数据库 | 面试官:一次到底插入多少条数据合适啊?.....面试连环炮
数据库中的插入操作是一项既微妙又关键的任务,特别是当我们需要处理大量数据时。这篇文章深入探讨了影响插入性能的各种因素,并为你提供了一些实际的策略和建议。以下是我们讨论的一些要点:🎯磁盘I/O与性能的关系:直接的大量写入可能会导致磁盘I/O饱和,降低整体性能。通过理解磁盘的工作方式,我们可以更好地调整我们的插入策略。📌如何决定插入数据量:考虑硬件、系统资源和数据库的内部机制是关键。每个环境都有其
前言
大家好!👋 在互联网时代,我们的每一个动作,无论是浏览网页、分享动态、点赞、购物或者搜索信息,都会在背后产生数据。这些数据,根据其用途和重要性,可能会被储存到不同的地方,其中最常见的存储载体就是——数据库。
不过,数据库并非一成不变的。根据应用场景和数据特性,我们有关系型数据库如MySQL,也有非关系型数据库,例如Redis。比如说,当你在社交网络上点赞一条动态时,为了快速响应,可能是一个基于内存的数据库如Redis首先记录这一动作,而后台可能会周期性地同步这些动作到持久化的存储系统中。
那么,当面对巨大的数据流入时,我们如何高效、稳定地将这些数据存储到数据库中呢?“我每次应该插入多少数据才最合适?” 这个问题,尽管看似简单,但涉及到的策略和技术都颇为丰富。
所以,本文的目的,就是带领大家一同探索这个话题。不论你是初涉数据库的新手,还是有经验的开发者,我都希望你能从这篇文章中获得有价值的信息。那么,不再赘述,我们现在就开始吧!
说在开头
在开始讨论这个话提前,我们先看面试场景中的对话:
👨 面试官: 在你之前的工作经验中,当你们需要向数据库中插入大量数据时,你们是如何操作的?
👦 候选者: 噢,我们使用批量插入来优化性能。
👨 面试官: 很好。那你们每次批量插入大约多少条数据?
👦 候选者: 通常我们每次批量插入超过2000万条数据。
👨 面试官: 😲 2000万条?你确定每次都插入这么多数据?不担心资源过载或事务延迟等问题吗?
👦 候选者: 我这系统插入2000w条数据没问题啊!不信你可以回访我们Leader
👨 面试官: 但是,你有没有考虑过为什么2000w条数据可以?2000w条数据是基于什么方式算出来的?
👦 候选者: 是不是数据量?
👨 面试官: 数据量只是其中一个因素。但2000万条数据对于不同的数据库配置、硬件环境、甚至数据本身的复杂性来说,可能有不同的影响。只是简单地说“我们的系统可以处理”并不足以说明问题。真正的关键是,你知道为什么你的系统可以处理这么大的数据量吗?或者说,你们是怎么确定2000万是一个合适的数字的?
👦 候选者: 呃…这个…我不太清楚,是我们之前的一位资深工程师定的。
👨 面试官: 这就是问题所在。我们在工作中不仅要知道如何做,还要知道为什么这么做。只有了解背后的原理和策略,我们才能更好地优化和应对各种问题。
👦 候选者: 明白了,我以后会更加注意这个问题。
👨 面试官: 很好,对于这个问题你可以回去深入研究一下。你先回去等通知。
从上面的对话中,我们可以看到一个很现实的问题:很多人可能知道批量插入可以提高性能,但真正了解背后原因的却不多。而一个优秀的工程师,应该不仅仅满足于“这样做可以工作”,而是要探求背后的“为什么”。
所以,为了不让你们变成上面的候选者👦,在这篇文章中,我们将深入探讨数据库插入的各种策略、技术以及背后的原理。不过在此之前,我们还是得先了解一些基础。
数据库插入操作的基础知识
插入数据是数据库操作中的基础。但是,我们程序员将面临随之而来的问题:🤔如何快速有效地插入数据,并保持数据库性能?当你向数据库中插入数据时,这些数据直接存储到硬盘上吗?
