并发查询数据库并做汇总处理(多线程+CompletableFuture方式)
并发查询db进行汇总的两种方式
1.需求说明
我们想要通过更快的方式查询10w条user表数据内容,做数据的汇总,得到10w个用户的年龄分布。
此时很容易想到用多线程处理,但知易行难,还是动手来写写吧。
2.准备工作
我贴心的为大家准备了数据库脚本,直接执行即可。
-- 创建user表
CREATE TABLE user (
id INT AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(50) NOT NULL,
age INT NOT NULL
);
-- 插入10万条数据
DELIMITER //
CREATE PROCEDURE InsertData()
BEGIN
DECLARE i INT DEFAULT 0;
WHILE i < 100000 DO
INSERT INTO user (name, age) VALUES (CONCAT('Name', i), FLOOR(RAND() * 100));
SET i = i + 1;
END WHILE;
END //
DELIMITER ;
-- 调用存储过程插入数据
CALL InsertData();
User类
@Data
@Accessors(chain = true)
@NoArgsConstructor
@AllArgsConstructor
@TableName("user")
public class User {
@TableId(value = "id", type = IdType.AUTO)
private Integer id;
@TableField("name")
private String name;
@TableField("age")
private Integer age;
}
分页插件,这个很重要,不然分页失效,数据就会有问题了。
@Configuration
public class MybatisPlusConfig {
@Bean
public MybatisPlusInterceptor mybatisPlusInterceptor() {
MybatisPlusInterceptor interceptor = new MybatisPlusInterceptor();
interceptor.addInnerInterceptor(new PaginationInnerInterceptor(DbType.MYSQL));
return interceptor;
}
}
自定义线程池配置,这里有个小技巧,因为我们是针对数据库查询,是IO操作,所以更应该创建更多的线程,避免cpu的空闲,当然,实际证明对于这个查询来讲保持和cpu核心数相同即可,多一点差距也不大。
@Configuration
public class ThreadPoolConfig {
@Bean("defaultExecutor")
public ThreadPoolTaskExecutor orderLogExecutor() {
ThreadPoolTaskExecutor orderLogExecutor = new ThreadPoolTaskExecutor();
//设置线程池参数信息
orderLogExecutor.setCorePoolSize(20);
orderLogExecutor.setMaxPoolSize(50);
orderLogExecutor.setQueueCapacity(100);
orderLogExecutor.setKeepAliveSeconds(60);
orderLogExecutor.setThreadNamePrefix("Default-userOper-Executor-");
orderLogExecutor.setWaitForTasksToCompleteOnShutdown(true);
orderLogExecutor.setAwaitTerminationSeconds(60);
//修改拒绝策略为使用当前线程执行
orderLogExecutor.setRejectedExecutionHandler(new ThreadPoolExecutor.CallerRunsPolicy());
//初始化线程池
orderLogExecutor.initialize();
return orderLogExecutor;
}
}
3.线程池执行
首先我们就要想到应该用多线程分页拿到部分数据,进行处理,最终做个汇总。
具体代码如下,我来进行下说明。
@Slf4j
@Service
public class UserService extends ServiceImpl<UserMapper,User> {
@Autowired
private Executor defaultExecutor;
//目的: 分页查询10000条数据 进行数据处理 调用多个线程分别查询 处理 最后汇总 统计用户的年龄分段
public void pageSum() {
int max = 100000;
int split = 20;
int size = max / split;
AtomicInteger atomicInteger = new AtomicInteger(0);
CountDownLatch countDownLatch = new CountDownLatch(split);
Map<Integer, Integer> map= new ConcurrentHashMap<>();
for (int i = 1; i <= split; i++) {
int finalI = i;
defaultExecutor.execute(() -> {
log.info("当前线程:{}", Thread.currentThread().getName());
Page<User> page = this.page(new Page<>(finalI, size));
List<User> records = page.getRecords();
atomicInteger.addAndGet(records.size());
for (User record : records) {
Integer age = record.getAge();
map.compute(age, (key, value) -> value == null ? 1 : value + 1);
}
log.info("当前线程完成查询:{}", Thread.currentThread().getName());
countDownLatch.countDown();
});
}
try {
countDownLatch.await();
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
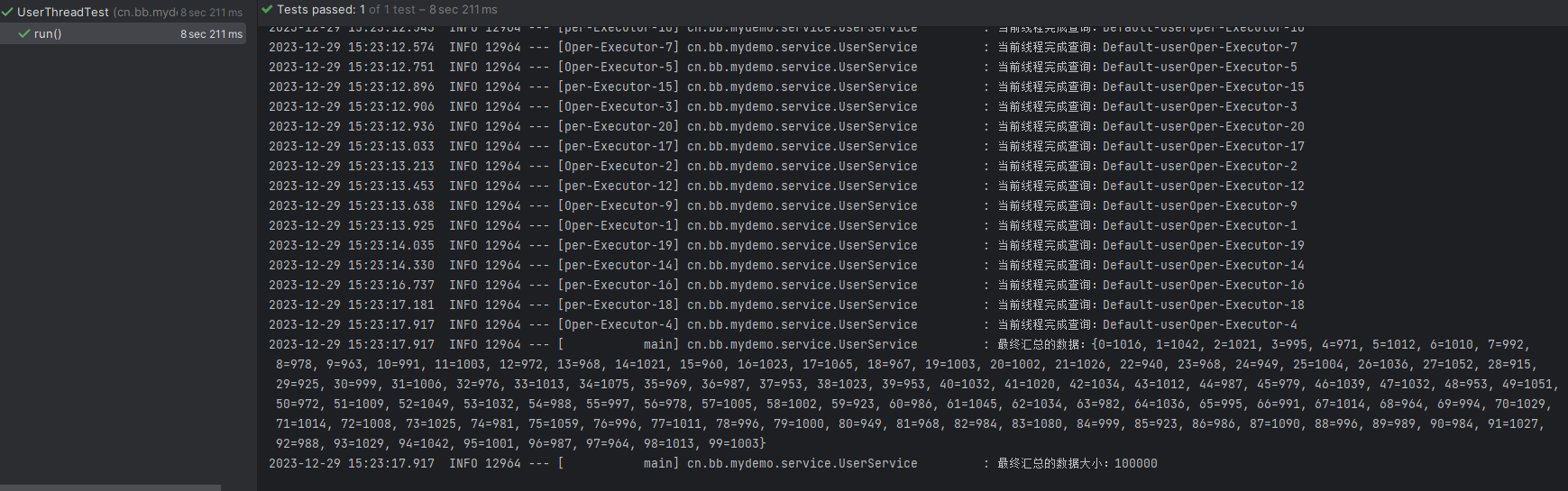
log.info("最终汇总的数据:{}", map);
log.info("最终汇总的数据大小:{}", atomicInteger.get());
}
}
1.我们通过max,split来进行分割,在for循环中进行数据的查询,保证了每次得到的数据是不同的,如果出现了数据重叠说明分页出现了问题。
2.使用CountDownLatch 来保证所有线程执行完毕后再进行汇总,当然,这里最好有没有进行汇总,但好处在于,方法不会直接执行完毕,而是会进行等待。
3.使用,ConcurrentHashMap,map.compute等,防止了数据的竞争,该方法是线程安全的。
最终执行效果如下,10w条查询用时8s多,还是可以的,比单线程快多了。

