毕业设计-基于深度学习的网络流量异常检测系统
毕业设计-基于深度学习 的 网络流量异常检测系统:近些年来,网络的高速发展、信息系统的规模增长以及数据的互联网络化,使得物联网、大数据等新产业快速演进,海量数据流量在网络中传输,互联网迎来了发展的黄金时期。根据互联网系统协会的不完全统计,截至2020年,全球范围内互联网用户数累计约为45.4亿,相比于2019年增长了近3亿。同时根据中国互联网信息中心第47次统计报告,截至2020年12月,我国网民
目录
前言
📅大四是整个大学期间最忙碌的时光,一边要忙着备考或实习为毕业后面临的就业升学做准备,一边要为毕业设计耗费大量精力。近几年各个学校要求的毕设项目越来越难,有不少课题是研究生级别难度的,对本科同学来说是充满挑战。为帮助大家顺利通过和节省时间与精力投入到更重要的就业和考试中去,学长分享优质的选题经验和毕设项目与技术思路。
🚀对毕设有任何疑问都可以问学长哦!
选题指导: https://blog.csdn.net/qq_37340229/article/details/128243277
大家好,这里是海浪学长毕设专题,本次分享的课题是
🎯毕业设计-基于深度学习 的 网络流量异常检测系统
课题背景和意义
近些年来,网络的高速发展、信息系统的规模增长以及数据的互联网络化,使得物联网、大数据等新产业快速演进,海量数据流量在网络中传输,互联网迎来了发展的黄金时期。根据互联网系统协会的不完全统计,截至2020年,全球范围内互联网用户数累计约为45.4亿,相比于2019年增长了近3亿。同时根据中国互联网信息中心第47次统计报告,截至2020年12月,我国网民数量累计约为9.89亿,相比同年3月提升了5.9个百分点。社会生活与企业的网络化、信息化,带来的是爆炸式增长的网络流量,企业以及运营商需要及时了解到网络流量的运行状态,需要在短时间内发现流量中是否包含着类似蠕虫、DDOS等恶意流量的存在,这给个人、企业、国家带来了前所未有的安全挑战。互联网流量逐年激增,尤其是2020年由于疫情的影响攻击者外出困难,更多地采取网络犯罪方式来侵犯人们财产安全,DDoS、网络钓鱼、撞库攻击等攻击方式都出现了激增,特别是最近勒索攻击快速发展,使得不少难以支付赎金的企业陷入瘫痪境地。随着信息载体类型的增加,攻击者能获得的攻击潜在入口和可利用的途径也在增加。所以实施网络监测是十分有必要的。
实现技术思路
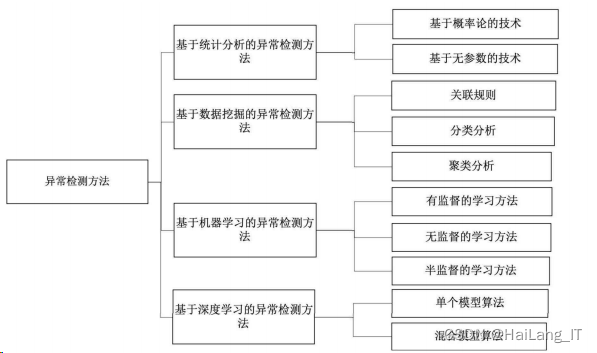
一、网络流量异常检测方法
异常检测 对于确保 网 络安全至关重要 , 但是由于网络流量的爆发式增长 ,网络环境的复杂性增加和网络流量攻击更加多变 , 面对此种情况需要特定领域知识的传统异常检测方法无法直接应对这些挑战 。
基于统计分析的异常检测方法
基于统计分析的异常检测方法是最早解决异常值问题的一种算法,它常常被用宁区分当前行为与芷常行为是否有任何形式的偏差在19世纪初就已经提出一种基于统计方法异常离群值的检测方法。这是假设正常数据符合某一种统计假定,正常数据是由一个统计模型模拟产生的,不符合这个模型分布的离群点就是异常数据。
基于数据挖掘的异常检测方法
随着近年来数据挖掘技术的大热,越来越多的研究者们对将其与异常检测场景结合产生了浓厚的兴趣。数据挖掘是从数据中获取有意义、有潜在关联的信息,并将其转化为规则、模式等形式,从而形成正常网络的行为特征,和当前用户行为进行对比,用两者的差距来对网络流量进行异常判断。
基于机器学习的异常检测方法
基于机器学习的系统与关注于理解数据产生的基于统计分析方法的系统不同,在从大数据中自学习内在规律的基础上,机器学习方法有能力根据新获得的信息来改变执行策略,从而能提高在复杂网络下的检测性能。目前传统的基于机器学习的异常检测方法分为有监督学习、无监督学习以及半监督学习三大类。
1、有监督的机器学习方法
决策树利用现有数据和标签构建决策树,如图,根据测试数据所内含的属性进行划分,并将最终结果归并到各自的类中。采用决策树和模糊粗糙集 (fuzzy rough set method) 方法选择特征,然后基于特征子集构建学习机分类器模型,分类精度达到 80.08%。

