[论文笔记]Plan-and-Solve Prompting: Improving Zero-Shot Chain-of-Thought Reasoning by Large Language Mod
⭐ 为了解决思维链应用中的计算错误、缺失推理步骤错误和语义理解错误。作者引入了计划与解决提示策略。引导大语言模型制定一个将整个任务分解为较小子任务的计划,并根据计划执行子任务,从而达到更好的效果。
引言
今天带来一篇论文笔记Plan-and-Solve Prompting: Improving Zero-Shot Chain-of-Thought Reasoning by Large Language Models,翻译过来是 规划和解决提示:通过大型语言模型改进零样本的思维链推理。
为了解决多步推理任务,少样本的思维链提示包括一些手工制作的逐步推理演示,使LLMs能够明确生成推理步骤并提高推理任务的准确性。为了消除手工操作,Zero-shot-CoT将目标问题陈述与“让我们逐步思考”作为输入提示连接到LLMs。尽管Zero-shot-CoT取得了成功,但仍存在计算错误、缺失步骤错误和语义误解错误等三个问题。
为了解决缺失步骤错误,作者提出了计划与解决(Planand-Solve,PS)提示。它由两个组成部分组成:首先,制定一个计划将整个任务划分为较小的子任务,然后根据计划执行子任务。代码可以在 https://github.com/AGI-Edgerunners/Plan-and-Solve-Prompting 找到。
1. 总体介绍
我们通过使用说明(或触发句)来利用LLMs解决复杂的推理问题,从而引发它们在嵌入知识上的强大推理能力。到目前为止,LLMs已经展示出通过简单地将它们与一些说明性示例(即少样本学习)或用于解决新问题的提示(即零样本学习)相结合,即能够解决新的推理问题的令人印象深刻的能力。
为了利用LLMs解决多步复杂推理任务,Wei等人提出了少样本思维链提示,使LLMs能够在预测最终答案之前明确生成中间推理步骤,并提供了一些手工制作的逐步推理演示示例。Zero-shot CoT通过在输入到LLMs中的目标问题后附加“让我们逐步思考”来消除了提示中人工制作示例的需要。这种简单的提示策略让LLMs意外地产生了与少样本CoT提示相似的性能。

尽管Zero-shot-CoT在解决多步推理任务方面取得了显着的成功,但在100个算术测试示例中的结果仍然存在三个问题(如图1所示):
- 计算错误:计算错误导致了错误的答案;
- 缺失步骤错误:在涉及多个步骤时,会漏掉一些中间推理步骤;
- 语义误解:在问题的语义理解和推理步骤的连贯性方面存在其他错误,这可能是由于LLMs的能力不足造成的。
为了解决Zero-shot-CoT中由于缺失推理步骤引起的问题,作者提出了计划与解决(PS)提示。它由两个组成部分组成:首先,制定一个计划将整个任务划分为较小的子任务,然后根据计划执行子任务。

