告别繁琐操作:自动初始化数据库表
在现代软件开发中,手动初始化数据库表往往是一个耗时且容易出错的过程。为了简化这一过程,自动初始化数据库表技术应运而生。该技术可以在应用程序启动时,自动根据预定义的模式或迁移文件创建和配置数据库表,极大地减少了开发人员的手动操作。这不仅提高了开发效率,还确保了数据库结构的一致性,特别是在不同环境之间。通过使用自动化工具,如ORM框架和数据库迁移工具,开发团队可以专注于业务逻辑开发,而不是数据库的重复
文章目录
技术派项目源码地址 :
- Gitee :技术派 - https://gitee.com/itwanger/paicoding
- Github :技术派 - https://github.com/itwanger/paicoding
不想看啰嗦的说明可直接跳转到 [项目实战] 部分 !
引入依赖
<dependency>
<groupId>org.liquibase</groupId>
<artifactId>liquibase-core</artifactId>
</dependency>
配置文件
spring:
liquibase:
change-log: classpath:liquibase/master.xml
enabled: true # 当实际使用的数据库不支持liquibase,如 mariadb 时,将这个参数设置为false

说明:
- 对于不支持liquibase的数据库,如mariadb,请将上面的 spring.liquibase.enabled 设置为 false
- change-log: 对应的是核心的数据库版本变更配置
配置 master.xml 文件
master.xml 文件中的内容如下 :
<?xml version="1.0" encoding="utf-8"?>
<databaseChangeLog
xmlns="http://www.liquibase.org/xml/ns/dbchangelog"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.liquibase.org/xml/ns/dbchangelog
http://www.liquibase.org/xml/ns/dbchangelog/dbchangelog-3.5.xsd">
<include file="liquibase/changelog/000_initial_schema.xml" relativeToChangelogFile="false"/>
</databaseChangeLog>
- 注意上面这个 include, 这里就是告诉liquibase,所有的变更记录,
- 都放在了
**liquibase/changelog/000_initial_schema.xml**这个文件中
技术派中现在只有一个include标签,但是实际上是可以有很多个的;一个好的建议是,项目首次启动的初始化表、初始化数据可以是一个 include 标签;后续的每个大的版本迭代,对应一个新的include
配置 000_initial_schema.xml 文件
再看一下
**000_initial_schema.xml**文件的内容 :
<?xml version="1.0" encoding="utf-8"?>
<databaseChangeLog
xmlns="http://www.liquibase.org/xml/ns/dbchangelog"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.liquibase.org/xml/ns/dbchangelog http://www.liquibase.org/xml/ns/dbchangelog/dbchangelog-3.5.xsd">
<property name="now" value="now()" dbms="mysql"/>
<property name="autoIncrement" value="true"/>
<changeSet id="00000000000001" author="YiHui">
<sqlFile dbms="mysql" endDelimiter=";" encoding="UTF-8" path="liquibase/data/init_schema_221209.sql"/>
</changeSet>
<changeSet id="00000000000002" author="YiHui">
<sqlFile dbms="mysql" endDelimiter=";" encoding="UTF-8" path="liquibase/data/init_data_221209.sql"/>
</changeSet>
</xml>

说明:
- changeSet 标签,id必须唯一,不能出现冲突
- sqlFile 里面的path,可以是标准的sql文件,也可以是xml格式的数据库表定义、数据库操作文件
- 一旦写上去,changeSet的顺序不要调整
比如建表SQL :
- 如果是一个新的项目,接入liquibase之后,数据库,请注意还是需要自己来创建的
- 项目启动之后,一切正常的话,直接连上数据库可以看到库表创建成功,
- 数据也初始化完成,当然也可以直接观察控制台的输出
执行完欲回滚 ?
- 当ChangeSet执行完毕之后,对应的sql文件/xml文件(即path定义的文件)不允许再修改,
- 因为db中会记录这个文件的 md5,当修改这个文件之后,这个md5也会随之发生改变
- 因此两个解决方案:新增一个changeSet
- 删除 DATABASECHANGELOG 表中 changeSet id 对应的记录,然后重新走一遍

DataSourceInitializer首次初始化方案
我们这里主要是借助 DataSourceInitializer 来实现初始化,其核心有两个配置
- DatabasePopulator: 通过addScripts来指定对应的sql文件
- DataSourceInitializer#setEnabled: 判断是否需要执行初始化
- 我们主要借助DataSourceInitializer来实现Liquibase的表创建、数据变更等操作;
- 但是再次之前,我们还做了一个库的初始化
库初始化

/**
* 检测一下数据库中表是否存在,若存在则不初始化;否则基于 schema-all.sql 进行初始化表
*
* @param dataSource
* @return true 表示需要初始化; false 表示无需初始化
*/
private boolean needInit(DataSource dataSource) {
if (autoInitDatabase()) {
return true;
}
// 根据是否存在表来判断是否需要执行sql操作
JdbcTemplate jdbcTemplate = new JdbcTemplate(dataSource);
if (!liquibaseEnable) {
// 非liquibase做数据库版本管理的,根据用户来判断是否有初始化
List list = jdbcTemplate.queryForList("SELECT table_name FROM information_schema.TABLES where table_name = 'user_info' and table_schema = '" + database + "';");
return CollectionUtils.isEmpty(list);
}
// 对于liquibase做数据版本管控的场景,若使用的不是默认的pai_coding,则需要进行修订
List<Map<String, Object>> record = jdbcTemplate.queryForList("select * from DATABASECHANGELOG where ID='00000000000020' limit 1;");
if (CollectionUtils.isEmpty(record)) {
// 首次启动,需要初始化库表,直接返回
return true;
}
// 非首次启动时,判断记录对应的md5是否准确
if (Objects.equals(record.get(0).get("MD5SUM"), "8:a1a2d9943b746acf58476ae612c292fc")) {
// 这里主要是为了解决 <a href="https://github.com/itwanger/paicoding/issues/71">#71</a> 这个问题
jdbcTemplate.update("update DATABASECHANGELOG set MD5SUM='8:bb81b67a5219be64eff22e2929fed540' where ID='00000000000020'");
}
return false;
}
数据库初始化逻辑:
**autoInitDatabase()**: 检查并尝试创建数据库。如果数据库不存在则创建它并返回true。- 非 Liquibase 场景: 使用
JdbcTemplate查询information_schema.TABLES表,检查指定的表(如user_info)是否存在。如果不存在,返回true表示需要初始化。 - Liquibase 场景: 检查
DATABASECHANGELOG表中的特定记录,并验证其 MD5 校验和。如果记录不存在或 MD5 校验和不正确,则返回true表示需要初始化。
/**
* 数据库不存在时,尝试创建数据库
*/
private boolean autoInitDatabase() {
// 查询失败,可能是数据库不存在,尝试创建数据库之后再次测试
// 数据库链接
URI url = URI.create(SpringUtil.getConfigOrElse("spring.datasource.url", "spring.dynamic.datasource.master.url").substring(5));
// 用户名
String uname = SpringUtil.getConfigOrElse("spring.datasource.username", "spring.dynamic.datasource.master.username");
// 密码
String pwd = SpringUtil.getConfigOrElse("spring.datasource.password", "spring.dynamic.datasource.master.password");
// 创建连接
try (Connection connection = DriverManager.getConnection("jdbc:mysql://" + url.getHost() + ":" + url.getPort() +
"?useUnicode=true&characterEncoding=UTF-8&useSSL=false", uname, pwd);
Statement statement = connection.createStatement()) {
// 查询数据库是否存在
ResultSet set = statement.executeQuery("select schema_name from information_schema.schemata where schema_name = '" + database + "'");
if (!set.next()) {
// 不存在时,创建数据库
String createDb = "CREATE DATABASE IF NOT EXISTS " + database;
connection.setAutoCommit(false);
statement.execute(createDb);
connection.commit();
log.info("创建数据库({})成功", database);
if (set.isClosed()) {
set.close();
}
return true;
}
set.close();
log.info("数据库已存在,无需初始化");
return false;
} catch (SQLException e2) {
throw new RuntimeException(e2);
}
}
**autoInitDatabase**: 这个方法用于检查数据库是否存在,如果不存在则创建数据库。
-
数据库连接: 使用
DriverManager.getConnection创建数据库连接,连接到 MySQL 实例。 -
查询数据库: 通过
Statement.executeQuery方法查询information_schema.schemata表,检查指定的数据库是否存在。 -
创建数据库: 如果查询结果为空(表示数据库不存在),则执行
CREATE DATABASE来创建数据库。 -
为什么不直接使用 spring.datasource.url 来创建连接?
-
因为库不存在时,直接使用下面这个url进行连接会抛连接异常ᕦ(・ㅂ・)ᕤ
表初始化
- 表的初始化,其实可以理解为项目启动之后执行一些sql,
- 这时主要借助的就是 initializer.setDatabasePopulator
核心知识点 :
虽然技术派新增了一个DbChangeSetLoader 类来实现初始化sql的加载,但实际上,若你完全抛开Liquibase,单纯的希望项目启动后执行某些sql,可以非常简单的实现,直接用下面这种就可以了。
- 通过 @Value 来加载需要初始化的sql文件
- 直接通过 ResourceDatabasePoplulator 添加sql资源

在技术派中,做了liquibase的兼容,即找哪些sql需要进行初始化,完全遵循了 Liquibase 中定义的xml文件
核心实现点如下 :
- 我们依然借助了Liquibase 的xml文件来解析来加载对应的数据库表变更历史sql
- 但是需要注意的是,采用DataSourceInitializer初始化方案,只会执行一次;当你从github上拉了代码本地执行之后,后续再拉新的代码,有新的变更时,这些新的变更都不会被执行
对于liquibase的xml文件解析,核心逻辑再 DbChangeSetLoader 中,借助sax来进行xml文件的解析
项目实战
- 引入依赖
<dependency>
<groupId>org.liquibase</groupId>
<artifactId>liquibase-core</artifactId>
</dependency>
- 修改配置文件
spring:
datasource:
url: jdbc:mysql://localhost:3306/mp?useUnicode=true&characterEncoding=UTF-8&useSSL=false&serverTimezone=Asia/Shanghai
username: root
password: 123456
filters: stat
initialSize: 0
minIdle: 1
maxActive: 200
maxWait: 10000
time-between-eviction-runs-millis: 60000
min-evictable-idle-time-millis: 200000
testWhileIdle: true
testOnBorrow: true
validationQuery: select 1
liquibase:
change-log: classpath:liquibase/master.xml
enabled: true # 当实际使用的数据库不支持liquibase,如 mariadb 时,将这个参数设置为false
database:
name: mp # 改成对应的数据库名称
- 配置 master.xml 文件
<?xml version="1.0" encoding="utf-8"?>
<databaseChangeLog
xmlns="http://www.liquibase.org/xml/ns/dbchangelog"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.liquibase.org/xml/ns/dbchangelog
http://www.liquibase.org/xml/ns/dbchangelog/dbchangelog-3.5.xsd">
<include file="liquibase/changelog/000_initial_schema.xml" relativeToChangelogFile="false"/>
</databaseChangeLog>
- 配置 000_initial_schema.xml 文件
<?xml version="1.0" encoding="utf-8"?>
<databaseChangeLog
xmlns="http://www.liquibase.org/xml/ns/dbchangelog"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.liquibase.org/xml/ns/dbchangelog http://www.liquibase.org/xml/ns/dbchangelog/dbchangelog-3.5.xsd">
<property name="now" value="now()" dbms="mysql"/>
<property name="autoIncrement" value="true"/>
<!--这里 id 要唯一, 可以采用自增策略, path 为所要执行sql的文件位置, 后续修改数据库可以写多个 changeSet -->
<changeSet id="00000000000001" author="Yaeovo">
<sqlFile dbms="mysql" endDelimiter=";" encoding="UTF-8" path="liquibase/data/init_schema_230414.sql"/>
</changeSet>
</databaseChangeLog>
- 文件目录如下 :

- 库 / 表初始化
package com.itheima.mp.config.init;
import org.springframework.core.io.ClassPathResource;
import org.xml.sax.Attributes;
import org.xml.sax.SAXException;
import org.xml.sax.XMLReader;
import org.xml.sax.helpers.DefaultHandler;
import javax.xml.parsers.SAXParser;
import javax.xml.parsers.SAXParserFactory;
import java.util.ArrayList;
import java.util.List;
import java.util.stream.Collectors;
/**
* @author YiHui
* @date 2023/3/2
*/
public class DbChangeSetLoader {
public static XMLReader getInstance() throws Exception {
// javax.xml.parsers.SAXParserFactory 原生api获取factory
SAXParserFactory factory = SAXParserFactory.newInstance();
// javax.xml.parsers.SAXParser 原生api获取parse
SAXParser saxParser = factory.newSAXParser();
// 获取xml
return saxParser.getXMLReader();
}
public static List<ClassPathResource> loadDbChangeSetResources(String source) {
try {
XMLReader xmlReader = getInstance();
ChangeHandler logHandler = new ChangeHandler("include", "file");
xmlReader.setContentHandler(logHandler);
xmlReader.parse(new ClassPathResource(source.replace("classpath:", "").trim()).getFile().getPath());
List<String> changeSetFiles = logHandler.getSets();
List<ClassPathResource> result = new ArrayList<>();
ChangeHandler setHandler = new ChangeHandler("sqlFile", "path");
for (String set : changeSetFiles) {
xmlReader.setContentHandler(setHandler);
// 解析xml
xmlReader.parse(new ClassPathResource(set).getFile().getPath());
result.addAll(setHandler.getSets().stream().map(ClassPathResource::new).collect(Collectors.toList()));
setHandler.reset();
}
return result;
} catch (Exception e) {
throw new IllegalStateException("加载初始化脚本异常!");
}
}
public static class ChangeHandler extends DefaultHandler {
private List<String> sets = new ArrayList<>();
private final String tag;
private final String attr;
public ChangeHandler(String tag, String attr) {
this.tag = tag;
this.attr = attr;
}
@Override
public void startElement(String uri, String localName, String qName, Attributes attributes) throws SAXException {
if (tag.equals(qName)) {
sets.add(attributes.getValue(attr));
}
}
public List<String> getSets() {
return sets;
}
public void reset() {
sets.clear();
}
}
}
package com.itheima.mp.config.init;
import com.itheima.mp.util.SpringUtil;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.core.io.ClassPathResource;
import org.springframework.jdbc.core.JdbcTemplate;
import org.springframework.jdbc.datasource.init.DataSourceInitializer;
import org.springframework.jdbc.datasource.init.DatabasePopulator;
import org.springframework.jdbc.datasource.init.ResourceDatabasePopulator;
import org.springframework.util.CollectionUtils;
import javax.sql.DataSource;
import java.net.URI;
import java.sql.*;
import java.util.List;
import java.util.Map;
import java.util.Objects;
/**
* 表初始化,只有首次启动时,才会执行
*
* @author YiHui
* @date 2022/10/15
*/
@Slf4j
@Configuration
public class ForumDataSourceInitializer {
@Value("${database.name}")
private String database;
@Value("${spring.liquibase.enabled:true}")
private Boolean liquibaseEnable;
@Value("${spring.liquibase.change-log}")
private String liquibaseChangeLog;
@Bean
public DataSourceInitializer dataSourceInitializer(final DataSource dataSource) {
final DataSourceInitializer initializer = new DataSourceInitializer();
// 设置数据源
initializer.setDataSource(dataSource);
boolean enable = needInit(dataSource);
initializer.setEnabled(enable);
initializer.setDatabasePopulator(databasePopulator(enable));
return initializer;
}
private DatabasePopulator databasePopulator(boolean initEnable) {
final ResourceDatabasePopulator populator = new ResourceDatabasePopulator();
// 下面这种是根据sql文件来进行初始化;改成 liquibase 之后不再使用这种方案,由liquibase来统一管理表结构数据变更
if (initEnable && !liquibaseEnable) {
// fixme: 首次启动时, 对于不支持liquibase的数据库,如mariadb,采用主动初始化
// fixme 这种方式不支持后续动态的数据表结构更新、数据变更
populator.addScripts(DbChangeSetLoader.loadDbChangeSetResources(liquibaseChangeLog).toArray(new ClassPathResource[]{}));
populator.setSeparator(";");
log.info("非Liquibase管理数据库,请手动执行数据库表初始化!");
}
return populator;
}
/**
* 检测一下数据库中表是否存在,若存在则不初始化;否则基于 schema-all.sql 进行初始化表
*
* @param dataSource
* @return true 表示需要初始化; false 表示无需初始化
*/
private boolean needInit(DataSource dataSource) {
if (autoInitDatabase()) {
return true;
}
// 根据是否存在表来判断是否需要执行sql操作
JdbcTemplate jdbcTemplate = new JdbcTemplate(dataSource);
if (!liquibaseEnable) {
// 非liquibase做数据库版本管理的,根据用户来判断是否有初始化
List list = jdbcTemplate.queryForList("SELECT table_name FROM information_schema.TABLES where table_name = 'user_info' and table_schema = '" + database + "';");
return CollectionUtils.isEmpty(list);
}
// 对于liquibase做数据版本管控的场景,若使用的不是默认的pai_coding,则需要进行修订
List<Map<String, Object>> record = jdbcTemplate.queryForList("select * from DATABASECHANGELOG where ID='00000000000001' limit 1;");
if (CollectionUtils.isEmpty(record)) {
// 首次启动,需要初始化库表,直接返回
return true;
}
// 非首次启动时,判断记录对应的md5是否准确
if (Objects.equals(record.get(0).get("MD5SUM"), "8:a1a2d9943b746acf58476ae612c292fc")) {
// 这里主要是为了解决 <a href="https://github.com/itwanger/paicoding/issues/71">#71</a> 这个问题
jdbcTemplate.update("update DATABASECHANGELOG set MD5SUM='8:ee7d1b664e29fb551929db798a0bf167' where ID='00000000000001'");
}
return false;
}
/**
* 数据库不存在时,尝试创建数据库
*/
private boolean autoInitDatabase() {
// 查询失败,可能是数据库不存在,尝试创建数据库之后再次测试
// 数据库链接
URI url = URI.create(SpringUtil.getConfigOrElse("spring.datasource.url", "spring.dynamic.datasource.master.url").substring(5));
// 用户名
String uname = SpringUtil.getConfigOrElse("spring.datasource.username", "spring.dynamic.datasource.master.username");
// 密码
String pwd = SpringUtil.getConfigOrElse("spring.datasource.password", "spring.dynamic.datasource.master.password");
// 创建连接
try (Connection connection = DriverManager.getConnection("jdbc:mysql://" + url.getHost() + ":" + url.getPort() +
"?useUnicode=true&characterEncoding=UTF-8&useSSL=false", uname, pwd);
Statement statement = connection.createStatement()) {
// 查询数据库是否存在
ResultSet set = statement.executeQuery("select schema_name from information_schema.schemata where schema_name = '" + database + "'");
if (!set.next()) {
// 不存在时,创建数据库
String createDb = "CREATE DATABASE IF NOT EXISTS " + database;
connection.setAutoCommit(false);
statement.execute(createDb);
connection.commit();
log.info("创建数据库({})成功", database);
if (set.isClosed()) {
set.close();
}
return true;
}
set.close();
log.info("数据库已存在,无需初始化");
return false;
} catch (SQLException e2) {
throw new RuntimeException(e2);
}
}
}
package com.itheima.mp.util;
import org.springframework.beans.BeansException;
import org.springframework.boot.context.properties.bind.Binder;
import org.springframework.context.ApplicationContext;
import org.springframework.context.ApplicationContextAware;
import org.springframework.context.ApplicationEvent;
import org.springframework.context.EnvironmentAware;
import org.springframework.core.env.Environment;
import org.springframework.stereotype.Component;
/**
* @author YiHui
* @date 2022/8/29
*/
@Component
public class SpringUtil implements ApplicationContextAware, EnvironmentAware {
private volatile static ApplicationContext context;
private volatile static Environment environment;
private static Binder binder;
@Override
public void setApplicationContext(ApplicationContext applicationContext) throws BeansException {
SpringUtil.context = applicationContext;
}
@Override
public void setEnvironment(Environment environment) {
SpringUtil.environment = environment;
binder = Binder.get(environment);
}
public static ApplicationContext getContext() {
return context;
}
/**
* 获取bean
*
* @param bean
* @param <T>
* @return
*/
public static <T> T getBean(Class<T> bean) {
return context.getBean(bean);
}
public static <T> T getBeanOrNull(Class<T> bean) {
try {
return context.getBean(bean);
} catch (Exception e) {
return null;
}
}
public static Object getBean(String beanName) {
return context.getBean(beanName);
}
public static Object getBeanOrNull(String beanName) {
try {
return context.getBean(beanName);
} catch (Exception e) {
return null;
}
}
/**
* 获取配置
*
* @param key
* @return
*/
