Python 在线电子零售公司销售数据(Online Retail | Kaggle)关联规则分析(Apriori算法)
本文使用python语言完成了在线电子零售公司的跨国交易数据集的数据分析与可视化、根据关联规则原理设计实现了基于Apriori算法的关联规则挖掘程序并将程序封装、使用封装好的关联规则挖掘程序对数据集进行关联规则的挖掘,并对挖掘结果进行分析。......
引言:
本文使用python语言完成了在线电子零售公司的跨国交易数据集的数据分析与可视化、根据关联规则原理设计实现了基于Apriori算法的关联规则挖掘程序并将程序封装、使用封装好的关联规则挖掘程序对数据集进行关联规则的挖掘,并对挖掘结果进行分析。
数据集地址:Online Retail | Kaggle https://www.kaggle.com/puneetbhaya/online-retail
https://www.kaggle.com/puneetbhaya/online-retail
目录
4.1. 关联规则程序执行原理,数据为演示数据,并非 Online Retail 数据集中数据。
4.2 编写数据集格式修改函数,生成适合 Apriori 算法程序执行的数据格式。
4.3 编写生成关联规则类(即将关联规则生成程序封装在类中,方便调用)
一、算法原理
1.1 关联规则
关联规则是以规则的方式呈现项目之间的相关性,目的是在一个数据集中找到各项之间的关联关系(这种关系往往不会在数据中直接体现出来)。并且将发现的联系用关联规则或频繁项集的形式表现。
相关概念解释如下:
①关联规则的支持度(相对支持度):
项集A、B同时发生的概率称为关联规则的支持度(相对支持度)。
Support ( A = > B ) = P ( A∪B )
②关联规则的置信度:
在项集A发生的条件下,则项集B发生的概率为关联规则的置信度。
Confidence(A=>B)=P(B|A)
③关联规则的提升度:
指A项和B项一同出现的频率,但同时要考虑这两项各自出现的频率。
{A→B}的提升度={A→B}的置信度/P(B)=P(B|A)/P(B)= P(A∩B)/(P(A)*P(B))。
④最小支持度:衡量支持度的一个阈值,表示项目集在统计意义上的最低重要性。
⑤最小置信度:衡量置信度的一个阈值,表示关联规则的最低可靠性。
⑥强规则:同时满足最小支持度阈值和最小置信度阈值的规则。
⑦项集:项的集合。包含k个项的集合称为k项集,如集合 {牛奶,麦片,糖} 是一个三项集。项集出现的频率是所有包含项集的事务计数,又称为绝对支持度或支持度计数。如果项集L的相对支持度满足预定义的最小支持度阈值,则L是频繁项集。如果有K项,记为Lk。
1.2 Apriori原则生成频繁项集
Apriori算法是常用于挖掘出数据关联规则的算法,能够发现事物数据库中频繁出现的数据集,这些联系构成的规则可帮助用户找出某些行为特征,以便进行企业决策。例如,某食品商店希望发现顾客的购买行为,通过购物篮分析得到大部分顾客会在一次购物中同时购买面包和牛奶,那么该商店便可以通过降价促销面包的同时提高面包和牛奶的销量。
(1)找出全部频繁项集(支持度大于等于给定的支持度阈值)
①连接
连接步的目的是找到K项集。对于给定的最小支持度阈值,分别对1项候选项集C1,剔除支持度小于阈值的项集得到1项频繁项集L1;下一步由L1自身连接产生2项候选项集C2,剔除支持度小于阈值的项集得到2项频繁项集L2;再下一步由L2和L1连接产生3项候选集项集C3;剔除支持度小于阈值的项集得到3项频繁项集L3;这样循环下去,直至由L(k-1)和L1连接产生k项候选项集Ck,剔除小于阈值的项集得到最大频繁项集Lk。
②剪枝
剪枝紧接着连接步骤,在产生候选项集Ck的过程中起到了减小搜索空间的目的。根据Apriori的性质,频繁项集的所有非空子集也一定是频繁项集,所以不满足该性质的项集将不会存在于候选项集C中,该过程就是剪枝。
(2)由频繁项集生成强关联规则
由(1)可知,支持度未超过支持度阈值的项集已被剔除,如果剩下的这些项集又满足预定的置信度阈值,那么就可挖掘出强关联规则,并计算规则的提升度。
Apriori算法的详细过程以及示意图将在下文操作部分给出。
二、数据预处理
2.1 数据描述
数据集来自一个在英国注册的在线电子零售公司,在2010年12月1日到2011年12月9日期间发生的网络交易数据,共有541909条记录、8个字段。
字段含义如下:
- InvoiceNo:发票编号。为每笔订单唯一分配的6位整数。若以字母“C”开头,则表示该订单被取消。
- StockCode:产品代码。为每个产品唯一分配的编码。
- Description:产品描述。
- Quantity:数量。每笔订单中各产品分别的数量。
- InvoiceDate:发票日期和时间。每笔订单发生的日期和时间。
