使用sysbench为mysql全方位压测,单台mysql服务器支持多少并发?
这个压测结果会根据每个人的机器的性能不同有很大的差距,你要是机器性能特别高,那你可以开很多的并发线程去压测,比如100个线程,此时可能会发现数据库每秒的TPS有上千个,如果你的机器性能很低,可能压测出来你的TPS才二三十个,QPS才几百个,这都是有可能的。对于内存而言,同样是要在压测的过程中紧密的观察,一般来说,如果内存的使用率在80%以内,基本都还能接受,在正常范围内,但是如果你的机器的内存使用
文章目录
一、压测前的储备知识
1、普通的Java应用系统部署在机器上能抗多少并发
通常来说,根据我们的经验值而言,Java应用系统部署的时候常选用的机器配置大致是2核4G和4核8G的较多一些,数据库部署的时候常选用的机器配置最低在8核16G以上,正常在16核32G。
那么以我们大量的高并发线上系统的生产经验观察下来而言,一般Java应用系统部署在4核8G的机器上,每秒钟抗下500左右的并发访问量,差不多是比较合适的,当然这个也不一定。因为你得考虑一下,假设你每个请求花费1s可以处理完,那么你一台机器每秒也许只可以处理100个请求,但是如果你每个请求只要花费100ms就可以处理完,那么你一台机器每秒也许就可以处理几百个请求。
所以一台机器能抗下每秒多少请求,往往是跟你每个请求处理耗费多长时间是关联的,但是大体上来说,根据我们大量的经验观察而言,4核8G的机器部署普通的Java应用系统,每秒大致就是抗下几百的并发访问,从每秒一两百请求到每秒七八百请求,都是有可能的,关键是看你每个请求处理需要耗费多长时间。
2、mysql单台数据库能支持多少并发
对于数据库而言,通常推荐的数据库至少是选用8核16G以的机器,甚至是16核32G的机器更加合适一些。因为数据库需要执行大量的磁盘IO操作,他的每个请求都比较耗时一些,所以机器的配置自然需要高一些了。
后通过我们之前的经验而言,一般8核16G的机器部署的MySQL数据库,每秒抗个一两千并发请求是没问题的,但是如果你的并发量再高一些,假设每秒有几千并发请求,那么可能数据库就会有点危险了,因为数据库的CPU、磁盘、IO、内存的负载都会很高,弄不数据库压力过大就会宕机。
对于16核32G的机器部署的MySQL数据库而言,每秒抗个两三千,甚至三四千的并发请求也都是可以的,但是如果你达到每秒上万请求,那么数据库的CPU、磁盘、IO、内存的负载瞬间都会飙升到很高,数据库也是可能会扛不住宕机的。
二、使用sysbench压测数据库
1、准备mysql数据库
此处使用mysql8.0版本的数据库。
2、安装sysbench
curl -s https://packagecloud.io/install/repositories/akopytov/sysbench/script.rpm.sh | bash
sudo yum -y install sysbench
sysbench --version
如果上面可以看到sysbench的版本号,就说明安装成功了。
3、准备压测用户和数据库
-- 创建用户名为test_user,设所有ip均可登录,密码test_user
create user test_user@'%' identified WITH mysql_native_password BY 'test_user';
-- grant给test_user赋予所有的库和表的权限。
grant all privileges on *.* to test_user@'%' with grant option;
-- 刷新
flush privileges;
注意,密码加密方式只能是mysql_native_password ,而不能用caching_sha2_password。
然后创建test_db数据库。
然后我们将要基于sysbench构建20个测试表,每个表里有100万条数据,接着使用10个并发线程去对这个数据库发起访问,连续访问5分钟,也就是300秒,然后对其进行压力测试。
4、基于sysbench构造测试表和测试数据
sysbench --db-driver=mysql --time=300 --threads=10 --report-interval=1 --mysql-host=127.0.0.1 --mysql-port=3306 --mysql-user=test_user --mysql-password=test_user --mysql-db=test_db --tables=20 --table_size=1000000 oltp_read_write --db-ps-mode=disable prepare
上面我们构造了一个sysbench命令,给他加入了很多的参数,现在我们来 解释一下这些参数,相信很多参数大家自己看到也就大致明白什么意思了:
–db-driver=mysql:这个很简单,就是说他基于mysql的驱动去连接mysql数据库,你要是oracle,或者sqlserver,那自然就是其他的数据库的驱动了
–time=300:这个就是说连续访问300秒
–threads=10:这个就是说用10个线程模拟并发访问
–report-interval=1:这个就是说每隔1秒输出一下压测情况
–mysql-host=127.0.0.1 --mysql-port=3306 --mysql-user=test_user --mysql-password=test_user:这一大串,就是说连接到哪台机器的哪个端口上的MySQL库,他的用户名和密码是什么
