LangChain教程:从入门到精通,解锁LLM的进阶技巧
LangChain中的LLM是指纯文本完成模型(text completion models.)。这些模型通常都是接收一个字符串输入并返回一个字符串输出。大型语言模型 (LLM) 是 LangChain 的核心组件。LangChain没有自己的LLM,而是提供了一个标准接口,用于与许多不同的LLM进行交互。一句话解释:使用纯文本作为输入和输出的语言模型的接口。
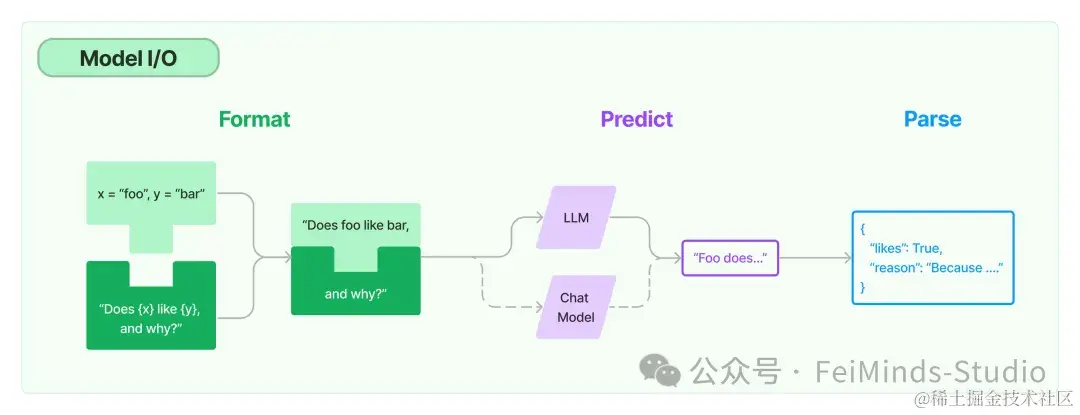
01 Model介绍
任何语言模型应用程序的核心元素都是…模型(Model)。LangChain 提供了与任何语言模型进行交互的构建块(building blocks)。
LangChain 的 Model I/O 组件包括:两种不同类型的模型 - LLM 和 Chat model;格式化模型输入 Prompt;输出解析器 Output parser。

本文将重点介绍:Model I/O子组件—>LLM
02 LLM介绍
LangChain中的LLM是指纯文本完成模型(text completion models.)。这些模型通常都是接收一个字符串输入并返回一个字符串输出。
大型语言模型 (LLM) 是 LangChain 的核心组件。LangChain没有自己的LLM,而是提供了一个标准接口,用于与许多不同的LLM进行交互。
一句话解释:使用纯文本作为输入和输出的语言模型的接口。
LLM 类旨在为所有这些模型提供标准接口,比如国外的模型:OpenAI、Cohere、Hugging Face等,国内的模型:通义千问、百川、ChatGLM等等。
我们可以看下LangChain中目前已经支持的大语言模型有哪些,我格式化打印了下直接子类和间接子类,细分下来已经支持模型总共有100多个。这里可以狂呼666…
class BaseLLM
class LLM
class FakeListLLM
class FakeStreamingListLLM
class CustomLLM
class CustomLLM
class Anthropic
class Banana
class CerebriumAI
class Cohere
class ForefrontAI
class GooseAI
class Modal
class Petals
class PipelineAI
class StochasticAI
class Writer
class HuggingFaceHub
class SagemakerEndpoint
class LlamaCpp
class HuggingFaceTextGenInference
class AI21
class AlephAlpha
class AmazonAPIGateway
class Arcee
class Aviary
class BaichuanLLM
class Baseten
class Beam
class Bedrock
class CTransformers
class ChatGLM
class Clarifai
class Databricks
class DeepInfra
class DeepSparse
class EdenAI
class FakeListLLM
class FakeStreamingListLLM
class Friendli
class GPT4All
class HuggingFaceEndpoint
class HumanInputLLM
class IpexLLM
class JavelinAIGateway
class KoboldApiLLM
class Konko
class Llamafile
class ManifestWrapper
class Minimax
class Mlflow
class MlflowAIGateway
class MosaicML
class NIBittensorLLM
class NLPCloud
class Nebula
class OCIGenAI
class OCIModelDeploymentLLM
class OCIModelDeploymentTGI
class OCIModelDeploymentVLLM
class OctoAIEndpoint
class OpaquePrompts
class OpenLLM
class PaiEasEndpoint
class Predibase
class PredictionGuard
class QianfanLLMEndpoint
class RWKV
class Replicate
class SelfHostedPipeline
class SelfHostedHuggingFaceLLM
class SelfHostedEmbeddings
class SelfHostedHuggingFaceEmbeddings
class SelfHostedHuggingFaceInstructEmbeddings
class SparkLLM
class TextGen
class TitanTakeoff
class TitanTakeoffPro
class Together
class VolcEngineMaasLLM
class Xinference
class YandexGPT
class Yuan2
class BaseOpenAI
class OpenAI
class AzureOpenAI
class BaseOpenAI
class OpenAI
class PromptLayerOpenAI
class AzureOpenAI
class Anyscale
class OpenLM
class VLLMOpenAI
class OpenAIChat
class PromptLayerOpenAIChat
class GradientLLM
class HuggingFacePipeline
class Aphrodite
class AzureMLOnlineEndpoint
class CTranslate2
class Fireworks
class GigaChat
class GooglePalm
