深度学习PyTorch,TensorFlow中GPU利用率较低,CPU利用率很低,且模型训练速度很慢的问题总结与分析
在深度学习模型训练过程中,在服务器端或者本地pc端,输入nvidia-smi来观察显卡的GPU内存占用率(Memory-Usage),显卡的GPU利用率(GPU-util),然后采用top来查看CPU的线程数(PID数)和利用率(%CPU)。往往会发现很多问题,比如,GPU内存占用率低,显卡利用率低,CPU百分比低等等。接下来仔细分析这些问题和处理办法。1. GPU内存占用率问题这往往是由于模型的
在深度学习模型训练过程中,在服务器端或者本地pc端,输入nvidia-smi来观察显卡的GPU内存占用率(Memory-Usage),显卡的GPU利用率(GPU-util),然后采用top来查看CPU的线程数(PID数)和利用率(%CPU)。往往会发现很多问题,比如,GPU内存占用率低,显卡利用率低,CPU百分比低等等。接下来仔细分析这些问题和处理办法。
1. GPU内存占用率问题
这往往是由于模型的大小以及batch size的大小,来影响这个指标。当你发下你的GPU占用率很小的时候,比如40%,70%,等等。此时,如果你的网络结构已经固定,此时只需要改变batch size的大小,就可以尽量利用完整个GPU的内存。GPU的内存占用率主要是模型的大小,包括网络的宽度,深度,参数量,中间每一层的缓存,都会在内存中开辟空间来进行保存,所以模型本身会占用很大一部分内存。其次是batch size的大小,也会占用影响内存占用率。batch size设置为128,与设置为256相比,内存占用率是接近于2倍关系。当你batch size设置为128,占用率为40%的话,设置为256时,此时模型的占用率约等于80%,偏差不大。所以在模型结构固定的情况下,尽量将batch size设置大,充分利用GPU的内存。(GPU会很快的算完你给进去的数据,主要瓶颈在CPU的数据吞吐量上面。)
2. GPU利用率问题
这个是Volatile GPU-Util表示,当没有设置好CPU的线程数时,这个参数是在反复的跳动的,0%,20%,70%,95%,0%。这样停息1-2 秒然后又重复起来。其实是GPU在等待数据从CPU传输过来,当从总线传输到GPU之后,GPU逐渐起计算来,利用率会突然升高,但是GPU的算力很强大,0.5秒就基本能处理完数据,所以利用率接下来又会降下去,等待下一个batch的传入。因此,这个GPU利用率瓶颈在内存带宽和内存介质上以及CPU的性能上面。最好当然就是换更好的四代或者更强大的内存条,配合更好的CPU。
另外的一个方法是,在PyTorch这个框架里面,数据加载Dataloader上做更改和优化,包括num_workers(线程数),pin_memory,会提升速度。解决好数据传输的带宽瓶颈和GPU的运算效率低的问题。在TensorFlow下面,也有这个加载数据的设置。
torch.utils.data.DataLoader(image_datasets[x],
batch_size=batch_size,
shuffle=True,
num_workers=8,
pin_memory=True)为了提高利用率,首先要将num_workers(线程数)设置得体,4,8,16是几个常选的几个参数。本人测试过,将num_workers设置的非常大,例如,24,32,等,其效率反而降低,因为模型需要将数据平均分配到几个子线程去进行预处理,分发等数据操作,设高了反而影响效率。当然,线程数设置为1,是单个CPU来进行数据的预处理和传输给GPU,效率也会低。其次,当你的服务器或者电脑的内存较大,性能较好的时候,建议打开pin_memory打开,就省掉了将数据从CPU传入到缓存RAM里面,再给传输到GPU上;为True时是直接映射到GPU的相关内存块上,省掉了一点数据传输时间。
3. CPU的利用率问题
