
python操作PDF中各类文本内容的方法
PDF格式有几种专门的变体 - 标准化和开发中。这些是PDF格式的子集。每个文件都是有效的PDF文档,但对所使用的设施或内容本身有限制。其中两个,PDF/A和PDF/X,现在是ISO标准。典型的PDF文件包含数千个对象,多种压缩机制,不同的字体格式, 以及矢量和光栅图形的混合以及各种元数据和辅助内容。PDF完全向后兼容(你可以将PDF版本1.0文档加载到为PDF 1.7设计的程序中) 并且大部分向

目录
- 楔子
- PDF文件研究
- python操作PDF
- Google Tesseract OCR
- 全面解析PDF
-
- 文档的布局(Layout)分析
- 引入hugging face大模型
-
- 告警处理
-
- 报错:UserWarning: 1Torch was not compiled with flash attention.
- 报错:The attention mask and the pad token id were not set. As a consequence, you may observe unexpected behavior. Please pass your input's `attention_mask` to obtain reliable results.Setting `pad_token_id` to `eos_token_id`:151643 for open-end generation.
- 报错:no module named _verovio
- 定义从PDF中提取文本的函数
- 扩展:全面解析Docx
- FAQ(Frequently Asked Questions)
楔子
随着大型语言模型(LLM)的应用不断发展,从简单的文本摘要和翻译,到复杂的检索(如RAG),都需要我们首先从真实世界提取文本数据。
有许多类型的文档共享这种非结构化信息,从网络文章、博客文章到手写信件和图表。然而,这些文本数据的很大一部分是以PDF格式存储和传输的。
因此,从PDF文档中提取信息,是很多类似RAG这样的应用第一步要处理的事情,在这个环节,我们需要做好三件事:
- 提取出来的文本要保持信息完整性,也就是准确性;
- 提出的结果需要有附加信息,也就是要保存元数据;
- 提取过程要完成自动化,也就是流程化。
目前而言,出现次数最频繁的PDF格式有以下三种:
-
机器生成的pdf文件:这些pdf文件是在计算机上使用W3C技术(如HTML、CSS和Javascript)或其他软件(如Adobe Acrobat、Word或Typora等MarkDown工具)创建的。这种类型的文件可以包含各种组件,例如图像、文本和链接,这些组件都是可以被选中、搜索和易于编辑的。
-
传统扫描文档:这些PDF文件是通过扫描仪、手机是的扫描王这样的APP从实物上扫描创建的。这些文件只不过是存储在PDF文件中的图像集合。也就是说,出现在这些图像中的元素,如文本或链接是不能被选择或搜索的。本质上,PDF只是这些图像的容器而已。
-
带OCR的扫描文档:这种类似有点特殊,在扫描文档后,使用光学字符识别(OCR)软件识别文件中每个图像中的文本,将其转换为可搜索和可编辑的文本。然后软件会在图像上添加一个带有实际文本的图层,这样就可以在浏览文件时选择它作为一个单独的组件。但是有时候我们不能完全信任OCR,因为它还是存在一定几率的识别错误的。
另外还有一种情况是,尽管现在越来越多的机器安装了OCR系统,可以识别扫描文档中的文本,但仍然有一些文档以图像格式包含整页。当读到一篇很棒的文章时,想选中一个句子,但却选择了整个页面。这可能是由于特定OCR程序的限制…
PDF文件研究
PDF(Portable Document Format,可移植文档格式)是一种由Adobe Systems开发的文件格式,用于跨平台、跨设备呈现文档内容。PDF文件的核心特性包括以下几个方面:
-
固定格式:PDF文件的布局和格式在不同的设备和操作系统上保持一致,包括文本、图像、字体、颜色等。
-
多功能性:PDF支持嵌入多种内容类型,如文本、矢量图、位图图像、表格、链接、表单、嵌入式媒体(如音频、视频)等,还可以包含JavaScript脚本用于交互。
-
设备无关性:PDF文件不依赖于具体的软件、硬件或操作系统,能够在各种平台上打开并显示。
-
压缩与安全性:PDF可以进行高效的压缩以减小文件大小,同时支持加密、数字签名等功能来保证文件的安全性。
-
分页与导航:PDF文件具有固定分页,同时可以通过书签、目录、超链接等方式进行快速导航。
PDF文件由多个部分组成,核心结构如下:
- Header:文件的起始部分,包含PDF版本信息。
- Body:文档的主体部分,包含对象(如文本、图像、表格等)的定义。
- Cross-Reference Table(交叉引用表):用于快速定位PDF文件中的各个对象。
- Trailer:文档的末尾部分,指向交叉引用表,并提供了文档的元数据。
PDF格式是基于PostScript语言发展的,强调页面描述能力,并且被广泛用于生成无法轻易修改的文件,如合同、发票、电子书等。
接下来,我们将借助:PDF Explained (译作《PDF 解析》)和 pdf1.7标准参考 来详细了解下PDF文件的结构,以做到知己知彼百战百胜。
PDF介绍
PDF格式有几种专门的变体 - 标准化和开发中。这些是PDF格式的子集。 每个文件都是有效的PDF文档,但对所使用的设施或内容本身有限制。其中两个,PDF/A和PDF/X,现在是ISO标准。
典型的PDF文件包含数千个对象,多种压缩机制,不同的字体格式, 以及矢量和光栅图形的混合以及各种元数据和辅助内容。
PDF/A
PDF/A标准(ISO 19005-1:2005)为在图书馆,国家档案馆和官僚机构中长期存档的文件定义了一套规则。 它还需要“符合标准的阅读器”以某种方式,使用嵌入字体,使用颜色管理等。简而言之,对PDF/A的限制是:
- 无加密
- 要嵌入的所有字体
- 需要元数据
- 不允许使用JavaScript
- 仅限与设备无关的色彩空间
- 没有音频或视频内容
PDF/A合规性有两个级别:PDF/A-1b(“B级合规性”)要求对文档进行精确的视觉复制。 PDF/A-1a(“A级合规性”)要求文本可以映射到Unicode,并且除了要求精确的视觉再现之外,还要记录文本的顺序和结构。
PDF/A能力中心是代表PDF/A利益相关者的行业组织。第二个ISO版本的PDF/A正在准备中。
PDF/X
PDF/X标准是印刷行业图形交换的ISO标准系列,其中最新的是PDF/X-5(ISO 15930-8:2010)。它定义了许多限制:
- 必须嵌入所有字体
- 必须嵌入所有图像数据
- 不能包含声音,电影或不可打印的注释
- 没有表格
- 没有JavaScript
- 有限的压缩算法
- 无加密
以及一些额外的要求:
- 文件使用subversion标记为PDF/X(例如,PDF/X-5)
- 除了正常的页面尺寸外,还需要出血,修剪和/或艺术盒。这些框定义了介质的大小,可打印区域,最终切割尺寸等。
- 如果文件已被捕获,则设置标志。陷印是在图形对象之间创建小的重叠以掩盖多个彩色打印过程中的注册问题的过程。
- 文件必须包含输出意图,其中包含描述如何打印的颜色配置文件。
版本摘要
PDF完全向后兼容(你可以将PDF版本1.0文档加载到为PDF 1.7设计的程序中) 并且大部分向前兼容(为PDF 1.0编写的程序通常可以加载PDF 1.7文件)。 确保前向兼容性是因为读者忽略了他们不理解的内容 - 只有在引入新的压缩方法或对象存储机制时才会被忽略。 自2003年的PDF 1.5以来,这种变化很小。表1-1总结了PDF版本及其功能。
| PDF 版本 | Acrobat Reader 版本 | 推出 | 新功能摘要 |
|---|---|---|---|
| 1.0 | 1.0 | 1993 | 首发 |
| 1.1 | 2.0 | 1996 | 设备无关的颜色空间,加密(40位),文章线程,命名目标和超链接 |
| 1.2 | 3.0 | 1996 | AcroForms(交互式表单),电影和声音,更多压缩方法,Unicode支持。 |
| 1.3 | 4.0 | 2000 | 更多色彩空间,嵌入(附加)文件,数字签名,注释,蒙版图像,渐变填充,逻辑文档结构,印前支持 |
| 1.4 | 5.0 | 2001 | 透明度,128位加密,更好的表单支持,XML元数据流,标记PDF,JBIG2压缩 |
| 1.5 | 6.0 | 2003 | 对象流和交叉引用流,用于更紧凑的文件,JPEG 2000支持,XFA表单,公钥加密,自定义加密方法,可选内容组 |
| 1.6 | 7.0 | 2004 | OpenType字体,3D内容,AES加密,新颜色空间 |
| 1.7 (later ISO 32000-1:2008) | 8.0 | 2006 | XFA 2.4,新类型的字符串,公钥体系结构的扩展 |
| 1.7 Extension Level 3 | 9.0 | 2008 | 256位AES加密 |
| 1.7 Extension Level 5 | 9.1 | 2009 | XFA 3.0. |
| 1.7 Extension Level 8 | X | 2011 | 未知 |
构建一个简单的PDF
语法
PDF 文档的内容由多个对象组成,其中包括五种基本对象:
- 整数和实数,例如 42 和 3.1415
- 字符串,括在括号中,例如前面的
(Hello, World!) - 名称 Names,他们带有
/,例如/count - 布尔值,由关键字
true和false表示 null对象,由关键字null表示
和三种复合对象:
- 数组 Arrays,包含其他对象的有序集合,如
[1 0 0 0] - 字典 Dictionaries,包含
<name, object>对的无序集合,例如<< /Contents 4 0 R /Resources 5 0 R >>表示将/Contents映射到间接引用4 0 R,将/Resources映射到间接引用5 0 R - 流 Streams,保存图片、字体等二进制数据,连带一个描述数据属性(如长度、压缩参数)的字典
- 间接引用 Indirect Reference,一种将对象链接在一起的方式
整数和实数
整数被写成一个或多个十进制数字 0-9,前面可包含加减号:
0 +1 -1 63
实数被写为一个或多个十进制数字,前面可包含加减号,以及一个小数点,可以在开头,中间或结尾:
0.0 0. .0 -0.004 65.4
字符串
字符串包含一系列字节,写在括号之间:
(Hello, World!)
如果字符串中包含反斜杠和括号,则必须在它们前面加上反斜杠进行转义:
(Some \\ escaped \(characters)
字符串也可以写为 < 和 > 之间的16进制数字序列,每一对表示一个字节:
<4F6Eff3> // 字节 0x4F, 0x6E, 0xFF, and 0x30
如果序列个数为奇数,则在最后加一个0。
名称 Names
名称在整个PDF中有使用,用于定义对象和字典的键。名称前面引入了一个正斜杠,例如:
/Count
名称中一般是不包含空格的,如果需要的话,可以使用 “#20” 符号:
/Websafe#20Dark#20Green // /Websafe Dark Green
名称区分大小写,/Count 和 /count 是不一样的。
布尔值
PDF允许布尔值为 true 和 false 。它们经常在字典条目中用作标志。
数组
数组表示PDF对象的有序集合:
[0 0 400 500]
数组中对象不一定都是同一类型,也可以包括其他数组例如:
[/Green /Blue [/Red /Yellow]]
其中包含三个对象:名称 /Green 、名称 /Blue 和一个包含两个名称的数组 [/Red /Yellow]。
字典 Dictionaries
字典表示由键值对组成的无序集合。键是名称,值可以是任何 PDF 对象,写在 << 和 >>之间,例如:
<</One 1 /Two 2 /Three 3>>
字典中也可以包含其他字典,嵌套字典构成了大多数PDF文件中大量的非图形结构化数据。
间接引用 Indirect References
为了将 PDF 内容拆分成独立的对象(以便按需读取),我们将它们与间接引用连接在一起。例如对象6的间接引用写为:
6 0 R
其中,6是对象编号,0是世代号(基本是0),R 是间接引用关键字。
下面是一个使用间接引用的典型字典:
<< /Resources 10 0 R /Contents [4 0 R] >>
名称 /Resources 映射到了对象10的间接引用,/Contents 映射到了对象4的间接引用。
流 Streams
流用于保存二进制数据,它们由一个字典和一个二进制数据块组成。字典根据流的特定用途列出数据的长度和其他可选参数。
在结构上,流包含一个字典,后面跟随 stream 关键字,然后是多个字节的数据,最后是 endstream 关键字,如下:
4 0 obj // 对象4
<</Length 65>> // 数据长度
stream
1. 0. 0. 1. 50. 700. cm // 一个图形流,包含65字节的数据
BT
/F0 36. Tf
(Hello, World!) Tj
ET
endstream
endobj
这里字典只包含 /Length 条目,以字节为单位给出流的长度。
文件结构
一个简单有效的 PDF 文件按顺序包含4个部分:
- header(文件头):提供 PDF 版本号;
- body(文件体):包含页面,图形内容和大部分辅助信息,全部编码为一系列对象;
- cross-reference table(交叉引用表):列出文件中每个对象的位置便于随机访问;
- trailer(文件尾):通过它可以在不处理整个文件的情况下找到文件的各个部分。
文件头 Header
PDF 文件的第一行给出文档的版本号:
%PDF-1.0
这将文件定义为1.0版本。PDF 是向后兼容的,很大程度上也是向前兼容的,所以无论版本号是多少,大多数PDF程序都会尝试读取其内容。
由于PDF文件几乎总是包含二进制数据,为了允许传统文件传输程序确定文件是二进制文件,通常在标头中包含一些字符代码高于127的字节。例如:
%âãÏÓ
百分号表示另一个标题行,其他几个字节是超过127的任意字符代码。 因此,我们示例中的整个header是:
%PDF-1.0
%âãÏÓ
文件体 Body
文件体由一系列对象组成,每个对象在一行上都有一个对象编号(object number),世代号(generation number)和 obj 关键字,在这之后跟随一个 endobj 关键字:
1 0 obj
<< /Type /Pages
/Count 1
/Kids [2 0 R]
>>
endobj
在此处,对象编号是 1,世代号是 0(几乎总是),它的内容位于 1 0 obj 和 endobj 两行之间,是一个字典。
交叉引用表 Cross-Reference Table
交叉引用表列出了文件正文中每个对象的字节偏移量。这允许随机访问对象,因此不必按顺序读取它们,一个从未使用过的对象就永远不会被读取。这尤其意味着,即使在大型文件上,像计算PDF文档中的页数这样的简单操作也可以很快。
交叉引用表由一个表示条目数的标题行组成,然后是一个特殊条目,接下来是文件体中的每个对象,如下所示:
xref // 交叉引用表从这里开始
0 6 // 表中有6个条目,从0开始
0000000000 65535 f // 特别条目
0000000015 00000 n // 对象1的字节偏移量为15
0000000074 00000 n // 对象2的字节偏移量为74
0000000182 00000 n // ...
