Python Flask框架-开发简单博客-定义和操作数据库_flask创建数据库
开发的个人博客,计划使用SQLite 数据库来储存用户和博客内容。Python 内置了 SQLite 数据库支持,相应的模块为 sqlite3如果你不是很熟悉 SQL ,请先阅读SQLite 官方文档,不用精通,能使用即可。计划建两个表分别为user表和post表,sql表文件保存路径为。
本人经验,学习一门语言或框架时,
请首先阅读官方文档。学习完毕后,再看其他相关文章(如本系列文章),才是正确的学习道路。
如果python都完全不熟悉,一定不要着急学习框架,
请首先学习python官方文档,一步一个脚印。要不然从入门到放弃是大概率事件。
Python 官方文档教程
本系列已发布文章:
文章目录
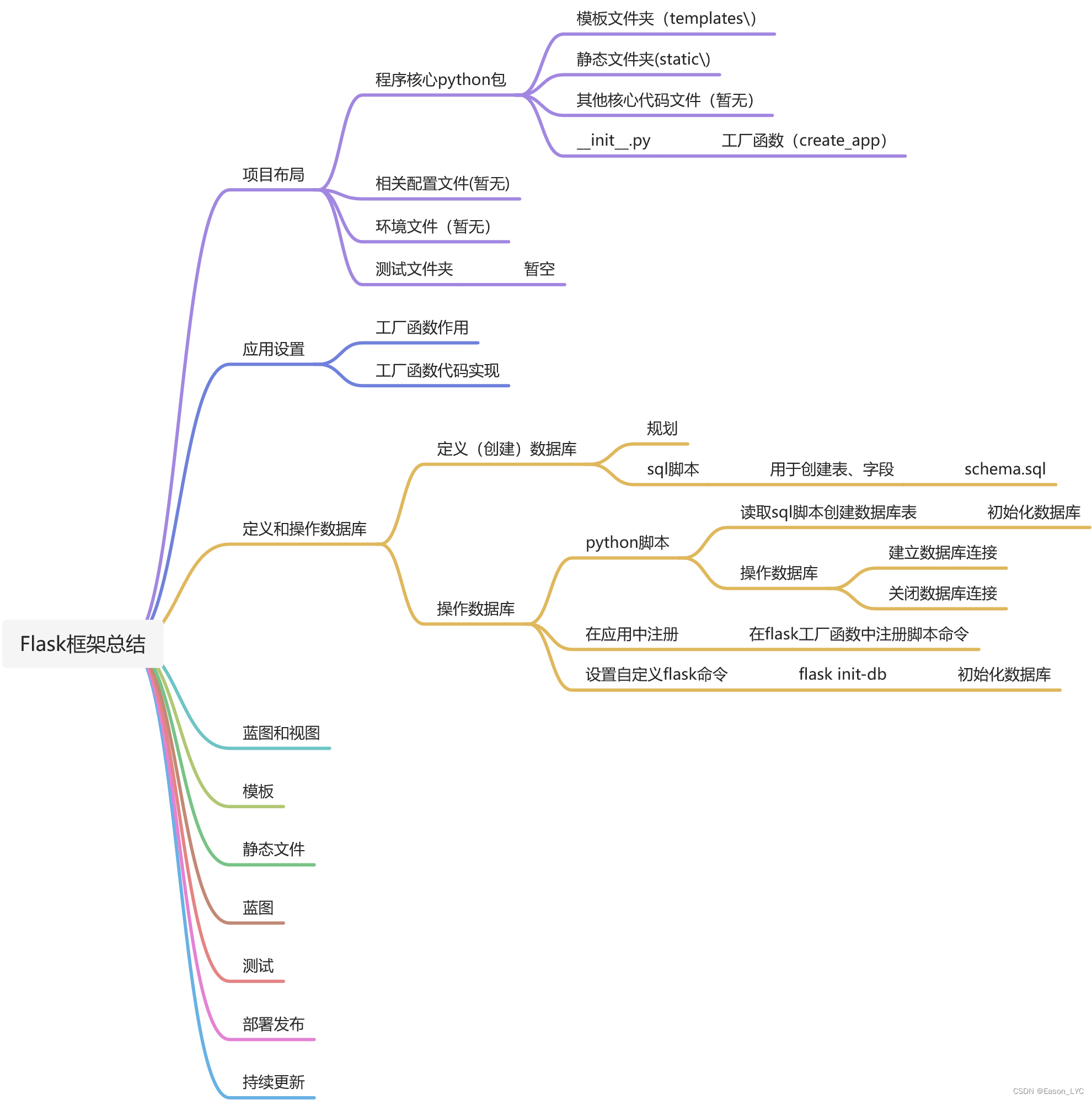
1. 本章知识点总结
2. 定义(创建)数据库
2.1 简单规划
开发的个人博客,计划使用SQLite 数据库来储存用户和博客内容。 Python 内置了 SQLite 数据库支持,相应的模块为 sqlite3
如果你不是很熟悉 SQL ,请先阅读SQLite 官方文档 ,不用精通,能使用即可。
计划建两个表分别为user表和post表,sql表文件保存路径为flaskr/schema.sql
2.2 user表字段分析
- id:用户id、整数、主键、自增加
- username:用户名、文本、值唯一,不能重复
- password: 登陆密码、文本、不能为空
flaskr/schema.sql
2.3 post表字段分析
- id: 文章id、整数、主键、自增加
- author_id:文章作者id、整数、不为空、外键
- created:文章创建时间、时间戳、不为空(默认值为创建时间)
- title:文章标题、文本、不为空
- body:文章内容、文本,不为空
2.4 创建数据库的sql脚本
编写schema.sql的脚本,该脚本用于创建SQLite 数据库,并内置user表和post表。所以这个创建过程仅在个人博客第一次运行时运行一次即可。
后续数据库内容的更新应执行常规的增删改查操作。
注意,该脚本仅在个人博客第一次运行时创建数据库,后续不应再次运行(否则,数据库将被重置)。
所以在第一次运行时,要先卸载数据库中所有表,以防报错。
路径flaskr/schema.sql
// 卸载库中所有表
DROP TABLE IF EXISTS user;
DROP TABLE IF EXISTS post;
// 新建user表
CREATE TABLE user (
id INTEGER PRIMARY KEY AUTOINCREMENT,
username TEXT UNIQUE NOT NULL,
password TEXT NOT NULL
);
// 新建post表
CREATE TABLE post (
id INTEGER PRIMARY KEY AUTOINCREMENT,
author_id INTEGER NOT NULL,
created TIMESTAMP NOT NULL DEFAULT CURRENT\_TIMESTAMP,
title TEXT NOT NULL,
body TEXT NOT NULL,
FOREIGN KEY (author_id) REFERENCES user (id)
);
3. 操作数据库
前面写完了sql脚本,接下来就要写db.py这个python脚本,用来操作数据库。路径规划为flaskr/db.py
操作具体包括了如下几个具体功能
- 建立数据库连接 — 用于将程序与数据库建立连接
- 关闭数据库连接 — 完成一次操作后,及时关闭当前连接
- 初始化数据库 — 第一次运行博客时创建数据库生成表
- 在应用中注册
db.py实现flask的调用
这个理解起来,有点绕,简单说来,
我们自己定义的函数需要在应用实例中注册,否则无法使用。应用实例就是app = Flask(__name__, instance_relative_config=True)但是问题是,这个app=我们是写在了工厂函数中(create_app)。意思就是这个实例其实并没有建立,所以我们这个注册只能在工厂函数中注册。那问题来了,在一个工厂函数中如何注册。
答案就是,函数调用另一个函数实现:工厂函数中app实例动态创建时,动态调用注册函数,实现动态注册。
flaskr/db.py 请注意代码中的注释和下面关于各函数的说明文字。
import sqlite3
import click
