深度学习之卷积神经网络
如果我们采用多层BP神经网络去训练1000x1000像素的图像,有1百万个隐层神经元,那么他们全连接的话,就有101210^{12}1012个连接,也就是101210^{12}1012个权值参数。这训练量是很惊人的.卷积神经网络使用权值共享网络结构,降低了网络模型的复杂度,减少了权值的数量。
前言
如果我们采用多层BP神经网络去训练1000x1000像素的图像,有1百万个隐层神经元,那么他们全连接的话,就有 1 0 12 10^{12} 1012个连接,也就是 1 0 12 10^{12} 1012个权值参数。这训练量是很惊人的.卷积神经网络使用权值共享网络结构,降低了网络模型的复杂度,减少了权值的数量。
卷积网络的“前世今生”
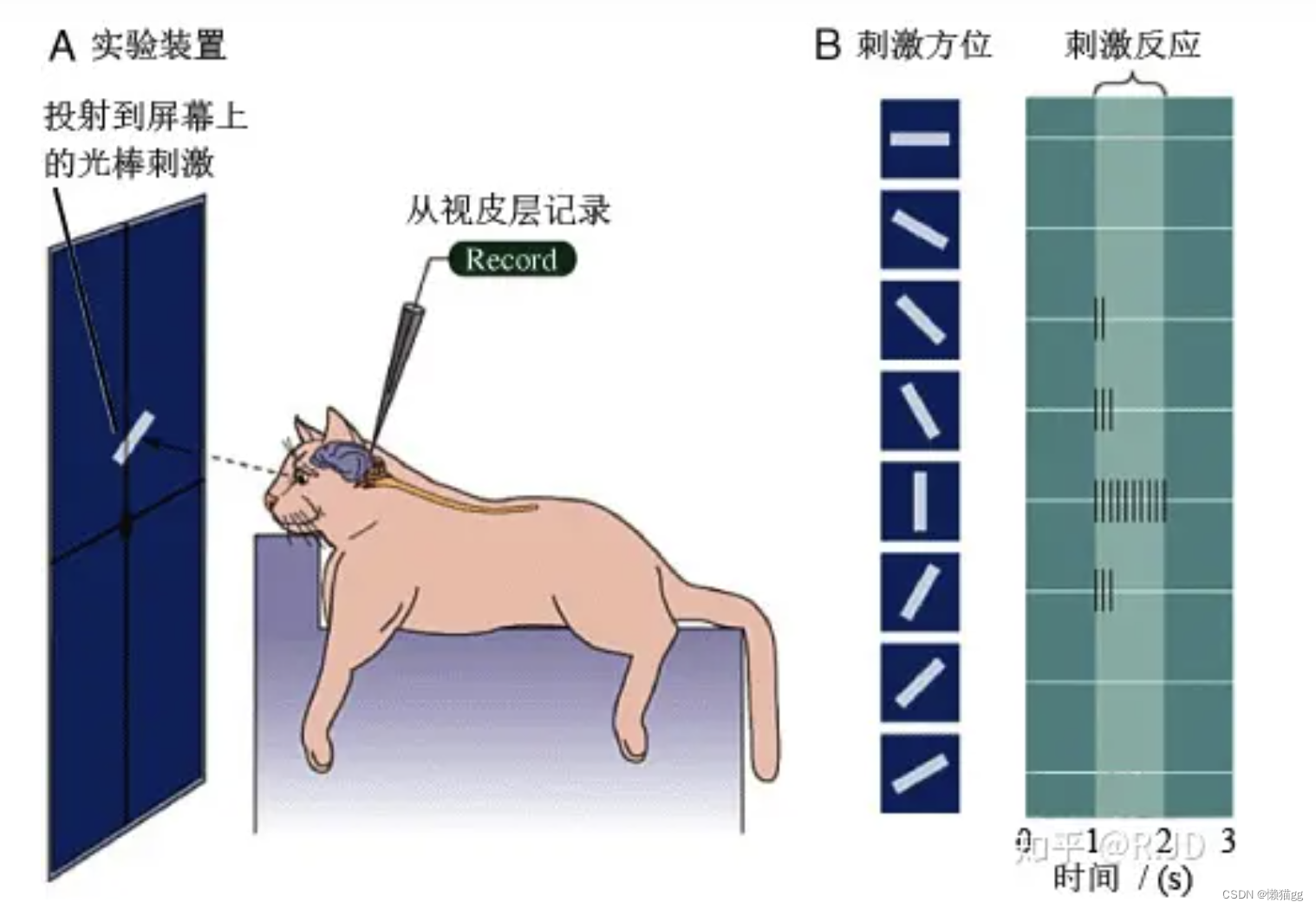
卷积网络是一个生物神经网络.其的结论来源于一只猫.