很多人在模型训练过程中,不只是关注GPU的各种性能参数,往往还需要查看CPU处理的怎么样,利用的好不好。这一点至关重要。但是对于CPU,不能一味追求超高的占用率。如图所示,对于14339这个程序来说,其CPU占用率为2349%(我的服务器是32核的,所以最高为3200%)。这表明用了24核CPU来加载数据和做预处理和后处理等。其实主要的CPU花在加载传输数据上。此时,来测量数据加载的时间发现,即使CPU利用率如此之高,其实际数据加载时间是设置恰当的DataLoader的20倍以上,也就是说这种方法来加载数据慢20倍。当DataLoader的num_workers=0时,或者不设置这个参数,会出现这个情况。
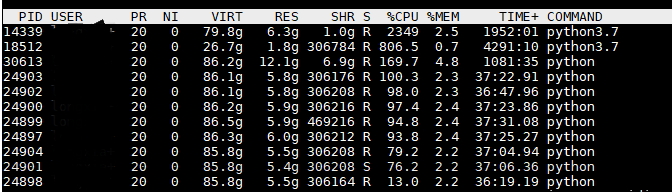
CPU利用率查看结果
下图中可以看出,加载数据的实际是12.8s,模型GPU运算时间是0.16s,loss反传和更新时间是0.48s。此时,即使CPU为2349%,但模型的训练速度还是非常慢,而且,GPU大部分是时间是空闲等待状态。

num_workers=0,模型每个阶段运行时间统计
当我将num_workers=1时,出现的时间统计如下,load data time为6.3,数据加载效率提升1倍。且此时的CPU利用率为170%,用的CPU并不多,性能提升1倍。

num_workers=1时,模型每个阶段运行时间统计
此时,查看GPU的性能状态(我的模型是放在1,2,3号卡上训练),发现,虽然GPU(1,2,3)的内存利用率很高,基本上为98%,但是利用率为0%左右。表面此时网络在等待从CPU传输数据到GPU,此时CPU疯狂加载数据,而GPU处于空闲状态。
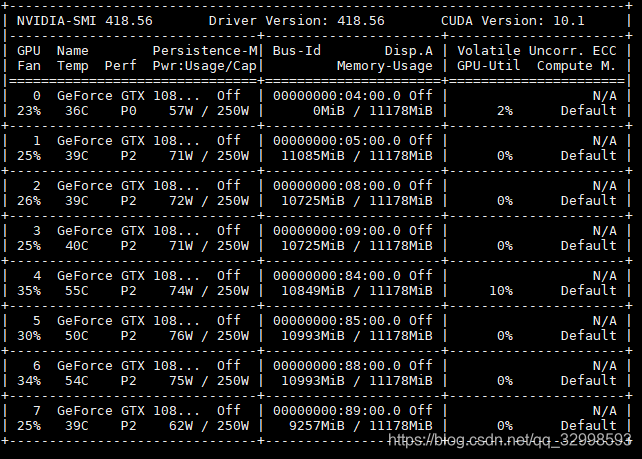
1,2,3号GPU的内存占用率和计算效率截图
由此可见,CPU的利用率不一定最大才最好。
对于这个问题,解决办法是,增加DataLoader这个num_wokers的个数,主要是增加子线程的个数,来分担主线程的数据处理压力,多线程协同处理数据和传输数据,不用放在一个线程里负责所有的预处理和传输任务。
我将num_workers=8,16都能取得不错的效果。此时用top查看CPU和线程数,如果我设置为num_workers=8,线程数有了8个连续开辟的线程PID,且大家的占用率都在100%左右,这表明模型的CPU端,是较好的分配了任务,提升数据吞吐效率。效果如下图所示,CPU利用率很平均和高效,每个线程是发挥了最大的性能。
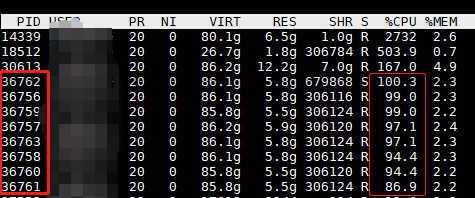
num_workers=8时,CPU利用率和8个连续PID任务
此时,在用nvidia-smi查看GPU的利用率,几块GPU都在满负荷,满GPU内存,满GPU利用率的处理模型,速度得到巨大提升。
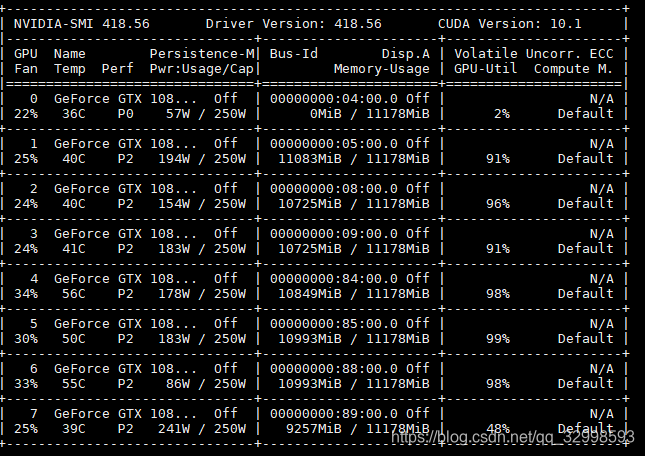
优化数据加载num_workers=8,和设置batch size的结果
上图中可以看见,GPU的内存利用率最大化,此时是将batch size设置的较大,占满了GPU的内存,然后将num_workers=8,分配多个子线程,且设置pin_memory=True,直接映射数据到GPU的专用内存,减少数据传输时间。GPU和CPU的数据瓶颈得到解决。整体性能得到权衡。
此时的运行时间在表中做了统计:
| 处理阶段 | 时间 |
| 数据加载 | 0.25s |
| 模型在GPU计算 | 0.21s |
| loss反传,参数更新 | 0.43s |
4. 总结
对上面的分析总结一下,第一是增加batch size,增加GPU的内存占用率,尽量用完内存,而不要剩一半,空的内存给另外的程序用,两个任务的效率都会非常低。第二,在数据加载时候,将num_workers线程数设置稍微大一点,推荐是8,16等,且开启pin_memory=True。不要将整个任务放在主进程里面做,这样消耗CPU,且速度和性能极为低下。
Supplementary:看到大家在评论回复的问题比较多,所以再加一些叙述!
