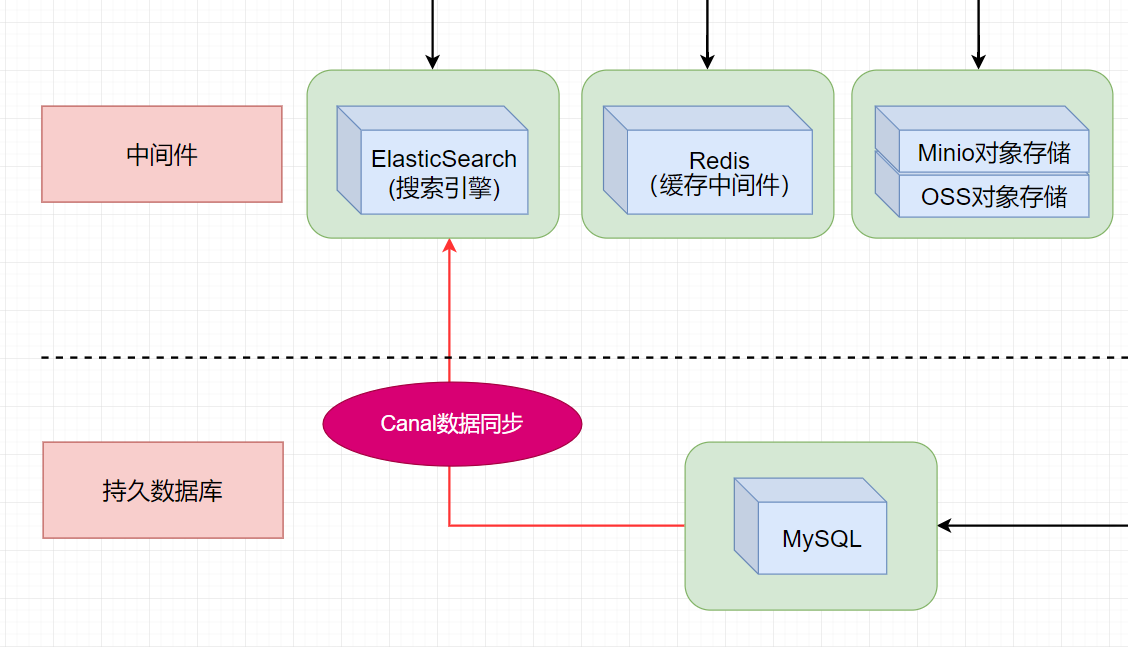
docker环境安装mysql、canal、elasticsearch,基于binlog利用canal实现mysql的数据同步到elasticsearch中
docker环境安装mysql、canal、elasticsearch、canal-server、canal-adapter,mysql数据同步到es,es安装ik中文分词器失败的处理办法-离线安装。容器启动顺序:mysql、es、canal、adapter。
文章目录
🚀 本文提供的指令完全可以按顺序逐一执行,已进行了多次测试。因此如果你是直接按照我本文写的指令一条条执行的,而非自定义修改过,执行应当是没有任何问题的。
🚀 本文讲述:使用docker环境安装mysql、canal、elasticsearch,基于binlog利用canal实现mysql的数据同步到elasticsearch中。
❗️ ❗️❗️ 注意事项(如果你在运行命令时遇到问题一定看下这里):
容器启动顺序:mysql、es、canal、adapter
按照本文的命令启动容器正常情况下是没有问题的,如果遇到启动不了的情况,可以通过
sudo docker logs 容器名查看日志信息,我遇到的一个启动不了的情况是日志报错为内存不足,这与你自身的服务器有关,因此在实操时我使用了两台虚拟机进行操作。如果你的服务器或本地虚拟机内存大小在2.5G以上应该使用一台就够了。很多容器中都只有 vi 命令,而没有 vim 命令,关于 vim 命令的下载我试过很多次都没有成功,并且有些容器的 vi 命令版本比较老导致使用起来一件很折磨人的事情,和vim有所不同。因此在本文中的容器内的配置文件的修改,我的建议是复制一份配置文件到你的windows电脑进行修改,然后删除原配置文件新建一份同名文件,把你修改后的文件内容拷贝上去即可。
你在自定义编写
es_demo_collect.yml的es_demo_collect.yml文件的 SQL 语句时需要注意(如果直接按照我写的来是没有问题的):
不要加顿号,例如:
select b.`user_id` ... on b.`user_id`=u.`id`上述sql中的顿号必须全部删除,即不能出现顿号。应该改为如下:
select b.user_id ... on b.user_id=u.id外连接时必须将连接条件字段放入查询中,例如 on b.user_id = u.id ,这里以 b.user_id/u.id 作为了连接条件,,则在 select 中必须查询 b.user_id 或 u.id 。
你需要让这些防火墙端口处于开放状态:3306,9200,9300,11111,8081
1.docker安装
1.1 基于ubuntu
# 1.更新软件包索引
sudo apt update
# 2.安装必要的依赖软件,来添加一个新的 HTTPS 软件源,遇到 y/N 输入y
sudo apt install apt-transport-https ca-certificates curl gnupg-agent software-properties-common
# 3.使用下面的 curl 导入源仓库的 GPG key
sudo curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo apt-key add -
# 4.将 Docker APT 软件源添加到你的系统
sudo add-apt-repository "deb [arch=amd64] https://download.docker.com/linux/ubuntu $(lsb_release -cs) stable"
# 5.更新软件包索引
sudo apt update
# 6.安装 Docker 最新版本,遇到 Y/n 输入y
sudo apt install docker-ce docker-ce-cli containerd.io
# 7.安装完成,查看docker版本
sudo docker --version
# 8.设置docker自启动
sudo systemctl enable docker