D.H.Hubel 和 T.N.Wiesel直接将示波器插入猫的视觉神经中,观察猫在看东西时的波形变化.提出了感受野(receptive field)的概念
- 猫观查图片是局部的
- 对图片有反应的神经是固定(共享权值)
卷积的数学解释
假设猫
t
t
t时刻看到局部图片产生的信号值的函数为
h
(
t
)
h(t)
h(t),图片移动的函数为
x
(
t
)
x(t)
x(t),

将它们放在同一坐标系,即卷积就是描述两个函数相互作用的结果
y
(
t
)
=
x
(
t
)
∗
h
(
t
)
y(t)=x(t)*h(t)
y(t)=x(t)∗h(t)



这是一种自适应,平移不变的 识别模式
卷积层提取特征的流程
怎么将一个55的图片提取成33的特征.

- 左上角9个像素点则是局部视野
- 左上角9个像素点中的小红字,则为共享权值
- 特征图C中的数值4,具体计算: 1 ∗ 1 + 1 ∗ 0 + 1 ∗ 1 + 0 ∗ 0 + 1 ∗ 1 + 1 ∗ 0 + 0 ∗ 1 + 0 ∗ 0 + 1 ∗ 1 = 4 1*1+1*0+1*1+0*0+1*1+1*0+0*1+0*0+1*1=4 1∗1+1∗0+1∗1+0∗0+1∗1+1∗0+0∗1+0∗0+1∗1=4

移动窗口,计算特征图中的第二个值,注:对应位置权值不变.最终得图

一个卷积的计算过程完成了,生成了一个特征图. 这个过程还有一些其他的知识点:
- 每次卷积核移动一个单位,这个距离就是步长(stride),一般来说,步长位置为1或者2即可。
- 这个卷积核的尺寸为33,也可以是55,77,1111,一般来说为单数正方形,也会有3*5这种长方形卷积核。
W
W
W值相当于filter,他的不同,可以构造出不同的特征图,多提供几个filter就可以有多几个特征.效果如下

文字识别系统LeNet-5
一种典型的用来识别数字的卷积网络是LeNet-5。当年美国大多数银行就是用它来识别支票上面的手写数字的。能够达到这种商用的地步,它的准确性可想而知。

- 输入图像是32x32的大小,局部滑动窗的大小是5x5的,由于不考虑对图像的边界进行拓展,则滑动窗将有28x28个不同的位置,也就是C1层的大小是28x28。这里设定有6个不同的C1层,每一个C1层内的权值是相同的。C1就我们的上述的卷积层
- S2层是一个下采样层。简单的说,由4个点下采样为1个点。即有6个14*14的特征图.这过程也叫Pool