public static String getConfig(String key) {
return environment.getProperty(key);
}
public static String getConfigOrElse(String mainKey, String slaveKey) {
String ans = environment.getProperty(mainKey);
if (ans == null) {
return environment.getProperty(slaveKey);
}
return ans;
}
/**
* 获取配置
*
* @param key
* @param val 配置不存在时的默认值
* @return
*/
public static String getConfig(String key, String val) {
return environment.getProperty(key, val);
}
/**
* 发布事件消息
*
* @param event
*/
public static void publishEvent(ApplicationEvent event) {
context.publishEvent(event);
}
/**
* 配置绑定类
*
* @return
*/
public static Binder getBinder() {
return binder;
}
}
- 这里提供一个建表SQL文件, 里面有三张表
article,article_detail,article_tag
SET NAMES utf8;
SET FOREIGN_KEY_CHECKS = 0;
-- ----------------------------
-- Table structure for `article`
-- ----------------------------
DROP TABLE IF EXISTS `article`;
CREATE TABLE `article` (
`id` int(10) unsigned NOT NULL AUTO_INCREMENT COMMENT '主键ID',
`user_id` int(10) unsigned NOT NULL DEFAULT '0' COMMENT '用户ID',
`article_type` tinyint(4) NOT NULL DEFAULT '1' COMMENT '文章类型:1-博文,2-问答',
`title` varchar(120) NOT NULL DEFAULT '' COMMENT '文章标题',
`short_title` varchar(120) NOT NULL DEFAULT '' COMMENT '短标题',
`picture` varchar(128) NOT NULL DEFAULT '' COMMENT '文章头图',
`summary` varchar(300) NOT NULL DEFAULT '' COMMENT '文章摘要',
`category_id` int(10) unsigned NOT NULL DEFAULT '0' COMMENT '类目ID',
`source` tinyint(4) NOT NULL DEFAULT '1' COMMENT '来源:1-转载,2-原创,3-翻译',
`source_url` varchar(128) NOT NULL DEFAULT '1' COMMENT '原文链接',
`offical_stat` int(10) unsigned NOT NULL DEFAULT '0' COMMENT '官方状态:0-非官方,1-官方',
`topping_stat` int(10) unsigned NOT NULL DEFAULT '0' COMMENT '置顶状态:0-不置顶,1-置顶',
`cream_stat` int(10) unsigned NOT NULL DEFAULT '0' COMMENT '加精状态:0-不加精,1-加精',
`status` tinyint(4) NOT NULL DEFAULT '0' COMMENT '状态:0-未发布,1-已发布',
`deleted` tinyint(4) NOT NULL DEFAULT '0' COMMENT '是否删除',
`create_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`update_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '最后更新时间',
PRIMARY KEY (`id`),
KEY `idx_category_id` (`category_id`),
KEY `idx_title` (`title`),
KEY `idx_short_title` (`short_title`)
) ENGINE=InnoDB AUTO_INCREMENT=108 DEFAULT CHARSET=utf8mb4 COMMENT='文章表';
-- ----------------------------
-- Records of `article`
-- ----------------------------
BEGIN;
INSERT INTO `article` VALUES ('1', '1', '1', '技术派全方位视角解读', '关于技术派', '', '技术派的使用说明介绍', '1', '2', '', '0', '0', '0', '1', '0', '2023-01-13 19:15:58', '2023-01-13 19:15:58'), ('100', '1', '1', '分布式系统的38个知识点', '38个知识点', '', '天天说分布式分布式,那么我们是否知道什么是分布式,分布式会遇到什么问题,有哪些理论支撑,有哪些经典的应对方案,业界是如何设计并保证分布式系统的高可用呢?\n\n1.架构设计\n这一节将从一些经典的开源系统架构设计出发,来看一下,如何设计一个高质量的分布式系统;', '1', '2', '', '0', '1', '0', '1', '0', '2022-10-08 19:12:32', '2023-04-15 20:12:47'), ('101', '1', '1', '分布式系统的8个谬误', '8个经典谬误', '', '你在分布式系统上工作吗?微服务,Web API,SOA,Web服务器,应用服务器,数据库服务器,缓存服务器,负载均衡器 - 如果这些描述了系统设计中的组件,那么答案是肯定的。分布式系统由许多计算机组成,这些计算机协调以实现共同的目标。\n\n20多年前,Peter Deutsch和James Gosling定义了分布式计算的8个谬误。这些是许多开发人员对分布式系统做出的错误假设。从长远来看,这些通常被证明是错误的,导致难以修复错误。', '1', '2', '', '0', '1', '0', '1', '0', '2022-10-08 19:13:38', '2023-04-15 20:13:31'), ('102', '1', '1', '分布式系统的特征、瓶颈以及性能指标介绍', '分布式系统概要', 'https://spring.hhui.top/spring-blog/imgs/220819/logo.jpg', '分布式的概念存在年头有点久了,在正式进入我们《分布式专栏》之前,感觉有必要来聊一聊,什么是分布式,分布式特点是什么,它又有哪些问题,在了解完这个概念之后,再去看它的架构设计,理论奠基可能帮助会更大', '1', '2', '', '0', '1', '0', '1', '0', '2022-10-08 19:14:17', '2023-04-15 20:14:07'), ('103', '2', '1', 'ceshibug', '', '', '>整体阅读时间,在40分钟左右。大家好,我是楼仔!常见的消息队列很多,主要包括RabbitMQ、Kafka、RocketMQ和ActiveMQ,相关的选型可以看我之前的系列,这篇文章只讲RabbitMQ,先讲原理,后搞实战。文章很长,如果你能一次性看完,“', '1', '2', '', '0', '0', '0', '1', '0', '2023-01-13 19:54:17', '2023-01-13 19:54:17'), ('104', '4', '1', '二哥的 Java 进阶之路.pdf 开放下载了,GitHub 星标 7700+,太赞了!', '', '', '小册名字:二哥的Java进阶之路小册作者:沉默王二小册品质:能在GitHub取得7600star自认为品质是有目共睹的,尤其是国内还有不少小伙伴在访问GitHub的时候很不顺利。小册风格:通俗易懂、风趣幽默、深度解析,新手可以拿来入门,老手可以拿来进阶,重要的知识,比如说面试高频的内容会从应用到源码挖个底朝天,还会穿插介绍一些计算机底层知识,力求讲个明白)小册简介:这是一份通俗易懂、风趣幽默的Java学习指南,内容涵', '1', '2', '', '1', '0', '0', '1', '0', '2023-04-15 15:25:17', '2023-04-15 16:00:32'), ('105', '4', '1', '官宣:技术派上线了!⭐️一款好用又强大的开源社区,学编程,就上技术派?', '', '/forum/image/20230415081529547_1.jpg', '一个基于 Spring Boot、MyBatis-Plus、MySQL、Redis、ElasticSearch、MongoDB、Docker、RabbitMQ 等技术栈实现的社区系统,采用主流的互联网技术架构、全新的UI设计、支持一键源码部署,拥有完整的文章&教程发布/搜索/评论/统计流程等,代码完全开源,没有任何二次封装,是一个非常适合二次开发/实战的现代化社区项目? ', '1', '2', '', '1', '0', '0', '1', '0', '2023-04-15 16:03:43', '2023-04-15 20:15:31'), ('106', '4', '1', '对标大厂的技术派详细方案设计,务必要看', '', '', '这个项目诞生的背景和企业内生的需求不太一样,主要是某一天二哥说,“我们一起搞事吧”,楼仔问,“搞什么”,然后这个项目的需求就来了言归正传,我们主要的目的是希望打造一个切实可用的项目,依托于这个项目,将java从业者所用到的技术栈真实的展现出来,对于经验不是那么足的小伙伴,可以在一个真实的系统上,理解到自己学习的知识点是如何落地的,同时也能真实的了解一个项目是从0到1实现的全过程系统模块介绍系统架构基于社区系统的分层特点,将整个系统架构划分为展示层,应用层,服务层,如下图展示层其中展示层主要为用', '1', '2', '', '1', '0', '0', '1', '0', '2023-04-15 20:00:49', '2023-04-15 20:00:49'), ('107', '4', '1', '技术派的知识星球,开通啦!附 120 篇技术派的详细教程!', '', '', '大家好呀,我是楼仔。上周推出了我们的开源项目技术派,大家好评如潮,很多同学都想学习这个项目,为了更好带大家一起飞,我们今天正式推出技术派的知识星球。什么是知识星球呢?你可以理解为高品质社群,方便大家跟着我们一起学习。01星球介绍先来介绍下星球的三位联合创始人:楼仔:8年一线大厂后端经验(百度/小米/美团),技术派团队负责人,擅长高并发、架构、源码,有很强的项目/团队管理、职业规划能力。沉默王二:GitHub星标6400k开源知识库《Java程序员进阶之路》作者,CSDN两届博客之星,掘金/知乎Java领域优', '1', '2', '', '1', '0', '0', '1', '0', '2023-04-15 20:07:49', '2023-04-15 20:07:49');
COMMIT;
-- ----------------------------
-- Table structure for `article_detail`
-- ----------------------------
DROP TABLE IF EXISTS `article_detail`;
CREATE TABLE `article_detail` (
`id` int(10) unsigned NOT NULL AUTO_INCREMENT COMMENT '主键ID',
`article_id` int(10) unsigned NOT NULL DEFAULT '0' COMMENT '文章ID',
`version` int(10) unsigned NOT NULL DEFAULT '0' COMMENT '版本号',
`content` longtext COMMENT '文章内容',
`deleted` tinyint(4) NOT NULL DEFAULT '0' COMMENT '是否删除',
`create_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`update_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '最后更新时间',
PRIMARY KEY (`id`),
UNIQUE KEY `idx_article_version` (`article_id`,`version`)
) ENGINE=InnoDB AUTO_INCREMENT=12 DEFAULT CHARSET=utf8mb4 COMMENT='文章详情表';
-- ----------------------------
-- Records of `article_detail`
-- ----------------------------
BEGIN;
INSERT INTO `article_detail` VALUES ('1', '100', '2', '\n> 大家好我是咸鱼了大半年的一灰灰,终于放暑假了,把小孩送回老家,作为咸鱼的我也可以翻翻身了,接下来将趁着暑假的这段时间,将准备一个全新的分布式专栏,为了给大家提供更好的阅读体验,可以再我的个人站点上查看系列的专栏内容:\n>\n> [https://hhui.top/分布式](https://hhui.top/分布式)\n>\n\n天天说分布式分布式,那么我们是否知道什么是分布式,分布式会遇到什么问题,有哪些理论支撑,有哪些经典的应对方案,业界是如何设计并保证分布式系统的高可用呢?\n\n## 1.架构设计\n\n这一节将从一些经典的开源系统架构设计出发,来看一下,如何设计一个高质量的分布式系统;\n\n而一般的设计出发点,无外乎\n\n- 冗余:简单理解为找个备胎,现任挂掉之后,备胎顶上\n- 拆分:不能让一个人承担所有的重任,拆分下,每个人负担一部分,压力均摊\n\n\n### 1.1 主备架构\n\n给现有的服务搭建一个备用的服务,两者功能完全一致,区别在于平时只有主应用对外提供服务能力;而备应用则只需要保证与主应用能力一致,随时待机即可,并不用对外提供服务;当主应用出现故障之后,将备应用切换为主应用,原主应用下线;迅速的主备切换可以有效的缩短故障时间\n\n\n\n基于上面的描述,主备架构特点比较清晰\n\n- 采用冗余的方案,加一台备用服务\n- 缺点就是资源浪费\n\n\n\n其次就是这个架构模型最需要考虑的则是如何实现主备切换?\n\n- 人工\n- VIP(虚拟ip) + keepalived 机制\n\n### 1.2 主从架构\n\n主从一般又叫做读写分离,主提供读写能力,而从则只提供读能力\n\n鉴于当下的互联网应用,绝大多数都是读多写少的场景;读更容易成为性能瓶颈,所以采用读写分离,可以有效的提高整个集群的响应能力\n\n主从架构可以区分为:一主多从 + 一主一从再多从,以mysql的主从架构模型为例进行说明\n\n\n\n\n\n\n主从模式的主要特点在于\n\n- 添加从,源头依然是数据冗余的思想\n- 读写分离:主负责读写,从只负责读,可以视为负载均衡策略\n- 从需要向主同步数据,所若有的从都同步与主,对主的压力依然可能很大;所以就有了主从从的模式\n\n关键问题则在于\n\n- 主从延迟\n- 主的写瓶颈\n- 主挂之后如何选主\n\n\n\n\n### 1.3 多主多从架构\n\n一主多从面临单主节点的瓶颈问题,那就考虑多主多从的策略,同样是主负责提供读写,从提供读;\n\n但是这里有一个核心点在于多主之间的数据同步,如何保证数据的一致性是这个架构模型的重点\n\n如MySql的双主双从可以说是一个典型的应用场景,在实际使用的时候除了上面的一致性之外,还需要考虑主键id冲突的问题\n\n\n### 1.4 普通集群模式\n\n无主节点,集群中所有的应用职能对等,没有主次之分(当下绝大多数的业务服务都属于这种),一个请求可以被集群中任意一个服务响应;\n\n这种也可以叫做去中心化的设计模式,如redis的集群模式,eureka注册中心,以可用性为首要目标\n\n\n\n对于普通集群模式而言,重点需要考虑的点在于\n\n- 资源竞争:如何确保一个资源在同一时刻只能被一个业务操作\n - 如现在同时来了申请退款和货物出库的请求,如果不对这个订单进行加锁,两个请求同时响应,将会导致发货又退款了,导致财货两失\n- 数据一致性:如何确保所有的实例数据都是一致的,或者最终是一致的\n - 如应用服务使用jvm缓存,那么如何确保所有实例的jvm缓存一致?\n - 如Eureka的分区导致不同的分区的注册信息表不一致\n\n\n\n### 1.5 数据分片架构\n\n> 这个分片模型的描述可能并不准确,大家看的时候重点理解一下这个思想\n\n前面几个的架构中,采用的是数据冗余的方式,即所有的实例都有一个全量的数据,而这里的数据分片,则从数据拆分的思路来处理,将全量的数据,通过一定规则拆分到多个系统中,每个系统包含部分的数据,减小单个节点的压力,主要用于解决数据量大的场景\n\n比如redis的集群方式,通过hash槽的方式进行分区\n\n如es的索引分片存储\n\n\n### 1.6 一灰灰的小结\n\n这一节主要从架构设计层面对当前的分布式系统所采用的方案进行了一个简单的归类与小结,并不一定全面,欢迎各位大佬留言指正\n\n\n\n基于冗余的思想:\n\n- 主备\n- 主从\n- 多主多从\n- 无中心集群\n\n基于拆分的思想:\n\n- 数据分片\n\n> 对于拆分这一块,我们常说的分库分表也体现的是这一思想\n\n\n\n## 2.理论基础\n\n这一小节将介绍分布式系统中的经典理论,如广为流程的CAP/BASE理论,一致性理论基础paxios,raft,信息交换的Gossip协议,两阶段、三阶段等\n\n本节主要内容参考自\n\n* [一致性算法-Gossip协议详解 - 腾讯云开发者社区-腾讯云](https://cloud.tencent.com/developer/article/1662426)\n* [P2P 网络核心技术:Gossip 协议 - 知乎](https://zhuanlan.zhihu.com/p/41228196)\n* [从Paxos到Raft,分布式一致性算法解析_mb5fdb0a87e2fa1的技术博客_51CTO博客](https://blog.51cto.com/u_15060467/2678779)\n* [【理论篇】浅析分布式中的 CAP、BASE、2PC、3PC、Paxos、Raft、ZAB - 知乎](https://zhuanlan.zhihu.com/p/338628717)\n\n### 2.1 CAP定理\n\nCAP 定理指出,分布式系统 **不可能** 同时提供下面三个要求:\n\n- Consistency:一致性\n - 操作更新完成并返回客户端之后,所有节点数据完全一致\n- Availability:可用性\n - 服务一直可用\n- Partition tolerance:分区容错性\n - 分布式系统在遇到某节点或网络分区故障的时候,仍然能够对外提供满足**一致性**和**可用性**的服务\n\n通常来讲P很难不保证,当服务部署到多台实例上时,节点异常、网络故障属于常态,根据不同业务场景进行选择\n\n对于服务有限的应用而言,首选AP,保证高可用,即使部分机器异常,也不会导致整个服务不可用;如绝大多数的前台应用都是这种\n\n对于数据一致性要求高的场景,如涉及到钱的支付结算,CP可能更重要了\n\n\n\n对于CAP的三种组合说明如下\n\n| 选择 | 说明 |\n| --- | --- |\n| CA | 放弃分区容错性,加强一致性和可用性,其实就是传统的单机场景 |\n| AP | 放弃一致性(这里说的一致性是强一致性),追求分区容错性和可用性,这是很多分布式系统设计时的选择,例如很多NoSQL系统就是如此 |\n| CP | 放弃可用性,追求一致性和分区容错性,基本不会选择,网络问题会直接让整个系统不可用 |\n\n\n\n ### 2.2 BASE理论\n\n base理论作为cap的延伸,其核心特点在于放弃强一致性,追求最终一致性\n\n- Basically Available: 基本可用\n - 指分布式系统在出现故障的时候,允许损失部分可用性,即保证核心可用\n - 如大促时降级策略\n- Soft State:软状态\n - 允许系统存在中间状态,而该中间状态不会影响系统整体可用性\n - MySql异步方式的主从同步,可能导致的主从数据不一致\n- Eventual Consistency:最终一致性\n - 最终一致性是指系统中的所有数据副本经过一定时间后,最终能够达到一致的状态\n\n\n\n基于上面的描述,可以看到BASE理论适用于大型高可用可扩展的分布式系统\n\n注意其不同于ACID的强一致性模型,而是通过牺牲强一致性 来获得可用性,并允许数据在一段时间内是不一致的,但最终达到一致状态\n\n\n\n\n### 2.3 PACELEC 定理\n\n> 这个真没听说过,以下内容来自:\n> * [Distributed System Design Patterns | by Nishant | Medium](https://medium.com/@nishantparmar/distributed-system-design-patterns-2d20908fecfc)\n\n- 如果有一个分区(\'P\'),分布式系统可以在可用性和一致性(即\'A\'和\'C\')之间进行权衡;\n- 否则(\'E\'),当系统在没有分区的情况下正常运行时,系统可以在延迟(\'L\')和一致性(\'C\')之间进行权衡。\n\n\n\n定理(PAC)的第一部分与CAP定理相同,ELC是扩展。整个论点假设我们通过复制来保持高可用性。因此,当失败时,CAP定理占上风。但如果没有,我们仍然必须考虑复制系统的一致性和延迟之间的权衡。\n\n\n### 2.4 Paxos共识算法\n\n> Paxos算法解决的问题是分布式共识性问题,即一个分布式系统中的各个进程如何就某个值(决议)通过共识达成一致\n\n基于上面这个描述,可以看出它非常适用于选举;其工作流程\n\n- 一个或多个提议进程 (Proposer) 可以发起提案 (Proposal),\n- Paxos算法使所有提案中的某一个提案,在所有进程中达成一致。 系统中的多数派同时认可该提案,即达成了一致\n\n角色划分:\n\n- Proposer: 提出提案Proposal,包含编号 + value\n- Acceptor: 参与决策,回应Proposers的提案;当一个提案,被半数以上的Acceptor接受,则该提案被批准\n - 每个acceptor只能批准一个提案\n- Learner: 不参与决策,获取最新的提案value\n\n\n### 2.5 Raft算法\n\n> 推荐有兴趣的小伙伴,查看\n> * [Raft 算法动画演示](http://thesecretlivesofdata.com/raft/)\n> * [Raft算法详解 - 知乎](https://zhuanlan.zhihu.com/p/32052223)\n\n\n为了解决paxos的复杂性,raft算法提供了一套更易理解的算法基础,其核心流程在于:\n\nleader接受请求,并转发给follow,当大部分follow响应之后,leader通知所有的follow提交请求、同时自己也提交请求并告诉调用方ok\n\n角色划分:\n\n- Leader:领导者,接受客户端请求,并向Follower同步请求,当数据同步到大多数节点上后告诉Follower提交日志\n- Follow: 接受并持久化Leader同步的数据,在Leader告之日志可以提交之后,提交\n- Candidate:Leader选举过程中的临时角色,向其他节点拉选票,得到多数的晋升为leader,选举完成之后不存在这个角色\n\n\n\n\n\n### 2.6 ZAB协议\n\n> ZAB(Zookeeper Atomic Broadcast) 协议是为分布式协调服务ZooKeeper专门设计的一种支持崩溃恢复的一致性协议,基于该协议,ZooKeeper 实现了一种 主从模式的系统架构来保持集群中各个副本之间的数据一致性。\n>\n> * [zookeeper核心之ZAB协议就这么简单!](https://segmentfault.com/a/1190000037550497)\n\n\n主要用于zk的数据一致性场景,其核心思想是Leader再接受到事务请求之后,通过给Follower,当半数以上的Follower返回ACK之后,Leader提交提案,并向Follower发送commit信息\n\n**角色划分**\n\n- Leader: 负责整个Zookeeper 集群工作机制中的核心\n - 事务请求的唯一调度和处理者,保证集群事务处理的顺序性\n - 集群内部各服务器的调度者\n- Follower:Leader的追随者\n - 处理客户端的非实物请求,转发事务请求给 Leader 服务器\n - 参与事务请求 Proposal 的投票\n - 参与 Leader 选举投票\n- Observer:是 zookeeper 自 3.3.0 开始引入的一个角色,\n - 它不参与事务请求 Proposal 的投票,\n - 也不参与 Leader 选举投票\n - 只提供非事务的服务(查询),通常在不影响集群事务处理能力的前提下提升集群的非事务处理能力。\n\n\n\n\n\n\n### 2.7 2PC协议\n\n> two-phase commit protocol,两阶段提交协议,主要是为了解决强一致性,中心化的强一致性协议\n\n**角色划分**\n\n- 协调节点(coordinator):中心化\n- 参与者节点(partcipant):多个\n\n**执行流程**\n\n协调节点接收请求,然后向参与者节点提交 `precommit`,当所有的参与者都回复ok之后,协调节点再给所有的参与者节点提交`commit`,所有的都返回ok之后,才表明这个数据确认提交\n\n当第一个阶段,有一个参与者失败,则所有的参与者节点都回滚\n\n\n\n\n\n\n**特点**\n\n优点在于实现简单\n\n缺点也很明显\n\n- 协调节点的单点故障\n- 第一阶段全部ack正常,第二阶段存在部分参与者节点异常时,可能出现不一致问题\n\n\n\n### 2.8 3PC协议\n\n> [分布式事务:两阶段提交与三阶段提交 - SegmentFault 思否](https://segmentfault.com/a/1190000012534071)\n>\n\n在两阶段的基础上进行扩展,将第一阶段划分两部,cancommit + precommit,第三阶段则为 docommit\n\n\n**第一阶段 cancommit**\n\n该阶段协调者会去询问各个参与者是否能够正常执行事务,参与者根据自身情况回复一个预估值,相对于真正的执行事务,这个过程是轻量的\n\n**第二阶段 precommit**\n\n本阶段协调者会根据第一阶段的询盘结果采取相应操作,若所有参与者都返回ok,则协调者向参与者提交事务执行(单不提交)通知;否则通知参与者abort回滚\n\n**第三阶段 docommit**\n\n如果第二阶段事务未中断,那么本阶段协调者将会依据事务执行返回的结果来决定提交或回滚事务,若所有参与者正常执行,则提交;否则协调者+参与者回滚\n\n\n在本阶段如果因为协调者或网络问题,导致参与者迟迟不能收到来自协调者的 commit 或 rollback 请求,那么参与者将不会如两阶段提交中那样陷入阻塞,而是等待超时后继续 commit,相对于两阶段提交虽然降低了同步阻塞,但仍然无法完全避免数据的不一致\n\n\n\n**特点**\n\n- 降低了阻塞与单点故障:\n - 参与者返回 CanCommit 请求的响应后,等待第二阶段指令,若等待超时/协调者宕机,则自动 abort,降低了阻塞;\n - 参与者返回 PreCommit 请求的响应后,等待第三阶段指令,若等待超时/协调者宕机,则自动 commit 事务,也降低了阻塞;\n- 数据不一致问题依然存在\n - 比如第三阶段协调者发出了 abort 请求,然后有些参与者没有收到 abort,那么就会自动 commit,造成数据不一致\n\n\n\n\n### 2.9 Gossip协议\n\n> Gossip 协议,顾名思义,就像流言蜚语一样,利用一种随机、带有传染性的方式,将信息传播到整个网络中,并在一定时间内,使得系统内的所有节点数据一致。Gossip 协议通过上面的特性,可以保证系统能在极端情况下(比如集群中只有一个节点在运行)也能运行\n>\n> * [P2P 网络核心技术:Gossip 协议 - 知乎](https://zhuanlan.zhihu.com/p/41228196)\n\n主要用在分布式数据库系统中各个副本节点同步数据之用,这种场景的一个最大特点就是组成的网络的节点都是对等节点,是非结构化网络\n\n\n**工作流程**\n\n- 周期性的传播消息,通常周期时间为1s\n- 被感染的节点,随机选择n个相邻节点,传播消息\n- 每次传播消息都选择还没有发送过的节点进行传播\n- 收单消息的节点,不会传播给向它发送消息的节点\n\n\n\n\n\n**特点**\n\n- 扩展性:允许节点动态增加、减少,新增的节点状态最终会与其他节点一致\n- 容错:网络中任意一个节点宕机重启都不会影响消息传播\n- 去中心化:不要求中心节点,所有节点对等,任何一个节点无需知道整个网络状况,只要网络连通,则一个节点的消息最终会散播到整个网络\n- 一致性收敛:协议中的消息会以一传十、十传百一样的指数级速度在网络中快速传播,因此系统状态的不一致可以在很快的时间内收敛到一致。消息传播速度达到了 logN\n- 简单:Gossip 协议的过程极其简单,实现起来几乎没有太多复杂性\n\n**缺点**\n\n- 消息延迟:节点只会随机向少数几个节点发送消息,消息最终是通过多个轮次的散播而到达全网的,因此使用 Gossip 协议会造成不可避免的消息延迟\n- 消息冗余:节点会定期随机选择周围节点发送消息,而收到消息的节点也会重复该步骤,导致消息的冗余\n\n\n\n\n### 2.10 一灰灰的小结\n\n本节主要介绍的是分布式系统设计中的一些常见的理论基石,如分布式中如何保障一致性,如何对一个提案达成共识\n\n- BASE,CAP,PACELEC理论:构建稳定的分布式系统应该考虑的方向\n- paxos,raft共识算法\n- zab一致性协议\n- gossip消息同步协议\n\n## 3.算法\n\n这一节将主要介绍下分布式系统中的经典的算法,比如常用于分区的一致性hash算法,适用于一致性的Quorum NWR算法,PBFT拜占庭容错算法,区块链中大量使用的工作量证明PoW算法等\n\n### 3.1 一致性hash算法\n\n一致性hash算法,主要应用于数据分片场景下,有效降低服务的新增、删除对数据复制的影响\n\n通过对数据项的键进行哈希处理映射其在环上的位置,然后顺时针遍历环以查找位置大于该项位置的第一个节点,将每个由键标识的数据分配给hash环中的一个节点\n\n\n\n一致散列的主要优点是增量稳定性; 节点添加删除,对整个集群而言,仅影响其直接邻居,其他节点不受影响。\n\n**注意:**\n\n- redis集群实现了一套hash槽机制,其核心思想与一致性hash比较相似\n\n\n### 3.2 Quorum NWR算法\n\n> 用来保证数据冗余和最终一致性的投票算法,其主要数学思想来源于鸽巢原理\n>\n> * [分布式系统之Quorum (NRW)算法-阿里云开发者社区](https://developer.aliyun.com/article/53498)\n\n- N 表示副本数,又叫做复制因子(Replication Factor)。也就是说,N 表示集群中同一份数据有多少个副本\n- W,又称写一致性级别(Write Consistency Level),表示成功完成 W 个副本更新写入,才会视为本次写操作成功\n- R 又称读一致性级别(Read Consistency Level),表示读取一个数据对象时需要读 R 个副本, 才会视为本次读操作成功\n\nQuorum NWR算法要求每个数据拷贝对象 都可以投1票,而每一个操作的执行则需要获取最小的读票数,写票数;通常来讲写票数W一般需要超过N/2,即我们通常说的得到半数以上的票才表示数据写入成功\n\n事实上当W=N、R=1时,即所谓的WARO(Write All Read One)。就是CAP理论中CP模型的场景\n\n\n### 3.3 PBFT拜占庭算法\n\n拜占庭算法主要针对的是分布式场景下无响应,或者响应不可信的情况下的容错问题,其核心分三段流程,如下\n\n\n\n假设集群节点数为 N,f个故障节点(无响应)和f个问题节点(无响应或错误响应),f+1个正常节点,即 3f+1=n\n\n- 客户端向主节点发起请求,主节点接受请求之后,向其他节点广播 pre-prepare 消息\n- 节点接受pre-prepare消息之后,若同意请求,则向其他节点广播 prepare 消息;\n- 当一个节点接受到2f+1个prepare新消息,则进入commit阶段,并广播commit消息\n- 当收到 2f+1 个 commit 消息后(包括自己),代表大多数节点已经进入 commit 阶段,这一阶段已经达成共识,于是节点就会执行请求,写入数据\n\n\n\n相比 Raft 算法完全不适应有人作恶的场景,PBFT 算法能容忍 (n 1)/3 个恶意节点 (也可以是故障节点)。另外,相比 PoW 算法,PBFT 的优点是不消耗算 力。PBFT 算法是O(n ^ 2) 的消息复杂度的算法,所以以及随着消息数 的增加,网络时延对系统运行的影响也会越大,这些都限制了运行 PBFT 算法的分布式系统 的规模,也决定了 PBFT 算法适用于中小型分布式系统\n\n\n\n### 3.4 PoW算法\n\n工作量证明 (Proof Of Work,简称 PoW),同样应用于分布式下的一致性场景,区别于前面的raft, pbft, paxos采用投票机制达成共识方案,pow采用工作量证明\n\n客户端需要做一定难度的工作才能得出一个结果,验证方却很容易通过结果来检查出客户端是不是做了相应的工作,通过消耗一定工作浪,增加消息伪造的成本,PoW以区块链中广泛应用而广为人知,下面以区块链来简单说一下PoW的算法应用场景\n\n以BTC的转账为例,A转n个btc给B,如何保证不会同时将这n个币转给C?\n\n- A转账给B,交易信息记录在一个区块1中\n- A转账给C,交易信息被记录在另一个区块2中\n- 当区块1被矿工成功提交到链上,并被大多数认可(通过校验区块链上的hash值验证是否准确,而这个hash值体现的是矿工的工作量),此时尚未提交的区块2则会被抛弃\n- 若区块1被提交,区块2也被提交,各自有部分人认可,就会导致分叉,区块链中采用的是优选最长的链作为主链,丢弃分叉的部分(这就属于区块链的知识点了,有兴趣的小伙伴可以扩展下相关知识点,这里就不展开了)\n\n\nPoW的算法,主要应用在上面的区块提交验证,通过hash值计算来消耗算力,以此证明矿工确实有付出,得到多数认可的可以达成共识\n\n\n### 3.5 一灰灰的小结\n\n本节主要介绍了下当前分布式下常见的算法,\n\n- 分区的一致性hash算法: 基于hash环,减少节点动态增加减少对整个集群的影响;适用于数据分片的场景\n- 适用于一致性的Quorum NWR算法: 投票算法,定义如何就一个提案达成共识\n- PBFT拜占庭容错算法: 适用于集群中节点故障、或者不可信的场景\n- 区块链中大量使用的工作量证明PoW算法: 通过工作量证明,认可节点的提交\n\n\n## 4.