from flask import current_app, g
from flask.cli import with_appcontext
# 1.创建数据库连接
def get\_db():
if 'db' not in g:
g.db = sqlite3.connect(
current_app.config['DATABASE'],
detect_types=sqlite3.PARSE_DECLTYPES
)
g.db.row_factory = sqlite3.Row
return g.db
# 2. 关闭数据库连接
def close\_db():
db = g.pop('db', None)
if db is not None:
db.close()
# 3. 初始化数据库
def init\_db():
db = get_db()
with current_app.open_resource('schema.sql') as f:
db.executescript(f.read().decode('utf8'))
@click.command('init-db')
@with\_appcontext
# app context,应用上下文,存储的是应用级别的信息,比如数据库连接信息。
# request context,程序上下文,存储的是请求级别的信息,比如当前访问的url
def init\_db\_command():
init_db()
click.echo('数据库初始化成功。')
# 4. 在应用中注册`db.py`实现flask的调用
# 此处为注册函数,另一端在工厂函数(create\_app)中,动态调用此函数,实现动态注册。
def init\_app(app):
# teardown\_appcontext
# 不管是否有异常,注册的函数都会在每次请求之后执行。
# flask 为上下文提供了一个 teardown\_appcontext 钩子,使用它注册的毁掉函数会在程序上下文被销毁时调用,通常也在请求上下文被销毁时调用。
# 比如你需要在每个请求处理结束后销毁数据库连接:app.teardown\_appcontext 装饰器注册的回调函数需要接收异常对象作为参数,当请求被正常处理时这个参数将是None,这个函数的返回值将被忽略。
# 参考链接 https://www.cnblogs.com/Wu13241454771/p/15439350.html
app.teardown_appcontext(close_db)
app.cli.add_command(init_db_command)
- g 是一个特殊对象,独立于每一个请求。在处理请求过程中,它可以用于储存可能多个函数都会用到的数据。把连接储存于其中,可以多次使用,而不用在同一个请求中每次调用 get_db 时都创建一个新的连接。
- current_app 是另一个特殊对象,该对象指向处理请求的 Flask 应用。这里使用了应用工厂,那么在其余的代码中就不会出现应用对象。当应用创建后,在处理一个请求时, get_db 会被调用。这样就需要使用 current_app 。
- sqlite3.connect() 建立一个数据库连接,该连接指向配置中的 DATABASE 指定的文件。这个文件现在还没有建立,后面会在初始化数据库的时候建立该文件。
- sqlite3.Row 告诉连接返回类似于字典的行,这样可以通过列名称来操作数据。
- close_db 通过检查 g.db 来确定连接是否已经建立。如果连接已建立,那么就关闭连接。以后会在应用工厂中告诉应用 close_db 函数,这样每次请求后就会调用它。
- open_resource() 打开一个文件,该文件名是相对于 flaskr 包的。这样就不需要考虑以后应用具体部署在哪个位置。 get_db 返回一个数据库连接,用于执行文件中的命令。
- click.command() 定义一个名为 init-db 命令行,它调用 init_db 函数,并为用户显示一个成功的消息。
- app.teardown_appcontext() 告诉 Flask 在返回响应后进行清理的时候调用此函数。
- app.cli.add_command() 添加一个新的可以与 flask 一起工作的命令。
flaskr/__init__.py

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐

 27
27 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)