0000000281 00000 n
0000000410 00000 n // 对象5的字节偏移量为409
文件尾 Trailer
文件尾的第一行是 trailer 关键字。之后是 trailer 字典,其中至少包含 /Size 条目(给出交叉引用表中条目的数量)和 /Root 条目(给出文档目录的对象编号,它是Body中对象图的根元素)。
接下来是 startxref 关键字,然后是一个表示交叉引用表字节偏移量的数字,最后是 %%EOF ,PDF 文件的结束标记,如下:
trailer // trailer 关键字
// trailer 字典
<< /Size 6
/Root 5 0 R
>>
startxref // startxref 关键字
459 // 交叉引用表字节偏移量
%%EOF // 文件结束标记
Trailer 是从文件尾向前读取的: 先找到文件结束标记,然后提取交叉引用表的字节偏移量,接着解析trailer字典。trailer 关键字标记了trailer的上限。
PDF文件的读取流程
为了读取一个PDF文件,将其从一个扁平的字节序列转变成一个内存中的对象图形,一般有以下几个步骤:
- 从文件开头读取 header,确认它确实是一个PDF文档并检索其版本号;
- 接着通过从文件结尾向前搜索,找到文件结束标记。然后读取交叉引用表的字节偏移量和trailer字典;
- 接着通过读取交叉引用表,就可以知道文件中每个对象的位置;
- 到这一步,所有的对象都可以根据需要来读取和解析;
- 现在,可以提取页面,解析图形内容,提取元数据等等。
文档结构
下图是一个典型文档的逻辑结构:
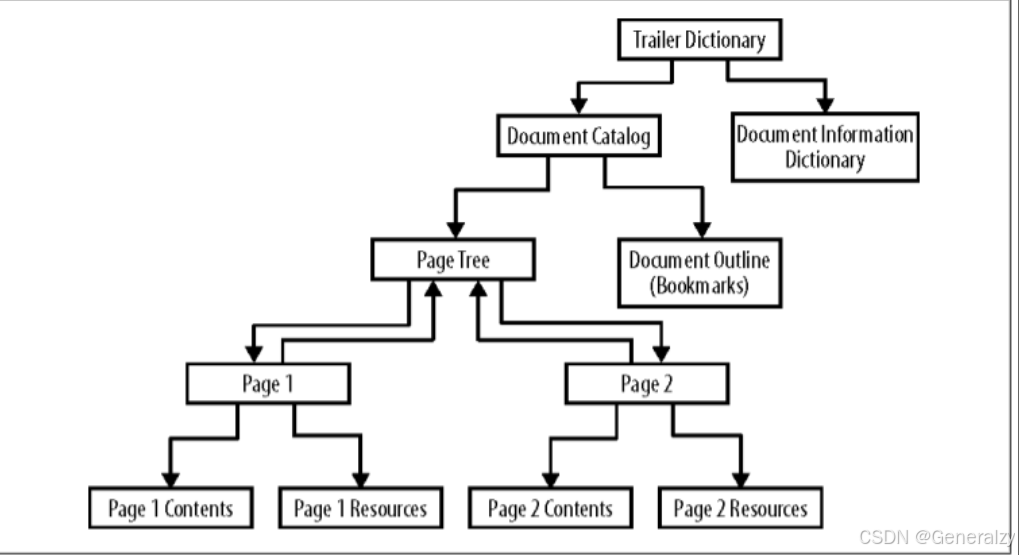
Trailer 字典
这个字典存在于文档尾而不是Body中,是程序读取PDF文档的第一步。以下是字典中的一些重要条目(*表示必需条目):
| 键 | 值类型 | 值 |
|---|---|---|
| /Size* | 整数 | 文件交叉引用表中的条目总数(通常等于文件中的对象数加1) |
| /Root* | 间接引用字典 | 文档目录 |
| /Info | 间接引用字典 | 文档信息字典 |
| /ID | 2个字符串的数组 | 唯一标识工作流中的文件。第一个字符串在首次创建文件时确定,第二个字符串在工作流系统修改文件时进行修改 |
例如:
<<
/Size 421
/Root 377 0 R
/Info 375 0 R
/ID [<75ff22189ceac848dfa2afec93deee03> <057928614d9711db835e000d937095a2>]
>>
一旦处理了trailer字典,我们就可以继续读取文档信息字典和文档目录。
文档信息字典
文档信息字典包含文件的创建和修改日期,以及一些简单的元数据。
下表是文档信息字典的条目:
| 键 | 值类型 | 值 |
|---|---|---|
| /Title | 文本字符串 | 文档标题,与第一页上显示的任何标题无关 |
| /Subject | 文本字符串 | 文件的主题。同样,这只是元数据,没有关于内容的特定规则 |
| /Keywords | 文本字符串 | 与此文档相关的关键字。没有给出关于如何构建的建议 |
| /Author | 文本字符串 | 文件作者的姓名 |
| /CreationDate | 日期字符串 | 文档创建的日期 |
| /ModDate | 日期字符串 | 上次修改文档的日期 |
| /Creator | 文本字符串 | 最初创建此文档的程序的名称 |
| /Producer | 文本字符串 | 将此文件转换为PDF的程序的名称 |
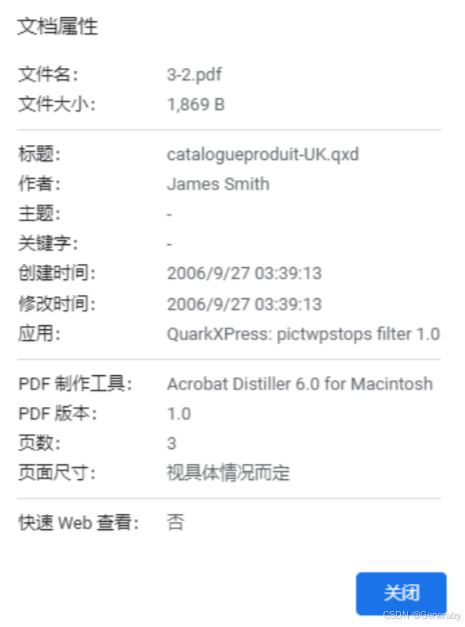
下面是一个典型的文档信息字典:
<<
/ModDate (D:20060926213913+02'00')
/CreationDate (D:20060926213913+02'00')
/Title (catalogueproduit-UK.qxd)
/Creator (QuarkXPress: pictwpstops filter 1.0)
/Producer (Acrobat Distiller 6.0 for Macintosh)
/Author (James Smith)
>>
其在PDF浏览器中展示如下:
文档目录
文档目录是主对象图的根对象,通过间接引用可以找到所有其它对象。下表介绍了文档目录的一些必需条目的可选条目(*表示必需条目):
| 键 | 值类型 | 值 |
|---|---|---|
| /Type* | 名称 | 必须是 /Catalog |
| /Pages* | 间接引用字典 | 页面树的根节点 |
| /PageLabels | number tree | 一个数字树,给出了该文档的页面标签。 这种机制允许文档中的页面具有比1,2,3更复杂的编号 |
| /Names | 字典 | 名字词典。它包含各种名称树,它们将名称映射到实体,以避免使用对象编号来直接引用 |
| /Dests | 字典 | 将名称映射到目标的字典,和超链接相关 |
| /ViewerPreferences | 字典 | 一个查看器首选项字典,允许指定在屏幕上查看文档时PDF查看器的行为,例如打开文档的页面,初始查看比例等 |
| /PageLayout | 名称 | 指定PDF查看器要使用的页面布局 |
| /PageMode | 名称 | 指定PDF查看器要使用的页面模式 |
| /Outlines | 间接引用字典 | 大纲字典是文档大纲的根,通常称为书签 |
| /Metadata | 间接引用流 | 文档的XMP元数据 |
页面和页面树
PDF 文档的页面字典中包含了绘制图形和文本内容的指令,还包括页面尺寸以及一些定义剪裁的方框等等。
下表列出了页面字典的条目(*表示必需条目):
| 键 | 值类型 | 值 |
|---|---|---|
| /Type* | 名称 | 必须是 /Page |
| /Parent* | 间接引用字典 | 页面树中该节点的父节点 |
| /Resources | 字典 | 页面的资源(字体,图像等)。如果完全省略此条目,则资源将从页面树中的父节点继承。如果确实没有资源,请包含此条目但使用空字典 |
| /Contents | 间接引用流或间接引用流数组 | 页面的图形内容。如果缺少此条目,则页面内容为空 |
| /Rotate | 整数 | 浏览页面的顺时针旋转角度,必须是90的倍数,默认值是0 |
| /MediaBox* | 矩形 | 页面的媒体框,也就是纸张大小。如果缺少此条目,则从父节点中继承 |
| /CropBox | 矩形 | 页面的裁剪框。这定义了在显示或打印页面时默认可见的页面区域。如果不存在,则将其值与媒体框相同 |
媒体框和其他方框的矩形数据用一个包含4个数字的数组表示。数组的前两个数字表示矩形的左下角坐标,后两个数字表示右上角坐标,例如:
/MediaBox [0 0 500 800]
/CropBox [100 100 400 700]
定义了一个500x800磅的页面,以及一个在页面每侧裁除100磅的裁剪框。
页面使用页面树而不是一个简单的数组进行链接。这个树形结构使得在一个包含成百上千个页面的文档中查找一个指定的页面变得更快。
下表是页面树的根节点或者中间节点的条目(*表示必需条目):
| 键 | 值类型 | 值 |
|---|---|---|
| /Type* | 名称 | 必须是 /Pages |
| /Kids* | 间接引用数组 | 此节点的直接子节点 |
| /Count* | 整数 | 此节点最终的页节点的数量 |
| /Parent | 树节点的间接引用 | 引用此节点的父节点。 如果不是页面树的根节点,则必须存在 |
下图是一个7页的页面树结构:
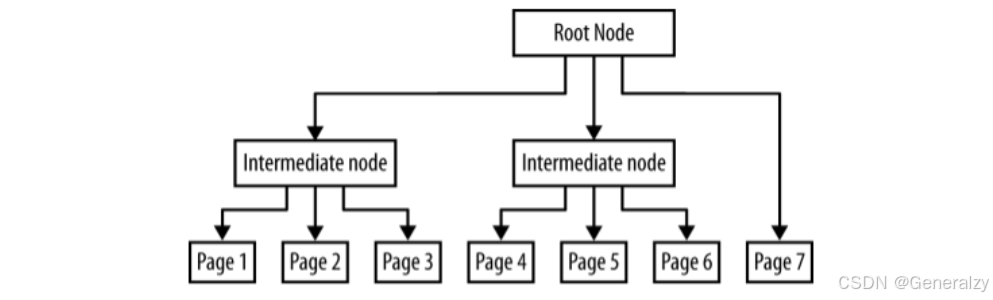
其对应的 PDF 对象如下:
1 0 obj // 根节点
<< /Type /Pages /Kids [2 0 R 3 0 R 4 0 R] /Count 7 >>
endobj
2 0 obj // 中间节点
<< /Type /Pages /Kids [5 0 R 6 0 R 7 0 R] /Parent 1 0 R /Count 3 >>
endobj
3 0 obj // 中间节点
<< /Type /Pages /Kids [8 0 R 9 0 R 10 0 R] /Parent 1 0 R /Count 3 >>
endobj
4 0 obj // 页面 7
<< /Type /Page /Parent 1 0 R /MediaBox [0 0 500 500] /Resources << >> >>
endobj
5 0 obj // 页面 1
<< /Type /Page /Parent 2 0 R /MediaBox [0 0 500 500] /Resources << >> >>
endobj
6 0 obj // 页面 2
<< /Type /Page /Parent 2 0 R /MediaBox [0 0 500 500] /Resources << >> >>
endobj
7 0 obj // 页面 3
<< /Type /Page /Parent 2 0 R /MediaBox [0 0 500 500] /Resources << >> >>
endobj
8 0 obj // 页面 4
<< /Type /Page /Parent 3 0 R /MediaBox [0 0 500 500] /Resources << >> >>
endobj
9 0 obj // 页面 5
<< /Type /Page /Parent 3 0 R /MediaBox [0 0 500 500] /Resources << >> >>
endobj
10 0 obj // 页面 6
<< /Type /Page /Parent 3 0 R /MediaBox [0 0 500 500] /Resources << >> >>
endobj
合在一起
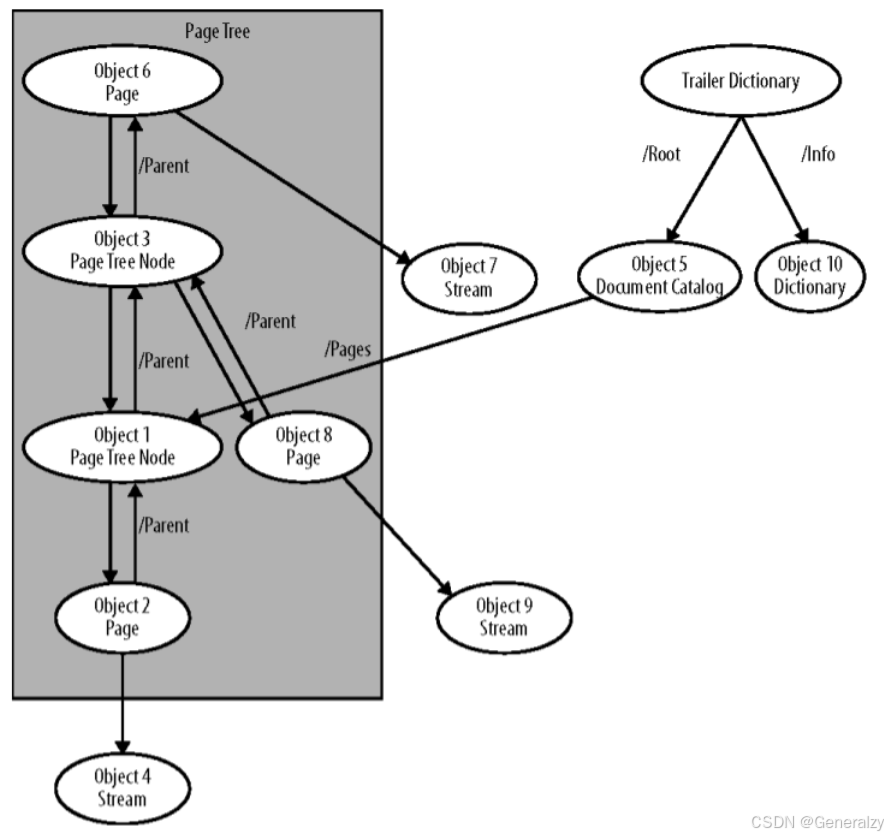
下面的例子是一个手动创建的3页文档,包含文档信息字典和页面树:
%PDF-1.0
1 0 obj // 页面树根节点
<< /Kids [2 0 R 3 0 R] /Type /Pages /Count 3 >>
endobj
4 0 obj // 页面1的内容
<< >>
stream
1. 0.000000 0.000000 1. 50. 770. cm BT /F0 36. Tf (Page One) Tj ET
endstream
endobj
2 0 obj // 页面 1
<<
/Rotate 0
/Parent 1 0 R
/Resources
<< /Font << /F0 << /BaseFont /Times-Italic /Subtype /Type1 /Type /Font >> >> >>
/MediaBox [0.000000 0.000000 595.275590551 841.88976378]
/Type /Page
/Contents [4 0 R]
>>
endobj
5 0 obj // 文档目录
<< /PageLayout /TwoColumnLeft /Pages 1 0 R /Type /Catalog >>
endobj
6 0 obj // 页面 3
<<
/Rotate 0
/Parent 3 0 R
/Resources
<< /Font << /F0 << /BaseFont /Times-Italic /Subtype /Type1 /Type /Font >> >> >>
/MediaBox [0.000000 0.000000 595.275590551 841.88976378]
/Type /Page
/Contents [7 0 R]
>>
endobj
3 0 obj // 中间树节点,指向页面2和3
<< /Parent 1 0 R /Kids [8 0 R 6 0 R] /Count 2 /Type /Pages >>
endobj
8 0 obj // 页面 2
<<
/Rotate 270
/Parent 3 0 R
/Resources
<< /Font << /F0 << /BaseFont /Times-Italic /Subtype /Type1 /Type /Font >> >> >>
/MediaBox [0.000000 0.000000 595.275590551 841.88976378]
/Type /Page
/Contents [9 0 R]
>>
endobj
9 0 obj // 页面2的内容
<< >>
stream
q 1. 0.000000 0.000000 1. 50. 770. cm BT /F0 36. Tf (Page Two) Tj ET Q
1. 0.000000 0.000000 1. 50. 750 cm BT /F0 16 Tf ((Rotated by 270 degrees)) Tj ET
endstream
endobj
7 0 obj // 页面3的内容
<< >>
stream
1. 0.000000 0.000000 1. 50. 770. cm BT /F0 36. Tf (Page Three) Tj ET
endstream
endobj
10 0 obj // 文档信息字典
<<
/Title (PDF Explained Example)
/Author (John Whitington)