4.使用CompletableFuture
使用CompletableFuture,不要忘记内部装入线程池,否则用的是系统默认的,还不如不用呢。
public void pageUseCompatableFuture() {
// 创建并启动多个 CompletableFuture 任务来并发查询数据库
int max = 100000;
int split = 20;
int size = max / split;
AtomicInteger atomicInteger = new AtomicInteger(0);
Map<Integer, Integer> map = new ConcurrentHashMap<>();
List<CompletableFuture> futures = new ArrayList<>();
for (int i = 1; i <= split; i++) {
int finalI = i;
CompletableFuture<Void> future = CompletableFuture.supplyAsync(() -> {
log.info("当前线程:{}", Thread.currentThread().getName());
Page<User> userPage = this.page(new Page<>(finalI, size));
List<User> records = userPage.getRecords();
atomicInteger.addAndGet(records.size());
for (User record : records) {
Integer age = record.getAge();
// 细节 线程安全的合并方法 如果单单使用put会有线程安全问题
map.compute(age, (key, value) -> value == null ? 1 : value + 1);
}
log.info("当前线程完成查询:{}", Thread.currentThread().getName());
return null;
}, defaultExecutor);
// 装入集合方便后续处理
futures.add(future);
}
// 所有结果使用allof处理 如果还需操作则往后接whenxx即可
CompletableFuture<Void> allOf = CompletableFuture.allOf(futures.toArray(new CompletableFuture[0]));
// 这里只需要等待其他操作完成即可 不做处理
allOf.join();
log.info("最终汇总的数据:{}", map);
log.info("最终汇总的数据大小:{}", atomicInteger.get());
}
1.supplyAsync方法可以保证异步执行,里面传入一个提供者函数式接口,这里因为无需返回什么东西,所以用了Void作为返回值。
2.将所有的future装入了集合中,最终通过allOf 进行处理,后面没有汇总操作,但是也可以自定义加上,而后面的allOf.join()起到了和上面countDownLatch类似的效果,但看起来更加的直观。
最终的结果也和上面相同,用时也差不多,但个人认为后一种方式更加酷炫哈哈。

总结下,
1.多线程编程的难点在于数据竞争导致的数据错乱问题,不懂的api一定要查资料验证后再使用,不要盲目使用。
2.还有就是,脑子以为会了?不如代码写一下,相信还是会遇到问题的,不要想当然。
其实我们都是普通人 想着比别人花更少的时间做更多的事 其实是奢望 普通人只有专注一道 获得很精深的经验才能突破

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 9
9 1
1- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)