- UnitPrice:单价。单位产品价格,单位为英镑。
- CustomerID:客户编号。为每个客户唯一分配的5位整数。
- Country:国家。客户所在国家/地区的名称
2.2 导入需要的第三方库、读取数据集、查看数据集基本信息
import matplotlib.pyplot as plt
import pandas as pd
import missingno as msno
import seaborn as sns
from matplotlib import cm
plt.rcParams['font.sans-serif'] = ['SimHei'] # 显示中文标签
plt.rcParams['axes.unicode_minus'] = False
# 读取数据
dataset = pd.read_excel("Online Retail.xlsx")
#查看数据集维度
print(dataset.shape) # (541909, 8)
#查看数据集中各列数据格式
print(dataset.dtypes)
#查看各列数据分布情况
print(dataset.info())
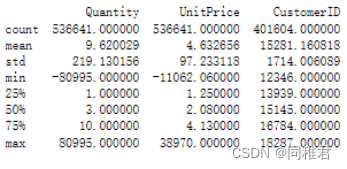
print(dataset.describe())运行结果如下:
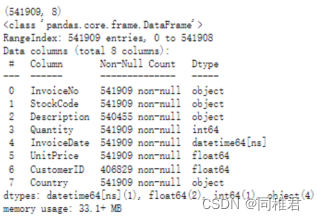
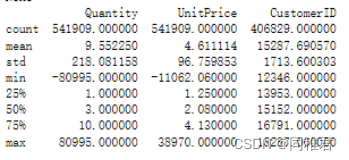
可以看出数据总共有541909条,其中“Description”、“CustomerID”两个字段存在数据缺失情况。“Quantity”、“UnitPrice”字段最小值为负数,产品销售数量存在负数可能是存在退货情况,但是这种情况对产生关联规则存在反向作用(削弱关联强度),产品销售单价存在负数说明该字段存在异常数据。
2.3 数据去重
删除完全相同的记录。
dataset.drop_duplicates(inplace=True)
print("去重后数据基本信息:")
#查看数据集维度
print(dataset.shape) # (536641, 8)
#查看数据集中各列数据格式
print(dataset.dtypes)
#查看各列数据分布情况
print(dataset.info())
print(dataset.describe())运行结果如下:
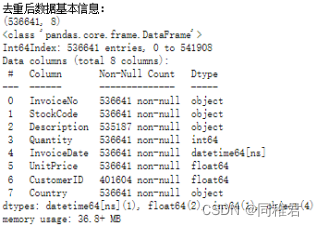
可以看到,数据集中存在5268条完全重复的记录,删除重复记录后,数据集还剩536641条记录。
2.4 数据异常值处理
去除“Quantity”<= 0 或“UnitPrice”< 0 的不符合实际情况的异常记录。
print("数据异常值处理:")
dataset = dataset.loc[(dataset["Quantity"]>0) & (dataset["UnitPrice"]>=0)]
print(dataset.describe())运行结果如下:
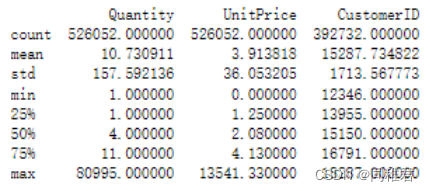
可以看到,去除异常值后还剩下526052条记录。
2.5 数据缺失值处理
查看数据缺失情况
msno.matrix(dataset, labels=True, fontsize=9) # 矩阵图
plt.show()
print(dataset.info())运行结果如下:
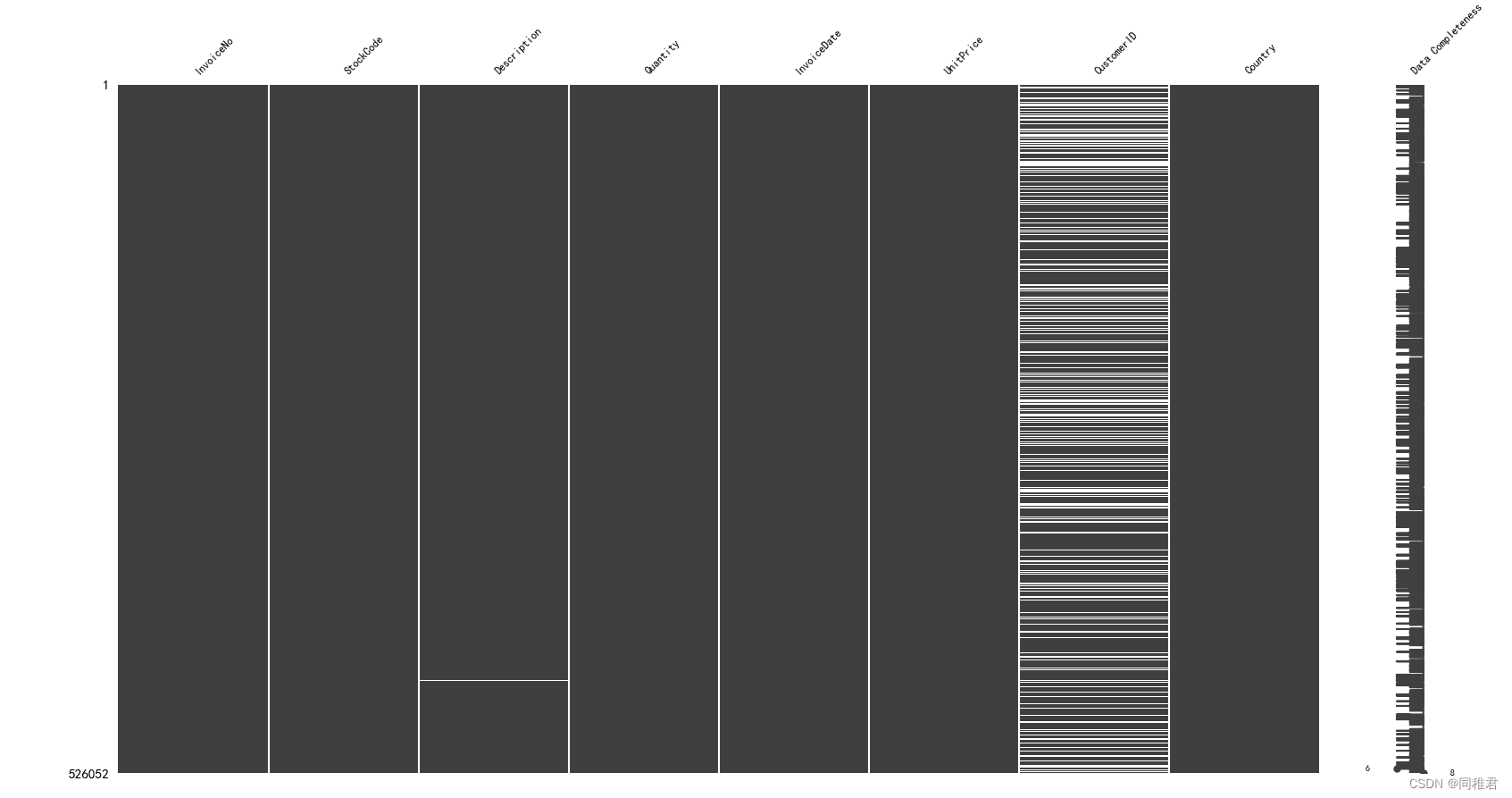
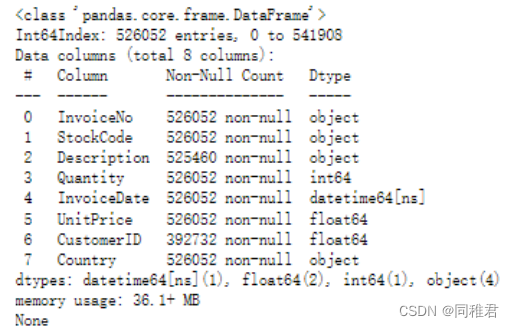
可以看到“CustomerID”字段数据存在明显大量的缺失,“Description”字段数据存在少量缺失数据。考虑到“CustomerID”字段数据缺失量极大,且客户编号难以估计,遂删除在“CustomerID”字段存在缺失值的记录。“Description”为产品信息描述,其缺失量较少,同一种产品的描述相同,因此可以很容易地填补“Description”字段的空缺值。由于“Description”字段对构建关联规则作用不大,因此之后可以单独提取出“StockCode”和“Description”字段,并对其进行去重,生成{“StockCode” : “Description”}字典,用于根据产品编号查找对应的产品描述。
删除在“CustomerID”字段存在缺失值的记录
dataset["InvoiceNo"] = dataset["InvoiceNo"].astype("int")
print(dataset.info())运行结果如下:
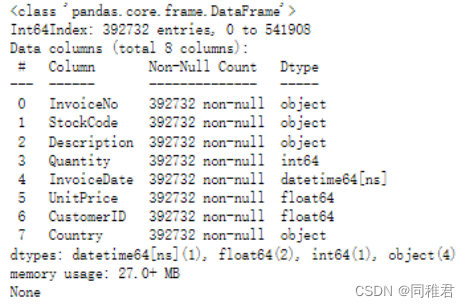
可以看到,去除缺失值后,数据集还剩下392732条记录。