1.2 基于centos7
# 1.安装 docker
yum install docker
# 2.检验安装是否成功
docker --version
# 3.启动
systemctl start docker
# 4.设置为自启动
systemctl enable docker
# 5.换镜像源
sudo vim /etc/docker/daemon.json
#内容如下:
{
"registry-mirrors": ["https://m9r2r2uj.mirror.aliyuncs.com"]
}
# 6.重启
sudo service docker restart
# 7.列出镜像
docker images
# 8.查看运行进程
docker ps
2.数据卷统一管理
# 1.根目录下创建waveedu文件夹
sudo mkdir /wave
# 2.移动到wave文件夹
cd /wave
3.安装mysql
# 1.拉取镜像
sudo docker pull mysql:5.7.36
# 2.创建容器,密码设置为123456,启动mysql
sudo docker run --name mysql5736 \
-v /wave/mysql/log:/var/log/mysql \
-v /wave/mysql/data:/var/lib/mysql \
-v /wave/mysql/conf:/etc/mysql/conf.d \
-e MYSQL_ROOT_PASSWORD=123456 \
-p 3306:3306 \
-d mysql:5.7.36
# 3.查看容器状态,可以看到一个容器名称为mysql5736的容器在运行
sudo docker ps
# 4./wave/mysql/conf 目录(数据卷目录)中新建 my.cnf 文件,并在其中写入如下内容
sudo vim /wave/mysql/conf/my.cnf
# 表示客户端的默认字符集为utf8。
[client]
default_character_set=utf8
# 表示MySQL命令行客户端的默认字符集为utf8。
[mysql]
default_character_set=utf8
# 表示MySQL服务器的默认字符集为utf8,并且 character_set_server 设置MySQL服务器默认使用utf8字符集。
[mysqld]
character_set_server=utf8
[mysqld]
#binlog setting
# 开启logbin
log-bin=mysql-bin
# binlog日志格式
binlog-format=ROW
# mysql主从备份serverId,canal中不能与此相同
server-id=1
# 5.重启容器
sudo docker restart mysql5736
# 6.进入容器终端
sudo docker exec -it mysql5736 /bin/bash
# 7.登录mysql
mysql -uroot -p123456
# 8.查看字符编码是否为utf8
show variables like 'character%';
# 显示信息如下说明配置ok
+--------------------------+----------------------------+
| Variable_name | Value |
+--------------------------+----------------------------+
| character_set_client | utf8 |
| character_set_connection | utf8 |
| character_set_database | utf8 |
| character_set_filesystem | binary |
| character_set_results | utf8 |
| character_set_server | utf8 |
| character_set_system | utf8 |
| character_sets_dir | /usr/share/mysql/charsets/ |
+--------------------------+----------------------------+
8 rows in set (0.00 sec)
# 9.展示binlog日志文件
show master status;