–mysql-db=test_db --tables=20 --table_size=1000000:这一串的意思,就是说在test_db这个库里,构造20个测试表,每个测试表里构造100万条测试数据,测试表的名字会是类似于sbtest1,sbtest2这个样子的
oltp_read_write:这个就是说,执行oltp数据库的读写测试
–db-ps-mode=disable:这个就是禁止ps模式
最后有一个prepare,意思是参照这个命令的设置去构造出来我们需要的数据库里的数据,他会自动创建20个测试表,每个表里创建100万条测试数据,所以这个工具是非常的方便的。
5、对数据库进行360度的全方位测试
# 测试数据库的综合读写TPS,使用的是oltp_read_write模式(大家看命令中最后不是prepare,是run了,就是运行压测):
sysbench --db-driver=mysql --time=300 --threads=10 --report-interval=1 --mysql-host=127.0.0.1 --mysql-port=3306 --mysql-user=test_user --mysql-password=test_user --mysql-db=test_db --tables=20 --table_size=1000000 oltp_read_write --db-ps-mode=disable run
# 测试数据库的只读性能,使用的是oltp_read_only模式(大家看命令中的oltp_read_write已经变为oltp_read_only了):
sysbench --db-driver=mysql --time=300 --threads=10 --report-interval=1 --mysql-host=127.0.0.1 --mysql-port=3306 --mysql-user=test_user --mysql-password=test_user --mysql-db=test_db --tables=20 --table_size=1000000 oltp_read_only --db-ps-mode=disable run
# 测试数据库的删除性能,使用的是oltp_delete模式:
sysbench --db-driver=mysql --time=300 --threads=10 --report-interval=1 --mysql-host=127.0.0.1 --mysql-port=3306 --mysql-user=test_user --mysql-password=test_user --mysql-db=test_db --tables=20 --table_size=1000000 oltp_delete --db-ps-mode=disable run
# 测试数据库的更新索引字段的性能,使用的是oltp_update_index模式:
sysbench --db-driver=mysql --time=300 --threads=10 --report-interval=1 --mysql-host=127.0.0.1 --mysql-port=3306 --mysql-user=test_user --mysql-password=test_user --mysql-db=test_db --tables=20 --table_size=1000000 oltp_update_index --db-ps-mode=disable run
# 测试数据库的更新非索引字段的性能,使用的是oltp_update_non_index模式:
sysbench --db-driver=mysql --time=300 --threads=10 --report-interval=1 --mysql-host=127.0.0.1 --mysql-port=3306 --mysql-user=test_user --mysql-password=test_user --mysql-db=test_db --tables=20 --table_size=1000000 oltp_update_non_index --db-ps-mode=disable run
# 测试数据库的更新非索引字段的性能,使用的是oltp_update_non_index模式:
sysbench --db-driver=mysql --time=300 --threads=10 --report-interval=1 --mysql-host=127.0.0.1 --mysql-port=3306 --mysql-user=test_user --mysql-password=test_user --mysql-db=test_db --tables=20 --table_size=1000000 oltp_update_non_index --db-ps-mode=disable run
# 测试数据库的插入性能,使用的是oltp_insert模式:
sysbench --db-driver=mysql --time=300 --threads=10 --report-interval=1 --mysql-host=127.0.0.1 --mysql-port=3306 --mysql-user=test_user --mysql-password=test_user --mysql-db=test_db --tables=20 --table_size=1000000 oltp_insert --db-ps-mode=disable run
