毕业设计:基于机器学习的音乐流派分类算法 深度学习
毕业设计:基于机器学习的音乐流派分类算法的毕业设计项目。该算法利用Librosa工具包提取音频特征,使用支持向量机(SVM)作为分类器,实现了对音乐流派的准确分类。通过对提取的特征进行训练和预测,该算法能够将音频数据自动分类到不同的流派中。这项研究为计算机毕业设计提供了一个创新的方向。对于计算机专业、软件工程专业、人工智能专业、大数据专业的毕业生而言,提供了一个具有挑战性和创新性的研究课题。无论您
目录
前言
📅大四是整个大学期间最忙碌的时光,一边要忙着备考或实习为毕业后面临的就业升学做准备,一边要为毕业设计耗费大量精力。近几年各个学校要求的毕设项目越来越难,有不少课题是研究生级别难度的,对本科同学来说是充满挑战。为帮助大家顺利通过和节省时间与精力投入到更重要的就业和考试中去,学长分享优质的选题经验和毕设项目与技术思路。
🚀对毕设有任何疑问都可以问学长哦!
大家好,这里是海浪学长计算机毕设专题,本次分享的课题是
🎯基于机器学习的音乐流派分类算法
项目背景
为了快速且准确地根据用户的喜好推送理想流派的音乐,音乐人和研究人员借助深度学习技术进行音乐流派分类的研究。传统的音乐流派分类方法需要人工注释和专业知识,耗费人力和时间,并且准确率不稳定。而深度学习利用神经网络的大规模堆叠构建了深度学习模型,省去了设计声学特征的步骤,并在图像分类等领域取得了良好效果。因此,研究人员开始应用深度学习技术解决音乐流派分类问题,提高音乐流派分类的效果。这种方法可以更好地结合用户的喜好和需求,挖掘音乐内涵,并进行精准的音乐推广。
算法理论基础
通过创建音频数据集、提取特征信息、设计音乐流派分类算法以及系统设计和封装部署等步骤,提出了一种基于深度学习的音乐流派分类算法,并对其进行优化。该算法在解决训练数据集少、分类精度低、训练速度慢和设备算力需求大等问题方面具有一定的创新性和实用性。主要研究内容如下:
- 创建音频数据集和预处理:通过爬虫方法从音乐播放软件和短视频平台获取音频数据,并对获取的数据进行格式转换和小波阈值去噪操作。此步骤可以提高数据的一致性和质量,为后续的特征提取和模型训练提供高质量的音频数据。
- 提取特征信息:针对音乐流派分类,设计合适的方法来提取频谱特征,以最大化贴合人耳的听觉系统。对不同提取音乐特征的方法进行实验分析,选择合适的方法来提取频谱特征,这对于模型的分类性能至关重要。
- 设计音乐流派分类算法:将提取的频谱特征转换成频谱图,并以卷积神经网络为基础层,选择适合的网络模型结构进行优化。本文选择了GoogLeNet网络模型中的Inception模块,并结合BN层和残差连接对网络模型进行优化。通过正向和反向传播来更新模型权重,并训练得到最优的音乐流派分类器。
- 系统设计和封装部署:搭建音频数据预处理模块和音乐分类模块,将其组成音乐流派分类算法系统。通过使用Docker进行封装,将算法部署到服务器上,提高算法的可移植性和部署效率。
数据处理
在音乐流派分类中,数据的质量和多样性对于网络模型的训练性能至关重要。采取了一系列预处理操作和数据增强方法来优化音频数据,扩充数据集规模,提升分类模型的性能。
-
小波去噪法:引入小波去噪法对音频数据进行优化。小波去噪是一种常用的信号处理方法,可以去除音频中的噪声,提高音频数据的质量。通过对音频数据进行小波变换,并应用合适的阈值函数来滤除噪声信号,可以减少噪声对音频特征的干扰,提高分类模型的准确性。