三、统计不同国家销售量
# 对数据集按照"Country"字段值进行分组
groupByCountry = dataset.groupby("Country")
# 对各组中数据的"Quantity"字段进行求和
country_quantity_list = list(dict(groupByCountry["Quantity"].sum()).items())
# 对数据集按照产品销售总量进行排序
country_quantity_list.sort(key=lambda x: x[1])
print("country_quantity_list:")
print(country_quantity_list)统计结果如下:

对统计结果可视化
# country_quantity_list.pop() #在可视化时去除/保留销量第一的国家销量数据
norm = plt.Normalize(0, country_quantity_list[-1][1])
norm_values = norm([i[1] for i in country_quantity_list])
map_vir = cm.get_cmap(name='jet')
colors = map_vir(norm_values)
plt.barh([i[0] for i in country_quantity_list], [i[1] for i in country_quantity_list], height = 0.4,color=colors)
plt.tick_params(labelsize=8) #设置坐标字体大小
sm = cm.ScalarMappable(cmap=map_vir, norm=norm) # norm设置最大最小值
sm.set_array([])
plt.colorbar(sm)
# 给条形图添加数据标注
for index, y_value in enumerate([i[1] for i in country_quantity_list]):
plt.text(y_value+10, index-0.2, "%s" %y_value)
plt.ylabel("Country", fontdict={'size':18})
plt.title("不同国家产品总销售量")
plt.show() 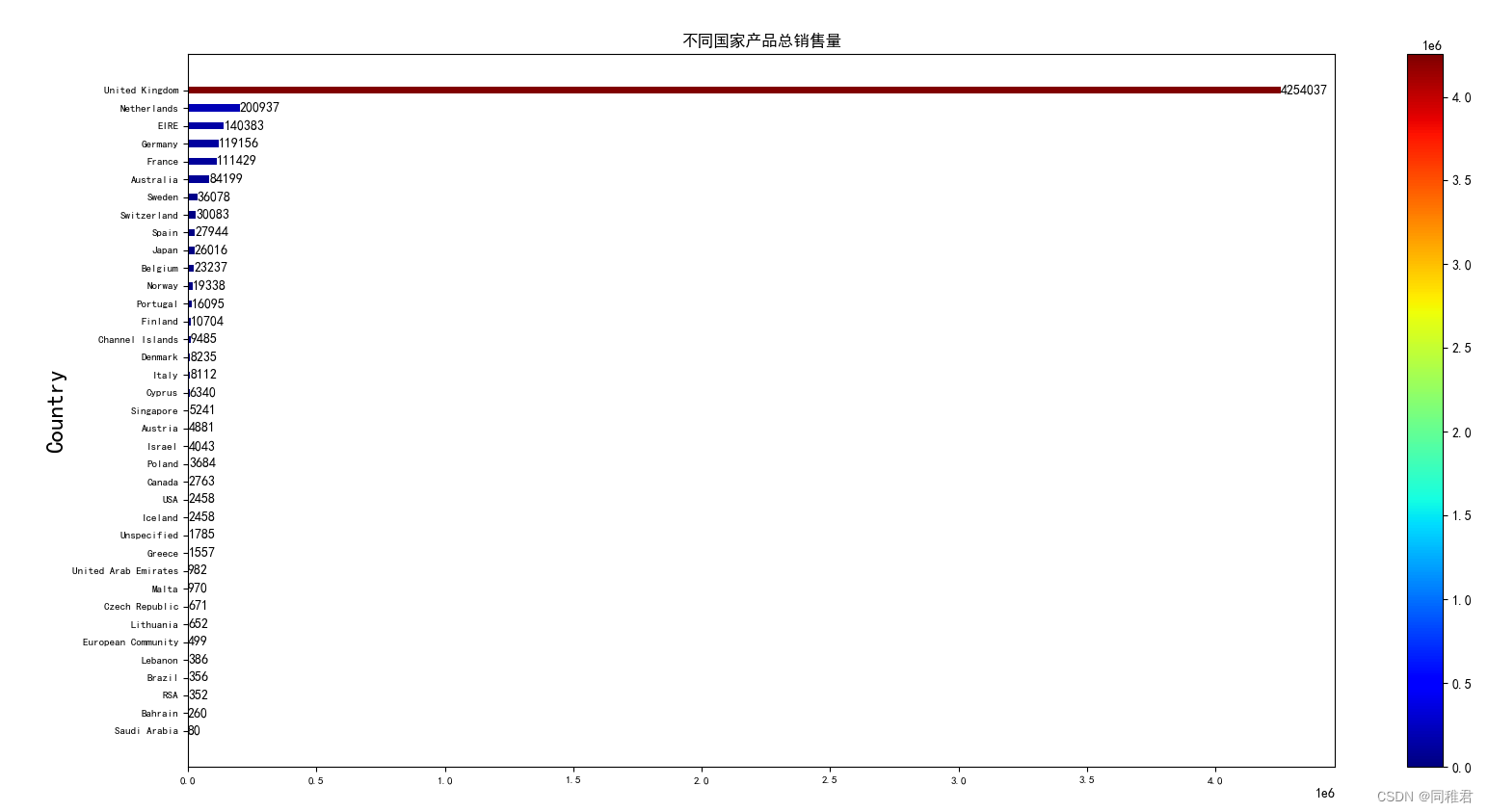
可以看到该商店产品在United Kingdom中销量最高,远远超过了在剩余国家中销量的总和。销量前五的国家依次是United Kingdom、Netherlands、EIRE、Germany、France。
为了更直观看清产品在除United Kingdom之外的国家中的销量情况,遂再绘制没有United Kingdom的产品销量条形图。
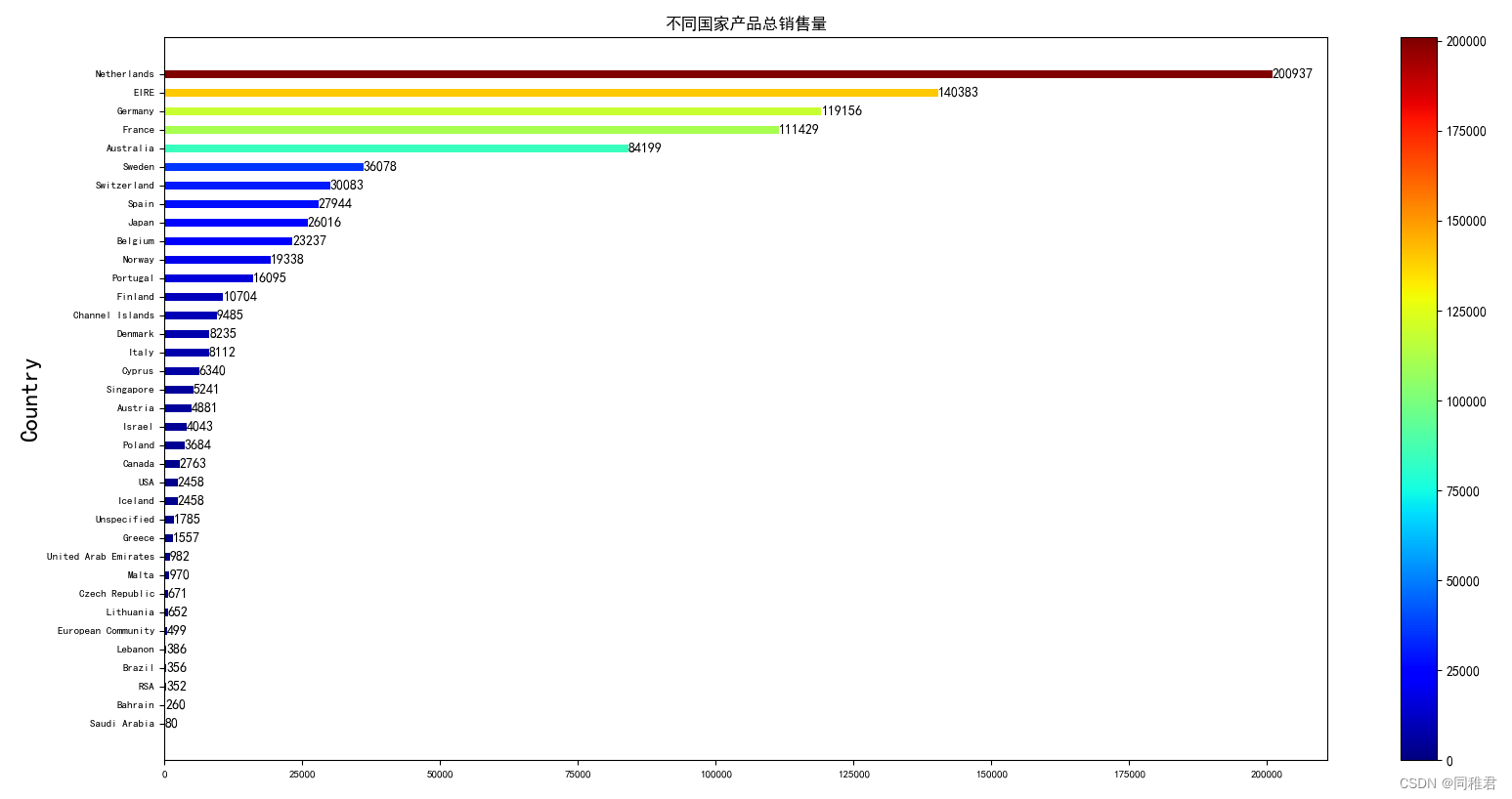
可以看到该商店的产品的出口国主要为英国周边的国家(如荷兰、爱尔兰)以及欧洲的部分人口大国(如德国、法国)。
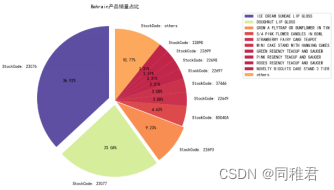
分别统计United Kingdom与Bahrain国家中各产品的销量情况,并绘制销量排前十的产品的饼状图(其中others表示第11名到最后一名的产品的销量总和),对产品销售量排名的统计可以在一定程度上反映一些产品之间的关联,如若销售量排名第一的产品的销售量与排名第二的产品的销售量接近,则这两种产品肯能存在较强的关联。
# 获取产品代码及其对应的描述
Sto_Des = dataset.loc[:,["StockCode","Description"]]
Sto_Des.dropna(inplace=True) # 先除去缺失产品描述的行
Sto_Des.drop_duplicates(inplace=True) # 去重,留下产品唯一的 StockCode与Description
# print("Sto_Des shape:",Sto_Des.shape)
# print("Sto_Des:", Sto_Des)
# 分别查看销量前三的国家中各产品的销量
country_quantity_list.sort(key=lambda x: x[1], reverse=True)
for element in country_quantity_list[0:3]:
contryName = element[0]
# 获取对应国家的分组数据
df = groupByCountry.get_group(contryName)
# 依照产品代码 StockCode 进行分组
groupByStockCode = df.groupby("StockCode")