开这么多线程。第一个,查看你的数据的batch_size,batchsize小了,主CPU直接就加载,处理,而且没有分配到多GPU里面(如果你使用的是多GPU);如果是单GPU,那么就是CPU使劲读数据,加载数据,然后GPU一下就处理完了,你的模型应该是很小,或者模型的FLOPs很小。检查一下模型问题。还有就是,现在这个情况下,开8个线程和1个线程,没什么影响,你开一个num_workers都一样的。如果速度快,没必要分配到多个num_workers去。当数据量大的时候,num_workers设置大,会非常降低数据加载阶段的耗时。这个主要还是应该配合过程。
在调试过程,命令:top 实时查看你的CPU的进程利用率,这个参数对应你的num_workers的设置;
命令: watch -n 0.5 nvidia-smi 每0.5秒刷新并显示显卡设置。
实时查看你的GPU的使用情况,这是GPU的设置相关。这两个配合好。包括batch_size的设置。
时间:2019年9月20日
5. 再次补充内容
有很多网友都在讨论一些问题,有时候,我们除了排查代码,每个模块的处理信息之外,其实还可以查一下,你的内存卡,是插到哪一块插槽的。这个插槽的位置,也非常影响代码在GPU上运行的效率。
大家除了看我上面的一些小的建议之外,评论里面也有很多有用的信息。遇到各自问题的网友们,把他们的不同情况,都描述和讨论了一下,经过交流,大家给出了各自在训练中,CPU,GPU效率问题的一些新的发现和解决问题的方法。
针对下面的问题,给出一点补充说明:
问题1. CPU忙碌,GPU清闲。
数据的预处理,和加载到GPU的内存里面,花费时间。平衡一下batch size, num_workers。
问题2. CPU利用率低,GPU跑起来,利用率浮动,先增加,然后降低,然后等待,CPU也是浮动。
- 2.1 下面是具体的步骤和对策:
在pytorch训练模型时出现以下情况, 情况描述: 首先环境:2080Ti + I7-10700K, torch1.6, cuda10.2, 驱动440 参数设置:shuffle=True, num_workers=8, pin_memory=True; 现象1:该代码在另外一台电脑上,可以将GPU利用率稳定在96%左右 现象2:在个人电脑上,CPU利用率比较低,导致数据加载慢,GPU利用率浮动,训练慢约4倍;有意思的是,偶然开始训练时,CPU利用率高,可以让GPU跑起来,但仅仅几分钟,CPU利用率降下来就上不去了,又回到蜗牛速度。
- 可以采用的方法:
两边的配置都一样吗。另一台电脑和你的电脑。你看整体,好像设置配置有点不同。包括硬件,CPU的核,内存大小。你对比一下两台设备。这是第一个。第二个,还是代码里面的配置,代码的高效性。你一来,CPU利用率低,你看一下每一步,卡到哪里,哪里是瓶颈,什么步骤最耗时。都记录一下每一个大的步骤的耗时,然后在分析。测试了每一个大的过程的时间,可以看见,耗时在哪里。主要包括,加载数据,前向传播,反向更新,然后下一步。
- 2.2 经过测试之后,第二次问题分析:
经过测试,发现本机卡的地方在加载图像的地方,有时加载10kb左右的图像需要1s以上,导致整个batch数据加载慢!代码应该没有问题,因为在其他电脑能全速跑起来;硬件上,本机的GPU,CPU都强悍,环境上也看不出差距,唯一差在内存16G,其他测试电脑为32G,请问这种现象和内存直接关系大吗?
- 情况分析
最多可能就在这边。你可以直接测试batch size为1情况下的整个计算。或者将batch size 开到不同的设置下。看加载数据,计算之间的差值。最有可能就是在这个load data,读取数据这块。 电脑的运行内存16g 32g。其实都已经够了,然后加载到GPU上,GPU内存能放下,影响不大。所以估计是你的内存相对小了,导致的问题。试一下。
- 2.3 问题定位,解决方法:
- 这台电脑的内存条插的位置不对,4个插槽的主板,1根内存的时候应该插在第2个插槽(以cpu端参考起),而组装电脑的商家不专业,放在了第4个插槽上,影响性能,更换位置后,速度飞起来了!关于插槽详情,有遇到的朋友去网上收,一大堆!
