深度学习系列29:VQ-GAN模型
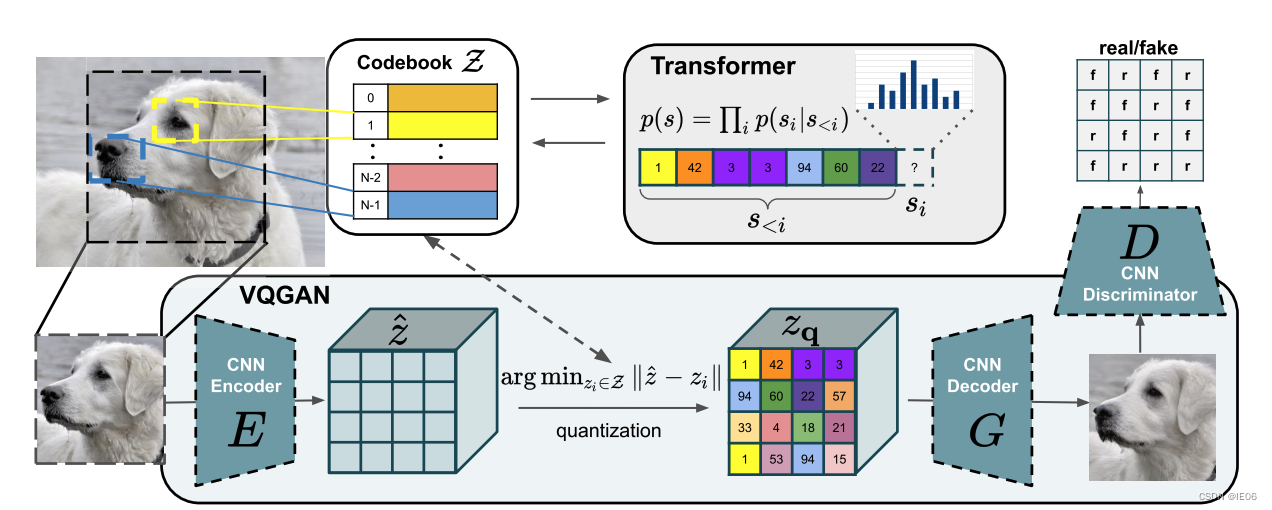
1. 介绍发表于2021年,来自德国海德堡大学IWR研究团队。最大的亮点在于其可以生成百万像素级别的图片。VQGAN的突出点在于其使用codebook来离散编码模型中间特征,并且使用Transformer(GPT-2模型)作为编码生成工具。codebook的思想在VQVAE中已经提出,而VQGAN的整体架构大致是将VQVAE的编码生成器从pixelCNN换成了Transformer,并且在训练过程
总结:
VAVAE的解码器换成Transformer再用GAN训一遍
1. 介绍
发表于2021年,来自德国海德堡大学IWR研究团队。最大的亮点在于其可以生成百万像素级别的图片。
VQGAN的突出点在于其使用codebook来离散编码模型中间特征,并且使用Transformer(GPT-2模型)作为编码生成工具。codebook的思想在VQVAE中已经提出,而VQGAN的整体架构大致是将VQVAE的编码生成器从pixelCNN换成了Transformer,并且在训练过程中使用PatchGAN的判别器加入对抗损失。
2. 详情

整理一下,输入x,通过编码器E得到z,然后离散化得到
z
q
z_q
zq,然后解码器G得到
x
^
\hat{x}
x^
训练的部分和VQ-VAE基本相同,自监督损失为:
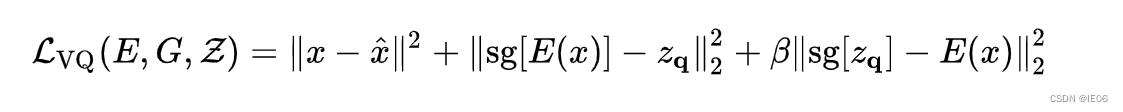
另一部分损失为GAN中的对抗loss,比如用
E
(
D
(
x
^
)
)
E(D(\hat{x}))
E(D(x^))。
对于判别器D(patch-based)而言,其损失函数可以笼统地表示为
L
G
A
N
(
{
E
,
G
,
Z
}
,
D
)
=
E
(
D
(
x
)
)
+
E
(
1
−
D
(
x
^
)
)
L_{GAN}(\{E,G,Z \},D) = E(D(x))+E(1-D(\hat{x}))
LGAN({E,G,Z},D)=E(D(x))+E(1−D(x^))
则优化目标为:
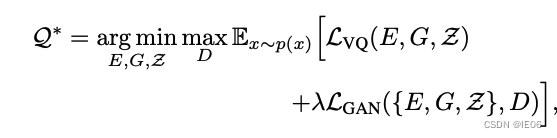
到这里,我们训练除了code book Z,cnn生成器E,和cnn解码器G
3. transformer使用
生成图片的时候,我们并没有x,因此在最终生成结果时,我们需要丢弃掉CNN生成器E,而使用transformer来生成z。我们从Z中选一个初始的code,然后用transformer一步步推出完整的code列表,然后再送入G进行解码。
训练方法是,使用当前的
z
q
∈
R
h
×
w
×
n
z
z_q\in R^{h\times w\times n_{z}}
zq∈Rh×w×nz,得到
h
w
hw
hw个维度为
n
z
n_{z}
nz的code,随机替换其中一部分code,即modified_indices,通过训练使用transformer重构出unmodified_indices。训练损失函数为cross-entropy交叉熵损失。
在VQVAE工作中,生成code这一步是使用PixelCNN来实现的。但是从效果上已经看出了,VQVAE只能生成低分辨率的64×64的图像,而在Transformer的大力支持下,VQGAN已经实现了百万像素图像的生成。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐



 6
6 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)