技术思想\n\n这一节的内容相对前面几个而言,并不太容易进行清晰的分类;主要包含一些高质量的分布式系统的实践中,值得推荐的设计思想、技术细节\n\n### 4.1 CQRS\n\n> * [DDD 中的那些模式 — CQRS - 知乎](https://zhuanlan.zhihu.com/p/115685384)\n> * [详解CQRS架构模式_架构_Kislay Verma_InfoQ精选文章](https://www.infoq.cn/article/wdlpjosudoga34jutys9)\n\nCommand Query Responsibility Segregation 即我们通俗理解的读写分离,其核心思想在于将两类不同操作进行分离,在独立的服务中实现\n\n\n\n用途在于将领域模型与查询功能进行分离,让一些复杂的查询摆脱领域模型的限制,以更为简单的 DTO 形式展现查询结果。同时分离了不同的数据存储结构,让开发者按照查询的功能与要求更加自由的选择数据存储引擎\n\n\n### 4.2 复制负载平衡服务\n\n> * [分布式系统设计:服务模式之复制负载平衡服务 - 知乎](https://zhuanlan.zhihu.com/p/34191846)\n> * [负载均衡调度算法大全 | 菜鸟教程](https://www.runoob.com/w3cnote/balanced-algorithm.html)\n\n复制负载平衡服务(Replication Load Balancing Service, RLBS),可以简单理解为我们常说的负载均衡,多个相同的服务实例构建一个集群,每个服务都可以响应请求,负载均衡器负责请求的分发到不同的实例上,常见的负载算法\n\n\n| 算法 | 说明 | 特点 |\n| --- | --- | --- |\n| 轮询 | 请求按照顺序依次分发给对应的服务器 | 优点简单,缺点在于未考虑不同服务器的实际性能情况 |\n| 加权轮询 | 权重高的被分发更多的请求 | 优点:充分利用机器的性能 |\n| 最少连接数 | 找连接数最少的服务器进行请求分发,若所有服务器相同的连接数,则找第一个选择的 | 目的是让优先让空闲的机器响应请求 |\n| 少连接数慢启动时间 | 刚启动的服务器,在一个时间段内,连接数是有限制且缓慢增加 | 避免刚上线导致大量的请求分发过来而超载 |\n| 加权最少连接 | 平衡服务性能 + 最少连接数 | |\n| 基于代理的自适应负载均衡 | 载主机包含一个自适用逻辑用来定时监测服务器状态和该服务器的权重 | |\n| 源地址哈希法 | 获取客户端的IP地址,通过哈希函映射到对应的服务器 | 相同的来源请求都转发到相同的服务器上 |\n| 随机 | 随机算法选择一台服务器 | |\n| 固定权重 | 最高权重只有在其他服务器的权重值都很低时才使用。然而,如果最高权重的服务器下降,则下一个最高优先级的服务器将为客户端服务 | 每个真实服务器的权重需要基于服务器优先级来配置|\n| 加权响应 | 服务器响应越小其权重越高,通常是基于心跳来判断机器的快慢 | 心跳的响应并不一定非常准确反应服务情况 |\n\n\n### 4.3 心跳机制\n\n在分布式环境里中,如何判断一个服务是否存活,当下最常见的方案就是心跳\n\n比如raft算法中的leader向所有的follow发送心跳,表示自己还健在,避免发生新的选举;\n\n比如redis的哨兵机制,也是通过ping/pong的心跳来判断节点是否下线,是否需要选新的主节点;\n\n再比如我们日常的业务应用得健康监测,判断服务是否正常\n\n\n### 4.4 租约机制\n\n租约就像一个锁,但即使客户端离开,它也能工作。客户端请求有限期限的租约,之后租约到期。如果客户端想要延长租约,它可以在租约到期之前续订租约。\n\n\n租约主要是了避免一个资源长久被某个对象持有,一旦对方挂了且不会主动释放的问题;在实际的场景中,有两个典型的应用\n\n**case1 分布式锁**\n\n业务获取的分布式锁一般都有一个有效期,若有效期内没有主动释放,这个锁依然会被释放掉,其他业务也可以抢占到这把锁;因此对于持有锁的业务方而言,若发现在到期前,业务逻辑还没有处理完,则可以续约,让自己继续持有这把锁\n\n典型的实现方式是redisson的看门狗机制\n\n**case2 raft算法的任期**\n\n在raft算法中,每个leader都有一个任期,任期过后会重新选举,而Leader为了避免重新选举,一般会定时发送心跳到Follower进行续约\n\n\n### 4.5 Leader & Follow\n\n这个比较好理解,上面很多系统都采用了这种方案,特别是在共识算法中,由领导者负责代表整个集群做出决策,并将决策传播到所有其他服务器\n\n领导者选举在服务器启动时进行。每个服务器在启动时都会启动领导者选举,并尝试选举领导者。除非选出领导者,否则系统不接受任何客户端请求\n\n### 4.6 Fencing\n\n在领导者-追随者模式中,当领导者失败时,不可能确定领导者已停止工作,如慢速网络或网络分区可能会触发新的领导者选举,即使前一个领导者仍在运行并认为它仍然是活动的领导者\n\nFencint是指在以前处于活动状态的领导者周围设置围栏,使其无法访问集群资源,从而停止为任何读/写请求提供服务\n\n- 资源屏蔽:系统会阻止以前处于活动状态的领导者访问执行基本任务所需的资源。\n- 节点屏蔽:系统会阻止以前处于活动状态的领导者访问所有资源。执行此操作的常见方法是关闭节点电源或重置节点。\n\n### 4.7 Quorum法定人数\n\n法定人数,常见于选举、共识算法中,当超过Quorum的节点数确认之后,才表示这个提案通过(数据更新成功),通常这个法定人数为 = 半数节点 + 1\n\n### 4.8 High-Water mark高水位线\n\n\n高水位线,跟踪Leader(领导者)上的最后一个日志条目,且该条目已成功复制到>quorum(法定人数)的Follow(跟谁者),即表示这个日志被整个集群接受\n\n日志中此条目的索引称为高水位线索引。领导者仅公开到高水位线索引的数据。\n\n如Kafka:为了处理非可重复读取并确保数据一致性,Kafka broker会跟踪高水位线,这是特定分区的最大偏移量。使用者只能看到高水位线之前的消息。\n\n\n### 4.9 Phi 累计故障检测\n\nPhi Accrual Failure Detection,使用历史检测信号信息使阈值自适应\n\n通用的应计故障检测器不会判断服务器是否处于活动状态,而是输出有关服务器的可疑级别。\n\n如Cassandra(Facebook开源的分布式NoSql数据库)使用 Phi 应计故障检测器算法来确定群集中节点的状态\n\n### 4.10 Write-ahead Log预写日志\n\n\n预写日志记录是解决操作系统中文件系统不一致的问题的高级解决方案,当我们提交写到操作系统的文件缓存,此时业务会认为已经提交成功;但是在文件缓存与实际写盘之间会有一个时间差,若此时机器宕机,会导致缓存中的数据丢失,从而导致完整性缺失\n\n为了解决这个问题,如mysql,es等都采用了预写日志的机制来避免这个问题\n\nMySql:\n\n- 事务提交的流程中,先写redolog precommit, 然后写binlog,最后再redolog commit;当redolog记录成功之后,才表示事务执行成功;\n- 因此当出现上面的宕机恢复时,则会加载redologo,然后重放对应的命令,来恢复未持久化的数据\n\nElasticSearch:\n\n- 在内存中数据生成段写到操作系统文件缓存前,会先写事务日志,出现异常时,也是从事务日志进行恢复\n\n### 4.11 分段日志\n\n将日志拆分为多个较小的文件,而不是单个大文件,以便于操作。\n\n单个日志文件在启动时读取时可能会增长并成为性能瓶颈。较旧的日志会定期清理,并且很难对单个大文件执行清理操作。\n\n\n单个日志拆分为多个段。日志文件在指定的大小限制后滚动。使用日志分段,需要有一种将逻辑日志偏移量(或日志序列号)映射到日志段文件的简单方法。\n\n\n这个其实也非常常见,比如我们实际业务应用配置的log,一般都是按天、固定大小进行拆分,并不会把所有的日志都放在一个日志文件中\n\n\n再比如es的分段存储,一个段就是一个小的存储文件\n\n\n\n### 4.12 checksum校验\n\n在分布式系统中,在组件之间移动数据时,从节点获取的数据可能会损坏。\n\n计算校验和并将其与数据一起存储。\n\n要计算校验和,请使用 MD5、SHA-1、SHA-256 或 SHA-512 等加密哈希函数。哈希函数获取输入数据并生成固定长度的字符串(包含字母和数字);此字符串称为校验和。\n\n当系统存储某些数据时,它会计算数据的校验和,并将校验和与数据一起存储。当客户端检索数据时,它会验证从服务器接收的数据是否与存储的校验和匹配。如果没有,则客户端可以选择从另一个副本检索该数据。\n\nHDFS和Chubby将每个文件的校验和与数据一起存储。\n\n### 4.13 一灰灰的小结\n\n这一节很多内容来自下面这篇博文,推荐有兴趣的小伙伴查看原文\n\n* [Distributed System Design Patterns | by Nishant | Medium](https://medium.com/@nishantparmar/distributed-system-design-patterns-2d20908fecfc)\n\n这一节主要简单的介绍了下分布式系统中应用到的一些技术方案,如有对其中某个技术有兴趣的小伙伴可以留言,后续会逐一进行补全\n\n\n## 5.分布式系统解决方案\n\n最后再介绍一些常见的分布式业务场景及对应的解决方案,比如全局唯一的递增ID-雪花算法,分布式系统的资源抢占-分布式锁,分布式事务-2pc/3pc/tcc ,分布式缓存等\n\n### 5.1 缓存\n\n缓存实际上并不是分布式独有的,这里把它加进来,主要是因为实在是应用得太广了,无论是应用服务、基础软件工具还是操作系统,大量都可以见到缓存的身影\n\n缓存的核心思想在于: 借助更高效的IO方式,来替代代价昂贵的IO方式\n\n如:\n\n- redis的性能高于mysql\n- 如内存的读写,远高于磁盘IO,文件IO\n- 磁盘顺序读写 > 随机读写\n\n\n\n用好缓存可以有效提高应用性能,下面以一个普通的java前台应用为例说明\n\n- JVM缓存 -> 分布式缓存(redis/memcache) -> mysql缓存 -> 操作系统文件缓存 -> 磁盘文件\n\n缓存面临的核心问题,则在于\n\n- 一致性问题:缓存与db的一致性如何保障(相信大家都听说过或者实际处理过这种问题)\n- 数据完整性:比如常见的先写缓存,异步刷新到磁盘,那么缓存到磁盘刷新这段时间内,若宕机导致数据丢失怎么办?\n - TIP: 上面这个问题可以参考mysql的redolog\n\n\n\n\n### 5.2 全局唯一ID\n\n在传统的单体架构中,业务id基本上是依赖于数据库的自增id来处理;当我们进入分布式场景时,如我们常说的分库分表时,就需要我们来考虑如何实现全局唯一的业务id了,避免出现在分表中出现冲突\n\n\n\n\n全局唯一ID解决方案:\n\n- uuid\n- 数据库自增id表\n- redis原子自增命令\n- 雪花算法 (原生的,扩展的百度UidGenerator, 美团Leaf等)\n- Mist 薄雾算法\n\n\n\n\n### 5.3 分布式锁\n\n常用于分布式系统中资源控制,只有持有锁的才能继续操作,确保同一时刻只会有一个实例访问这个资源\n\n\n\n\n常见的分布式锁有\n\n* 基于数据库实现分布式锁\n* [Redis实现分布式锁(应用篇) | 一灰灰Learning](https://hhui.top/spring-db/09.%E5%AE%9E%E4%BE%8B/20.201030-springboot%E7%B3%BB%E5%88%97%E6%95%99%E7%A8%8Bredis%E5%AE%9E%E7%8E%B0%E5%88%86%E5%B8%83%E5%BC%8F%E9%94%81%E5%BA%94%E7%94%A8%E7%AF%87/)\n* [从0到1实现一个分布式锁 | 一灰灰Learning](https://hhui.top/spring-middle/03.zookeeper/02.210415-springboot%E6%95%B4%E5%90%88zookeeper%E4%BB%8E0%E5%88%B01%E5%AE%9E%E7%8E%B0%E4%B8%80%E4%B8%AA%E5%88%86%E5%B8%83%E5%BC%8F%E9%94%81/)\n* etcd实现分布式锁\n* 基于consul实现分布式锁\n\n\n\n### 5.4 分布式事务\n\n事务表示一组操作,要么全部成功,要么全部不成功;单机事务通常说的是数据库的事务;而分布式事务,则可以简单理解为多个数据库的操作,要么同时成功,要么全部不成功\n\n更确切一点的说法,分布式事务主要是要求事务的参与方,可能涉及到多个系统、多个数据资源,要求它们的操作要么都成功,要么都回滚;\n\n\n一个简单的例子描述下分布式事务场景:\n\n**下单扣库存**\n\n- 用户下单,付钱\n- 此时订单服务,会生成订单信息\n- 支付网关,会记录付款信息,成功or失败\n- 库存服务,扣减对应的库存\n\n一个下单支付操作,涉及到三个系统,而分布式事务则是要求,若支付成功,则上面三个系统都应该更新成功;若有一个操作失败,如支付失败,则已经扣了库存的要回滚(还库存),生成的订单信息回滚(删掉--注:现实中并不会去删除订单信息,这里只是用于说明分布式事务,请勿带入实际的实现方案)\n\n\n\n\n分布式事务实现方案:\n\n- 2PC: 前面说的两阶段提交,就是实现分布式事务的一个经典解决方案\n- 3PC: 三阶段提交\n- TCC:补偿事务,简单理解为应用层面的2PC\n- SAGA事务\n- 本地消息表\n- MQ事务方案\n\n\n\n\n### 5.5 分布式任务\n\n分布式任务相比于我们常说单机的定时任务而言,可以简单的理解为多台实例上的定时任务,从应用场景来说,可以区分两种\n\n- 互斥性的分布式任务\n - 即同一时刻,集群内只能有一个实例执行这个任务\n- 并存式的分布式任务\n - 同一时刻,所有的实例都可以执行这个任务\n - 续考虑如何避免多个任务操作相同的资源\n\n\n\n\n分布式任务实现方案:\n\n- Quartz Cluster\n- XXL-Job\n- Elastic-Job\n- 自研:\n - 资源分片策略\n - 分布式锁控制的唯一任务执行策略\n\n\n\n### 5.6 分布式Session\n\n> Session一般叫做会话,Session技术是http状态保持在服务端的解决方案,它是通过服务器来保持状态的。我们可以把客户端浏览器与服务器之间一系列交互的动作称为一个 Session。是服务器端为客户端所开辟的存储空间,在其中保存的信息就是用于保持状态。因此,session是解决http协议无状态问题的服务端解决方案,它能让客户端和服务端一系列交互动作变成一个完整的事务。\n\n单机基于session/cookie来实现用户认证,那么在分布式系统的多实例之间,如何验证用户身份呢?这个就是我们说的分布式session\n\n\n\n\n分布式session实现方案:\n\n- session stick:客户端每次请求都转发到同一台服务器(如基于ip的hash路由转发策略)\n- session复制: session生成之后,主动同步给其他服务器\n- session集中保存:用户信息统一存储,每次需要时统一从这里取(也就是常说的redis实现分布式session方案)\n- cookie: 使用客户端cookie存储session数据,每次请求时携带这个\n\n\n\n### 5.7 分布式链路追踪\n\n\n分布式链路追踪也可以叫做全链路追中,而它可以说是每个开发者的福音,通常指的是一次前端的请求,将这个请求过程中,所有涉及到的系统、链路都串联起来,可以清晰的知道这一次请求中,调用了哪些服务,有哪些IO交互,瓶颈点在哪里,什么地方抛出了异常\n\n\n当前主流的全链路方案大多是基于google的`Dapper` 论文实现的\n\n\n\n全链路实现方案\n\n- zipkin\n- pinpoint\n- SkyWalking\n- CAT\n- jaeger\n\n\n\n### 5.8 布隆过滤器\n\nBloom过滤器是一种节省空间的概率数据结构,用于测试元素是否为某集合的成员。\n\n布隆过滤器由一个长度为 m 比特的位数组(bit array)与 k 个哈希函数(hash function)组成的数据结构。\n\n原理是当一个元素被加入集合时,通过 K 个散列函数将这个元素映射成一个位数组中的 K 个点,把它们置为 1。\n\n检索时,我们只要看看这些点是不是都是 1 就大约知道集合中有没有它了,也就是说,如果这些点有任何一个 0 ,则被检元素一定不在;如果都是 1 ,则被检元素很可能在。\n\n\n关于布隆过滤器,请牢记一点\n\n- 判定命中的,不一定真的命中\n- 判定没有命中的,则一定不在里面\n\n\n\n常见的应用场景,如\n\n- 防止缓存穿透\n- 爬虫时重复检测\n\n\n### 5.9 一灰灰的小结\n\n分布式系统的解决方案当然不局限于上面几种,比如分布式存储、分布式计算等也属于常见的场景,当然在我们实际的业务支持过程中,不太可能需要让我们自己来支撑这种大活;而上面提到的几个点,基本上或多或少会与我们日常工作相关,这里列出来当然是好为了后续的详情做铺垫\n\n\n## 6.一灰灰的总结\n\n### 6.1 综述\n\n这是一篇概括性的综述类文章,可能并没有很多的干货,当然也限于“一灰灰”我个人的能力,上面的总结可能并不准确,如有发现,请不吝赐教\n\n全文总结如下\n\n常见的分布式架构设计方案:\n\n- 主备,主从,多主多从,普通无中心集群,数据分片架构\n\n分布式系统中的理论基石:\n\n- CAP, BASE, PACELEC\n- 共识算法:paxos, raft, zab\n- 一致性协议:2pc, 3pc\n- 数据同步:gossip\n\n分布式系统中的算法:\n\n- 分区的一致性hash算法: 基于hash环,减少节点动态增加减少对整个集群的影响;适用于数据分片的场景\n- 适用于一致性的Quorum NWR算法: 投票算法,定义如何就一个提案达成共识\n- PBFT拜占庭容错算法: 适用于集群中节点故障、或者不可信的场景\n- 区块链中大量使用的工作量证明PoW算法: 通过工作量证明,认可节点的提交\n\n分布式系统解决方案:\n\n- 分布式缓存\n- 全局唯一ID\n- 分布式锁\n- 分布式事务\n- 分布式任务\n- 分布式会话\n- 分布式链路追踪\n- 布隆过滤器\n\n\n### 6.2 题外话\n\n最后总结一下这篇耗时两周写完的“心血巨作”(有点自吹了哈),准备这篇文章确实花了很大的精力,首先我个人对于分布式这块的理解并不能算深刻,其次分布式这块的理论+实践知识特别多,而且并不是特别容易上手理解,在输出这篇文章的同时,遇到一些疑问点我也会去查阅相关资料去确认,整个过程并不算特别顺利; 那么为什么还要去做这个事情呢?\n\n1. 咸鱼太久了,想做一些有意思的东西,活跃一下大脑\n2. 准备依托于《分布式专栏》来将自己的知识体系进行归纳汇总,让零散分布在大脑中的知识点能有一个脉络串联起来\n3. 不想做架构的码农不是好码农,而想成为一个好的架构,当然得做一些基础准备,向业务精品学习取经\n\n\n', '0', '2022-10-08 19:12:32', '2022-10-08 19:23:14'), ('2', '101', '2', '\n\n你在分布式系统上工作吗?微服务,Web API,SOA,Web服务器,应用服务器,数据库服务器,缓存服务器,负载均衡器 - 如果这些描述了系统设计中的组件,那么答案是肯定的。分布式系统由许多计算机组成,这些计算机协调以实现共同的目标。\n\n20多年前,Peter Deutsch和James Gosling定义了分布式计算的8个谬误。这些是许多开发人员对分布式系统做出的错误假设。从长远来看,这些通常被证明是错误的,导致难以修复错误。\n\n8个谬误是:\n\n1. 网络可靠。\n2. 延迟为零。\n3. 带宽是无限的。\n4. 网络是安全的。\n5. 拓扑不会改变。\n6. 有一个管理员。\n7. 运输成本为零。\n8. 网络是同质的。\n\n让我们来看看每个谬误,讨论问题和潜在的解决方案。\n\n## 1.网络可靠\n\n### 问题\n\n> 通过网络呼叫将失败。\n\n今天的大多数系统都会调用其他系统。您是否正在与第三方系统(支付网关,会计系统,CRM)集成?你在做网络服务电话吗?如果呼叫失败会发生什么?如果您要查询数据,则可以进行简单的重试。但是如果您发送命令会发生什么?我们举一个简单的例子:\n\n```\nvar creditCardProcessor = new CreditCardPaymentService();\ncreditCardProcessor.Charge(chargeRequest);\n```\n\n\n如果我们收到HTTP超时异常会怎么样?如果服务器没有处理请求,那么我们可以重试。但是,如果它确实处理了请求,我们需要确保我们不会对客户进行双重收费。您可以通过使服务器具有幂等性来实现此目的。这意味着如果您使用相同的收费请求拨打10次,则客户只需支付一次费用。如果您没有正确处理这些错误,那么您的系统是不确定的。处理所有这些情况可能会非常复杂。\n\n### 解决方案\n\n因此,如果网络上的呼叫失败,我们能做什么?好吧,我们可以自动重试。排队系统非常擅长这一点。它们通常使用称为存储和转发的模式。它们在将消息转发给收件人之前在本地存储消息。如果收件人处于脱机状态,则排队系统将重试发送邮件。MSMQ是这种排队系统的一个例子。\n\n但是这种变化将对您的系统设计产生重大影响。您正在从请求/响应模型转移到触发并忘记。由于您不再等待响应,因此您需要更改系统中的用户行程。您不能只使用队列发送替换每个Web服务调用。\n\n### 结论\n\n你可能会说网络现在更可靠 - 而且它们是。但事情发生了。硬件和软件可能会出现故障 - 电源,路由器,更新或补丁失败,无线信号弱,网络拥塞,啮齿动物或鲨鱼。是的,鲨鱼:在一系列鲨鱼叮咬之后,谷歌正在加强与Kevlar的海底数据线。\n\n还有人为因素。人们可以开始DDOS攻击,也可以破坏物理设备。\n\n这是否意味着您需要删除当前的技术堆栈并使用消息传递系统?并不是的!您需要权衡失败的风险与您需要进行的投资。您可以通过投资基础架构和软件来最小化失败的可能性。在许多情况下,失败是一种选择。但在设计分布式系统时,您确实需要考虑失败的问题。\n\n## 2.延迟是零\n\n### 问题\n\n> 通过网络拨打电话不是即时的。\n\n内存呼叫和互联网呼叫之间存在七个数量级的差异。您的应用程序应该是网络感知。这意味着您应该清楚地将本地呼叫与远程呼叫分开。让我们看看我在代码库中看到的一个例子:\n\n\n```\nvar viewModel = new ViewModel();\nvar documents = new DocumentsCollection();\nforeach (var document in documents)\n{\n var snapshot = document.GetSnapshot();\n viewModel.Add(snapshot);\n}\n```\n\n\n没有进一步检查,这看起来很好。但是,有两个远程呼叫。第2行进行一次调用以获取文档摘要列表。在第5行,还有另一个调用,它检索有关每个文档的更多信息。这是一个经典的Select n + 1问题。为了解决网络延迟问题,您应该在一次调用中返回所有必需的数据。一般的建议是本地调用可以细粒度,但远程调用应该更粗粒度。这就是为什么分布式对象和网络透明度的想法死了。但是,即使每个人都同意分布式对象是一个坏主意,有些人仍然认为延迟加载总是一个好主意:\n\n\n```\nvar employee = EmployeeRepository.GetBy(someCriteria)\nvar department = employee.Department;\nvar manager = department.Manager;\nforeach (var peer in manager.Employees;)\n{\n// do something\n}\n```\n\n\n您不希望财产获取者进行网络呼叫。但是,每个。 在上面的代码中调用实际上可以触发数据库之旅。\n\n### 解决方案\n\n#### 带回您可能需要的所有数据\n\n如果您进行远程呼叫,请确保恢复可能需要的所有数据。网络通信不应该是唠叨的。\n\n#### 将Data Closer移动到客户端\n\n另一种可能的解决方案是将数据移近客户端。如果您正在使用云,请根据客户的位置仔细选择可用区。缓存还可以帮助最小化网络呼叫的数量。对于静态内容,内容交付网络(CDN)是另一个不错的选择。\n\n#### 反转数据流\n\n删除远程调用的另一个选项是反转数据流。我们可以使用Pub / Sub并在本地存储数据,而不是查询其他服务。这样,我们就可以在需要时获取数据。当然,这会带来一些复杂性,但它可能是工具箱中的一个很好的工具。\n\n### 结论\n\n虽然延迟可能不是LAN中的问题,但当您转移到WAN或Internet时,您会注意到延迟。这就是为什么将网络呼叫与内存中的呼叫明确分开是很重要的。在采用微服务架构模式时,您应该牢记这一点。您不应该只使用远程调用替换本地呼叫。这可能会使你的系统变成分布式的大泥球。\n\n## 3.带宽是无限的\n\n### 问题\n\n> 带宽是有限的。\n\n带宽是网络在一段时间内发送数据的容量。到目前为止,我还没有发现它是一个问题,但我可以看到为什么它在某些条件下可能是一个问题。虽然带宽随着时间的推移而有所改善,但我们发送的数据量也有所增加。与通过网络传递简单DTO的应用相比,视频流或VoIP需要更多带宽。带宽对于移动应用程序来说更为重要,因此开发人员在设计后端API时需要考虑它。\n\n错误地使用ORM也会造成伤害。我见过开发人员在查询中过早调用.ToList()的示例,因此在内存中加载整个表。\n\n### 解决方案\n\n#### 领域驱动的设计模式\n\n那么我们怎样才能确保我们不会带来太多数据呢?域驱动设计模式可以帮助:\n\n* 首先,您不应该争取单一的企业级域模型。您应该将域划分为有界上下文。\n* 要避免有界上下文中的大型复杂对象图,可以使用聚合模式。聚合确保一致性并定义事务边界。\n\n#### 命令和查询责任隔离\n\n我们有时会加载复杂的对象图,因为我们需要在屏幕上显示它的一部分。如果我们在很多地方这样做,我们最终会得到一个庞大而复杂的模型,对于写作和阅读来说都是次优的。另一种方法可以是使用命令和查询责任隔离 - CQRS。这意味着将域模型分为两部分:\n\n* 在写模式将确保不变保持真实的数据是一致的。由于写模型不关心视图问题,因此可以保持较小且集中。\n* 该读取模型是视图的担忧进行了优化,所以我们可以获取所有所需的特定视图中的数据(例如,我们的应用程序的屏幕)。\n\n### 结论\n\n在第二个谬误(延迟不是0)和第三个谬误(带宽是无限的)之间有延伸,您应该传输更多数据,以最大限度地减少网络往返次数。您应该传输较少的数据以最小化带宽使用。您需要平衡这两种力量,并找到通过线路发送的_正确_数据量。\n\n虽然您可能不会经常遇到带宽限制,但考虑传输的数据非常重要。更少的数据更容易理解。数据越少意味着耦合越少。因此,只传输您可能需要的数据。\n\n## 4.网络是安全的\n\n### 问题\n\n> 网络并不安全。\n\n这是一个比其他人更多的媒体报道的假设。您的系统仅与最薄弱的链接一样安全。坏消息是分布式系统中有很多链接。您正在使用HTTPS,除非与不支持它的第三方遗留系统进行通信。您正在查看自己的代码,寻找安全问题,但正在使用可能存在风险的开源库。一个OpenSSL的漏洞允许人们通过盗取SSL / TLS保护的数据。Apache Struts中的一个错误允许攻击者在服务器上执行代码。即使你正在抵御所有这些,仍然存在人为因素。恶意DBA可能错放数据库备份。今天的攻击者掌握着大量的计算能力和耐心。所以问题不在于他们是否会攻击你的系统,而是什么时候。\n\n### 解决方案\n\n#### 深度防御\n\n您应该使用分层方法来保护您的系统。您需要在网络,基础架构和应用程序级别进行不同的安全检查。\n\n#### 安全心态\n\n在设计系统时要牢记安全性。十大漏洞列表在过去5年中没有发生太大变化。您应遵循安全软件设计的最佳实践,并检查常见安全漏洞的代码。您应该定期搜索第三方库以查找新漏洞。常见漏洞和暴露列表可以提供帮助。\n\n#### 威胁建模\n\n威胁建模是一种识别系统中可能存在的安全威胁的系统方法。首先确定系统中的所有资产(数据库中的用户数据,文件等)以及如何访问它们。之后,您可以识别可能的攻击并开始执行它们。我建议阅读高级API安全性的第2章,以便更好地概述威胁建模。\n\n### 结论\n\n唯一安全的系统是关闭电源的系统,不连接到任何网络(理想情况下是在一个有形模块中)。它是多么有用的系统!事实是,安全是艰难而昂贵的。分布式系统中有许多组件和链接,每个组件和链接都是恶意用户的可能目标。企业需要平衡攻击的风险和概率与实施预防机制的成本。\n\n攻击者手上有很多耐心和计算能力。我们可以通过使用威胁建模来防止某些类型的攻击,但我们无法保证100%的安全性。因此,向业务部门明确表示这一点是个好主意,共同决定投资安全性的程度,并制定安全漏洞何时发生的计划。\n\n## 5.拓扑不会改变\n\n### 问题\n\n> 网络拓扑不断变化。\n\n网络拓扑始终在变化。有时它会因意外原因而发生变化 - 当您的应用服务器出现故障并需要更换时。很多时候它是故意的 - 在新服务器上添加新进程。如今,随着云和容器的增加,这一点更加明显。弹性扩展 - 根据工作负载添加或删除服务器的能力 - 需要一定程度的网络灵活性。\n\n### 解决方案\n\n#### 摘要网络的物理结构\n\n您需要做的第一件事是抽象网络的物理结构。有几种方法可以做到这一点:\n\n* 停止硬编码IP - 您应该更喜欢使用主机名。通过使用URI,我们依靠DNS将主机名解析为IP。\n* 当DNS不够时(例如,当您需要映射IP和端口时),则使用发现服务。\n* Service Bus框架还可以提供位置透明性。\n\n#### 无价值的,而非重要的\n\n通过将您的服务器视为没有价值的,而不是很重要的,您确保没有服务器是不可替代的。这一点智慧可以帮助您进入正确的思维模式:任何服务器都可能出现故障(从而改变拓扑结构),因此您应该尽可能地自动化。\n\n#### 测试\n\n最后一条建议是测试你的假设。停止服务或关闭服务器,看看您的系统是否仍在运行。像Netflix的Chaos Monkey这样的工具可以通过随机关闭生产环境中的VM或容器来实现这一目标。通过带来痛苦,您更有动力构建一个可以处理拓扑更改的更具弹性的系统。\n\n### 结论\n\n十年前,大多数拓扑结构并没有经常改变。但是当它发生时,它可能发生在生产中并引入了一些停机时间。如今,随着云和容器的增加,很难忽视这种谬误。你需要为失败做好准备并进行测试。不要等到它在生产中发生!\n\n## 6.有一位管理员\n\n### 问题\n\n> 这个知道一切的并不存在。\n\n嗯,这个看起来很明显。当然,没有一个人知道一切。这是一个问题吗?只要应用程序运行顺利,它就不是。但是,当出现问题时,您需要修复它。因为很多人触摸了应用程序,知道如何解决问题的人可能不在那里。\n\n有很多事情可能会出错。一个例子是配置。今天的应用程序在多个商店中存储配置:配置文件,环境变量,数据库,命令行参数。没有人知道每个可能的配置值的影响是什么。\n\n另一件可能出错的事情是系统升级。分布式应用程序有许多移动部件,您需要确保它们是同步的。例如,您需要确保当前版本的代码适用于当前版本的数据库。如今,人们关注DevOps和持续交付。但支持零停机部署并非易事。\n\n但是,至少这些东西都在你的控制之下。许多应用程序与第三方系统交互。这意味着,如果它们失效,你可以做的事情就不多了。因此,即使您的系统有一名管理员,您仍然无法控制第三方系统。\n\n### 解决方案\n\n#### 每个人都应对释放过程负责\n\n这意味着从一开始就涉及Ops人员或系统管理员。理想情况下,他们将成为团队的一员。尽早让系统管理员了解您的进度可以帮助您发现限制因素。例如,生产环境可能具有与开发环境不同的配置,安全限制,防火墙规则或可用端口。\n\n#### 记录和监控\n\n系统管理员应该拥有用于错误报告和管理问题的正确工具。你应该从一开始就考虑监控。分布式系统应具有集中式日志。访问十个不同服务器上的日志以调查问题是不可接受的方法。\n\n#### 解耦\n\n您应该在系统升级期间争取最少的停机时间。这意味着您应该能够独立升级系统的不同部分。通过使组件向后兼容,您可以在不同时间更新服务器和客户端。\n\n通过在组件之间放置队列,您可以暂时将它们分离。这意味着,例如,即使后端关闭,Web服务器仍然可以接受请求。\n\n#### 隔离第三方依赖关系\n\n您应该以不同于您拥有的组件的方式处理控制之外的系统。这意味着使您的系统更能适应第三方故障。您可以通过引入抽象层来减少外部依赖的影响。这意味着当第三方系统出现故障时,您将找到更少的地方来查找错误。\n\n### 结论\n\n要解决这个谬论,您需要使系统易于管理。DevOps,日志记录和监控可以提供帮助。您还需要考虑系统的升级过程。如果升级需要数小时的停机时间,则无法部署每个sprint。没有一个管理员,所以每个人都应该对发布过程负责。\n\n## 7.运输成本为零\n\n### 问题\n\n> 运输成本_不是_零。\n\n这种谬论与第二个谬误有关,即 延迟为零。通过网络传输内容在时间和资源上都有代价。如果第二个谬误讨论了时间方面,那么谬误#7就会解决资源消耗问题。\n\n这种谬论有两个不同的方面:\n\n#### 网络基础设施的成本\n\n网络基础设施需要付出代价。服务器,SAN,网络交换机,负载平衡器以及负责此设备的人员 - 所有这些都需要花钱。如果您的系统是在内部部署的,那么您需要预先支付这个价格。如果您正在使用云,那么您只需为您使用的内容付费,但您仍然需要付费。\n\n#### 序列化/反序列化的成本\n\n这种谬误的第二个方面是在传输级别和应用程序级别之间传输数据的成本。序列化和反序列化会消耗CPU时间,因此需要花钱。如果您的应用程序是内部部署的,那么如果您不主动监视资源消耗,则会隐藏此成本。但是,如果您的应用程序部署在云端,那么这笔费用就会非常明显,因为您需要为使用的内容付费。\n\n### 解决方案\n\n关于基础设施的成本,你无能为力。您只能确保尽可能高效地使用它。SOAP或XML比JSON更昂贵。JSON比像Google的Protocol Buffers这样的二进制协议更昂贵。根据系统的类型,这可能或多或少重要。例如,对于与视频流或VoIP有关的应用,传输成本更为重要。\n\n### 结论\n\n您应该注意运输成本以及应用程序正在执行的序列化和反序列化程度。这并不意味着您应该优化,除非需要它。您应该对资源消耗进行基准测试和监控,并确定运输成本是否对您有用。\n\n## 8.网络是同质的\n\n### 问题\n\n> 网络_不是_同质的。\n\n同质网络是使用类似配置和相同通信协议的计算机网络。拥有类似配置的计算机是一项艰巨的任务。例如,您几乎无法控制哪些移动设备可以连接到您的应用。这就是为什么重点关注标准协议。\n\n### 解决方案\n\n您应该选择标准格式以避免供应商锁定。这可能意味着XML,JSON或协议缓冲区。有很多选择可供选择。\n\n### 结论\n\n您需要确保系统的组件可以相互通信。使用专有协议会损害应用程序的互操作性。\n\n## 设计分布式系统很难\n\n这些谬论发表于20多年前。但他们今天仍然坚持,其中一些比其他人更多。我认为今天许多开发人员都知道它们,但我们编写的代码并没有显示出来。\n\n我们必须接受这些事实:网络不可靠,不安全并且需要花钱。带宽有限。网络的拓扑结构将发生变化。其组件的配置方式不同。意识到这些限制将有助于我们设计更好的分布式系统。