1.1 插入数据的原理
深入了解插入数据时背后发生的事情是优化数据库性能的关键。
1.1.1 写入缓存与磁盘同步
当数据被写入数据库时,它首先应该被写入缓存中,而不是缓慢的磁盘中。然后后台线程在适当的时间点将数据同步到磁盘上。
这样做的主要原因有以下几点:
- 速度差异:RAM(随机存取存储器)的速度远远快于磁盘。RAM对数据的读写几乎是瞬时的。而磁盘,无论是传统的机械硬盘还是现代的固态硬盘,其读写速度都远慢于 RAM。
- 磁盘 I/O 的成本:每次进行磁盘 I/O操作都有一定的开销。如果数据库频繁地进行小批量的磁盘写入,这会导致大量的 I/O 开销,得不偿失哇。
- 合并写入:首先将数据写入 RAM,在数据库可以把数据同步到磁盘之前,累积多个写入操作。最后一次性将大量数据写入磁盘,从而减少 I/O 操作的次数和开销。
💡 总结: 总的来说嘛,为了最大化性能,数据库首先将数据写入缓存,并在适当的时间点将这些数据同步到磁盘。这种策略不仅加速了写入操作,还有效地减少了磁盘 I/O,提高数据库性能。
👨:🤔那脏页还没有来得及刷入到磁盘时,MySQL 宕机了,数据不就莫得了?
👦:这我懂!InnoDB 在进行更新操作时采用了 Write Ahead Log(先写日志)策略。这意味着在数据被写入磁盘之前,相关的操作会首先被记录到 redo log 日志中。这种策略赋予了 MySQL 在系统崩溃后的恢复能力。
1.1.2 事务日志与数据持久化
为了确保数据的完整性,数据库首先将插入操作写入事务日志。只有当数据被安全地写入日志后,它才被移动到实际的数据表中。
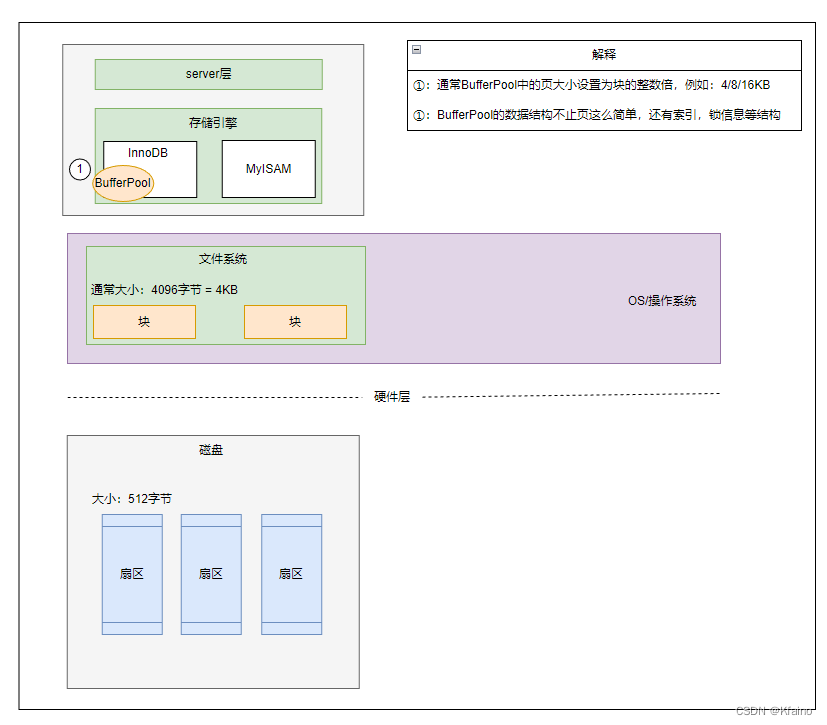
👨:🤔那为什么数据库要用“页”来存储数据呢?
