大模型的“记忆”不应仅仅只依靠向量数据库,mem0是一个很好的“融合架构”实践方向
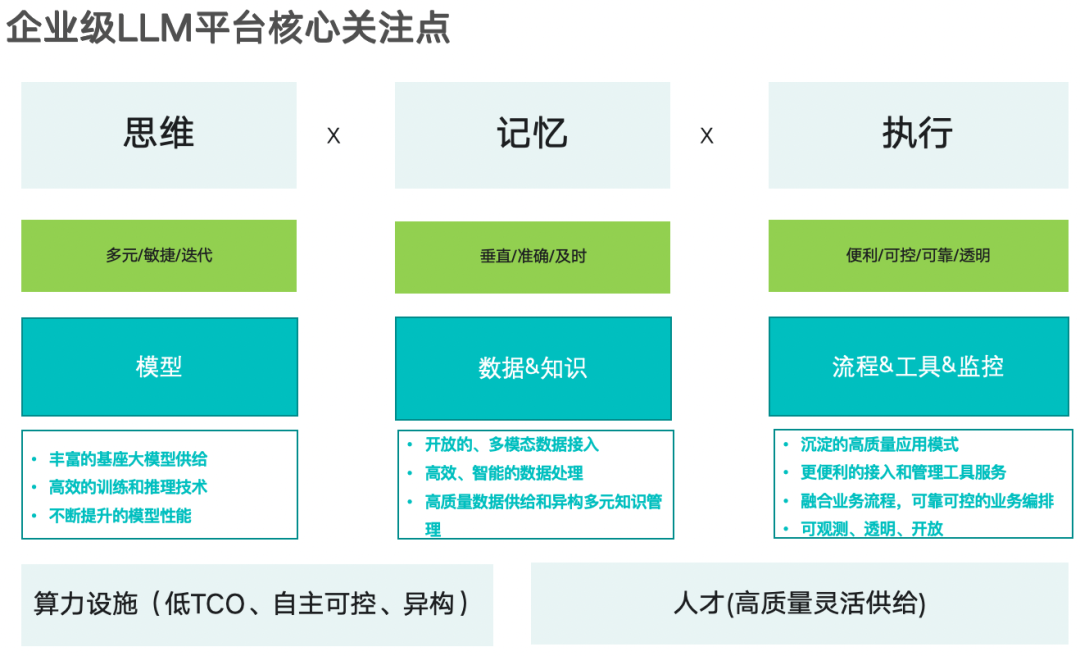
我们在探讨大模型应用的成败时,我们往往会聚焦于三个关键要素:模型本身的性能、支撑长期记忆能力的知识库,以及扩展执行能力的工具箱。企业级层面更多因素参考下图:感兴趣可以联系获取更多细节就为大模型构建记忆能力来讲,过去一年里我们的重点落在向量检索层面,其存储底层焦点就是向量数据库,曾一度爆发向量数据库大战。随着需求的复杂化,我们越来越清楚地意识到,大模型的记忆能力仅仅依赖向量数据库是不够的。在今年,随
我们在探讨大模型应用的成败时,我们往往会聚焦于三个关键要素:模型本身的性能、支撑长期记忆能力的知识库,以及扩展执行能力的工具箱。企业级层面更多因素参考下图:
感兴趣可以联系获取更多细节
就为大模型构建记忆能力来讲,过去一年里我们的重点落在向量检索层面,其存储底层焦点就是向量数据库,曾一度爆发向量数据库大战。随着需求的复杂化,我们越来越清楚地意识到,大模型的记忆能力仅仅依赖向量数据库是不够的。在今年,随着GraphRAG的爆火,知识图谱融合到RAG中变成一个新的热点,这也反映了在此领域的发展趋势。
融合"记忆"架构
从笔者来看,不论是向量数据库,图数据库,KV数据库,以及关系数据库,他们都各有所长,都可以为大模型提供特有的上下文供给,比如检索一个问题可以知识图谱构建骨架,向量数据库来联想周边相似的内容,kv数据库丰富细节,关系数据库提供可靠数据支持。它们融合起来,能够更全面,更准确的召回结果,以便大模型生成更准确的结果。可以预言,向量数据库、图数据库、KV数据库等多种存储方式结合,构建出一个多层次的记忆系统,为大模型提供了更全面、更智能的记忆支持,将会成为主流实践。
最近有一篇论文《HybridRAG: Integrating Knowledge Graphs and Vector Retrieval Augmented Generation for Efficient Information Extraction》,也用实际的评估结果证明GraphRAG + VectorRAG,即 HybridRAG,从向量数据库和知识图谱(KG)中检索上下文,显著优于传统的单一使用 VectorRAG 和 GraphRAG的结果。在信息提取过程中,利用向量数据库进行广泛的相似性检索,同时通过知识图谱提供结构化的、关系丰富的上下文数据,从而生成更准确、上下文相关的回答。
在论文提到的金融领域的实验显示,HybridRAG在检索准确性和答案生成方面表现出色,尤其在结合了两种RAG方法后,相比单独使用任一技术,HybridRAG在信实性(faithfulness)和答案相关性(answer relevance)等关键指标上都有显著提升。以下是论文中三种RAG管道(VectorRAG、GraphRAG、HybridRAG)在不同评估指标上的实验结果展示:
| 评估指标 | VectorRAG | GraphRAG | HybridRAG |
|---|---|---|---|
| 准确性(Faithfulness) | 0.94 | 0.96 | 0.96 |
| 答案相关性(Answer Relevance) | 0.91 | 0.89 | 0.96 |
| 上下文精度(Context Precision) | 0.84 | 0.96 | 0.79 |
| 上下文召回率(Context Recall) | 1.0 | 0.85 | 1.0 |
来自:https://arxiv.org/abs/2408.04948
现在,我们已经理解了多种异构存储对大模型记忆构建的意义,那么在这方面比较有前途的框架支持呢。
Mem0

Mem0正是这样一个项目,它通过结合知识图谱、向量数据库和键值存储等多种数据存储方式,为AI提供了一个强大的记忆中间层。这不仅让AI能够记住用户偏好,还能根据个体需求不断学习和适应。