-
数据增强:根据音频特性和图像特点,采用两个方面的数据增强方法来扩充数据集规模。数据增强是通过对原始数据进行变换和扩展,生成新的训练样本,以增加数据的多样性和丰富性。在音频领域,可以采用平移、伸缩、变速、添加噪声等方法来增加数据集的多样性,使分类模型具有更好的泛化能力。
在深度学习中,神经网络的层数对模型的训练效果有重要影响,通常情况下,层数越多,模型的表达能力越强,训练效果也更好。然而,增加网络层数会导致参数量的急剧增加,使得模型更加复杂和庞大,对于数据集的要求也更高。在音乐流派分类这个课题中,由于受限于音乐数据集的有限性和版权问题,开源的音乐数据集数量较少,部分数据还存在标签错误的问题。为了克服这些限制,采用了两个方向的数据增强方法,基于音频特性和图像特点,来扩充数据集规模并创造更多样化的数据。
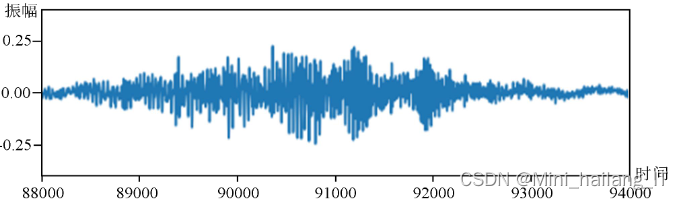
通过数据增强,可以使训练数据更加多样化,丰富模型的输入空间,提高模型的泛化能力和鲁棒性。这样可以更好地挖掘最优模型进行迭代训练,找到合适的参数值。尽管音乐数据集有限,但通过数据增强,可以使训练中的模型内容更加多样化,更有利于网络的训练和学习。
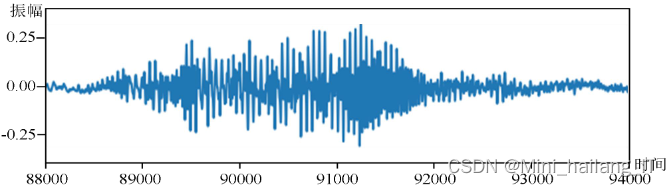
时域遮掩和频域遮掩是针对音频信号特点提出的增强方法,旨在确保增强后的音频仍符合音乐的逻辑体系,不影响原始音频的旋律。时域遮掩(Time domain masking)是对完整音频数据中的某些时间节点的信号进行覆盖,即将这些节点时刻的信号特征赋值为0。这个操作不会影响整体音乐的时序性,仍然可以判断出原音频的流派类别,只是部分信号特征会缺失。具体操作步骤如下:
- 首先,将原始音频按照一定的分帧方式进行划分,得到总长度L。
- 选择被覆盖的信号起始时间帧0L,其中0L的取值范围在[0, L-S]之间,S表示被覆盖的单位长度。
- 随机选取0L的值,最后得到被覆盖的信号特征时间帧范围为[0, 0L]和[0L+S, L]。
通过这个操作,部分时间节点的信号特征会被覆盖为0,但整体音乐的时序性仍然保持,可以继续判断音频的流派类别。
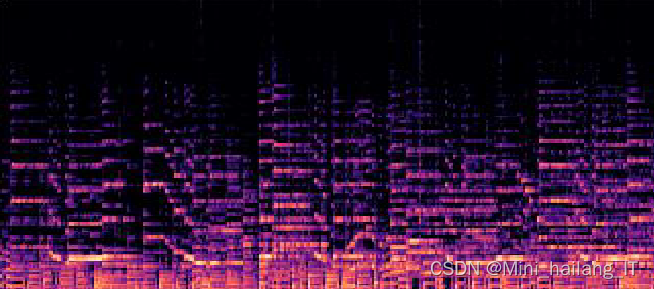
模型训练
使用Python语言编写脚本,利用Librosa工具包对音频数据进行处理和特征提取。为了确保信息的完整体现,我们选择30秒长度的音频进行转换,并生成频谱图。频谱图以二维图像的形式表示音频的三维立体信息,其中特征的颜色深浅传递了音频能量的大小。颜色越深表示在该时间和频率的汇集处音频能量越强。最后,我们将生成的频谱图作为网络的输入层,实现端到端的深度学习网络结构。

在音乐流派分类任务中,选择召回率和准确率作为评价指标。召回率衡量了模型对正样本的检测能力,即正确预测出的正样本比例;准确率则表示模型整体预测的准确性,即所有正确预测的样本比例。通过综合考虑这两个指标,可以评估模型在分类任务中的性能,追求高召回率和高准确率,以确保模型能够准确预测出大部分正样本,并保持整体预测准确性。
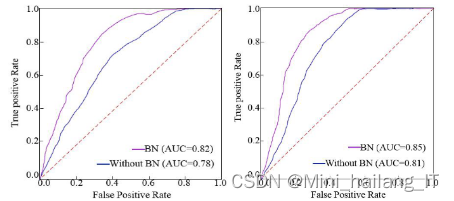
相关代码示例:
def extract_features(file_path):
audio, sr = librosa.load(file_path)
features = librosa.feature.mfcc(y=audio, sr=sr)
flattened_features = np.ravel(features)
return flattened_features
file_paths = ["path_to_audio_file1", "path_to_audio_file2", ...]
labels = ["class1", "class2", ...]
features = []
for file_path in file_paths:
feature = extract_features(file_path)
features.append(feature)
X = np.array(features)
y = np.array(labels)
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# 划分数据集为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X_scaled, y, test_size=0.2, random_state=42)
# 使用支持向量机(SVM)作为分类器
svm = SVC()
svm.fit(X_train, y_train)
# 在测试集上进行预测
y_pred = svm.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
classification_report = classification_report(y_test, y_pred)
print("Accuracy:", accuracy)
print("Classification Report:\n", classification_report)更多帮助

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐


 28
28 0
0- 0



 已为社区贡献48条内容
已为社区贡献48条内容

所有评论(0)