NLP实战:Pytorch实现7大经典深度学习中文文本分类-TextCNN+TextRNN+FastText+TextRCNN+TextRNN_Attention+DPCNN+Transformer
本文以Pytorch为框架,实现了7种经典的深度学习中文文本分类模型,包括TextCNN、TextRNN、FastText、TextRCNN、TextRNN_Attention、DPCNN和Transformer。通过这篇文章,读者可以了解到各种深度学习中文文本分类模型的实现细节和性能表现。本文不仅为学术研究者提供了参考,也为开发者和实践者提供了可复用的代码和实验指南,帮助他们在中文文本分类任务中
目录

Introduction 导言
本文以Pytorch为框架,实现了7种经典的深度学习中文文本分类模型,包括TextCNN、TextRNN、FastText、TextRCNN、TextRNN_Attention、DPCNN和Transformer。
首先,提供了详细的数据集说明,包括数据集的来源、预处理方法和划分方式。这样,读者可以了解数据集的特点和如何准备数据。
在环境搭建方面,提供了必要的依赖库和环境配置说明,帮助读者顺利运行并进行实验。
对于每个模型,我们提供了详细的说明,包括模型的结构、输入数据的格式以及模型的训练和推理过程。这些说明有助于读者理解每个模型的工作原理和实现细节。
最后,我们提供了训练和测试结果的详细报告。这些结果可以帮助读者评估各个模型在中文文本分类任务上的性能,并进行比较和分析。
通过这篇文章,读者可以了解到各种深度学习中文文本分类模型的实现细节和性能表现。本文不仅为学术研究者提供了参考,也为开发者和实践者提供了可复用的代码和实验指南,帮助他们在中文文本分类任务中取得更好的结果。
数据集
从THUCNews中抽取了20万条新闻标题,文本长度在20到30之间。一共10个类别,每类2万条。
以字为单位输入模型,使用了预训练词向量:搜狗新闻 Word+Character 300d。
类别:财经、房产、股票、教育、科技、社会、时政、体育、游戏、娱乐。
数据集、词表及对应的预训练词向量,已经打包好,详见下面Github地址中THUCNews文件夹。

Python环境及安装相应依赖包
- python 3.7以上
- pytorch 1.1 以上
- tqdm
- sklearn
- tensorboardX
Anaconda环境配置
-
登录Anaconda官网,下载并安装Anaconda
-
接着打开终端,依次输入下面终端命令:
新建环境:chinese_text_classification
conda create --name chinese_text_classification python==3.8.10
激活环境:
conda activate chinese_text_classification
依次输入下面命令安装相关python包
conda install pytorch
conda install scikit-learn
conda install tqdm
conda install tensorboardX
注意上述安装的pytorch默认是CPU版本的。如果要安装GPU版本的pytorch,可以参考下面步骤。
首先,确保你已经正确安装了NVIDIA显卡驱动程序,并且你的显卡支持CUDA。可以在NVIDIA官方网站上查找相应的驱动程序和CUDA兼容性信息。
在Python环境中安装PyTorch之前,你需要安装适用于你的CUDA版本的CUDAToolkit。可以通过NVIDIA的开发者网站下载并安装适合你的CUDA版本的CUDAToolkit。
完成上面步骤后,你可以使用下面命令,来查看你的GPU相关版本。
nvcc --version

如果没有上述版本的话,需要检查下是否安装好了CUDA 与 CUDAToolkit。
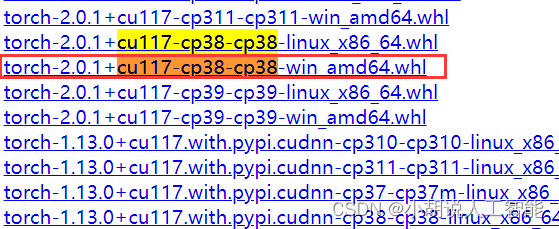
接着,可以在pytorch的下载网站上下载相应版本的whl进行安装,因为一般gpu版本的pytorch文件都很大,不太建议直接使用pip安装。比如下面就是直接使用pip安装gpu版本的pytorch命令,需要花费大概13个小时:
pip3 install torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cu117

可以直接用浏览器打开上图中出现的下载网站:https://download.pytorch.org/whl/cu117 然后选择torch 接着搜索上图中的关键词cu117-cp38-cp38-win_amd64.whl。点击即可下载。一般网速快的话,大概10余分钟就可以下载成功。
下载成功后,就可以直接使用下面命令进行安装:
pip install <path/to/your/whl/file.whl>
请将<path/to/your/whl/file.whl>替换为实际的.wl文件路径(例如:pip install /path/to/your/file.whl)
源代码地址
Github地址:https://github.com/649453932/Chinese-Text-Classification-Pytorch
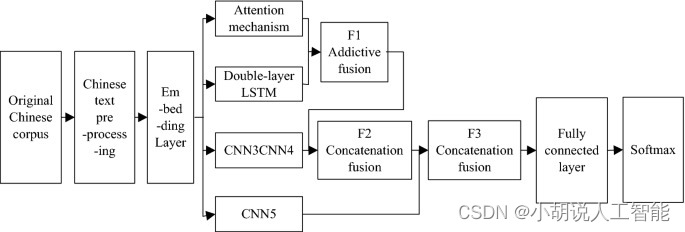
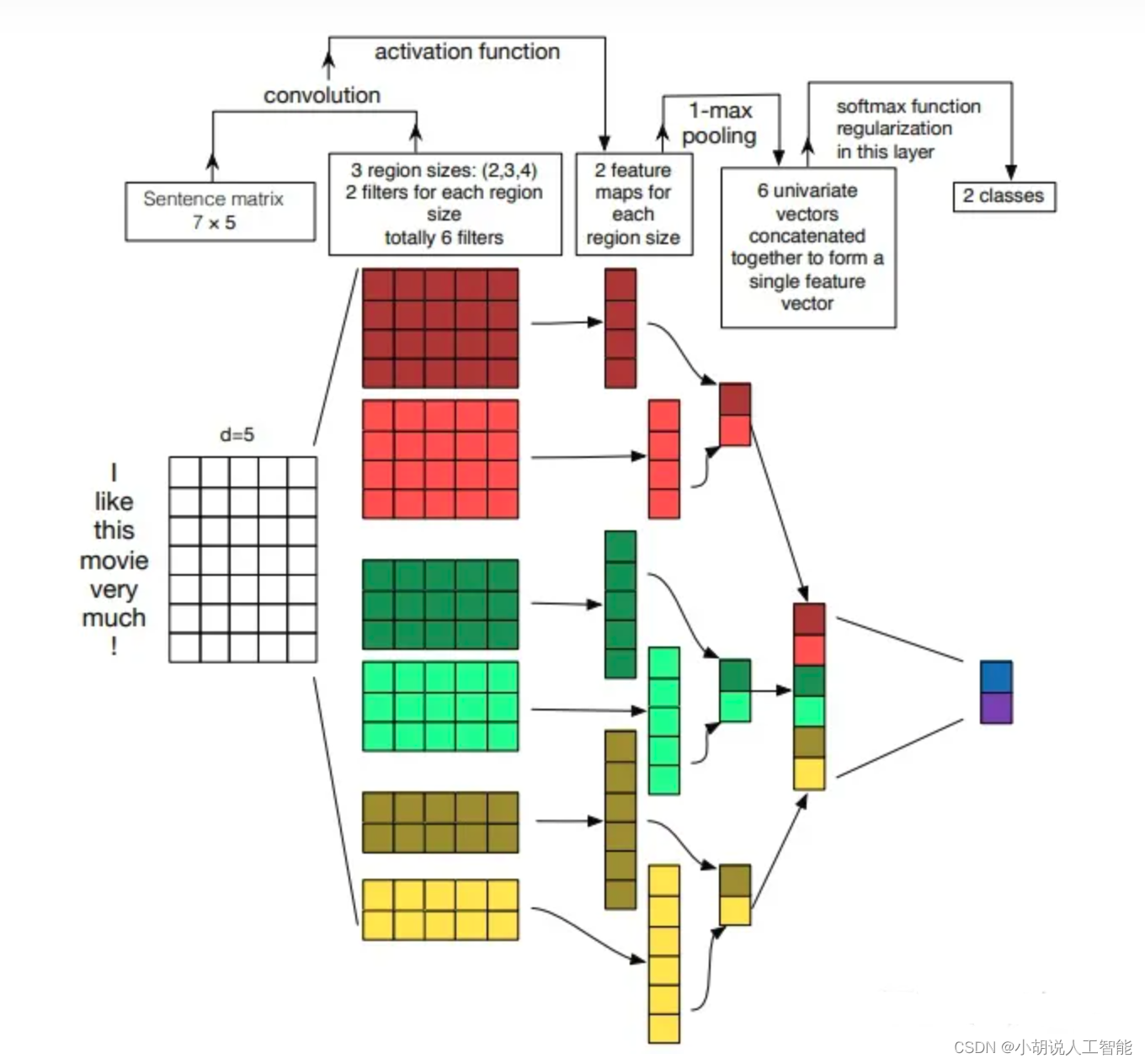
TextCNN
模型说明
1.模型输入:[batch_size, seq_len]
2.经过embedding层:加载预训练词向量或者随机初始化, 词向量维度为embed_size:Embedding (4762, 300)
3.卷积层:
(0): Conv2d (1, 256, kernel_size=(2, 300), stride=(1,1))
(1): Conv2d (1, 256,kerne1_size=(3, 300) ,stride=(1, 1))
(2): Conv2d (1, 256, kernel_size=(4, 300), stride=(1, 1))
4. dropout层:Dropout (p=0. 5, inplace=False)
5. 全连接:Linear (in_features=768, out_features=10, bias=True)
分析:
卷积操作相当于提取了句中的2-gram,3-gram,4-gram信息,多个卷积是为了提取多种特征,最大池化将提取到最重要的信息保留。
原理图如下:
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
class Config(object):
"""配置参数"""
def __init__(self, dataset, embedding):
self.model_name = 'TextCNN'
self.train_path = dataset + '/data/train.txt' # 训练集
self.dev_path = dataset + '/data/dev.txt' # 验证集
self.test_path = dataset + '/data/test.txt' # 测试集
self.class_list = [x.strip() for x in open(
dataset + '/data/class.txt', encoding='utf-8').readlines()] # 类别名单
self.vocab_path = dataset + '/data/vocab.pkl' # 词表
self.save_path = dataset + '/saved_dict/' + self.model_name + '.ckpt' # 模型训练结果
self.log_path = dataset + '/log/' + self.model_name
self.embedding_pretrained = torch.tensor(
np.load(dataset + '/data/' + embedding)["embeddings"].astype('float32'))\
if embedding != 'random' else None # 预训练词向量
self.device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') # 设备
self.dropout = 0.5 # 随机失活
self.require_improvement = 1000 # 若超过1000batch效果还没提升,则提前结束训练
self.num_classes = len(self.class_list) # 类别数
self.n_vocab = 0 # 词表大小,在运行时赋值
self.num_epochs = 20 # epoch数
self.batch_size = 128 # mini-batch大小