# 10.重启日志
reset master;
# 11.查看binlog文件格式
show variables like 'binlog_format';

如果显示信息和上面一致,说明MySQL安装与配置成功,退出容器终端。
# 12.退出mysql
exit
# 13.退出容器终端
exit
4.安装elasticsearch
# 1.拉取镜像
sudo docker pull elasticsearch:7.16.2
# 2.创建容器并启动
sudo docker run --name='es7162' \
-p 9200:9200 \
-p 9300:9300 \
-e "discovery.type=single-node" \
-d elasticsearch:7.16.2
# 3.在运行的es7162容器中打开一个新的终端会话
sudo docker exec -ites es7162 /bin/bash
# 4.删除原配置文件
rm -rf config/elasticsearch.yml
# 5.新建配置文件
vi config/elasticsearch.yml
# 配置文件内容为如下
cluster.name: fox-es
network.host: 0.0.0.0
node.name: node-1
http.port: 9200
http.cors.enabled: true
http.cors.allow-origin: "*"
node.master: true
node.data: true
# 6.退出容器会话
exit
# 7.重启es
sudo docker restart es7162
浏览器测试:http://【服务器地址】:9200
注意防火墙需要开放端口

5.es安装ik中文分词器
5.1 在线安装
# 1.在运行的es7362容器中打开一个新的终端会话
sudo docker exec -ites es7162 /bin/bash
# 2.在线下载(服务器网速不好下载会比较缓慢或下载失败,则建议使用离线安装的方式)
./bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.16.2/elasticsearch-analysis-ik-7.16.2.zip
# 3.退出容器会话
exit
# 4.重启es
sudo docker restart es7162
# 5.查看日志是否加载ik分词器成功
sudo docker logs es7162

5.2 离线安装
首先打开这个链接:https://github.com/medcl/elasticsearch-analysis-ik/releases/tag/v7.16.2,把分词器插件下载下来

# 1.把下载的 zip 上传至linux服务器的 wave 文件夹下
# 2.把插件复制到容器内
sudo docker cp elasticsearch-analysis-ik-7.16.2.zip es7162:/usr/share/elasticsearch/plugins
# 3.进入容器
sudo docker exec -it es7162 /bin/bash
# 4.切换目录
cd /usr/share/elasticsearch/plugins/
# 5.创建ik目录
mkdir ik
# 6.解压zip文件
unzip elasticsearch-analysis-ik-7.16.2.zip -d ik
# 7.移除zip文件
rm -rf elasticsearch-analysis-ik-7.16.2.zip
# 8.退出容器会话
exit
# 9.重启es
sudo docker restart es7162
使用 Apipost7 测试路径:【POST方式】 http://【linux服务器IP】:9200/_analyze
// 传参如下
{
"analyzer": "ik_smart",
"text": "java名字由来"
}

出现如上信息说明ik分词器配置成功。
5.安装canal-server
# 1.拉取镜像
sudo docker pull canal/canal-server:v1.1.5
# 2.创建容器并启动
# --name canal115 为容器命名为canal115
# -p 11111:11111 表示将容器的11111端口映射到主机的11111端口
# --link mysql5736:mysql5736 表示将mysql5736容器链接到canal115容器,并且在canal115容器中可以使用mysql5736作为主机名访问mysql5736容器
# -id canal/canal-server:v1.1.5 表示使用镜像canal/canal-server:v1.1.5创建并启动一个新的后台运行的容器。
sudo docker run --name canal115 \
-p 11111:11111 \
--link mysql5736:mysql5736 \
-id canal/canal-server:v1.1.5
# 3.在运行的canal115容器中打开一个新的终端会话
sudo docker exec -it canal115 /bin/bash
# 4.修改配置文件
vi canal-server/conf/example/instance.properties
# 把0改成10,只要不和mysql的id相同就行
canal.instance.mysql.slaveId=10
# 修改成mysql对应的账号密码,mysql5736就是mysql镜像的链接别名
canal.instance.master.address=mysql5736:3306
canal.instance.dbUsername=root
canal.instance.dbPassword=123456