/Producer (Manually Created)
/ModDate (D:20110313002346Z)
/CreationDate (D:2011)
>>
endobj
xref
0 11
trailer // trailer 字典
<<
/Info 10 0 R
/Root 5 0 R
/Size 11
/ID [<75ff22189ceac848dfa2afec93deee03> <057928614d9711db835e000d937095a2>]
>>
startxref
0
%%EOF
上面的例子的对象图如下:
实际查看效果如下图:

文本
默认情况下,PDF坐标系的原点位于页面的左下角,x和y分别向右和向上增加。
在页面上打印文本需要:
- 选择字体;
- 选择位置,大小和方向;
- 选择间距,颜色,文本渲染模式和其他参数;
- 从字体中选择字符,并在页面上显示。
- 一段文本包括在 BT(begin text)和 ET(end text)操作符之间。用于在页面的内容流中显示文本的操作符可能- 仅出现在BT和ET之间。 但是,用于改变文本状态的操作符不受这种限制。
例如前面的“Hello, World!”:
1. 0. 0. 1. 50. 700. cm // 文本位置为 (50, 700)
BT // 文本块开始
/F0 36. Tf // 选择 /F0 字体,字号为 36磅
(Hello, World!) Tj // 在当前位置显示字符串
ET // 文本块结束
在这里,我们使用带有字体名称和大小的 Tf 操作符来选择字体,使用 Tj 操作符来显示文本字符串,依靠图形运算符 cm 来定位文本。这些操作符及其说明可以在下表中找到,每个操作符前面都有0个或多个操作数:
| 操作符 | 操作数 | 说明 |
|---|---|---|
| Tf | font, size | 选择对应字号的字体 |
| Tj | string | 在当前位置显示字符串 |
| T* | - | 将文本位置移动到下一行 |
| Tc | charSpace | 设置字符间距 |
| Tw | wordSpace | 设置字间距 |
| TL | leading | 设置前导的文本 |
| ... |
下面的例子中我们使用各种操作符来显示一些文本:
BT
/F0 36 Tf // 选择36磅的 /F0 字体
1 0 0 1 120 350 Tm // 将文本位置设置为(120,350)
50 TL // 将前导设置为50磅
(Character and Word Spacing) Tj T* //显示字符串并移动到下一行
3 Tc // 设置字符间距为3磅
(Character and Word Spacing) Tj T* // 再次绘制字符串
10 Tw // 设置字间距为10磅
(Character and Word Spacing) Tj // 第三次绘制字符串
ET
显示结果如下:

提取方法
考虑到所有上面说的几种不同类型的PDF文件格式,对PDF的布局进行初步分析以确定每个组件所需的适当工具就很重要了。
更具体地说,根据此分析的结果,我们将应用适当的方法从PDF中提取文本,无论是在具有元数据的语料库块中呈现的文本、图像中的文本还是表格中的结构化文本。在没有OCR的扫描文档中,从图像中识别和提取文本将非常繁重。此过程的输出将是一个Python字典(dictionary),其中包含为PDF文件的每个页面提取的信息。该字典(dictionary)中的每个键将表示文档的页码,其对应的值将是一个列表,其中包含以下5个嵌套列表:
- 从语料库中每个文本块提取的文本
- 每个文本块中文本的格式,包括font-family和font-size
- 从页面中的图像上提取的文本
- 以结构化格式从表格中提取的文本
- 页面的完整文本内容

python操作PDF
相关三方库总结
Python中有许多操作PDF文件的库,它们提供了丰富的功能来处理PDF文档,从简单的阅读到复杂的编辑和生成。不同的库有各自的优劣,适合不同的应用场景。以下是一些常用的Python PDF库的详细介绍:
1. PyPDF2
简介:
PyPDF2 是一个流行的开源库,用于操作PDF文件。它支持对PDF文件进行拆分、合并、旋转、加密、解密等基本操作,还可以提取文本、图片和表单数据。
安装:
pip install PyPDF2
使用方法:
from PyPDF2 import PdfFileReader, PdfFileWriter
# PdfFileReader 读取器
# PdfFileWriter 写入器
读取器只能将读取的内容一页一页交给写入器
- 读取PDF文档:
from PyPDF2 import PdfReader
reader = PdfReader("example.pdf")
for page in reader.pages:
print(page.extract_text())
- 合并多个PDF文件:
from PyPDF2 import PdfMerger
merger = PdfMerger()
merger.append("file1.pdf")
merger.append("file2.pdf")
merger.write("merged.pdf")
merger.close()
- 拆分PDF文件:
from PyPDF2 import PdfReader, PdfWriter
reader = PdfReader("input.pdf")
writer = PdfWriter()
# 复制第一页
writer.add_page(reader.pages[0])
with open("output.pdf", "wb") as output_pdf:
writer.write(output_pdf)
- 旋转页面:
from PyPDF2 import PdfReader, PdfWriter
reader = PdfReader("input.pdf")
writer = PdfWriter()
page = reader.pages[0]
page.rotate(90) # 旋转90度
writer.add_page(page)
with open("rotated_output.pdf", "wb") as output_pdf:
writer.write(output_pdf)
- 合并pdf:
from PyPDF2 import PdfFileReader, PdfFileWriter
pdf_writer = PdfFileWriter()
for i in range(1, 6):
pdf_reader = PdfFileReader(f"./pdf{i}.pdf")
for page in range(pdf_reader.getNumPages()):
pdf_writer.addPage(pdf_reader.getPage(page))
# 写入pdf
with open("./merge.pdf", 'wb') as out:
pdf_writer.write(out)
- 拆分pdf:
from PyPDF2 import PdfFileReader, PdfFileWriter
pdf_reader = PdfFileReader("./test.pdf")
for page in range(pdf_reader.getNumPages()):
# 遍历到每一页挨个生成写入器
pdf_writer = PdfFileWriter()
pdf_writer.addPage(pdf_reader.getPage(page))
# 写入器被添加一页后立即输出产生pdf
with open(f"./pdf{page}.pdf", 'wb') as out:
pdf_writer.write(out)
- 加密pdf:
- 将页写入读取器
- pdf_writer.encrypt(密码)
- 写入pdf
- 旋转pdf:
-
page.rotateClockwise(90的倍数):顺时针旋转90度
-
page.rotateCounterClockwise(90的倍数):逆时针旋转90度
from PyPDF2 import PdfFileReader, PdfFileWriter
pdf_reader = PdfFileReader(r"xxx.pdf")
# 新建一个writer
pdf_writer = PdfFileWriter()
for page in range(pdf_reader.getNumPages()):
if page % 2 == 0:
rotation_page = pdf_reader.getPage(page).rotateCounterClockwise(90)
else:
rotation_page = pdf_reader.getPage(page).rotateClockwise(90)
pdf_writer.addPage(rotation_page)
# 结果输出
with open("xxx2.pdf", "wb") as out:
pdf_writer.write(out)
- 倒序pdf:
from PyPDF2 import PdfFileReader, PdfFileWriter
# 打开pdf
pdf_reader = PdfFileReader(r"xxx.pdf")
pdf_writer = PdfFileWriter()
# 倒序遍历range步长为-1即为倒序
for page in range(pdf_reader.getNumPages()-1, -1, -1):
pdf_writer.addPage(pdf_reader.getPage(page))
# 写入结果
with open("xxx2.pdf", "wb") as out:
pdf_writer.write(out)
- 加水印:加水印本质上就是把水印PDF页和需要加水印的页合并
- 准备水印pdf
- 使用自带的copy包复制水印:
from copy import copy
# 读取水印
water_reader = PdfFileReader("./water.pdf")
water = water_reader.getPage(0) # 第一页是水印页
# 读取待加水印的pdf
reader = PdfFileReader("./dst.pdf")
# 新建pdf
writer = PdfFileWriter()
for page in range(reader.getNumPages()):
# 获取每一页
p = reader.getPage(page)
# 必须取水印的副本
tmp = copy(water)
# 合并
newPage = tmp.mergePage(p)
# 放到pdf
writer.addPage(newPage)
# 写入pdf
with open("加了水印.pdf", "wb") as out:
writer.write(out)
- 由于需要加水印的PDF可能有很多页,而水印PDF只有一页,因此如果直接把水印PDF拿来合并,水印PDF页就没有了。
- 因此不能直接拿来合并,而要把水印PDF页不断copy出来成新的一页备用new_page,再运用.mergePage方法完成跟每一页合并,把合并后的页交给写入器待最后统一输出。
- 进行pdf合并的时候,“水印”在下面,文字在上面,因此是“水印”.mergePage(“图片页”)
- pdf添加密码:
from PyPDF2 import PdfFileReader, PdfFileWriter
pdf_reader = PdfFileReader(r"xxx.pdf")
pdf_writer = PdfFileWriter()
# 读取出来写到writer
for page in range(pdf_reader.getNumPages()):
pdf_writer.addPage(pdf_reader.getPage(page))
# 添加密码
pdf_writer.encrypt("123456")
# 保存文件
with open("result.pdf", "wb") as out:
pdf_writer.write(out)
输入密码:
from PyPDF2 import PdfFileReader, PdfFileWriter
pdf_reader = PdfFileReader(r"xxx.pdf")
# 解密pdf
pdf_reader.decrypt("123456")
# writer
pdf_writer = PdfFileWriter()
for page in range(pdf_reader.getNumPages()):
pdf_writer.addPage(pdf_reader.getPage(page))
# 解密好的pdf写出
with open("xxx2.pdf", "wb") as out:
pdf_writer.write(out)
优点:
- 操作简单,适合大部分基本的PDF操作,如拆分、合并、加密等。
- 支持旋转页面、提取文本和元数据。
缺点:
- 处理复杂PDF时的文本提取能力较弱,尤其是带有复杂布局的文档。
- 对于图像和复杂的表单操作支持有限。
适用场景:
- 需要执行基本的PDF操作,如合并、拆分、旋转、加密。
- 不需要处理复杂的布局或进行复杂的内容提取。
2. pdfplumber
简介:
pdfplumber 是一个强大的PDF提取库,专注于精确提取PDF中的内容,特别是复杂的表格、图像和文字。这是一个非常适合处理复杂PDF文档的库。
