∗;
- R R R中所有的解决方案被测试之后, R ∗ ∗ = R ∗ R^{**}=R^* R∗∗=R∗。
实验设置
EMO框架使用Python的Inspyred包实现。EMO框架的终止条件为50代,种群中个体数量为50。两点交叉的交叉概率为1;随机更改一个基因编码的变异操作的概率为0.1。对比算法:没有偏好信息的NSGAⅡ、MOEA/D、有偏好信息的NSGAⅢ。
结论
本文针对综合优化问题:
- 提出了一种带有偏好信息和筛选过程的多目标进化优化框架。这个问题结合了机场地面移动和跑道调度问题;
- 提出的方法在主要国际枢纽机场的数据上进行了测试;
- 提出的进化框架解决了两个具有挑战性的任务:
1)将近似或不确定的偏好信息表示为每个目标单位的经济价值的区间;
2)在Pareto前沿上找到均匀分布的解。
为了应对第一个挑战,在进化算法的替换过程中,新设计的拥挤距离考虑了滑行延误和燃油消耗的单位成本范围,以控制RoI的范围。在进化过程中对兴趣区域范围的有效控制成功地提高了算法的收敛性。这种改进具有实际意义,因为可以在总时间、燃料消耗和排放量上找到更好的解决方案。
本文提出的筛选过程解决了第二个挑战。筛选过程被用来选择速度轮廓的一个均匀分布的子集,和从兴趣区间中选择解决方案呈现给决策者。实验强调了均匀分布的解决方案对于节省成本的重要性。
计算实验表明,机场可以从采用所提出的决策支持方法中受益。
为了进一步研究,本文提出的后验筛选方法可以嵌入EMO中,在进化过程中选择均匀分布的解。另外,将不确定性系统地纳入偏好信息的想法也值得重视。例如,不确定性可以用模糊值表示。最后,在处理像机场运营这样的现实问题时,不仅要找到最优的解决方案,而且还要找到具有鲁棒性的解决方案(鲁棒的针对出租车时间、出发时间和到达时间的偏差)。为了达到这个目标,稳健优可以包含在搜索算法中。
个人理解
简单阅读完该论文之后,对于文中提到了一些定义、公式并没有完全理解,只是对论文算法的思想有了大致的了解。就算法框架而言,本文所提出的P-EMOA类似于NSGAⅡ算法,对于遗传算子没有特殊变化,比较重要的地方是对NSGAⅡ算法中的拥挤距离进行了重新设计,即在下一代的解决方案的挑选方式上进行了改变,而Pareto前沿的筛选程序是在进化算法框架遗传操作迭代过程之外,是对最终结果的进一步筛选出均匀分布的解决方案以供决策者选择,减轻决策者的选择负担,对于均匀分布的解能够有助于节省成本这一点没太理解。
论文原文:
Preference-based evolutionary algorithm for airport surface operations

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐



 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)