【提高工作效率的神器:深度学习自动标注软件推荐AutoLabelImg,X-AnyLabeling,LabelTrack,PLabel,Auto-MOS的使用】】
X-AnyLabeling是一款创新性的交互式自动标注工具,它基于AnyLabeling进行构建和二次开发,通过扩展和支持多种模型和功能,结合Segment Anything和YOLO等主流模型,为用户提供了强大的人工智能支持。通过这些算法的融合,该工具实现了对图像和视频的自动标注,并且可以对自动算法生成的结果进行人工标注,以获取更准确的标注结果。除了常见的图像标注,该工具还支持文本检测、识别以及
概要
自动标注软件在现代工作环境中的应用日益广泛,其高效的特性使其成为节省人力资源的不可或缺的工具。随着深度学习技术的快速发展,市场上涌现了众多自动化标定软件,它们以更智能、精准的方式完成标注任务。
这些软件不仅仅是简单的工具,更是在深度学习算法支持下,能够自动识别、分类和标注大量数据的先进系统。
从图像标注到自然语言处理,这些软件涵盖了多个领域,使其在各种项目和行业中都能发挥重要作用。
AutoLabelImg
AutoLabelImg是一款功能强大的标注软件,不仅包含了labelimg的基本功能,还新增了许多辅助标注功能,这些功能主要集中在Annoatate-tools和Video-tools两个新的菜单栏下。以下是AutoLabelImg的一些主要特色功能:
自动标注:
基于yolov5模型的自动标注功能。通过该功能,用户可以将yolov5检测模型的结果转化为.xml标注文件,从而快速生成标注信息,提高标注效率。自动标注demo

追踪标注:
采用基于opencv的追踪模块,实现视频自动标注。标注的起始帧由用户手动指定,而后利用追踪模块智能预测后续视频帧的标注结果,大大简化了视频标注的流程。追踪标注demo
放大镜:
提供鼠标附近区域的放大展示功能。这使得用户能够更容易地标注一些微小目标,而且可以根据需要选择开启或关闭放大镜功能。放大镜demo
数据增强:
支持多种数据增强手段,包括平移、翻转、缩放、亮度、gama调整、模糊等。这有助于提高训练数据的多样性,增强模型的鲁棒性。数据增强demo
查询系统:
引入了十多种新功能,让用户无需过多了解,只需通过模糊搜索即可找到所需功能。这种设计使得软件更加用户友好,降低了使用门槛。搜索系统demo
其他批量处理工具:
提供了多种批量处理工具,包括类别筛选、重命名、统计,标注文件属性校正,视频提取/合成,图片重命名等。用户可以通过软件中的查询系统获取详细介绍,或者直接上手体验这些实用的批量处理功能。