class Ollama
class Tongyi
class VLLM
class VertexAI
class VertexAIModelGarden
class WatsonxLLM
03 LLM案例实操
1 准备好LLM和输入
LLM的输入是纯文本,所以这里创建起来也很方便。
from langchain_openai import OpenAI
# 问号部分自己填自己的,verbose设置成True用于打印一些中间过程日志
llm = OpenAI(temperature=?, model_name=?, openai_api_key=?,verbose=True)
text = "我想创办一家公司,主要承接相亲业务,请帮我想一个公司名称。"
2 invoke执行
一次性全部输出纯文本结果。
llm.invoke(text)
# >> 当然可以,考虑到您的业务性质,我建议的公司名称可以是“红线牵缘”或者“心桥相会”。这两个名字都寓意着帮助人们建立感情的桥梁,符合相亲业务的主题。希望您会喜欢。
3 stream执行
流式输出,下一次输出不包括上一次的输出,结果与invoke一致。
for chunk in llm.stream(
"我想创办一家公司,主要承接相亲业务,请帮我想一个公司名称。"
):
print(chunk, end="", flush=True)
4 batch执行
顾名思义,批量执行多个文本输入,在一次性输出每个输入对应的结果。
llm.batch(
[
"我想创办一家公司,主要承接相亲业务,请帮我想一个公司名称。"
]
)
# >> [' 当然可以,考虑到您的业务性质,我建议的公司名称可以是“红线牵缘”或者“心桥相会”。这两个名字都寓意着帮助人们建立感情的桥梁,符合相亲业务的主题。希望您会喜欢。 ']
5 astream_log执行
异步执行,并且下一次输出包含上一次的输出累加,结果与invoke一致。。
async for chunk in llm.astream_log(
"我想创办一家公司,主要承接相亲业务,请帮我想一个公司名称。"
):
print(chunk)
04 自定义LLM
既然LangChain提供了LLM执行的标准接口,必然我们也可以自定义自己的LLM执行逻辑。
自定义LLM只需要实现两个必需的方法:
-
_call:根据用户输入,执行具体逻辑,然后返回输出
-
_llm_type:获取此聊天模型使用的语言模型的类型。仅用于日志记录。
让我们自定义一个自己的LLM,执行逻辑是:在用户输入的文本前加上“_oh,我的天哪_”。比如用户输入“你好呀!”,模型输出“oh,我的天哪你好呀!”; 用户输入“你吃饭了吗?”,模型输出“oh,我的天哪~你吃饭了吗?”。
from typing import Any, Dict, Iterator, List, Optional
from langchain_core.callbacks.manager import CallbackManagerForLLMRun
from langchain_core.language_models.llms import LLM
from langchain_core.outputs import GenerationChunk
class CustomLLM(LLM):
"""
自定义一个LLM,在用户输入的基础上加上前缀:oh,我的天哪~
"""
def _call(
self,
prompt: str,
stop: Optional[List[str]] = None,
run_manager: Optional[CallbackManagerForLLMRun] = None,
**kwargs: Any,
) -> str:
"""
根据用户输入,执行具体逻辑,然后返回输出
"""
return "oh,我的天哪~" + prompt
def _stream(
self,
prompt: str,
stop: Optional[List[str]] = None,
run_manager: Optional[CallbackManagerForLLMRun] = None,
**kwargs: Any,
) -> Iterator[GenerationChunk]:
"""
根据用户输入,执行具体逻辑,然后流式返回输出
"""
for char in "oh,我的天哪~" + prompt:
chunk = GenerationChunk(text=char)
if run_manager:
run_manager.on_llm_new_token(chunk.text, chunk=chunk)
yield chunk
@property
def _identifying_params(self) -> Dict[str, Any]:
"""返回模型自定义参数字典"""
return {
"model_name": "Custommm",
"model_version":"1.0.0"
}
@property
def _llm_type(self) -> str:
"""获取此聊天模型使用的语言模型的类型。仅用于日志记录。"""
return "custom"
使用方式跟其他LLM一样,我们打印一些输入输出看看效果。
llm = CustomLLM()
print(llm)
# CustomLLM
# Params: {'model_name': 'Custommm', 'model_version': '1.0.0'}
llm.invoke("你好呀")
# oh,我的天哪~~你好呀
await llm.ainvoke("你好呀")
# oh,我的天哪~~你好呀
llm.batch(["你好呀", "猪八戒"])
# ['oh,我的天哪~你好呀', 'oh,我的天哪~猪八戒']
await llm.abatch(["你好呀", "孙悟空"])
# ['oh,我的天哪~你好呀', 'oh,我的天哪~孙悟空']
async for token in llm.astream("你好呀"):
print(token, end="|", flush=True)
# o|h|,|我|的|天|哪|~|你|好|呀
能不能与其他的LangChain组件很好的集成在一起?答案是: 能!