\n\n## 参考文章\n\n\n原文标题 [《Understanding the 8 Fallacies of Distributed Systems》](https://dzone.com/articles/understanding-the-8-fallacies-of-distributed-syste)\n\n作者:Victor Chircu\n\n译者:February\n\n译文: [https://cloud.tencent.com/developer/article/1370391](https://cloud.tencent.com/developer/article/1370391)\n', '0', '2022-10-08 19:13:38', '2023-04-15 20:37:45'), ('3', '102', '2', '\n\n\n分布式的概念存在年头有点久了,在正式进入我们《分布式专栏》之前,感觉有必要来聊一聊,什么是分布式,分布式特点是什么,它又有哪些问题,在了解完这个概念之后,再去看它的架构设计,理论奠基可能帮助会更大\n\n本文将作为专栏的第0篇,将从三个方面来讲述一下我理解的\"分布式系统\"\n\n- 分布式系统的特点\n- 分布式系统面临的挑战\n- 如何衡量一个分布式系统\n\n## 1.分布式系统特点\n\n什么是分布式系统,看一下wiki上的描述\n\n### 1.1 定义\n\n\n> 分布式系统(distributed system)是建立在网络之上的软件系统。正是因为软件的特性,所以分布式系统具有高度的内聚性和透明性。因此,网络和分布式系统之间的区别更多的在于高层软件(特别是操作系统),而不是硬件\n> * [分布式系统(建立在网络之上的软件系统)\\_百度百科](https://baike.baidu.com/item/%E5%88%86%E5%B8%83%E5%BC%8F%E7%B3%BB%E7%BB%9F/4905336)\n\n---\n\n> 分布式操作系统(Distributed operating system),是一种软件,它是许多独立的,网络连接的,通讯的,并且物理上分离的计算节点的集合[1]。每个节点包含全局总操作系统的一个特定的软件子集。每个软件子集是两个不同的服务置备的复合物[2]。第一个服务是一个普遍存在的最小的内核,或微内核,直接控制该节点的硬件。第二个服务是协调节点的独立的和协同的活动系统管理组件的更高级别的集合。这些组件抽象微内核功能,和支持用户应用程序[3]。\n> * [分布式操作系统 - 维基百科,自由的百科全书](https://zh.m.wikipedia.org/zh-hans/%E5%88%86%E5%B8%83%E5%BC%8F%E6%93%8D%E4%BD%9C%E7%B3%BB%E7%BB%9F)\n\n---\n\n> Distributed system: is a system in which components located on networked computers communicate and coordinate their actions by passing messages. The components interact with each other in order to achieve a common goal[3].\n> * [Distributed systems - Computer Science Wiki](https://computersciencewiki.org/index.php/Distributed_systems)\n\n\n\n虽然上面几个描述不完全相同,但是含义其实也差不了太多;基于我个人的理解,用大白话来描述一下分布式系统,就是“一个系统的服务能力,由网络上多个节点共同提供”,正如其名的“分布一词”\n\n在了解完分布式系统的概念之后,接下来抓住其主要特点,来加深这个分布式的理解\n\n### 1.2 分布性\n\n分布式系统分布在多个节点(可以理解为多个计算机),这些节点可以是网络上任意的一台计算机,即在空间上没有原则性的限制\n\n### 1.3 对等性\n\n分布式系统中有很多的节点,这些节点之间没有主从、优劣直说,它们应该是对等的,从服务能力来说,访问分布式系统中的任何一个节点,整个服务请求应该都是等价的\n\n看到这里可能就会有一个疑问了,分布式系统中经典主从架构,数据拆分架构,就不满足这个对等特性了啊(这个问题先留着,后续再详情中进行解答)\n\n### 1.4 自治性\n\n分布式系统中的各个节点都有自己的计算能力,各自具有独立的处理数据的功能。通常,彼此在地位上是平等的,无主次之分,既能自治地进行工作,又能利用共享的通信线路来传送信息,协调任务处理。\n\n### 1.5 并发性\n\n分布式系统既然存在多个节点,那么天然就存在多个节点的同事响应请求的能力,即并发性支持,如何做好分布式系统的并发控制则是所有分布式系统需要解决的一个问题\n\n\n## 2. 分布式系统面临的问题\n\n当系统分布在多个节点之上时,自然而然就带来了很多单机场景下不会有问题,如经典的 [分布式系统的8个谬误 | 一灰灰Learning](https://hhui.top/%E5%88%86%E5%B8%83%E5%BC%8F/%E8%AE%BE%E8%AE%A1%E6%A8%A1%E5%BC%8F/02.%E5%88%86%E5%B8%83%E5%BC%8F%E7%B3%BB%E7%BB%9F%E7%9A%848%E4%B8%AA%E8%B0%AC%E8%AF%AF/)\n\n\n### 2.1 全局时钟\n\n分布式系统的多个节点,如何保证每个节点的时钟一致?这个是需要重点考虑的问题\n\n我们知道大名鼎鼎的分布式主键生成算法 “雪花算法” 就是利用了机器时钟来作为算法因子,如果一个系统的多个节点不能保证时钟统一,那这个算法的唯一性将无法得到保障\n\n### 2.2 网络延迟、异常\n\n网络是有开销的,多个节点之间的通信是有成本的,既然存在网络的开销、或异常状况,那么如何保证多个节点的数据一致性呢? 当无法保证数据的一致性时,如何提供分布式系统的对等性呢?\n\n在经典的CAP理论中,对于P(网络分区)一般都是需要保障的,一个系统存在多个计算节点,那么网络问题将不可避免,网络分区必然会存在\n\n\n### 2.3 数据一致性\n\n如何保证所有节点中的数据完全一致是一个巨大的挑战,这个问题比较好理解,我们操作分布式系统中的一个节点实现数据修改,如果要保证数据一致性,则要求所有的节点,同步收到这个修改\n\n但是我们需要注意的时,网络是不可靠的,且网络的传输是存在延迟的,如何衡量数据的一致性和服务的可用性则是我们在设计一个分布式系统中需要取舍的\n\n### 2.4 节点异常\n\n机器宕机属于不可抗力因素,如果分布式系统中的一个节点宕机了,整个系统会怎么样?要如何确保机器宕机也不会影响系统的可用性呢? 机器恢复之后,又应该如何保证数据的一致性呢? 又应该如何判断一个节点是否正常呢?\n\n\n### 2.5 资源竞争\n\n前面说到分布式系统天然支持并发,那么随之而来的问题则是如何资源竞争的问题;当一个资源同一时刻只允许一个实例访问时,怎么处理?多个系统同时访问一个资源是否会存在数据版本差异性(如经典的ABA问题)、数据一致性问题?\n\n基于这个问题,分布式锁可以说是应运而生,相信各位开发大佬都不会陌生这个知识点\n\n### 2.6 全局协调\n\n这个协调怎么理解呢? 举几个简单的实例\n\n- 如何判断分布式系统中那些节点正常提供服务,那些节点故障\n- 如一个任务希望在分布式系统中只执行一次,那么应该哪个节点执行这个任务呢?\n- 如一组有先后顺序的请求发送给分布式系统,但是由于网络问题,可能出现后面的请求先被系统接收到,这种场景怎么处理呢?\n- 一个用户已经登录,如何在所有节点中确认他的身份呢?\n\n### 2.7 一灰灰的小结\n\n实际上分布式系统面临的挑战并不止于上面这些,一个具体的系统面临的问题可能各不相同,但总的来说,分布式系统的理论基础会给我们非常好的指引方向,这一节推荐查看 * [分布式设计模式综述 | 一灰灰Learning](https://hhui.top/%E5%88%86%E5%B8%83%E5%BC%8F/%E8%AE%BE%E8%AE%A1%E6%A8%A1%E5%BC%8F/01.%E5%88%86%E5%B8%83%E5%BC%8F%E8%AE%BE%E8%AE%A1%E6%A8%A1%E5%BC%8F%E7%BB%BC%E8%BF%B0/)\n\n\n## 3. 分布式系统的衡量指标\n\n最后再来看一下如何衡量一个分布式系统的“好差”,它的指标有哪些\n\n### 3.1 性能指标\n\n常见的性能指标如rt, QPS, TPS来判断一个系统的承载能力,重点关注是哪个要点\n\n- 响应延迟\n- 并发能力\n- 事务处理能力\n\n### 3.2 可用性\n\n这个就是传说中你的系统达到几个9的那个指标,即系统的异常时间占总的可用时间的比例\n\n统的可用性可以用系统停服务的时间与正常服务的时间的比例来衡量,也可以用某功能的失败次数与成功次数的比例来衡量。可用性是分布式的重要指标,衡量了系统的鲁棒性,是系统容错能力的体现。\n\n\n### 3.3 扩展性\n\n系统的可扩展性(scalability)指分布式系统通过扩展集群机器规模提高系统性能(吞吐、延迟、并发)、存储容量、计算能力的特性\n\n最简单来讲,就是你的系统能不能直接加机器,来解决性能瓶颈,如果能加机器,有没有上限(如由于数据库的连接数限制了机器的数量上限, 如机器加到某个程度之后,服务能力没有明显提升)\n\n\n### 3.4 一致性\n\n分布式系统为了提高可用性,总是不可避免的使用副本的机制,从而引发副本一致性的问题。越是强的一致的性模型,对于用户使用来说使用起来越简单\n\n\n## 4. 总结\n\n这一篇文章相对来说比较干燥,全是文字描述,介绍下什么是分布式系统,分布系统的特点及面对的问题和衡量指标,提炼一下关键要素,如下\n\n\n分布式系统的特点\n\n- 分布性\n- 对等性\n- 并发性\n- 自治性\n\n分布式系统面临的挑战\n\n- 全局时钟\n- 网络延迟、异常\n- 数据一致性\n- 节点异常\n- 资源竞争\n- 全局协调\n\n分布式系统衡量指标\n\n- 性能指标\n- 可用性\n- 扩展性\n- 一致性\n\n<small>\n\n我是一灰灰,欢迎感兴趣的小伙伴关注最近持续更新的分布式专栏:\n\n* [分布式常用的设计模式 | 一灰灰Learning](https://hhui.top/%E5%88%86%E5%B8%83%E5%BC%8F/%E8%AE%BE%E8%AE%A1%E6%A8%A1%E5%BC%8F/)\n\n最后强烈推荐阅读下面两个万字干货\n\n* [1w5字详细介绍分布式系统的38个技术方案](https://mp.weixin.qq.com/s?__biz=MzU3MTAzNTMzMQ==&mid=2247487507&idx=1&sn=9c4ff02747e8335ee5e3c7765cc80b3c&chksm=fce70bbfcb9082a9a8d972af80f19a9b66a5425c949bc400872727cc2da9f401047a5a523ac4&token=1624762777&lang=zh_CN#rd)\n* [基于MySql,Redis,Mq,ES的高可用方案解析](https://mp.weixin.qq.com/s?__biz=MzU3MTAzNTMzMQ==&mid=2247487533&idx=1&sn=cd07d5d601986fd3911858ea5f3a18d4&chksm=fce70b81cb908297fe66eac564028a6c7ef197f8f10921c4dfe05cf8d433b5ee45566099e467&token=1624762777&lang=zh_CN#rd)\n\n</small>', '0', '2022-10-08 19:14:17', '2023-04-15 20:37:51'), ('4', '1', '2', '技术派\n---\n\n技术派是一个基于SpringBoot实现完全开源的技术论坛社区\n\n\n## 本地部署教程\n\n> [本地开发环境手把手教程](docs/本地开发环境配置教程.md)\n\n## 云服务器部署教程\n\n> [环境搭建 & 基于源码的部署教程](docs/安装环境.md)\n> [服务器启动教程](docs/服务器启动教程.md)\n\n## 项目结构说明\n\n**当前项目工程模块**\n\n- [forum-api](forum-api): 定义一些通用的枚举、实体类定义、DODTOVO等\n- [forum-core](forum-core): 核心工具组件相关的模块,如工具包util, 如通用的组件放在这个模块(以包路径对模块功能进行拆分,如搜索、缓存、推荐等)\n- [forum-service](forum-service): 服务模块,业务相关的主要逻辑,db的操作都在这里\n- [forum-ui](forum-ui): html前端资源\n- [forum-web](forum-web): web模块,http入口,项目启动的入口,包括权限身份校验、全局异常处理等\n\n**环境配置说明**\n\n资源配置都放在 `forum-web` 模块的资源路径下,通过maven的env进行环境选择切换\n\n当前提供了四种开发环境\n\n- resources-env/dev: 本地开发环境,也是默认环境\n- resources-env/test: 测试环境\n- resources-env/pre: 预发环境\n- resources-env/prod: 生产环境\n\n环境切换命令\n\n```bash\n# 如切换生产环境\nmvn clean install -DskipTests=true -Pprod\n```\n\n**配置文件说明**\n\n- resources\n - application.yml: 主配置文件入口\n - application-config.yml: 全局的站点信息配置文件\n - logback-spring.xml: 日志打印相关配置文件\n - liquibase: 由liquibase进行数据库表结构管理\n- resources-env\n - xxx/application-dal.yml: 定义数据库相关的配置信息\n - xxx/application-image.yml: 定义上传图片的相关配置信息\n - xxx/application-web.yml: 定义web相关的配置信息\n\n### 前端工程结构说明\n\n#### 前端页面都放在 ui 模块中\n\n- resources/static: 静态资源文件,如css/js/image,放在这里\n- resources/templates: html相关页面\n - views: 业务相关的页面\n - 定义:\n - 页面/index.html: 这个index.html表示的是这个业务对应的主页面\n - 页面/模块/xxx.html: 若主页面又可以拆分为多个模块页面进行组合,则在这个页面下,新建一个模块目录,下面放对应的html文件\n - article-category-list: 对应 分类文章列表页面,\n - article-detail: 对应文章详情页\n - side-float-action-bar: 文章详情,左边的点赞/收藏/评论浮窗\n - side-recommend-bar: 文章详情右边侧边栏的sidebar\n - article-edit: 对应文章发布页\n - article-search-list: 对应文章搜索页\n - article-tag-list: 对应标签文章列表\n - column-detail:对应专栏阅读详情页\n - column-home: 对应专栏首页\n - home: 全站主页\n - login: 登录页面\n - notice: 通知页面\n - user: 用户个人页\n - error: 错误页面\n - components: 公用的前端页面组件\n\n\n#### 前端 css 全部放在 static/css 中\n\n- components: 公共组件的css\n - navbar: 导航栏样式\n - footer: 底部样式\n - article-item: 文章块展示样式\n - article-footer: 文章底部(点赞、评论等)\n - side-column: 侧边栏(公告等)\n- views: 主页面css(直接在主页面内部引入)\n - home: 主页样式\n - article-detail: 详情页样式\n - ...\n- three: 第三方css\n - index: 第三方css集合\n - ...\n- common: 公共组件的css集合 (直接在公共组件components/layout/header/index.html内引入)\n- global: 全局样式(全局的样式控制,注意覆盖问题,直接在公共组件components/layout/header/index.html内引入)\n', '0', '2023-01-13 19:15:58', '2023-01-13 19:15:58'), ('5', '103', '1', '> 整体阅读时间,在 40 分钟左右。\n\n大家好,我是楼仔!\n\n常见的消息队列很多,主要包括 RabbitMQ、Kafka、RocketMQ 和 ActiveMQ,相关的选型可以看我之前的系列,**这篇文章只讲 RabbitMQ,先讲原理,后搞实战。**\n\n文章很长,如果你能一次性看完,“大哥,请收下我的膝盖”,建议大家先收藏,啥时需要面试,或者工作中遇到了,可以再慢慢看。\n\n**提示:结语有彩蛋,非常好的建议,值得大家一看!**\n\n不 BB,直接上思维导图:\n\n\n\n# 1. 消息队列\n\n## 1.1 消息队列模式\n\n消息队列目前主要 2 种模式,分别为“点对点模式”和“发布/订阅模式”。\n\n#### 1.1.1 点对点模式\n\n一个具体的消息只能由一个消费者消费,多个生产者可以向同一个消息队列发送消息,但是一个消息在被一个消息者处理的时候,这个消息在队列上会被锁住或者被移除并且其他消费者无法处理该消息。\n\n需要额外注意的是,如果消费者处理一个消息失败了,消息系统一般会把这个消息放回队列,这样其他消费者可以继续处理。\n\n\n\n#### 1.1.2 发布/订阅模式\n\n单个消息可以被多个订阅者并发的获取和处理。一般来说,订阅有两种类型:\n\n* **临时(ephemeral)订阅**:这种订阅只有在消费者启动并且运行的时候才存在。一旦消费者退出,相应的订阅以及尚未处理的消息就会丢失。\n* **持久(durable)订阅**:这种订阅会一直存在,除非主动去删除。消费者退出后,消息系统会继续维护该订阅,并且后续消息可以被继续处理。\n\n\n\n## 1.2 衡量标准\n\n对消息队列进行技术选型时,需要通过以下指标衡量你所选择的消息队列,是否可以满足你的需求:\n\n* **消息顺序**:发送到队列的消息,消费时是否可以保证消费的顺序,比如A先下单,B后下单,应该是A先去扣库存,B再去扣,顺序不能反。\n* **消息路由**:根据路由规则,只订阅匹配路由规则的消息,比如有A/B两者规则的消息,消费者可以只订阅A消息,B消息不会消费。\n* 消息可靠性:是否会存在丢消息的情况,比如有A/B两个消息,最后只有B消息能消费,A消息丢失。\n* **消息时序**:主要包括“消息存活时间”和“延迟/预定的消息”,“消息存活时间”表示生产者可以对消息设置TTL,如果超过该TTL,消息会自动消失;“延迟/预定的消息”指的是可以延迟或者预订消费消息,比如延时5分钟,那么消息会5分钟后才能让消费者消费,时间未到的话,是不能消费的。\n* **消息留存**:消息消费成功后,是否还会继续保留在消息队列。\n* **容错性**:当一条消息消费失败后,是否有一些机制,保证这条消息是一种能成功,比如异步第三方退款消息,需要保证这条消息消费掉,才能确定给用户退款成功,所以必须保证这条消息消费成功的准确性。\n* **伸缩**:当消息队列性能有问题,比如消费太慢,是否可以快速支持库容;当消费队列过多,浪费系统资源,是否可以支持缩容。\n* **吞吐量**:支持的最高并发数。\n\n# 2. RabbitMQ 原理初探\n\nRabbitMQ 2007 年发布,是使用 Erlang 语言开发的开源消息队列系统,基于 AMQP 协议来实现。\n\n## 2.1 基本概念\n\n提到RabbitMQ,就不得不提AMQP协议。AMQP协议是具有现代特征的二进制协议。是一个提供统一消息服务的应用层标准高级消息队列协议,是应用层协议的一个开放标准,为面向消息的中间件设计。\n\n先了解一下AMQP协议中间的几个重要概念:\n\n* Server:接收客户端的连接,实现AMQP实体服务。\n* Connection:连接,应用程序与Server的网络连接,TCP连接。\n* Channel:信道,消息读写等操作在信道中进行。客户端可以建立多个信道,每个信道代表一个会话任务。\n* Message:消息,应用程序和服务器之间传送的数据,消息可以非常简单,也可以很复杂。由Properties和Body组成。Properties为外包装,可以对消息进行修饰,比如消息的优先级、延迟等高级特性;Body就是消息体内容。\n* Virtual Host:虚拟主机,用于逻辑隔离。一个虚拟主机里面可以有若干个Exchange和Queue,同一个虚拟主机里面不能有相同名称的Exchange或Queue。\n* Exchange:交换器,接收消息,按照路由规则将消息路由到一个或者多个队列。如果路由不到,或者返回给生产者,或者直接丢弃。RabbitMQ常用的交换器常用类型有direct、topic、fanout、headers四种,后面详细介绍。\n* Binding:绑定,交换器和消息队列之间的虚拟连接,绑定中可以包含一个或者多个RoutingKey。\n* RoutingKey:路由键,生产者将消息发送给交换器的时候,会发送一个RoutingKey,用来指定路由规则,这样交换器就知道把消息发送到哪个队列。路由键通常为一个“.”分割的字符串,例如“com.rabbitmq”。\n* Queue:消息队列,用来保存消息,供消费者消费。\n\n## 2.2 工作原理\n\nAMQP 协议模型由三部分组成:生产者、消费者和服务端,执行流程如下:\n\n1. 生产者是连接到 Server,建立一个连接,开启一个信道。\n2. 生产者声明交换器和队列,设置相关属性,并通过路由键将交换器和队列进行绑定。\n3. 消费者也需要进行建立连接,开启信道等操作,便于接收消息。\n4. 生产者发送消息,发送到服务端中的虚拟主机。\n5. 虚拟主机中的交换器根据路由键选择路由规则,发送到不同的消息队列中。\n6. 订阅了消息队列的消费者就可以获取到消息,进行消费。\n\n\n\n## 2.3 常用交换器\n\nRabbitMQ常用的交换器类型有direct、topic、fanout、headers四种:\n\n* Direct Exchange:见文知意,直连交换机意思是此交换机需要绑定一个队列,要求该消息与一个特定的路由键完全匹配。简单点说就是一对一的,点对点的发送。\n\n\n\n* Fanout Exchange:这种类型的交换机需要将队列绑定到交换机上。一个发送到交换机的消息都会被转发到与该交换机绑定的所有队列上。很像子网广播,每台子网内的主机都获得了一份复制的消息。简单点说就是发布订阅。\n\n\n\n* Topic Exchange:直接翻译的话叫做主题交换机,如果从用法上面翻译可能叫通配符交换机会更加贴切。这种交换机是使用通配符去匹配,路由到对应的队列。通配符有两种:\"\\*\" 、 \"#\"。需要注意的是通配符前面必须要加上\".\"符号。\n\n * \\*符号:有且只匹配一个词。比如 a.\\*可以匹配到\"a.b\"、\"a.c\",但是匹配不了\"a.b.c\"。\n\n * \\#符号:匹配一个或多个词。比如\"rabbit.#\"既可以匹配到\"rabbit.a.b\"、\"rabbit.a\",也可以匹配到\"rabbit.a.b.c\"。\n\n\n\n* Headers Exchange:这种交换机用的相对没这么多。它跟上面三种有点区别,它的路由不是用routingKey进行路由匹配,而是在匹配请求头中所带的键值进行路由。创建队列需要设置绑定的头部信息,有两种模式:全部匹配和部分匹配。如上图所示,交换机会根据生产者发送过来的头部信息携带的键值去匹配队列绑定的键值,路由到对应的队列。\n\n\n\n## 2.4 消费原理\n\n我们先看几个基本概念:\n\n* broker:每个节点运行的服务程序,功能为维护该节点的队列的增删以及转发队列操作请求。\n* master queue:每个队列都分为一个主队列和若干个镜像队列。\n* mirror queue:镜像队列,作为master queue的备份。在master queue所在节点挂掉之后,系统把mirror queue提升为master queue,负责处理客户端队列操作请求。注意,mirror queue只做镜像,设计目的不是为了承担客户端读写压力。\n\n集群中有两个节点,每个节点上有一个broker,每个broker负责本机上队列的维护,并且borker之间可以互相通信。集群中有两个队列A和B,每个队列都分为master queue和mirror queue(备份)。那么队列上的生产消费怎么实现的呢?\n\n\n\n对于消费队列,如下图有两个consumer消费队列A,这两个consumer连在了集群的不同机器上。RabbitMQ集群中的任何一个节点都拥有集群上所有队列的元信息,所以连接到集群中的任何一个节点都可以,主要区别在于有的consumer连在master queue所在节点,有的连在非master queue节点上。\n\n因为mirror queue要和master queue保持一致,故需要同步机制,正因为一致性的限制,导致所有的读写操作都必须都操作在master queue上(想想,为啥读也要从master queue中读?和数据库读写分离是不一样的),然后由master节点同步操作到mirror queue所在的节点。即使consumer连接到了非master queue节点,该consumer的操作也会被路由到master queue所在的节点上,这样才能进行消费。\n\n\n\n对于生成队列,原理和消费一样,如果连接到非 master queue 节点,则路由过去。\n\n\n\n> 所以,到这里小伙伴们就可以看到 RabbitMQ的不足:由于master queue单节点,导致性能瓶颈,吞吐量受限。虽然为了提高性能,内部使用了Erlang这个语言实现,但是终究摆脱不了架构设计上的致命缺陷。\n\n## 2.5 高级特性\n\n#### 2.5.1 过期时间\n\nTime To Live,也就是生存时间,是一条消息在队列中的最大存活时间,单位是毫秒,下面看看RabbitMQ过期时间特性:\n\n* RabbitMQ可以对消息和队列设置TTL。\n* RabbitMQ支持设置消息的过期时间,在消息发送的时候可以进行指定,每条消息的过期时间可以不同。\n* RabbitMQ支持设置队列的过期时间,从消息入队列开始计算,直到超过了队列的超时时间配置,那么消息会变成死信,自动清除。\n* 如果两种方式一起使用,则过期时间以两者中较小的那个数值为准。\n* 当然也可以不设置TTL,不设置表示消息不会过期;如果设置为0,则表示除非此时可以直接将消息投递到消费者,否则该消息将被立即丢弃。\n\n#### 2.5.2 消息确认\n\n为了保证消息从队列可靠地到达消费者,RabbitMQ提供了消息确认机制。\n\n消费者订阅队列的时候,可以指定autoAck参数,当autoAck为true的时候,RabbitMQ采用自动确认模式,RabbitMQ自动把发送出去的消息设置为确认,然后从内存或者硬盘中删除,而不管消费者是否真正消费到了这些消息。\n\n当autoAck为false的时候,RabbitMQ会等待消费者回复的确认信号,收到确认信号之后才从内存或者磁盘中删除消息。\n\n消息确认机制是RabbitMQ消息可靠性投递的基础,只要设置autoAck参数为false,消费者就有足够的时间处理消息,不用担心处理消息的过程中消费者进程挂掉后消息丢失的问题。\n\n#### 2.5.3 持久化\n\n消息的可靠性是RabbitMQ的一大特色,那么RabbitMQ是如何保证消息可靠性的呢?答案就是消息持久化。持久化可以防止在异常情况下丢失数据。RabbitMQ的持久化分为三个部分:交换器持久化、队列持久化和消息的持久化。\n\n交换器持久化可以通过在声明队列时将durable参数设置为true。如果交换器不设置持久化,那么在RabbitMQ服务重启之后,相关的交换器元数据会丢失,不过消息不会丢失,只是不能将消息发送到这个交换器了。\n\n队列的持久化能保证其本身的元数据不会因异常情况而丢失,但是不能保证内部所存储的消息不会丢失。要确保消息不会丢失,需要将其设置为持久化。队列的持久化可以通过在声明队列时将durable参数设置为true。\n\n设置了队列和消息的持久化,当RabbitMQ服务重启之后,消息依然存在。如果只设置队列持久化或者消息持久化,重启之后消息都会消失。\n\n当然,也可以将所有的消息都设置为持久化,但是这样做会影响RabbitMQ的性能,因为磁盘的写入速度比内存的写入要慢得多。\n\n对于可靠性不是那么高的消息可以不采用持久化处理以提高整体的吞吐量。鱼和熊掌不可兼得,关键在于选择和取舍。在实际中,需要根据实际情况在可靠性和吞吐量之间做一个权衡。\n\n#### 2.5.4 死信队列\n\n当消息在一个队列中变成死信之后,他能被重新发送到另一个交换器中,这个交换器成为死信交换器,与该交换器绑定的队列称为死信队列。\n\n消息变成死信有下面几种情况:\n\n* 消息被拒绝。\n* 消息过期\n* 队列达到最大长度\n\nDLX也是一个正常的交换器,和一般的交换器没有区别,他能在任何的队列上面被指定,实际上就是设置某个队列的属性。当这个队列中有死信的时候,RabbitMQ会自动将这个消息重新发送到设置的交换器上,进而被路由到另一个队列,我们可以监听这个队列中消息做相应的处理。\n\n死信队列有什么用?当发生异常的时候,消息不能够被消费者正常消费,被加入到了死信队列中。后续的程序可以根据死信队列中的内容分析当时发生的异常,进而改善和优化系统。\n\n#### 2.5.5 延迟队列\n\n一般的队列,消息一旦进入队列就会被消费者立即消费。延迟队列就是进入该队列的消息会被消费者延迟消费,延迟队列中存储的对象是的延迟消息,“延迟消息”是指当消息被发送以后,等待特定的时间后,消费者才能拿到这个消息进行消费。\n\n延迟队列用于需要延迟工作的场景。最常见的使用场景:淘宝或者天猫我们都使用过,用户在下单之后通常有30分钟的时间进行支付,如果这30分钟之内没有支付成功,那么订单就会自动取消。\n\n除了延迟消费,延迟队列的典型应用场景还有延迟重试。比如消费者从队列里面消费消息失败了,可以延迟一段时间以后进行重试。\n\n## 2.6 特性分析\n\n这里才是内容的重点,不仅需要知道Rabbit的特性,还需要知道支持这些特性的原因:\n\n* **消息路由(支持)**:RabbitMQ可以通过不同的交换器支持不同种类的消息路由;\n* **消息有序(不支持)**:当消费消息时,如果消费失败,消息会被放回队列,然后重新消费,这样会导致消息无序;\n* **消息时序(非常好)**:通过延时队列,可以指定消息的延时时间,过期时间TTL等;\n* **容错处理(非常好)**:通过交付重试和死信交换器(DLX)来处理消息处理故障;\n* **伸缩(一般)**:伸缩其实没有非常智能,因为即使伸缩了,master queue还是只有一个,负载还是只有这一个master queue去抗,所以我理解RabbitMQ的伸缩很弱(个人理解)。\n* **持久化(不太好)**:没有消费的消息,可以支持持久化,这个是为了保证机器宕机时消息可以恢复,但是消费过的消息,就会被马上删除,因为RabbitMQ设计时,就不是为了去存储历史数据的。\n* **消息回溯(支持)**:因为消息不支持永久保存,所以自然就不支持回溯。\n* **高吞吐(中等)**:因为所有的请求的执行,最后都是在master queue,它的这个设计,导致单机性能达不到十万级的标准。\n\n# 3. RabbitMQ环境搭建\n\n因为我用的是Mac,所以直接可以参考官网:\n\n> <https://www.rabbitmq.com/install-homebrew.html>\n\n需要注意的是,一定需要先执行:\n\n brew update\n\n然后再执行:\n\n brew install rabbitmq\n\n> 之前没有执行brew update,直接执行brew install rabbitmq时,会报各种各样奇怪的错误,其中“403 Forbidde”居多。\n\n但是在执行“brew install rabbitmq”,会自动安装其它的程序,如果你使用源码安装Rabbitmq,因为启动该服务依赖erlang环境,所以你还需手动安装erlang,但是目前官方已经一键给你搞定,会自动安装Rabbitmq依赖的所有程序,是不是很棒!\n\n\n\n最后执行成功的输出如下:\n\n\n\n启动服务:\n\n # 启动方式1:后台启动\n brew services start rabbitmq\n # 启动方式2:当前窗口启动\n cd /usr/local/Cellar/rabbitmq/3.8.19\n rabbitmq-server\n\n在浏览器输入:\n\n http://localhost:15672/\n\n会出现RabbitMQ后台管理界面(用户名和密码都为guest):\n\n\n\n通过brew安装,一行命令搞定,真香!\n\n# 4. RabbitMQ测试\n\n## 4.1 添加账号\n\n首先得启动mq\n\n ## 添加账号\n ./rabbitmqctl add_user admin admin\n ## 添加访问权限\n ./rabbitmqctl set_permissions -p \"/\" admin \".*\" \".*\" \".