self.pad_size = 32 # 每句话处理成的长度(短填长切)
self.learning_rate = 1e-3 # 学习率
self.embed = self.embedding_pretrained.size(1)\
if self.embedding_pretrained is not None else 300 # 字向量维度
self.filter_sizes = (2, 3, 4) # 卷积核尺寸
self.num_filters = 256 # 卷积核数量(channels数)
'''Convolutional Neural Networks for Sentence Classification'''
class Model(nn.Module):
def __init__(self, config):
super(Model, self).__init__()
if config.embedding_pretrained is not None:
self.embedding = nn.Embedding.from_pretrained(config.embedding_pretrained, freeze=False)
else:
self.embedding = nn.Embedding(config.n_vocab, config.embed, padding_idx=config.n_vocab - 1)
self.convs = nn.ModuleList(
[nn.Conv2d(1, config.num_filters, (k, config.embed)) for k in config.filter_sizes])
self.dropout = nn.Dropout(config.dropout)
self.fc = nn.Linear(config.num_filters * len(config.filter_sizes), config.num_classes)
def conv_and_pool(self, x, conv):
x = F.relu(conv(x)).squeeze(3)
x = F.max_pool1d(x, x.size(2)).squeeze(2)
return x
def forward(self, x):
out = self.embedding(x[0])
out = out.unsqueeze(1)
out = torch.cat([self.conv_and_pool(out, conv) for conv in self.convs], 1)
out = self.dropout(out)
out = self.fc(out)
return out
终端运行下面命令,进行训练和测试:
python run.py --model TextCNN
训练过程如下:
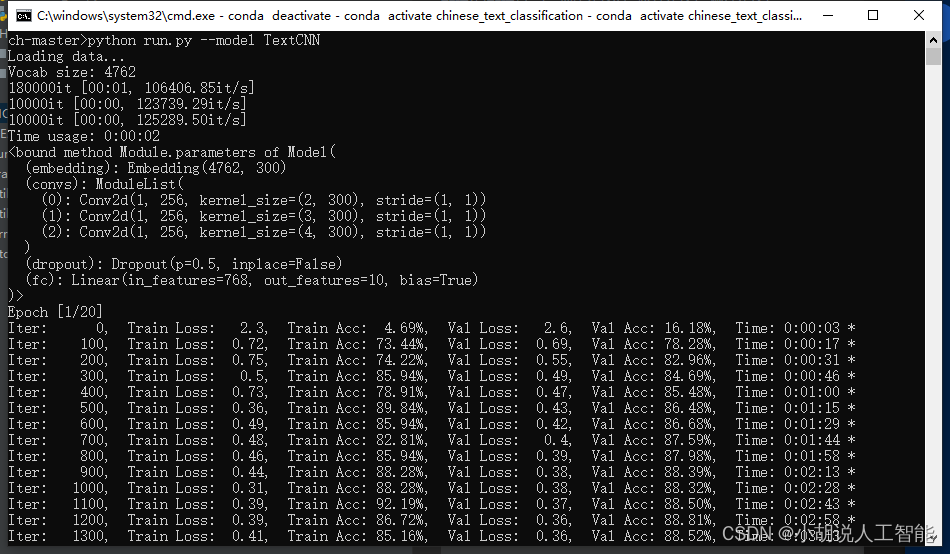
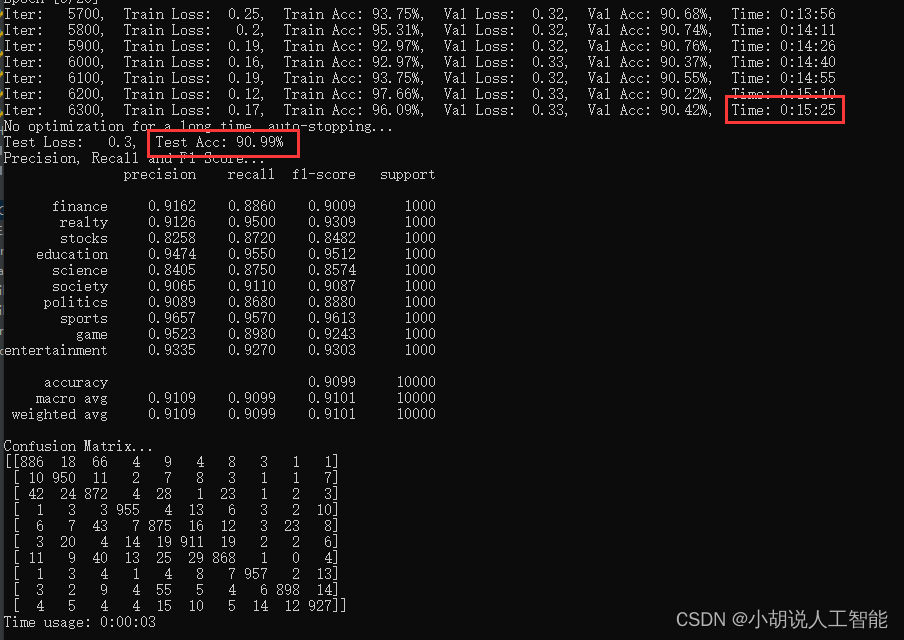
训练及测试结果如下:
使用CPU版本pytorch,耗时15分25秒,准确率90.99%
TextRNN
模型说明
1.模型输入:[batch_size, seq_len]
2.经过embedding层:加载预训练词向量或者随机初始化, 词向量维度为embed_size:Embedding (4762, 300)
3.双向LSTM:(lstm) : LSTM(300, 128, num_layers=2, batch_first=True, dropout=0.5, bidirectional=True)
4. 全连接:Linear (in_features=256, out_features=10, bias=True)
分析:
LSTM能更好的捕捉长距离语义关系,但是由于其递归结构,不能并行计算,速度慢。
原理图如下:
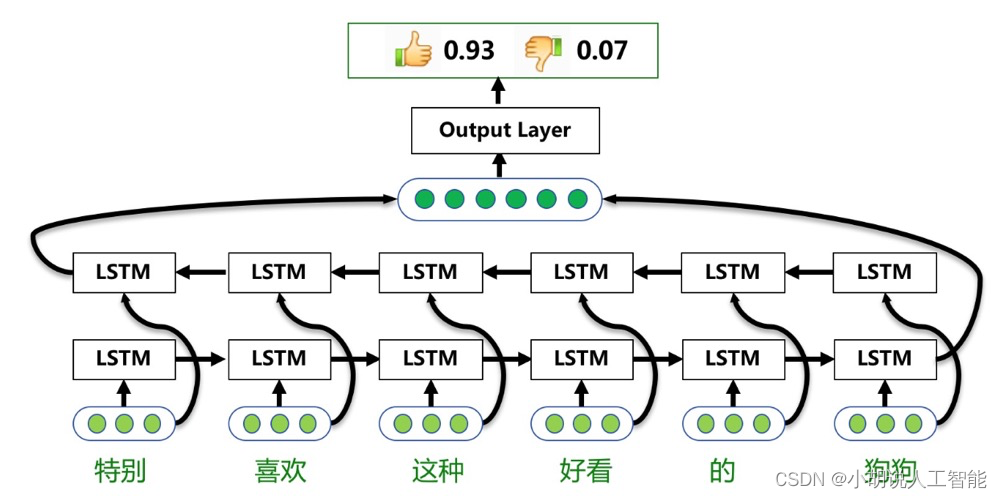
# coding: UTF-8
import torch
import torch.nn as nn
import numpy as np
class Config(object):
"""配置参数"""
def __init__(self, dataset, embedding):
self.model_name = 'TextRNN'
self.train_path = dataset + '/data/train.txt' # 训练集
self.dev_path = dataset + '/data/dev.txt' # 验证集
self.test_path = dataset + '/data/test.txt' # 测试集
self.class_list = [x.strip() for x in open(
dataset + '/data/class.txt', encoding='utf-8').readlines()] # 类别名单
self.vocab_path = dataset + '/data/vocab.pkl' # 词表
self.save_path = dataset + '/saved_dict/' + self.model_name + '.ckpt' # 模型训练结果
self.log_path = dataset + '/log/' + self.model_name
self.embedding_pretrained = torch.tensor(
np.load(dataset + '/data/' + embedding)["embeddings"].astype('float32'))\
if embedding != 'random' else None # 预训练词向量
self.device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') # 设备
self.dropout = 0.5 # 随机失活
self.require_improvement = 1000 # 若超过1000batch效果还没提升,则提前结束训练
self.num_classes = len(self.class_list) # 类别数
self.n_vocab = 0 # 词表大小,在运行时赋值
self.num_epochs = 10 # epoch数
self.batch_size = 128 # mini-batch大小
self.pad_size = 32 # 每句话处理成的长度(短填长切)
self.learning_rate = 1e-3 # 学习率
self.embed = self.embedding_pretrained.size(1)\
if self.embedding_pretrained is not None else 300 # 字向量维度, 若使用了预训练词向量,则维度统一
self.hidden_size = 128 # lstm隐藏层
self.num_layers = 2 # lstm层数
'''Recurrent Neural Network for Text Classification with Multi-Task Learning'''
class Model(nn.Module):
def __init__(self, config):
super(Model, self).__init__()
if config.embedding_pretrained is not None:
self.embedding = nn.Embedding.from_pretrained(config.embedding_pretrained, freeze=False)
else:
self.embedding = nn.Embedding(config.n_vocab, config.embed, padding_idx=config.n_vocab - 1)
self.lstm = nn.LSTM(config.embed, config.hidden_size, config.num_layers,
bidirectional=True, batch_first=True, dropout=config.dropout)
self.fc = nn.Linear(config.hidden_size * 2, config.num_classes)
def forward(self, x):
x, _ = x
out = self.embedding(x) # [batch_size, seq_len, embeding]=[128, 32, 300]
out, _ = self.lstm(out)
out = self.fc(out[:, -1, :]) # 句子最后时刻的 hidden state
return out
'''变长RNN,效果差不多,甚至还低了点...'''
