Word2vec代码解析1--training word2vec modell
这个函数其实就是kemr编码啦,假设输入的是AGTCGATCACTCGACTACGCA,而kemr等于3,则输出的是AGT,GTC,TCG,
·
Word2vec代码解析1–training word2vec modell
代码在最后
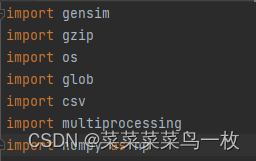
首先import第三方包

然后定义一下全局变量,

这里解释一下,
Embsize是向量的长度,为150维,为什么是150而不是100或者200呢,因为我们经过查证资料和验证发现150表现最好,你也可以变成别的数字看一下哪个效果最好。
Embepochs为迭代次数。迭代50次,至于为什么是50而不是30,原理同上,你改一下数字,看看哪个效果好。
kmer是指一种编码方式,这里以生物编码为例,i就是我们代码中的lens长度,假设i=4,那么他的意思就是,连续四个核苷酸出现的次数除以总的次数。公式如下:

然后定义了三个函数
第一个函数Gen_Words,kemr形式

这个函数其实就是kemr编码啦,假设输入的是AGTCGATCACTCGACTACGCA,而kemr等于3,则输出的是AGT,GTC,TCG,
CGA,GAT,ATC,TCA,CAC,ACT,CTC,TCG,CGA,
第二个函数train,训练模型 本函数其实就是训练模型,
本函数其实就是训练模型,
document= Gen_Words(sequences,kmer_len,stride)
#print(document)
modell = gensim.models.Word2Vec (document, window=int(12 / stride), min_count=0, size=Embsize,workers=multiprocessing.cpu_count())
# size:是指特征向量的维度 window:表示当前词与预测词在一个句子中的最大距离是多少
# min_count: 可以对字典做截断. 词频少于min_count次数的单词会被丢弃掉, 默认值为5
#workers参数控制训练的并行数。multiprocessing.cpu_count() —> 实际指的是线程数 结果输出为8(运行电脑是四核八线程)
modell.train(document,total_examples=len(document),epochs=Embepochs)
#total_examples(int) - 句子数。epochs(int) - 语料库上的迭代次数(epochs)。
modell.save(word2vec_modell+str(kmer_len))
#str() 函数将对象转化为适于人阅读的形式。其实就是字符串
#model.train() 就是告诉 Dropout 层,你下面应该遮住一神经元
#model.test() 就是告诉 Dropout 层,你下面别遮住了,我全都需要
return document
第三个函数read_fasta_file,读入文档

本函数就是读入文档,将文档中的各个字符变成数组的形式,存入seq数组,如果发现回车和换行符的话就将他们变成空
主函数

先读入文件中的各个字符,然后变成kemr的形式,最后进行模型训练,整个代码就是这么简单,你学会了吗?
参考文献
[1] Mikolov, T., Chen, K., Corrado, G., and Dean, J. (2013a) “Efficient estimation of word representations in vector space.” arXiv preprintarXiv:1301.3781.
这是完整的代码
import gensim
import gzip
import os
import glob
import csv
import multiprocessing
import numpy as np
word2vec_modell = 'wanmei'
Embsize = 150
stride = 1
Embepochs = 50
kmer_len3 = 3
kmer_len4 = 4
kmer_len5 = 5
kmer_len6 = 6
def Gen_Words(sequences,kmer_len,s):
out=[]
for i in sequences:
kmer_list=[]
for j in range(0,(len(i)-kmer_len)+1,s):
kmer_list.append(i[j:j+kmer_len])
out.append(kmer_list)
return out
def train(sequences,kmer_len):
print('training word2vec modell')
document= Gen_Words(sequences,kmer_len,stride)
#print(document)
modell = gensim.models.Word2Vec (document, window=int(12 / stride), min_count=0, size=Embsize,workers=multiprocessing.cpu_count())
modell.train(document,total_examples=len(document),epochs=Embepochs)
modell.save(word2vec_modell+str(kmer_len))
return document
def read_fasta_file():
'''
used for load fasta data and transformd into numpy.array format
#用于加载 Fasta 数据并转换为 numpy.array 格式
'''
fh = open('wanmei.txt', 'r')
seq = []
for line in fh:
if line.startswith('>'):
continue
else:
seq.append(line.replace('\n', '').replace('\r', ''))
fh.close()
matrix_data = np.array([list(e) for e in seq])
#print(matrix_data)
return seq
sequences = read_fasta_file()
document3=train(sequences,kmer_len3)
document4=train(sequences,kmer_len4)
document5=train(sequences,kmer_len5)
document6=train(sequences,kmer_len6)
model3 = gensim.models.Word2Vec.load(word2vec_modell+str(kmer_len3))
model4 = gensim.models.Word2Vec.load(word2vec_modell+str(kmer_len4))
model5 = gensim.models.Word2Vec.load(word2vec_modell+str(kmer_len5))
model6 = gensim.models.Word2Vec.load(word2vec_modell+str(kmer_len6))

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐


 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)