安装:
pip install pdfplumber
使用方法:
- 提取文本:
import pdfplumber
with pdfplumber.open("example.pdf") as pdf:
for page in pdf.pages:
print(page.extract_text())
- 提取表格:
with pdfplumber.open("example.pdf") as pdf:
first_page = pdf.pages[0]
table = first_page.extract_table()
for row in table:
print(row)
- 提取图片:
with pdfplumber.open("example.pdf") as pdf:
for page in pdf.pages:
for image in page.images:
print(image)
优点:
- 对复杂布局的PDF提取能力非常强,特别是在处理表格和图像时非常高效。
- 支持对内容的精确定位,可以按坐标提取文本和图像。
- 支持读取嵌入的表单数据。
缺点:
- 主要专注于PDF内容的提取,无法进行修改、合并、加密等操作。
- 对某些非常复杂的PDF布局可能提取效果不佳,尤其是包含很多非标准字体和格式的PDF。
适用场景:
- 需要从PDF中提取精确的表格、图片或复杂的文本内容。
- 需要对PDF页面进行分析,例如根据坐标提取特定区域的内容。
3. ReportLab
简介:
ReportLab 是一个强大的Python库,主要用于生成PDF文件。它提供了一个全面的API,用于创建自定义的PDF文档,适合需要动态生成PDF的应用。
安装:
pip install reportlab
使用方法:
- 生成简单的PDF文件:
from reportlab.lib.pagesizes import letter
from reportlab.pdfgen import canvas
c = canvas.Canvas("output.pdf", pagesize=letter)
c.drawString(100, 750, "Hello World!")
c.save()
- 绘制图形:
from reportlab.lib.pagesizes import letter
from reportlab.pdfgen import canvas
c = canvas.Canvas("shapes.pdf", pagesize=letter)
c.drawString(100, 750, "Drawing shapes")
c.line(100, 700, 300, 700) # 画一条直线
c.rect(100, 650, 200, 50) # 画一个矩形
c.save()
- 生成带表格的PDF:
from reportlab.lib import colors
from reportlab.lib.pagesizes import letter
from reportlab.platypus import SimpleDocTemplate, Table, TableStyle
pdf = SimpleDocTemplate("table.pdf", pagesize=letter)
data = [["Column1", "Column2", "Column3"], [1, 2, 3], [4, 5, 6]]
table = Table(data)
style = TableStyle([('BACKGROUND', (0, 0), (-1, 0), colors.grey), ('TEXTCOLOR', (0, 0), (-1, 0), colors.whitesmoke)])
table.setStyle(style)
elements = [table]
pdf.build(elements)
优点:
- 非常适合动态生成复杂的PDF文档,包括文本、图像、图表和表格等内容。
- 提供了非常细粒度的控制,可以完全自定义PDF的布局和内容。
- 支持生成具有多种字体、颜色和图形的高质量PDF。
缺点:
- 生成PDF的API较为复杂,学习曲线较陡,尤其是对于没有排版经验的开发者来说。
- 对现有的PDF文档操作(如修改、提取内容)的支持有限。
适用场景:
- 需要动态生成PDF文件,尤其是在报表、发票生成等应用场景下。
- 需要生成高度自定义的PDF文档。
4. PDFMiner
简介:
PDFMiner 是一个专注于PDF文本提取的库,支持从PDF文件中提取出详细的文本、字体和布局信息,特别适合需要进行复杂文本分析的场景。
安装:
pip install pdfminer.six
使用方法:
- 提取PDF中的文本:
from pdfminer.high_level import extract_text
text = extract_text("example.pdf")
print(text)
- 提取PDF中的详细布局信息:
from pdfminer.high_level import extract_text_to_fp
from io import StringIO
output_string = StringIO()
with open("example.pdf", "rb") as f:
extract_text_to_fp(f, output_string)
print(output_string.getvalue())
优点:
- 支持提取PDF文件中的详细文本布局信息,可以获取字体、大小、位置等。
- 提供了对复杂文本和表格的高精度提取,适合做PDF的自然语言处理(NLP)任务。
- 支持处理加密的PDF文件。
缺点:
- 对于新手来说,API的使用较为复杂,尤其是需要理解PDF的内部结构。
- 提取图像和图形支持较弱。
适用场景:
- 需要从PDF中提取复杂的文本信息,尤其是涉及文本分析或自然语言处理的任务。
- 需要精确获取PDF文件中的字体、段落和布局信息。
5. PyMuPDF (fitz)
简介:
PyMuPDF(也称为fitz)是一个快速的PDF处理库,支持PDF的读取、文本提取、注释、绘图和页面操作。它提供了丰富的PDF操作功能,并且性能较为优异。
安装:
pip install pymupdf
使用方法:
- 提取PDF中的文本:
import fitz
doc = fitz.open("example.pdf")
for page in doc:
print(page.get_text())
- 添加注释:
import fitz
doc = fitz.open("example.pdf")
page = doc[0]
annot = page.add_highlight_annot(page.search_for("text")[0])
annot.update()
doc.save("annotated_output.pdf")
优点:
- 提供快速且高效的PDF处理能力,尤其适合处理大量PDF文件。
- 支持文本提取、注释、修改页面和绘图等操作。
- 兼具处理图像和图形的功能。
**
缺点:**
- API较为复杂,尤其是对新手来说理解其完整功能可能需要一定时间。
- 对某些特殊格式的PDF可能支持不佳。
适用场景:
- 需要对PDF文件进行批量操作,特别是在需要高性能的应用场景下。
- 需要执行复杂的PDF注释和绘图操作。
6. pdfrw
简介:pdfrw 是一个轻量级的 Python 库,用于读取和写入 PDF 文件。它支持 PDF 文件的合并、旋转、裁剪等基本操作,此外,它还能生成新的 PDF 文件,并与 ReportLab 兼容,允许将现有的 PDF 文件与生成的文档结合起来。
安装:
pip install pdfrw
使用方法:
- 读取和修改 PDF 文件:
from pdfrw import PdfReader, PdfWriter
# 读取 PDF 文件
reader = PdfReader("example.pdf")
# 获取第一页
first_page = reader.pages[0]
# 进行修改,假设要旋转90度
first_page.Rotate = (int(first_page.inheritable.Rotate or 0) + 90) % 360
# 写入新的文件
writer = PdfWriter()
writer.addpage(first_page)
writer.write("rotated_output.pdf")
- 合并多个 PDF 文件:
from pdfrw import PdfReader, PdfWriter
writer = PdfWriter()
# 逐个添加 PDF 文件
for pdf_file in ["file1.pdf", "file2.pdf"]:
reader = PdfReader(pdf_file)
writer.addpages(reader.pages)
# 写入输出
writer.write("merged_output.pdf")
- 与 ReportLab 结合使用:
pdfrw可以与ReportLab一起使用,用于将现有的 PDF 文档嵌入到动态生成的文档中。通过将pdfrw提供的 PDF 页面作为ReportLab的画布对象,可以将新生成的内容合并到已有的 PDF 文档中。
优点:
- 体积小、依赖少,适合只需要进行简单 PDF 操作的场景。
- 与 ReportLab 兼容,能够组合已有 PDF 和动态生成的内容。
- 提供了对 PDF 的简单修改、合并、旋转等基本功能。
缺点:
- 功能较为基础,无法处理复杂的 PDF 内容提取,如文本或表格提取。
- 在处理复杂 PDF 文档时可能不够灵活。
适用场景:
- 需要进行简单的 PDF 操作,如合并、拆分、旋转页面。
- 希望与 ReportLab 一起使用,生成并修改 PDF 文件。
7. pdfquery
简介:pdfquery 是基于 lxml 和 pyquery 的工具,主要用于从 PDF 文件中提取特定的元素和数据。它适合需要处理结构化数据提取的应用,特别是在需要从表格或表单中提取数据时效果很好。
安装:
pip install pdfquery
使用方法:
- 从 PDF 文件中提取特定文本:
import pdfquery
pdf = pdfquery.PDFQuery("example.pdf")
pdf.load(0)
# 通过坐标选择特定区域的文本
label = pdf.pq('LTTextLineHorizontal:contains("Text to extract")')
print(label.text())
- 提取表单字段:
pdf = pdfquery.PDFQuery("example.pdf")
pdf.load(0)
# 提取 PDF 中的表单数据
fields = pdf.pq('LTTextLineHorizontal:contains("Field Name")')
for field in fields:
print(field.text)
优点:
- 提供对 PDF 结构的深入控制,支持使用类似 CSS 选择器的方式来提取内容。
- 适合从复杂 PDF 布局中提取结构化数据,特别是表格和表单数据。
- 可以根据位置坐标精确定位和提取内容。
缺点:
- 针对特定任务的专用工具,不适合大多数普通 PDF 操作(如合并、旋转等)。
- API 使用较为复杂,尤其是对于初学者,定位内容可能需要较高的技术门槛。
适用场景:
- 需要从结构化 PDF 文档(如表单、报表)中提取精确的数据。
- 适合复杂的文本分析和数据提取场景,尤其是在表格或特定格式化内容中。
8. slate3k
简介:slate3k 是一个轻量级的 PDF 文本提取工具,它基于 pdfminer,旨在提供一个更简单的接口用于提取 PDF 文本。
安装:
pip install slate3k
使用方法:
- 提取 PDF 文本:
import slate3k
with open("example.pdf", "rb") as f:
extracted_text = slate3k.PDF(f)
print(extracted_text.text())
优点:
- 提供简单的 API,方便快速提取 PDF 文件中的文本。
- 基于
pdfminer,具备较强的文本提取能力。
缺点:
- 功能单一,仅支持文本提取,不能处理其他复杂的 PDF 操作。
- 对带有复杂布局的 PDF 文档(如包含图片或表格)可能效果不佳。
适用场景:
- 仅需要简单、快速地提取 PDF 文本的场景。
- 不需要处理其他复杂的 PDF 操作。
对比总结
| 库名称 | 功能 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|---|
| PyPDF2 | 拆分、合并、加密、解密 | 操作简单,支持基本的 PDF 操作 | 文本提取和复杂文档支持有限 | 基本 PDF 操作,如合并、拆分、加密、旋转等 |
| pdfplumber | 精确提取 PDF 内容 | 对复杂布局的 PDF 提取效果好,尤其适合表格和图像提取 | 不能修改 PDF 文件 | 需要从复杂 PDF 文档中提取表格、图像或特定内容 |
| ReportLab | 生成 PDF | 动态生成复杂 PDF 文档,支持高度自定义的布局和图形绘制 | 主要用于生成 PDF,修改现有 PDF 的能力有限 | 动态生成发票、报告或复杂 PDF 文档 |
| PDFMiner | 文本和布局提取 | 对文本、字体、段落和布局的精确提取,适合复杂文本分析 | API 使用复杂,图像和图形支持较弱 | 需要从 PDF 中提取复杂文本和详细的布局信息 |