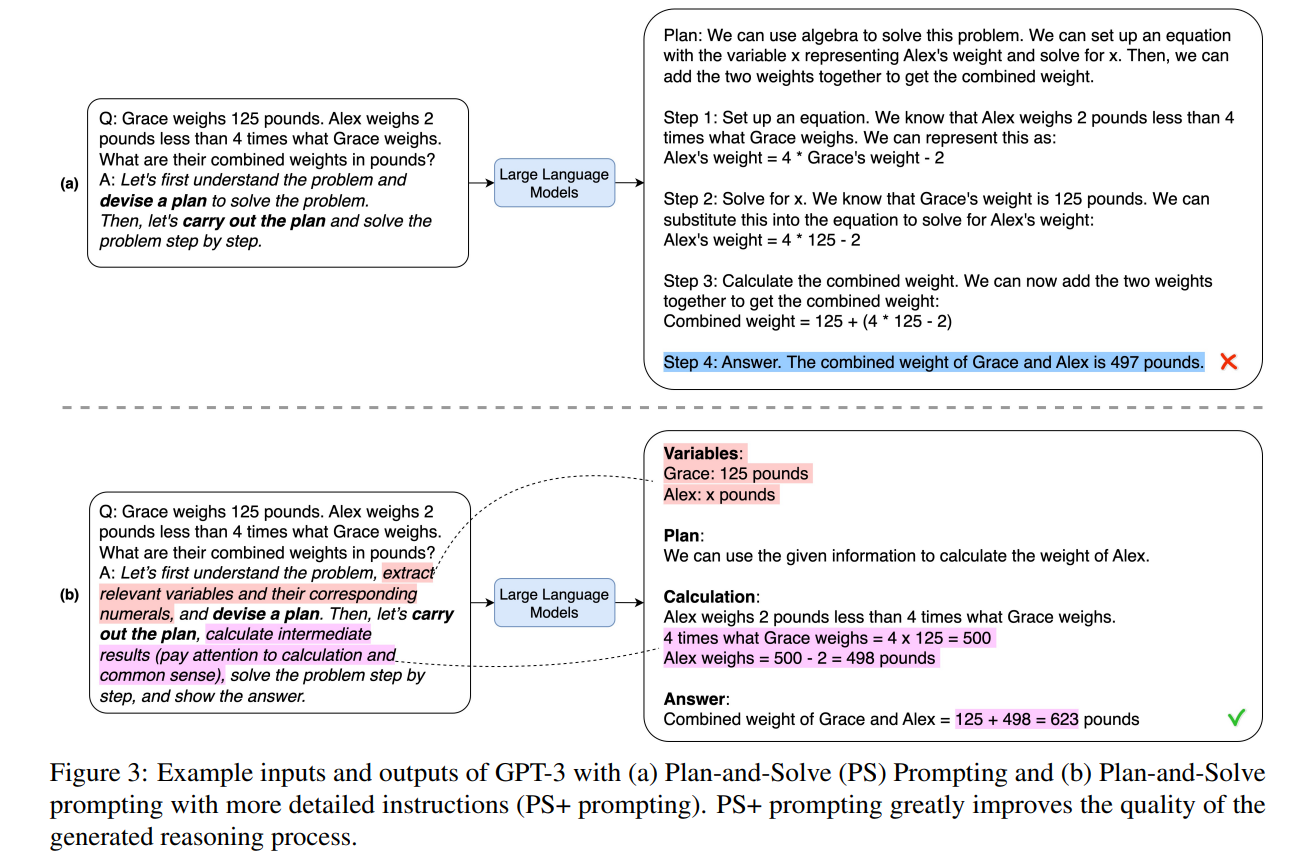
简单地用“让我们首先理解问题并制定解决问题的计划。然后,让我们按照计划逐步解决问题”(Let’s first understand the problem and devise a plan to solve the problem. Then, let’s carry out the plan and solve the problem step by step”)来替换Zero-shot-CoT中的“让我们逐步思考”(图2b)。