贝叶斯网络是机器学习在有监督领域常用的一种方法 , 将 分类建模 图 形化表达。它是一个由节点以及节点属性之间关系构成的有向无环图(Directed Acyclic Graph,DAG),并且包含一个表示属性特征间特定状态概率的条件概率表 Conditional Probability Table,CPT)。

2、无监督的机器学习方法
在很多异常检测的场景中,无法准确的区分正常和异常数据的区别,就无法打上标签,同时为了避免人工标记海量数据繁杂的工作,采用无监督的机器学习方法来进行异常检测。它通过数学建模,识别出相对而言较为孤立的数据点,并将其认定为异常点。
3、半监督的机器学习方法
在实际场景中,无标签的数据量常常会远超过有标签的数据量,所以基于半监督的机器学习便由此诞生。它的目标是利用大量未标记的数据来提高小数据集一监督学习的性能,该方法能同时利用带有标签和未带标签的混合数据集进行模型的训练学习,利用未带标签的数据之间所隐藏的内在分布信息来标记数据,进而获得更多的带标签的数据。
基于深度学习的异常检测方法
深度学习算法可以被看作是机器学习算法成熟的发展和数学理论复杂的进化。深度学习基于人工神经网络,是具有多层次表达的表示学习方法,不依赖于特征工程,通过组成简单却非线性的模块来获得,每个模块将原始表达抽象成更高级的表达方式。

1、卷积神经网络(CNN)
CNN 是深度学习算法在各领域中应用的成功典范之一,是神经网络的一种。 CNN 有卷积、激活、池化三种结构。卷积层中含有过滤器,这些过滤器代表输人数据的较小维度的切片,用干特征提取,池化层对特征进行操作来进行子采样,从而降低了特征的维数5。
2、循环神经网络(RNN)及长短期记忆网络(LSTM)
循环神经网络(RNN)对于序列数据建模有着强大的功能。如图是RNN的简单结构图 RNN 有很多类型,最常用的是基于长期短期记忆(LSTM)的 RNN。

RNN 是在处理时序问题是最常用模型中的一个,它相较千传统神经网络而言,它的隐藏节点的输出不仅仅只依赖于当前时间戳状态的输入,而是可以将之前时间戳的状态直接用于当前,所以它在时序数据上有着不错的表现。

RNN 的基本结构如图所示,它是一种链式结构,它的隐藏节点的计算公式为:

长短期记忆网络(LSTM)是一个递归神经网络,其结构如图 2.7。它是一种增强型 RNN。可以解决传统 RNN 中存在着的长期依赖的问题,它引人可门(gate)的概念,用门来控制信息的传输以及损失,能够控制在任意时间间隔记住有价值的信息。

LSTM 的核心部分是细胞状态,它类似于传送带,如图所示。状态信息在传送带上流通的时候不会产生梯度消失的问题,它只会有些许线性计算。细胞状态自始至终都存在,它横穿干神经元,

LSTM 单元中一共有三个门:“遗忘门”、“更新门”和“输出门”,它们可以根据输入数据每次选择必要的先前信息和新信息,保护和控制细胞状态。假设 C<t>是t时刻的细胞状态,则在t时刻,LSTM 的计算过程如下:记忆细胞更新:
![]()
更新 门:
![]()
遗忘 门 :

输出门:

记忆细胞:

3、自动编码器(AutoEncoder)
自动编码器(AutoEncoder)是一种常见的深度学习算法,属于无监督的一种。它具有低维特征表示的隐藏层,以及具有相等数量特征向量的输人和输出层。它致力于令输出尽可能匹配输入。自动编码器以编码器-解码器的方式工作,其网络是对称结构。图 2.9是自动编码器的简单结构图。编码器通过将输入转换为:

在早期传统的神经网络中,输入层的数据都是带有标签的 ,神经网络根据训练有标签数据得到的输出结果与最终训练目标之间的相差以及参数来自动改变 网 络层的参数 , 直至完全收敛 , 如图 所示:

使用多层感知器(Multi-Layer Perception,MLP)实现对原始输入和编码器输出的基本数据分级处理,但由于在实际繁杂的网络中,无标签的数据往往更容易获取和处理。后来研究者们逐渐将其演化,变为现如今的自动编码器模型(AutoEncoder),简单工作的网络原理模型如图所示。

一个完整的自动编码器至少需要三层(如图):输入层、隐藏层、输出层。自动编码器的基本目标是重建其自身的输入并学习隐藏层中输人数据的低维表示(编码)。

重构误差 的 计算方 式 如 式所示:

通过对自动编码器网络进行训练,使重建误差最小化,这个过程可以用一个损失函数 L 来表示,如式所示:

深度降噪自动编码器(DAE)是经典 AE 的改进。它在 AE 基础上,拥有更多的隐藏层来训练数据,如图所示。多层隐藏层可以令自动编码器能学习数据之间更复杂的关联模式,第一层学习原始输人的一阶特征,第二层则学习与一阶特征相对应的更高阶特征。

变分自动编码器(VAE)是经典编码器的另一种变形,它的主要目的是为了找到一个可以用于生成原始数据的训练数据的分布,通过这个分布我们可以自己构造隐藏数据来生成相似的原始数据,如图 。VAE 是一个深层的贝叶斯网络。

4、深度学习混合模型
对于异常检测而言,深度学习算法相当于一个黑盒模型,它们提供了将异常检测和判别统一到单个框架中,从而更直实的解释特定模型发现的异常。但是单一的深度学习算法有时候无法适用于复杂的数据中,所以研究者们常常会把几种算法相结合来使用检测,利用各自算法的擅长处,来从各种类型数据中学习复杂的结构和关系,以此来应对各种挑战。
二、基于LSTMs-AE的物联网流量异常检测
LSTMs-AE 物联网流量异常检测实现流程如图所示:

特征提取
特征提取模块主要针对 pcap 数据包进行特征统计计算。在物联网环境下,考虑到网络流量数据包大小数量是重要特征,且针对不同的源IP、目的IP等相关信息,帧大小在时间和空间上存在一定的分布特征.

LSTMs-AE 方法
LSTMs-AE 是一个基于 LSTM 的自动编码器变型(如图所示),是由编码器和解码器组成,但神经元替换成了 LSTM 单元,通过判断重构误差来完成对流量数据的异常检测。

三、实验
实验环境如表所示,在 PC 机上进行开发和模型训练。

在实验中使用了五个数据集(表),即 ARP MitM、Fuzzing、Mirai、SSDP Flood、 Video Iniection。

实验结果与分析
我们的模型在 ARP MitM、Fuzzing、Mirai、SSDP Flood、Video Injection这五个数据集上进行验证。实验中训练效果 loss 函数变化如图所示,我们展示的是训练5个epoch的效果,实际还分别训练了 20、30epoch的模型,选择最优的模型进行异常检测。

同时从图可以看出,loss 随着 epoch 增加而减小,最后稳定在一个值。
在实验中,选择了两种传统机器学习方法和两种深度学习方法作为基准进行对比实验。机器学习方法选择的是支持向量机(SVM)和k最近邻 kNN)。深度学习方法选择的是自动编码器(AE)和堆叠自动编码器(Stacked AE),AE是最简单的一种深度神经网络,Stacked AE是自动编码器的比较常见一种变体,现在都广泛被应用于异常检测。

图展示了 SVM、KNN、AE 和 Stacked AE 在数据集中 AUC 指标的结果。

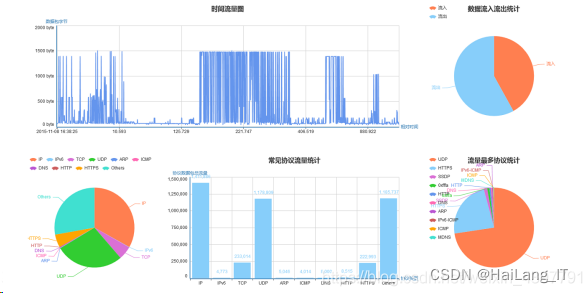
实现效果图样例
网络流量异常检测系统:
我是海浪学长,创作不易,欢迎点赞、关注、收藏、留言。
毕设帮助,疑难解答,欢迎打扰!
最后

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐



 6
6 0
0- 0



 已为社区贡献20条内容
已为社区贡献20条内容

所有评论(0)