# 对分别对某一产品的全部销售量进行求和
country_StockCode_quantity_list = list(dict(groupByStockCode["Quantity"].sum()).items())
country_StockCode_quantity_list.sort(key=lambda x: x[1], reverse=True)
# 对销量后10名的产品销量进行求和,并命名为"others"
othersQuantity = sum(list(i[1] for i in country_StockCode_quantity_list[10:]))
new_country_StockCode_quantity_list = country_StockCode_quantity_list[0:10] + [("others", othersQuantity)]
# 为产品添加对应的描述信息
# print(new_country_StockCode_quantity_list)
for i in range(len(new_country_StockCode_quantity_list)-1):
item = new_country_StockCode_quantity_list[i]
stockCode = item[0]
quantity = item[1]
description = Sto_Des["Description"].loc[Sto_Des["StockCode"]==item[0]]
new_country_StockCode_quantity_list[i] = (stockCode, quantity, list(description)[0])
# print(new_country_StockCode_quantity_list)
norm = plt.Normalize(0, max(new_country_StockCode_quantity_list, key=lambda x:x[1])[1])
# print(max(new_country_StockCode_quantity_list, key=lambda x:x[1])[1])
norm_values = norm([i[1] for i in new_country_StockCode_quantity_list])
map_vir = cm.get_cmap(name='Spectral')
# 产生连续的配色
colors = map_vir(norm_values)
explode = [0.09, 0.06, 0.03] + [0]*(len(new_country_StockCode_quantity_list)-3)
plt.pie([i[1] for i in new_country_StockCode_quantity_list],
autopct='%.2f%%',
labels=["StockCode: " + str(i[0]) for i in new_country_StockCode_quantity_list],
explode=explode,
startangle=90,
colors=colors)
labels = [i[2] for i in new_country_StockCode_quantity_list[0:-1]] + ["others"]
plt.legend(labels,
loc="upper left",
bbox_to_anchor=(1.2, 0, 0.5, 1))
plt.title(f"{contryName}产品销量占比")
plt.show()运行结果如下:
United Kingdom
销量排名前十的产品名单如下:

绘制的饼图如下:
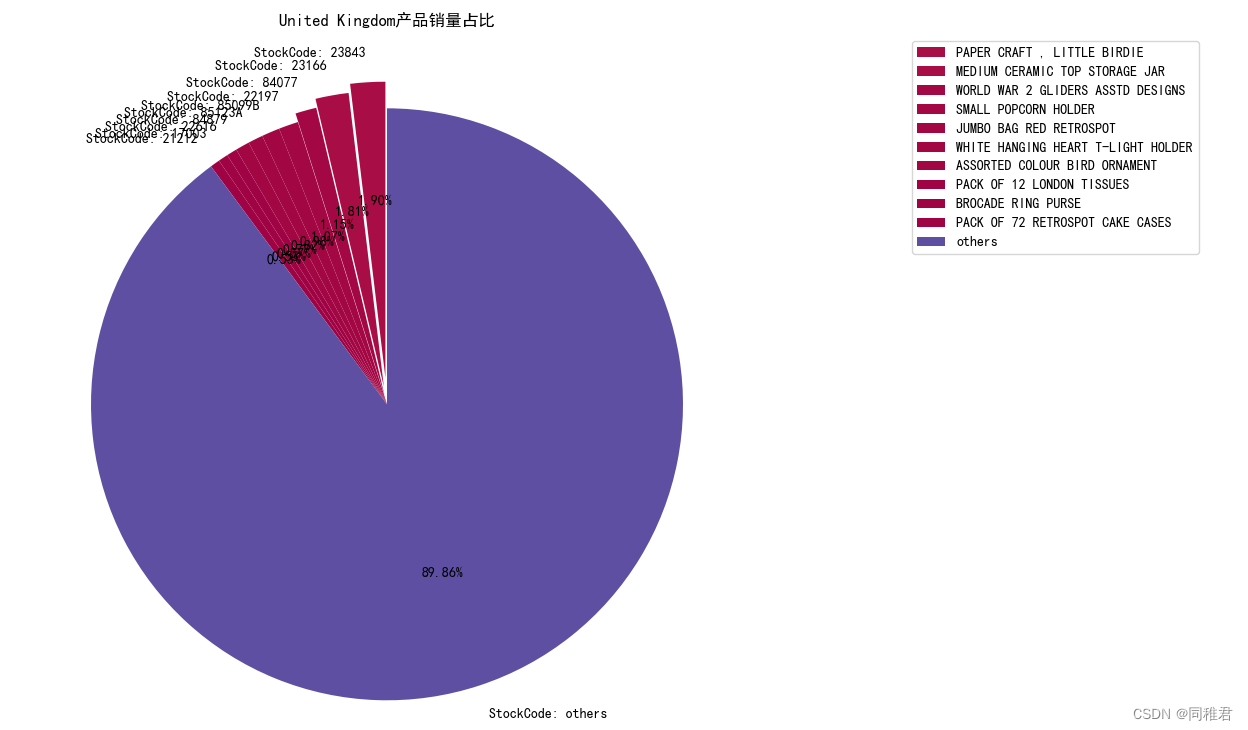
可以看出该商店的各产品在United Kingdom国内的销售量比较均衡,没有一款特别火爆的产品
Bahrain
销量排名前十的产品名单如下:
![]()
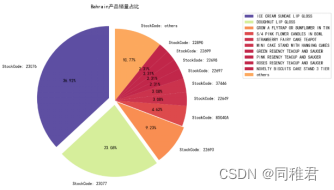
可以看到产品“23076”和“23077”的销售量之和的占比超过了一般,并且两个产品的编号相近,说明产品“23076”和“23077”之间可能存在较强关联。
四、整体关联规则
4.1. 关联规则程序执行原理,数据为演示数据,并非 Online Retail 数据集中数据。
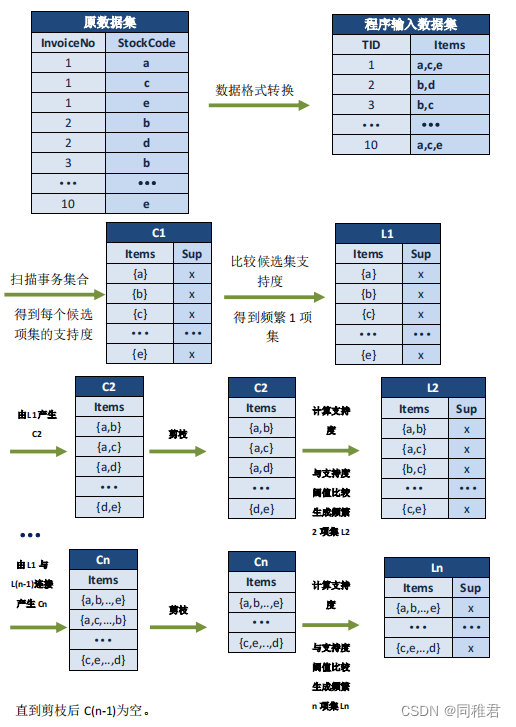
4.2 编写数据集格式修改函数,生成适合 Apriori 算法程序执行的数据格式。
# 加载用于Apriori算法的数据
# InvoiceNo:发票编号。为每笔订单唯一分配的6位整数。若以字母'C'开头,则表示该订单被取消。
# StockCode:产品代码。为每个产品唯一分配的编码。
'''