# def forward(self, x):
# x, seq_len = x
# out = self.embedding(x)
# _, idx_sort = torch.sort(seq_len, dim=0, descending=True) # 长度从长到短排序(index)
# _, idx_unsort = torch.sort(idx_sort) # 排序后,原序列的 index
# out = torch.index_select(out, 0, idx_sort)
# seq_len = list(seq_len[idx_sort])
# out = nn.utils.rnn.pack_padded_sequence(out, seq_len, batch_first=True)
# # [batche_size, seq_len, num_directions * hidden_size]
# out, (hn, _) = self.lstm(out)
# out = torch.cat((hn[2], hn[3]), -1)
# # out, _ = nn.utils.rnn.pad_packed_sequence(out, batch_first=True)
# out = out.index_select(0, idx_unsort)
# out = self.fc(out)
# return out
终端运行下面命令,进行训练和测试:
python run.py --model TextRNN
训练过程如下:
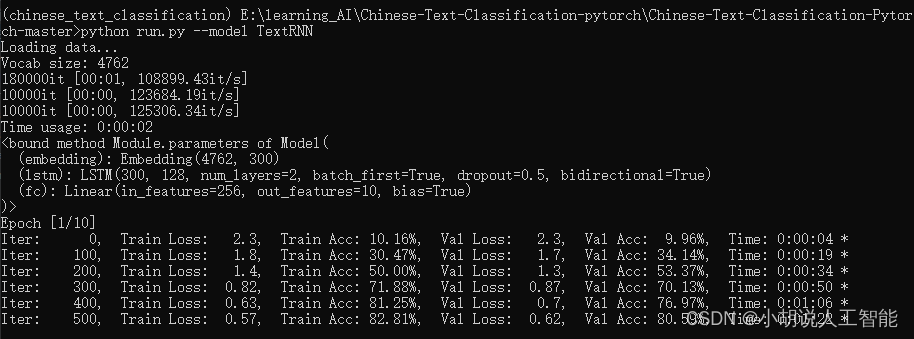
训练及测试结果如下:
使用CPU版本pytorch,耗时18分54秒,准确率90.90%
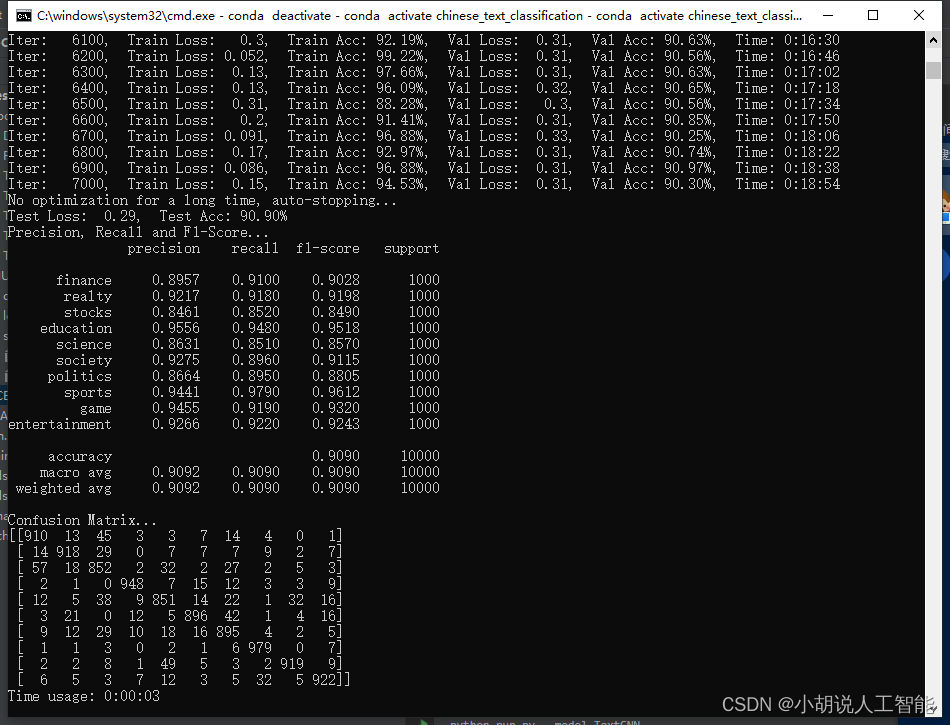
TextRNN_Att
模型说明
1.模型输入: [batch_size, seq_len]
2.经过embedding层:加载预训练词向量或者随机初始化, 词向量维度为embed_size: [batch_size, seq_len, embed_size]
3.双向LSTM:隐层大小为hidden_size,得到所有时刻的隐层状态(前向隐层和后向隐层拼接) [batch_size, seq_len, hidden_size * 2]
4.初始化一个可学习的权重矩阵w
w=[hidden_size * 2, 1]
5.对LSTM的输出进行非线性激活后与w进行矩阵相乘,并经行softmax归一化,得到每时刻的分值:
[batch_size, seq_len, 1]
6.将LSTM的每一时刻的隐层状态乘对应的分值后求和,得到加权平均后的终极隐层值
[batch_size, hidden_size * 2]
7.对终极隐层值进行非线性激活后送入两个连续的全连接层
[batch_size, num_class]
8.预测:softmax归一化,将num_class个数中最大的数对应的类作为最终预测
[batch_size, 1]
分析:
其中4~6步是attention机制计算过程,其实就是对lstm每刻的隐层进行加权平均。比如句长为4,首先算出4个时刻的归一化分值:[0.1, 0.3, 0.4, 0.2],然后
h 终极 = 0.1 h 1 + 0.3 h 2 + 0.4 h 3 + 0.2 h 4 h_{\text {终极}}=0.1 h_1+0.3 h_2+0.4 h_3+0.2 h_4 h终极=0.1h1+0.3h2+0.4h3+0.2h4
原理图如下:
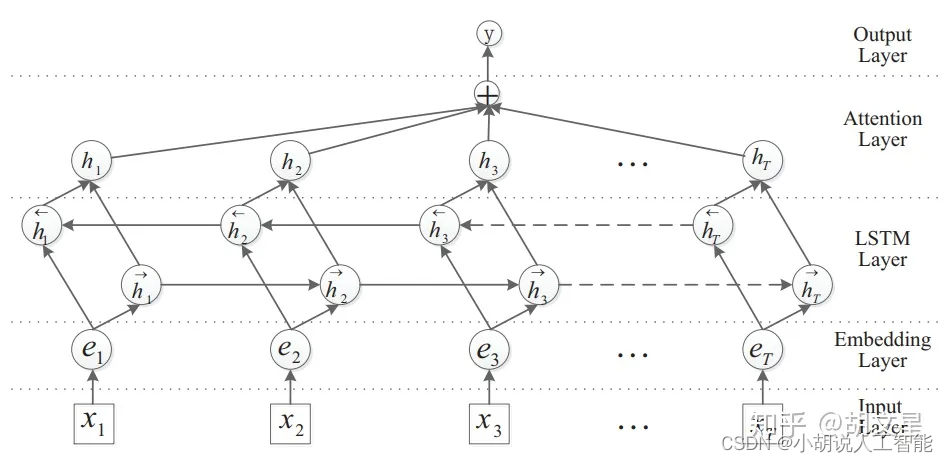
# coding: UTF-8
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
class Config(object):
"""配置参数"""
def __init__(self, dataset, embedding):
self.model_name = 'TextRNN_Att'
self.train_path = dataset + '/data/train.txt' # 训练集
self.dev_path = dataset + '/data/dev.txt' # 验证集
self.test_path = dataset + '/data/test.txt' # 测试集
self.class_list = [x.strip() for x in open(
dataset + '/data/class.txt', encoding='utf-8').readlines()] # 类别名单
self.vocab_path = dataset + '/data/vocab.pkl' # 词表
self.save_path = dataset + '/saved_dict/' + self.model_name + '.ckpt' # 模型训练结果
self.log_path = dataset + '/log/' + self.model_name
self.embedding_pretrained = torch.tensor(
np.load(dataset + '/data/' + embedding)["embeddings"].astype('float32'))\
if embedding != 'random' else None # 预训练词向量
self.device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') # 设备
self.dropout = 0.5 # 随机失活
self.require_improvement = 1000 # 若超过1000batch效果还没提升,则提前结束训练
self.num_classes = len(self.class_list) # 类别数
self.n_vocab = 0 # 词表大小,在运行时赋值
self.num_epochs = 10 # epoch数
self.batch_size = 128 # mini-batch大小
self.pad_size = 32 # 每句话处理成的长度(短填长切)
self.learning_rate = 1e-3 # 学习率
self.embed = self.embedding_pretrained.size(1)\
if self.embedding_pretrained is not None else 300 # 字向量维度, 若使用了预训练词向量,则维度统一
self.hidden_size = 128 # lstm隐藏层
self.num_layers = 2 # lstm层数
self.hidden_size2 = 64
'''Attention-Based Bidirectional Long Short-Term Memory Networks for Relation Classification'''
class Model(nn.Module):
def __init__(self, config):
super(Model, self).__init__()
if config.embedding_pretrained is not None:
self.embedding = nn.Embedding.from_pretrained(config.embedding_pretrained, freeze=False)
else:
self.embedding = nn.Embedding(config.n_vocab, config.embed, padding_idx=config.n_vocab - 1)
self.lstm = nn.LSTM(config.embed, config.hidden_size, config.num_layers,
bidirectional=True, batch_first=True, dropout=config.dropout)
self.tanh1 = nn.Tanh()
# self.u = nn.Parameter(torch.Tensor(config.hidden_size * 2, config.hidden_size * 2))
self.w = nn.Parameter(torch.zeros(config.hidden_size * 2))
self.tanh2 = nn.Tanh()
self.fc1 = nn.Linear(config.hidden_size * 2, config.hidden_size2)