Mem0的记忆系统不仅仅是数据的简单存储和检索,而是通过智能化的分析和管理,让大模型的记忆变得更具个性化,Mem0可以即时更新记忆,加入新的信息和交互,在多个会话中保留信息,保持对话连续性,对于长期参与至关重要,如虚拟伴侣或个性化学习助手。,維持上下文的連貫性,具有时效性、相关性和遗忘机制,会优先考虑最近的对话,并逐渐遗忘过时的信息,这能够确保记忆的准确和及时,以便给出更准确的响应。
官方是这么解释其工作过程的:
Mem0 采用混合数据库方法来管理和检索人工智能代理和助手的长期记忆。每个记忆都与唯一标识符(如用户 ID 或Agent ID)相关联,从而使 Mem0 能够组织和访问特定于个人或上下文的记忆。当使用 add() 方法将信息添加到 Mem0 时,系统会提取相关事实和偏好,并将其存储到不同的数据存储区:向量数据库、KV数据库和图数据库。当AI Agent或 LLM 需要调用记忆时,就会使用 search() 方法。然后,Mem0 会在这些数据存储中执行搜索,从每个来源检索相关信息。然后,这些信息会通过一个评分层,评分层会根据相关性、重要性和再现性来评估这些信息的重要性。检索到的记忆可以根据需要添加到 LLM 的提示中,从而增强其响应的个性化和相关性。
当一个AI助手或代理与用户互动时,Mem0会根据交互中的关键信息,为用户建立专属的记忆空间。通过对用户的长期行为进行分析,Mem0能够实时调整和优化大模型的应答,使其更加贴近用户的个性和需求。
例如,当你告诉AI助手你喜欢在周末打网球时,Mem0不仅会记录下这条信息,还会通过图数据库将这条信息与其他相关记忆(如你平时的运动习惯、喜欢的运动品牌等)关联起来。未来,当你再与AI互动时,它不仅能记住你喜欢网球,还能根据这些信息提供更为细致和个性化的建议。
下面是mem0使用的基本方法。
pip install mem0ai
import os
from mem0 import Memory
# 假设你已经有了OpenAI API密钥
os.environ['OPENAI_API_KEY'] = 'sk-proj-V7DGXzoKsCZVKMGSq3otY4ir2ip8vUwpI8ec_nT3BlbkFJAOz9PVs3oe-6Qq8gW0DRBGBOqTmcsfWP4FDkdXymrdTN9kSUXFqmEdrycA'
m = Memory()
def store_practice_memory(user_id, practice_details):
"""
存储用户的网球训练记忆。
"""
m.add(practice_details, user_id=user_id, metadata={"category": "tennis_practice"})
all_memories = m.get_all(user_id=user_id)
print("memorie0------: ", all_memories[0])
memory_id = all_memories[0]["id"] # get a memory_id
return memory_id
def retrieve_practice_memory(user_id, query):
"""
检索用户的网球训练记忆。
"""
related_memories = m.search(query=query, user_id=user_id)
return related_memories
def provide_training_advice(user_id, query):
"""
提供个性化的网球训练建议。
"""
training_history = retrieve_practice_memory(user_id, query)
if training_history:
response = "基于你之前的训练,建议你今天专注于提升反手击球技巧。"
else:
response = "欢迎开始你的网球训练之旅,让我们从基础的正手和反手击球开始吧。"
return response
def update_practice_memory(memory_id, new_details):
"""
更新用户的网球训练记忆。
"""
m.update(memory_id=memory_id, data=new_details)
return memory_id
def get_memory_history(user_id, memory_id):