dataset:预处理好的数据集;pandas DataFrame
'''
def loatdata(dataset):
dataset["StockCode"] = dataset["StockCode"].apply(lambda x: "," + str(x))
# 将数据按照发票编号进行分组
dataset = dataset.groupby('InvoiceNo').sum().reset_index()
# 将相同发票编号的产品代码放入同一个列表中
dataset["StockCode"] = dataset["StockCode"].apply(lambda x: [x[1:]])
StockCodeLists = list(dataset["StockCode"])
# 由于此时 StockCodeLists 中的具有相同发票编号的商品代码是以一整个字符串形式组合在一起的,因此要将这一整个字符串进行切分
for i in range(len(StockCodeLists)):
StockCodesString = StockCodeLists[i][0]
StockCodeList = StockCodesString.split(",")
StockCodeLists[i] = StockCodeList
return StockCodeLists
StockCodeLists = loatdata(dataset.loc[:,["InvoiceNo", "StockCode"]])
for item in StockCodeLists:
print(item)
每个列表中存储“InvoiceNo”发票编号相同的记录的产品代码。
4.3 编写生成关联规则类(即将关联规则生成程序封装在类中,方便调用)
from exam import loatdata, dataset
StockCodeLists = loatdata(dataset.loc[:,["InvoiceNo", "StockCode"]])
class Apriori:
# 初始化函数,获取给定的数据集、支持度阈值、置信度阈值
'''
函数说明:
dataset:给定的数据集;二维列表;列表中的每一个子列表中存放一个 TID 的所有Items
supportThreshold:支持度阈值;float
confidenceThreshold:置信度阈值;float
'''
def __init__(self, dataset, supportThreshold, confidenceThreshold):
self.dataset = dataset
self.supportThreshold = supportThreshold
self.confidenceThreshold = confidenceThreshold
'''
函数说明:
找到1项候选集C1
param data: 数据集
return: 1项候选集C1
'''
def creatC1(self):
C1 = []
for row in self.dataset:
for item in row:
if [item] not in C1:
C1.append([item])
# 中文字符串升序排序
C1.sort()
# frozenset()返回1项集,项集中的每一项均为一个冻结的集合,冻结后集合不能再添加或删除任何元素
return list(map(frozenset, C1))
'''
函数描述:
计算1项候选集的支持度,剔除小于最小支持度的项集,
param D: 数据集
param C1: 候选集
return: 返回1项频繁集及其支持度
'''
def calSupport(self, D, C):
dict_sup = {} # 中间储存变量,用于计数
# 迭代每一条数据,对项集中的每一项进行计数
for i in D:
for j in C:
# 集合j是否是集合i的子集,如果是返回True,否则返回False
if j.issubset(i):
# 再判断之前有没有统计过,没有统计过的话为1
if j not in dict_sup:
dict_sup[j] = 1
else:
dict_sup[j] += 1
# 事务总数
sumCount = float(len(D))
# 计算支持度,支持度 = 项集的计数/事务总数
supportData = {} # 用于存储频繁集的支持度
relist = [] # 用于存储频繁集
for i in dict_sup:
temp_sup = dict_sup[i] / sumCount
# 将剔除后的频繁项集及其对应支持度保存起来
if temp_sup > self.supportThreshold:
relist.append(i)
supportData[i] = temp_sup
# 返回1项频繁项集及其对应支持度
return relist, supportData
'''
函数描述:
使用剪枝算法,减少了候选集空间,找到k项候选集
param Lk: k-1项频繁集
param k: 第k项
return: 第k项候选集
'''
def aprioriGen(self, Lk, k):
reList = [] # 用来存储第k项候选集
lenLk = len(Lk) # 第k-1项频繁集的长度
# 两两组合遍历
for i in range(lenLk):
for j in range(i + 1, lenLk):
L1 = list(Lk[i])[:k - 2]
L2 = list(Lk[j])[:k - 2]
L1.sort()
L2.sort()
# 前k-1项相等,则可相乘,这样可以防止重复项出现
if L1 == L2:
a = Lk[i] | Lk[j] # a为frozenset集合
# 进行剪枝
a1 = list(a) # a1为k项集中的一个元素
b = [] # b为它的所有k-1项子集
# 构造b:遍历取出每一个元素,转换为set,依次从a1中剔除该元素,并加入到b中
for q in range(len(a1)):
t = [a1[q]]
tt = frozenset(set(a1) - set(t))
b.append(tt)
# 当b都是频繁集时,则保留a1,否则,删除
t = 0
for w in b:
# 如果为True,说明是属于候选集,否则不属于候选集
if w in Lk:
t += 1
# 如果它的子集都为频繁集,则a1是候选集
if len(b) == t:
reList.append(b[0] | b[1])
return reList
'''
函数说明:
计算候选k项集的支持度,剔除小于最小支持度的候选集,得到频繁k项集及其支持度
param D: 数据集
param Ck: 候选k项集
return: 返回频繁k项集及其支持度
'''
def scanD(self, D, Ck):
sscnt = {} # 存储支持度
for tid in D: # 遍历数据集
for can in Ck: # 遍历候选项
if can.issubset(tid): # 判断数据集中是否含有候选集各项
if can not in sscnt:
sscnt[can] = 1
else:
sscnt[can] += 1
# 计算支持度
itemNum = len(D) # 事务总数
reList = [] # 存储k项频繁集
supportData = {} # 存储频繁集对应支持度
for key in sscnt:
support = sscnt[key] / itemNum
if support > self.supportThreshold:
reList.insert(0, key) # 满足条件的加入Lk中
supportData[key] = support
return reList, supportData
def get_FrequentItemset(self):
# 首先,找到1项候选集
C1 = self.creatC1()
# 将数据集中各Item中的产品代码装入集合中,再将各Items放入列表中,用于支持度计算
D = list(map(set, self.dataset))
# 计算1项候选集的支持度,剔除小于最小支持度的项集,返回1项频繁项集及其支持度
L1, supportData = self.calSupport(D, C1)
L = [L1] # 加列表框,使得1项频繁集称为一个单独的元素
k = 2 # k项
# 跳出循环的条件是没有候选集
while len(L[k - 2]) > 0:
# 产生k项候选集Ck
Ck = self.aprioriGen(L[k - 2], k)
# 计算候选k项集的支持度,剔除小于最小支持度的候选集,得到频繁k项集及其支持度
Lk, supK = self.scanD(D, Ck)
# 将supK中的键值对添加到supportData字典中
supportData.update(supK)
# 将第k项的频繁集添加到L中
L.append(Lk) # L的最后一个值为空值
k += 1
del L[-1]
# 返回频繁集及其对应的支持度;L为频繁项集,是一个列表,1,2,3项集分别为一个元素
return L, supportData
'''
函数描述:
生成集合的所有子集
param fromList:
param totalList:
'''