from langchain_core.prompts import ChatPromptTemplate
prompt = ChatPromptTemplate.from_messages(
[("system", "you are a bot"), ("human", "{input}")]
llm = CustomLLM()
chain = prompt | llm
idx = 0
async for event in chain.astream_events({"input": "你好呀!"}, version="v1"):
print(event)
# 输出很多的Event,由于输出太多,这里省略输出,大家可以自行验证。
05 LLM缓存
LangChain为LLM提供了一个可选的缓存层。这之所以有用,有两个原因:
-
如果经常多次请求相同的输入,它可以通过减少对LLM提供者的API调用次数来节省资金。
-
它可以通过减少对LLM提供程序的API调用次数来加快应用程序的速度。
注意看下面程序的执行时间对比!!!
from langchain.globals import set_llm_cache
from langchain_openai import OpenAI
from langchain.cache import InMemoryCache
llm = OpenAI(xxxxx)
# 输出一下程序执行时间
%%time
# 设置内存缓存
set_llm_cache(InMemoryCache())
llm.invoke("请讲一个关于乌龟的冷笑话。")
# CPU times: total: 0 ns
# Wall time: 965 ms
# 为什么乌龟总是带着头盔? 因为它想成为一只安全的慢行者!
# 再次执行
%%time
llm.invoke("请讲一个关于乌龟的冷笑话。")
# CPU times: total: 0 ns
# Wall time: 1.01 ms
# 为什么乌龟总是带着头盔? 因为它想成为一只安全的慢行者!
这里设置了“内存缓存”,你说:我不想用内存缓存怎么办?LangChain:嗯!可以不用内存缓存,还有这些缓存你可以使用。
class BaseCache
class InMemoryCache
class SQLAlchemyCache
class SQLiteCache
class UpstashRedisCache
class _RedisCacheBase
class RedisCache
class AsyncRedisCache
class RedisSemanticCache
class GPTCache
class MomentoCache
class CassandraCache
class CassandraSemanticCache
class SQLAlchemyMd5Cache
class AstraDBCache
class AstraDBSemanticCache
class AzureCosmosDBSemanticCache
06 跟踪token使用情况
token是什么?token是模型的输入与输出的容量,每次token的生成都需要耗费资源,这也是为什么模型的token是有限制的,OpenAI甚至按照token使用来收费。所以跟踪token的使用情况也是大模型开发中重要的一环。
很遗憾,目前LangChain仅支持OpenAI的token使用记录与计算,所以这里用一个简单的示例展示下效果。这里不能自定义啊,大家别上来就自定义~
from langchain_community.callbacks import get_openai_callback
from langchain_openai import OpenAI
llm = OpenAI(xxxxxx)
with get_openai_callback() as cb:
result = llm.invoke("Tell me a joke")
print(cb)
# Tokens Used: 37
# Prompt Tokens: 4
# Completion Tokens: 33
# Successful Requests: 1
# Total Cost (USD): $7.2e-05
07 总结
这里LangChain进阶系列的第一篇文章,主要对Model I/O中的LLM组件进行详细解析,从基础使用,到流式输出,再到自定义LLM,再到LLM缓存,最后加上一个仅适用于LLM的小知识(token使用跟踪)。希望这篇文章能帮助到已经看完的你,人工智能时代你我都不想太掉队~

如何学习AI大模型?
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。

1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 15
15 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)