在自己电脑,或者自己配的主机上,跑GPU的时候,记得注意查看你自己的内存卡是插到哪一个槽上的。
问题1:博主您好,我是tensorflow框架,是os.environ["CUDA_DEVICE_ORDER"] = "PCI_BUS_ID" 和os.environ["CUDA_VISIBLE_DEVICES"] = "0"制定了gpu,虽然gpu内存占满,但是利用率忽高忽低,大部分出现的的是0,刷的频繁了也会出现99%的情况,这为啥呀?会对训练结果造成影响么?非常感谢
答:您好,我现在使用Python tensorflow写代码,但现在我的cpu利用率很高,GPU利用率几乎为零,但是我用import os os.environ["CUDA_VISIBLE_DEVICES"] = "0" 来指定了GPU。您之前的博客写了torch如何解决这个问题,拜托您能不能对于使用tensorflow如何解决这个问题给我做歌解答,非常感谢您 你的私信开启防打扰模式,回复不过来。 在这里做回复:你应该没有将模型load到GPU上面,全在CPU上面跑。
问题2:大佬啊,请教一下啊!这里描述一下我的问题:开始是 CPU 占用高,设置 num_works=16;之后训练过程中GPU占用逐渐增加直到OOM,然后在每个epoch 之后加 torch.cuda.empty_cache();最后,现在,gpu usage 变化很大 700MB -> 1500MB -> 2300MB -> 700MB 这样变;而 cup 占用也 1000% -> 1700% -> 2400% -> 700% -> 100% -> 400% -> 1100% 这样变,这是什么问题呀?
答:先是CPU在加载数据,从内存load到GPU的内存。CPU占用过程高。然后开始训练,GPU内部的缓存不断增加。前向传播存储中间变量,反传更新权重。更新完之后,你进行了cache的清除,GPU就减少为最初始的状态,这个700MB应该是整个网络结构在GPU里面,以及权重参数的值。然后继续load 数据从CPU到GPU。CPU也不断增加。进入这个循环。你的应该是正常的情况。没问题的。
问题3:楼主,我设置的batch size为128,计算每个模块的时间,然后在每个batch后统一打印,`print(t2-t1,t3-t2,t4-t3,t5-t4)`,结果每次一下子出来将近100个batch,等待一会又打印出来近100行信息。更神奇的是,他会在一个print里面停止,不是打印完整的4个时间后停止。这是什么问题呢?谢谢啦!
答: 这样,每一个要测试的点,插入时间点:check1=time.time(), 然后,到这个模块的结束,去print一下 print(time.time()-check1)。 分别记录每个模块的耗时,分开print()。试一下这个。 到下一个函数,然后 check2=time.time() ,然后到函数完成了,又print(time.time()-check2)。类似这种结果。还没解决。我是把print函数放在一个循环里面——每个iteration打印一次。但是系统在print执行期间卡壳有点不理解。。因为print执行也不需要太多计算资源吧。。我是小白,可能思维比较直。。。解决了吗?应该是循环的问题,循环放置的问题。你主要看一下你的print()函数放置的问题。
问题4:博主请问 4G显存跑Alexnet网络分类花卉数据集CPU占用率大概85%-90%,GPU在20-30%之间是正常的吗 主要是我发现CPU占有率总是比GPU高很多 而且我这张1650卡跑VGGnet就几乎跑不动了 batch和epoch要设很低才能龟速跑...
答:是不是显存没设置按需求分配, tf这里好像默认是设置占用8g显存, 你的数据集很大么, 我10monkey数据集, 读取处理数据在50秒(282mb), 训练很快, 都卡在读取处理数据上了。对,刚刚这个老哥回复你的,我也觉得是这个原因。基本上卡在数据的传输上了。从CPU到GPU的数据传递。你的显卡很小。显存小,能够放下的数据量和自己网络结构,很有限制。你4G的显存,VGGNet很大的,所以占你很大显存。后面稍微新一点的网络。显存没有这么大了,MobileNet,SqueezeNet这些。
问题5:博主,您好,能否分享一下各个阶段计算时间的代码呢?万分感谢,我想根据这个代码找到数据加载的瓶颈,因为我将数据转为tensor后存储进lmdb中了,速度确实快了,但是gpu利用率还是会隔一段时间变为0.
答:计算时间这个,直接开始一个 time_start=timer.time() time_end = timer.time() processing_time=time_end - time_start. 你GPU利用率变为0,说明此时你GPU在等待,数据传输到GPU的input data的这个tensor过程中,SSD或者你服务器的内存传输至GPU有延迟,或者速度跟不上,所以GPU空闲,然后这个CPU使劲转。
问题6:就是利用GPU运行时打开任务管理器性能看到的,GPU内存使用100%占满了,但是利用率只有2%,我自己找了80多张图进行训练的,多线程加载我不会,一直是2%或者1%,很确定就是利用gpu device 0跑程序的。
答:你的计算资源是不是很小的GPU哦。还有就是,数据加载过程,开启多线程加载没有。你看一下GPU的内存使用情况,2%是计算情况下还是模型加载到GPU上,一直是稳定的2%吗。多个参数都看一下。您说的调整DataLoader这个num_wokers的个数,我找遍了代码没这个numworker,在哪里呢?这个num_workers是pytorch下面的设置,在数据加载里面。你用的是TensorFlow,那个相应的设置也有,但是不是叫num_workers。具体是什么我忘了,查一下。 你的GPU内存沾满100%,利用率2%,就是上面的这个,把batch_size增大,或者减少,看一下你的利用率。然后,增加TensorFlow下面的num_workers这个设置,看利用率的上升。主要就是这两个设置。你配合着查看一下。 主要是把模型加载到GPU上来。剩下就在上面两个设置上调整。
问题7:请教一下,我在做一个项目数据量大概有几十万和几十个特征,电脑给的内存几乎用到90%,cpu大概是有七八十,不过pycharm中的gpu都是0好像都没有用到,to.device和num_works用过了也没用,有什么办法吗?