话不多说,直接上仓库地址(这次分了中文版和英文版的readme,读者可以随意切换):项目地址: github仓库
安装教程
请参考项目仓库中的readme
X-AnyLabeling
X-AnyLabeling是一款创新性的交互式自动标注工具,它基于AnyLabeling进行构建和二次开发,通过扩展和支持多种模型和功能,结合Segment Anything和YOLO等主流模型,为用户提供了强大的人工智能支持。以下是X-AnyLabeling的主要特点:
多样的标注支持:
X-AnyLabeling支持多边形、矩形、圆形、直线和点等多种图像标注方式,满足不同项目的标注需求,使用户能够灵活选择适用于其数据集的标注方式。
全面的文本处理:
除了常见的图像标注,该工具还支持文本检测、识别以及关键信息提取(KIE)等功能,为用户提供了更为全面的标注能力,尤其适用于需要处理文本信息的项目。
检测-分类级联模型:
X-AnyLabeling支持检测-分类级联模型,使用户能够进行更细粒度的分类,进一步提高模型对不同类别的敏感性和准确性。
人脸和关键点检测:
提供一键式人脸和关键点检测功能,为人脸相关任务提供便捷而高效的标注工具,满足人脸检测和关键点定位的需求。
多框架支持:
支持多个主流深度学习框架,包括PaddlePaddle、OpenMMLab、Pytorch-TIMM等,使用户能够选择适合其需求和熟悉度的框架进行工作。
标准文件格式转换:
X-AnyLabeling能够将标注结果转换为标准的COCO-JSON、VOC-XML以及YOLOv5-TXT等文件格式,确保与其他系统和工具的兼容性,方便用户在不同平台之间共享和应用标注数据。
先进的检测器支持:
集成了先进的检测器,包括YOLOv5、YOLOv6、YOLOv7、YOLOv8、YOLOX以及DETR系列模型,为用户提供了在不同应用场景下选择最适合模型的灵活性。
源码链接
视频教程
安装
下载和运行可执行文件
整个安装及使用教程都很简单,目前已在Windows系统上编译成可执行软件,可直接在release页面直接下载使用。其他平台可根据以下指令自行打包即可:
1.安装 PyInstaller
pip install -r requirements-dev.txt
2.构建
bash build_executable.sh
请注意,在运行之前,请根据本地conda环境在anylabeling.spec文件中替换’pathex’。
