【Yolov5】保姆级别源码讲解之-模型训练部分train.py文件
第十八部分 模型数据封装到model类 Model attributes。第六部分 控制训练的层,可以调整参数,从对应的第几层开始进行训练。第十九部分 开始训练Start training 循环调用。第一部分 产生两个权重文件,权重文件是。第十七部分 分布式训练DDP mode。第六部分 model 检查训练权重。第十二部分 恢复训练 Resume。第八部分 batch的大小。第三部分 保存的运行
·
本次讲解yolov5训练类train.py
1.主函数
- opt参数部分和main方法

- weights:权重文件路径
– cfg:存储模型结构的配置文件 制定的网络模型配置文件 - data:存储训练、测试数据的文件
- hyp 定义了网络训练需要的一些参数,比如学习率等配置信息,具体可以查看data/hyps下的hyp.scratch-low.yaml文件
- epochs:指的就是训练过程中整个数据集将被迭代多少次,显卡不行你就调小点。 所有的数据送入网络中, 完成了一次前向计算 + 反向传播的过程
- batch-size:一次看完多少张图片才进行权重更新,梯度下降的mini-batch,显卡不行你就调小点。
- img-size:输入图片宽高,显卡不行你就调小点。
- rect:进行矩形训练
- resume:恢复最近保存的模型开始训练 训练中断可以配置此参数进行链接运算
- nosave:仅保存最终checkpoint
- notest:仅测试最后的epoch
- evolve:进化超参数
- bucket:gsutil bucket
- cache-images:缓存图像以加快训练速度
- name: 重命名results.txt to results_name.txt
- device:cuda device, i.e. 0 or 0,1,2,3 or cpu
- adam:使用adam优化
- multi-scale:多尺度训练,img-size +/- 50%
- single-cls:单类别的训练集

2.main函数
- 四个全局变量
- RANk主要是做分布式训练使用的
- WORLD_SIZE获取一个环境变量,如果它不存在,则返回None。可选的第二个参数可以指定备用默认值。key、default和结果为str。
- GIT_INFO检测git下的yolov5的更新信息


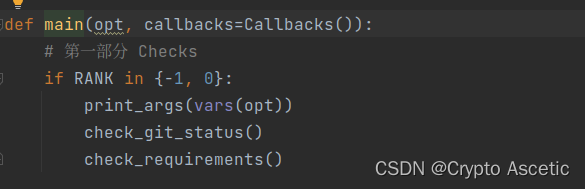
2.1 第一部分 进行校验

2.2 第二部分 配置resume参数用于中断之后进行训练

2.3第三部分 DDP mode
- 选择cpu训练还是Gpu训练
- 如果配置了分布式训练就需要额外进行配置

2.4 第四部分
-
训练部分

-
第一部分 产生两个权重文件,权重文件是

-
第二部分 超级参数 Hyperparameters

-
第三部分 保存的运行设置

-
第四部分 loogger信息设置

-
第五部分 配置部分

-
第六部分 model 检查训练权重

-
第六部分 控制训练的层,可以调整参数,从对应的第几层开始进行训练

-
第七部分 设置图片的大小

-
第八部分 batch的大小

-
第九部分 配置优化器

-
第十部分 调度程序 ,lf为学习率因子

-
第十一部分 保持模型state_dict(参数和缓冲区)中所有内容的移动平均值

-
第十二部分 恢复训练 Resume

-
第十三部分 多卡训练训练

-
第十四部分 同步批处理

-
第十五部分 Trainloader

-
第十六部分 校验loader

-
第十七部分 分布式训练DDP mode

-
第十八部分 模型数据封装到model类 Model attributes

-
第十九部分 开始训练Start training 循环调用

-
第二十部分 结束训练

3.训练结果

- x和y表示标注框,深度越深表示标注的点越多
- heitht和width是代码标注的数据的位置

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 3
3 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)