| PyMuPDF (fitz) | 快速 PDF 处理 | 性能高效,支持文本提取、注释、修改页面和绘图等操作 | API 较为复杂,某些特殊 PDF 格式支持有限 | 需要批量处理 PDF 或执行复杂的注释和绘图操作 |
| pdfrw | 合并、旋转、裁剪 | 轻量级,依赖少,适合简单 PDF 操作,能与 ReportLab 结合使用 | 功能基础,无法处理复杂内容提取 | 与 ReportLab 结合生成和修改 PDF,或进行简单操作 |
| pdfquery | 结构化内容提取 | 能从 PDF 中精准提取结构化内容,支持复杂的数据定位 | 针对特定任务设计,不适合普通的 PDF 操作 | 需要从复杂 PDF 中提取结构化数据,如表单、报表等 |
| slate3k | 文本提取 | API 简单,适合快速文本提取 | 功能单一,处理复杂布局的效果较差 | 仅需要快速提取 PDF 文本的简单场景 |
-
如果你需要进行基本的 PDF 操作(如拆分、合并、加密、旋转等),
PyPDF2是一个很好的选择,因其 API 简单且功能全面,能够满足大部分日常需求。 -
如果你的需求是从复杂的 PDF 文档中提取内容(特别是表格或图片),
pdfplumber是最为适合的库。它提供了强大的提取功能,特别是针对复杂布局的 PDF 文档。 -
如果你需要生成动态 PDF 文档,
ReportLab是业界标准,它能让你完全控制 PDF 的生成,包括文本、图表、图像和表格的排版。 -
如果你需要进行高级的文本提取,特别是需要对 PDF 的字体、布局和段落进行分析,那么
PDFMiner会是一个理想的选择。 -
如果你需要一个快速且高效的 PDF 处理库,
PyMuPDF(fitz)的性能和多功能性使它非常适合需要高效处理 PDF 的应用场景。
根据具体的需求,选择合适的库能极大提高工作效率。在实际应用中,可能还需要结合多个库来处理复杂的 PDF 操作,例如使用 pdfplumber 提取表格数据,再用 PyPDF2 或 pdfrw 合并页面或进行加密操作。此外,还可以用 ReportLab 动态生成新的 PDF 内容,并将其插入到已有的 PDF 文档中。
示例:结合多个库处理 PDF:
假设你需要从一个 PDF 中提取表格数据,并生成一份新的报告,结合多个库可以实现如下操作:
- 使用
pdfplumber提取表格数据。 - 使用
ReportLab生成新的报告,包含提取的表格和其他动态内容。 - 使用
PyPDF2将生成的报告合并到原始 PDF 中。
import pdfplumber
from reportlab.lib.pagesizes import letter
from reportlab.pdfgen import canvas
from PyPDF2 import PdfWriter, PdfReader
# Step 1: 提取 PDF 表格
with pdfplumber.open("source.pdf") as pdf:
page = pdf.pages[0]
table = page.extract_table()
print("Extracted Table:", table)
# Step 2: 使用 ReportLab 生成新的 PDF 报告
report_file = "report.pdf"
c = canvas.Canvas(report_file, pagesize=letter)
c.drawString(100, 750, "Generated Report")
c.drawString(100, 700, "Extracted Table:")
# 假设简单打印表格内容
for i, row in enumerate(table):
c.drawString(100, 700 - (i + 1) * 20, str(row))
c.save()
# Step 3: 使用 PyPDF2 合并 PDF
output = PdfWriter()
source_pdf = PdfReader("source.pdf")
report_pdf = PdfReader(report_file)
# 添加原始 PDF 的所有页面
for page_num in range(len(source_pdf.pages)):
output.add_page(source_pdf.pages[page_num])
# 添加生成的报告页面
output.add_page(report_pdf.pages[0])
# 保存合并后的文件
with open("final_output.pdf", "wb") as f:
output.write(f)
通过这种方式,你可以灵活地组合多个 Python 库,以满足复杂的 PDF 处理需求。
库的选择总结:
PyPDF2适合用于日常的 PDF 操作,如合并、拆分、加密等。pdfplumber非常适合从 PDF 中提取结构化数据,特别是复杂表格或多列布局。ReportLab适合动态生成 PDF 内容,可以创建具有高度自定义布局的文档。PyMuPDF (fitz)提供高性能的 PDF 操作,适合大规模、复杂的 PDF 处理任务。pdfrw是轻量级的选择,适合与ReportLab一起使用来生成和修改 PDF。pdfquery适合需要从 PDF 中精准提取特定元素的场景,特别是表单或结构化数据提取。
通过结合这些库,可以实现从简单的文本提取到复杂的 PDF 操作,如动态生成、表单处理、数据提取等,提高了处理 PDF 文档的灵活性和效率。
Google Tesseract OCR
Tesseract是一个开源文本识别 (OCR)引擎,是目前公认最优秀、最精确的开源OCR系统,用于识别图片中的文字并将其转换为可编辑的文本。
Tesseract能够将印刷体文字图像转换成可编辑文本,它支持多种语言,并且在许多平台上都可使用,包括Windows、Mac OS和Linux。Tesseract可以处理各种图像文件格式,如JPEG、PNG、TIFF等。
Tesseract的主要功能是识别图像中的文字,并将其转换成机器可读的文本内容。它采用了一系列图像处理、特征提取和机器学习技术来实现文字识别的过程。Tesseract算法的基础是使用训练好的模型来识别字符,并通过上下文和语言模型来提高识别准确性。
其他常见的OCR识别平台:
微软Azure图像识别:https://azure.microsoft.com/zh-cn/services/cognitive-services/computer-vision
有道智云文字识别:https://ai.youdao.com
阿里云图文识别:https://www.aliyun.com/product/cdi
腾讯OCR文字识别:https://cloud.tencent.com/product/ocr
安装地址:https://tesseract-ocr.github.io/tessdoc/Installation.html
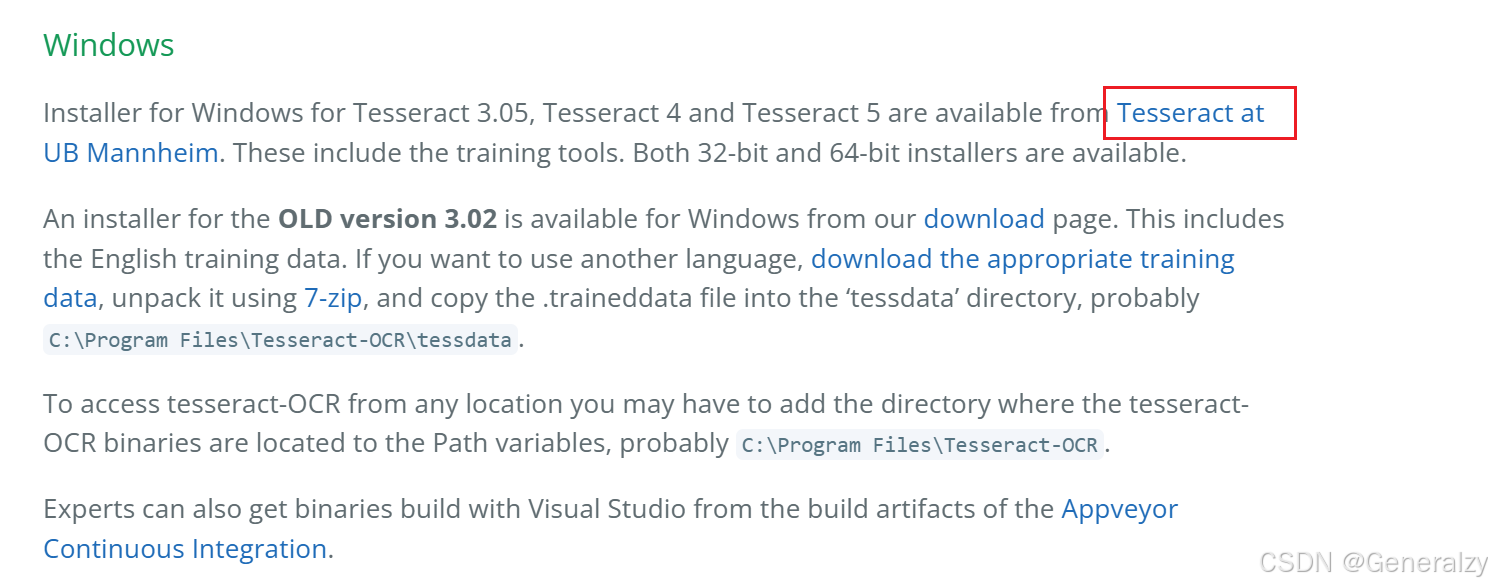
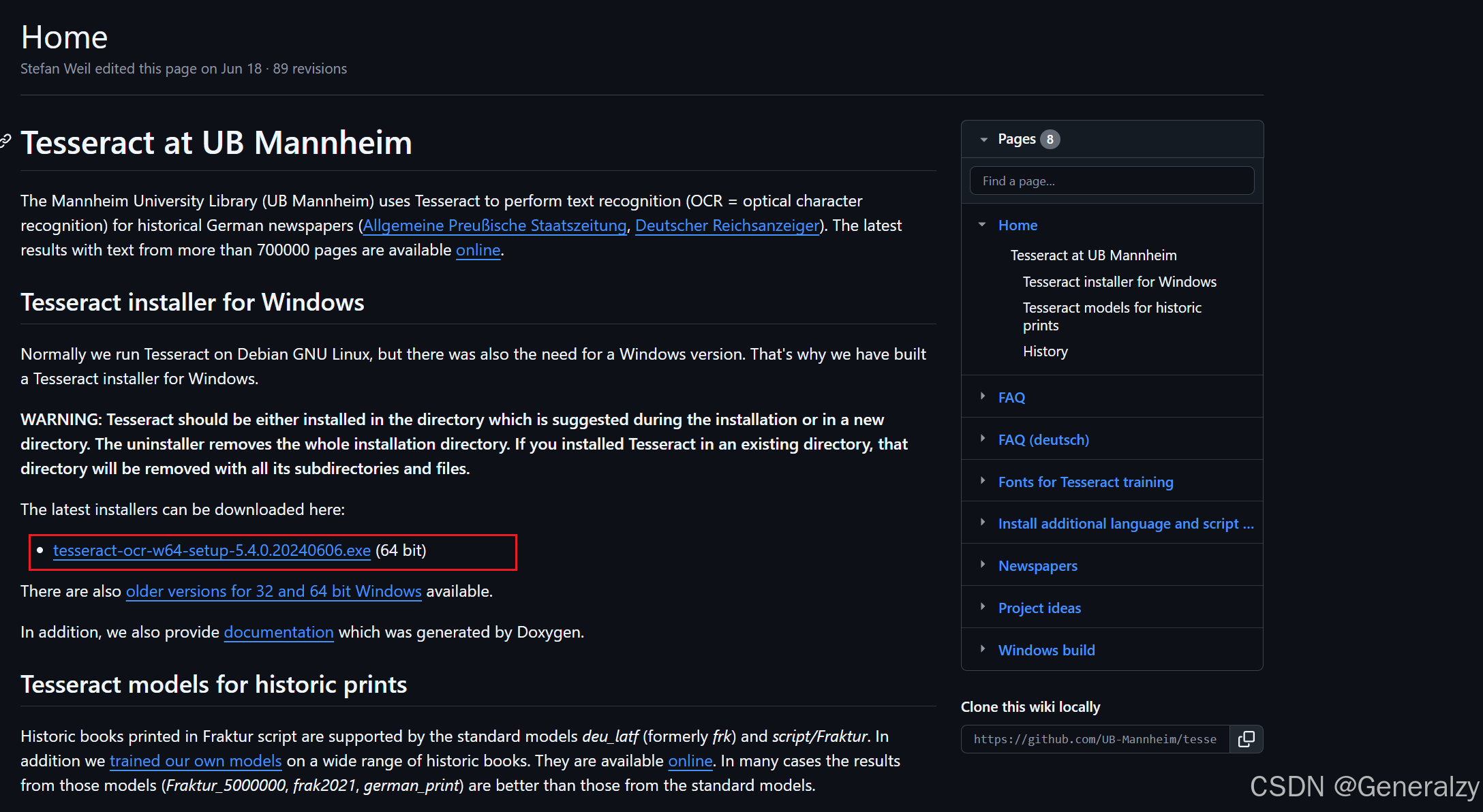
安装软件后需要将其加入环境变量:
打开命令行窗口,输入tesseract -v命令进行验证:

然后就可以安装Python库了:
pip install pytesseract
显示当前训练语言列表
使用命令tesseract --list-langs查看当前支持的语言:

如果没有简体中文,那么就需要配置语言字体库:
在安装目录下,默认有个 tessdata目录,该目录中存放的是语言字库文件:
访问:https://github.com/tesseract-ocr/tessdata项目,下载需要的语言字库文件,例如中文字库:chi_sim.traineddata下载后放到该目录即可。
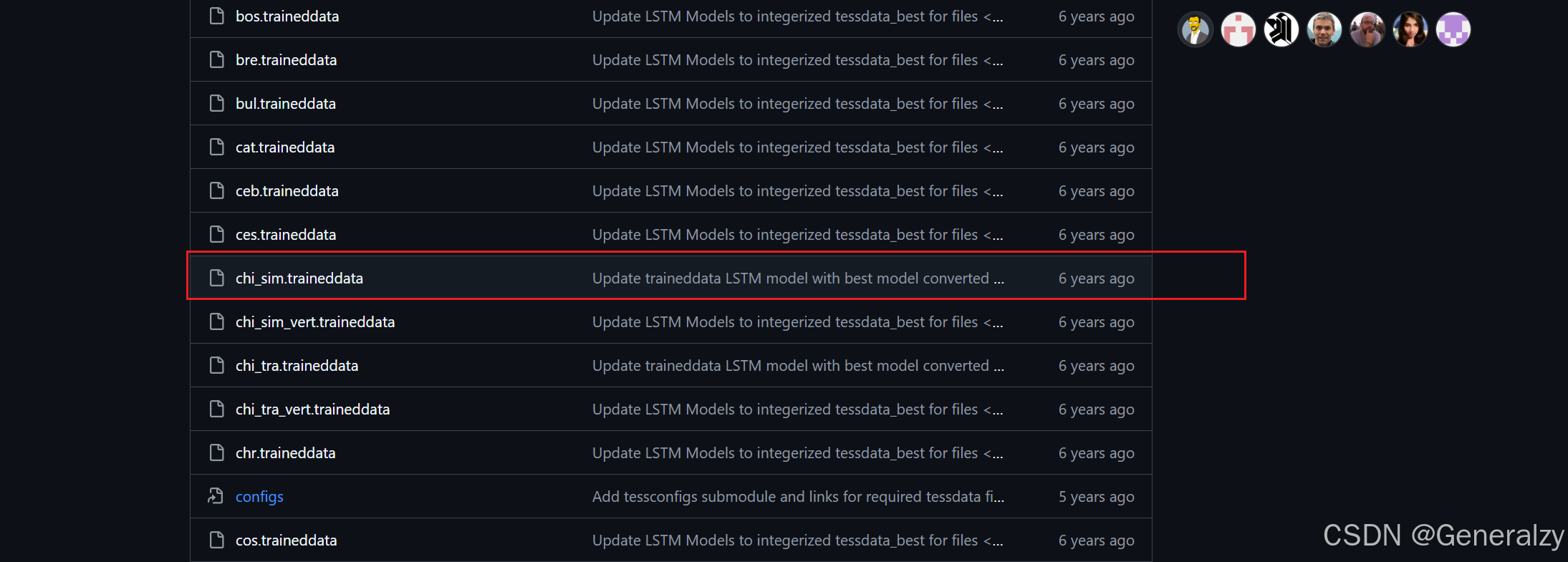
再次查看支持的语言,可以看到多了一个简体中文(vert是竖排列的中文字符训练集):
使用CMD测试验证下模型效果,
tesseract imagename outputbase [-l lang] [--psm pagesegmode]
参数解释:
-l eng:代表使用英语识别
-psm 7:表示用单行文本识别
pagesegmode可选值:
0 =定向和脚本检测(OSD)
1 =带OSD的自动页面分割
2 =自动页面分割,但没有OSD或OCR
3 =全自动页面分割,但没有OSD(默认)
4 =假设一列可变大小的文本
5 =假设一个统一的垂直对齐文本块
6 =假设一个统一的文本块
7 =将图像作为单个文本行处理
8 =把图像当作一个单词
9 =把图像当作一个圆圈中的一个词来对待
10 =将图像作为单个字符处理
tesseract.exe ./g.png ./out.txt -l eng --psm 7
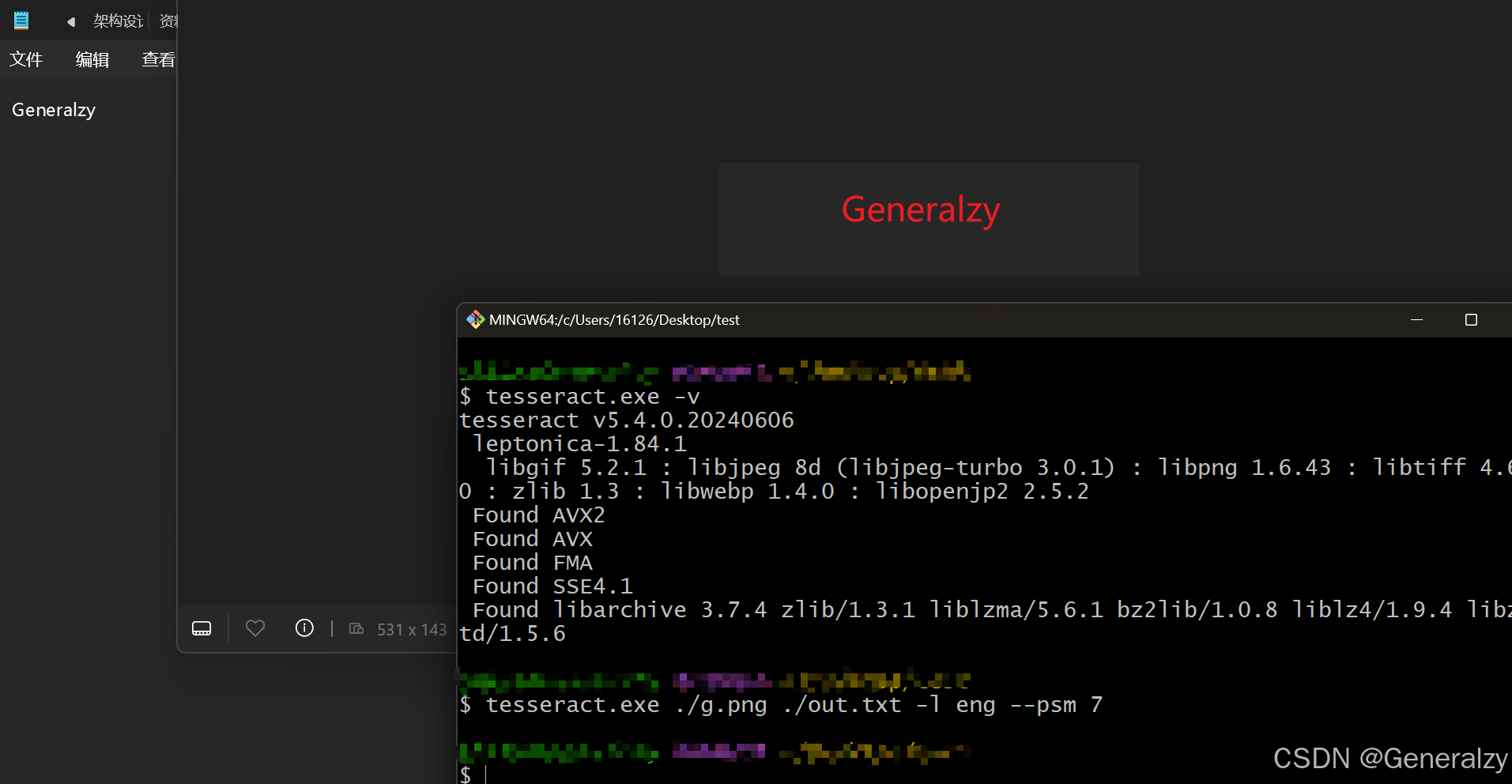
再来测试下代码执行效果:
# PIL用于打开图片文件
pip/pip3 install pillow
# pytesseract模块用于从图片中解析数据
pip/pip3 install pytesseract
# 导入模块
import pytesseract
# 导入图片库
from PIL import Image
# 创建图片对象,使用pillow库加载图片
image = Image.open("./g.png")
# 识别图片
text = pytesseract.image_to_string(image, config="--psm 7")
print(text)
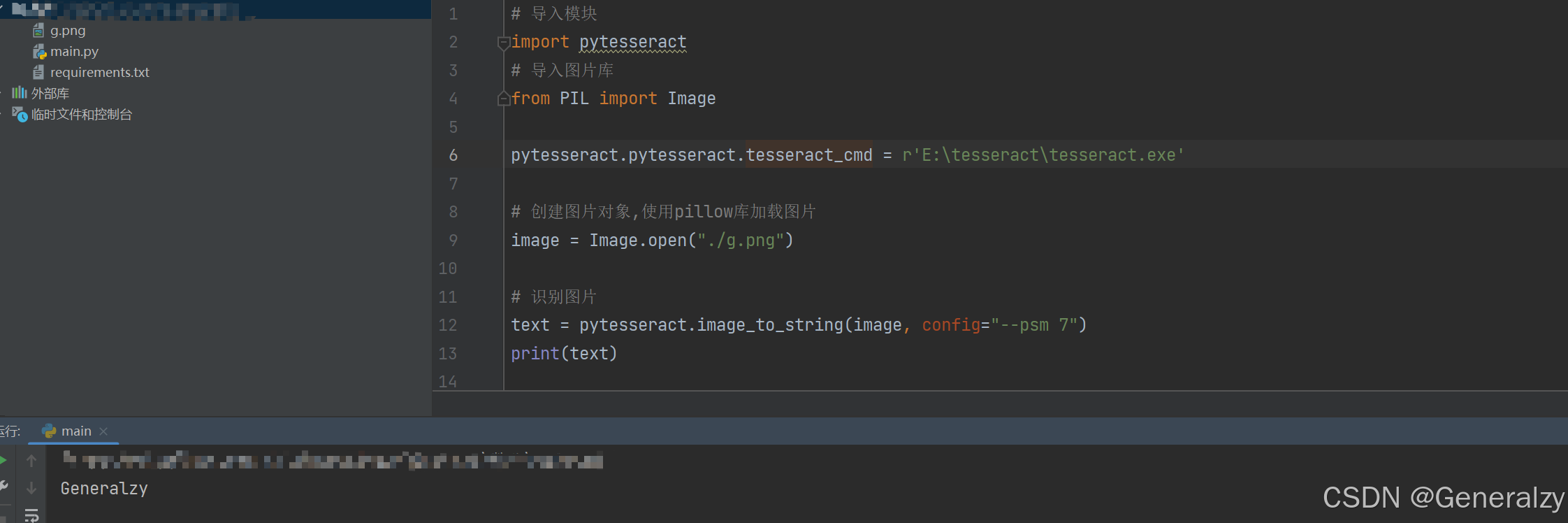
可能会出现如下异常:
pytesseract.pytesseract.TesseractNotFoundError: tesseract is not installed or it's not in your PATH. See README file for more information.
看描述,是因为找不到tesseract,给出两个解决方案(根本上是一个解决方案):
-
方案1:指定绝对路径
# 指定tesseract目录,该目录是安装tesseract-OCR的目录: pytesseract.pytesseract.tesseract_cmd = r'E:\tesseract\tesseract.exe' -
方案2:在pytesseract库下的pytesseract.py文件中找到tesseract_cmd = ‘tesseract’,修改成方案1的绝对路径。
最后执行python代码,成功!!!
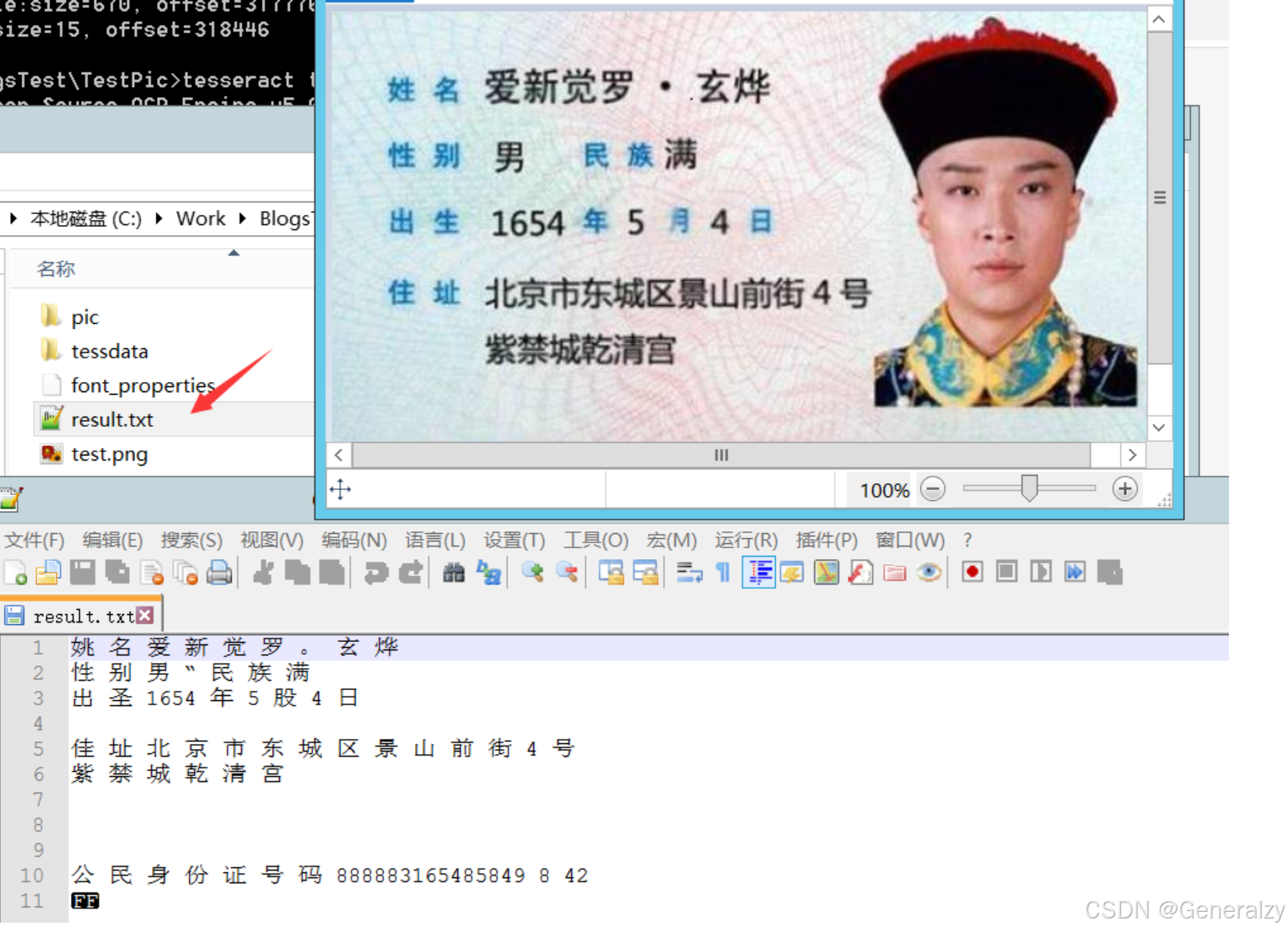
更换语言字体库识别:
text = pytesseract.image_to_string(image, lang='chi_sim', config="--psm 7")
改进图片识别准确度
由于tesseract的训练集数据4.0版本都已经是2017年的了,因此对于非英文字符,尤其是汉字的识别较为不准确:
对于这个问题,有两个方向:
- 寻找新的训练集
- 自己训练生成训练集
鉴于自己训练的难度较大,并且费时费力,因此我直接去github寻找第三方的训练集(https://github.com/gumblex/tessdata_chi/releases):
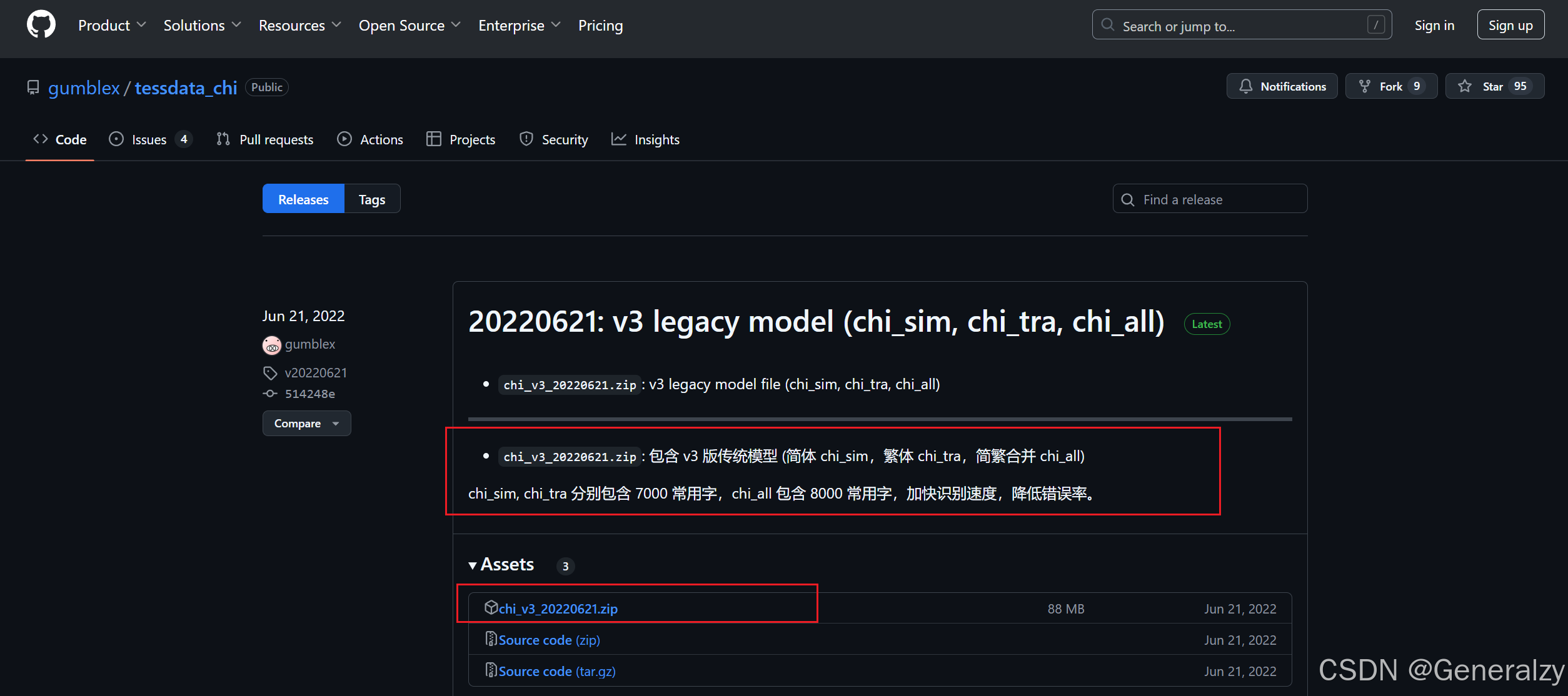
下载下来替换官方的训练集即可,但经过本人测试,基本识别的中文全部乱码。
对于自己训练数据的方法,后续可能会补充,目前我们有更好的办法。
对比GOT-OCR2_0

从papper.cool(写了个刷论文的辅助网站:Cool Papers)可以看到GOT-OCR模型是非常新的一个模型,
这篇论文提出了一个名为GOT的OCR-2.0模型,旨在解决传统OCR系统(OCR-1.0)在处理人造光学字符时遇到的挑战。随着对智能处理需求的增长,传统OCR系统越来越难以满足人们的需求。论文中提到的主要问题包括:
-
多模块化流程的局限性:传统OCR系统通常基于多模块化流水线设计,包括元素检测、区域裁剪和字符识别等部分。这种设计容易陷入局部最优,导致整个系统维护成本高。
-
泛化能力不足:不同的OCR-1.0网络通常针对不同的子任务设计,缺乏足够的泛化能力,给用户在选择适合特定任务的模型时带来不便。
-
与大型视觉语言模型(LVLMs)的冲突:LVLMs虽然在视觉推理性能上表现出色,但它们主要关注视觉推理任务,这与纯感知OCR任务(尤其是高密度文本场景)的需求不符。此外,LVLMs通常拥有数十亿参数,导致训练和部署成本过高。
为了解决这些问题,论文提出了通用OCR理论(OCR-2.0),并介绍了GOT模型,该模型具有以下特点:
-
端到端架构:简化了OCR-1.0模型的复杂流程,降低了维护成本。
-
低成本训练和推理:与专注于推理任务的LVLMs不同,GOT专注于光学字符的强大感知和识别能力,因此需要更合理的模型参数数量,以降低训练和推理成本。
-
多功能性:GOT模型能够识别更广泛的人造光学“字符”,如乐谱、图表、几何形状等,并支持具有更强可读性的输出格式,例如用于公式和表格的LATEX/Markdown格式。
总的来说,论文的目标是通过提出通用OCR理论和GOT模型,推动OCR技术的发展,使其能够更好地满足人们对光学字符智能处理的需求。
全面解析PDF
铺垫了这么久,终于进入了我们的重头戏,PDF解析!