答:应该是没有放进去,你自己看一下,gpu的内存开始用起来没有。
问题8:博主你好,你文章中的“不要将整个任务放在主进程里面做,这样消耗CPU,且速度和性能极为低下” 要怎么理解,我目前开启的多进程里只有一个占用了226%,其他都是不到2%,是因为我放主进程里了吗?可是我只有一个GPU,这会和我不是固态有关系吗?
答:ImageNet也是100多G。你在平衡一下,按照步骤来。应该能够充分利用的。pin_memory为true,将model加到多个GPU里面的写明没有。
-
if torch.cuda.device_count() > 1: model = nn.DataParallel(model, device_ids=[0, 1, 2, 3]) model = model.to(device)
谢谢回复,不过我在将pin_memory设置为true之后,gpu利用率还是很低,我的显存16G,数据一百多G,是因为数据太大没有效果吗?这个没问题的。你已经放进去了,后面再运行中,运行稳定了,查看后面的设备的使用情况,包括CPU的使用率,GPU的占用率,一开始CPU也许有一个主进程使用得比较多。你设置了num_workers,4或者8,16吧。这个后面跑起来,应该有这么多个进程能够看见的。用top查看。后面应该稳定。这是一个。第二,我也发现,TensorFlow有时候存在这个情况。
问题9:博主您好,我目前也是使用pytorch框架做一个任务,数据量非常大,读完数据大概需要100g的内存,然后dataloader我也是设置了num和pinmemory,但这样仍不能提速,我的gpu利用率大概在0~40%浮动,且不稳定,如果再继续调大dataloader里的num会报出memory不足的错误,请问一下您在这种情况下有没有些建议。另外我看到您总结里面有这么一条“不要将整个任务放在主进程里面做,这样消耗CPU,且速度和性能极为低下。”我请问您这个应该怎么理解,我多卡使用的是dataparllel,希望能得到您的回复,谢谢!
答:batch size设置大点,你的GPU最大占比能够用上去。第二个是,来回的浮动,不稳定,那就是你的数据吞吐速度赶不上你的GPU处理速度,GPU把你的batch数据处理完了,等待你数据喂进来。这个时候就没有计算,利用率降低。所以,你在提升num_workers的时候,也要把batch_size加大。主要是配合这两个。DataLoader的pin_memory=True,计算过程中: input = input.to(device) target = target.to(device) 大概试一试,没有效果再说。 我再加大batchsize就会让显存爆掉,而且我现在的data吞吐速度已经不支持目前的batchsize,再增大恐怕是更没办法负载。谢谢您的建议。请问您最后怎么优化解决的? 我现在也是数据吞吐速度赶不上GPU处理速度,GPU利用率在17%左右,时而跳转为0.。 我的batchsize=256,但是因为特征较多,一条样本差不多10w维度的特征,所以传送起来着实慢。不知道有什么解决方法吗?您好,我最后尝试了几种方法都没有得到很好的解决,最后由于时间问题,不得不妥协了,不过我可以和你分享一些我的思路。你如果用的torch并行的话,可以试试distributed dataparallel,我当时用的是dataparallel,通信速度会慢些,换成ddl可能数据分发会快很多,但是我尝试了一些demo出现数据重复读取的问题,所以未果。另外还可以尝试下混合精度计算,可以提高batchsize的大小。这是我的思路,如果您有更好的方法,可以留言跟我分享下,谢谢。最后解决了吗。这个问题,解决了,多方面优化吧。① 训练的时候,定义了一个SequenceData 迭代器,用了多线程,调整了works数量以及max_queue_size。此外还对生成一个batch数据进行了优化,例如使用了np.repeat、np.tile。②预测的时候,把训练好的模型分了3块,用户侧走了一部分模型,item侧走了一部分模型,最后进行交叉预测计算。(例如每个用户对6个item分布进行打分,这样做用户侧只需要计算一次计算,节省了不少时间!)。
问题10:我只有一个gpu,用pin_memory报错: return data.pin_memory() RuntimeError: cannot pin 'torch.cuda.FloatTensor' only dense CPU tensors can be pinned 用num_workers报错: File "D:\ProgramData\Anaconda3\envs\pytorch_gpu\lib\site-packages\torch\multiprocessing\reductions.py", line 242, in reduce_tensor event_sync_required) = storage._share_cuda_() RuntimeError: cuda runtime error (801) : operation not supported at C:\w\1\s\tmp_conda_3.7_104508\conda\conda-bld\pytorch_1572950778684\work\torch/csrc/generic/StorageSharing.cpp:245 两个问题都没成功解决,不知道为什么,如果可以的话,请博主赐教
答:1. CPU tensor才可以pin_memory,你是不是在加载数据之前,对数据进行了处理,导致数据成为了torch.cuda.FloatTensor了。查看一下。 2. 你自己查看一下你的电脑的num_workers数,自己电脑的CPU核数,num_workers不应该超过你的核数。我们用的服务器是64核的,所以设置16,32的num_workers没问题。好的谢谢您,pin_memory的问题明白啦,可是我的电脑是6核12线程,num_worker是设置的12以下
问题11:感谢博主详细解答,我做文字检测任务,使用Pytorch,有3块2080ti,bs设置为16(吃满卡),num_work设置为3的时候速度最快,过高过低都慢,但是此时GPU的利用率大约只有五成,这还有提升的空间吗?
