深度学习笔记(一)— VGG11
深度学习笔记(1)——VGG111.网络结构2.代码实现3.运行结果本文介绍复现VGG11并用于CIFAR10数据集分类(Pytorch)。1.网络结构上图给出了所有VGG网络的结构,其中VGG11网络结构为:Block1:3*3卷积×1+最大池化×1+relu(输入通道:3,输出通道:64)Block2:3*3卷积×1+最大池化×1+relu(输入通道:64,输出通道:128)Block3:3*
·
本文介绍复现VGG11并用于CIFAR10数据集分类(Pytorch)。
1.网络结构
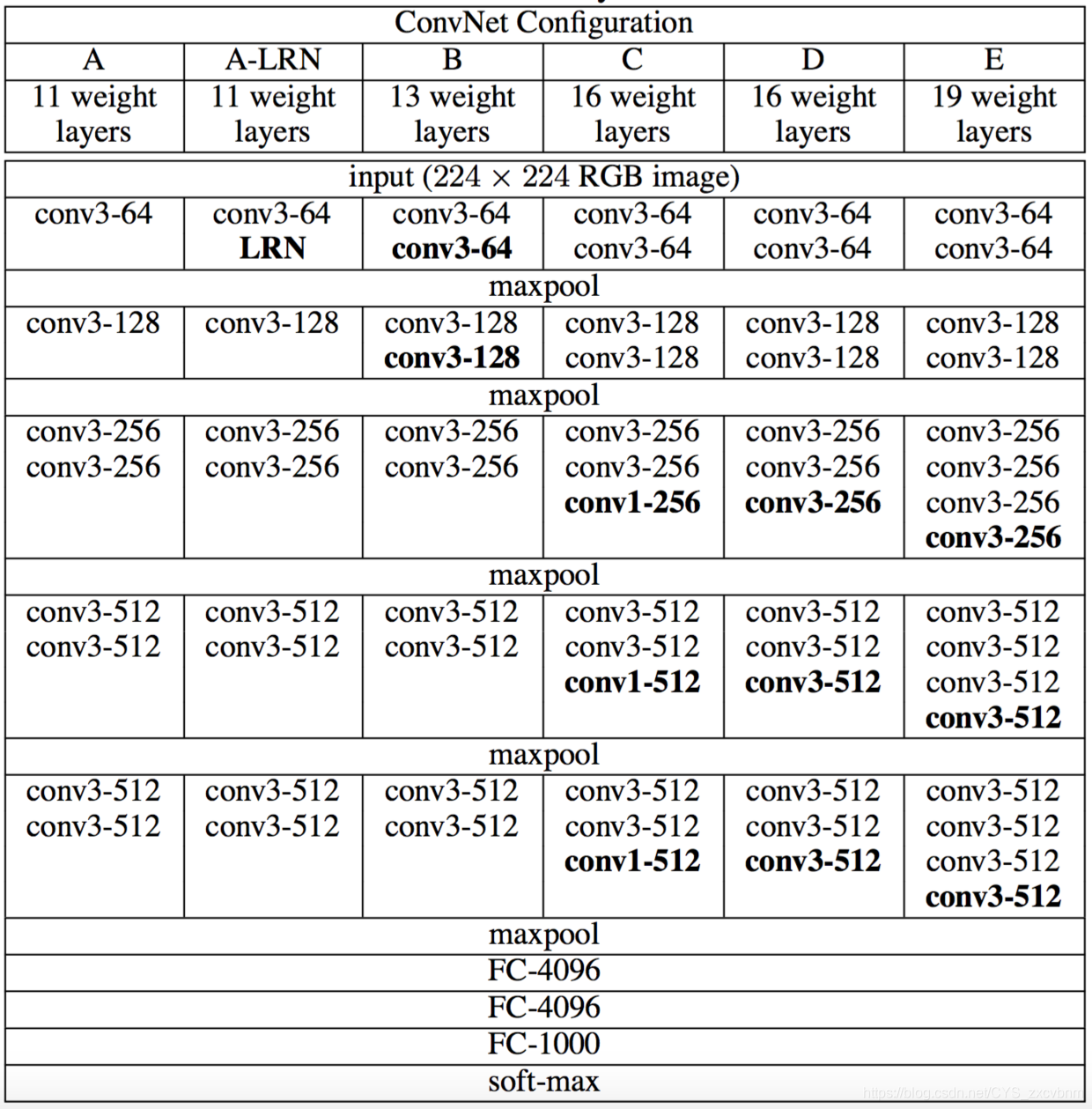
上图给出了所有VGG网络的结构,其中VGG11网络结构为:
- Block1:3*3卷积×1+最大池化×1+relu(输入通道:3,输出通道:64)
- Block2:3*3卷积×1+最大池化×1+relu(输入通道:64,输出通道:128)
- Block3:3*3卷积×2+最大池化×2+relu(输入通道:128,输出通道:256)
- Block4:3*3卷积×2+最大池化×2+relu(输入通道:256,输出通道:512)
- Block5:3*3卷积×2+最大池化×2+relu(输入通道:512,输出通道:512)
- classifier:fc×3+softmax
2.代码实现
原网络中输入图像为3*224*224,经Block5后为512*7*7,fc层输出为1000类,这里使用CIFAR10数据集,输入为3*32*32,输出为10类,fc层神经元数量略有改动。
文件结构:
vgg/__init__.py:
import torch
import torch.nn as nn
import torch.nn.functional as F
class VGG11(nn.Module):
def __init__(self, num_classes=10):
super(VGG11, self).__init__()
self.conv_layer1 = self._make_conv_1(3,64)
self.conv_layer2 = self._make_conv_1(64,128)
self.conv_layer3 = self._make_conv_2(128,256)
self.conv_layer4 = self._make_conv_2(256,512)
self.conv_layer5 = self._make_conv_2(512,512)
self.classifier = nn.Sequential(
nn.Linear(512, 64), # 这里修改一下输入输出维度
nn.ReLU(inplace=True),
nn.Dropout(p=0.5),
nn.Linear(64, 64),
nn.ReLU(inplace=True),
nn.Dropout(p=0.5),
nn.Linear(64, num_classes)
# 使用交叉熵损失函数,pytorch的nn.CrossEntropyLoss()中已经有过一次softmax处理,这里不用再写softmax
)
def _make_conv_1(self,in_channels,out_channels):
layer = nn.Sequential(
nn.Conv2d(in_channels,out_channels, kernel_size=3, padding=1),
nn.BatchNorm2d(out_channels, affine=True),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2)
)
return layer
def _make_conv_2(self,in_channels,out_channels):
layer = nn.Sequential(
nn.Conv2d(in_channels,out_channels, kernel_size=3, padding=1),
nn.BatchNorm2d(out_channels, affine=True),
nn.ReLU(inplace=True),
nn.Conv2d(out_channels,out_channels, kernel_size=3, padding=1),
nn.BatchNorm2d(out_channels, affine=True),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2)
)
return layer
def forward(self, x):
# 32*32 channel == 3
x = self.conv_layer1(x)
# 16*16 channel == 64
x = self.conv_layer2(x)