3.移步至目录 dist/ 下检查输出。
源码编译
1.安装依赖包
pip install -r requirements.txt
2.生成资源
pyrcc5 -o anylabeling/resources/resources.py anylabeling/resources/resources.qrc
3.运行应用程序
python anylabeling/app.py
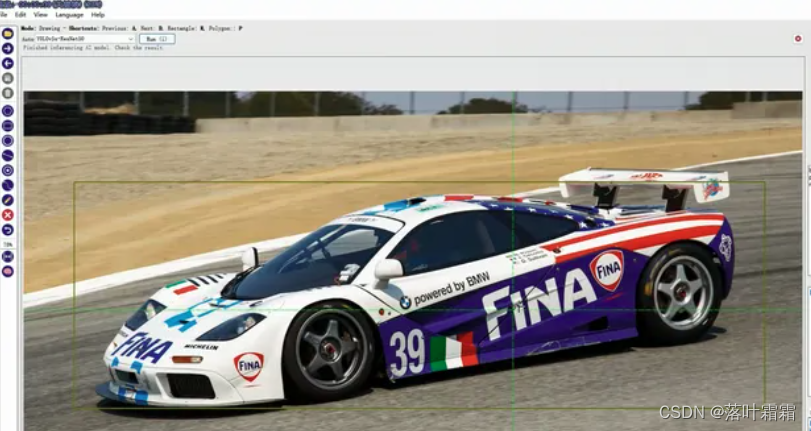
使用X-AnyLabeling进行自动标记的步骤如下:
步骤一:激活自动标记
点击左侧的"Brain"按钮,以激活自动标记功能。
步骤二:选择模型类型
从下拉菜单"Model"中选择"Segment Anything Models"类型的模型。请注意,不同模型具有不同的精度和速度。例如,"Segment Anything Model (ViT-B)"速度最快但精度较低,而"Segment Anything Model (ViT-H)"则是最慢但最准确的。其中,"Quant"表示量化过的模型。
步骤三:标记对象
使用自动分割标记工具标记对象:
"+Point": 添加属于对象的点。
"-Point": 移除对象中不需要的点。
"+Rect": 绘制包含对象的矩形,Segment Anything 将自动分割对象。
"清除": 清除所有自动分段标记。
步骤四:完成对象
当完成当前标记后,按下快捷键"f",输入标签名称并保存对象。
注意事项:
X-AnyLabeling在第一次运行任何模型时,需要从服务器下载模型,可能需要一段时间,取决于本地网络速度。
首次进行AI推理也需要一些时间,请耐心等待。
后台任务正在运行以缓存"Segment Anything"模型的"编码器",因此,在接下来的图像中自动分割工作会变得更加迅速,无需担心。
参考:CVHub-工具篇
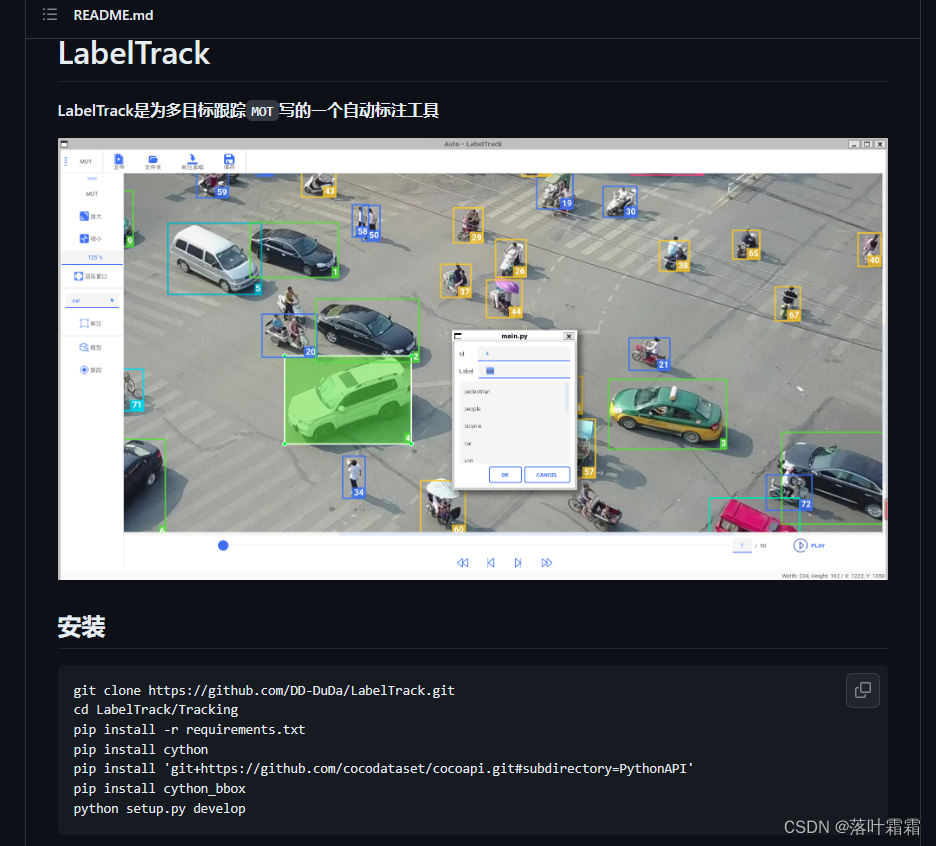
LabelTrack
LabelTrack是专为多目标跟踪(MOT)场景设计的自动标注工具。它通过简单的操作,如导入视频流,提供了快速而高效的行人标注功能。
主要功能包括:
视频导入:
用户可以轻松地导入MP4文件或视频帧文件夹,为后续的标注过程提供数据源。
手动标注:
提供了手动标注的功能,用户可以直观地在视频中标注行人的位置。这样的灵活性使得用户能够对标注结果进行更为精细的调整。
标注框修改:
允许用户修改标注框的各种属性,包括大小、标签、ID等信息。这种灵活性使得用户能够根据实际情况进行个性化的标注。
SOTA目标跟踪预测:
使用先进的目标跟踪模型进行预跟踪,以提高标注的准确性和效率。这有助于自动捕捉视频中的行人并生成初步的标注结果。
数据集导出和导入:
支持将标注结果导出为VisDrone格式的数据集,以满足不同项目的需求。同时,也提供了导入VisDrone格式数据集的功能,使得LabelTrack更加灵活和通用。
PLabel
这个工具是由鹏城实验室自主研发的,它集成了视频抽帧、目标检测、视频跟踪、ReID分类、人脸检测等先进算法。通过这些算法的融合,该工具实现了对图像和视频的自动标注,并且可以对自动算法生成的结果进行人工标注,以获取更准确的标注结果。
此外,该工具还支持对视频、图片以及医疗数据(包括DICOM文件及病理图像)进行人工标注。标注结果可导出为COCO及VOC格式,以满足不同应用场景的需求。
特别值得注意的是,该工具支持多人协同标注,为团队合作提供了便利。另外,最新新增了基于GPU的Segment Anything分割自动标注镜像,使用户能够对任意图片进行高效的分割标注,提高标注效率。
Auto-MOS
Auto-MOS源码链接
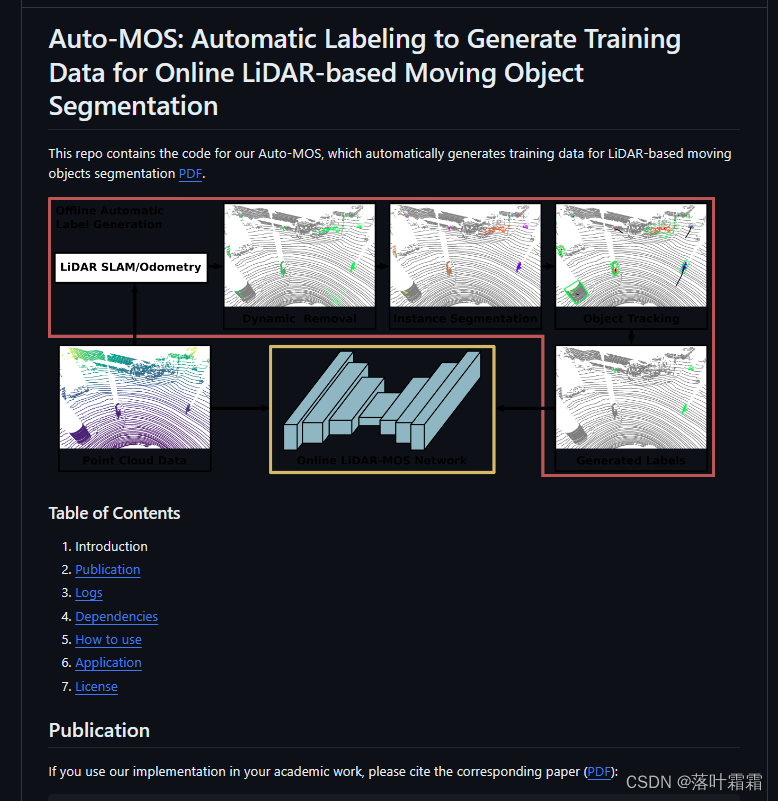
该项目旨在自动生成基于激光雷达的运动对象分割的训练数据,通过批量离线处理数据来实现这一目标。
具体实现方式如下:
基于占据的动态物体去除:
首先,该工具利用基于占据的动态物体去除方法,对激光雷达数据进行批量离线处理。这一步骤旨在粗略检测可能的动态物体,通过识别被占据的区域来排除静态背景。
提取段和卡尔曼滤波跟踪:
其次,从初步的动态物体提议中,该工具提取段并使用卡尔曼滤波器进行跟踪。这一步骤有助于精细地追踪动态物体的运动轨迹,提高对运动物体的准确性。
基于跟踪的轨迹标记:
基于成功的跟踪轨迹,该工具将实际移动的物体,如驾驶汽车和行人,标记为移动。这种基于跟踪的轨迹标记策略使得对真实运动物体的标识更加可靠。
静态物体标记:
与此相反,非移动的物体,例如停放的汽车、灯、道路或建筑物,则被标记为静态。通过对不具有明显运动轨迹的物体进行静态标记,工具能够区分并分类不同类型的物体。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐



 19
19 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)