def getSubset(self, freqList, all_subset):
for i in range(len(freqList)):
t1 = [freqList[i]]
t2 = frozenset(set(freqList) - set(t1)) # k-1项子集
if t2 not in all_subset:
all_subset.append(t2)
t2 = list(t2)
if len(t2) > 1:
self.getSubset(t2, all_subset) # 所有非1项子集
'''
函数说明:
计算置信度,并剔除小于最小置信度的数据,这里利用了提升度概念
param freqSet: k项频繁集
param H: k项频繁集对应的所有子集
param supportData: 支持度
param RuleList: 强关联规则
'''
def calcConf(self, freqSet, all_subset, supportData, strongRuleList):
# 遍历freqSet中的所有子集并计算置信度
for conseq in all_subset:
conf = supportData[freqSet] / supportData[freqSet - conseq] # 相当于把事务总数抵消了
# 提升度lift计算lift=p(a&b)/p(a)*p(b)
lift = supportData[freqSet] / (supportData[conseq] * supportData[freqSet - conseq])
if conf >= self.confidenceThreshold and lift > 1:
print(freqSet - conseq, '-->', conseq, '支持度', round(supportData[freqSet], 6), '置信度:', round(conf, 6),
'lift值为:', round(lift, 6))
strongRuleList.append((freqSet - conseq, conseq, conf))
'''
函数描述:
生成强关联规则:频繁项集中满足最小置信度阈值,就会生成强关联规则
param L: 频繁集
param supportData: 支持度
return: 返回强关联规则
'''
def get_rule(self, L, supportData):
strongRuleList = [] # 存储强关联规则
# 从2项频繁集开始计算置信度
for i in range(1, len(L)):
for freqSet in L[i]:
freqList = list(freqSet)
all_subset = [] # 存储H1的所有子集
# 生成所有子集
self.getSubset(freqList, all_subset)
# print(all_subset)
# 计算置信度,并剔除小于最小置信度的数据
self.calcConf(freqSet, all_subset, supportData, strongRuleList)
return strongRuleList4.4 调用Apriori类
# 以荷兰为例
Netherlands_dataset = dataset.loc[dataset["Country"]=="Netherlands"]
StockCodeLists2 = loatdata(Netherlands_dataset.loc[:,["InvoiceNo", "StockCode"]])
apriori2 = Apriori(StockCodeLists2, 0.1, 0.7)
L, supportData = apriori2.get_FrequentItemset()
print("所有频繁项集:")
for i in range(len(L)):
print(f"频繁 {i+1} 项集:")
print(f"个数:{len(L[i])}")
for j in L[i]:
print(j)
print("符合要求的关联规则如下:")
rule = apriori2.get_rule(L, supportData)
print(f"个数:{len(rule)}")考虑到数据集的数据量较大(共392732条),关联规则存在的稀疏性较大,因此数据集中存在的关联规则的支持度会比较小。在经过多次调整支持度阈值与置信度阈值后,设置支持度阈值为0.006,置信度阈值为0.7,生成整体关联规则。
最终获得1069个频繁1项集、1178个频繁2项集、529个频繁3项集、135个频繁4项集、18个频繁5项集、1个频繁6项集。
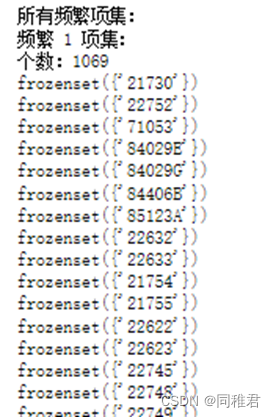