# 测试数据库的写入性能,使用的是oltp_write_only模式:
sysbench --db-driver=mysql --time=300 --threads=10 --report-interval=1 --mysql-host=127.0.0.1 --mysql-port=3306 --mysql-user=test_user --mysql-password=test_user --mysql-db=test_db --tables=20 --table_size=1000000 oltp_write_only --db-ps-mode=disable run
使用上面的命令,sysbench工具会根据你的指令构造出各种各样的SQL语句去更新或者查询你的20张测试表里的数据,同时监测出你的数据库的压测性能指标,最后完成压测之后,可以执行下面的cleanup命令,清理数据。
sysbench --db-driver=mysql --time=300 --threads=10 --report-interval=1 --mysql-host=127.0.0.1 --mysql-port=3306 --mysql-user=test_user --mysql-password=test_user --mysql-db=test_db --tables=20 --table_size=1000000 oltp_read_write --db-ps-mode=disable cleanup
6、压测结果分析
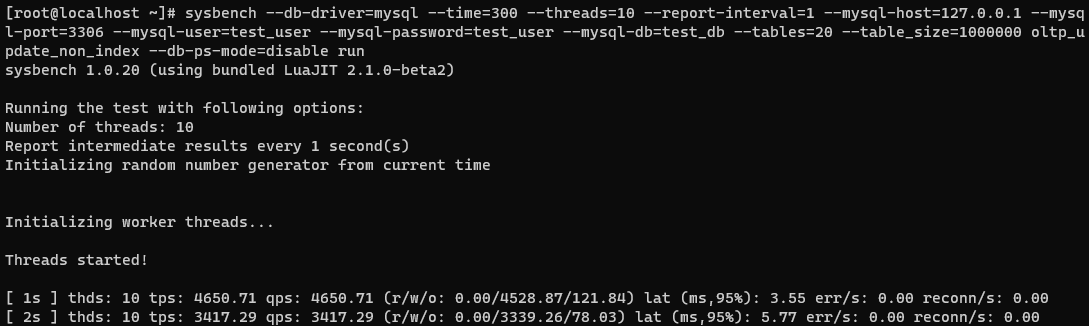
按照我们上面的命令,我们是让他每隔1秒都会输出一次压测报告的,此时他每隔一秒会输出类似下面的一段东西:

[root@localhost ~]# sysbench --db-driver=mysql --time=300 --threads=10 --report-interval=1 --mysql-host=127.0.0.1 --mysql-port=3306 --mysql-user=test_user --mysql-password=test_user --mysql-db=test_db --tables=20 --table_size=1000000 oltp_update_non_index --db-ps-mode=disable run
sysbench 1.0.20 (using bundled LuaJIT 2.1.0-beta2)
Running the test with following options:
Number of threads: 10
Report intermediate results every 1 second(s)
Initializing random number generator from current time
Initializing worker threads...
Threads started!
[ 1s ] thds: 10 tps: 4650.71 qps: 4650.71 (r/w/o: 0.00/4528.87/121.84) lat (ms,95%): 3.55 err/s: 0.00 reconn/s: 0.00
[ 2s ] thds: 10 tps: 3417.29 qps: 3417.29 (r/w/o: 0.00/3339.26/78.03) lat (ms,95%): 5.77 err/s: 0.00 reconn/s: 0.00
首先他说的这是第1s、2s输出的一段压测统计报告,然后是其他的一些统计字段:
thds: 10,这个意思就是有10个线程在压测
tps: 4650.71,这个意思就是每秒执行了4650.71个事务
qps: 4650.71,这个意思就是每秒可以执行4650.71个请求
(r/w/o: 0.00/4528.87/121.84),这个意思就是说,在每秒中,分别是读、写、其他请求的个数,就是对QPS进行了拆解
lat (ms, 95%): 3.55,这个意思就是说,95%的请求的延迟都在3.55毫秒以下
err/s: 0.00 reconn/s: 0.00,这两个的意思就是说,每秒有0个请求是失败的,发生了0次网络重连
这个压测结果会根据每个人的机器的性能不同有很大的差距,你要是机器性能特别高,那你可以开很多的并发线程去压测,比如100个线程,此时可能会发现数据库每秒的TPS有上千个,如果你的机器性能很低,可能压测出来你的TPS才二三十个,QPS才几百个,这都是有可能的。
另外在完成压测之后,最后会显示一个总的压测报告:

SQL statistics:
queries performed:
read: 0 # 在300s的压测期间执行了0次的读请求
write: 1072573 # 在压测期间执行了107万多次的写请求
other: 28340 # 在压测期间执行了2万多次的其他请求
total: 1100913 # 所有请求数
transactions: 1100913 (3669.66 per sec.) # 这是说一共执行了100万多个事务,每秒执行3669多个事务
queries: 1100913 (3669.66 per sec.) # 一共100多万请求,每秒3669请求
ignored errors: 0 (0.00 per sec.)
reconnects: 0 (0.00 per sec.)