为了解决Zero-shot-CoT中的计算错误并提高生成的推理步骤的质量,给PS提示增加了更详细的说明。具体而言,通过“提取相关变量及其对应的数值”(extract relevant variables and their corresponding numerals)和“计算中间结果(注意计算和常识)”(calculate intermediate results (pay attention to calculation and commonsense)”)的指令来扩展PS提示。这种提示变体称为PS+提示策略(见图3b)。尽管它很简单,但PS+策略极大地提高了生成的推理过程的质量。此外,这种提示策略可以轻松地定制解决各种问题,而不仅仅是数学推理问题,如常识和符号推理问题。
作者进行了一些实验,结果表明:
- Zero-shot PS提示能够生成比Zero-shot-CoT提示更高质量的推理过程,因为PS提示提供了更详细的指导说明,引导LLMs执行正确的推理任务;
- Zero-shot PS+提示在某些数据集上优于少样本手动CoT提示,这表明在某些情况下,它有可能超过手动少样本CoT提示,这有望进一步促进新的CoT提示方法的开发,以引发LLMs中的推理。
2. 计划和解决提示
概述 引入了PS提示,一种新的零样本CoT提示方法,使LLMs能够明确制定解决给定问题的计划,并在预测输入问题的最终答案之前生成中间推理过程。与之前的少样本CoT方法不同,其中提示包含了逐步示范例子,零样本PS提示方法不需要示范例子,其提示包括问题本身和一个简单的触发句。与Zero-shot-CoT类似,Zero-shot PS提示包括两个步骤。在第一步中,提示使用提出的提示模板进行推理,生成问题的推理过程和答案。在第二步中,它使用答案提取提示来提取答案进行评估,例如“因此,答案(阿拉伯数字)是”(Therefore, the answer (arabic numerals) is)。
2.1 第一步:推理生成的提示
为了解决输入问题并避免由于错误计算和缺失推理步骤而导致的错误,该步骤旨在构建模板以满足以下两个标准:
- 模板应引导LLMs确定子任务并完成这些子任务。
- 模板应指导LLMs更加关注计算和中间结果,并尽可能确保它们的正确执行。
为了满足第一个标准,遵循Zero-shot-CoT的方法,将输入数据示例转换为带有简单模板的提示:Q: [X]. A: [T]。具体地,输入槽[X]包含输入问题陈述,人工指令在输入槽[T]中指定,以触发LLMs生成包括计划和完成计划所需步骤的推理过程。在Zero-shot-CoT中,输入槽[T]中的指令包括触发指令“让我们逐步思考”(‘Let’s think step by step”)。Zero-shot PS提示方法改为包含指令“制定计划”(devise a plan)和“执行计划”(carry out the plan),如图2(b)所示。因此,提示将是 Q: [X]. A: Let’s first understand the problem and devise a plan to solve the problem. Then, let’s carry out the plan and solve the problem step by step.” (让我们首先了解问题并制定解决问题的计划。然后,让我们逐步执行计划并解决问题)。然后,将以上提示传递给LLM,随后LLM输出一个推理过程。

为了满足第二个标准,通过更详细的指导说明扩展基于计划的触发句子。具体而言,在触发句子中添加了“注意计算”(pay attention to calculation),要求LLMs尽可能准确地进行计算。为了减少由于缺失必要推理步骤而导致的错误,明确指示LLMs“提取相关变量及其对应的数字”(extract relevant variables and their corresponding numerals”),以指导LLMs不要忽略输入问题陈述中的相关信息。如果LLMs忽略了相关且重要的变量,就更容易漏掉相关的推理步骤。图5中变量生成内容与漏掉推理步骤错误的相关性分析支持了这一假设(相关值小于0)。此外,在提示中添加“计算中间结果”(calculate intermediate results),以增强LLM生成相关且重要的推理步骤的能力。具体示例如图3(b)所示。在第一步结束时,LLM生成包含答案的推理文本。例如,图3(b)中生成的推理文本包括“Combined weight of Grace and Alex = 125 + 498 = 623 pounds”。在触发句子中添加具体描述的策略代表了改进复杂推理的零样本性能的新方法。
2.2 第二步:提取答案的提示
与Zero-shot-CoT类似,在第2步中设计另一个提示,以使LLM从第1步生成的推理文本中提取出最终的数值答案。这个提示包括在第一个提示后附加的答案提取指令,然后是LLM生成的推理文本。这样,我们期望LLM以所需的形式返回最终答案。
基于图3(b)中的示例,第2步中使用的提示将包括“Q: Grace weighs 125 pounds · · · Variables: Grace: 125 pounds … Answer: Combined weight of Grace and Alex = 125 + 498 = 623 pounds. Therefore, the answer (arabic numerals) is”。对于这个示例,LLM返回的最终答案是“623”。
3. 实验设置
略
4. 实验结果

4.2 分析
自一致性( Self-Consistency)提示的结果 自一致性被提出来减少LLM输出的随机性,通过生成N个推理结果,并通过多数投票确定最终答案。使用自一致性,通常期望方法的结果是一致且更好的。图4显示,带有自一致性的PS+提示在GSM8K和SVAMP上的表现远远优于没有自一致性的提示。