👦:我画个图,你看下

👨:没看出来啊,你这基础还不错。
👦:谢谢,我接着往下说:
1.2 数据存储单位:页
操作系统为了管理物理内存和虚拟内存,使用一个称为“页”的结构来管理,说白了其实就是一块固定的连续内存空间而已。这些页有固定的大小,如 4KB、8KB 或 16KB。这个大小一般是块的整数倍。
使用页进行存储有多种优势,如减少磁盘I/O、高效的空间管理以及缓存优化。了解你的数据库页的大小可以帮助你优化插入操作和空间管理!
👨 :🤔那么,单条数据插入和批量数据插入在速度和效率上有什么不同呢?
1.3 单条数据与批量数据插入的差异
1.3.1 速度和效率比较
📘 知识点:我们的业务系统的CUD操作,每次都要伴随着事务开销。如果你在应用中执行单条插入,插入了1000次数据,那么你就有1000次事务开销。而批量插入可以将这些数据在一个事务中插入,大大减少了总的事务开销。
单条插入虽然简单明了,但在大量数据插入时,其性能上的缺陷会逐渐显现。与之相对,批量插入可以显著提高性能,但它也引入了其它问题,数据的验证和错误处理变得更为复杂。(鱼与熊掌不可兼得)
1.3.2 对数据库性能的影响
💡 小贴士:批量插入可以减少磁盘I/O次数,从而提高性能。但是,如果一次插入的数据量过大,它可能会暂时阻塞其他操作,影响数据库的响应时间。
为了达到最佳性能,您可能需要根据实际情况调整批量插入的数据量。过少的数据可能导致性能优化不足,而过多的数据可能导致数据库响应时间增加。
👨 :🤔数据库的锁机制和并发控制策略在插入操作中起到关键作用。如果多个进程或线程试图同时插入数据,可能会发生锁争用,进而影响性能。我们又该如何优化这些机制进一步提高批量插入的性能呢?
如何决定合适的插入数据量?
为了实现数据库的最大效能,确定合适的插入数据量至关重要。但这并不是一项简单的任务,需要考虑多种因素。
👨 :🤔很好啊,能考虑这个说明你有在思考了,那当你决定插入一大批数据时,你通常是如何选择具体的数量的?
2.1 考虑硬件和系统资源
在考虑合适的插入数据量时,首先需要考虑的是硬件和系统的限制。
磁盘I/O:
磁盘I/O是插入数据时的主要瓶颈之一。过多的插入操作会导致磁盘I/O饱和,降低系统的响应时间。
🚀 优化建议:监控磁盘I/O使用情况,确保在高插入量时不超过其峰值。
内存使用:
大量的插入操作可能会增加RAM的使用量。如果内存使用接近或达到了系统限制,可能会导致性能下降,甚至导致系统崩溃。
💡 小贴士:定期检查系统的内存使用情况,确保有足够的可用资源来处理大量的插入操作。
2.2 数据库的内部机制
数据库本身也有一些内部机制,这些机制在决定插入数据量时也应该考虑。
事务大小
数据库事务的大小直接影响其性能。较大的事务可能会导致长时间的锁定,从而影响其他查询的性能。
💡 小贴士:找到合适的事务大小平衡点是提高插入性能的关键。太小的事务可能会增加总的事务数量,而太大的事务可能会导致系统资源的饱和。
锁策略
考虑到数据库的锁策略也很重要。过多的锁争用可能会导致性能下降。
🔍 深入探讨:优化数据库的锁策略和并发控制可以进一步提高插入性能。
👨 : ?你先别管事务和锁的问题,你是通过监控这些硬件性能去调整合适的插入量,那生产怎么办?没有可以估算的大小?我不是很满意你这个回答,你思考思考再回答,我出去接个水。
👦: 这…(拿起手机google)…
2.3 估算插入量
为了进行这个估算,我们首先要确定一条记录的结构。假设我们有以下的记录结构:
- 整型字段 (
int): 4 字节 - 变长字符字段 (
varchar): 假设平均长度为 50 字节,最大长度为 255 字节 - 日期字段 (
date): 3 字节 - 浮点数字段 (
float): 4 字节
基于上述的结构,一条记录的平均大小可以估算为:
记录大小 = 4 + 50 + 3 + 4 = 61 字节 \text{记录大小} = 4 + 50 + 3 + 4 = 61 \text{字节} 记录大小=4+50+3+4=61字节
为了考虑到某些记录可能使用 varchar 的最大长度,我们也可以计算最大记录大小:
最大记录大小
=
4
+
255
+
3
+
4
=
266
字节
\text{最大记录大小} = 4 + 255 + 3 + 4 = 266 \text{字节}