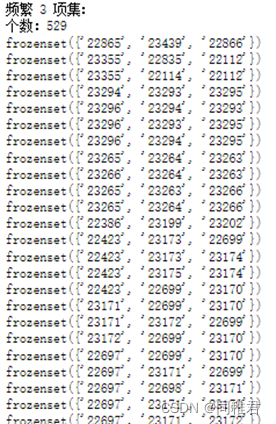

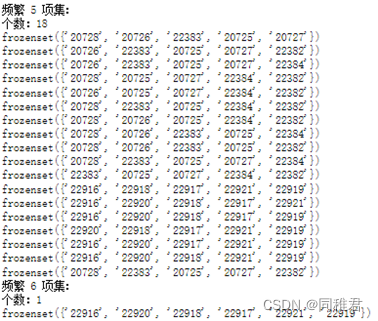
在符合置信度阈值要求的频繁项集中,频繁1项集的支持度普遍要高于频繁k(1<k<6)项集。总共挖掘出1101个强关联规则,在所有的强关联规则中,支持度最高的关联规则为:
frozenset({'22697'}) --> frozenset({'22699'}) 支持度 0.029186 置信度: 0.782923 lift值为: 18.534184
'22697'的产品描述为:GREEN REGENCY TEACUP AND SAUCER
'22699'的产品描述为:ROSES REGENCY TEACUP AND SAUCER
五、主要的 3 个国家的关联规则分析
根据不同国家产品销量排名,确定产品销量前三的国家为:United Kingdom、Netherlands、EIRE,遂对这三个主要国家进行关联规则分析。
①United Kingdom
设置支持度阈值为0.006,置信度阈值为0.7。
得到频繁1项集1068个、频繁2项集1179个,频繁3项集571个,频繁4项集169个,频繁5项集23个,频繁6项集1个。总共挖掘出1101个强关联规则。
其中支持度最高的三个关联规则为:
frozenset({'22699'}) --> frozenset({'22697'}) 支持度 0.02859 置信度: 0.702065 lift值为: 19.099148
frozenset({'22698'}) --> frozenset({'22697'}) 支持度 0.024266 置信度: 0.819473 lift值为: 22.293137
frozenset({'22698'}) --> frozenset({'22699'}) 支持度 0.023004 置信度: 0.776876 lift值为: 19.07701
②Netherlands
设置支持度阈值为0.1,置信度阈值为0.7。
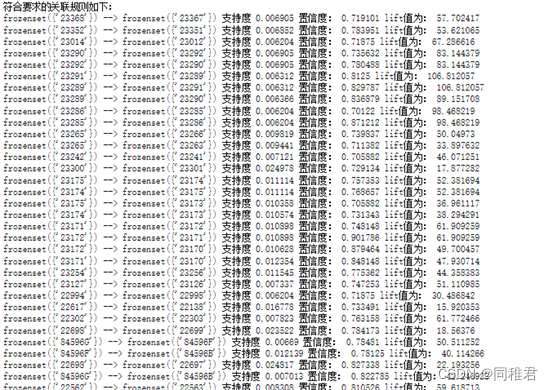
得到频繁1项集34个、频繁2项集25个,频繁3项集8个,频繁4项集1个。总共挖掘出47个强关联规则。
其中支持度最高的三个关联规则为:
frozenset({'22630'}) --> frozenset({'22629'}) 支持度 0.221053 置信度: 0.954545 lift值为: 3.238636
frozenset({'22326'}) --> frozenset({'22629'}) 支持度 0.189474 置信度: 0.72 lift值为: 2.442857
frozenset({'22630'}) --> frozenset({'22326'}) 支持度 0.168421 置信度: 0.727273 lift值为: 2.763636
③EIRE
设置支持度阈值为0.1,置信度阈值为0.7。
得到频繁1项集77个、频繁2项集45个,频繁3项集43个,频繁4项集11个。总共挖掘出258个强关联规则。
其中支持度最高的三个关联规则为:
frozenset({'22697'}) --> frozenset({'22699'}) 支持度 0.119231 置信度: 0.911765 lift值为: 5.387701
frozenset({'22698'}) --> frozenset({'22699'}) 支持度 0.103846 置信度: 0.964286 lift值为: 5.698052
frozenset({'22698'}) --> frozenset({'22697'}) 支持度 0.1 置信度: 0.928571 lift值为: 7.10084
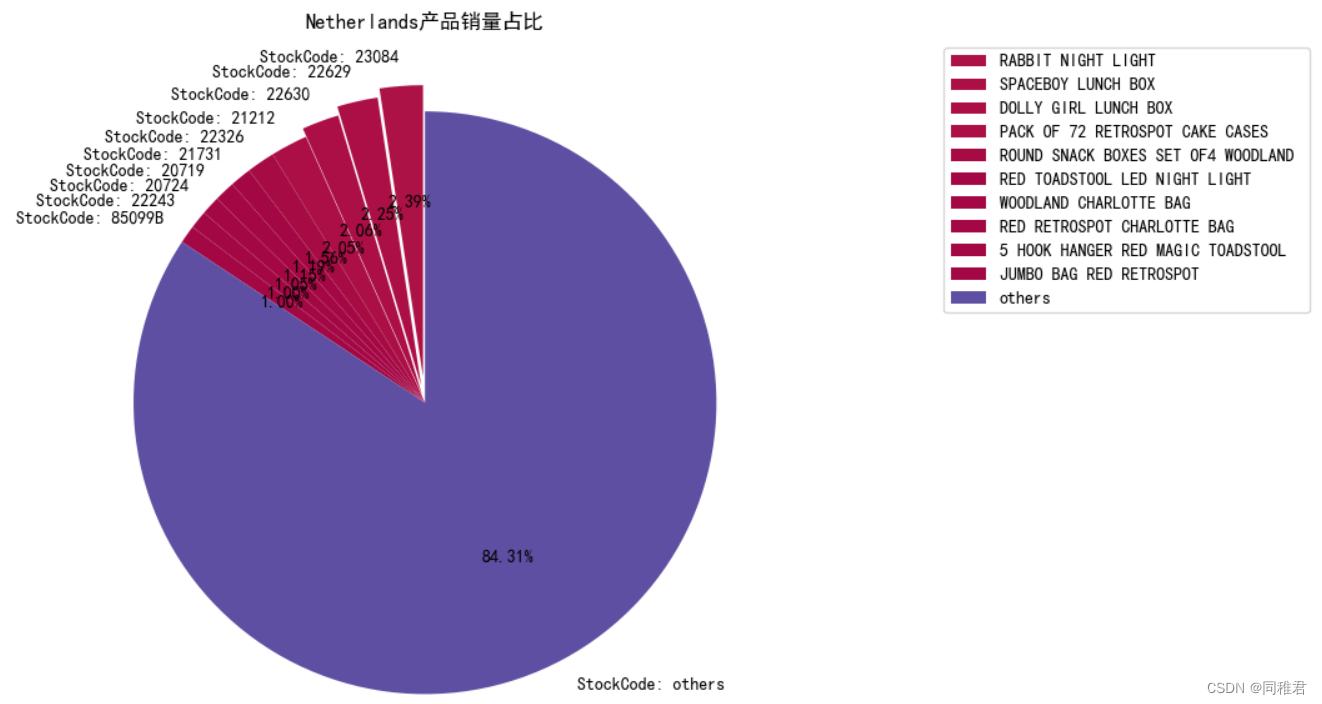
从以上挖掘结果中,可以发现项集{'22699'}、{'22698'}、{'22697'}在United Kingdom和EIRE中均为支持度较高的频繁项集,并且这三个频繁项集均在这两个国家的销售中存在强关联性。考虑到爱尔兰在地理位置上紧挨英国,因此民众的消费特性接近,关联规则的挖掘结果也间接证明了这一点。荷兰民众购买的产品的关联规则则与英国和爱尔兰不同,值得注意的是产品'22629'、'22630'、'22326'在荷兰的销售量分别排在第二、三、五名(产品在荷兰的销售量占比饼图如下),说明具有强关联性的产品,其销售量往往相近,通过产品的强关联性,热销产品可以带动其相关产品的销售。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐



 15
15 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)