答:bs为16都吃满卡了。你的模型是多大啊,已经中间的层数,缓存的feature map。有这么大吗。看一下你batchsize设置对不对。16就能把你的2080ti占满,是显卡的内存都吃满了吗。这个要注意一下。num_workers差不多。因为你的数据就只有16的batchsize,加载数据只需要3-4额num_workers就能加进去。GPU只跑到5成,那就是你batchsize设置小了,没有将gpu充分发挥使用。后来是不是你的GPU空闲着,等待新的数据,如果是的话,那你的数据加载处,也有点问题。加载慢了,GPU空着等数据来。
问题12:博主你好,我是学校和别人共用一个服务器,服务器有两个gpu,第一个gpu的内存利用率百分之20,第二个没人用,为什么我把batch size从64改为128就显示RuntimeError: CUDA out of memory. Tried to allocate 392.00 MiB (GPU 0; 15.90 GiB total capacity; 11.42 GiB already allocated; 368.88 MiB free; 149.58 MiB cached)呢?求告知,谢谢
答:是还需要在开辟392MB的内存。但是当前的已经被用了,只有368.8MiB了。你要开辟392MiB,当前free的不够用。所以要报错。模型和内存的需求量不是成正比的,batch size越大,内存需要的不只是两倍,应该是大于两倍。3倍左右的需求量。博主你好,谢谢你的回复,有一点不明白他这个内存是怎么算的,因为我batch size为64的时候内存只用3321M,即使改成128按理说最多也只需要6642M啊,内存应该是完全够用的,而且 上面为什么显示 Tried to allocate 392M(为啥才需要392M这么少,却说内存不够用呢?困扰很久了,谢谢博主你)。内存不够用了。你加的太大了。96也许就差不多了。加大了GPU的内存不足。才报这个错。
问题13:博主您好~,我出现的问题是,想在模型测试效果好的情况下,保存该模型。使用torch.save(),进行保存,报错cannot serialize a bytes object larger than 4 GiB。您遇到过这个问题么?
答:模型太大了。包括参数太多了,model size太大。中间的weights过多。等等。需要看看这个模型的大小。 第二,分模块保存,然后分模块加载。
问题14:我现在是本地3分钟一个step,服务器却要2个多小时才一个step,cpu500%多,单GPU,显存占满,利用率却只有10%,增大批次的确增加至20%,但是这种反差说明哪里还是有问题,不知道博主遇到过这种情况吗?
答:服务器多少个核啊。你用的500%多,那就是相当于用了5个核左右。 你自己的电脑,本地,你看你的CPU是几核几线程的,而且,你本地应该是用满了CPU的核。CPU这边的核心数,包括算力,也是一个容易忽视的点。 你本地跑,用的GPU和服务器的GPU,是一样的吗,GPU数量相同吗,GPU的性能显存差别大吗。这几个硬件配置弄完了对比清楚了,那剩下就是代码的问题了。刚解决了,是我的模型函数里面,自己写的attention_mask函数估计是使用了两层tf.map_fn函数,导致在GPU上无法运行,但是对于数据尺寸小的,比如【10,30】这种形状的tensor 没有问题,如果大了,就运算不出来,或者非常非常的缓慢,具体原因还在想,不过问题解决了,我把attention_mask函数改了一下,一切正常。
问题15:您好,我想请教一下您文中说的“不要将整个任务放在主进程里面做,这样消耗CPU,且速度和性能极为低下。”具体是什么含义。我是把模型的搭建数据读取都放在main()函数中,然后是在 if __name__ == '__main__': main()调用的。我dataloder的num_work数设置的是8(用的服务器是40核的)但训练时看cpu只有一个核是100%其他占用都很少。使用的是单GPU,GPU的使用率在100%,50%之间跳动,请问是什么情况。望有空时解答谢谢。
答: 按照我的方法,处理不好吗。 这个情况我有时候也用到。这个一般都是pytorch才有的问题。你用的是pytorch吧。使用率在跳动,就是你的内存数据往gpu里面塞,送数据的时候,在跳动。尽量把那个map给开启。我发现他们,有些,就是不按照这样设置,反而是1700%这样的用,相当于用了17核心。 这个你看速度起得来吧。 我一般是比如 设置为8核心,那么基本上8个核,都是100%或者80-90%这种范围。你设置了之后,只有一个这么高,看你的数据,batchsize设置多大。分配到每个cpu核上的多大。你在试一试,不行效果在交流。
问题16:不要将整个任务放在主进程里面做,这样消耗CPU,且速度和性能极为低下。这句话是什么意思啊,是把number_worker设多一点吗?