self.fc = nn.Linear(config.hidden_size2, config.num_classes)
def forward(self, x):
x, _ = x
emb = self.embedding(x) # [batch_size, seq_len, embeding]=[128, 32, 300]
H, _ = self.lstm(emb) # [batch_size, seq_len, hidden_size * num_direction]=[128, 32, 256]
M = self.tanh1(H) # [128, 32, 256]
# M = torch.tanh(torch.matmul(H, self.u))
alpha = F.softmax(torch.matmul(M, self.w), dim=1).unsqueeze(-1) # [128, 32, 1]
out = H * alpha # [128, 32, 256]
out = torch.sum(out, 1) # [128, 256]
out = F.relu(out)
out = self.fc1(out)
out = self.fc(out) # [128, 64]
return out
终端运行下面命令,进行训练和测试:
python run.py --model TextRNN_Att
训练过程如下:
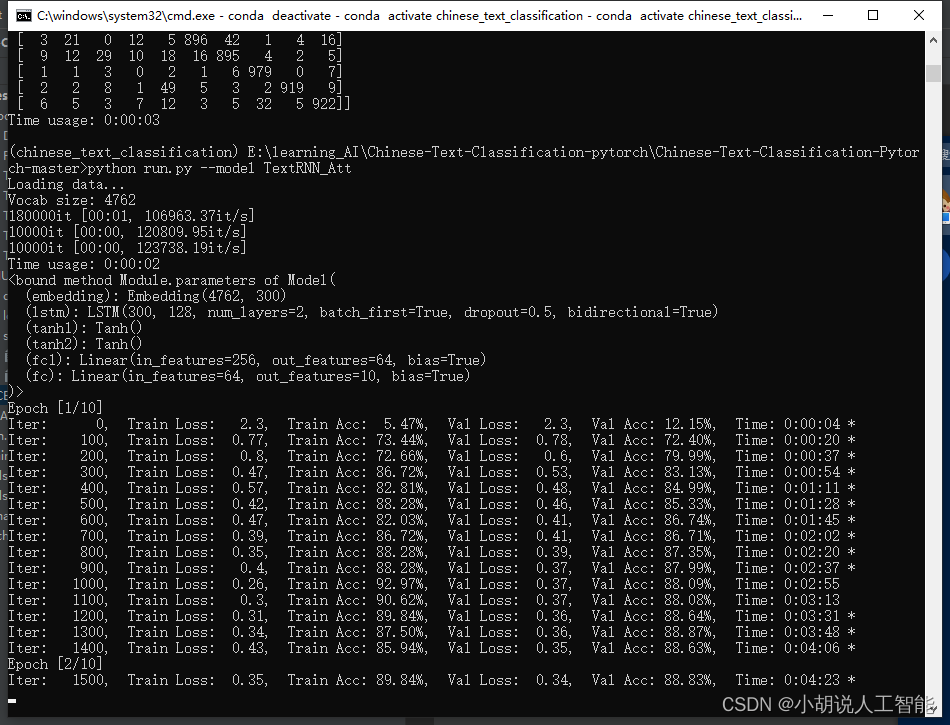
训练及测试结果如下:
使用CPU版本pytorch,耗时10分48秒,准确率89.89%
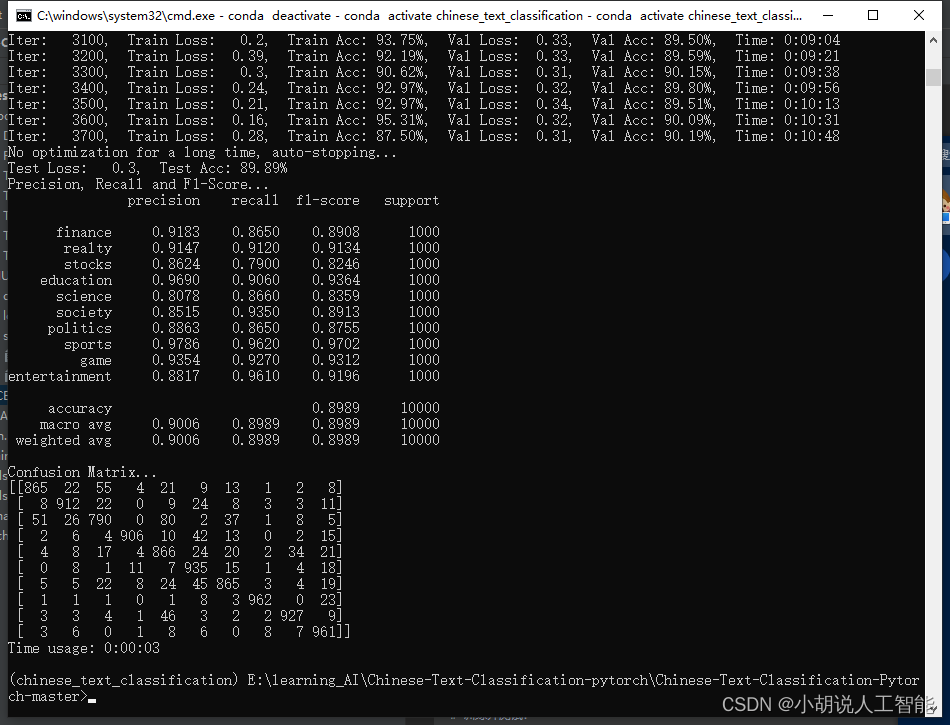
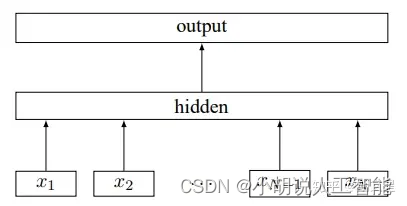
FastText
模型说明
1.模型输入: [batch_size, seq_len]
2.embedding层:随机初始化, 词向量维度为embed_size,2-gram和3-gram同理:
word: [batch_size, seq_len, embed_size]
2-gram:[batch_size, seq_len, embed_size]
3-gram:[batch_size, seq_len, embed_size]
3.拼接embedding层:
[batch_size, seq_len, embed_size * 3]
4.求所有seq_len个词的均值
[batch_size, embed_size * 3]
5.全连接+非线性激活:隐层大小hidden_size
[batch_size, hidden_size]
6.全连接+softmax归一化:
[batch_size, num_class]==>[batch_size, 1]
原理图如下:
# coding: UTF-8
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
class Config(object):
"""配置参数"""
def __init__(self, dataset, embedding):
self.model_name = 'FastText'
self.train_path = dataset + '/data/train.txt' # 训练集
self.dev_path = dataset + '/data/dev.txt' # 验证集
self.test_path = dataset + '/data/test.txt' # 测试集
self.class_list = [x.strip() for x in open(
dataset + '/data/class.txt', encoding='utf-8').readlines()] # 类别名单
self.vocab_path = dataset + '/data/vocab.pkl' # 词表
self.save_path = dataset + '/saved_dict/' + self.model_name + '.ckpt' # 模型训练结果
self.log_path = dataset + '/log/' + self.model_name
self.embedding_pretrained = torch.tensor(
np.load(dataset + '/data/' + embedding)["embeddings"].astype('float32'))\
if embedding != 'random' else None # 预训练词向量
self.device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') # 设备
self.dropout = 0.5 # 随机失活
self.require_improvement = 1000 # 若超过1000batch效果还没提升,则提前结束训练
self.num_classes = len(self.class_list) # 类别数
self.n_vocab = 0 # 词表大小,在运行时赋值
self.num_epochs = 20 # epoch数
self.batch_size = 128 # mini-batch大小
self.pad_size = 32 # 每句话处理成的长度(短填长切)
self.learning_rate = 1e-3 # 学习率
self.embed = self.embedding_pretrained.size(1)\
if self.embedding_pretrained is not None else 300 # 字向量维度
self.hidden_size = 256 # 隐藏层大小
self.n_gram_vocab = 250499 # ngram 词表大小
'''Bag of Tricks for Efficient Text Classification'''
class Model(nn.Module):
def __init__(self, config):
super(Model, self).__init__()
if config.embedding_pretrained is not None:
self.embedding = nn.Embedding.from_pretrained(config.embedding_pretrained, freeze=False)
else:
self.embedding = nn.Embedding(config.n_vocab, config.embed, padding_idx=config.n_vocab - 1)
self.embedding_ngram2 = nn.Embedding(config.n_gram_vocab, config.embed)
self.embedding_ngram3 = nn.Embedding(config.n_gram_vocab, config.embed)
self.dropout = nn.Dropout(config.dropout)
self.fc1 = nn.Linear(config.embed * 3, config.hidden_size)
# self.dropout2 = nn.Dropout(config.dropout)
self.fc2 = nn.Linear(config.hidden_size, config.num_classes)
def forward(self, x):
out_word = self.embedding(x[0])
out_bigram = self.embedding_ngram2(x[2])
out_trigram = self.embedding_ngram3(x[3])
out = torch.cat((out_word, out_bigram, out_trigram), -1)
out = out.mean(dim=1)
out = self.dropout(out)
out = self.fc1(out)
out = F.relu(out)
out = self.fc2(out)
return out
终端运行下面命令,进行训练和测试:
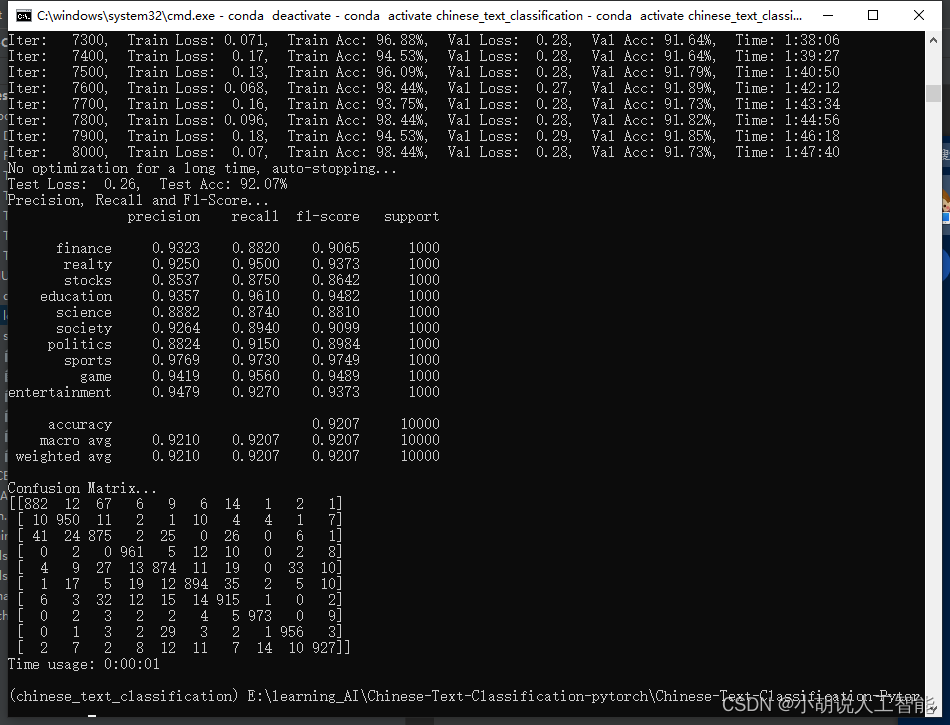
python run.py --model FastText
训练过程如下:

训练及测试结果如下:
使用CPU版本pytorch,耗时1小时47分40秒,准确率92.07%
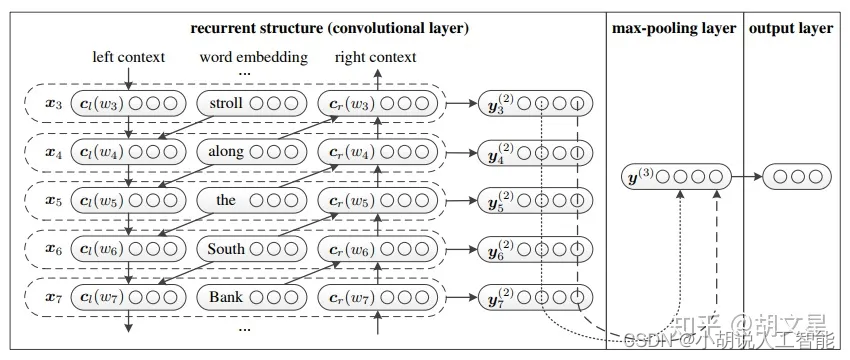
TextRCNN
模型说明
1.模型输入: [batch_size, seq_len]
2.经过embedding层:加载预训练词向量或者随机初始化, 词向量维度为embed_size: [batch_size, seq_len, embed_size]
3.双向LSTM:隐层大小为hidden_size,得到所有时刻的隐层状态(前向隐层和后向隐层拼接) [batch_size, seq_len, hidden_size * 2]
4.将embedding层与LSTM输出拼接,并进行非线性激活:
[batch_size, seq_len, hidden_size * 2 + embed_size]
5.池化层:seq_len个特征中取最大的
[batch_size, hidden_size * 2 + embed_size]
6.全连接后softmax
[batch_size, num_class] ==> [batch_size, 1]
分析:
双向LSTM每一时刻的隐层值(前向+后向)都可以表示当前词的前向和后向语义信息,将隐藏值与embedding值拼接来表示一个词;然后用最大池化层来筛选出有用的特征信息。
原理图如下:
# coding: UTF-8
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
class Config(object):
"""配置参数"""
def __init__(self, dataset, embedding):
self.model_name = 'TextRCNN'
self.train_path = dataset + '/data/train.txt' # 训练集
self.dev_path = dataset + '/data/dev.txt' # 验证集
self.test_path = dataset + '/data/test.txt' # 测试集
self.class_list = [x.strip() for x in open(
dataset + '/data/class.txt', encoding='utf-8').readlines()] # 类别名单
self.vocab_path = dataset + '/data/vocab.pkl' # 词表
self.save_path = dataset + '/saved_dict/' + self.model_name + '.ckpt' # 模型训练结果
self.log_path = dataset + '/log/' + self.model_name
self.embedding_pretrained = torch.tensor(
np.load(dataset + '/data/' + embedding)["embeddings"].astype('float32'))\
if embedding != 'random' else None # 预训练词向量
self.device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') # 设备
self.dropout = 1.0 # 随机失活
self.require_improvement = 1000 # 若超过1000batch效果还没提升,则提前结束训练
self.num_classes = len(self.class_list) # 类别数
self.n_vocab = 0 # 词表大小,在运行时赋值
self.num_epochs = 10 # epoch数
self.batch_size = 128 # mini-batch大小
self.pad_size = 32 # 每句话处理成的长度(短填长切)
self.learning_rate = 1e-3 # 学习率
self.embed = self.embedding_pretrained.size(1)\
if self.embedding_pretrained is not None else 300 # 字向量维度, 若使用了预训练词向量,则维度统一
self.hidden_size = 256 # lstm隐藏层
self.num_layers = 1 # lstm层数
'''Recurrent Convolutional Neural Networks for Text Classification'''
class Model(nn.Module):
def __init__(self, config):
super(Model, self).__init__()
if config.embedding_pretrained is not None:
self.embedding = nn.Embedding.from_pretrained(config.embedding_pretrained, freeze=False)
else:
self.embedding = nn.Embedding(config.n_vocab, config.embed, padding_idx=config.n_vocab - 1)
self.lstm = nn.LSTM(config.embed, config.hidden_size, config.num_layers,
bidirectional=True, batch_first=True, dropout=config.dropout)
self.maxpool = nn.MaxPool1d(config.pad_size)
self.fc = nn.Linear(config.hidden_size * 2 + config.embed, config.num_classes)
def forward(self, x):
x, _ = x
embed = self.embedding(x) # [batch_size, seq_len, embeding]=[64, 32, 64]
out, _ = self.lstm(embed)
out = torch.cat((embed, out), 2)
out = F.relu(out)
out = out.permute(0, 2, 1)
out = self.maxpool(out).squeeze()
out = self.fc(out)
return out
终端运行下面命令,进行训练和测试:
python run.py --model TextRCNN
训练过程如下:
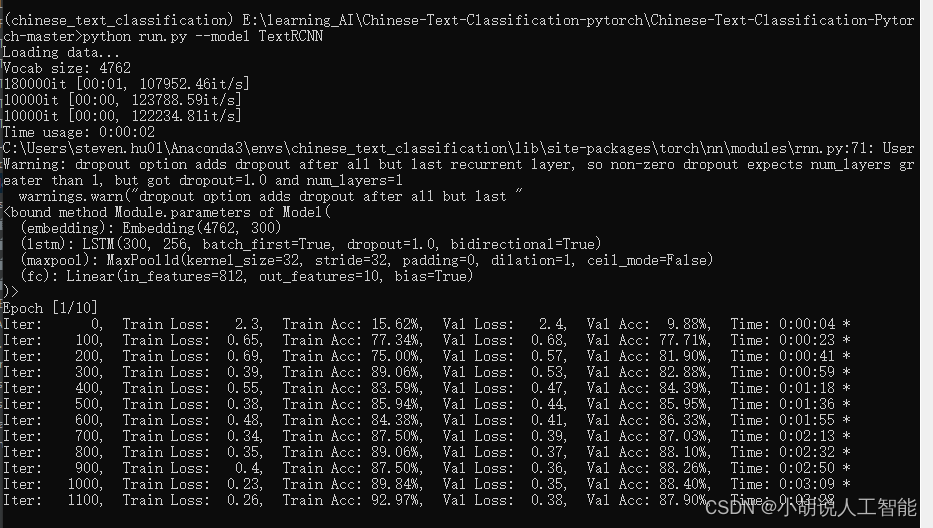
训练及测试结果如下:
使用CPU版本pytorch,耗时10分23秒,准确率90.83%
DPCNN
模型说明
1.模型输入: [batch_size, seq_len]
2.经过embedding层:加载预训练词向量或者随机初始化, 词向量维度为embed_size: [batch_size, seq_len, embed_size]
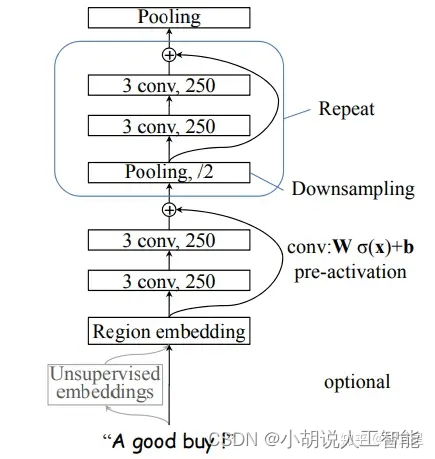
3.进行卷积,250个尺寸为3的卷积核,论文中称这层为region embedding。
[batch_size, 250, seq_len - 3 + 1]
4.接两层卷积(+relu),每层都是250个尺寸为3的卷积核,(等长卷积,先padding再卷积,保证卷积前后的序列长度不变)
[batch_size, 250, seq_len - 3 + 1]
5.接下来进行上图中小框中的操作。
I. 进行 大小为3,步长为2的最大池化,将序列长度压缩为原来的二分之一。(进行采样)
II. 接两层等长卷积(+relu),每层都是250个尺寸为3的卷积核。
III. I的结果加上II的结果。(残差连接)
重复以上操作,直至序列长度等于1。
[batch_size, 250, 1]
6.全连接+softmax归一化:
[batch_size, num_class]==>[batch_size, 1]
分析:
TextCNN的过程类似于提取N-Gram信息,而且只有一层,难以捕捉长距离特征。
反观DPCNN,可以看出来它的region embedding就是一个去掉池化层的TextCNN,再将卷积层叠加。
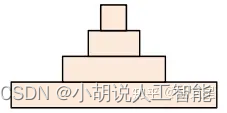