# 一共压测300s,执行110w+事务
General statistics:
total time: 300.0032s
total number of events: 1100913
Latency (ms):
min: 0.06 # 最小延迟的请求
avg: 2.72 # 平均延迟
max: 41.06 # 最大延迟
95th percentile: 5.57 # / 95%的请求延迟都在5.57秒内
sum: 2998745.07
Threads fairness:
events (avg/stddev): 110091.3000/123.27
execution time (avg/stddev): 299.8745/0.00
三、使用top命令观察机器负载
1、查看CPU负载
top命令后,首先我们会看到如下一行信息:
top - 15:52:00 up 42:35, 1 user, load average: 0.15, 0.05, 0.01
这行信息是最直观可以看到机器的cpu负载情况的,首先15:52:00指的是当前时间,up 42:35指的是机器已经运行了多长时间,1 user就是说当前机器有1个用户在使用。
最重要的是load average: 0.15, 0.05, 0.01这行信息,他说的是CPU在1分钟、5分钟、15分钟内的负载情况。
这里要给大家着重解释一下这个CPU负载是什么意思,假设我们是一个4核的CPU,此时如果你的CPU负载是0.15,这就说明,4核CPU中连一个核都没用满,4核CPU基本都很空闲,没啥人在用。
如果你的CPU负载是1,那说明4核CPU中有一个核已经被使用的比较繁忙了,另外3个核还是比较空闲一些。要是CPU负载是1.5,说明有一个核被使用繁忙,另外一个核也在使用,但是没那么繁忙,还有2个核可能还是空闲的。
如果你的CPU负载是4,那说明4核CPU都被跑满了,如果你的CPU负载是6,那说明4核CPU被繁忙的使用还不够处理当前的任务,很多进程可能一直在等待CPU去执行自己的任务。
这个就是CPU负载的概念和含义。
所以大家现在知道了,上面看到的load average实际上就是CPU在最近1分钟,5分钟,15分钟内的平均负载数值,上面都是0.15之类的,说明CPU根本就没怎么用。
但是如果你在压测的过程中,发现4核CPU的load average已经基本达到3.5,4了,那么说明几个CPU基本都跑满了,在满负荷运转,那么此时你就不要再继续提高线程的数量和增加数据库的QPS了,否则CPU负载太高是不合理的。
2、查看内存负载
执行top命令之后,中间我们跳过几行内容,可以看到如下一行内容:
Mem: 33554432k total, 20971520k used, 12268339 free, 307200k buffers
这里说的就是当前机器的内存使用情况,这个其实很简单,明显可以看出来就是总内存大概有32GB,已经使用了20GB左右的内存,还有10多G的内存是空闲的,然后有大概300MB左右的内存用作OS内核的缓冲区了。
对于内存而言,同样是要在压测的过程中紧密的观察,一般来说,如果内存的使用率在80%以内,基本都还能接受,在正常范围内,但是如果你的机器的内存使用率到了70%~80%了,就说明有点危险了,此时就不要继续增加压测的线程数量和QPS了,差不多就可以了。
3、观察磁盘IO
使用dstat -d命令,会看到如下的东西:
-dsk/total -
read writ
103k 211k
0 11k
在上面可以清晰看到,存储的IO吞吐量是每秒钟读取103kb的数据,每秒写入211kb的数据,像这个存储IO吞吐量基本上都不算多的,因为普通的机械硬盘都可以做到每秒钟上百MB的读写数据量。
使用命令:dstat -r,可以看到如下的信息
–io/total-
read writ
0.25 31.9
0 253
0 39.0
他的这个意思就是读IOPS和写IOPS分别是多少,也就是说随机磁盘读取每秒钟多少次,随机磁盘写入每秒钟执行多少次,大概就是这个意思,一般来说,随机磁盘读写每秒在两三百次都是可以承受的。
所以在这里,我们就需要在压测的时候密切观察机器的磁盘IO情况,如果磁盘IO吞吐量已经太高了,都达到极限的每秒上百MB了,或者随机磁盘读写每秒都到极限的两三百次了,此时就不要继续增加线程数量了,否则磁盘IO负载就太高了。
4、观察网卡流量
我们可以使用dstat -n命令,可以看到如下的信息:
-net/total-
recv send
16k 17k
这个说的就是每秒钟网卡接收到流量有多少kb,每秒钟通过网卡发送出去的流量有多少kb,通常来说,如果你的机器使用的是千兆网卡,那么每秒钟网卡的总流量也就在100MB左右,甚至更低一些。
所以我们在压测的时候也得观察好网卡的流量情况,如果网卡传输流量已经到了极限值了,那么此时你再怎么提高sysbench线程数量,数据库的QPS也上不去了,因为这台机器每秒钟无法通过网卡传输更多的数据了。
四、使用Prometheus+Grafana监控服务器
不光是对数据库监控可以采用Prometheus+Grafana的组合,对你开发出来的各种Java系统、中间件系统,都可以使用这套组合去进行可视化的监控,无非就是让Prometheus去采集你的监控数据,然后用Grafana展示成报表而已。
此文不讨论Prometheus+Grafana的部署,感兴趣的同学可以参考其他资料
巨详细的prometheus+grafana实现服务器(集群)性能监控,并学着调用prometheus的api

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 3
3 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)