*\"\n ## 设置超级权限\n ./rabbitmqctl set_user_tags admin administrator\n\n## 4.2 编码实测\n\n因为代码中引入了java 8的特性,pom引入依赖:\n\n <dependency>\n <groupId>com.rabbitmq</groupId>\n <artifactId>amqp-client</artifactId>\n <version>5.5.1</version>\n </dependency>\n\n <plugins>\n <plugin>\n <groupId>org.apache.maven.plugins</groupId>\n <artifactId>maven-compiler-plugin</artifactId>\n <configuration>\n <source>8</source>\n <target>8</target>\n </configuration>\n </plugin>\n </plugins>\n\n开始写代码:\n\n```java\npublic class RabbitMqTest {\n //消息队列名称\n private final static String QUEUE_NAME = \"hello\";\n\n @Test\n public void send() throws java.io.IOException, TimeoutException {\n //创建连接工程\n ConnectionFactory factory = new ConnectionFactory();\n factory.setHost(\"127.0.0.1\");\n factory.setPort(5672);\n factory.setUsername(\"admin\");\n factory.setPassword(\"admin\");\n //创建连接\n Connection connection = factory.newConnection();\n //创建消息通道\n Channel channel = connection.createChannel();\n //生成一个消息队列\n channel.queueDeclare(QUEUE_NAME, true, false, false, null);\n\n for (int i = 0; i < 10; i++) {\n String message = \"Hello World RabbitMQ count: \" + i;\n //发布消息,第一个参数表示路由(Exchange名称),为\"\"则表示使用默认消息路由\n channel.basicPublish(\"\", QUEUE_NAME, null, message.getBytes());\n System.out.println(\" [x] Sent \'\" + message + \"\'\");\n }\n //关闭消息通道和连接\n channel.close();\n connection.close();\n }\n\n @Test\n public void consumer() throws java.io.IOException, TimeoutException {\n //创建连接工厂\n ConnectionFactory factory = new ConnectionFactory();\n factory.setHost(\"127.0.0.1\");\n factory.setPort(5672);\n factory.setUsername(\"admin\");\n factory.setPassword(\"admin\");\n //创建连接\n Connection connection = factory.newConnection();\n //创建消息信道\n final Channel channel = connection.createChannel();\n //消息队列\n channel.queueDeclare(QUEUE_NAME, true, false, false, null);\n System.out.println(\"[*] Waiting for message. To exist press CTRL+C\");\n\n DeliverCallback deliverCallback = (consumerTag, delivery) -> {\n String message = new String(delivery.getBody(), \"UTF-8\");\n System.out.println(\" [x] Received \'\" + message + \"\'\");\n };\n channel.basicConsume(QUEUE_NAME, true, deliverCallback, consumerTag -> {});\n }\n}\n```\n\n执行send()后控制台输出:\n\n [x] Sent \'Hello World RabbitMQ count: 0\'\n [x] Sent \'Hello World RabbitMQ count: 1\'\n [x] Sent \'Hello World RabbitMQ count: 2\'\n [x] Sent \'Hello World RabbitMQ count: 3\'\n [x] Sent \'Hello World RabbitMQ count: 4\'\n [x] Sent \'Hello World RabbitMQ count: 5\'\n [x] Sent \'Hello World RabbitMQ count: 6\'\n [x] Sent \'Hello World RabbitMQ count: 7\'\n [x] Sent \'Hello World RabbitMQ count: 8\'\n [x] Sent \'Hello World RabbitMQ count: 9\'\n\n\n\n执行consumer()后:\n\n\n\n> 示例中的代码讲解,可以直接参考官网:<https://www.rabbitmq.com/tutorials/tutorial-one-java.html>\n\n# 5. 基本使用姿势\n\n## 5.1 公共代码封装\n\n封装工厂类:\n\n```java\npublic class RabbitUtil {\n public static ConnectionFactory getConnectionFactory() {\n //创建连接工程,下面给出的是默认的case\n ConnectionFactory factory = new ConnectionFactory();\n factory.setHost(\"127.0.0.1\");\n factory.setPort(5672);\n factory.setUsername(\"admin\");\n factory.setPassword(\"admin\");\n factory.setVirtualHost(\"/\");\n return factory;\n }\n}\n```\n\n封装生成者:\n\n```java\npublic class MsgProducer {\n public static void publishMsg(String exchange, BuiltinExchangeType exchangeType, String toutingKey, String message) throws IOException, TimeoutException {\n ConnectionFactory factory = RabbitUtil.getConnectionFactory();\n //创建连接\n Connection connection = factory.newConnection();\n //创建消息通道\n Channel channel = connection.createChannel();\n // 声明exchange中的消息为可持久化,不自动删除\n channel.exchangeDeclare(exchange, exchangeType, true, false, null);\n // 发布消息\n channel.basicPublish(exchange, toutingKey, null, message.getBytes());\n System.out.println(\"Sent \'\" + message + \"\'\");\n channel.close();\n connection.close();\n }\n}\n```\n\n封装消费者:\n\n```java\npublic class MsgConsumer {\n public static void consumerMsg(String exchange, String queue, String routingKey)\n throws IOException, TimeoutException {\n ConnectionFactory factory = RabbitUtil.getConnectionFactory();\n //创建连接\n Connection connection = factory.newConnection();\n //创建消息信道\n final Channel channel = connection.createChannel();\n //消息队列\n channel.queueDeclare(queue, true, false, false, null);\n //绑定队列到交换机\n channel.queueBind(queue, exchange, routingKey);\n System.out.println(\"[*] Waiting for message. To exist press CTRL+C\");\n\n Consumer consumer = new DefaultConsumer(channel) {\n @Override\n public void handleDelivery(String consumerTag, Envelope envelope, AMQP.BasicProperties properties,\n byte[] body) throws IOException {\n String message = new String(body, \"UTF-8\");\n try {\n System.out.println(\" [x] Received \'\" + message);\n } finally {\n System.out.println(\" [x] Done\");\n channel.basicAck(envelope.getDeliveryTag(), false);\n }\n }\n };\n // 取消自动ack\n channel.basicConsume(queue, false, consumer);\n }\n}\n```\n\n## 5.2 Direct方式\n\n\n\n#### 5.2.1 Direct示例\n\n生产者:\n\n```java\npublic class DirectProducer {\n private static final String EXCHANGE_NAME = \"direct.exchange\";\n public void publishMsg(String routingKey, String msg) {\n try {\n MsgProducer.publishMsg(EXCHANGE_NAME, BuiltinExchangeType.DIRECT, routingKey, msg);\n } catch (Exception e) {\n e.printStackTrace();\n }\n }\n public static void main(String[] args) throws InterruptedException {\n DirectProducer directProducer = new DirectProducer();\n String[] routingKey = new String[]{\"aaa\", \"bbb\", \"ccc\"};\n String msg = \"hello >>> \";\n for (int i = 0; i < 10; i++) {\n directProducer.publishMsg(routingKey[i % 3], msg + i);\n }\n System.out.println(\"----over-------\");\n Thread.sleep(1000 * 60 * 100);\n }\n}\n```\n\n执行生产者,往消息队列中放入10条消息,其中key分别为“aaa”、“bbb”和“ccc”,分别放入qa、qb、qc三个队列:\n\n\n\n下面是qa队列的信息:\n\n\n\n消费者:\n\n```java\npublic class DirectConsumer {\n private static final String exchangeName = \"direct.exchange\";\n public void msgConsumer(String queueName, String routingKey) {\n try {\n MsgConsumer.consumerMsg(exchangeName, queueName, routingKey);\n } catch (IOException e) {\n e.printStackTrace();\n } catch (TimeoutException e) {\n e.printStackTrace();\n }\n }\n public static void main(String[] args) throws InterruptedException {\n DirectConsumer consumer = new DirectConsumer();\n String[] routingKey = new String[]{\"aaa\", \"bbb\", \"ccc\"};\n String[] queueNames = new String[]{\"qa\", \"qb\", \"qc\"};\n\n for (int i = 0; i < 3; i++) {\n consumer.msgConsumer(queueNames[i], routingKey[i]);\n }\n Thread.sleep(1000 * 60 * 100);\n }\n}\n```\n\n执行后的输出:\n\n [*] Waiting for message. To exist press CTRL+C\n [x] Received \'hello >>> 0\n [x] Done\n [x] Received \'hello >>> 3\n [x] Done\n [x] Received \'hello >>> 6\n [x] Done\n [x] Received \'hello >>> 9\n [x] Done\n [*] Waiting for message. To exist press CTRL+C\n [x] Received \'hello >>> 1\n [x] Done\n [x] Received \'hello >>> 4\n [x] Done\n [x] Received \'hello >>> 7\n [x] Done\n [*] Waiting for message. To exist press CTRL+C\n [x] Received \'hello >>> 2\n [x] Done\n [x] Received \'hello >>> 5\n [x] Done\n [x] Received \'hello >>> 8\n [x] Done\n\n可以看到,分别从qa、qb、qc中将不同的key的数据消费掉。\n\n#### 5.2.2 问题探讨\n\n> 有个疑问:这个队列的名称qa、qb和qc是RabbitMQ自动生成的么,我们可以指定队列名称么?\n\n我做了个简单的实验,我把消费者代码修改了一下:\n\n```java\npublic static void main(String[] args) throws InterruptedException {\n DirectConsumer consumer = new DirectConsumer();\n String[] routingKey = new String[]{\"aaa\", \"bbb\", \"ccc\"};\n String[] queueNames = new String[]{\"qa\", \"qb\", \"qc1\"}; // 将qc修改为qc1\n\n for (int i = 0; i < 3; i++) {\n consumer.msgConsumer(queueNames[i], routingKey[i]);\n }\n Thread.sleep(1000 * 60 * 100);\n}\n```\n\n执行后如下图所示:\n\n\n\n我们可以发现,多了一个qc1,所以可以判断这个界面中的queues,是消费者执行时,会将消费者指定的队列名称和direct.exchange绑定,绑定的依据就是key。\n\n当我们把队列中的数据全部消费掉,然后重新执行生成者后,会发现qc和qc1中都有3条待消费的数据,因为绑定的key都是“ccc”,所以两者的数据是一样的:\n\n\n\n绑定关系如下:\n\n\n\n> 注意:当没有Queue绑定到Exchange时,往Exchange中写入的消息也不会重新分发到之后绑定的queue上。\n\n> 思考:不执行消费者,看不到这个Queres中信息,我其实可以把这个界面理解为消费者信息界面。不过感觉还是怪怪的,这个queues如果是消费者信息,就不应该叫queues,我理解queues应该是RabbitMQ中实际存放数据的queues,难道是我理解错了?\n\n## 5.3 Fanout方式(指定队列)\n\n\n\n生产者封装:\n\n```java\npublic class FanoutProducer {\n private static final String EXCHANGE_NAME = \"fanout.exchange\";\n public void publishMsg(String routingKey, String msg) {\n try {\n MsgProducer.publishMsg(EXCHANGE_NAME, BuiltinExchangeType.FANOUT, routingKey, msg);\n } catch (Exception e) {\n e.printStackTrace();\n }\n }\n public static void main(String[] args) {\n FanoutProducer directProducer = new FanoutProducer();\n String msg = \"hello >>> \";\n for (int i = 0; i < 10; i++) {\n directProducer.publishMsg(\"\", msg + i);\n }\n }\n}\n```\n\n消费者:\n\n```java\npublic class FanoutConsumer {\n private static final String EXCHANGE_NAME = \"fanout.exchange\";\n public void msgConsumer(String queueName, String routingKey) {\n try {\n MsgConsumer.consumerMsg(EXCHANGE_NAME, queueName, routingKey);\n } catch (IOException e) {\n e.printStackTrace();\n } catch (TimeoutException e) {\n e.printStackTrace();\n }\n }\n public static void main(String[] args) {\n FanoutConsumer consumer = new FanoutConsumer();\n String[] queueNames = new String[]{\"qa-2\", \"qb-2\", \"qc-2\"};\n for (int i = 0; i < 3; i++) {\n consumer.msgConsumer(queueNames[i], \"\");\n }\n }\n}\n```\n\n执行生成者,结果如下:\n\n\n\n我们发现,生产者生产的10条数据,在每个消费者中都可以消费,这个是和Direct不同的地方,但是使用Fanout方式时,有几个点需要注意一下:\n\n* 生产者的routkey可以为空,因为生产者的所有数据,会下放到每一个队列,所以不会通过routkey去路由;\n* 消费者需要指定queues,因为消费者需要绑定到指定的queues才能消费。\n\n\n\n这幅图就画出了Fanout的精髓之处,exchange会和所有的queue进行绑定,不区分路由,消费者需要绑定指定的queue才能发起消费。\n\n> 注意:往队列塞数据时,可能通过界面看不到消息个数的增加,可能是你之前已经开启了消费进程,导致增加的消息马上被消费了。\n\n## 5.4 Fanout方式(随机获取队列)\n\n上面我们是指定了队列,这个方式其实很不友好,比如对于Fanout,我其实根本无需关心队列的名字,如果还指定对应队列进行消费,感觉这个很冗余,所以我们这里就采用随机获取队列名字的方式,下面代码直接Copy官网。\n\n生成者封装:\n\n```java\npublic static void publishMsgV2(String exchange, BuiltinExchangeType exchangeType, String message) throws IOException, TimeoutException {\n ConnectionFactory factory = RabbitUtil.getConnectionFactory();\n //创建连接\n Connection connection = factory.newConnection();\n //创建消息通道\n Channel channel = connection.createChannel();\n\n // 声明exchange中的消息\n channel.exchangeDeclare(exchange, exchangeType);\n\n // 发布消息\n channel.basicPublish(exchange, \"\", null, message.getBytes(\"UTF-8\"));\n\n System.out.println(\"Sent \'\" + message + \"\'\");\n channel.close();\n connection.close();\n}\n```\n\n消费者封装:\n\n```java\npublic static void consumerMsgV2(String exchange) throws IOException, TimeoutException {\n ConnectionFactory factory = RabbitUtil.getConnectionFactory();\n Connection connection = factory.newConnection();\n final Channel channel = connection.createChannel();\n\n channel.exchangeDeclare(exchange, \"fanout\");\n String queueName = channel.queueDeclare().getQueue();\n channel.queueBind(queueName, exchange, \"\");\n\n System.out.println(\" [*] Waiting for messages. To exit press CTRL+C\");\n\n DeliverCallback deliverCallback = (consumerTag, delivery) -> {\n String message = new String(delivery.getBody(), \"UTF-8\");\n System.out.println(\" [x] Received \'\" + message + \"\'\");\n };\n channel.basicConsume(queueName, true, deliverCallback, consumerTag -> { });\n}\n```\n\n生产者:\n\n public class FanoutProducer {\n private static final String EXCHANGE_NAME = \"fanout.exchange.v2\";\n public void publishMsg(String msg) {\n try {\n MsgProducer.publishMsgV2(EXCHANGE_NAME, BuiltinExchangeType.FANOUT, msg);\n } catch (Exception e) {\n e.printStackTrace();\n }\n }\n public static void main(String[] args) {\n FanoutProducer directProducer = new FanoutProducer();\n String msg = \"hello >>> \";\n for (int i = 0; i < 10000; i++) {\n directProducer.publishMsg(msg + i);\n }\n }\n }\n\n消费者:\n\n```java\npublic class FanoutConsumer {\n private static final String EXCHANGE_NAME = \"fanout.exchange.v2\";\n public void msgConsumer() {\n try {\n MsgConsumer.consumerMsgV2(EXCHANGE_NAME);\n } catch (IOException e) {\n e.printStackTrace();\n } catch (TimeoutException e) {\n e.printStackTrace();\n }\n }\n public static void main(String[] args) {\n FanoutConsumer consumer = new FanoutConsumer();\n for (int i = 0; i < 3; i++) {\n consumer.msgConsumer();\n }\n }\n}\n```\n\n执行后,管理界面如下:\n\n\n\n\n\n\n\n## 5.5 Topic方式\n\n\n\n代码详见官网:<https://www.rabbitmq.com/tutorials/tutorial-five-java.html>\n\n> 更多方式,请直接查看官网:<https://www.rabbitmq.com/getstarted.html>\n\n\n\n# 6. RabbitMQ 进阶\n\n## 6.1 durable 和 autoDeleted\n\n在定义Queue时,可以指定这两个参数:\n\n```java\n/**\n * Declare an exchange.\n * @see com.rabbitmq.client.AMQP.Exchange.Declare\n * @see com.rabbitmq.client.AMQP.Exchange.DeclareOk\n * @param exchange the name of the exchange\n * @param type the exchange type\n * @param durable true if we are declaring a durable exchange (the exchange will survive a server restart)\n * @param autoDelete true if the server should delete the exchange when it is no longer in use\n * @param arguments other properties (construction arguments) for the exchange\n * @return a declaration-confirm method to indicate the exchange was successfully declared\n * @throws java.io.IOException if an error is encountered\n */\nExchange.DeclareOk exchangeDeclare(String exchange, BuiltinExchangeType type, boolean durable, boolean autoDelete,\n Map<String, Object> arguments) throws IOException;\n \n/**\n* Declare a queue\n* @see com.rabbitmq.client.AMQP.Queue.Declare\n* @see com.rabbitmq.client.AMQP.Queue.DeclareOk\n* @param queue the name of the queue\n* @param durable true if we are declaring a durable queue (the queue will survive a server restart)\n* @param exclusive true if we are declaring an exclusive queue (restricted to this connection)\n* @param autoDelete true if we are declaring an autodelete queue (server will delete it when no longer in use)\n* @param arguments other properties (construction arguments) for the queue\n* @return a declaration-confirm method to indicate the queue was successfully declared\n* @throws java.io.IOException if an error is encountered\n*/\nQueue.DeclareOk queueDeclare(String queue, boolean durable, boolean exclusive, boolean autoDelete,\n Map<String, Object> arguments) throws IOException;\n```\n\n#### 6.1.1 durable\n\n持久化,保证RabbitMQ在退出或者crash等异常情况下数据没有丢失,需要将queue,exchange和Message都持久化。\n\n若是将queue的持久化标识durable设置为true,则代表是一个持久的队列,那么在服务重启之后,会重新读取之前被持久化的queue。\n\n虽然队列可以被持久化,但是里面的消息是否为持久化,还要看消息的持久化设置。即重启queue,但是queue里面还没有发出去的消息,那队列里面还存在该消息么?这个取决于该消息的设置。\n\n#### 6.1.2 autoDeleted\n\n自动删除,如果该队列没有任何订阅的消费者的话,该队列会被自动删除。这种队列适用于临时队列。\n\n当一个Queue被设置为自动删除时,当消费者断掉之后,queue会被删除,这个主要针对的是一些不是特别重要的数据,不希望出现消息积累的情况。\n\n#### 6.1.3 小节\n\n* 当一个Queue已经声明好了之后,不能更新durable或者autoDelted值;当需要修改时,需要先删除再重新声明\n* 消费的Queue声明应该和投递的Queue声明的 durable,autoDelted属性一致,否则会报错\n* 对于重要的数据,一般设置 durable=true, autoDeleted=false\n* 对于设置 autoDeleted=true 的队列,当没有消费者之后,队列会自动被删除\n\n## 6.4 ACK\n\n执行一个任务可能需要花费几秒钟,你可能会担心如果一个消费者在执行任务过程中挂掉了。一旦RabbitMQ将消息分发给了消费者,就会从内存中删除。在这种情况下,如果正在执行任务的消费者宕机,会丢失正在处理的消息和分发给这个消费者但尚未处理的消息。\n\n但是,我们不想丢失任何任务,如果有一个消费者挂掉了,那么我们应该将分发给它的任务交付给另一个消费者去处理。\n\n为了确保消息不会丢失,RabbitMQ支持消息应答。消费者发送一个消息应答,告诉RabbitMQ这个消息已经接收并且处理完毕了。RabbitMQ就可以删除它了。\n\n因此手动ACK的常见手段:\n\n // 接收消息之后,主动ack/nak\n Consumer consumer = new DefaultConsumer(channel) {\n @Override\n public void handleDelivery(String consumerTag, Envelope envelope, AMQP.BasicProperties properties,\n byte[] body) throws IOException {\n String message = new String(body, \"UTF-8\");\n try {\n System.out.println(\" [ \" + queue + \" ] Received \'\" + message);\n channel.basicAck(envelope.getDeliveryTag(), false);\n } catch (Exception e) {\n channel.basicNack(envelope.getDeliveryTag(), false, true);\n }\n }\n };\n // 取消自动ack\n channel.basicConsume(queue, false, consumer);\n\n# 7. 结语\n\n\n\n前段时间有粉丝问我问题,是否可以只学习理论知识,如何将理论知识和应用结合起来?\n\n**我的回答:不要做 PPT 专家,理论需要和实际相结合。**\n\n那如何结合呢,比如本文的 RabbitMQ,**我之前其实没有用过,但是你可以自己把环境搭起来,然后到机器上跑跑**,虽然和实际应用还有些距离,但至少你实操过,不会浮于表面,也印象深刻,等后续项目需要使用时,就更容易上手。\n\n可能有同学杠上了,楼哥,你写的高并发系列文章,都是纯理论,没有实操,**那是因为高并发系列的东西,楼哥都搞了好几年了,现在只是简单的输出。**\n\n其实还有一个非常重要的原因,那就是**现在的读者,都喜欢看理论,不喜欢大段代码的内容,都认为看完即掌握,或者懒得动**,所以楼哥就投其所好,后面的文章就摘掉实操的内容。\n\n对于勤动手实操的同学,可以翻看楼哥之前的文章,基本每个系列,里面都有大量的实操示例哈。\n\n理论要掌握,实操不能落!\n', '0', '2023-01-13 19:54:17', '2023-01-13 19:54:17'), ('6', '104', '1', '\n\n\n\n# 第一章:小册简介\n\n以上就是小册的封面了,自我感觉还不错哈,简洁大方,但包含的信息又足够的丰富:\n\n- 小册名字:二哥的 Java 进阶之路\n- 小册作者:沉默王二\n- 小册品质:能在 GitHub 取得 7600+ star 自认为品质是有目共睹的,尤其是国内还有不少小伙伴在访问 GitHub 的时候很不顺利。\n- 小册风格:通俗易懂、风趣幽默、深度解析,新手可以拿来入门,老手可以拿来进阶,重要的知识,比如说面试高频的内容会从应用到源码挖个底朝天,还会穿插介绍一些计算机底层知识,力求讲个明白)\n- 小册简介:这是一份通俗易懂、风趣幽默的Java学习指南,内容涵盖Java基础、Java并发编程、Java虚拟机、Java面试等核心知识点。学Java,就认准二哥的Java进阶之路?\n- 小册品位:底部用了梵高 1889 年的《星空》(the starry night),绝美的漩涡星空,耀眼的月亮,宁静的村庄,还有一颗燃烧着火焰的巨大柏树,我想小册的艺术品位也是恰到好处的。\n- 小册角色:为了增加小册的趣味性,我特意为此追加了两个虚拟角色,一个二哥,一个三妹,二哥负责教,三妹负责学。这样大家在学习 Java 的时候代入感也会更强烈一些,希望这样的设定能博得大家的欢心。\n\n## 小册包含哪些内容?\n\n三妹出场:“二哥,帮读者朋友们问一下哈,为什么会有《二哥的Java进阶之路》这份小册呢?”\n\n*二哥巴拉巴拉 ing...*\n\n小册的内容主要来源于我的开源知识库《[Java程序员进阶之路](https://github.com/itwanger/toBeBetterJavaer)》,目前在 GitHub 上收获 7600+ star,深受读者喜爱。小册之所以叫《二哥的Java进阶之路》,是因为这样更方便小册的读者知道这份小册的作者是谁,IP 感更强烈一些。\n\n如果有读者是第一次阅读这份小册,肯定又会问,“二哥是哪个鸟人?”\n\n噢噢噢噢,正是鄙人了,一个英俊潇洒的男人(见下图),你可以通过我的微信公众号“**沉默王二**”了解更多关于我的信息,总之,就是一个非常喜欢王小波的程序员了,写得一手风趣幽默的技术文章,所以被读者“尊称”为二哥就对了。现实中,三妹也是真实存在的哦。\n\n\n\n《**二哥的 Java 进阶之路**》是我自学 Java 以来所有原创文章和学习资料的大聚合。[在线网站](https://tobebetterjavaer.com/)和 [GitHub 仓库](https://github.com/itwanger/toBeBetterJavaer)里的内容包括 Java 基础、Java 并发编程、Java 虚拟机、Java 企业级开发(包括开发/构建/测试、JavaWeb、SSM、Spring Boot、Linux、Nginx、Docker、k8s、微服务&分布式、消息队列等)、Java 面试等核心内容。