最大记录大小=4+255+3+4=266字节
内存分析:
假设给定 8G 内存,并且预留 20% 的空间,我们可以使用的内存为:
可用内存
=
0.8
×
8
G
=
6.4
G
\text{可用内存} = 0.8 \times 8 \text{G} = 6.4 \text{G}
可用内存=0.8×8G=6.4G
由此,我们可以存储的最大记录数为:
最大记录数 (平均大小)
=
6.4
×
1
0
9
字节
61
字节/记录
\text{最大记录数 (平均大小)} = \frac{6.4 \times 10^9 \text{字节}}{61 \text{字节/记录}}
最大记录数 (平均大小)=61字节/记录6.4×109字节
最大记录数 (最大大小)
=
6.4
×
1
0
9
字节
266
字节/记录
\text{最大记录数 (最大大小)} = \frac{6.4 \times 10^9 \text{字节}}{266 \text{字节/记录}}
最大记录数 (最大大小)=266字节/记录6.4×109字节
硬盘分析:
考虑 512G 硬盘,我们可以存储的最大记录数为:
最大记录数 (平均大小)
=
512
×
1
0
9
字节
61
字节/记录
\text{最大记录数 (平均大小)} = \frac{512 \times 10^9 \text{字节}}{61 \text{字节/记录}}
最大记录数 (平均大小)=61字节/记录512×109字节
最大记录数 (最大大小)
=
512
×
1
0
9
字节
266
字节/记录
\text{最大记录数 (最大大小)} = \frac{512 \times 10^9 \text{字节}}{266 \text{字节/记录}}
最大记录数 (最大大小)=266字节/记录512×109字节
👦: 差不多就这样(为自己的计算沾沾自喜中)
👨 : 可以啊,功底不错,虽然有点瑕疵(刮目相看,这轮面试差不多就让你过了)
实际应用中的策略与建议:结合MyBatis
👨 : 上面说的都是理论,你项目中一般怎么使用批量插入的?
👦: 我想下啊, 大概就这些点:
使用<foreach>标签进行批量插入
在MyBatis的映射文件中,通常使用<foreach>标签来进行批量插入。
<insert id="insertMultiple" parameterType="list">
INSERT INTO tableName (column1, column2, ...)
VALUES
<foreach collection="list" item="record" separator=",">
(#{record.column1}, #{record.column2}, ...)
</foreach>
</insert>
ExecutorType.BATCH
Mybatis Plus也有相关的批量插入的方法。不过你也可以设置ExecutorType为BATCH来开启批处理模式。这样,所有的SQL语句都会被积累,直到手动提交或关闭会话。
SqlSession session = sqlSessionFactory.openSession(ExecutorType.BATCH);
使用BATCH模式时,MyBatis允许你设置一个batchSize。累积到多少数量的SQL语句时,MyBatis就会会将它们批量执行。合理设置batchSize可以避免OOM(Out of Memory)问题。一帮情况下,我们项目组就是用这个办法,怕有些新手程序员批量单条插入,导致性能缓慢。
避免频繁的会话提交
在批量插入期间,频繁提交会话可能会导致性能下降。一般在插入完所有数据后再进行一次会话提交。
👦: 大概就这些
👦: 好,了解了
总结
最后,我们来总结下扒。在本文中,我们旨在为你提供一个参与面试的视角,帮助你理解和优化数据库的插入操作。不管你是数据库新手还是经验丰富的开发者,我们希望这些建议能够为你在实际应用中带来价值。
感谢你的阅读!如有任何疑问或建议,请随时与我们分享!🙌
参考文献

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐


 2
2 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)