现在导入所有需要用到的包:
# 读取PDF
import PyPDF2
# 分析PDF的layout,提取文本
from pdfminer.high_level import extract_pages, extract_text
from pdfminer.layout import LTTextContainer, LTChar, LTRect, LTFigure
# 从PDF的表格中提取文本
import pdfplumber
# 从PDF中提取图片
from PIL import Image
// pip install pdf2image
from pdf2image import convert_from_path
# 运行OCR从图片中提取文本
import pytesseract
# 清除过程中的各种过程文件
import os
pdf2image 依赖于 poppler,这是一个用于 PDF 渲染的第三方工具库。Windows下载 Poppler 二进制文件:
- 访问 Poppler for Windows 并下载最新的 poppler-xx.x.x.zip 文件。
- 解压该文件,将解压后的文件夹路径(如 C:\path\to\poppler-xx.x.x\poppler-xx\bin)添加到系统的环境变量中。
Linux在终端中运行以下命令安装 poppler:
sudo apt install poppler-utils
安装完成并且添加到环境变量后,使用pdfinfo -v验证安装:

文档的布局(Layout)分析

对于初步分析,使用PDFMiner的Python库将文档对象中的文本分离为多个页面对象,然后分解并检查每个页面的布局。
PDFMiner使用高级函数extract_pages()从PDF文件中分离各个页面,并将它们转换为LTPage对象。然后,对于每个LTPage对象,它从上到下遍历每个元素,并尝试将适当的组件识别为:
- LTFigure:表示PDF中页面上的图形或图像的区域。
- LTTextContainer:代表一个矩形区域(段落)中的一组文本行(line),然后进一步分析成LTTextLine对象的列表。它们中的每一个都表示一个LTChar对象列表,这些对象存储文本的单个字符及其元数据。
- LTRect表示一个二维矩形,可用于在LTPage对象中占位区或者Panel,图形或创建表。
因此,使用Python对页面进行重构之后,将页面元素分类为LTFigure(图像或图形)、LTTextContainer(文本信息)或LTRect(表格),我们就可以选择适当的函数来更好地提取内容信息了。
for pagenum, page in enumerate(extract_pages(pdf_path)):
# Iterate the elements that composed a page
for element in page:
# Check if the element is a text element
if isinstance(element, LTTextContainer):
# Function to extract text from the text block
pass
# Function to extract text format
pass
# Check the elements for images
if isinstance(element, LTFigure):
# Function to convert PDF to Image
pass
# Function to extract text with OCR
pass
# Check the elements for tables
if isinstance(element, LTRect):
# Function to extract table
pass
# Function to convert table content into a string
pass
引入hugging face大模型
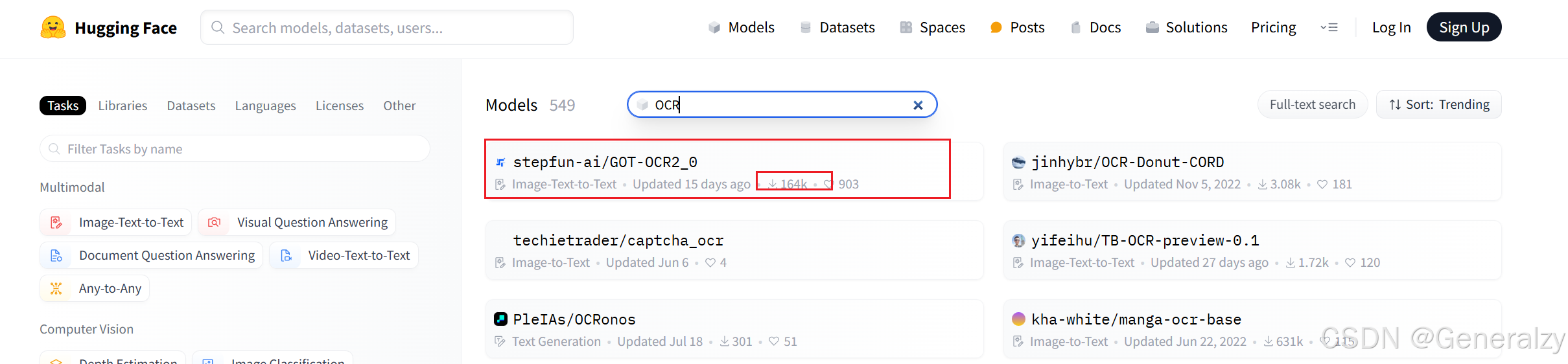
在hugging face首页所搜OCR,下载次数最多的排行第一的就是stepfun-ai/GOT-OCR2_0这个模型:
点击进入model card,下载依赖库和模型:

然后执行给出的样例代码:
from transformers import AutoModel, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained('F:\\Model\\GOT-OCR2_0', trust_remote_code=True)
model = AutoModel.from_pretrained('F:\\Model\\GOT-OCR2_0', trust_remote_code=True, low_cpu_mem_usage=True, device_map='cuda', use_safetensors=True, pad_token_id=tokenizer.eos_token_id)
model = model.eval().cuda()
# input your test image
image_file = '1.jpg'
# plain texts OCR
res = model.chat(tokenizer, image_file, ocr_type='ocr')
# format texts OCR:
# res = model.chat(tokenizer, image_file, ocr_type='format')
# fine-grained OCR:
# res = model.chat(tokenizer, image_file, ocr_type='ocr', ocr_box='')
# res = model.chat(tokenizer, image_file, ocr_type='format', ocr_box='')
# res = model.chat(tokenizer, image_file, ocr_type='ocr', ocr_color='')
# res = model.chat(tokenizer, image_file, ocr_type='format', ocr_color='')
# multi-crop OCR:
# res = model.chat_crop(tokenizer, image_file, ocr_type='ocr')
# res = model.chat_crop(tokenizer, image_file, ocr_type='format')
# render the formatted OCR results:
# res = model.chat(tokenizer, image_file, ocr_type='format', render=True, save_render_file = './demo.html')
print(res)

可以看出识别效果比谷歌的OCR强很多,但有几个警告也需要我们解决一下。
告警处理
报错:UserWarning: 1Torch was not compiled with flash attention.
这个报错的意思是,你运行的 PyTorch 模型尝试调用了 flash attention 功能,但 PyTorch 并没有在你的系统中编译支持该功能。flash attention 是一种优化,可以加速自注意力机制的计算,但需要特定的编译选项和支持的硬件(如高级 GPU 和相应的 CUDA 版本)。
首先运行,nvidia-smi 命令确认当前的 CUDA 版本,以及你的 GPU 是否支持 flash attention。
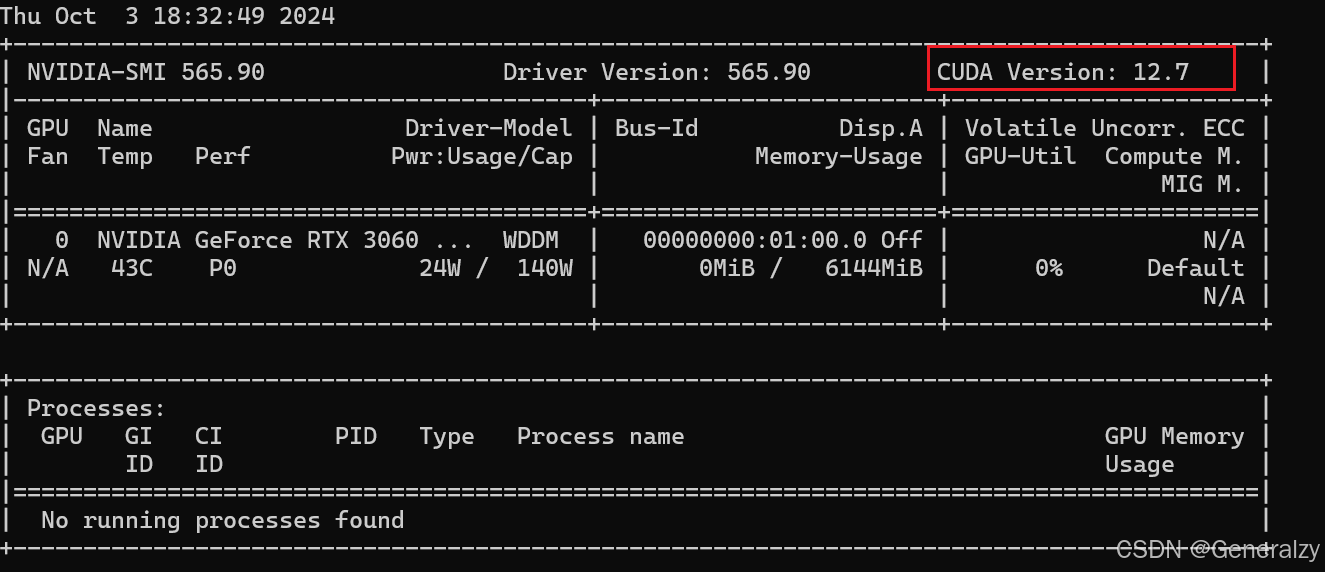
然后,可以检查当前的 PyTorch 是否编译了支持 flash attention 的版本。通过以下代码确认:
import torch
torch.backends.cuda.flash_sdp_enabled() # Returns True if flash attention is enabled
如果返回 False,说明当前 PyTorch 版本不支持 flash attention。
即便你的 GPU 支持 flash attention,也需要确保你的 CUDA 版本和 NVIDIA 驱动正确配置。确保:
- 安装了符合你 GPU 支持的 CUDA 版本。
- PyTorch 安装时编译了与当前 CUDA 版本兼容的库。
如果你实在需要使用 flash attention,可以尝试安装一个支持的 PyTorch 版本。例如:
set USE_FLASH_ATTENTION=1
pip uninstall torch
pip install torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cu124
pip install build
pip install cmake
pip install ninja
pip install wheel
pip install flash-attn --no-build-isolation
如果 flash attention 并非关键需求,你可以回退pytorch版本来绕过此问题(官网默认下载的是最新的):
pip install torch2.1.2 torchvision0.16.2 torchaudio==2.1.2 --index-url https://download.pytorch.org/whl/cu121
如果实在不行做额外操作,你也可以选择忽略掉他,毕竟他只是个Warning而不是Error。
报错:The attention mask and the pad token id were not set. As a consequence, you may observe unexpected behavior. Please pass your input’s attention_mask to obtain reliable results.Setting pad_token_id to eos_token_id:151643 for open-end generation.