这也是小册最终版会覆盖的内容。\n\n小册旨在为学习 Java 的小伙伴提供一系列:\n\n - **优质的原创 Java 教程**\n - **全面清晰的 Java 学习路线**\n - **免费但靠谱的 Java 学习资料**\n - **精选的 Java 岗求职面试指南**\n - **Java 企业级开发所需的必备技术**\n\n接下来,送你 4 个“掏心掏肺”的阅读建议:\n\n- 如果你是零基础的小白,可以按照小册的顺序一路读下去,小册的内容安排都是经过我精心安排的;\n- 否则,请按照目录按需阅读,该跳过的跳过,该放慢节奏的放慢节奏。\n- 小册中会有一个虚拟人物,三妹,当然她的原型也是真实存在的,目的就是通过我们之间的对话,来增强文章的趣味性,以便你能更轻松地获取知识。\n- 最重要的一点,“光看不练假把戏”,请在阅读的过程中把该敲的代码敲了,把该记的笔记记了,语雀、思维导图、GitHub 仓库都可以,养成好的学习习惯。\n\n这里展示一下暗黑版的 PDF 视图,大家先感受一下,手绘图都画得非常用心。\n\n\n\n这是 epub 版本的阅读效果,感觉左右翻动的效果好舒服,一次可以看两页,真的就像在读纸质版书籍一样,体验非常棒。\n\n\n\n如果你喜欢在线阅读,请戳下面这个网址:\n\n> [https://tobebetterjavaer.com](https://tobebetterjavaer.com)\n\n首页见下图,同样简洁、清新、方便沉浸式阅读:\n\n\n\n你也可以到技术派的[教程栏(戳这里)](https://paicoding.com/column)里阅读,目前正在连载更新中。\n\n\n\n>技术派是一个基于 Spring Boot、MyBatis-Plus、MySQL、Redis、ElasticSearch、MongoDB、Docker、RabbitMQ 等技术栈实现的社区系统,采用主流的互联网技术架构、全新的UI设计、支持一键源码部署,拥有完整的文章&教程发布/搜索/评论/统计流程等,[代码完全开源(可戳)](https://github.com/itwanger/paicoding),没有任何二次封装,是一个非常适合二次开发/实战的现代化社区项目? 。\n\n如果你在阅读过程中感觉这份小册写的还不错,甚至有亿点点收获,**请肆无忌惮地把这份小册分享给你的同事、同学、舍友、朋友,让他们也进步亿点点,赠人玫瑰手有余香嘛**。\n\n如果这份小册有幸被更多人看得到,我的虚荣心也会得到恰当的满足,嘿嘿?\n\n## 如何获取最新版?\n\n小册分为 3 个版本,暗黑版(适合夜服)、亮白版(适合打印)、epub 版,可以说凝聚了二哥十多年来学习 Java 的心血,33 万+,绝对不虚市面上任何一本 Java 实体书!\n\n\n\n小册会持续保持**更新**,如果想获得最新版,请在我的微信公众号 **沉默王二** 后台回复 **222** 获取(你懂我的意思吧,我肯定是足够二才有这样的勇气定义这样一个关键字)!\n\n\n\n## 面试指南(配套教程)\n\n《Java 面试指南》是[二哥编程星球的](https://tobebetterjavaer.com/zhishixingqiu/)的一个内部小册,和《Java 进阶之路》内容互补。相比开源的版本来说,《Java 面试指南》添加了下面这些板块和内容:\n\n- 面试准备篇(20+篇),手把手教你如何准备面试。\n- 职场修炼篇(10+篇),手摸手教你如何在职场中如鱼得水。\n- 技术提升篇(30+篇),手拉手教你如何成为团队不可或缺的技术攻坚小能手。\n- 面经分享篇(20+篇),手牵手教你如何在面试中知彼知己,百战不殆。\n- 场景设计篇(20+篇),手握手教你如何在面试中脱颖而出。\n\n### 内容概览\n\n#### 面试准备篇\n\n所谓临阵磨枪,不快也光。更何况提前做好充足的准备呢?这 20+篇文章会系统地引导你该如何做准备。\n\n\n\n#### 职场修炼篇\n\n如何平滑度过试用期?如何平滑度过 35 岁程序员危机?如何在繁重的工作中持续成长?如何做副业?等等,都是大家迫切关心的问题,这 10+篇文章会一一为你揭晓答案。\n\n\n\n#### 技术提升篇\n\n编程能力、技术功底,是我们程序员安身立命之本,是我们求职/工作的最核心的武器。\n\n\n\n#### 面经分享篇\n\n知彼知己,方能百战不殆,我们必须得站在学长学姐的肩膀上,才能走得更远更快。\n\n\n\n#### 场景设计题篇\n\n这里收录的都是精华,让天底下没有难背的八股文;场景设计题篇页都是面试中经常考察的大项,可以让你和面试官对线半小时(?)\n\n\n\n### 星球其他资源\n\n除了《Java 面试指南》外,星球还提供了《编程喵实战项目笔记》、《二哥的 LeetCode 刷题笔记》,以及技术派实战项目配套的 120+篇硬核教程。\n\n\n\n这里重点介绍一下技术派吧,这个项目上线后,一直广受好评,读者朋友们的认可度非常高,项目配套的教程也足够的硬核。\n\n\n\n这是部分目录(共计 120 篇,大厂篇、基础篇、进阶篇、工程篇,全部落地)。\n\n开篇:\n\n- 技术答疑(⭐️)\n- 技术派问题反馈及解决方案(⭐️)\n- 踩坑实录之本地缓存Caffeine采坑实录(⭐️)\n- 技术派系统架构、功能模块一览(⭐️⭐️⭐️⭐️⭐️)\n\n大厂篇:\n\n- 技术派产品调研,让你了解产品诞生背后的故事(⭐️⭐️)\n- 技术派产品设计(⭐️)\n- 技术派交互视觉设计(⭐️)\n- 技术派整体架构方案设计全过程(⭐️⭐️⭐️)\n- 技术方案详细设计(⭐️⭐️⭐️⭐️)\n- 技术派项目管理流程(⭐️⭐️)\n- 技术派项目管理研发阶段(⭐️⭐️⭐️)\n\n基础篇:\n\n- 技术派中实体对象 DO、DTO、VO 到底代表了什么(⭐️)\n- 通过技术派项目讲解 MVC 分层架构的应用(⭐️⭐️)\n- 技术派整合本地缓存之Guava(⭐️⭐️⭐️)\n- 技术派整合本地缓存之Caffeine(⭐️⭐️⭐️⭐️)\n- 技术派整合 Redis(⭐️)\n- 技术派中基于 Redis 的缓存示例(⭐️⭐️⭐️)\n- 技术派中基于Cacheable注解实现缓存示例(⭐️⭐️)\n- 技术派中的事务使用实例(⭐️⭐️⭐️)\n- 事务使用的 7 条注意事项(⭐️⭐️⭐️)\n- 技术派中的多配置文件说明(⭐️)\n- 技术派整合 Logback/lombok 配置日志输出(⭐️)\n- 技术派整合邮件服务实现邮件发送(⭐️)\n- Web 三大组件之 Filter 在技术派中的应用(⭐️)\n- Web 三大组件之 Servlet 在技术派中的应用(⭐️)\n- Web 三大组件之 listenter 在技术派中的应用(⭐️)\n- 技术派实时在线人数统计-单机版(⭐️)\n\n进阶篇:\n\n- 技术派之扫码登录实现原理(⭐️)\n- 技术派身份验证之session与 cookie(⭐️)\n- 技术派中基于异常日志的报警通知(⭐️)\n\n扩展篇:\n\n- 技术派的数据库表自动初始化实现方案(⭐️⭐️⭐️⭐️⭐️)\n- 技术派中基于 filter 实现请求日志记录(⭐️)\n\n工程篇:\n\n- 技术派项目工程搭建手册(⭐️⭐️⭐️⭐️)\n- 技术派本地多机器部署开发教程(⭐️⭐️)\n- 技术派服务器部署指导手册(⭐️⭐️)\n- 技术派的 MVC 分层架构(⭐️⭐️)\n- 技术派 Docker 本机部署开发手册(⭐️⭐️⭐️)\n- 技术派多环境配置管理(⭐️)\n\n欣赏一下技术派实战项目的首页吧,绝壁清新、高级、上档次!\n\n\n\n### 星球限时优惠\n\n一年前,星球的定价是 99 元一年,第一批优惠券的额度是 30 元,等于说 69 元的低价就可以加入,再扣除掉星球手续费,几乎就是纯粹做公益。\n\n随着时间的推移,星球积累的干货/资源越来越多,我花在星球上的时间也越来越多,[星球的知识图谱](https://tobebetterjavaer.com/zhishixingqiu/map.html)里沉淀的问题,你可以戳这个[链接](https://tobebetterjavaer.com/zhishixingqiu/map.html)去感受一下。有学习计划啊、有学生党秋招&春招&offer选择&考研&实习&专升本&培训班的问题啊、有工作党方向选择&转行&求职&职业规划的问题啊,还有大大小小的技术细节,我都竭尽全力去帮助球友,并且得到了球友的认可和尊重。\n\n目前星球已经 2100+ 人了,所以星球也涨价到了 119 元,后续会讲星球的价格调整为 139 元/年,所以想加入的小伙伴一定要趁早。\n\n\n\n你可以添加我的微信(没有⼿机号再申请微信,故使⽤企业微信。不过,请放⼼,这个号的消息也是\n我本⼈处理,平时最常看这个微信)领取星球专属优惠券(推荐),限时 89/年 加⼊(续费半价)!\n\n<img src=\"https://cdn.tobebetterjavaer.com/tobebetterjavaer/images/zhishixingqiu/readme-c773d5ff-4458-4d92-868b-2d1d95d6a409.png\" title=\"二哥的编程星球\" width=\"300\" />\n\n\n或者你也可以微信扫码或者长按自动识别领取 30 元优惠券,**89/年** 加入!\n\n<img src=\"https://cdn.tobebetterjavaer.com/stutymore/readme-20230411114734.png\" title=\"二哥的编程星球\" width=\"300\" />\n\n对了,**加入星球后记得花 10 分钟时间看一下星球的两个置顶贴,你会发现物超所值**!\n\n成功没有一蹴而就,没有一飞冲天,但只要你能够一步一个脚印,就能取得你心满意足的好结果,请给自己一个机会!\n\n最后,把二哥的座右铭送给你:**没有什么使我停留——除了目的,纵然岸旁有玫瑰、有绿荫、有宁静的港湾,我是不系之舟**。\n\n共勉 ⛽️。\n\n## 如何贡献?\n\n对了,如果你在阅读的过程中遇到一些错误,欢迎到我的开源仓库提交 issue、PR(审核通过后可成为 Contributor),我会第一时间修正,感谢你为后来者做出的贡献。\n\n>- GitHub:[https://github.com/itwanger/toBeBetterJavaer](https://github.com/itwanger/toBeBetterJavaer)\n>- 码云:[https://gitee.com/itwanger/toBeBetterJavaer](https://gitee.com/itwanger/toBeBetterJavaer)\n\n## 更新记录\n\n### V1.0-2023年04月11日\n\n第一版《二哥的 Java 进阶之路》正式完结发布!', '0', '2023-04-15 15:25:17', '2023-04-15 15:25:17');
INSERT INTO `article_detail` VALUES ('7', '104', '2', '\n\n以上就是小册的封面了,自我感觉还不错哈,简洁大方,但包含的信息又足够的丰富:\n\n- 小册名字:二哥的 Java 进阶之路\n- 小册作者:沉默王二\n- 小册品质:能在 GitHub 取得 7600+ star 自认为品质是有目共睹的,尤其是国内还有不少小伙伴在访问 GitHub 的时候很不顺利。\n- 小册风格:通俗易懂、风趣幽默、深度解析,新手可以拿来入门,老手可以拿来进阶,重要的知识,比如说面试高频的内容会从应用到源码挖个底朝天,还会穿插介绍一些计算机底层知识,力求讲个明白)\n- 小册简介:这是一份通俗易懂、风趣幽默的Java学习指南,内容涵盖Java基础、Java并发编程、Java虚拟机、Java面试等核心知识点。学Java,就认准二哥的Java进阶之路?\n- 小册品位:底部用了梵高 1889 年的《星空》(the starry night),绝美的漩涡星空,耀眼的月亮,宁静的村庄,还有一颗燃烧着火焰的巨大柏树,我想小册的艺术品位也是恰到好处的。\n- 小册角色:为了增加小册的趣味性,我特意为此追加了两个虚拟角色,一个二哥,一个三妹,二哥负责教,三妹负责学。这样大家在学习 Java 的时候代入感也会更强烈一些,希望这样的设定能博得大家的欢心。\n\n## 小册包含哪些内容?\n\n三妹出场:“二哥,帮读者朋友们问一下哈,为什么会有《二哥的Java进阶之路》这份小册呢?”\n\n*二哥巴拉巴拉 ing...*\n\n小册的内容主要来源于我的开源知识库《[Java程序员进阶之路](https://github.com/itwanger/toBeBetterJavaer)》,目前在 GitHub 上收获 7600+ star,深受读者喜爱。小册之所以叫《二哥的Java进阶之路》,是因为这样更方便小册的读者知道这份小册的作者是谁,IP 感更强烈一些。\n\n如果有读者是第一次阅读这份小册,肯定又会问,“二哥是哪个鸟人?”\n\n噢噢噢噢,正是鄙人了,一个英俊潇洒的男人(见下图),你可以通过我的微信公众号“**沉默王二**”了解更多关于我的信息,总之,就是一个非常喜欢王小波的程序员了,写得一手风趣幽默的技术文章,所以被读者“尊称”为二哥就对了。现实中,三妹也是真实存在的哦。\n\n\n\n《**二哥的 Java 进阶之路**》是我自学 Java 以来所有原创文章和学习资料的大聚合。[在线网站](https://tobebetterjavaer.com/)和 [GitHub 仓库](https://github.com/itwanger/toBeBetterJavaer)里的内容包括 Java 基础、Java 并发编程、Java 虚拟机、Java 企业级开发(包括开发/构建/测试、JavaWeb、SSM、Spring Boot、Linux、Nginx、Docker、k8s、微服务&分布式、消息队列等)、Java 面试等核心内容。这也是小册最终版会覆盖的内容。\n\n小册旨在为学习 Java 的小伙伴提供一系列:\n\n - **优质的原创 Java 教程**\n - **全面清晰的 Java 学习路线**\n - **免费但靠谱的 Java 学习资料**\n - **精选的 Java 岗求职面试指南**\n - **Java 企业级开发所需的必备技术**\n\n接下来,送你 4 个“掏心掏肺”的阅读建议:\n\n- 如果你是零基础的小白,可以按照小册的顺序一路读下去,小册的内容安排都是经过我精心安排的;\n- 否则,请按照目录按需阅读,该跳过的跳过,该放慢节奏的放慢节奏。\n- 小册中会有一个虚拟人物,三妹,当然她的原型也是真实存在的,目的就是通过我们之间的对话,来增强文章的趣味性,以便你能更轻松地获取知识。\n- 最重要的一点,“光看不练假把戏”,请在阅读的过程中把该敲的代码敲了,把该记的笔记记了,语雀、思维导图、GitHub 仓库都可以,养成好的学习习惯。\n\n这里展示一下暗黑版的 PDF 视图,大家先感受一下,手绘图都画得非常用心。\n\n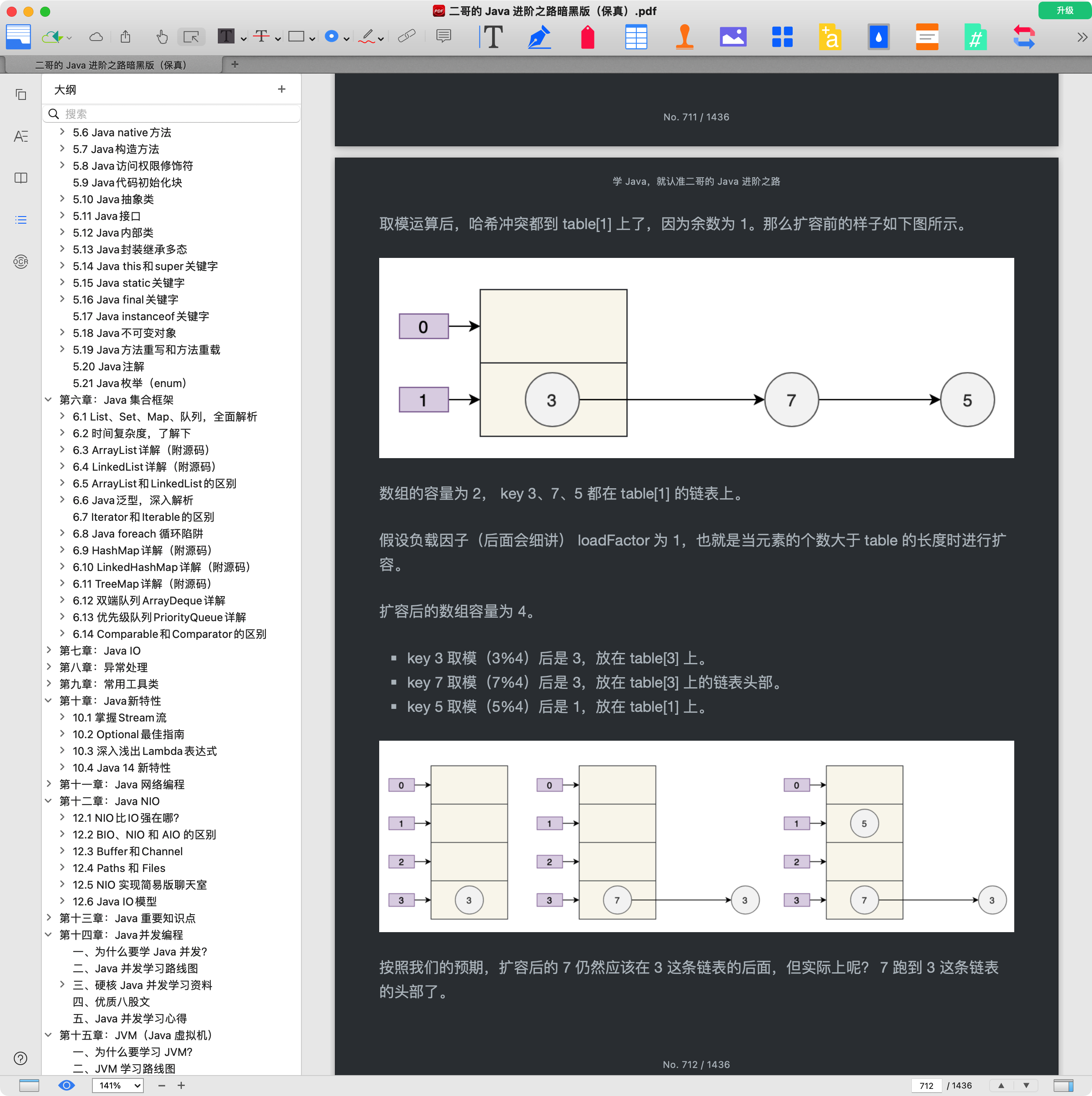\n\n这是 epub 版本的阅读效果,感觉左右翻动的效果好舒服,一次可以看两页,真的就像在读纸质版书籍一样,体验非常棒。\n\n\n\n如果你喜欢在线阅读,请戳下面这个网址:\n\n> [https://tobebetterjavaer.com](https://tobebetterjavaer.com)\n\n首页见下图,同样简洁、清新、方便沉浸式阅读:\n\n\n\n你也可以到技术派的[教程栏(戳这里)](https://paicoding.com/column)里阅读,目前正在连载更新中。\n\n\n\n>技术派是一个基于 Spring Boot、MyBatis-Plus、MySQL、Redis、ElasticSearch、MongoDB、Docker、RabbitMQ 等技术栈实现的社区系统,采用主流的互联网技术架构、全新的UI设计、支持一键源码部署,拥有完整的文章&教程发布/搜索/评论/统计流程等,[代码完全开源(可戳)](https://github.com/itwanger/paicoding),没有任何二次封装,是一个非常适合二次开发/实战的现代化社区项目? 。\n\n如果你在阅读过程中感觉这份小册写的还不错,甚至有亿点点收获,**请肆无忌惮地把这份小册分享给你的同事、同学、舍友、朋友,让他们也进步亿点点,赠人玫瑰手有余香嘛**。\n\n如果这份小册有幸被更多人看得到,我的虚荣心也会得到恰当的满足,嘿嘿?\n\n## 如何获取最新版?\n\n小册分为 3 个版本,暗黑版(适合夜服)、亮白版(适合打印)、epub 版,可以说凝聚了二哥十多年来学习 Java 的心血,33 万+,绝对不虚市面上任何一本 Java 实体书!\n\n\n\n小册会持续保持**更新**,如果想获得最新版,请在我的微信公众号 **沉默王二** 后台回复 **222** 获取(你懂我的意思吧,我肯定是足够二才有这样的勇气定义这样一个关键字)!\n\n\n\n## 面试指南(配套教程)\n\n《Java 面试指南》是[二哥编程星球的](https://tobebetterjavaer.com/zhishixingqiu/)的一个内部小册,和《Java 进阶之路》内容互补。相比开源的版本来说,《Java 面试指南》添加了下面这些板块和内容:\n\n- 面试准备篇(20+篇),手把手教你如何准备面试。\n- 职场修炼篇(10+篇),手摸手教你如何在职场中如鱼得水。\n- 技术提升篇(30+篇),手拉手教你如何成为团队不可或缺的技术攻坚小能手。\n- 面经分享篇(20+篇),手牵手教你如何在面试中知彼知己,百战不殆。\n- 场景设计篇(20+篇),手握手教你如何在面试中脱颖而出。\n\n### 内容概览\n\n#### 面试准备篇\n\n所谓临阵磨枪,不快也光。更何况提前做好充足的准备呢?这 20+篇文章会系统地引导你该如何做准备。\n\n\n\n#### 职场修炼篇\n\n如何平滑度过试用期?如何平滑度过 35 岁程序员危机?如何在繁重的工作中持续成长?如何做副业?等等,都是大家迫切关心的问题,这 10+篇文章会一一为你揭晓答案。\n\n\n\n#### 技术提升篇\n\n编程能力、技术功底,是我们程序员安身立命之本,是我们求职/工作的最核心的武器。\n\n\n\n#### 面经分享篇\n\n知彼知己,方能百战不殆,我们必须得站在学长学姐的肩膀上,才能走得更远更快。\n\n\n\n#### 场景设计题篇\n\n这里收录的都是精华,让天底下没有难背的八股文;场景设计题篇页都是面试中经常考察的大项,可以让你和面试官对线半小时(?)\n\n\n\n### 星球其他资源\n\n除了《Java 面试指南》外,星球还提供了《编程喵实战项目笔记》、《二哥的 LeetCode 刷题笔记》,以及技术派实战项目配套的 120+篇硬核教程。\n\n\n\n这里重点介绍一下技术派吧,这个项目上线后,一直广受好评,读者朋友们的认可度非常高,项目配套的教程也足够的硬核。\n\n\n\n这是部分目录(共计 120 篇,大厂篇、基础篇、进阶篇、工程篇,全部落地)。\n\n开篇:\n\n- 技术答疑(⭐️)\n- 技术派问题反馈及解决方案(⭐️)\n- 踩坑实录之本地缓存Caffeine采坑实录(⭐️)\n- 技术派系统架构、功能模块一览(⭐️⭐️⭐️⭐️⭐️)\n\n大厂篇:\n\n- 技术派产品调研,让你了解产品诞生背后的故事(⭐️⭐️)\n- 技术派产品设计(⭐️)\n- 技术派交互视觉设计(⭐️)\n- 技术派整体架构方案设计全过程(⭐️⭐️⭐️)\n- 技术方案详细设计(⭐️⭐️⭐️⭐️)\n- 技术派项目管理流程(⭐️⭐️)\n- 技术派项目管理研发阶段(⭐️⭐️⭐️)\n\n基础篇:\n\n- 技术派中实体对象 DO、DTO、VO 到底代表了什么(⭐️)\n- 通过技术派项目讲解 MVC 分层架构的应用(⭐️⭐️)\n- 技术派整合本地缓存之Guava(⭐️⭐️⭐️)\n- 技术派整合本地缓存之Caffeine(⭐️⭐️⭐️⭐️)\n- 技术派整合 Redis(⭐️)\n- 技术派中基于 Redis 的缓存示例(⭐️⭐️⭐️)\n- 技术派中基于Cacheable注解实现缓存示例(⭐️⭐️)\n- 技术派中的事务使用实例(⭐️⭐️⭐️)\n- 事务使用的 7 条注意事项(⭐️⭐️⭐️)\n- 技术派中的多配置文件说明(⭐️)\n- 技术派整合 Logback/lombok 配置日志输出(⭐️)\n- 技术派整合邮件服务实现邮件发送(⭐️)\n- Web 三大组件之 Filter 在技术派中的应用(⭐️)\n- Web 三大组件之 Servlet 在技术派中的应用(⭐️)\n- Web 三大组件之 listenter 在技术派中的应用(⭐️)\n- 技术派实时在线人数统计-单机版(⭐️)\n\n进阶篇:\n\n- 技术派之扫码登录实现原理(⭐️)\n- 技术派身份验证之session与 cookie(⭐️)\n- 技术派中基于异常日志的报警通知(⭐️)\n\n扩展篇:\n\n- 技术派的数据库表自动初始化实现方案(⭐️⭐️⭐️⭐️⭐️)\n- 技术派中基于 filter 实现请求日志记录(⭐️)\n\n工程篇:\n\n- 技术派项目工程搭建手册(⭐️⭐️⭐️⭐️)\n- 技术派本地多机器部署开发教程(⭐️⭐️)\n- 技术派服务器部署指导手册(⭐️⭐️)\n- 技术派的 MVC 分层架构(⭐️⭐️)\n- 技术派 Docker 本机部署开发手册(⭐️⭐️⭐️)\n- 技术派多环境配置管理(⭐️)\n\n欣赏一下技术派实战项目的首页吧,绝壁清新、高级、上档次!\n\n\n\n### 星球限时优惠\n\n一年前,星球的定价是 99 元一年,第一批优惠券的额度是 30 元,等于说 69 元的低价就可以加入,再扣除掉星球手续费,几乎就是纯粹做公益。\n\n随着时间的推移,星球积累的干货/资源越来越多,我花在星球上的时间也越来越多,[星球的知识图谱](https://tobebetterjavaer.com/zhishixingqiu/map.html)里沉淀的问题,你可以戳这个[链接](https://tobebetterjavaer.com/zhishixingqiu/map.html)去感受一下。有学习计划啊、有学生党秋招&春招&offer选择&考研&实习&专升本&培训班的问题啊、有工作党方向选择&转行&求职&职业规划的问题啊,还有大大小小的技术细节,我都竭尽全力去帮助球友,并且得到了球友的认可和尊重。\n\n目前星球已经 2100+ 人了,所以星球也涨价到了 119 元,后续会讲星球的价格调整为 139 元/年,所以想加入的小伙伴一定要趁早。\n\n\n\n你可以添加我的微信(没有⼿机号再申请微信,故使⽤企业微信。不过,请放⼼,这个号的消息也是\n我本⼈处理,平时最常看这个微信)领取星球专属优惠券(推荐),限时 89/年 加⼊(续费半价)!\n\n<img src=\"https://cdn.tobebetterjavaer.com/tobebetterjavaer/images/zhishixingqiu/readme-c773d5ff-4458-4d92-868b-2d1d95d6a409.png\" title=\"二哥的编程星球\" width=\"300\" />\n\n\n或者你也可以微信扫码或者长按自动识别领取 30 元优惠券,**89/年** 加入!\n\n<img src=\"https://cdn.tobebetterjavaer.com/stutymore/readme-20230411114734.png\" title=\"二哥的编程星球\" width=\"300\" />\n\n对了,**加入星球后记得花 10 分钟时间看一下星球的两个置顶贴,你会发现物超所值**!\n\n成功没有一蹴而就,没有一飞冲天,但只要你能够一步一个脚印,就能取得你心满意足的好结果,请给自己一个机会!\n\n最后,把二哥的座右铭送给你:**没有什么使我停留——除了目的,纵然岸旁有玫瑰、有绿荫、有宁静的港湾,我是不系之舟**。\n\n共勉 ⛽️。\n\n## 如何贡献?\n\n对了,如果你在阅读的过程中遇到一些错误,欢迎到我的开源仓库提交 issue、PR(审核通过后可成为 Contributor),我会第一时间修正,感谢你为后来者做出的贡献。\n\n>- GitHub:[https://github.com/itwanger/toBeBetterJavaer](https://github.com/itwanger/toBeBetterJavaer)\n>- 码云:[https://gitee.com/itwanger/toBeBetterJavaer](https://gitee.com/itwanger/toBeBetterJavaer)\n\n## 更新记录\n\n### V1.0-2023年04月11日\n\n第一版《二哥的 Java 进阶之路》正式完结发布!', '0', '2023-04-15 15:25:17', '2023-04-15 15:25:17'), ('8', '105', '1', '大家好,我是二哥呀。\n\n给大家官宣一件大事,我们搞了近半年的实战项目——[**技术派**](https://paicoding.com/),终于上线了!瞅瞅这首页,清新、高级、上档次!\n\n\n\n瞅瞅我们的文章详情页的楼仔,帅气、文雅,气质拿捏的死死的。\n\n\n\n文章底部的点赞、留言、文章目录,都是妥妥的细节控。\n\n\n\n我们的教程,写得特别用心,这篇《高并发限流》近万字,手绘图也是毫不吝啬。\n\n\n\n[admin 端](https://paicoding.com/admin-view)也是开源的,可以对文章/教程进行管理配置,并且加入了游客/管理员账户,方便大家在线体验。\n\n\n\n好了,接下来,就由我来给大家“隆重”地介绍一下技术派的整个生态圈子。\n\n## 技术派是做什么的?\n\n这是一个基于 Spring Boot、MyBatis-Plus、MySQL、Redis、ElasticSearch、MongoDB、Docker、RabbitMQ 等技术栈实现的社区系统,**采用主流的互联网技术架构、全新的UI设计、支持一键源码部署**,拥有完整的文章&教程发布/搜索/评论/统计流程等,代码完全开源,没有任何二次封装,是一个非常适合二次开发/实战的现代化社区项目? 。\n\n>- 首页地址:[https://paicoding.com](https://paicoding.com)\n>- GitHub 仓库:[https://github.com/itwanger/paicoding](https://github.com/itwanger/paicoding)\n>- 码云仓库(国内访问更快):[https://gitee.com/itwanger/paicoding](https://gitee.com/itwanger/paicoding)\n\n对于这个项目我们是有野心的:\n\n1、国内的不少社区不思进取,你发个文章各种限制你,不让你干这个不让你干那个(我就不点名批评了,比如说某乎放个 B站视频链接就不给你流量),我们就是要打破这种条条框框,给开发者一个自由创作的平台。\n\n2、到了找工作的季节,很多小伙伴简历上没有项目经验可写,这个很吃亏。虽然 GitHub 和码云上已经有不少优秀的开源项目,但**大多数没有成熟且体系化的教程**,总不能直接下载到本地跑一下 main 方法就算学习了吧?\n\n我们要负责到底!接下来,我们会更新一系列的教程,不仅包含项目的开发文档,还会包括 Java、Go 语言、Spring、MySQL、Redis、微服务&分布式、消息队列、操作系统、计算机网络、数据结构与算法等内容。\n\n总之一句话:**学编程,就上技术派**?。\n\n## 技术派能让你学到什么?\n\n这绝不是我在口嗨哈,给大家看一下我们的系统架构图,就知道我们有多用心。\n\n\n\n再用文字详细地描述下,方便大家做笔记,也方便大家监督我们,这些技术栈最终都将以专栏/教程的方式和大家见面,让天下没有难学的技术(?)!\n\n- 构建工具:后端(Maven、Gradle)、前端(Webpack、Vite)\n- 单元测试:[Junit](https://tobebetterjavaer.com/gongju/junit.html)\n- 开发框架:SpringMVC、Spring、Spring Boot\n- Web 服务器:Tomcat、Caddy、Nginx\n- 微服务:Spring Cloud\n- 数据层:JPA、MyBatis、MyBatis-Plus\n- 模板引擎:thymeleaf\n- 容器:Docker(镜像仓库服务Harbor、图形化工具Portainer)、k8s、Podman\n- 分布式 RPC 框架:Dubbo\n- 消息队列:Kafka(图形化工具Eagle)、RocketMQ、RabbitMQ、Pulsar\n- 持续集成:Jenkins、Drone\n- 压力测试:Jmeter\n- 数据库:MySQL(数据库中间件Gaea、同步数据canal、数据库迁移工具Flyway)\n- 缓存:Redis(增强模块RedisMod、ORM框架RedisOM)\n- nosql:MongoDB\n- 对象存储服务:minio\n- 日志:[Log4j](https://tobebetterjavaer.com/gongju/log4j.html)、[Logback](https://tobebetterjavaer.com/gongju/logback.html)、[SF4J](https://tobebetterjavaer.com/gongju/slf4j.html)、[Log4j2](https://tobebetterjavaer.com/gongju/log4j2.html)\n- 搜索引擎:ES\n- 日志收集:ELK(日志采集器Filebeat)、EFK(Fluentd)、LPG(Loki+Promtail+Grafana)\n- 大数据:Spark、Hadoop、HBase、Hive、Storm、Flink\n- 分布式应用程序协调:Zookeeper\n- token 管理:jwt(nimbus-jose-jwt)\n- 诊断工具:arthas\n- 安全框架:Shiro、SpringSecurity\n- 权限框架:Keycloak、Sa-Token\n- JSON 处理:fastjson2、[Jackson](https://tobebetterjavaer.com/gongju/jackson.html)、[Gson](https://tobebetterjavaer.com/gongju/gson.html)\n- office 文档操作:EasyPoi、EasyExcel\n- 文件预览:kkFileView\n- 属性映射:mapStruct\n- Java硬件信息库:oshi\n- Java 连接 SSH 服务器:ganymed\n- 接口文档:Swagger-ui、Knife4j、Spring Doc、Torna、YApi\n- 任务调度框架:Spring Task、Quartz、PowerJob、XXL-Job\n- Git服务:Gogs\n- 低代码:LowCodeEngine、Yao、Erupt、magic-api\n- API 网关:Gateway、Zuul、apisix\n- 数据可视化(Business Intelligence,也就是 BI):DataEase、Metabase\n- 项目文档:Hexo、VuePress\n- 应用监控:SpringBoot Admin、Grafana、SkyWalking、Elastic APM\n- 注解:lombok\n- jdbc连接池:Druid\n- Java 工具包:hutool、Guava\n- 数据检查:hibernate validator\n- 代码生成器:Mybatis generator\n- Web 自动化测试:selenium\n- HTTP客户端工具:Retrofit\n- 脚手架:sa-plus\n\n我们希望通过**技术派**这个项目打造一个闭环,既能帮大家提升项目经验、升职加薪,又能提升我们的技术影响力,还能增加我们原创教程的流量(典型的既要又要还要,有没有?)。\n\n\n\n为了做好这个项目,我们付出了巨大的努力。先来看源码,分支 30 个,提交 595 次,这还不包括 admin 端的,已经推出,就广受好评,这才第一周,就收获了 100+ star,这还只是码云上。\n\n\n\n\n\n代码严格按照大厂的规范要求来,组织结构清晰、项目文档齐全、代码注释到位,你想学不到知识都难!\n\n\n\n只要你本地安装好 JDK 8(以上版本均可),MySQL(5.x/8.x+),配置好 Maven,导入项目源码后,直接运行 main 方法就可以轻松在本地跑起来,你甚至不需要额外手动创建数据库,不用在浏览器地址栏键入 `localhost:8080`,只要轻轻一点控制台提供的链接就可以访问了。\n\n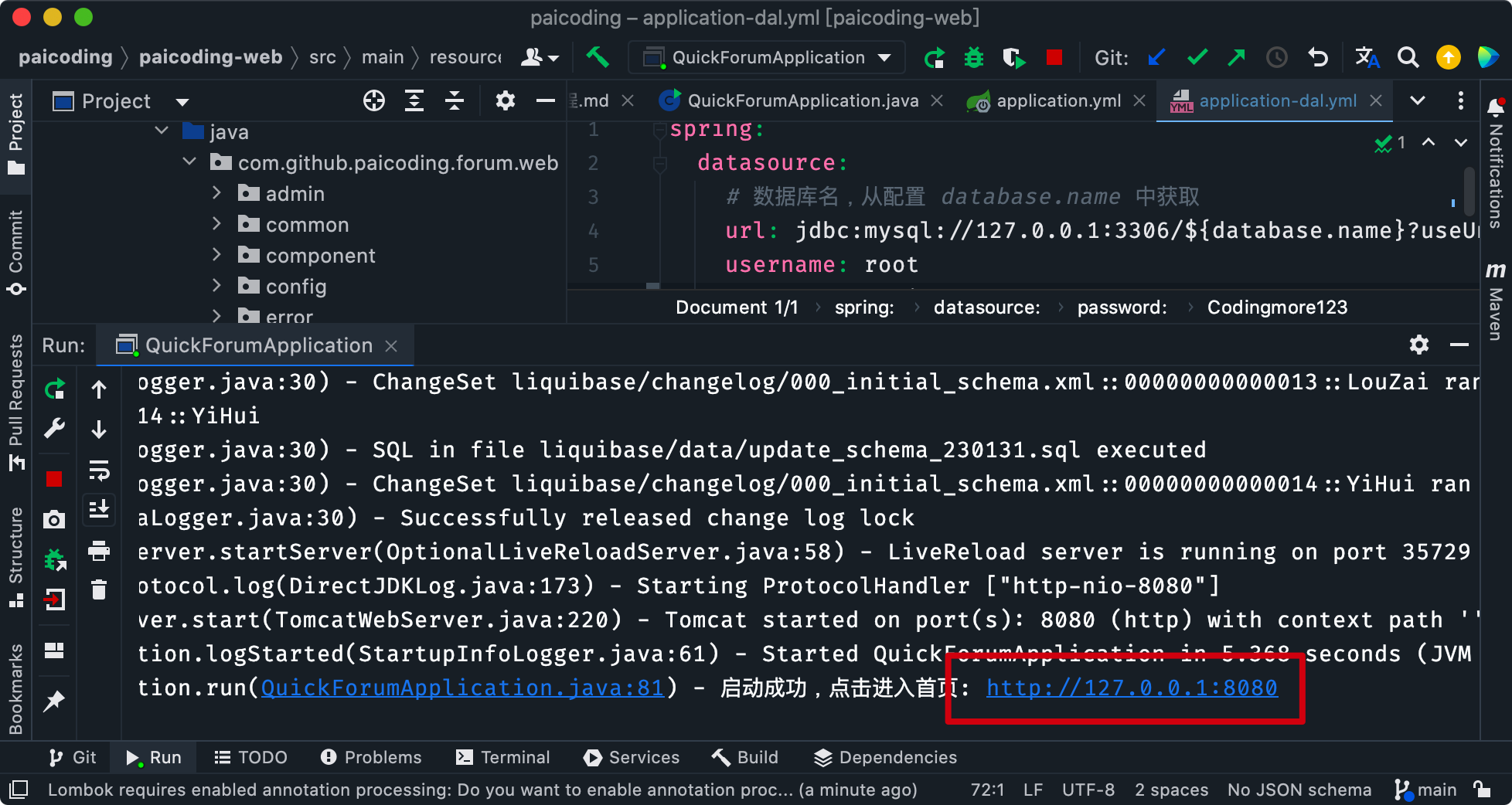\n\n这些琐事我们已经帮你做好了,省心吧?\n\n## 技术派的成长过程\n\n这个项目并不是二哥一时兴起发起的,而是做了充分的准备和调研。来介绍一下我们技术派的联合创始人,前后端我们三个人均有参与:\n\n- **楼仔**,8 年一线大厂后端经验(百度/小米/美团),技术派团队负责人,擅长高并发、架构、源码,有很强的项目/团队管理、职业规划能力\n- **一灰**,国企里莫过鱼、大厂里拧过螺丝、创业团队冲过浪的资深后端,主研Java技术栈,擅长架构设计、高并发、微服务等领域\n- **沉默王二**,GitHub 星标 6400k+开源知识库《Java 程序员进阶之路》作者,CSDN 两届博客之星,掘金/知乎 Java 领域优质创作者\n\n前期的需求调研、开发中的进度管理、上线后的文档教程,也都是不能少的,后期我们也会把这些开源出来,先截图给大家看看。\n\n1、整体设计草图\n\n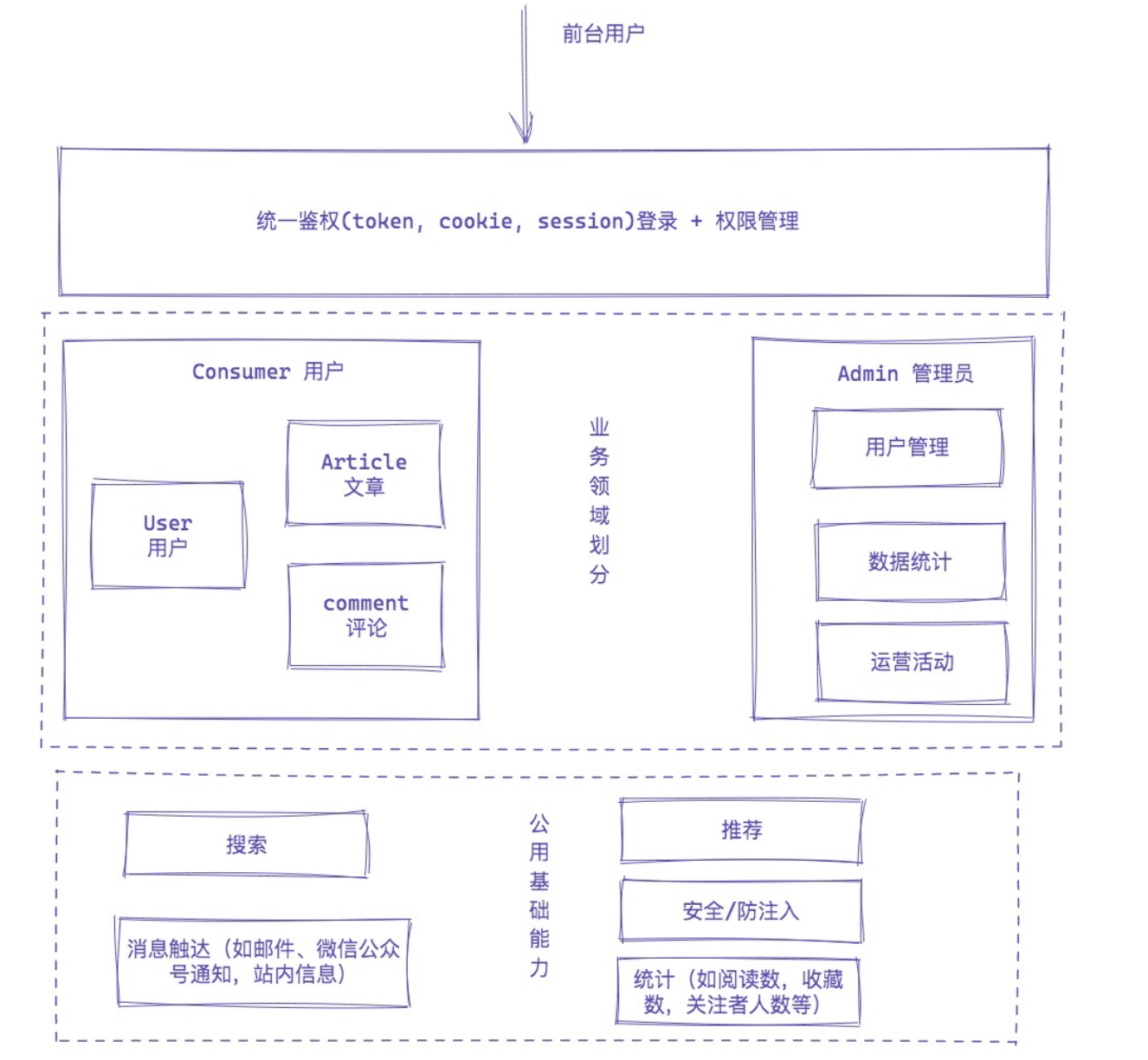\n\n2、库表设计\n\n\n\n3、产品方案\n\n\n\n4、UI设计\n\n\n\n5、接口文档\n\n\n\n6、进度排期\n\n\n\n7、bug&优化\n\n\n\n8、年度复盘\n\n\n\n## 技术派的后期打算\n\n项目上线后,最重要的两件事,一个是持续迭代,修复线上问题,并且把需求池中 p3 的任务开发掉;另外一个就是完成开发文档的编写,我们计划每周更新三篇。\n\n先是大厂篇,由我们技术派团队的楼仔负责。\n\n\n\n然后是基础篇,由二哥来负责。\n\n\n\n接着是进阶篇,由我们技术派团队的一灰来负责。\n\n\n\n后面还会推出扩展篇、前端篇、工程篇,把整个 Java 后端的技术栈全部搞定。\n\n\n\n## 技术派编程星球\n\n当然了,这些教程会优先开放给[技术派编程星球](https://t.zsxq.com/0buCVQ3qQ)的球友们,毕竟这群家伙都是氪金过的 VIP,一直在等这个项目的官宣,等的嗷嗷叫。\n\n\n\n如果你也想加入技术派的编程星球,现在送出 30 元的优惠券,原价 129 元,等于说优惠完**只需要 99 年就可以加入,每天不到 0.27 元**,超级划算!\n\n\n\n\n\n\n\n要知道,这还只是星球的一小部分服务,我们还会提供以下这些服务\n\n1. **技术派项目学习教程**,后续会采用连载的方式,让你从 0 到 1 也能搭建一套自己的网站\n2. 技术派项目答疑解惑,让你快速上手该项目,小白也能懂\n3. **向楼仔、二哥和大厂嘉宾 1 对 1 交流提问**,告别迷茫\n4. 个人成长路线、职业规划和建议,帮助你有计划学习\n5. 简历修改建议,让你的简历也能脱颖而出,收获更多面试机会\n6. 分享硬核技术学习资料,比如 **Spring 源码、高并发教程、JVM、架构选型**等\n7. 分享面试资料,都是一些高频面试题\n8. 分享工作中好用的开发小工具,助你提升开发效率\n9. 分享工作中的踩坑经历,让你快速获取工作经验,少走很多弯路\n10. 需求方案、技术架构设计提供参考建议,对标大厂\n11. 回答每天球友的问题\n12. 一起学习打卡,楼仔帮你分析学习进度\n\n\n**比如说星球分享的后端技术栈知识汇总**,全面系统的带你成为一名优秀的 Java 后端工程师。\n\n\n\n**像简历修改,绝不放过任何一个细节**,至今已经修改超过 100 份,所有的简历修改建议也都会第一时间同步到星球里。