答:嗯,要看自己电脑或者服务器的核心数量,是几核的。来设定。太小了,处理慢,太多了,分散的太多。num_workers不能超过电脑的CPU的核心数。设置为8差不多挺好的。
问题17:博主您好,我在实验室和同学共用服务器,总共是40核的cpu,其他同学在跑程序的时候已经占用了大约32核左右,我只能占用1.5以下.训练的速度十分的慢,我想复现别人论文实验结果然后加以提升,他只用2.4小时一轮epochs我需要20+小时.我猜测的就是CPU的占用低导致数据吞吐慢,gpu的利用率也一直在40%以下,请问这种情况怎么去提高自己CPU的占用率.我的batchsize是2,2080的卡,但是因为其他同学在跑程序显存留的不多.我2的batchsize已经占用了近4G的显存了.num_workers设置的为4.我尝试调高bathsize,cpu占用会在一开始高一点点到2~3之间,但马上就下降.请问这个我问题怎么处理.pytorch的网络.谢谢!
答:老铁,你这个电脑,40 核的,都被大家用了,32核,给你的,都没什么资源了。而且,你那边同学,是不是也用了GPU的。GPU同时跑几个计算的任务,需要调度,分配内存,这些都很耗时。你要在这么挤得情况下,想跑的很快,确实是很难。人家一轮2.4小时,你需要24小时。主要原因还是显卡和CPU都被很多任务占用吧。先找空试一试单独的跑一下。如果在电脑空闲情况下, 都比较慢,那再优化代码。先真正检查你的电脑,空闲情况下跑。你现在设置,和论文的设置,配置,差不多。如果人家也用相同的卡,相同的batchsize。那就应该是电脑被其他任务用了,占着的原因。找一个空时间段,试一下吧。你好博主, 我想继续请教一下怎么提高cpu的利用率,如何在保持batchsize不变的情况下提高.我目前的batchsize为1,cpu的利用率在200%左右浮动,我猜测数据的吞吐速度很慢,我跑项目的速度远远慢于论文的时间.我尝试调高torch.set_num_threads()的参数,cpu的使用率会上升但是对跑项目的速度没有任何帮助.我是直接从git上下载的原项目,参数也都对照无误,如何提高cpu的利用率呢?好的。明白。pin_memory也开了的吧。提前加载数据到GPU内存上面。就不用让GPU空闲着,等待数据从CPU load 到GPU。batch size为1,本来就不需要用CPU,你的batch size太小,CPU不用调用太多负载,也能给你处理。你即使现在写成4个num_workers,需要处理的数据量这么小,也不用你的CPU进行大负荷的运转。为了测你真正的把CPU利用率用起来,你直接加大你的batch size。变为16,32,64,试一试。这个时候,你的CPU利用率和GPU利用率一下就上来了。先按照我刚刚回复的,直接加大 batch size来测利用率。然后跑完实验之后给我回复一下实际效果和状态。加大的之后耗时明显缩短,cpu利用率变高了,但也还是时高时低的摇摆不定,GPU的利用率则先是0%,然后快速增长到60%-70%,然后又递减至0%,停留一会儿后重复增长降低。
问题18:大佬,你好,我这边用pytorch构建的网络, pin_memory=True, num_workers=4,前面训练最开始GPU利用率在0%,然后训练一个多小时后,GPU利用率跑到了80%左右,但是最近没有修改代码的情况下训练,GPU利用又是0%,top查看了CPU各个线程的利用率也是非常的低,大佬有遇到过类似的情况吗,或者说有啥方法和建议。多谢了!
答:这个代码没有变,应该是没问题的啊。你这个可以把速度打一下出来。每个环节的耗时。你的GPU 和CPU都是0吗,或者接近于0 。用watch -n nvidia-smi 0.5,实时监控一下显卡的应用。看是有冲低到高,然后又降低的过程。0%,然后10%,80%然后又掉到0%。如果是这样的过程,那就是数据加载,返回给CPU处理,没有配合好。CPU后处理,或者前处理,耗时过长。导致GPU等待时间过久。程序运行前一个小时是CPU10%左右,GPU0%,1-1.5小时是0% 10% 30% 然后0%这样往返,然后大概跑两小时后,GPU利用率60%-85%之间往返。还有一个问题是,我程序跑几次之后,整个服务器的GPU都没法调用了,如果我没跑,其他人跑tensorflow是没有出现导致GPU无法调用的情况,我的模型是pytorch构建的,结果就是导致pytorch和tensorflow都无法调用GPU了。重装CUDA后又变好,现在这种情况已经反复搞了好几次了,哎。代码问题了,你装的库,之前是装好的吗。这样一来,你这代码有破坏库文件的bug。好好检查一下代码。还有,前一个小时是CPU10%左右。后面慢慢增加。而且是以小时来计算。你前面有数据加载,模型构建, 初始化什么的,耗时一个小时吗。这个不应该。整个流程就是加载数据,处理。返回。然后继续下一轮。你的这个,是不是没有跑起来。你都实时输出你的状态,代码跑到那一步了,实时的输出一下,打印结果。你如果前面GPU利用率为0 。那就是没有在GPU上跑起来。但是你代码一定是显式的设置了,to.device. 都要放到GPU 上哈。
if torch.cuda.device_count() > 1:
model = nn.DataParallel(model, device_ids=[0, 1, 2, 3])
model = model.to(device)你好,我后来查看buff/catch发现,我的数据加载比较慢,在有多人使用服务器时候,会将我加载到服务器中的数据冲洗掉,如果我一个人使用服务器,等第一个epoch跑完后,训练速度就跑起来起来了。我将原始保存为.npy格式的文件保存为.h5,但是第一个epoch的数据加载速度似乎并没有太大变化。我想在又想能否直接将数据文件夹挂载,不知道速度会不会提高。有这个的。将数据转换为h5,或者,md什么的。数据压缩的lmdb。也就是.mdb文件。这样加载到GPU上会很快。这是一个专门的挂载文件。你查一下。我这边的数据,都是lmdb的类型。我这边直接将数据挂载上去,速度跑得飞快,GPU利用率现在基本稳定在99%,当然也也是进行了pin_memory=True, num_workers=4的.发现大部分速度慢都是因为数据准备花费了大量时间。大佬您好,刚刚我又尝试了一下训练,服务器就我一个人使用,在训练大概一个半小时后,GPU和CPU都跑起来了,特别服务器中wa 参数,在最开始时候大概是10,正常运行时候为0,网上查了一下说这个参数越大,IO堵塞层度越大,为啥最开始训练时候IO跟不上呢,你有遇到过这种问题没。
问题19:博主您好,我想请教一下增加num_workers和使用pin_memory对CPU占用的影响会有多大呢,我在跑一个2020年的模型,训练到20%的时候80G的内存就不够用了,后来我把num_workers从4改成了0,把pin_memory改成了False,情况有所缓解,但是还是无法完成整个训练过程,请问有什么办法能让训练过程的内存占用减少呢?
答:你中间绝对保存了什么中间变量的。训练一个阶段,只保存当前epoch的相关loss,梯度这些。然后训练完一个epoch,就会丢掉当前这个epoch的信息。下一个iterative会重新更新,计算,缓存的。你这个中间一定是保存了中间变量,包括checkpoint,以及model.state_dict,以及其他的变量,而且是每一个epoch都在存一下信息的。你要查一下。常规的显卡内存是不变的。跑起来显卡内存不变,CPU这边,应该也不是增量式的,只是会开始占用多少,后面略微增加,不会这种直接一直增加下去的。仔细审查代码,是不是有缓存的东西。
问题20:博主 您好! 我在pytorch训练模型时出现以下情况,不知您是否遇到,求教? 情况描述: 首先环境:2080Ti + I7-10700K, torch1.6, cuda10.2, 驱动440 参数设置:shuffle=True, num_workers=8, pin_memory=True; 现象1:该代码在另外一台电脑上,可以将GPU利用率稳定在96%左右 现象2:在个人电脑上,CPU利用率比较低,导致数据加载慢,GPU利用率浮动,训练慢约4倍;有意思的是,偶然开始训练时,CPU利用率高,可以让GPU跑起来,但仅仅几分钟,CPU利用率降下来就上不去了,又回到蜗牛速度。
答:两边的配置都一样吗。另一台电脑和你的电脑。你看整体,好像设置配置有点不同。包括硬件,CPU的核,内存大小。你对比一下两台设备。这是第一个。第二个,还是代码里面的配置,代码的高效性。你一来,CPU利用率低,你看一下每一步,卡到哪里,哪里是瓶颈,什么步骤最耗时。都记录一下每一个大的步骤的耗时,然后在分析。测试了每一个大的过程的时间,可以看见,耗时在哪里。主要包括,加载数据,前向传播,反向更新,然后下一步。你可以测一下。您好! 经过测试,发现本机卡的地方在加载图像的地方,有时加载10kb左右的图像需要1s以上,导致整个batch数据加载慢!代码应该没有问题,因为在其他电脑能全速跑起来;硬件上,本机的GPU,CPU都强悍,环境上也看不出差距,唯一差在内存16G,其他测试电脑为32G,请问这种现象和内存直接关系大吗???最多可能就在这边。你可以直接测试batch size为1情况下的整个计算。或者将batch size 开到不同的设置下。看加载数据,计算之间的差值。最有可能就是在这个load data,读取数据这块。 电脑的运行内存16g 32g。其实都已经够了,然后加载到GPU上,GPU内存能放下,影响不大。所以估计是你的内存相对小了,导致的问题。试一下。我怀疑是。我找到问题了,特意回复一下,有遇到同样问题,可参考。 主要问题是:这台电脑的内存条插的位置不对,4个插槽的主板,1根内存的时候应该插在第2个插槽(以cpu端参考起),而组装电脑的商家不专业,放在了第4个插槽上,影响性能,更换位置后,速度飞起来了!关于插槽详情,有遇到的朋友去网上收,一大堆! 嗯,这个很难让人怀疑到是硬件的问题,能够定位到加载数据很慢了。这个还是很艰难的找出原因了。可以。我放文档里面,补充说明一下

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 28
28 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)