neo4j(3.5.8)数据库切换、csv文件的导入和导出
neo4j默认数据库为graph.db,如果不需要创建新的数据库,可直接跳到 2.启动neo4j;如果需要创建新的数据库,进入neo4j安装目录的/conf中的.conf文件:1)找dbms.active_database=graph.db,graph.db即默认的数据库名称。2)将graph.db换成新的数据库名字,并去掉此行用来注释的#号,如图。
一、创建新数据库(数据库切换)
1. 数据库的选择
neo4j默认数据库为graph.db,如果不需要创建新的数据库,可直接跳到 2.启动neo4j;
如果需要创建新的数据库,进入neo4j安装目录的/conf中的.conf文件:
1)找dbms.active_database=graph.db,graph.db即默认的数据库名称。

2)将graph.db换成新的数据库名字,并去掉此行用来注释的#号,如图。

2. 启动neo4j
1)cmd 以管理员身份运行,输入
neo4j.bat console
2)浏览器打开网址:(cmd不要关闭)
3)点击左侧的数据库图标
可以看到当前的数据库已切换为GNNgraph.db(默认数据库为graph.db)

二、数据的导入
这里介绍Load CSV 指令 ,注意文件格式需为.csv格式,编码方式为UTF-8。
举例:
1. 导入结点
在neo4j安装目录/import中创建文件,保存文件类型为.csv格式,编码方式为UTF-8,内容如下:
编号,姓名,省份
1,张三,广东省
2,王五,浙江省
3,刘七,江苏省
4,孙九,山东省
5,陈十一,福建省
6,赵十三,四川省
7,吴十五,上海市
8,周十七,北京市
9,黄十九,湖南省
10,许二十一,湖北省

在neo4j的界面中输入命令:
LOAD CSV WITH HEADERS FROM 'file:///person.csv' AS row
MERGE (person:人物 {编号: toInteger(row.编号)})
ON CREATE SET
person.姓名 = row.姓名,
person.省份 = row.省份;
查询所有结点,可看到结点相关属性信息:

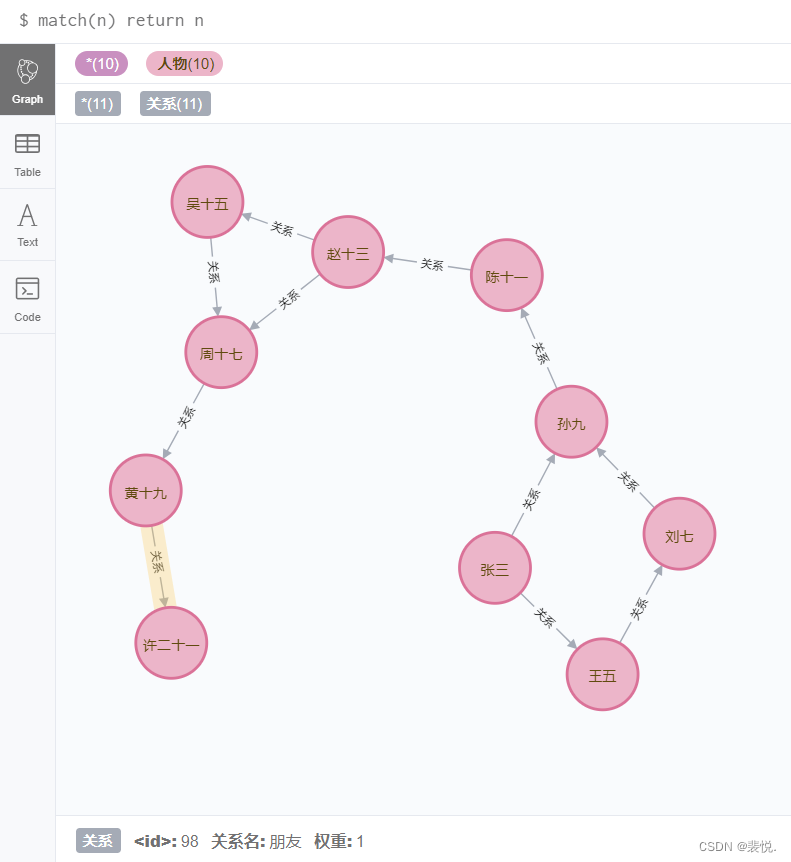
2. 导入关系
在neo4j安装目录/import中创建文件,保存文件类型为.csv格式,编码方式为UTF-8,内容如下:
人物1,人物2,关系,权重
张三,王五,朋友,1
王五,刘七,朋友,1
刘七,孙九,朋友,1
孙九,陈十一,朋友,1
陈十一,赵十三,朋友,1
赵十三,吴十五,朋友,1
吴十五,周十七,朋友,1
周十七,黄十九,朋友,1
黄十九,许二十一,朋友,1
赵十三,周十七,朋友,1
张三,孙九,朋友,1
在neo4j的界面中输入命令:
LOAD CSV WITH HEADERS FROM 'file:///关系.csv' AS row
MATCH (person1:人物 {姓名: row.人物1})
MATCH (person2:人物 {姓名: row.人物2})
MERGE (person1)-[r:关系{关系名:row.关系}]->(person2)
ON CREATE SET r.权重 = toInteger(row.权重);
得到结果:

三、数据的导出
1. 根据neo4j的版本,下载对应版本的apoc:
Installation - APOC Extended Documentation或
Releases · neo4j-contrib/neo4j-apoc-procedures · GitHub

2. 把下载的jar包放在neo4j安装目录的/plugins文件夹下

3. 将apoc.export.file.enabled=true 添加到 neo4j 安装目录/conf/neo4j.conf 文件的最后一行
4. 重启Neo4j服务
5、在neo4j界面运行:return apoc.version(),如果出现对应的版本号,证明安装成功

6. 导出命令:CALL apoc.export.csv.all("export.csv", {})
文件名可以自定义,会导出到neo4j安装目录/import中。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐

 53
53 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)