深度学习-图像分类(CNN)
助你快速学习CNN卷积神经网络,从原理到实战
深度学习-图像分类(CNN)
卷积神经网络(CNN convolution neural network )
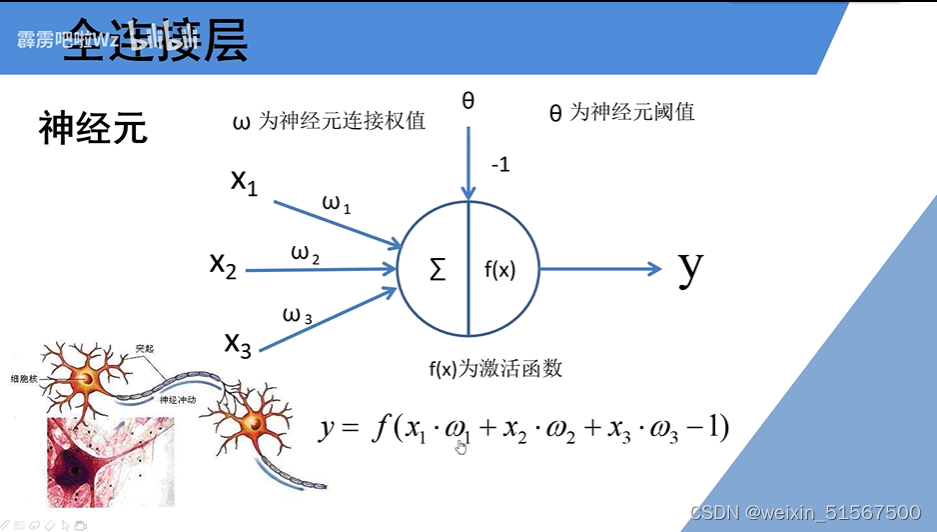
全连接层

-
通过x1,x2,x3的传入,以及对应的权值,再加上偏置值(神经元阈值),通过激励函数的action得到相应的输出
-
BP(back propagation)
-
包括信号的前向传播和误差的反向传播两个过程。即计算误差输出时按从输入到输出的方向进行(前向传播),而调整阈值和权值则从输出到输入反向(反向传播)
-

-
卷积层(CNN中独有的网络结构)
-
卷积:实质是一个滑动窗口(卷积核)在特征图上进行滑动,并进行相对应的计算(滑动计算过程中,卷积核的值是不会发生变化的,按照对应相乘,将特征图中的相对应的权值与卷积核中相对应的值进行相乘,最后输出得到卷积之后的特征矩阵)。
-
目的:进行图像的特征提取
-
卷积的特性:
- 拥有局部感知机制
- 权值共享
-

-
卷积核的深度(channel)与输入特征层的channel相同
-
输出的特征矩阵channel与卷积核个数相同
-
加入偏移量bias如何计算
- 首先按照卷积的定义依次与原特征图像进行卷积处理,再最后的结果时候加上其对应的偏移量bias即可
-
引入非线性因素使其具备解决非线性问题的能力
-
sigmoid激活函数:sigmoid激活函数饱和时梯度值非常小,当网络层数较深时易出现梯度消失(具体下现在当值越大时,其导数变化趋势会减少)
-
relu函数:缺点在于反向传播时,有一个非常大的梯度经过时,反向传播更新后导致权重分布中心小于0,反向传播无法更新权重,即进入失活状态。

-
-
如果卷积过程中出现越界(即滑动窗口某个部分肯能驶出边界)怎样处理
- 输入图片大小(原特征图像)W * W
- Filter(滑动窗口,滤波器)大小 F * F
- 步长(左右上下移动的距离) S
- padding的像素数P(补0的像素点,如果左右上下全补就是2p,否则补一半便是p)
- 卷积后矩阵尺寸大小计算公式:N=(W - F + 2P)/ S + 1 默认P=1
池化层
MaxPooling下采样层
- 目的:对特征图进行稀疏处理,减少数据运算量

AveragePooling下采样层
- 没有训练参数
- 只改变举证的w,h,不改变图像的深度(channel)
- 一般poolsize和stride相同

误差的计算(反向传播)
-

-
W(ij):其中i为上一层的第i个结点的流向下一层的j个节点所对应的神经元上的权重weight
-
bi代表第i个神经元的偏置值
-
sigama为激活函数(这里采用sigmoid函数)
-