每层序列长度都减半(如上图所示),可以这么理解:相当于在N-Gram上再做N-Gram。越往后的层,每个位置融合的信息越多,最后一层提取的就是整个序列的语义信息。
原理图如下:
# coding: UTF-8
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
class Config(object):
"""配置参数"""
def __init__(self, dataset, embedding):
self.model_name = 'DPCNN'
self.train_path = dataset + '/data/train.txt' # 训练集
self.dev_path = dataset + '/data/dev.txt' # 验证集
self.test_path = dataset + '/data/test.txt' # 测试集
self.class_list = [x.strip() for x in open(
dataset + '/data/class.txt', encoding='utf-8').readlines()] # 类别名单
self.vocab_path = dataset + '/data/vocab.pkl' # 词表
self.save_path = dataset + '/saved_dict/' + self.model_name + '.ckpt' # 模型训练结果
self.log_path = dataset + '/log/' + self.model_name
self.embedding_pretrained = torch.tensor(
np.load(dataset + '/data/' + embedding)["embeddings"].astype('float32'))\
if embedding != 'random' else None # 预训练词向量
self.device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') # 设备
self.dropout = 0.5 # 随机失活
self.require_improvement = 1000 # 若超过1000batch效果还没提升,则提前结束训练
self.num_classes = len(self.class_list) # 类别数
self.n_vocab = 0 # 词表大小,在运行时赋值
self.num_epochs = 20 # epoch数
self.batch_size = 128 # mini-batch大小
self.pad_size = 32 # 每句话处理成的长度(短填长切)
self.learning_rate = 1e-3 # 学习率
self.embed = self.embedding_pretrained.size(1)\
if self.embedding_pretrained is not None else 300 # 字向量维度
self.num_filters = 250 # 卷积核数量(channels数)
'''Deep Pyramid Convolutional Neural Networks for Text Categorization'''
class Model(nn.Module):
def __init__(self, config):
super(Model, self).__init__()
if config.embedding_pretrained is not None:
self.embedding = nn.Embedding.from_pretrained(config.embedding_pretrained, freeze=False)
else:
self.embedding = nn.Embedding(config.n_vocab, config.embed, padding_idx=config.n_vocab - 1)
self.conv_region = nn.Conv2d(1, config.num_filters, (3, config.embed), stride=1)
self.conv = nn.Conv2d(config.num_filters, config.num_filters, (3, 1), stride=1)
self.max_pool = nn.MaxPool2d(kernel_size=(3, 1), stride=2)
self.padding1 = nn.ZeroPad2d((0, 0, 1, 1)) # top bottom
self.padding2 = nn.ZeroPad2d((0, 0, 0, 1)) # bottom
self.relu = nn.ReLU()
self.fc = nn.Linear(config.num_filters, config.num_classes)
def forward(self, x):
x = x[0]
x = self.embedding(x)
x = x.unsqueeze(1) # [batch_size, 250, seq_len, 1]
x = self.conv_region(x) # [batch_size, 250, seq_len-3+1, 1]
x = self.padding1(x) # [batch_size, 250, seq_len, 1]
x = self.relu(x)
x = self.conv(x) # [batch_size, 250, seq_len-3+1, 1]
x = self.padding1(x) # [batch_size, 250, seq_len, 1]
x = self.relu(x)
x = self.conv(x) # [batch_size, 250, seq_len-3+1, 1]
while x.size()[2] > 2:
x = self._block(x)
x = x.squeeze() # [batch_size, num_filters(250)]
x = self.fc(x)
return x
def _block(self, x):
x = self.padding2(x)
px = self.max_pool(x)
x = self.padding1(px)
x = F.relu(x)
x = self.conv(x)
x = self.padding1(x)
x = F.relu(x)
x = self.conv(x)
# Short Cut
x = x + px
return x
终端运行下面命令,进行训练和测试:
python run.py --model DPCNN
训练过程如下:
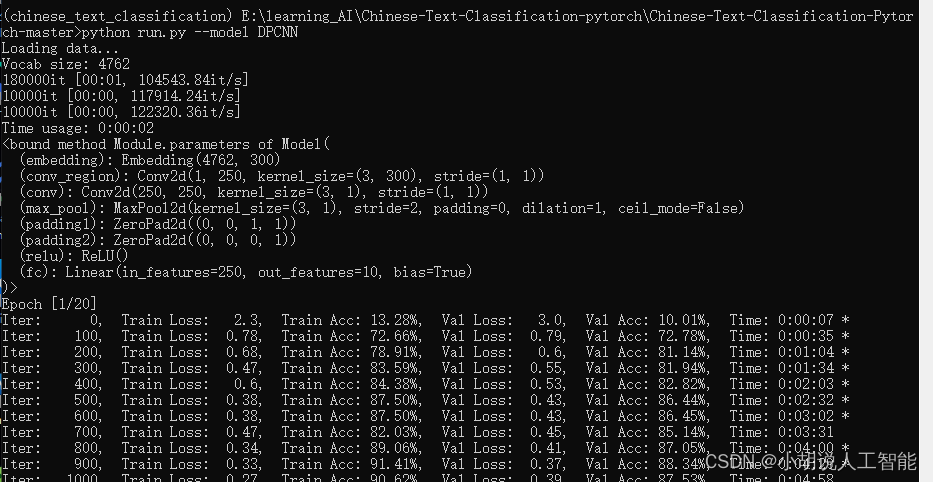
训练及测试结果如下:
使用CPU版本pytorch,耗时19分26秒,准确率91.21%
Transformer
模型说明
原理图如下:
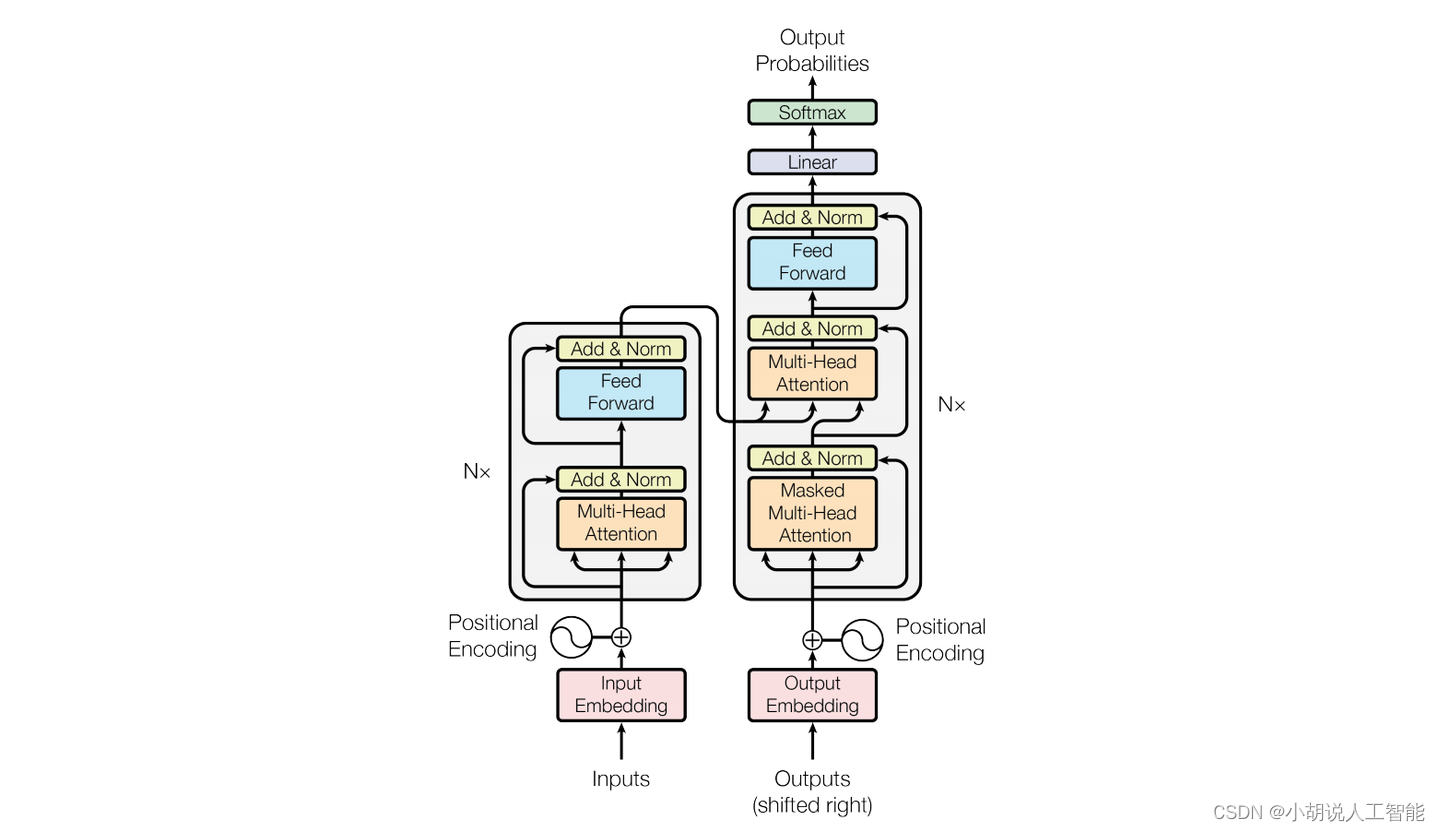
和大多数seq2seq模型一样,transformer的结构也是由encoder和decoder组成。
Encoder:
Encoder由6个相同的block(模型结构左侧部分)组成,layer指的就是原理图左侧的单元。每个block由多头自注意力块和全连接前向传播块组成。两个部分还都加了残差连接和归一化。
多头自注意力
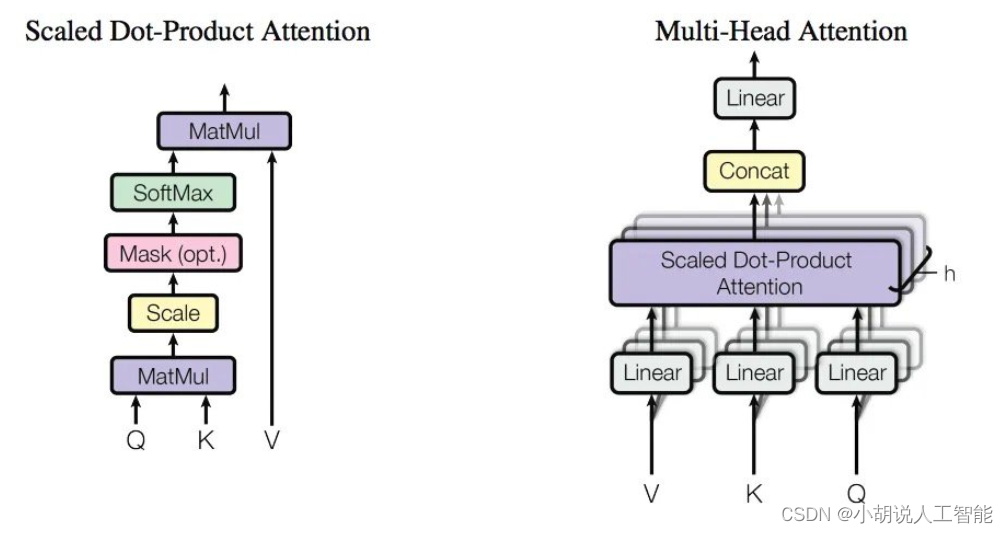
多头注意力是将多个注意力机制进行组合,将注意力处理后的输出进行拼接。其可以表示为:
MultiHead ( Q , K , V ) = Concat ( head 1 , ⋅ , head n ) W O h h e a d i = Attention ( Q W i Q , K W i K , V W i V ) \begin{aligned} & \text { MultiHead }(Q, K, V)=\text { Concat }\left(\text { head }_1, \cdot, \text { head }_n\right) W^O \\ & h^{h e a d_i}=\operatorname{Attention}\left(Q W_i^Q, K W_i^K, V W_i^V\right) \\ & \end{aligned} MultiHead (Q,K,V)= Concat ( head 1,⋅, head n)WOhheadi=Attention(QWiQ,KWiK,VWiV)