这个错误是 Hugging Face 模型在进行推理或生成任务时自动提示的。它提醒你没有提供注意力掩码 (attention_mask) 和填充符号 ID (pad_token_id),这可能会导致生成结果的不一致或意外行为。具体原因如下:
-
未设置 attention_mask:
- attention_mask 用来区分有效的输入标记和填充的部分。模型需要知道哪些是实际的输入数据,哪些只是填充物(填充符通常用来确保每个输入有相同的长度)。如果没有提供 attention_mask,模型可能无法正确地忽略填充部分,从而导致不可靠的输出。
-
pad_token_id 自动设置为 eos_token_id:
- 报错信息表明,模型正在使用 eos_token_id(结束标记 ID)作为 pad_token_id(填充符号 ID)。通常,填充符号和结束符号是不同的,但 Hugging Face 的一些模型在开放式生成任务中(例如文本生成)会将它们设置为相同值。这种设置有时会在生成过程中出现不理想的结果。
AutoTokenizer 是 Hugging Face 提供的一个通用接口,用于自动加载适用于你所用模型的 tokenizer。根据模型的配置,AutoTokenizer 会自动选择合适的 Tokenizer 类,生成可用于预处理文本的 tokenizer 对象。它的主要作用包括:
- 将文本转换为模型可接受的输入格式(如 input_ids)。
- 管理特殊标记符(如 eos_token, pad_token, bos_token 等)。
- 支持多种编码方式(如 BPE、WordPiece 等),并简化了预处理过程。
可以尝试将 pad_token_id 设置为 eos_token_id,但如果 eos_token_id 为 None,这个设置会失败。如果确实需要为模型设置 pad_token_id,可以考虑直接将其设置为模型中定义的 pad_token,例如:
model.config.pad_token_id = tokenizer.pad_token_id or tokenizer.eos_token_id
或者,手动设置 pad_token:
tokenizer.pad_token = '<PAD>'
tokenizer.pad_token_id = tokenizer.convert_tokens_to_ids(tokenizer.pad_token)
tokenizer.eos_token_id 为 None 的原因:
- 你加载的 tokenizer 对象(通过 AutoTokenizer.from_pretrained)没有定义 eos_token(结束符号)。
- 该模型的 tokenizer 配置文件(如 config.json 或 tokenizer_config.json)没有包含 eos_token_id。某些模型可能不需要 eos_token,或者这些符号在特定任务中不被定义。
报错:no module named _verovio
stepfun-ai/GOT-OCR2_0对音乐字符的识别需要用到一个基于C的三方库:verovio,verovio会使用python dll文件来提速(pyd,linux是.so)。
在一些python环境下verovio不能成功的导入_verovio文件,即pyd文件,就会抛出该错误。我曾经在python3.11环境下遇到过该错误,后期将python3.11升级为python3.12,该问题就没有再复现。
定义从PDF中提取文本的函数
从pdf提取文本,刚好langchain封装了很多loader,可以先试试langchain的提取效果,快速安装langchain:
pip install langchain
pip install langchain_community
然后导入loader,
from langchain_community.document_loaders import PDFPlumberLoader, PDFMinerLoader
def parse(pdf_path):
loader = PDFPlumberLoader(pdf_path)
pages = loader.load()
for page in pages:
print(page.page_content)
print(pages[0].page_content)
经过一番测试,langchain只会提取简单页面文档,并没有细化到pdf元素的类型,因此我们使用PDFMiner的Python库将文档对象中的文本分离为多个页面对象,然后分解并检查每个页面的布局,PDFMiner使用高级函数extract_pages()从PDF文件中分离各个页面,并将它们转换为LTPage对象。
对于每个LTPage对象,它从上到下遍历每个元素,并尝试将适当的组件识别为:
- LTFigure:表示PDF中页面上的图形或图像的区域。
- LTTextContainer:代表一个矩形区域(段落)中的一组文本行(line),然后进一步分析成LTTextLine对象的列表。它们中的每一个都表示一个LTChar对象列表,这些对象存储文本的单个字符及其元数据。
- LTRect表示一个二维矩形,可用于在LTPage对象中占位区或者Panel,图形或创建表。
因此,使用Python对页面进行重构之后,将页面元素分类为LTFigure(图像或图形)、LTTextContainer(文本信息)或LTRect(表格),我们就可以选择适当的函数来更好地提取内容信息了。
for pagenum, page in enumerate(extract_pages(pdf_path)):
# Iterate the elements that composed a page
for element in page:
# Check if the element is a text element
if isinstance(element, LTTextContainer):
# Function to extract text from the text block
pass
# Function to extract text format
pass
# Check the elements for images
if isinstance(element, LTFigure):
# Function to convert PDF to Image
pass
# Function to extract text with OCR
pass
# Check the elements for tables
if isinstance(element, LTRect):
# Function to extract table
pass
# Function to convert table content into a string
pass
定义从PDF中提取文本的函数
# 创建一个文本提取函数
def __text_block_parse(self, element):
# 从行元素中提取文本
line_text = element.get_text()
# 探析文本的格式
# 用文本行中出现的所有格式初始化列表
line_formats = []
for text_line in element:
if isinstance(text_line, LTTextContainer):
# 遍历文本行中的每个字符
for character in text_line:
if isinstance(character, LTChar):
# 追加字符的font-family
line_formats.append(character.fontname)
# 追加字符的font-size
line_formats.append(character.size)
# 找到行中唯一的字体大小和名称
format_per_line = list(set(line_formats))
# 返回包含每行文本及其格式的元组
return line_text, format_per_line
要从文本容器中提取文本,我们只需使用LTTextContainer元素的get_text()方法。此方法检索构成特定语料库框中单词的所有字符,并将输出存储在文本数据列表中。此列表中的每个元素表示容器中包含的原始文本信息。
为了识别该文本的格式,需要遍历LTTextContainer对象,以单独访问该语料库的每个文本行。在每次迭代中,都会创建一个新的LTTextLine对象,表示该语料库块中的一行文本。然后检查嵌套的line元素是否包含文本。如果是,则将每个单独的字符元素作为LTChar访问,其中包含该字符的所有元数据。从这个元数据中提取两种类型的格式,并将它们存储在一个单独的列表中,对应于检查的文本:
- 字符的font-family,包括字符是粗体还是斜体
- 字符的font-size
通常,特定文本块中的字符往往具有一致的格式,除非某些字符以粗体突出显示。为了便于进一步分析,我们捕获文本中所有字符的文本格式的唯一值,并将它们存储在适当的列表中。
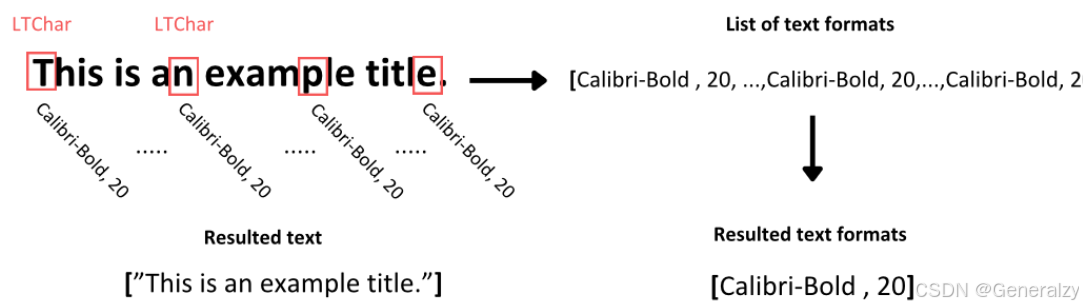
当然,如果没有格式要求的项目,可以不获取fontname和size,只提取段落内容即可。
定义从图像中提取文本的函数
首先,我们需要在这里确定存储在pdf中的图像元素与文件的格式不同,例如JPEG或PNG。这样,为了对它们应用OCR软件,我们需要首先将它们从文件中分离出来,然后将它们转换为图像格式。
import os
import PyPDF2
from pdf2image import convert_from_path
from transformers import AutoModel, AutoTokenizer
from pdfminer.high_level import extract_pages, extract_text
from pdfminer.layout import LTTextContainer, LTChar, LTRect, LTFigure
class PDFParser:
def __init__(self, model_path: str, pdf_path: str):
self.__model_path = model_path
if not os.path.isabs(model_path) or not os.path.exists(model_path):
raise ValueError(f"path error: not found model file {self.__model_path}.")
self.__pdf_path = pdf_path
self.__tokenizer = AutoTokenizer.from_pretrained(self.__model_path, trust_remote_code=True)
self.__model = AutoModel.from_pretrained(
self.__model_path,
trust_remote_code=True,
low_cpu_mem_usage=True,
device_map='cuda',
use_safetensors=True,
pad_token_id=self.__tokenizer.eos_token_id
).eval().cuda()
# 创建一个PDF阅读器对象
self.__pdf_fd = open(pdf_path, 'rb')
self.__pdf_reader = PyPDF2.PdfReader(self.__pdf_fd)
# 创建一个PDF图片存储器
self.__pdf_writer = PyPDF2.PdfWriter()
def __picture_parse(self, image_path: str):
return self.__model.chat(self.__tokenizer, image_path, ocr_type='ocr')
def __convert_to_images(self):
with open('image.pdf', 'wb') as image_pdf:
self.__pdf_writer.write(image_pdf)
images = convert_from_path("image.pdf")
for image_number, image in enumerate(images):
output_file = f"image{image_number}.png"
image.save(output_file, "PNG")
def __text_block_parse(self, element):
# 从行元素中提取文本
line_text = element.get_text()
# 探析文本的格式
# 用文本行中出现的所有格式初始化列表
line_formats = []
for text_line in element:
if isinstance(text_line, LTTextContainer):
# 遍历文本行中的每个字符
for character in text_line:
if isinstance(character, LTChar):
# 追加字符的font-family
line_formats.append(character.fontname)
# 追加字符的font-size
line_formats.append(character.size)
# 找到行中唯一的字体大小和名称
format_per_line = list(set(line_formats))
# 返回包含每行文本及其格式的元组
return line_text, format_per_line
def __picture_block_parse(self, element, page_number: int):
# picture box
x0, y0, x1, y1 = [element.x0, element.y0, element.x1, element.y1]
# 使用坐标((x0,y1),(x1,y0))裁剪页面
#
page_obj = self.__pdf_reader.pages[page_number]
page_obj.mediabox.lower_left = (x0, y1)
page_obj.mediabox.upper_right = (x1, y0)
# 将裁剪后的页面保存为新的PDF
self.__pdf_writer.add_page(page_obj)
def parse(self):
for page_number, page in enumerate(extract_pages(self.__pdf_path)):
# 检查每一页的元素
for element in page:
# Check if the element is a text element
if isinstance(element, LTTextContainer):
# Function to extract text from the text block
pass
# Function to extract text format
pass
# Check the elements for images
if isinstance(element, LTFigure):
# Function to convert PDF to Image
self.__picture_block_parse(element, page_number)
# Function to extract text with OCR
pass
# Check the elements for tables
if isinstance(element, LTRect):
# Function to extract table
pass
# Function to convert table content into a string
pass
self.__convert_to_images()
# input your test imag
if __name__ == '__main__':
parser = PDFParser("F:\\Model\\GOT-OCR2_0", "example\\x.pdf")
parser.parse()
思路如下:
- 使用从PDFMiner检测到的LTFigure对象的元数据来裁剪图像框,利用其在页面布局中的坐标。然后使用PyPDF2库将其保存为新的PDF文件。
- 然后,使用pdf2image库中的convert_from_file()函数将目录中的所有PDF文件转换为图像列表,并以PNG格式保存它们。
- 最后,利用OCR大模型识别图片内容。
关于bbox,可以从官方库的github仓库得到以下说明:
| 属性 | 描述 |
|---|---|
upright |
元素是否为正立。 |
height |
元素高度。 |
width |
元素宽度。 |
x0 |
元素左侧距离页面左侧的距离。 |
x1 |
元素右侧距离页面左侧的距离。 |
y0 |
元素底部距离页面底部的距离。 |
y1 |
元素顶部距离页面底部的距离。 |
top |
元素顶部距离页面顶部的距离。 |
bottom |
元素底部距离页面顶部的距离。 |
doctop |
元素顶部距离文档顶部的距离。 |
定义从表格中提取文本的函数
有几个库用于从pdf中提取表数据,其中Tabula-py是最著名的库之一,但他提取的信息以Pandas DataFrame而不是字符串的形式输出。在大多数情况下,这可能是一种理想的格式,但是在考虑文本的Transformers的情况下,这些结果需要在输入到模型之前进行转换。
因此选择pdfplumber库来处理这个任务。
def extract_table(pdf_path, page_num, table_num):
# 打开PDF文件
pdf = pdfplumber.open(pdf_path)
# 查找已检查的页面
table_page = pdf.pages[page_num]
# 提取适当的表格
table = table_page.extract_tables()[table_num]
return table
# 将表格转换为适当的格式
def table_converter(table):
table_string = ''
# 遍历表格的每一行
for row_num in range(len(table)):
row = table[row_num]
# 从warp的文字删除线路断路器
cleaned_row = [item.replace('\n', ' ') if item is not None and '\n' in item else 'None' if item is None else item for item in row]
# 将表格转换为字符串,注意'|'、'\n'
table_string+=('|'+'|'.join(cleaned_row)+'|'+'\n')
# 删除最后一个换行符
table_string = table_string[:-1]
return table_string
整合所有文本
import os
import PyPDF2
import pdfplumber
from pdf2image import convert_from_path
from transformers import AutoModel, AutoTokenizer
from pdfminer.high_level import extract_pages
from pdfminer.layout import LTTextContainer, LTRect, LTFigure
class PDFParser:
def __init_module(self):
self.__tokenizer = AutoTokenizer.from_pretrained(self.__model_path, trust_remote_code=True)
self.__model = AutoModel.from_pretrained(
self.__model_path,
trust_remote_code=True,
low_cpu_mem_usage=True,
device_map='cuda',
use_safetensors=True,
pad_token_id=self.__tokenizer.eos_token_id
).eval().cuda()
def __init__(self, model_path: str, pdf_path: str):
# 大模型绝对路径
self.__model_path = model_path
if not os.path.isabs(model_path) or not os.path.exists(model_path):
raise ValueError(f"path error: not found model file {self.__model_path}.")