\n\n\n\n\n星球刚开始运营,所以设置的门槛非常低,为的就是给所有人提供一个可持续的学习环境,不过随着人数的增多,**肯定会涨价**,今天这批 30 元的优惠券是 2023 年最大的优惠力度了,现在入手就是最划算的,再犹豫就只能等着涨价了。\n\n原价 **129元**,优惠完只需**99元**就能上车,星球不仅能开阔你的视野,还能跟一群优秀的人交流学习,如果工作学习中遇到难题也有人给你出谋划策,这个价格绝对超值!\n\n\n\n想想,QQ音乐听歌连续包年需要 **88元**,腾讯视频连续包年需要 **178元**,腾讯体育包年 **233元**。我相信,知识星球回馈给你的,将是 10 倍甚至百倍的价值。\n\n最后,希望球友们,能紧跟我们的步伐!不要掉队。兔年,和我们技术派一起翻身、一起逆袭、一起晋升、一起拿高薪 offer!\n\n\n\n', '0', '2023-04-15 16:03:43', '2023-04-15 16:03:43'), ('9', '106', '1', '## 整体介绍\n### 背景\n> 这个项目诞生的背景和企业内生的需求不太一样,主要是某一天二哥说,“我们一起搞事吧”, 楼仔问,“搞什么”,然后这个项目的需求就来了\n\n言归正传,我们主要的目的是希望打造一个切实可用的项目,依托于这个项目,将java从业者所用到的技术栈真实的展现出来,对于经验不是那么足的小伙伴,可以在一个真实的系统上,理解到自己学习的知识点是如何落地的,同时也能真实的了解一个项目是从0到1实现的全过程\n### 系统模块介绍\n#### 系统架构\n基于社区系统的分层特点,将整个系统架构划分为展示层,应用层,服务层,如下图\n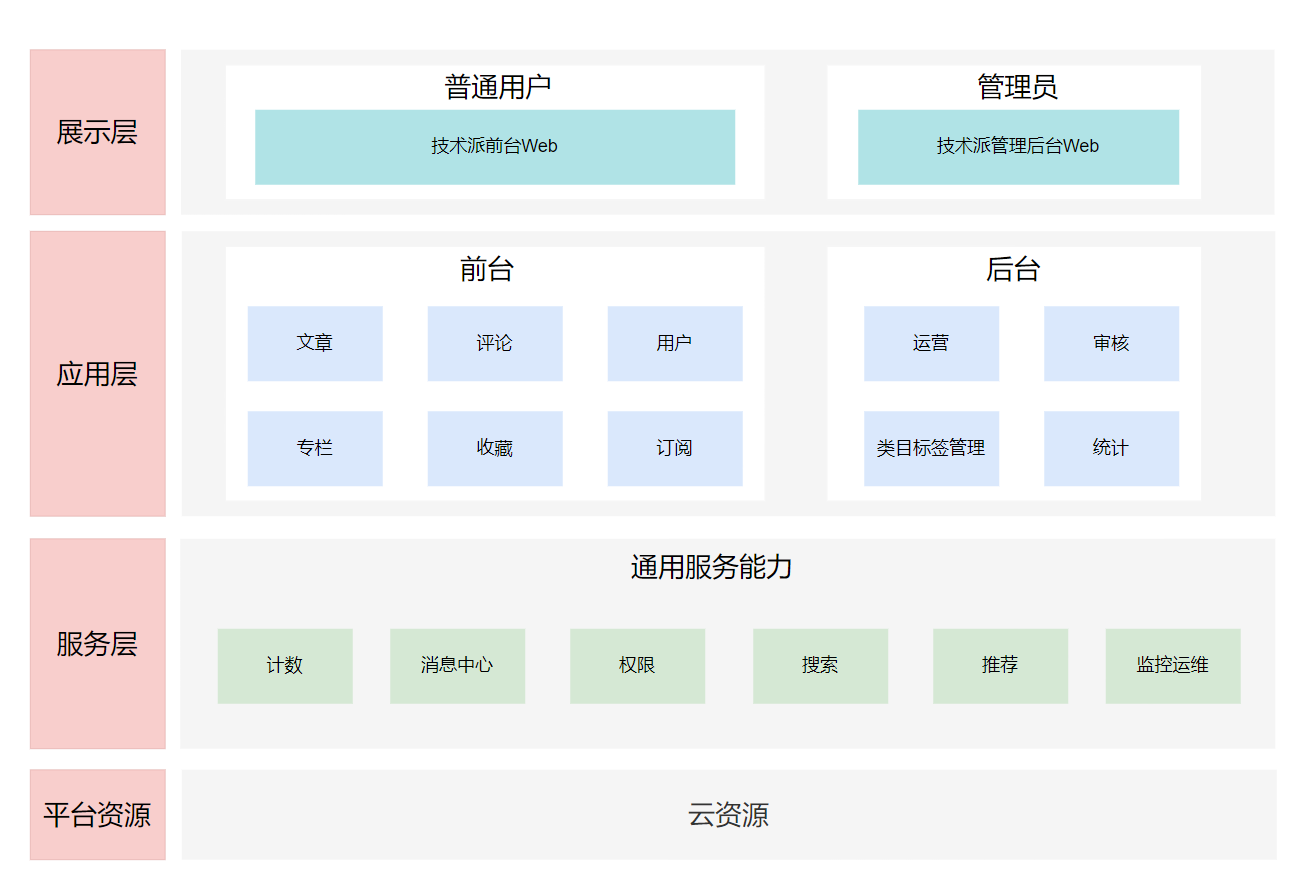\n\n#### 展示层\n其中展示层主要为用户直接接触的视图层,基于用户角色,分别提供为面向普通用户的前台与面向管理员的后台\n**前台web**\n\n- 采用Thymleaf模板引擎进行视图渲染\n- 对于不关心前端技术栈的小伙伴相对友好,学习成本低,只用会基本的html,css,js即可\n\n**管理后台**\n\n- 采用成熟的前后端分离技术方案\n- 前端基于react成熟框架搭建\n#### 应用层\n应用层,也可以称为业务层,强业务相关,其中每个划分出来的模块有较明显的业务边界,虽然在上图中区分了前台、后台\n但是需要注意的是,后台也是同样有文章、评论、用户等业务功能的,前台与后台可使用应用主要是权限粒度管理的差异性,对于技术派系统而言,我们的应用可分为:\n\n- 文章\n- 专栏\n- 评论\n- 用户\n- 收藏\n- 订阅\n- 运营\n- 审核\n- 类目标签\n- 统计\n#### 服务层\n我们将一些通用的、可抽离业务属性的功能模块,沉淀到服务层,作为一个一个的基础服务进行设计,比如计数服务、消息服务等,通常他们最大特点就是独立与业务之外,适用性更广,并不局限在特定的业务领域内,可以作为通用的技术方案存在\n在技术派的项目设计中,我们拟定以下基础服务\n\n- 用户权限管理 (auth)\n- 消息中心 (mq)\n- 计数 (redis)\n- 搜索服务 (es)\n- 推荐 (recommend)\n- 监控运维 (prometheus)\n#### 平台资源层\n这一层可以理解为更基础的下层支撑\n\n- 服务资源:数据库、redis、es、mq\n- 硬件资源:容器,ecs服务器\n### 术语介绍\n技术派整个系统中涉及到的术语并不多,也很容易理解,下面针对几个常用的进行说明\n\n- 用户:特指通过微信公众号扫码注册的用户,可以发布文章、阅读文章等\n- 管理员:可以登录后台的特殊用户\n- 文章:即博文\n- 专栏:由一系列相关的文章组成的一个合集\n- 订阅:专指关注用户\n\n### 技术架构\n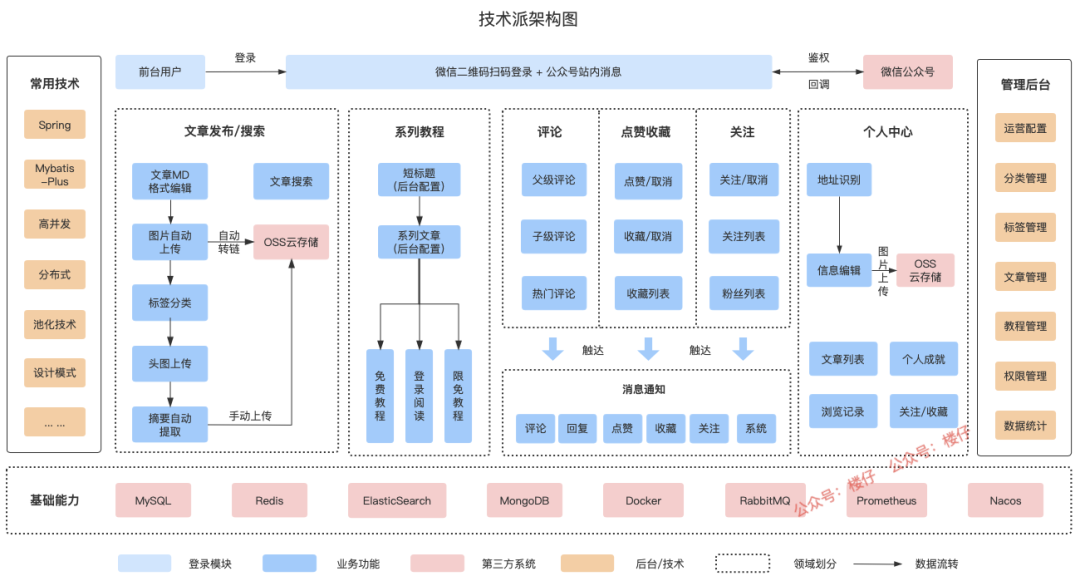\n## 系统模块设计\n针对前面技术派的业务架构拆分,技术派的实际项目划分,主要是五个模块,相反并没由将上面的每个应用、服务抽离为独立的模块,主要是为了避免过渡设计,粒度划分太细会增加整个项目的理解维护成本\n\n这里设置五个相对独立的模块,则主要是基于边界特别清晰这一思考点进行,后续做微服务演进时,下面每个模块可以作为独立的微服务存在\n\n### 用户模块\n在技术派中,整个用户模块从功能角度可以分为\n\n- 注册登录\n- 权限管理(是的,权限管理也放在这里了)\n- 业务逻辑\n\n#### 注册登录\n##### 方案设计\n注册登录除了常见的用户名+密码的登录方式之外,现在也有流行的手机号+验证,第三方授权登录;我们最终选择微信公众号登录方式(其最主要的目的,相信大家也知道...)\n对于个人公众号,很多权限没有;因此这个登录的具体实现,有两种实现策略\n\n- 点击登录,登录页显示二维码 + 输入框 -> 用户关注公众号,输入 \"login\" 获取登录验证码 -> 在登录界面输入验证码实现登录\n- 点击登录,登录页显示二维码 + 验证码 -> 用户关注公众号,将登录页面上的验证码输入到微信公众号 -> 自动登录\n\n其中第一种策略,类似于手机号/验证码的登录方式,主要是根据系统返回的验证码来主动登录\n\n**优点:**\n\n- 代码实现简单,逻辑清晰\n\n**缺点:**\n\n- 操作流程复杂,用户需要输入两次\n\n对于第二种策略,如果是企业公众号,是可以省略输入验证码这一步骤的,借助动态二维码来直接实现扫码登录;对于我们这种个人公众号,则需要多来一步,通过输入验证码来将微信公众号的用户与需要登录的用户绑定起来\n登录工作流程如下:\n\n\n\n##### 库表设计\n基于公众号的登录方式,看一下用户登录表的设计\n```sql\nCREATE TABLE `user` (\n `id` int(10) unsigned NOT NULL AUTO_INCREMENT COMMENT \'主键ID\',\n `third_account_id` varchar(128) NOT NULL DEFAULT \'\' COMMENT \'第三方用户ID\',\n `user_name` varchar(64) NOT NULL DEFAULT \'\' COMMENT \'用户名\',\n `password` varchar(128) NOT NULL DEFAULT \'\' COMMENT \'密码\',\n `login_type` tinyint(4) NOT NULL DEFAULT \'0\' COMMENT \'登录方式: 0-微信登录,1-账号密码登录\',\n `deleted` tinyint(4) NOT NULL DEFAULT \'0\' COMMENT \'是否删除\',\n `create_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT \'创建时间\',\n `update_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT \'最后更新时间\',\n PRIMARY KEY (`id`),\n KEY `key_third_account_id` (`third_account_id`),\n KEY `key_user_name` (`user_name`),\n) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4 COMMENT=\'用户登录表\';\n```\n\n注意上面的表结构设计,我们冗余了 `user_name`, `password` 用户名密码的登录方式,主要是给管理员登录后台使用\n\n用户首次登录之后,会在user表中插入一条数据,主要关注 `third_account_id` 这个字段,它记录的是微信开放平台返回的唯一用户id\n#### 权限管理\n权限管理会分为两块:用户身份识别 + 鉴权\n##### 方案设计\n**用户身份识别:**\n现在用户的身份识别有非常多的方案,我们现在采用的是最基础、历史最悠久的方案,cookie + session 方式(后续会迭代为分布式session + jwt)\n整体流程:\n\n- 用户登录成功,服务器生成sessionId -> userId 映射关系\n- 服务器返回sessionId,写到客户端的浏览器cookie\n- 后续用户请求,携带cookie\n- 服务器从cookie中获取sessionId,然后找到uesrId\n\n\n\n服务内部身份传递:\n另外一个需要考虑的点则是用户的身份如何在整个系统内传递? 对于一期我们采用的单体架构而言,借助ThreadLocal来实现\n\n- 自定义Filter,实现用户身份识别(即上面的流程,从cookie中拿到SessionId,转userId)\n- 定义全局上下文ReqInfoContext:将用户信息,写入全局共享的ThreadLocal中\n- 在系统内,需要获取当前用户的地方,直接通过访问 ReqInfoContext上下文获取用户信息\n- 请求返回前,销毁上下文中当前登录用户信息\n\n**鉴权**\n根据用户角色与接口权限要求进行判定,我们设计三种权限点类型\n\n- ADMIN:只有管理员才能访问的接口\n- LOGIN:只有登录了才能访问的接口\n- ALL:默认,没有权限限制\n\n我们在需要权限判定的接口上,添加上对应的权限要求,然后借助AOP来实现权限判断\n\n- 当接口上有权限点要求时(除ALL之外)\n- 首先获取用户信息,如果没有登录,则直接报403\n- 对于ADMIN限制的接口,要求查看用户角色,必须为admin\n\n##### 库表设计\n我们将用户角色信息写入用户基本信息表中,没有单独抽出一个角色表,然后进行映射,主要是因为这个系统逻辑相对清晰,没有太复杂的角色关系,因此采用了轻量级的设计方案\n\n```sql\n-- pai_coding.user_info definition\n\nCREATE TABLE `user_info` (\n `id` int(10) unsigned NOT NULL AUTO_INCREMENT COMMENT \'主键ID\',\n `user_id` int(10) unsigned NOT NULL DEFAULT \'0\' COMMENT \'用户ID\',\n `user_name` varchar(50) NOT NULL DEFAULT \'\' COMMENT \'用户名\',\n `photo` varchar(128) NOT NULL DEFAULT \'\' COMMENT \'用户图像\',\n `position` varchar(50) NOT NULL DEFAULT \'\' COMMENT \'职位\',\n `company` varchar(50) NOT NULL DEFAULT \'\' COMMENT \'公司\',\n `profile` varchar(225) NOT NULL DEFAULT \'\' COMMENT \'个人简介\',\n `user_role` int(4) NOT NULL DEFAULT \'0\' COMMENT \'0 普通用户 1 超管\',\n `extend` varchar(1024) NOT NULL DEFAULT \'\' COMMENT \'扩展字段\',\n `ip` json NOT NULL COMMENT \'用户的ip信息\',\n `deleted` tinyint(4) NOT NULL DEFAULT \'0\' COMMENT \'是否删除\',\n `create_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT \'创建时间\',\n `update_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT \'最后更新时间\',\n PRIMARY KEY (`id`),\n KEY `key_user_id` (`user_id`)\n) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4 COMMENT=\'用户个人信息表\';\n```\n\n#### 业务逻辑\n在业务模块,主要说两块,一个是用户的轨迹,一个是订阅关注\n\n##### 订阅关注\n订阅关注这块业务主要是用户可以相互关注,核心点就在于维护用户与用户之间的订阅关系\n\n业务逻辑上没有太复杂的东西,核心就是需要一张表来记录关注与被关注情况\n```sql\n-- pai_coding.user_relation definition\n\nCREATE TABLE `user_relation` (\n `id` int(10) unsigned NOT NULL AUTO_INCREMENT COMMENT \'主键ID\',\n `user_id` int(10) unsigned NOT NULL DEFAULT \'0\' COMMENT \'作者用户ID\',\n `follow_user_id` int(10) unsigned NOT NULL COMMENT \'关注userId的用户id,即粉丝userId\',\n `follow_state` tinyint(2) unsigned NOT NULL DEFAULT \'0\' COMMENT \'阅读状态: 0-未关注,1-已关注,2-取消关注\',\n `create_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT \'创建时间\',\n `update_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT \'最后更新时间\',\n PRIMARY KEY (`id`),\n UNIQUE KEY `uk_user_follow` (`user_id`,`follow_user_id`),\n KEY `key_follow_user_id` (`follow_user_id`)\n) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4 COMMENT=\'用户关系表\';\n```\n\n##### 用户轨迹\n在技术派的整体设计中,我们希望记录用户的阅读历史、关注列表、收藏列表、评价的文章列表,对于这种用户行为轨迹的诉求,我们采用设计一张大宽表的策略,其主要目的在于\n\n1. 记录用户的关键动作\n2. 便于文章的相关计数\n\n接下来看一下表结构设计\n```sql\n-- pai_coding.user_foot definition\n\nCREATE TABLE `user_foot` (\n `id` int(10) unsigned NOT NULL AUTO_INCREMENT COMMENT \'主键ID\',\n `user_id` int(10) unsigned NOT NULL DEFAULT \'0\' COMMENT \'用户ID\',\n `document_id` int(10) unsigned NOT NULL DEFAULT \'0\' COMMENT \'文档ID(文章/评论)\',\n `document_type` tinyint(4) NOT NULL DEFAULT \'1\' COMMENT \'文档类型:1-文章,2-评论\',\n `document_user_id` int(10) unsigned NOT NULL DEFAULT \'0\' COMMENT \'发布该文档的用户ID\',\n `collection_stat` tinyint(3) unsigned NOT NULL DEFAULT \'0\' COMMENT \'收藏状态: 0-未收藏,1-已收藏,2-取消收藏\',\n `read_stat` tinyint(3) unsigned NOT NULL DEFAULT \'0\' COMMENT \'阅读状态: 0-未读,1-已读\',\n `comment_stat` tinyint(3) unsigned NOT NULL DEFAULT \'0\' COMMENT \'评论状态: 0-未评论,1-已评论,2-删除评论\',\n `praise_stat` tinyint(3) unsigned NOT NULL DEFAULT \'0\' COMMENT \'点赞状态: 0-未点赞,1-已点赞,2-取消点赞\',\n `create_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT \'创建时间\',\n `update_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT \'最后更新时间\',\n PRIMARY KEY (`id`),\n UNIQUE KEY `idx_user_doucument` (`user_id`,`document_id`,`document_type`),\n KEY `idx_doucument_id` (`document_id`)\n) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4 COMMENT=\'用户足迹表\';\n```\n\n我们将用户 + 文章设计唯一键,用来记录用户对自己阅读过的文章的行为,因此可以直接通过这个表获取用户的历史轨迹\n同时也可以从文章的角度出发,查看被哪些用户点赞、收藏过\n\n#### 小结\n用户模块的核心支撑在上面几块,请重点关注上面的示意图与表结构;当然用户的功能点不止于上面几个,比如基础的个人主页、用户信息等也属于用户模块的业务范畴\n\n### 文章模块\n我们将文章和专栏都放在一起,同样也将类目管理、标签管理等也都放在这个模块中,实际上若文章模块过于庞大,也是可以按照最开始的划分进行继续拆分的;这里放在一起的主要原因在于他们都是围绕基本的文章这一业务属性来的,可以聚合在一起\n\n#### 文章\n文章的核心就在于发布、查看\n\n基本的发布流程:\n\n1. 用户登录,进入发布页面\n2. 输入标题、文章\n3. 选择分类、标签,封面、简介\n4. 提交文章,进入待审核状态,仅用户可看详情\n5. 管理员审核通过,所有人可看详情\n\n\n\n#### 文章库表设计\n考虑到文章的内容通常较大,在很多的业务场景中,我们实际上是不需要文章内容的,如首页、推荐列表等都只需要文章的标题等信息;此外我们也希望对文章做一个版本管理(比如上线之后,再修改则新生成一个版本)\n因此我们对文章设计了两张表\n```sql\n-- pai_coding.article definition\n\nCREATE TABLE `article` (\n `id` int(10) unsigned NOT NULL AUTO_INCREMENT COMMENT \'主键ID\',\n `user_id` int(10) unsigned NOT NULL DEFAULT \'0\' COMMENT \'用户ID\',\n `article_type` tinyint(4) NOT NULL DEFAULT \'1\' COMMENT \'文章类型:1-博文,2-问答\',\n `title` varchar(120) NOT NULL DEFAULT \'\' COMMENT \'文章标题\',\n `short_title` varchar(120) NOT NULL DEFAULT \'\' COMMENT \'短标题\',\n `picture` varchar(128) NOT NULL DEFAULT \'\' COMMENT \'文章头图\',\n `summary` varchar(300) NOT NULL DEFAULT \'\' COMMENT \'文章摘要\',\n `category_id` int(10) unsigned NOT NULL DEFAULT \'0\' COMMENT \'类目ID\',\n `source` tinyint(4) NOT NULL DEFAULT \'1\' COMMENT \'来源:1-转载,2-原创,3-翻译\',\n `source_url` varchar(128) NOT NULL DEFAULT \'1\' COMMENT \'原文链接\',\n `offical_stat` int(10) unsigned NOT NULL DEFAULT \'0\' COMMENT \'官方状态:0-非官方,1-官方\',\n `topping_stat` int(10) unsigned NOT NULL DEFAULT \'0\' COMMENT \'置顶状态:0-不置顶,1-置顶\',\n `cream_stat` int(10) unsigned NOT NULL DEFAULT \'0\' COMMENT \'加精状态:0-不加精,1-加精\',\n `status` tinyint(4) NOT NULL DEFAULT \'0\' COMMENT \'状态:0-未发布,1-已发布\',\n `deleted` tinyint(4) NOT NULL DEFAULT \'0\' COMMENT \'是否删除\',\n `create_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT \'创建时间\',\n `update_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT \'最后更新时间\',\n PRIMARY KEY (`id`),\n KEY `idx_category_id` (`category_id`),\n KEY `idx_title` (`title`),\n KEY `idx_short_title` (`short_title`)\n) ENGINE=InnoDB AUTO_INCREMENT=173 DEFAULT CHARSET=utf8mb4 COMMENT=\'文章表\';\n\n\n-- pai_coding.article_detail definition\n\nCREATE TABLE `article_detail` (\n `id` int(10) unsigned NOT NULL AUTO_INCREMENT COMMENT \'主键ID\',\n `article_id` int(10) unsigned NOT NULL DEFAULT \'0\' COMMENT \'文章ID\',\n `version` int(10) unsigned NOT NULL DEFAULT \'0\' COMMENT \'版本号\',\n `content` longtext COMMENT \'文章内容\',\n `deleted` tinyint(4) NOT NULL DEFAULT \'0\' COMMENT \'是否删除\',\n `create_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT \'创建时间\',\n `update_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT \'最后更新时间\',\n PRIMARY KEY (`id`),\n UNIQUE KEY `idx_article_version` (`article_id`,`version`)\n) ENGINE=InnoDB AUTO_INCREMENT=141 DEFAULT CHARSET=utf8mb4 COMMENT=\'文章详情表\';\n```\n\n文章对应的分类,我们要求一个文章只能挂在一个分类下\n```sql\n-- pai_coding.category definition\n\nCREATE TABLE `category` (\n `id` int(10) unsigned NOT NULL AUTO_INCREMENT COMMENT \'主键ID\',\n `category_name` varchar(64) NOT NULL DEFAULT \'\' COMMENT \'类目名称\',\n `status` tinyint(4) NOT NULL DEFAULT \'0\' COMMENT \'状态:0-未发布,1-已发布\',\n `rank` tinyint(4) NOT NULL DEFAULT \'0\' COMMENT \'排序\',\n `deleted` tinyint(4) NOT NULL DEFAULT \'0\' COMMENT \'是否删除\',\n `create_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT \'创建时间\',\n `update_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT \'最后更新时间\',\n PRIMARY KEY (`id`)\n) ENGINE=InnoDB AUTO_INCREMENT=10 DEFAULT CHARSET=utf8mb4 COMMENT=\'类目管理表\';\n```\n\n文章对应的标签属性,一个文章可以有多个标签\n```sql\n-- pai_coding.tag definition\n\nCREATE TABLE `tag` (\n `id` int(10) unsigned NOT NULL AUTO_INCREMENT COMMENT \'主键ID\',\n `tag_name` varchar(120) NOT NULL COMMENT \'标签名称\',\n `tag_type` tinyint(4) NOT NULL DEFAULT \'1\' COMMENT \'标签类型:1-系统标签,2-自定义标签\',\n `category_id` int(10) unsigned NOT NULL DEFAULT \'0\' COMMENT \'类目ID\',\n `status` tinyint(4) NOT NULL DEFAULT \'0\' COMMENT \'状态:0-未发布,1-已发布\',\n `deleted` tinyint(4) NOT NULL DEFAULT \'0\' COMMENT \'是否删除\',\n `create_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT \'创建时间\',\n `update_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT \'最后更新时间\',\n PRIMARY KEY (`id`),\n KEY `idx_category_id` (`category_id`)\n) ENGINE=InnoDB AUTO_INCREMENT=147 DEFAULT CHARSET=utf8mb4 COMMENT=\'标签管理表\';\n\n-- pai_coding.article_tag definition\n\nCREATE TABLE `article_tag` (\n `id` int(10) unsigned NOT NULL AUTO_INCREMENT COMMENT \'主键ID\',\n `article_id` int(10) unsigned NOT NULL DEFAULT \'0\' COMMENT \'文章ID\',\n `tag_id` int(11) NOT NULL DEFAULT \'0\' COMMENT \'标签\',\n `deleted` tinyint(4) NOT NULL DEFAULT \'0\' COMMENT \'是否删除\',\n `create_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT \'创建时间\',\n `update_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT \'最后更新时间\',\n PRIMARY KEY (`id`),\n KEY `idx_tag_id` (`tag_id`)\n) ENGINE=InnoDB AUTO_INCREMENT=145 DEFAULT CHARSET=utf8mb4 COMMENT=\'文章标签映射\';\n```\n\n#### 专栏\n专栏主要是一系列文章的合集,基于此最简单的设计方案就是加一个专栏表,然后再加一个专栏与文章的映射表\n\n但是需要注意的是专栏中文章的顺序,支持调整\n#### 专栏库表设计\n专栏表\n```sql\n-- pai_coding.column_info definition\n\nCREATE TABLE `column_info` (\n `id` int(10) unsigned NOT NULL AUTO_INCREMENT COMMENT \'专栏ID\',\n `column_name` varchar(64) NOT NULL DEFAULT \'\' COMMENT \'专栏名\',\n `user_id` int(10) unsigned NOT NULL DEFAULT \'0\' COMMENT \'作者id\',\n `introduction` varchar(256) NOT NULL DEFAULT \'\' COMMENT \'专栏简述\',\n `cover` varchar(128) NOT NULL DEFAULT \'\' COMMENT \'专栏封面\',\n `state` tinyint(3) unsigned NOT NULL DEFAULT \'0\' COMMENT \'状态: 0-审核中,1-连载,2-完结\',\n `publish_time` timestamp NOT NULL DEFAULT \'1970-01-02 00:00:00\' COMMENT \'上线时间\',\n `create_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT \'创建时间\',\n `update_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT \'最后更新时间\',\n `section` int(10) unsigned NOT NULL DEFAULT \'0\' COMMENT \'排序\',\n `nums` int(10) unsigned NOT NULL DEFAULT \'0\' COMMENT \'专栏预计的更新的文章数\',\n `type` int(10) unsigned NOT NULL DEFAULT \'0\' COMMENT \'专栏类型 0-免费 1-登录阅读 2-限时免费\',\n `free_start_time` timestamp NOT NULL DEFAULT \'1970-01-02 00:00:00\' COMMENT \'限时免费开始时间\',\n `free_end_time` timestamp NOT NULL DEFAULT \'1970-01-02 00:00:00\' COMMENT \'限时免费结束时间\',\n PRIMARY KEY (`id`),\n KEY `idx_user_id` (`user_id`)\n) ENGINE=InnoDB AUTO_INCREMENT=5 DEFAULT CHARSET=utf8mb4 COMMENT=\'专栏\';\n```\n\n专栏文章表\n```sql\n-- pai_coding.column_article definition\n\nCREATE TABLE `column_article` (\n `id` int(10) unsigned NOT NULL AUTO_INCREMENT COMMENT \'主键ID\',\n `column_id` int(10) unsigned NOT NULL DEFAULT \'0\' COMMENT \'专栏ID\',\n `article_id` int(10) unsigned NOT NULL DEFAULT \'0\' COMMENT \'文章ID\',\n `section` int(10) unsigned NOT NULL DEFAULT \'0\' COMMENT \'章节顺序,越小越靠前\',\n `create_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT \'创建时间\',\n `update_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT \'最后更新时间\',\n PRIMARY KEY (`id`),\n KEY `idx_column_id` (`column_id`)\n) ENGINE=InnoDB AUTO_INCREMENT=25 DEFAULT CHARSET=utf8mb4 COMMENT=\'专栏文章列表\';\n```\n\n#### 点赞收藏\n再技术派中,对于文章提供了点赞、收藏、评论三种交互,这里重点看一下点赞与收藏;\n\n点赞与收藏,实际上就是用户与文章之间的操作行为,再前面的`user_foot`表就已经介绍具体的表结构, 文章的统计计数就是根据这个表数据来的,当前用户与文章的点赞、收藏关系,同样是根据这个表来的\n\n唯一需要注意的点,就是这个数据的插入、更新策略:\n\n- 首次阅读文章时:插入一条数据\n- 点赞:若记录存在,则更新状态,之前时点赞的,设置为取消点赞;若记录不存在,则插入一条点赞的记录\n- 收藏:同上\n\n### 评论模块\n评论可以是针对文章进行,也可以是针对另外一个评论进行回复,我们将回复也当作是一个评论\n\n\n\n#### 评论\n我们将评论和回复都当成普通的评论,只是主体不同而已,因此一篇文章的评论列表,我们需要重点关注的就是,如何构建评论与其回复之间的层级关系\n\n对于这种评论与回复的层级关系,可以是建辅助表来处理;也可以是表内的父子关系来处理,这里我们采用第二种策略\n\n- 每个评论记录它的上一级评论id(若只是针对文章的评论,那么上一级评论id = 0)\n- 我们通过父子关系,在业务层进行逻辑还原\n\n#### 库表设计\n针对上面的策略,核心的评论库表设计如下\n```sql\n-- pai_coding.comment definition\n\nCREATE TABLE `comment` (\n `id` int(10) unsigned NOT NULL AUTO_INCREMENT COMMENT \'主键ID\',\n `article_id` int(10) unsigned NOT NULL DEFAULT \'0\' COMMENT \'文章ID\',\n `user_id` int(10) unsigned NOT NULL DEFAULT \'0\' COMMENT \'用户ID\',\n `content` varchar(300) NOT NULL DEFAULT \'\' COMMENT \'评论内容\',\n `top_comment_id` int(11) NOT NULL DEFAULT \'0\' COMMENT \'顶级评论ID\',\n `parent_comment_id` int(10) unsigned NOT NULL DEFAULT \'0\' COMMENT \'父评论ID\',\n `deleted` tinyint(4) NOT NULL DEFAULT \'0\' COMMENT \'是否删除\',\n `create_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT \'创建时间\',\n `update_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT \'最后更新时间\',\n PRIMARY KEY (`id`),\n KEY `idx_article_id` (`article_id`),\n KEY `idx_user_id` (`user_id`)\n) ENGINE=InnoDB AUTO_INCREMENT=75 DEFAULT CHARSET=utf8mb4 COMMENT=\'评论表\';\n```\n\n**注意:**\n\n- 为什么再表中需要冗余一个顶级评论id ?