提示的效果 表5展示了6种不同输入提示的性能比较。提示1和提示2分别用于零样本CoT和零样本PoT。其余的提示是零样本PS+提示策略第1步中使用的提示的变体,使用贪心解码。带有变量和数字提取的提示3的表现比零样本CoT的提示1差。原因是提示3没有包含用于制定和完成计划的指令。然而,零样本PS+的其他提示表现良好,因为增加了更多关于中间结果计算、计划设计和实现的指令。以上结果表明,当提示包含更详细的指导LLM的指令时,LLM能够生成高质量的推理文本。关于不同推理问题的更多提示可以在附录A.1中找到。

错误分析 为了定性评估零样本PS+提示对计算错误和缺失推理步骤错误的影响,检查了GSM8K数据集上错误的分布。首先从GSM8K中随机抽取100个问题,生成推理文本,并使用零样本CoT、零样本PS和零样本PS+的提示策略提取答案。其中,零样本CoT对46个问题生成了错误的最终答案,零样本PS对43个问题生成了错误的最终答案,零样本PS+对39个问题生成了错误的最终答案。随后,分析并确定了所有这些问题的错误类型,如表6所示。
分析结果显示,PS+提示实现了最少的计算错误和缺失推理步骤错误,并且与零样本CoT相比具有可比的语义理解错误。零样本PS有稍多的错误,但仍然优于零样本CoT。因此,它们的计划和求解提示有效地指导LLM生成清晰完整的推理步骤。此外,PS+提示中额外的详细说明(即extract relevant variables and their corresponding numerals“提取相关变量及其对应的数字”和 calculate intermediate variables“计算中间变量”)使得LLM能够生成高质量的推理步骤,从而减少计算错误。
生成的推理和错误类型的相关性分析 为了更深入地了解PS+提示对错误类型的影响,分析生成的推理子部分与错误类型之间的相关性。具体而言,分析生成的推理文本中变量定义、推理计划和解决方案的存在情况,并将它们与三种错误类型进行相关性分析。这个分析研究所使用的问题集与之前的错误类型分析中使用的问题集相同。图5显示了变量定义、计划、解决方案的存在与三种不同类型错误之间的相关矩阵。观察到,变量定义和计划的存在与计算错误和缺失推理步骤错误呈负相关。零样本PS+提示可以通过减少计算错误和缺失推理步骤错误来进一步提高LLM在数学推理问题上的性能。
探索PS预测中计划的存在 为了确定PS每个预测中是否存在计划,随机抽取了100个数据样例并检查它们对应的预测。这100个预测中有90个确实包含了计划。这一观察结果表明,近期的LLM模型(如GPT-3.5和GPT-4)具备了强大的规划能力。
5. 相关工作
5.1 自然语言处理中的推理
众所周知,复杂的推理问题对于自然语言处理模型来说是具有挑战性的,这些问题包括数学推理(需要理解数学概念、计算和多步推理的能力)、常识推理(需要基于常识知识做出判断)和逻辑推理(需要通过应用形式逻辑规则来操作符号)。在大语言模型出现之前,Talmor等使用由微调过的GPT模型生成的解释来训练NLP模型,并发现训练后的模型在常识问答问题上表现更好。Hendrycks等尝试使用带有标记的理由来微调预训练的语言模型,但发现这些微调后的模型很难生成高质量的推理步骤。最近的Wei的工作表明,当LLMs扩展到数百亿个参数时(如GPT-3和PaLM),它们展现出强大的推理能力。这些仅使用少量示例展示的LLMs在不同的NLP任务中可以取得令人印象深刻的性能。然而,这些模型在需要多步推理的问题上仍然表现不佳。这可能是因为提供的少量示例不足以发挥LLMs的能力。
5.2 提示方法
为了利用LLMs的推理能力,Wei等提出了Chain-of-Thought提示方法,即在输入问题之前附加多个推理步骤。通过这种简单的少样本提示策略,LLMs在复杂的推理问题中表现出更好的性能。随后,许多研究在CoT提示的不同方面提出了进一步改进,包括提示格式,提示选择,提示集成,问题分解和规划。Chen等引入了PoT提示,使用经过代码预训练的LLMs编写程序作为理由,以将计算与推理分离开来。为了减少人工工作,Kojima等提出了零样本CoT,可以在没有示例的情况下引发推理步骤生成。为了利用示例示范的好处并最小化人工工作,Zhang等设计了Auto-CoT。它首先通过对给定数据集进行聚类来自动获取k个示例。然后,它遵循零样本CoT为所选示例生成理由。最后,示例示范通过将生成的理由添加到所选示例作为CoT提示来构建。
作者的工作与上述工作不同,侧重于在零样本的情况下通过LLMs引发多步推理。要求LLMs编写一个计划,将复杂的推理任务分解成多个推理步骤。此外,在提示中引入详细的说明,以避免推理步骤中的明显错误。
6. 结论
作者发现零样本CoT仍然存在三个问题:计算错误、缺失推理步骤错误和语义理解错误。为了解决这些问题,引入了计划与解决(PS和PS+)提示策略。它们是一种新的零样本提示方法,引导LLMs制定一个将整个任务分解为较小子任务的计划,并根据计划执行子任务。
7. 限制
存在两个限制。首先,设计提示来引导LLMs生成正确的推理步骤需要一定的工作量。GPT-3模型对提示中的表达非常敏感,因此需要仔细设计提示。其次,所提出的计划与解决提示可以帮助解决计算错误和缺失推理步骤错误,但语义误解错误仍然存在。
A 附录
本节包括两个部分:(1)尝试的所有提示的结果;(2)零样本PS+生成的示例文本。
下面列出了作者所有使用的提示:
| Prompt_ID | Type | Trigger Sentence |
|---|---|---|