- 根据对前面C1层同样的理解,我们很容易得到C3层的大小为10x10. 只不过,C3层的变成了16个10x10网络! 试想一下,如果S2层只有1个平面,那么由S2层得到C3就和由输入层得到C1层是完全一样的。但是,S2层由多层,那么,我们只需要按照一定的顺序组合这些层就可以了。具体的组合规则,在 LeNet-5 系统中给出了下面的表格:
 简单的说,例如对于C3层第0张特征图,其每一个节点与S2层的第0张特征图,第1张特征图,第2张特征图,总共3个5x5个节点相连接。后面依次类推,C3层每一张特征映射图的权值是相同的。
简单的说,例如对于C3层第0张特征图,其每一个节点与S2层的第0张特征图,第1张特征图,第2张特征图,总共3个5x5个节点相连接。后面依次类推,C3层每一张特征映射图的权值是相同的。 - S4层是一个下采样层,由16个55大小的特征图构成。特征图中的每个单元与C3中相应特征图的22邻域相连接,跟C1和S2之间的连接一样。
- C5层是一个卷积层,有120个特征图大小为1*1。S4和C5之间的采用全连接的方式。C5层有48120个可训练连接: 16 ∗ 5 ∗ 5 ∗ 120 + 120 16*5*5*120 + 120 16∗5∗5∗120+120
- F6层有84个单元(之所以选这个数字的原因来自于输出层的设计)
- 输出层由欧式径向基函数(Euclidean Radial Basis Function)单元组成,即把样本中心化,然后根据欧式距离的远近来判断出是哪个字母.
下采样中如果发现输入不能数据不规整
- 空白地方补0
- 上采样,即下采样的逆算法
卷积神经网络采用BP网络相同的学习算法,来学习对应的权值.
残差神经网络
卷积神经网络在提取图象特征上面有显著的效果,但随着卷积层的堆叠,识别准确率反而下来了.学习算法随着层数变多,梯度消失了.残差网络怎么有效缓解梯度消失问题?

图中
x
x
x表示输入,
H
(
x
)
H(x)
H(x)表示输出.
- 卷积网络如左图所示,训练的是x输入与输出的关系 H H H.
- 残差网络如右图所示,训练的是x输入与输出之差的关系 F F F
为什么残差连接的网络结构更容易学习
假设我们有如下的一个网络,它可以在训练集和测试集上可以得到很好的性能。

接着我们构造如下的网络,前面4层的参数复制于上面的网络,训练时这几层的参数保持不变。换言之,我们只是在上面的网络新增加了几个紫颜色表示的层。

相信大家预想的结果是一样的,理论上,这个新的网络在训练集或者测试集上的性能要比第一个网络的性能好,毕竟多了几个新增加的层提取特征。然后,实际上这个新的网络却比原先的网络的性能要差(梯度消失)。
理论上,由于我们copy了前四层的参数,理论上前四层已经足够满足我们的性能要求,那么新增加的层便显得有些多余,如果这个新的网络也要达到性能100%,则新增加的层要做的事情就是“恒等映射”,也即后面几个紫色的层要实现的效果为 f ( x ) = x f(x)=x f(x)=x 。这样一来,网络的性能一样能达到100%。而退化现象也表明了,实际上新增加的几个紫色的层,很难做到恒等映射.
这时候,巧妙的通过添加”桥梁“,使得难以优化的问题瞬间迎刃而解。

可以看到通过添加这个桥梁,把数据原封不动得送到FC层的前面,而对于中间的紫色层,可以很容易的通过把这些层的参数逼近于0,进而实现
f
(
x
)
=
x
f(x)=x
f(x)=x 的功能。
通过跳连接,可以把前四层的输出先送到FC层前面,也就相当于告诉紫色层:”兄弟你放心,我已经做完98%的工作了,你看看能不能在剩下的2%中发点力,你要是找不出提升性能的效果也没事的,我们可以把你的参数逼近于0,所以放心大胆的找吧。

当然了,实际上网络运行的时候,我们并不会知道哪几层就能达到很好的效果,然后在它们的后面接一个跳连接,于是一开始便在两个层或者三个层之间添加跳连接,形成残差块,每个残差块只关注当前的残余映射,而不会关注前面已经实现的底层映射
神经网络无非是拟合一个复杂的函数映射关系,而通过跳链接,可以很好的“切割”这种映射关系,实现“分步”完成。
数学定量分析
从数学定量分析的角度去看,残差网络是如何解决梯度消失的问题的

如图A,B,C,D为不同的网络模块.

梯度消失的一般原因是因为在连乘导致梯度为0,而上图在计算梯度的时候前面加一个1,可以有效避免梯度消失的问题,所以可以加深网络层之后,也可以训练的很好。
主要参考
《Deep Learning(深度学习)学习笔记整理系列之(七)》
《请简短地描述卷积(convolution)》
《从头深度学习(经典卷积网络篇)- LeNet-5》
《卷积神经网络》
《为什么残差连接的网络结构更容易学习?》
《残差神经网络为何可以缓解梯度消失?》

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 21
21 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)