# 8*8 channel == 128
x = self.conv_layer3(x)
# 4*4 channel == 256
x = self.conv_layer4(x)
# 2*2 channel == 512
x = self.conv_layer5(x)
# 1*1 channel == 512
x = x.view(x.size(0), -1)
# 512
x = self.classifier(x)
# 10
return x
train_test_func/__init__.py:
import torch
import torch.nn as nn
def train_func(model,cur_epoch,optimizer,data_loader,loss_func):
model.train()
total_loss = 0 # 累加每个batch的loss,求均值作为该epoch的loss
data_len = len(data_loader)
for i, (data, target) in enumerate(data_loader):
optimizer.zero_grad()
data, target = data.cuda(), target.cuda()
result = model.forward(data)
loss = loss_func(result,target)
loss.backward()
optimizer.step()
cur_loss = loss.item()
total_loss += cur_loss
ave_loss = total_loss/data_len
print('epoch:%d || loss:%f'%(cur_epoch,ave_loss))
def test_func(model,data_loader):
model.eval()
data_cnt = 0
correct = 0
with torch.no_grad():
for i, (data, target) in enumerate(data_loader):
data, target = data.cuda(), target.cuda()
_,predict = torch.max(model.forward(data).data,1) # 取最大值的索引为预测结果
correct += int(torch.sum(predict==target).cpu().numpy()) # 统计正确个数
data_cnt += len(target)
print('Accuracy of model in test set is: %f'%(correct/data_cnt))
train,py:
from train_test_func import *
from vgg import VGG11
import torchvision
from torchvision import transforms
EPOCH = 100
LR = 1e-5
model = VGG11()
model = model.cuda()
train_transform = transforms.Compose([
transforms.Resize((32, 32)),
transforms.RandomHorizontalFlip(), # 为抑制过拟合,对于训练数据进行随机水平翻转和随机旋转处理
transforms.RandomRotation(30),
transforms.ToTensor(),
transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.2225))
])
test_transform = transforms.Compose([
transforms.Resize((32, 32)),
transforms.ToTensor(),
transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.2225))
])
trainset = torchvision.datasets.CIFAR10(root='./data', train=True,
download=True, transform=train_transform)
testset = torchvision.datasets.CIFAR10(root='./data', train=False,
download=True, transform=test_transform)
optimizer = torch.optim.Adam(model.parameters(), lr=LR, weight_decay=5e-4)
loss_func = nn.CrossEntropyLoss()
print('start training...')