而自注意力则是Q、K、V取相同的值。
Decoder:
Decoder和Encoder的结构非常相近,值得关注的是Decoder的输入与输出。
- 输入:包括Encoder的输出和对应i-1位置Decoder的输出。所以中间的attention不是自注意力,它的K,V来自Encoder,Q来自上一位置Decoder的输出;
- 输出:输出为对应位置的输出词的概率分布。
解码器在训练和预测时的机制也是不同的,在训练时,解码是一次全部decode出来,用上一步的ground truth来预测(mask矩阵也会改动,让解码时看不到未来的token);而预测时,因为没有ground truth了,需要一个个预测。
Positional Encoding:
为了让模型中序列的特征能够体现,需要将序列的位置信息编码到输入中。将位置编码和嵌入编码相加,即可得到最终的输入向量。总的来说,编码位置信息有两种方式:一种是基于公式的编码,另一种是通过训练动态学习的编码。原文作者经过测试,两种方法的效果基本相同,而基于公式的编码不需要额外训练,且能够处理训练集中未出现过的长度的序列,因此Transformer 中使用了基于公式的位置编码:
P E ( p o s , 2 i ) = sin ( pos / 1000 0 2 i / d model ) P E ( p o s , 2 i + 1 = cos ( p o s / 1000 0 2 i / d model ) \begin{gathered} P E_{(p o s, 2 i)}=\sin \left(\text { pos } / 10000^{2 i / d_{\text {model }}}\right) \\ P E_{(p o s, 2 i+1}=\cos \left(p o s / 10000^{2 i / d_{\text {model }}}\right) \end{gathered} PE(pos,2i)=sin( pos /100002i/dmodel )PE(pos,2i+1=cos(pos/100002i/dmodel )
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
import copy
class Config(object):
"""配置参数"""
def __init__(self, dataset, embedding):
self.model_name = 'Transformer'
self.train_path = dataset + '/data/train.txt' # 训练集
self.dev_path = dataset + '/data/dev.txt' # 验证集
self.test_path = dataset + '/data/test.txt' # 测试集
self.class_list = [x.strip() for x in open(
dataset + '/data/class.txt', encoding='utf-8').readlines()] # 类别名单
self.vocab_path = dataset + '/data/vocab.pkl' # 词表
self.save_path = dataset + '/saved_dict/' + self.model_name + '.ckpt' # 模型训练结果
self.log_path = dataset + '/log/' + self.model_name
self.embedding_pretrained = torch.tensor(
np.load(dataset + '/data/' + embedding)["embeddings"].astype('float32'))\
if embedding != 'random' else None # 预训练词向量
self.device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') # 设备
self.dropout = 0.5 # 随机失活
self.require_improvement = 2000 # 若超过1000batch效果还没提升,则提前结束训练
self.num_classes = len(self.class_list) # 类别数
self.n_vocab = 0 # 词表大小,在运行时赋值
self.num_epochs = 20 # epoch数
self.batch_size = 128 # mini-batch大小
self.pad_size = 32 # 每句话处理成的长度(短填长切)
self.learning_rate = 5e-4 # 学习率
self.embed = self.embedding_pretrained.size(1)\
if self.embedding_pretrained is not None else 300 # 字向量维度
self.dim_model = 300
self.hidden = 1024
self.last_hidden = 512
self.num_head = 5
self.num_encoder = 2
'''Attention Is All You Need'''
class Model(nn.Module):
def __init__(self, config):
super(Model, self).__init__()
if config.embedding_pretrained is not None:
self.embedding = nn.Embedding.from_pretrained(config.embedding_pretrained, freeze=False)
else:
self.embedding = nn.Embedding(config.n_vocab, config.embed, padding_idx=config.n_vocab - 1)
self.postion_embedding = Positional_Encoding(config.embed, config.pad_size, config.dropout, config.device)
self.encoder = Encoder(config.dim_model, config.num_head, config.hidden, config.dropout)
self.encoders = nn.ModuleList([
copy.deepcopy(self.encoder)
# Encoder(config.dim_model, config.num_head, config.hidden, config.dropout)
for _ in range(config.num_encoder)])
self.fc1 = nn.Linear(config.pad_size * config.dim_model, config.num_classes)
# self.fc2 = nn.Linear(config.last_hidden, config.num_classes)
# self.fc1 = nn.Linear(config.dim_model, config.num_classes)
def forward(self, x):
out = self.embedding(x[0])
out = self.postion_embedding(out)
for encoder in self.encoders:
out = encoder(out)
out = out.view(out.size(0), -1)
# out = torch.mean(out, 1)
out = self.fc1(out)
return out
class Encoder(nn.Module):
def __init__(self, dim_model, num_head, hidden, dropout):
super(Encoder, self).__init__()
self.attention = Multi_Head_Attention(dim_model, num_head, dropout)
self.feed_forward = Position_wise_Feed_Forward(dim_model, hidden, dropout)
def forward(self, x):
out = self.attention(x)
out = self.feed_forward(out)