\n- 主要的目的是简化业务层评论关系还原的复杂性\n\n通过上面的表结构,关系还原的策略:\n\n- 先查出文章的顶级评论(parent_comment_id = 0)\n- 接下来就是针对每个顶级评论,查询它下面的所有回复 ( top_comment_id = comment_id) \n - 构建顶级评论下的回复父子关系(根据parent_comment_id来构建依赖关系)\n\n拓展:如果不存在top_comment_id,那么要实现上面这个还原,要怎么做呢?\n\n#### 评论点赞\n技术派中同样支持对评论进行点赞,取消点赞;对于点赞的整体业务逻辑操作,实际上与文章的点赞一致,因此我们直接复用了文章的点赞逻辑,借助 `user_foot` 来实现的\n\n**说明**\n\n- 上面这种实现并不是一种优雅的选择,从`user_foot`的设计也能看出,它实际上与评论点赞这个业务是有些隔离的\n- 采用上面这个方案的主要原因在于,点赞这种属于通用的服务,使用mysql来维系点赞与否以及计数统计,再数据量大了之后,基本上玩不转;后续会介绍如何设计一个通用的点赞服务,以此来替换技术派中当前的点赞实现\n- 这种设计思路也经常体现在一个全新项目的设计中,最开始的设计并不会想着一蹴而就,整一个非常完美的系统出来,我们需要的是在最开始搭好基座、方便后续扩展;另外一点就是,如何在当前系统的基础上,最小成本的支持业务需求(相信各位小伙伴在日常工作中,这些事情不会陌生)\n\n### 消息模块\n消息模块主要是记录一些定义的事件,用于同步给用户;我们整体采用Event/Listener的异步方案来进行\n在单机应用中,借助`Spring Event/Listener`机制来实现;在集群中,将借助MQ消息中间件来实现\n\n#### 消息通知\n我们主要定义以下五种消息类型\n\n- 评论\n- 点赞\n- 收藏\n- 关注\n- 系统消息\n\n\n\n当发生方面的行为之后,再相应的地方进行主动埋点,手动发送一个消息事件,然后异步消费事件,生成消息通知\n\n需要注意一点:\n\n- 当用户点赞了一个文章,产生一个点赞消息之后;又取消了点赞,这个消息会怎样?\n- 撤销还是依然保留?(技术派中选择的方案是撤销)\n\n#### 库表设计\n```sql\n-- pai_coding.notify_msg definition\n\nCREATE TABLE `notify_msg` (\n `id` int(10) unsigned NOT NULL AUTO_INCREMENT COMMENT \'主键ID\',\n `related_id` int(10) unsigned NOT NULL DEFAULT \'0\' COMMENT \'关联的主键\',\n `notify_user_id` int(10) unsigned NOT NULL DEFAULT \'0\' COMMENT \'通知的用户id\',\n `operate_user_id` int(10) unsigned NOT NULL DEFAULT \'0\' COMMENT \'触发这个通知的用户id\',\n `msg` varchar(1024) NOT NULL DEFAULT \'\' COMMENT \'消息内容\',\n `type` tinyint(3) unsigned NOT NULL DEFAULT \'0\' COMMENT \'类型: 0-默认,1-评论,2-回复 3-点赞 4-收藏 5-关注 6-系统\',\n `state` tinyint(3) unsigned NOT NULL DEFAULT \'0\' COMMENT \'阅读状态: 0-未读,1-已读\',\n `create_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT \'创建时间\',\n `update_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT \'最后更新时间\',\n PRIMARY KEY (`id`),\n KEY `key_notify_user_id_type_state` (`notify_user_id`,`type`,`state`)\n) ENGINE=InnoDB AUTO_INCREMENT=1086 DEFAULT CHARSET=utf8mb4 COMMENT=\'消息通知列表\';\n```\n\n### 通用模块\n关于技术派中的通用模块大致有下面几种,相关的技术方案也比较简单,将配合库表进行简单说明\n\n#### 统计计数\n针对文章的阅读计数,没访问一次计数+1, 因此前面的`user_foot`不能使用(因为未登录的用户是不会生成user_foot记录的)\n\n我们当前设计的一个简单的计数表如下\n```sql\n-- pai_coding.read_count definition\n\nCREATE TABLE `read_count` (\n `id` int(10) unsigned NOT NULL AUTO_INCREMENT COMMENT \'主键ID\',\n `document_id` int(10) unsigned NOT NULL DEFAULT \'0\' COMMENT \'文档ID(文章/评论)\',\n `document_type` tinyint(4) NOT NULL DEFAULT \'1\' COMMENT \'文档类型:1-文章,2-评论\',\n `cnt` int(10) unsigned NOT NULL DEFAULT \'0\' COMMENT \'访问计数\',\n `create_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT \'创建时间\',\n `update_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT \'最后更新时间\',\n PRIMARY KEY (`id`),\n UNIQUE KEY `idx_document_id_type` (`document_id`,`document_type`)\n) ENGINE=InnoDB AUTO_INCREMENT=75 DEFAULT CHARSET=utf8mb4 COMMENT=\'计数表\';\n```\n\n注意,上面这个计数表中的cnt的更新,使用 `cnt = cnt + 1` 而不是 `cnt = xxx`的方案\n\n#### pv/uv\n每天的请求pv/uv计数统计,直接再filter层中记录\n\n```sql\n-- pai_coding.request_count definition\n\nCREATE TABLE `request_count` (\n `id` int(10) unsigned NOT NULL AUTO_INCREMENT COMMENT \'主键ID\',\n `host` varchar(32) NOT NULL DEFAULT \'\' COMMENT \'机器IP\',\n `cnt` int(10) unsigned NOT NULL DEFAULT \'0\' COMMENT \'访问计数\',\n `date` date NOT NULL COMMENT \'当前日期\',\n `create_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT \'创建时间\',\n `update_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT \'最后更新时间\',\n PRIMARY KEY (`id`),\n UNIQUE KEY `uk_unique_id_date` (`date`,`host`)\n) ENGINE=InnoDB AUTO_INCREMENT=8708 DEFAULT CHARSET=utf8mb4 COMMENT=\'请求计数表\';\n```\n\n#### 全局字典\n统一配置、全局字典相关的,主要是减少代码中的硬编码\n\n```sql\n-- pai_coding.dict_common definition\n\nCREATE TABLE `dict_common` (\n `id` int(10) unsigned NOT NULL AUTO_INCREMENT COMMENT \'主键ID\',\n `type_code` varchar(100) NOT NULL DEFAULT \'\' COMMENT \'字典类型,sex, status 等\',\n `dict_code` varchar(100) NOT NULL DEFAULT \'\' COMMENT \'字典类型的值编码\',\n `dict_desc` varchar(200) NOT NULL DEFAULT \'\' COMMENT \'字典类型的值描述\',\n `sort_no` int(8) unsigned NOT NULL DEFAULT \'0\' COMMENT \'排序编号\',\n `remark` varchar(500) DEFAULT \'\' COMMENT \'备注\',\n `create_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT \'创建时间\',\n `update_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT \'最后更新时间\',\n PRIMARY KEY (`id`),\n UNIQUE KEY `uk_type_code_dict_code` (`type_code`,`dict_code`)\n) ENGINE=InnoDB AUTO_INCREMENT=28 DEFAULT CHARSET=utf8mb4 COMMENT=\'通用数据字典\';\n```\n\n#### 图片上传\n文章的图片上传,我们支持服务器本地存储和oss存储,其中dev开发环境,默认是本地存储,即图片传到本地的一个目录下;prod生产环境,会将图片上传到阿里云的oss(其他厂商的oss也没有什么本质区别,都是一个post请求,将文件上传而已)\n\n注意:\n\n- 再具体的实现中,需要自动检测文章中的图片,进行转存,避免直接引入外部的资源,导致失效问题\n- 下载外网资源,是否会有安全问题? \n - 采用资源类型限制、校验\n - 生产环境中不存储资源到本地服务器/或者限制本地存储的文件名\n- 下载外网资源,转存是否会导致整个文章发布过程很慢? \n - 并发转存策略\n\n#### 搜索推荐\n技术派当前的搜索推荐主要是基于数据库来实现,后续再介绍es相关教程时,会同步引入ES进行替换当前的数据库方案\n\n## 迭代排期\n再详细设计这一阶段,一般来说会预估一下整体搞完需要多少人天,鉴于实际情况分几个迭代版本进行,每个版本的主要功能点有哪些;这一块就通过下面几张图简单给大家介绍下,详情推荐查看项目管理流程的内容\n\n关于技术派当前覆盖的功能点如:\n\n\n开发进度与后期版本迭代计划:\n\n\n## 技术派编程星球\n\n当然了,这些教程会优先开放给[技术派编程星球](https://t.zsxq.com/0buCVQ3qQ)的球友们,毕竟这群家伙都是氪金过的 VIP,一直在等这个项目的官宣,等的嗷嗷叫。\n\n\n\n如果你也想加入技术派的编程星球,现在送出 30 元的优惠券,原价 129 元,等于说优惠完**只需要 99 年就可以加入,每天不到 0.27 元**,超级划算!\n\n\n\n\n\n\n\n要知道,这还只是星球的一小部分服务,我们还会提供以下这些服务\n\n1. **技术派项目学习教程**,后续会采用连载的方式,让你从 0 到 1 也能搭建一套自己的网站\n2. 技术派项目答疑解惑,让你快速上手该项目,小白也能懂\n3. **向楼仔、二哥和大厂嘉宾 1 对 1 交流提问**,告别迷茫\n4. 个人成长路线、职业规划和建议,帮助你有计划学习\n5. 简历修改建议,让你的简历也能脱颖而出,收获更多面试机会\n6. 分享硬核技术学习资料,比如 **Spring 源码、高并发教程、JVM、架构选型**等\n7. 分享面试资料,都是一些高频面试题\n8. 分享工作中好用的开发小工具,助你提升开发效率\n9. 分享工作中的踩坑经历,让你快速获取工作经验,少走很多弯路\n10. 需求方案、技术架构设计提供参考建议,对标大厂\n11. 回答每天球友的问题\n12. 一起学习打卡,楼仔帮你分析学习进度\n\n\n**比如说星球分享的后端技术栈知识汇总**,全面系统的带你成为一名优秀的 Java 后端工程师。\n\n\n\n**像简历修改,绝不放过任何一个细节**,至今已经修改超过 100 份,所有的简历修改建议也都会第一时间同步到星球里。\n\n\n\n\n星球刚开始运营,所以设置的门槛非常低,为的就是给所有人提供一个可持续的学习环境,不过随着人数的增多,**肯定会涨价**,今天这批 30 元的优惠券是 2023 年最大的优惠力度了,现在入手就是最划算的,再犹豫就只能等着涨价了。\n\n原价 **129元**,优惠完只需**99元**就能上车,星球不仅能开阔你的视野,还能跟一群优秀的人交流学习,如果工作学习中遇到难题也有人给你出谋划策,这个价格绝对超值!\n\n\n\n想想,QQ音乐听歌连续包年需要 **88元**,腾讯视频连续包年需要 **178元**,腾讯体育包年 **233元**。我相信,知识星球回馈给你的,将是 10 倍甚至百倍的价值。\n\n最后,希望球友们,能紧跟我们的步伐!不要掉队。兔年,和我们技术派一起翻身、一起逆袭、一起晋升、一起拿高薪 offer!\n\n', '0', '2023-04-15 20:00:49', '2023-04-15 20:00:49'), ('10', '107', '1', '大家好呀,我是楼仔。\n\n上周推出了我们的开源项目「技术派」,大家好评如潮,很多同学都想学习这个项目,为了更好带大家一起飞,我们今天正式推出技术派的知识星球。\n\n什么是知识星球呢?你可以理解为高品质社群,方便大家跟着我们一起学习。\n\n\n\n## 01 星球介绍\n\n先来介绍下星球的三位联合创始人:\n\n* **楼仔**:8 年一线大厂后端经验(百度/小米/美团),技术派团队负责人,擅长高并发、架构、源码,有很强的项目/团队管理、职业规划能力。\n* **沉默王二**:GitHub 星标 6400k+开源知识库《 Java 程序员进阶之路》作者,CSDN 两届博客之星,掘金/知乎 Java 领域优质创作者。\n* **一灰**:担任过技术总监,大厂里搞架构、创业团队冲过浪的资深后端,主研 Java 技术栈,擅长架构设计、高并发、微服务等领域。\n\n再来介绍一下星球提供的服务内容:\n\n1. 技术派项目学习教程,后续会采用连载的方式,让你从 0 到 1 也能搭建一套自己的网站\n2. 技术派项目答疑解惑,让你快速上手该项目,小白也能懂\n3. 向楼仔、二哥和大厂嘉宾 1 对 1 交流提问,告别迷茫\n4. 个人成长路线、职业规划和建议,帮助你有计划学习\n5. 简历修改建议,让你的简历也能脱颖而出,收获更多面试机会\n6. 分享硬核技术学习资料,比如 Spring 源码、高并发教程、JVM、架构选型等\n7. 分享面试资料,都是一些高频面试题\n8. 分享工作中好用的开发小工具,助你提升开发效率\n9. 分享工作中的踩坑经历,让你快速获取工作经验,少走很多弯路\n10. 需求方案、技术架构设计提供参考建议,对标大厂\n11. 回答每天球友的问题\n12. 一起学习打卡,楼仔帮你分析学习进度\n\n## 02 技术派教程&答疑\n\n技术派教程是我们星球推出的主打服务项目。\n\n整个系列教程,会教你如何从 0 到 1 去完成一个对标大厂的项目,预计会出 100 篇文章,共划分为 6 个模块。\n\n\n\n大厂篇:\n\n\n\n进阶篇:\n\n\n\n由于教程目录太长,就不一一罗列,知识星球中有完整的教程目录。\n\n由于教程内容较多,不可能一次性写完,所以**会采用连载的方式,将教程发布到知识星球中**,该教程由 3 位合伙人一起撰写,我们会先选取里面最重要的 20 篇,在本月全部输出,也方面大家能快速入门学习。\n\n对于技术派项目中遇到的问题,**大家可以加入技术派的知识星球群,我们会给大家一一解答**,即使你是小白,也完全不用担心。\n\n## 03 成长答疑解惑\n\n其实楼仔在学习和成长的过程中,也曾焦虑过、迷茫过,如果你恰好和我一样,这里需要重点关注,就比如下面这位粉丝。\n\n\n\n如果你也一样,找楼仔不就得了。。。给大家看看楼仔这几年的学习计划(目前也都放到星球中):\n\n\n\n很多同学会问,楼哥,你怎么知道要学习这些内容呢?星球中其实已经给大家分享了后端技术栈需要掌握的全部知识,以及对应的学习资料,让你学习更有章法。\n\n对于还在迷茫和焦虑,不知道如何规划自己学习路径、不知如何进行时间管理、或者有其它疑惑的同学,都可以在星球中给楼仔提问,我都会耐心回复大家。\n\n\n\n对于制定好学习计划的同学,可以在星球中打卡,定期同步学习进度,楼仔也会对你的学习进度进行纠偏哈。\n\n\n\n## 04 有价值的资料\n\n星球中会提供大量有价值的学习资料,比如我之前面试大厂的一些笔记,都是我这几年实战的大厂面试题,真枪实弹!就靠这些面试题,拿到过百度、新浪、小米、美团、滴滴、陌陌的 Offer。\n\n\n\n星球中还会提供其它大量有价值的学习资料,之前有一部分已经免费发放给大家,但是有一部分属于星球专属。\n\n\n\n\n\n## 05 简历&大厂项目文档\n\n马上就到招聘季,我们也会帮大家一起修改简历,大家可以按照这个模板,将改好的简历发给我邮箱,我们会给你简历修改建议,让你能拿到更多面试机会。\n\n\n\n楼仔这边也有很多大厂的资料,需求文档、方案设计文档、架构设计文档等,如果你需要这些大厂资料,我都会给你提供,包括你自己进行方案&架构设计时,我们也会给你提供指导和建议。\n\n## 06 如何加入星球?\n\n技术派的知识星球原价是 **129** 元,特地给大家申请了一波 30 元的优惠券,最后的优惠价是 **99** 元。\n\n\n\n可能有同学会说,你的星球有点贵,这个还真不一样,**你需要看服务内容,并不是所有的星球,都有技术派这样的项目,都有我们这样专业的团队。**\n\n之前就有粉丝报培训班,花费近 2 万,为了就是能在简历上能多一些项目经验,最后效果也不太理想。\n\n我们这个星球,有项目、有技术、有个人计划、甚至连简历修改都包括,仅单简历修改这一项,外面至少也要 300 RMB,不信?大家可以自行百度。\n\n之前我也经常给同事说,在你这个年龄,但凡有人像我指导你一样,去指导我,我就可以少走 3 年弯路,人的黄金时间,又有多少个 3 年呢?\n\n**可以这么说,对于技术派提供的服务,只要有一项你需要,基本能赚回票价,绝对不会让粉丝们吃亏。**\n\n大家时间都很宝贵,早上车一天,就少浪费一天时间。\n\n\n\n一起加油,共勉!??', '0', '2023-04-15 20:07:49', '2023-04-15 20:07:49'), ('11', '105', '2', '大家好,我是二哥呀。\n\n给大家官宣一件大事,我们搞了近半年的实战项目——[**技术派**](https://paicoding.com/),终于上线了!瞅瞅这首页,清新、高级、上档次!\n\n\n\n瞅瞅我们的文章详情页的楼仔,帅气、文雅,气质拿捏的死死的。\n\n\n\n文章底部的点赞、留言、文章目录,都是妥妥的细节控。\n\n\n\n我们的教程,写得特别用心,这篇《高并发限流》近万字,手绘图也是毫不吝啬。\n\n\n\n[admin 端](https://paicoding.com/admin-view)也是开源的,可以对文章/教程进行管理配置,并且加入了游客/管理员账户,方便大家在线体验。\n\n\n\n好了,接下来,就由我来给大家“隆重”地介绍一下技术派的整个生态圈子。\n\n## 技术派是做什么的?\n\n这是一个基于 Spring Boot、MyBatis-Plus、MySQL、Redis、ElasticSearch、MongoDB、Docker、RabbitMQ 等技术栈实现的社区系统,**采用主流的互联网技术架构、全新的UI设计、支持一键源码部署**,拥有完整的文章&教程发布/搜索/评论/统计流程等,代码完全开源,没有任何二次封装,是一个非常适合二次开发/实战的现代化社区项目? 。\n\n>- 首页地址:[https://paicoding.com](https://paicoding.com)\n>- GitHub 仓库:[https://github.com/itwanger/paicoding](https://github.com/itwanger/paicoding)\n>- 码云仓库(国内访问更快):[https://gitee.com/itwanger/paicoding](https://gitee.com/itwanger/paicoding)\n\n对于这个项目我们是有野心的:\n\n1、国内的不少社区不思进取,你发个文章各种限制你,不让你干这个不让你干那个(我就不点名批评了,比如说某乎放个 B站视频链接就不给你流量),我们就是要打破这种条条框框,给开发者一个自由创作的平台。\n\n2、到了找工作的季节,很多小伙伴简历上没有项目经验可写,这个很吃亏。虽然 GitHub 和码云上已经有不少优秀的开源项目,但**大多数没有成熟且体系化的教程**,总不能直接下载到本地跑一下 main 方法就算学习了吧?\n\n我们要负责到底!接下来,我们会更新一系列的教程,不仅包含项目的开发文档,还会包括 Java、Go 语言、Spring、MySQL、Redis、微服务&分布式、消息队列、操作系统、计算机网络、数据结构与算法等内容。\n\n总之一句话:**学编程,就上技术派**?。\n\n## 技术派能让你学到什么?\n\n这绝不是我在口嗨哈,给大家看一下我们的系统架构图,就知道我们有多用心。\n\n\n\n再用文字详细地描述下,方便大家做笔记,也方便大家监督我们,这些技术栈最终都将以专栏/教程的方式和大家见面,让天下没有难学的技术(?)!\n\n- 构建工具:后端(Maven、Gradle)、前端(Webpack、Vite)\n- 单元测试:[Junit](https://tobebetterjavaer.com/gongju/junit.html)\n- 开发框架:SpringMVC、Spring、Spring Boot\n- Web 服务器:Tomcat、Caddy、Nginx\n- 微服务:Spring Cloud\n- 数据层:JPA、MyBatis、MyBatis-Plus\n- 模板引擎:thymeleaf\n- 容器:Docker(镜像仓库服务Harbor、图形化工具Portainer)、k8s、Podman\n- 分布式 RPC 框架:Dubbo\n- 消息队列:Kafka(图形化工具Eagle)、RocketMQ、RabbitMQ、Pulsar\n- 持续集成:Jenkins、Drone\n- 压力测试:Jmeter\n- 数据库:MySQL(数据库中间件Gaea、同步数据canal、数据库迁移工具Flyway)\n- 缓存:Redis(增强模块RedisMod、ORM框架RedisOM)\n- nosql:MongoDB\n- 对象存储服务:minio\n- 日志:[Log4j](https://tobebetterjavaer.com/gongju/log4j.html)、[Logback](https://tobebetterjavaer.com/gongju/logback.html)、[SF4J](https://tobebetterjavaer.com/gongju/slf4j.html)、[Log4j2](https://tobebetterjavaer.com/gongju/log4j2.html)\n- 搜索引擎:ES\n- 日志收集:ELK(日志采集器Filebeat)、EFK(Fluentd)、LPG(Loki+Promtail+Grafana)\n- 大数据:Spark、Hadoop、HBase、Hive、Storm、Flink\n- 分布式应用程序协调:Zookeeper\n- token 管理:jwt(nimbus-jose-jwt)\n- 诊断工具:arthas\n- 安全框架:Shiro、SpringSecurity\n- 权限框架:Keycloak、Sa-Token\n- JSON 处理:fastjson2、[Jackson](https://tobebetterjavaer.com/gongju/jackson.html)、[Gson](https://tobebetterjavaer.com/gongju/gson.html)\n- office 文档操作:EasyPoi、EasyExcel\n- 文件预览:kkFileView\n- 属性映射:mapStruct\n- Java硬件信息库:oshi\n- Java 连接 SSH 服务器:ganymed\n- 接口文档:Swagger-ui、Knife4j、Spring Doc、Torna、YApi\n- 任务调度框架:Spring Task、Quartz、PowerJob、XXL-Job\n- Git服务:Gogs\n- 低代码:LowCodeEngine、Yao、Erupt、magic-api\n- API 网关:Gateway、Zuul、apisix\n- 数据可视化(Business Intelligence,也就是 BI):DataEase、Metabase\n- 项目文档:Hexo、VuePress\n- 应用监控:SpringBoot Admin、Grafana、SkyWalking、Elastic APM\n- 注解:lombok\n- jdbc连接池:Druid\n- Java 工具包:hutool、Guava\n- 数据检查:hibernate validator\n- 代码生成器:Mybatis generator\n- Web 自动化测试:selenium\n- HTTP客户端工具:Retrofit\n- 脚手架:sa-plus\n\n我们希望通过**技术派**这个项目打造一个闭环,既能帮大家提升项目经验、升职加薪,又能提升我们的技术影响力,还能增加我们原创教程的流量(典型的既要又要还要,有没有?)。\n\n\n\n为了做好这个项目,我们付出了巨大的努力。先来看源码,分支 30 个,提交 595 次,这还不包括 admin 端的,已经推出,就广受好评,这才第一周,就收获了 100+ star,这还只是码云上。\n\n\n\n\n\n代码严格按照大厂的规范要求来,组织结构清晰、项目文档齐全、代码注释到位,你想学不到知识都难!\n\n\n\n只要你本地安装好 JDK 8(以上版本均可),MySQL(5.x/8.x+),配置好 Maven,导入项目源码后,直接运行 main 方法就可以轻松在本地跑起来,你甚至不需要额外手动创建数据库,不用在浏览器地址栏键入 `localhost:8080`,只要轻轻一点控制台提供的链接就可以访问了。\n\n\n\n这些琐事我们已经帮你做好了,省心吧?\n\n## 技术派的成长过程\n\n这个项目并不是二哥一时兴起发起的,而是做了充分的准备和调研。来介绍一下我们技术派的联合创始人,前后端我们三个人均有参与:\n\n- **楼仔**,8 年一线大厂后端经验(百度/小米/美团),技术派团队负责人,擅长高并发、架构、源码,有很强的项目/团队管理、职业规划能力\n- **一灰**,国企里莫过鱼、大厂里拧过螺丝、创业团队冲过浪的资深后端,主研Java技术栈,擅长架构设计、高并发、微服务等领域\n- **沉默王二**,GitHub 星标 6400k+开源知识库《Java 程序员进阶之路》作者,CSDN 两届博客之星,掘金/知乎 Java 领域优质创作者\n\n前期的需求调研、开发中的进度管理、上线后的文档教程,也都是不能少的,后期我们也会把这些开源出来,先截图给大家看看。\n\n1、整体设计草图\n\n\n\n2、库表设计\n\n\n\n3、产品方案\n\n\n\n4、UI设计\n\n\n\n5、接口文档\n\n\n\n6、进度排期\n\n\n\n7、bug&优化\n\n\n\n8、年度复盘\n\n\n\n## 技术派的后期打算\n\n项目上线后,最重要的两件事,一个是持续迭代,修复线上问题,并且把需求池中 p3 的任务开发掉;另外一个就是完成开发文档的编写,我们计划每周更新三篇。\n\n先是大厂篇,由我们技术派团队的楼仔负责。\n\n\n\n然后是基础篇,由二哥来负责。\n\n\n\n接着是进阶篇,由我们技术派团队的一灰来负责。\n\n\n\n后面还会推出扩展篇、前端篇、工程篇,把整个 Java 后端的技术栈全部搞定。\n\n\n\n## 技术派编程星球\n\n当然了,这些教程会优先开放给[技术派编程星球](https://t.zsxq.com/0buCVQ3qQ)的球友们,毕竟这群家伙都是氪金过的 VIP,一直在等这个项目的官宣,等的嗷嗷叫。\n\n\n\n如果你也想加入技术派的编程星球,现在送出 30 元的优惠券,原价 129 元,等于说优惠完**只需要 99 年就可以加入,每天不到 0.27 元**,超级划算!\n\n\n\n\n\n\n\n要知道,这还只是星球的一小部分服务,我们还会提供以下这些服务\n\n1. **技术派项目学习教程**,后续会采用连载的方式,让你从 0 到 1 也能搭建一套自己的网站\n2. 技术派项目答疑解惑,让你快速上手该项目,小白也能懂\n3. **向楼仔、二哥和大厂嘉宾 1 对 1 交流提问**,告别迷茫\n4. 个人成长路线、职业规划和建议,帮助你有计划学习\n5. 简历修改建议,让你的简历也能脱颖而出,收获更多面试机会\n6. 分享硬核技术学习资料,比如 **Spring 源码、高并发教程、JVM、架构选型**等\n7. 分享面试资料,都是一些高频面试题\n8. 分享工作中好用的开发小工具,助你提升开发效率\n9. 分享工作中的踩坑经历,让你快速获取工作经验,少走很多弯路\n10. 需求方案、技术架构设计提供参考建议,对标大厂\n11. 回答每天球友的问题\n12. 一起学习打卡,楼仔帮你分析学习进度\n\n\n**比如说星球分享的后端技术栈知识汇总**,全面系统的带你成为一名优秀的 Java 后端工程师。\n\n\n\n**像简历修改,绝不放过任何一个细节**,至今已经修改超过 100 份,所有的简历修改建议也都会第一时间同步到星球里。\n\n\n\n\n星球刚开始运营,所以设置的门槛非常低,为的就是给所有人提供一个可持续的学习环境,不过随着人数的增多,**肯定会涨价**,今天这批 30 元的优惠券是 2023 年最大的优惠力度了,现在入手就是最划算的,再犹豫就只能等着涨价了。\n\n原价 **129元**,优惠完只需**99元**就能上车,星球不仅能开阔你的视野,还能跟一群优秀的人交流学习,如果工作学习中遇到难题也有人给你出谋划策,这个价格绝对超值!\n\n\n\n想想,QQ音乐听歌连续包年需要 **88元**,腾讯视频连续包年需要 **178元**,腾讯体育包年 **233元**。我相信,知识星球回馈给你的,将是 10 倍甚至百倍的价值。\n\n最后,希望球友们,能紧跟我们的步伐!不要掉队。兔年,和我们技术派一起翻身、一起逆袭、一起晋升、一起拿高薪 offer!\n\n\n\n', '0', '2023-04-15 16:03:43', '2023-04-15 16:03:43');
COMMIT;
-- ----------------------------
-- Table structure for `article_tag`
-- ----------------------------
DROP TABLE IF EXISTS `article_tag`;
CREATE TABLE `article_tag` (
`id` int(10) unsigned NOT NULL AUTO_INCREMENT COMMENT '主键ID',
`article_id` int(10) unsigned NOT NULL DEFAULT '0' COMMENT '文章ID',
`tag_id` int(11) NOT NULL DEFAULT '0' COMMENT '标签',
`deleted` tinyint(4) NOT NULL DEFAULT '0' COMMENT '是否删除',
`create_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`update_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '最后更新时间',
PRIMARY KEY (`id`),
KEY `idx_tag_id` (`tag_id`)
) ENGINE=InnoDB AUTO_INCREMENT=12 DEFAULT CHARSET=utf8mb4 COMMENT='文章标签映射';
-- ----------------------------
-- Records of `article_tag`
-- ----------------------------
BEGIN;
INSERT INTO `article_tag` VALUES ('1', '100', '1', '0', '2022-10-08 19:23:14', '2022-10-08 19:23:14'), ('2', '101', '1', '0', '2022-10-08 19:23:35', '2022-10-08 19:23:35'), ('3', '102', '1', '0', '2022-10-08 19:23:43', '2022-10-08 19:23:43'), ('4', '103', '135', '0', '2023-01-13 19:54:17', '2023-01-13 19:54:17'), ('5', '104', '1', '0', '2023-04-15 15:25:17', '2023-04-15 15:25:17'), ('6', '104', '5', '0', '2023-04-15 15:25:17', '2023-04-15 15:25:17'), ('7', '104', '6', '0', '2023-04-15 15:25:17', '2023-04-15 15:25:17'), ('8', '105', '1', '0', '2023-04-15 16:03:43', '2023-04-15 16:03:43'), ('9', '105', '5', '0', '2023-04-15 16:03:43', '2023-04-15 16:03:43'), ('10', '106', '1', '0', '2023-04-15 20:00:49', '2023-04-15 20:00:49'), ('11', '107', '137', '0', '2023-04-15 20:07:49', '2023-04-15 20:07:49');
COMMIT;
- 运行初体验
- 可以看到自动为我们创建对应的数据库, 并执行SQL语句

- 数据库也出现了对应的数据库, 此时会比计划的多出两张表
**databasechangelog**里面存有一个md5值, 用来记录已执行sql的文件

-
当ChangeSet执行完毕之后,对应的sql文件/xml文件(即path定义的文件)不允许再修改,
-
因为db中会记录这个文件的md5,修改这个文件,这个md5也会随之发生改变. 因此两个解决方案
-
① : 新增一个changeSet
-
② : 删除 DATABASECHANGELOG 表中 changeSet id对应的记录,然后重新走一遍
-
再次启动项目, 新增一个ChangeSet, 结果如下

- 第三次启动, 没有任何修改

小结
这一章节主要介绍的就是技术派如何实现项目启动之后的库表初始化操作的,结合实际的代码介绍了两种姿势
- Liquibase: 代表的数据库版本管理方式
- DataSourceInitializer: 代表的项目启动之后执行某些初始化操作方式
这整个实现过程中,还有挺多的知识点:
- @Value 实现配置加载
- xml 文件的读取,资源文件的加载
- xml 文件的结构解析
- 基础的 jdbc 操作方式(库的初始化)
- 库的初始化校验相关操作
- @Configuration 配置类实现 Bean定义

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐


 14
14 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)