for epoch_i in range(EPOCH):
train_loader = torch.utils.data.DataLoader(trainset, batch_size=5000,
shuffle=True, num_workers=0)
train_func(model, epoch_i, optimizer, train_loader, loss_func)
test_loader = torch.utils.data.DataLoader(testset, batch_size=5000,
shuffle=False, num_workers=0)
test_func(model, test_loader)
if (epoch_i + 1) % 10 == 0:
torch.save(model.state_dict(), 'weights/%s_parameter.pkl' % str(epoch_i + 1))
print('save current parameter: %s_parameter.pkl' % str(epoch_i + 1))
3.运行结果
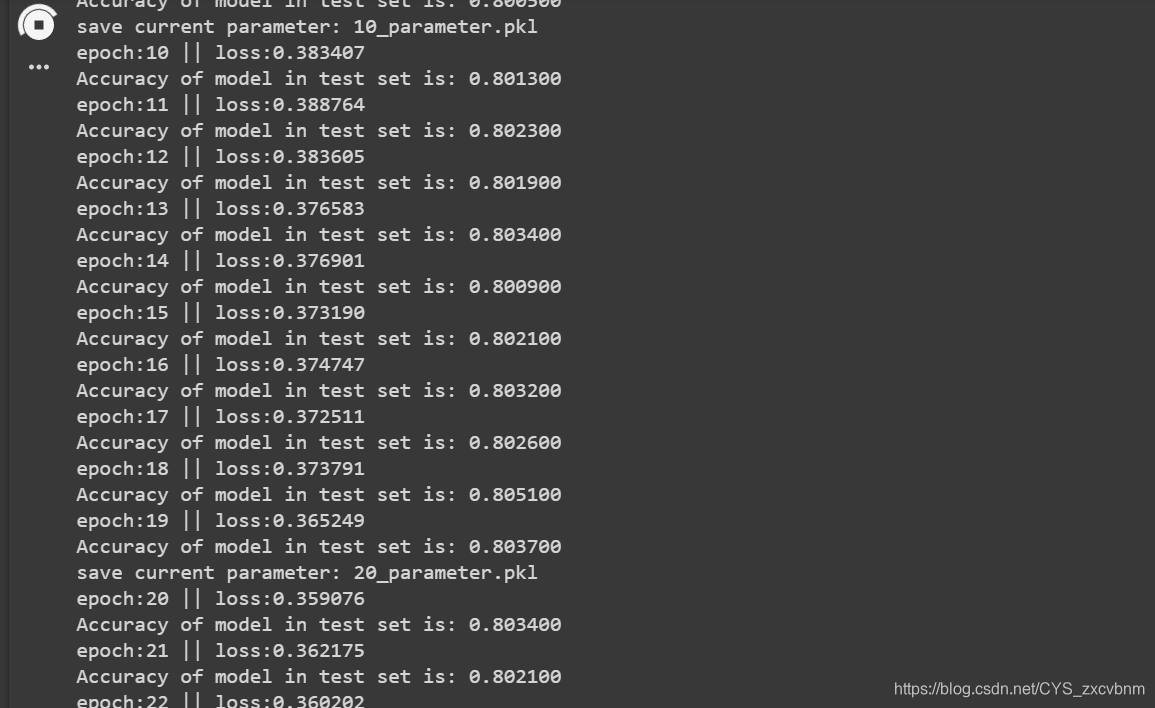
在训练过程中,lr=1e-4下运行约60个epoch时loss下降不再明显,此时测试集准确率在77左右,在此基础上,lr下调至1e-5,训练20个epoch后,loss下降幅度较小,测试集准确率到80左右。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐



 3
3 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)