# 源pdf路径
self.__pdf_path = pdf_path
# 初始化大模型
self.__model = None
# 缓存
self.__cache = {} # type:dict[tuple,bool]
# __pdfplumber_reader 用于细粒度解析pdf
self.__pdfplumber_reader = pdfplumber.open(self.__pdf_path)
# __pdf2_reade 用于粗粒度操作pdf
self.__pdf_fd = open(pdf_path, "rb")
self.__pdf2_reader = PyPDF2.PdfReader(self.__pdf_fd)
# 存储pdf内容
self.__content = []
def __del__(self):
"""
回收垃圾
"""
self.__pdfplumber_reader.close()
del self.__pdf2_reader
if not self.__pdf_fd.closed:
self.__pdf_fd.close()
def __picture_parse(self, image_path: str):
"""
调用OCR大模型识别图片
"""
# lazy
if self.__model is None:
self.__init_module()
return self.__model.chat(self.__tokenizer, image_path, ocr_type='ocr')
def __table_parse(self, table: list) -> str:
table_string = ""
# 遍历表格的每一行
for row_num in range(len(table)):
row = table[row_num]
# 从warp的文字删除线路断路器
cleaned_row = [
item.replace('\n', ' ') if item is not None and '\n' in item else 'None' if item is None else item for
item in row]
# 将表格转换为字符串,注意'|'、'\n'
table_string += ('|' + '|'.join(cleaned_row) + '|' + '\n')
# 删除最后一个换行符
table_string = table_string[:-1]
return table_string
def __text_block_parse(self, element) -> str:
"""
文本块解析
"""
_local_text = ""
for line in element.get_text():
# 排除pdf每行文本的换行符和空白字符(""," ","\n","\r\n","\r")
_local_text += line.strip()
return _local_text
def __picture_block_parse(self, element, page_number: int) -> str:
# picture box
x0, y0, x1, y1 = [element.x0, element.y0, element.x1, element.y1]
# 使用坐标((x0,y1),(x1,y0))裁剪页面
page_obj = self.__pdf2_reader.pages[page_number]
page_obj.mediabox.lower_left = (x0, y1)
page_obj.mediabox.upper_right = (x1, y0)
# 新建pdf保存图片
_local_pdf_writer = PyPDF2.PdfWriter()
_local_pdf_writer.add_page(page_obj)
# 保存新的PDF
with open("image.pdf", 'wb') as image_pdf:
_local_pdf_writer.write(image_pdf)
# 读取图片
images = convert_from_path("image.pdf")
try:
image = images[0]
image.save("image.png", "PNG")
return self.__picture_parse("image.png")
except Exception:
return ""
finally:
# 清除中间文件
if os.path.exists("image.pdf"):
os.remove("image.pdf")
if os.path.exists("image.png"):
os.remove("image.png")
def __table_block_parse(self, table):
return self.__table_parse(table.extract())
@property
def result(self):
return self.__content
def parse(self):
for page_number, page in enumerate(extract_pages(self.__pdf_path)):
# 获取当前页面对象
plumber_page_obj = self.__pdfplumber_reader.pages[page_number]
plumber_table_objs = plumber_page_obj.find_tables()
plumber_table_count = len(plumber_table_objs)
current_table_index = 0
# table标识
table_flag = False
# 用于判断第一个矩形元素是不是表格的一部分
table_element_flag = True
# 找到所有的元素并且按照高度排序
page_elements = [(element.y1, element) for element in page._objs]
page_elements.sort(key=lambda a: a[0], reverse=True)
# 解析当前页面所有元素
for element_index, component in enumerate(page_elements):
element = component[-1]
next_element = None
if element_index + 1 < len(page_elements):
next_element = page_elements[element_index + 1][1]
# 解析文本(LTTextContainer为文本类的根类)
if isinstance(element, LTTextContainer):
if not table_flag:
self.__content.append(self.__text_block_parse(element))
# 解析图片
if isinstance(element, LTFigure):
self.__content.append(self.__picture_block_parse(element, page_number))
# 解析表格
if isinstance(element, LTRect):
# 表格元素也会被认为是LTRect
"""
x0:元素左侧距离页面左侧的距离
y0:元素底部距离页面底部的距离
x1:元素右侧距离页面左侧的距离
y1:元素顶部距离页面底部的距离
"""
# 防止一些矩形元素被误判
if plumber_table_count == 0:
continue
if table_element_flag and current_table_index < plumber_table_count:
table_bbox = plumber_table_objs[current_table_index].bbox # type:tuple
self.__content.append(self.__table_block_parse(plumber_table_objs[current_table_index]))
self.__cache[(page_number, table_bbox)] = True
# 当前页面该表格已经解析过就不再解析
table_flag = True
table_element_flag = False
table_bbox = plumber_table_objs[current_table_index].bbox # type:tuple
# 根据坐标判断是否需要自增current_table_index
# page (0, 0, 595.32, 841.92)
lower_side = page.bbox[3] - table_bbox[3]
upper_side = element.y1
if element.y0 >= lower_side and element.y1 <= upper_side:
# do nothing
pass
elif not isinstance(next_element, LTRect):
# 判断下一个元素是不是表格
current_table_index += 1
table_element_flag = True
table_flag = False
if __name__ == '__main__':
parser = PDFParser("F:\\Model\\GOT-OCR2_0", "example.pdf")
parser.parse()
print(parser.result)
以上代码对于每个元素:
-
检查它是否是一个文本容器,并且没有出现在表元素中。然后使用text_extraction()函数提取文本及其格式,否则传递该文本。
-
检查它是否为图像,并使用crop_image()函数从PDF中裁剪图像组件,使用convert_to_images()将其转换为图像文件,并使用image_to_text()函数使用OCR从中提取文本。
-
检查它是否是一个矩形元素。在这种情况下,检查第一个矩形是否是页表的一部分,如果是,则执行以下步骤:
- 查找表的边界框,以便不再使用text_extraction()函数提取其文本。
- 提取表的内容并将其转换为字符串。
- 然后添加一个布尔参数来说明是从Table中提取文本的。
- 此过程将在最后一个LTRect落在表的边界框中并且布局中的下一个元素不是矩形对象之后结束。(构成表的所有其他对象都将被解析)
结果展示:
扩展:全面解析Docx
由于pdf解析非常成功,所以我们解析docx/doc的思路就是:docx/doc -> pdf -> text -> RAG语料。
python三方库转换docx/doc->pdf的功能都太弱,Office又不能跨平台,因此我们找到了办公3巨头(WPS,MS office,libreoffice)里的libreoffice:
可以从LibreOffice官网下载并安装适合你操作系统的版本。
在Linux系统上,可以使用包管理器安装,例如:
sudo apt update
sudo apt install libreoffice
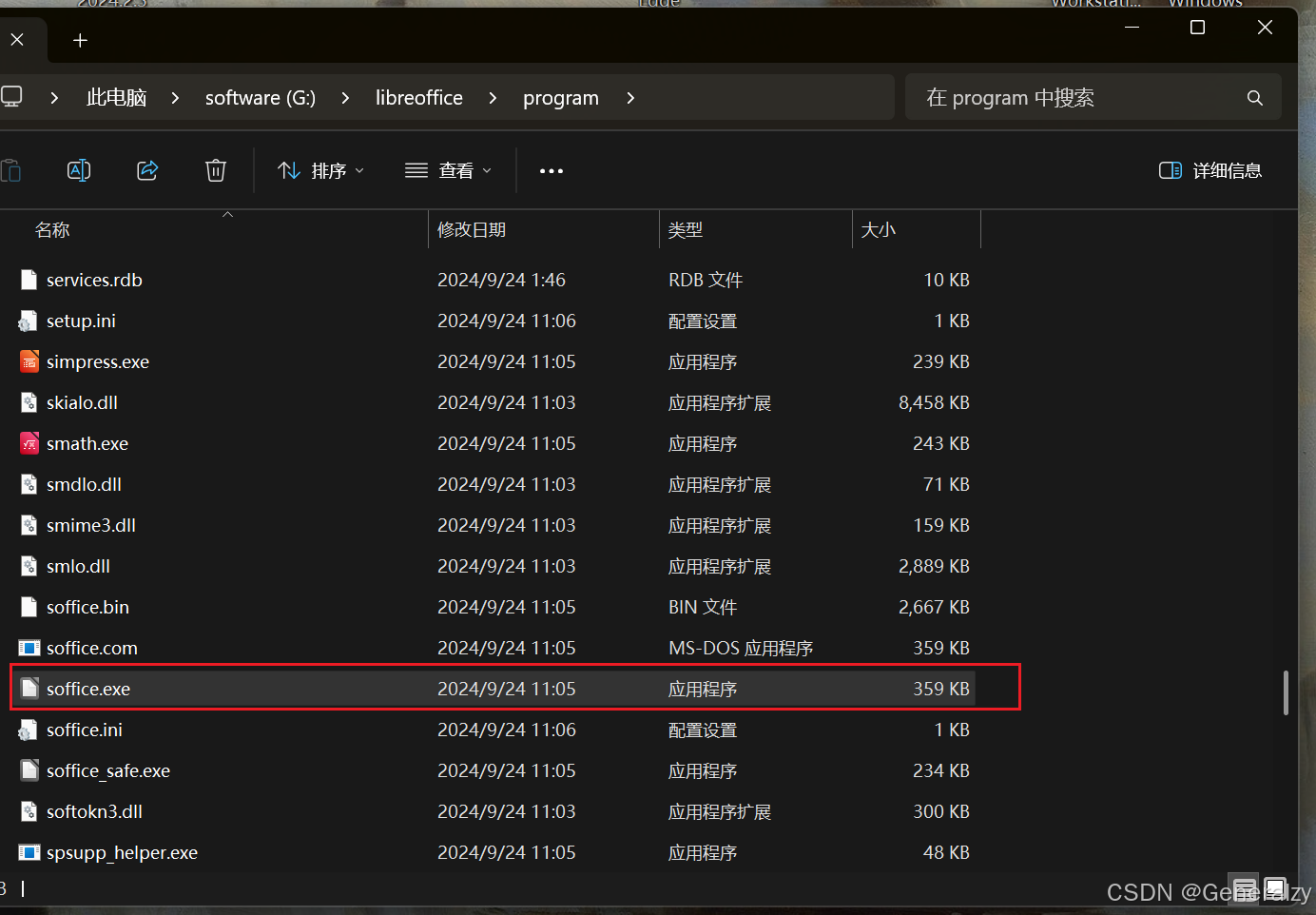
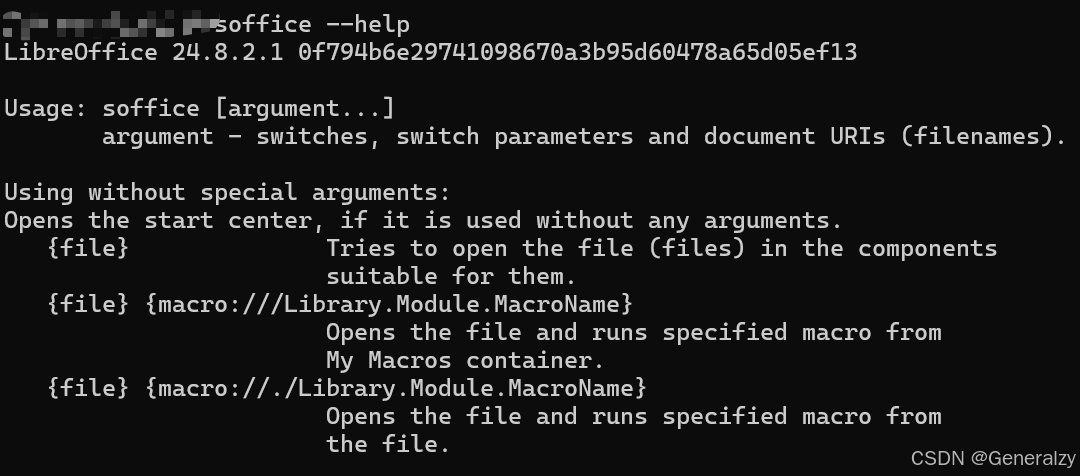
安装好后需要将soffice所在目录放到环境变量中,然后在cmd中输入soffice --help验证安装:
使用命令行进行转换
LibreOffice提供了一个命令行工具soffice,可以用来进行文档格式转换。以下是将DOC/DOCX文件转换为PDF的命令:
soffice --headless --convert-to pdf example.docx
--headless:以无界面模式运行LibreOffice,这对于服务器环境非常有用。--convert-to pdf:指定输出格式为PDF。example.docx:要转换的Word文件的路径。
假设你有一个名为example.docx的文件,并且希望将其转换为PDF,可以在终端中运行以下命令:
soffice --headless --convert-to pdf example.docx
-
路径问题:确保在命令中指定的文件路径是正确的。如果文件不在当前目录下,需要提供完整路径。
-
文件名冲突:如果输出目录中已经存在同名的PDF文件,LibreOffice会覆盖该文件。
-
批量转换:可以使用通配符或脚本批量转换多个文件。例如,转换当前目录下所有的DOCX文件:
soffice --headless --convert-to pdf *.docx -
其他格式:LibreOffice支持多种输入和输出格式,可以通过
--convert-to参数指定其他格式。 -
指定输出:LibreOffice可以指定输出目录,可以通过
--outdir $output_dir参数指定输出目录。(输出文件与输入文件名称一致)
LibreOffice使用中的一些问题
将 word 转化为 pdf 中文乱码
由于 linux 默认没有安装中文字体,所以导出有中文的文件会导致中文乱码,可以将windows c:\windows\Fonts目录下的字体文件,拷贝到服务器 /usr/share/font/目录下,然后建立缓存:sudo fc-cache -fv即可生效。
# 建立字体缓存信息
root@jt-test-web:/usr/share/fonts# apt install xfonts-utils -y
root@jt-test-web:/usr/share/fonts# mkfontscale
root@jt-test-web:/usr/share/fonts# mkfontdir
root@jt-test-web:/usr/share/fonts# fc-cache -fv
然后验证字体是否导入:
root@jt-test-web:/usr/share/fonts# fc-list :lang=zh
/usr/share/fonts/truetype/dejavu/MSYHBD.TTC: Microsoft YaHei UI:style=Bold,Negreta,tučné,fed,Fett,Έντονα,Negrita,Lihavoitu,Gras,Félkövér,Grassetto,Vet,Halvfet,Pogrubiony,Negrito,Полужирный,Fet,Kalın,Krepko,Lodia
/usr/share/fonts/truetype/dejavu/MSYH.TTC: Microsoft YaHei,微软雅黑:style=Regular,Normal,obyčejné,Standard,Κανονικά,Normaali,Normál,Normale,Standaard,Normalny,Обычный,Normálne,Navadno,Arrunta
/usr/share/fonts/truetype/dejavu/MSYHBD.TTC: Microsoft YaHei,微软雅黑:style=Bold,Negreta,tučné,fed,Fett,Έντονα,Negrita,Lihavoitu,Gras,Félkövér,Grassetto,Vet,Halvfet,Pogrubiony,Negrito,Полужирный,Fet,Kalın,Krepko,Lodia
/usr/share/fonts/truetype/dejavu/MSYH.TTC: Microsoft YaHei UI:style=Regular,Normal,obyčejné,Standard,Κανονικά,Normaali,Normál,Normale,Standaard,Normalny,Обычный,Normálne,Navadno,Arrunta
/usr/share/fonts/truetype/dejavu/MSYHL.TTC: Microsoft YaHei UI,Microsoft YaHei UI Light:style=Light,Regular
/usr/share/fonts/truetype/dejavu/MSYHL.TTC: Microsoft YaHei,微软雅黑,Microsoft YaHei Light,微软雅黑 Light:style=Light,Regular
最后再次执行转换命令即可正确显示中文。
将 word 转化为 pdf 异常卡慢甚至没有响应
我遇到这个问题的时候,找了很多资料都无解,然跳转解决第一个问题,也就是把字体文件拖入linux再次执行的时候,发现很快就转化完成了QAQ。
Libreoffice转换不成功,直接不做任何操作
Libreoffice在版本5.3.0之前都存在这个问题。现象是:当你运行其中一个LibreOffice的时候,再运行另外一个Libreoffice转换时,将不做任何操作。
FAQ(Frequently Asked Questions)
pdfminer解析PDF乱序问题
在做RAG的数据解析部分时,作者注意到pdfminer解析后的文件有这样的情况:
# 原文
4.1.2
ID:121943732
中文名:卡号
# 解析后
412 . . . ID卡号中文名::121943732
在排除元素排序问题后,最终定位到了页(page)上,根本原因是解析到的page就是乱序的,那么就是解析器的问题,查看源码,发现允许传入LAParams参数对解析器进行微调:
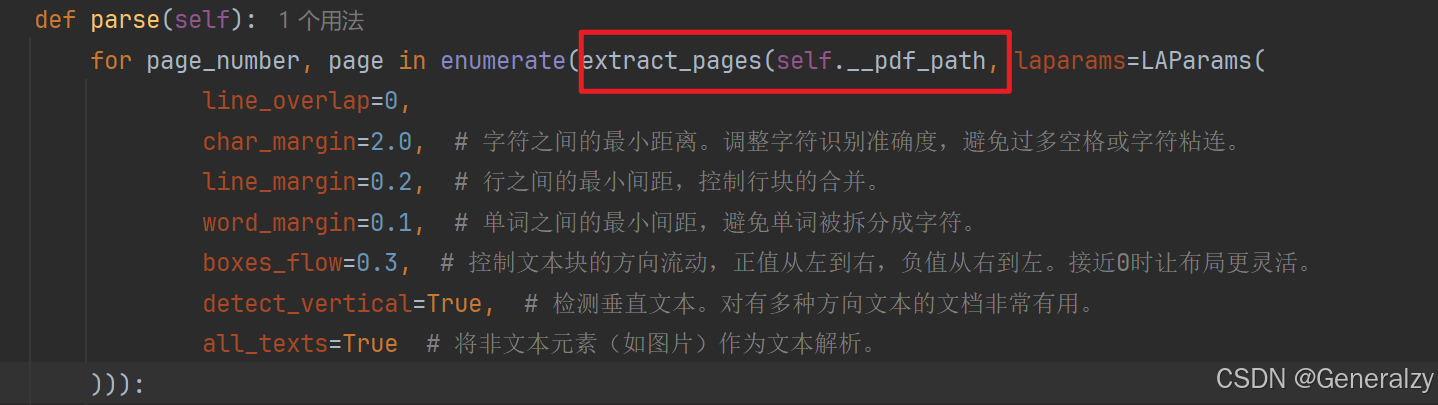
class LAParams:
"""布局分析的参数
:param line_overlap: 如果两个字符的重叠超过此值,则
被视为在同一行。重叠是相对于两个字符的最小高度指定的。
:param char_margin: 如果两个字符的间距小于此
边距,则它们被视为同一行的一部分。边距是相对于字符的宽度指定的。
:param word_margin: 如果同一行上的两个字符间距超过此边距,
则它们被视为两个独立的单词,并且会添加一个中间空格以提高可读性。
边距是相对于字符的宽度指定的。
:param line_margin: 如果两行相距很近,它们被视为
同一段落的一部分。边距是相对于一行的高度指定的。
:param boxes_flow: 指定在确定文本框顺序时
水平和垂直位置的重要性。值应在 -1.0(仅水平位置
重要)到 +1.0(仅垂直位置重要)的范围内。您还可以传递
`None` 以禁用高级布局分析,而是基于文本框左下角的位置返回文本。
:param detect_vertical: 在布局分析时是否应考虑垂直文本
:param all_texts: 是否应对图形中的文本进行布局分析。
"""
def __init__(
self,
line_overlap: float = 0.5,
char_margin: float = 2.0,
line_margin: float = 0.5,
word_margin: float = 0.1,
boxes_flow: Optional[float] = 0.5,
detect_vertical: bool = False,
all_texts: bool = False,
) -> None:
self.line_overlap = line_overlap
self.char_margin = char_margin
self.line_margin = line_margin
self.word_margin = word_margin
self.boxes_flow = boxes_flow
self.detect_vertical = detect_vertical
self.all_texts = all_texts
self._validate()
line_overlap参数是个滑动窗口参数,因为pdf的元素重叠与人眼看到的视觉效果并不同!!因此会被合并成一个块! 把这个参数设置为0,就可以避免4.1.2这种这种标题号被识别成412...的问题!

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐



 0
0 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)