"""
获取特定记忆的历史记录。
"""
all_memories = m.get_all(user_id=user_id)
print(all_memories)
memory_id = all_memories[0]["id"] # get a memory_id
history = m.history(memory_id=memory_id)
return history
def delete_memory(memory_id):
"""
删除特定记忆。
"""
result = m.delete(memory_id=memory_id)
return result
def delete_all_memory(user_id):
"""
删除所有记忆。
"""
result = m.delete_all(user_id=user_id)
return result
user_id = "alice"
practice_details = "今天练习了正手击球,感觉力量控制有所提升。"
memory_id = store_practice_memory(user_id, practice_details)
print(f"memory_id: {memory_id}\n")
#memory_id: 66b96ee0-dab6-4347-bcf6-280845f87983
# 用户请求训练建议
query = "正手击球训练"
advice = provide_training_advice(user_id, query)
print(f"advice: {advice}\n")
#advice: 基于你之前的训练,建议你今天专注于提升反手击球技巧。
# 用户在某项技能上取得了显著进步,更新记忆
new_details = "正手击球技巧已显著提升,可以开始练习截击了。"
update_practice_memory(memory_id, new_details)
# 获取记忆的历史变化
memory_history = get_memory_history(user_id, memory_id)
print(f"memory_history: {memory_history}\n")
#memory_history: [{'id': '1d1e7ac4-6cd5-431a-b931-b71d4940c30b', 'memory_id': '66b96ee0-dab6-4347-bcf6-280845f87983', 'old_memory': None, 'new_memory': 'Practiced forehand strokes today. Feels that power control has improved.', 'event': 'ADD', 'created_at': '2024-09-01T22:38:57.313817-07:00', 'updated_at': None}, {'id': 'fd36b9a3-4d50-44e8-9997-1d5a1a9f09f4', 'memory_id': '66b96ee0-dab6-4347-bcf6-280845f87983', 'old_memory': 'Practiced forehand strokes today. Feels that power control has improved.', 'new_memory': '正手击球技巧已显著提升,可以开始练习截击了。', 'event': 'UPDATE', 'created_at': '2024-09-01T22:38:57.313817-07:00', 'updated_at': '2024-09-01T22:38:57.752296-07:00'}]
# 删除记忆
delete_memory(memory_id)
all_memories = m.get_all(user_id)
print(f"all_memories: {all_memories}\n")
#all_memories: []
图数据库使用:
- 构建