| 101 | CoT | Let's think step by step. |
| 201 | PS | Let's first understand the problem and devise a plan to solve the problem. Then, let's carry out the plan to solve the problem step by step. |
| 301 | PS+ | Let's first understand the problem, extract relevant variables and their corresponding numerals, and devise a plan. Then, let's carry out the plan, calculate intermediate variables (pay attention to correct numeral calculation and commonsense), solve the problem step by step, and show the answer. |
| 302 | PS+ | Let's first understand the problem, extract relevant variables and their corresponding numerals, and devise a complete plan. Then, let's carry out the plan, calculate intermediate variables (pay attention to correct numerical calculation and commonsense), solve the problem step by step, and show the answer. |
| 303 | PS+ | Let's devise a plan and solve the problem step by step. |
| 304 | PS+ | Let's first understand the problem and devise a complete plan. Then, let's carry out the plan and reason problem step by step. Every step answer the subquestion, "does the person flip and what is the coin's current state?". According to the coin's last state, give the final answer (pay attention to every flip and the coin’s turning state). |
| 305 | PS+ | Let's first understand the problem, extract relevant variables and their corresponding numerals, and make a complete plan. Then, let's carry out the plan, calculate intermediate variables (pay attention to correct numerical calculation and commonsense), solve the problem step by step, and show the answer. |
| 306 | PS+ | Let's first prepare relevant information and make a plan. Then, let's answer the question step by step (pay attention to commonsense and logical coherence). |
| 307 | PS+ | Let's first understand the problem, extract relevant variables and their corresponding numerals, and make and devise a complete plan. Then, let's carry out the plan, calculate intermediate variables (pay attention to correct numerical calculation and commonsense), solve the problem step by step, and show the answer. |
A.1 所有触发句子的结果
表7至表16列出了为每个数据集尝试的所有提示的结果。









总结
⭐ 为了解决思维链应用中的计算错误、缺失推理步骤错误和语义理解错误。作者引入了计划与解决提示策略。引导大语言模型制定一个将整个任务分解为较小子任务的计划,并根据计划执行子任务,从而达到更好的效果。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐


 29
29 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)