-
上图为计算过程
-
softmax函数处理后所有输出节点概率和为1
-
计算公式为上述右下角 o 函数
-
Softmax函数的作用就是将每个类别所对应的输出分量归一化,使各个分量的和为1。可以理解为,能将任意是输入值转化为概率。Softmax主要用于多分类任务的激活函数,一般用在神经网络的输出端。
-

-
Cross Entropy Loss交叉熵损失
-
针对多分类问题:(softmax输出,所有输出和为1)
- 它的输出会属于不同的类别,列入人类和男人,可能会同时属于人类又会属于男人类别会出现重叠的部分
-
针对二分类问题(sigmoid输出,每个输出节点互不相干)
- 它的输只会属于某一个类别,列入猫狗分类

-
交叉熵损失函数经常用于分类问题中,特别是神经网络分类问题。交叉熵是用来描述两个分布的距离的,神经网络训练的目的就是使 g(x) 逼近 p(x)。
相对于sigmoid求损失函数,在梯度计算层面上,交叉熵对参数的偏导不含对sigmoid函数的求导,而均方误差(MSE)等其他则含有sigmoid函数的偏导项。Sigmoid的值很小或者很大时梯度几乎为零,这会使得梯度下降算法无法取得有效进展,交叉熵则避免了这一问题。
为了弥补 sigmoid 型函数的导数形式易发生饱和(saturate,梯度更新的较慢)的缺陷,可以引入Softmax作为预测结果,计算交叉熵损失。由于交叉熵涉及到计算每个类别的概率,所以在神经网络中,交叉熵与softmax函数紧密相关。
-
计算Loss:

误差的反向传播
-

-
以求解w11(2)的误差梯度为例,求误差梯度为求偏导,故使用高数的偏导数法则可以求解,注意o1和o2为对应y1,y2的函数,故要进一步进行求导
-

-

-
按照上述公式求出其值便可以得到每一层的误差梯度,同时也反向传播到每一层,接下来是对误差进行更新
权重的更新
-

-
gradient:误差损失梯度,为上一个误差传播函数计算的值,简单记忆为g()
-

-
由于我们进行训练不可能做到一次性把所有待训练的样本进行加载到内存中,故需要我们采取分批次训练进行求解,此时损失梯度指向当前批次最优方向。训练过程不平稳
-
解决这一问题我们需要优化器(Optimizer)
-
一言以蔽之,优化器就是在深度学习反向传播过程中,指引损失函数(目标函数)的各个参数往正确的方向更新合适的大小,使得更新后的各个参数让损失函数(目标函数)值不断逼近全局最小
- 随机梯度下降法(Stochastic Gradient Descent,SGD)
- SGD+Momentum
- Adagrad
- RMSProp
- Adam
-
原理解释 :优化问题可以看做是我们站在山上的某个位置(当前的参数信息),想要以最佳的路线去到山下(最优点)。首先,直观的方法就是环顾四周,找到下山最快的方向走一步,然后再次环顾四周,找到最快的方向,直到下山——这样的方法便是朴素的梯度下降——当前的海拔是我们的目标函数值,而我们在每一步找到的方向便是函数梯度的反方向(梯度是函数上升最快的方向,所以梯度的反方向就是函数下降最快的方向)。
事实上,使用梯度下降进行优化,是几乎所有优化器的核心思想。当我们下山时,有两个方面是我们最关心的:
- 首先是优化方向,决定“前进的方向是否正确”,在优化器中反映为梯度或动量。
- 其次是步长,决定“每一步 迈多远”,在优化器中反映为学习率。
所有优化器都在关注这两个方面,但同时也有一些其他问题,比如应该在哪里出发、路线错误如何处理……这是一些最新的优化器关注的方向
-
-
SGD优化器
-
SGD+Momentum
-

-
不仅会考虑当前的梯度下降的方向,还会考虑上一次的梯度下降的方向,从而进一步降低样本噪声的干扰
-
-
Adagrad

- 实质:分母在更新的时候St为求其损失梯度的平方和,会越来越大,所以会导致学习率会越来越小,从而导致学习率下降的很快
-
RMSProp
-

-
再Adagrad优化器上进行进一步的更新,从而控制Adagrad学习效率下降太快
-


腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐



 28
28 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)