from mem0 import Memory
config = {
"llm": {
"provider": "openai",
"config": {
"model": "gpt-4o-mini",
"temperature": 0
}
},
"graph_store": {
"provider": "neo4j",
"config": {
"url": URL,
"username": USERNAME,
"password": PASSWORD
}
},
"version": "v1.1"
}
m = Memory.from_config(config_dict=config)
user_id = "alice123"
m.add("I like painting", user_id=user_id)
m.add("I love to play badminton", user_id=user_id)
m.add("I hate playing badminton", user_id=user_id)
m.add("My friend name is john and john has a dog named tommy", user_id=user_id)
m.add("My name is alice", user_id=user_id)
m.add("John loves to hike and Harry loves to hike as well", user_id=user_id)
m.add("My friend peter is the spiderman", user_id=user_id)
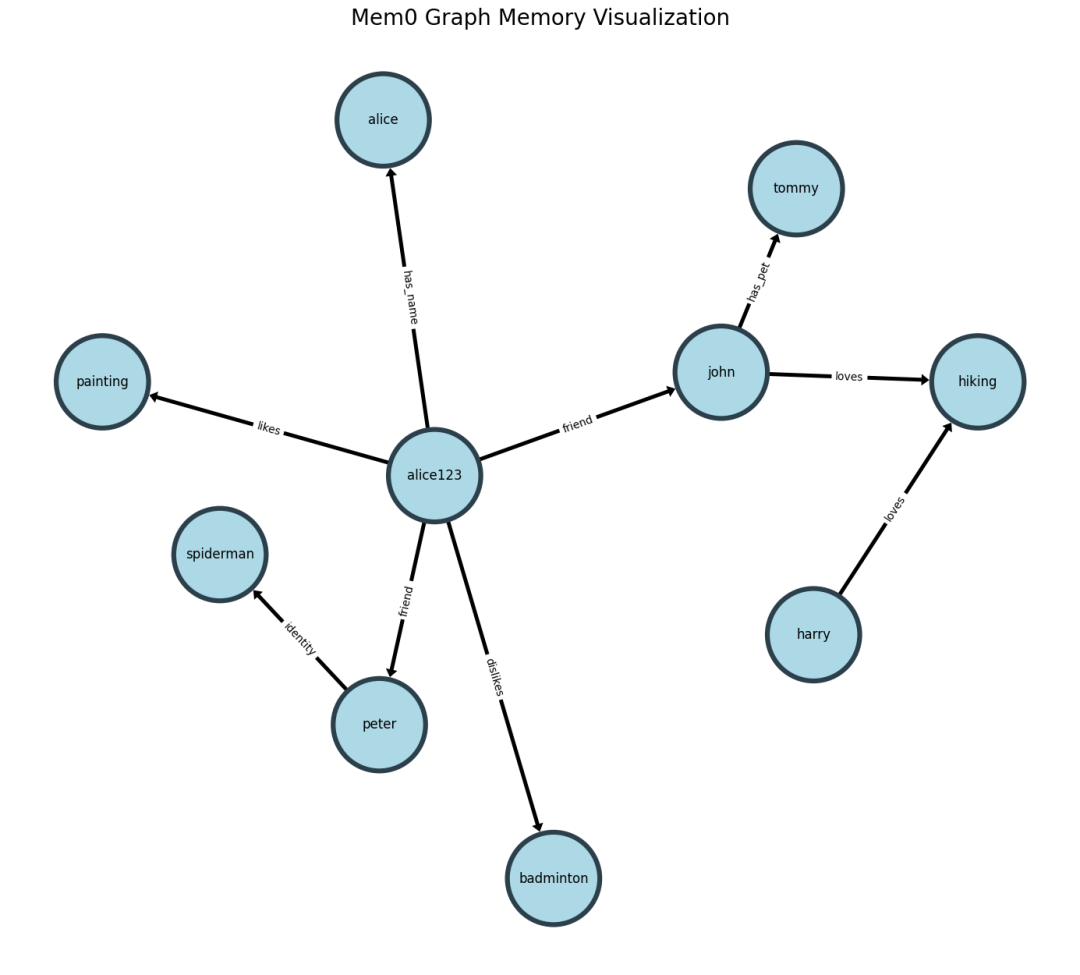
- 查询:
m.get_all(user_id=user_id)
m.search("Who is spiderman?", user_id=user_id)
{'memories': [{'id': '44c054fc-a671-4b51-baee-76f4f73b8135',
'memory': "Friend named Peter is referred to as 'the spiderman.'",
'hash': '3990cbff8c4252e1ea3435a9f0eebf3d',
'metadata': None,
'score': 0.657225732037368,
'created_at': '2024-08-27T15:53:17.605817-07:00',
'updated_at': None,
'user_id': 'alice123'}],
'entities': [{'source': 'peter',
'relation': 'identity',
'destination': 'spiderman'}]}
在这一过程中,Mem0不仅仅是一个简单的记忆存储工具,而是通过对信息的深度处理,成为了一个智能化的“记忆中枢”,帮助大模型在与用户的每次互动中都能变得更加精准和贴心。
如何系统的去学习大模型LLM ?
大模型时代,火爆出圈的LLM大模型让程序员们开始重新评估自己的本领。 “AI会取代那些行业?”“谁的饭碗又将不保了?”等问题热议不断。
不如成为「掌握AI工具的技术人」,毕竟AI时代,谁先尝试,谁就能占得先机!
但是LLM相关的内容很多,现在网上的老课程老教材关于LLM又太少。所以现在小白入门就只能靠自学,学习成本和门槛很高
针对所有自学遇到困难的同学们,我帮大家系统梳理大模型学习脉络,将这份 LLM大模型资料 分享出来:包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓
👉[CSDN大礼包🎁:全网最全《LLM大模型入门+进阶学习资源包》免费分享(安全链接,放心点击)]()👈


腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐

 26
26 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

{kind=link}
所有评论(0)