return out
class Positional_Encoding(nn.Module):
def __init__(self, embed, pad_size, dropout, device):
super(Positional_Encoding, self).__init__()
self.device = device
self.pe = torch.tensor([[pos / (10000.0 ** (i // 2 * 2.0 / embed)) for i in range(embed)] for pos in range(pad_size)])
self.pe[:, 0::2] = np.sin(self.pe[:, 0::2])
self.pe[:, 1::2] = np.cos(self.pe[:, 1::2])
self.dropout = nn.Dropout(dropout)
def forward(self, x):
out = x + nn.Parameter(self.pe, requires_grad=False).to(self.device)
out = self.dropout(out)
return out
class Scaled_Dot_Product_Attention(nn.Module):
'''Scaled Dot-Product Attention '''
def __init__(self):
super(Scaled_Dot_Product_Attention, self).__init__()
def forward(self, Q, K, V, scale=None):
'''
Args:
Q: [batch_size, len_Q, dim_Q]
K: [batch_size, len_K, dim_K]
V: [batch_size, len_V, dim_V]
scale: 缩放因子 论文为根号dim_K
Return:
self-attention后的张量,以及attention张量
'''
attention = torch.matmul(Q, K.permute(0, 2, 1))
if scale:
attention = attention * scale
# if mask: # TODO change this
# attention = attention.masked_fill_(mask == 0, -1e9)
attention = F.softmax(attention, dim=-1)
context = torch.matmul(attention, V)
return context
class Multi_Head_Attention(nn.Module):
def __init__(self, dim_model, num_head, dropout=0.0):
super(Multi_Head_Attention, self).__init__()
self.num_head = num_head
assert dim_model % num_head == 0
self.dim_head = dim_model // self.num_head
self.fc_Q = nn.Linear(dim_model, num_head * self.dim_head)
self.fc_K = nn.Linear(dim_model, num_head * self.dim_head)
self.fc_V = nn.Linear(dim_model, num_head * self.dim_head)
self.attention = Scaled_Dot_Product_Attention()
self.fc = nn.Linear(num_head * self.dim_head, dim_model)
self.dropout = nn.Dropout(dropout)
self.layer_norm = nn.LayerNorm(dim_model)
def forward(self, x):
batch_size = x.size(0)
Q = self.fc_Q(x)
K = self.fc_K(x)
V = self.fc_V(x)
Q = Q.view(batch_size * self.num_head, -1, self.dim_head)
K = K.view(batch_size * self.num_head, -1, self.dim_head)
V = V.view(batch_size * self.num_head, -1, self.dim_head)
# if mask: # TODO
# mask = mask.repeat(self.num_head, 1, 1) # TODO change this
scale = K.size(-1) ** -0.5 # 缩放因子
context = self.attention(Q, K, V, scale)
context = context.view(batch_size, -1, self.dim_head * self.num_head)
out = self.fc(context)
out = self.dropout(out)
out = out + x # 残差连接
out = self.layer_norm(out)
return out
class Position_wise_Feed_Forward(nn.Module):
def __init__(self, dim_model, hidden, dropout=0.0):
super(Position_wise_Feed_Forward, self).__init__()
self.fc1 = nn.Linear(dim_model, hidden)
self.fc2 = nn.Linear(hidden, dim_model)
self.dropout = nn.Dropout(dropout)
self.layer_norm = nn.LayerNorm(dim_model)
def forward(self, x):
out = self.fc1(x)
out = F.relu(out)
out = self.fc2(out)
out = self.dropout(out)
out = out + x # 残差连接
out = self.layer_norm(out)
return out
终端运行下面命令,进行训练和测试:
python run.py --model Transformer
训练过程如下:
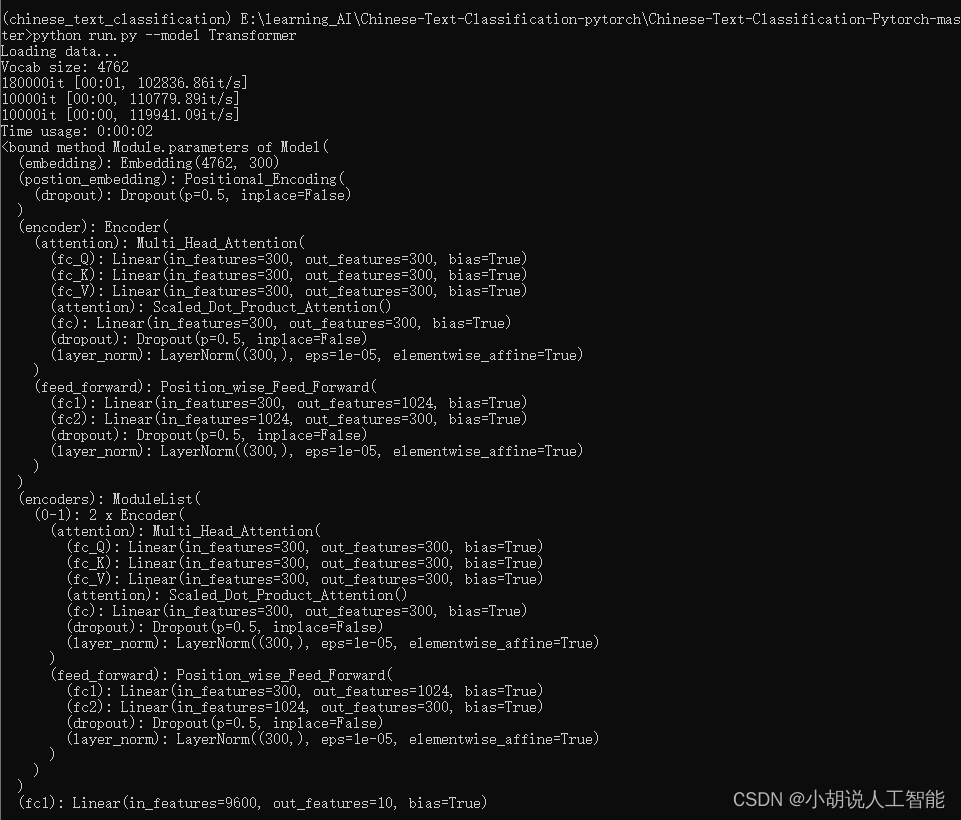
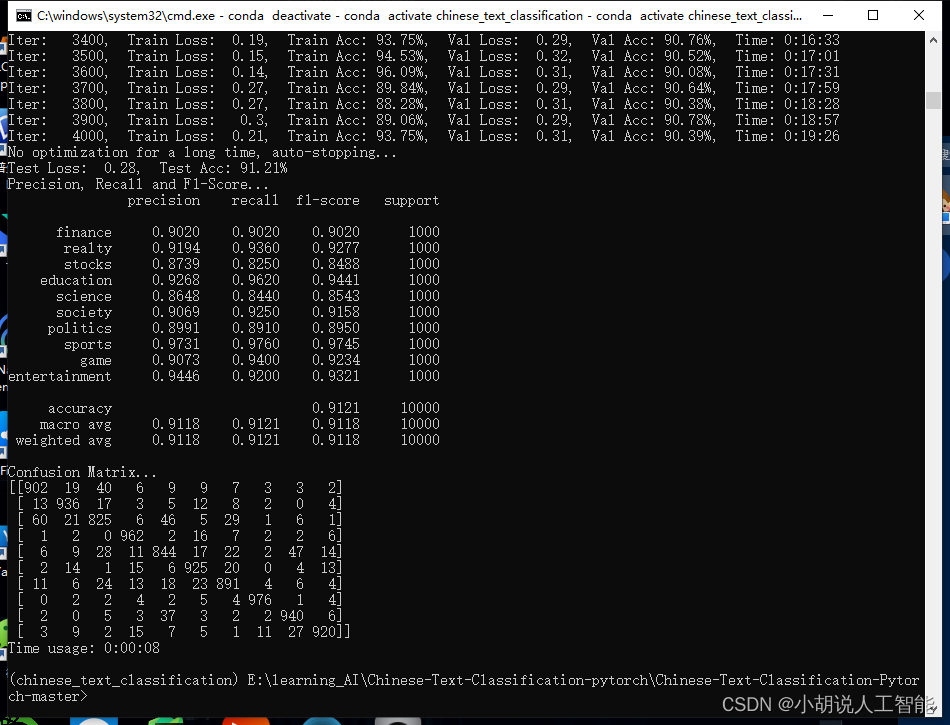
训练及测试结果如下:
博主使用CPU版本pytorch,耗时近4小时,都没有跑完一轮。
赶紧卸载CPU版本pytorch,使用GPU版本pytorch,耗时4分25秒跑完。准确度:90.01%。
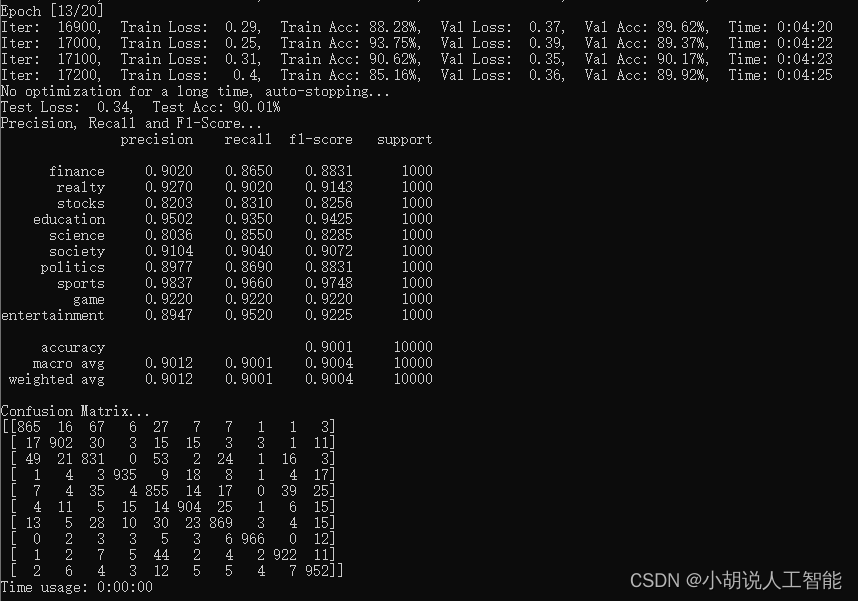
各模型效果对比
| 模型 | acc | 备注 |
|---|---|---|
| TextCNN | 90.99% | Kim 2014 经典的CNN文本分类 |
| TextRNN | 90.90% | BiLSTM |
| TextRNN_Att | 89.89% | BiLSTM+Attention |
| TextRCNN | 90.83% | BiLSTM+池化 |
| FastText | 92.07% | bow+bigram+trigram, 效果出奇的好 |
| DPCNN | 91.21% | 深层金字塔CNN |
| Transformer | 90.01% | 效果较差 |
参考资料
其它资料下载
如果大家想继续了解人工智能相关学习路线和知识体系,欢迎大家翻阅我的另外一篇博客《重磅 | 完备的人工智能AI 学习——基础知识学习路线,所有资料免关注免套路直接网盘下载》
这篇博客参考了Github知名开源平台,AI技术平台以及相关领域专家:Datawhale,ApacheCN,AI有道和黄海广博士等约有近100G相关资料,希望能帮助到所有小伙伴们。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐



 12
12 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)