# 5.退出canal容器会话
exit
# 6.重启canal
sudo docker restart canal115
# 7.在运行的canal115容器中打开一个新的终端会话
sudo docker exec -it canal115 /bin/bash
# 8.进入到日志 example 目录下
cd canal-server/logs/example/
# 9.查看日志,实时查看指定日志文件的最后100行,并将新添加到日志文件中的内容实时输出到屏幕。
tail -100f example.log
截图如下,说明已经链接上了mysql主机,此时mysql中的数据变化,都会在canal中有同步。

# 10.退出日志打印
ctrl + c
# 11.退出容器
exit
6.实战开发-数据库设计
6.1 开发背景
假设有一个博客模块,即有一个博客圈,用户可以通过搜索来获取与自己输入的关键字相关的数据列表,类似于CSDN的搜索。
由于只是 demo,因此这里会设计的很简单。
6.2 数据库表设计
使用客户端连接到容器mysql5736,执行下面语句进行建表操作。
必须在安装 canal-adapter 容器前先进行建表操作,否则对 canal-adapter 修改配置后,canal-adapter会重启失败。
# 如果存在 es_demo 数据库则删除
DROP DATABASE IF EXISTS `es_demo`;
# 创建新数据库
CREATE DATABASE `es_demo`;
# 使用数据库
USE `es_demo`;
# 创建一张用户表,注意自增主键id是从1000开始
CREATE TABLE `user`(
`id` INT NOT NULL AUTO_INCREMENT COMMENT '主键id',
`username` VARCHAR(24) NOT NULL COMMENT '用户名',
`icon` VARCHAR(255) NOT NULL COMMENT '头像url',
PRIMARY KEY(`id`)
)ENGINE=INNODB AUTO_INCREMENT=1000 DEFAULT CHARSET=utf8mb4 COMMENT='用户表';
# 创建一张博客表,注意自增主键id是从1000开始
CREATE TABLE `blog`(
`id` INT NOT NULL AUTO_INCREMENT COMMENT '主键id',
`user_id` INT NOT NULL COMMENT '用户id(雪花算法生成)',
`title` VARCHAR(255) NOT NULL COMMENT '标题',
`tags` VARCHAR(64) NOT NULL COMMENT '标签',
`introduce` VARCHAR(512) NOT NULL COMMENT '介绍',
`content` TEXT NOT NULL COMMENT '文章内容',
`create_time` DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`update_time` DATETIME DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '修改时间',
PRIMARY KEY(`id`),
KEY `idx_user_create`(`user_id`,`create_time` DESC)
)ENGINE=INNODB AUTO_INCREMENT=1000 DEFAULT CHARSET=utf8mb4 COMMENT='博客信息表';
7.安装canal-adapter
# 1.镜像拉取
sudo docker pull slpcat/canal-adapter:v1.1.5
# 2.你可以选择依旧在同一台虚拟机上创建容器并启动,那么启动方式如下
sudo docker run --name adapter115 \
-p 8081:8081 \
--link mysql5736:mysql5736 \
--link canal115:canal115 \
--link es7162:es7162 \
-d slpcat/canal-adapter:v1.1.5
# 但我启动时由于服务器内存不足导致启动失败,因此我选择在另一台虚拟机上执行下面的命令
# 2.我在这里选择放到了另一台虚拟机上运行,那么就不再链接,后面修改配置文件时直接写前三个容器的所在虚拟机IP
sudo docker run --name adapter115 \
-p 8081:8081 \
-d slpcat/canal-adapter:v1.1.5
# 3.进入容器
sudo docker exec -it adapter115 /bin/bash
# 4.进入 conf 目录
cd conf/
# 5.删除原配置文件
rm -rf application.yml
# 6.新建配置文件
vi application.yml
🍀 与 mysql、es、canal-server 依旧是在一台服务器时的application.yml信息配置:
server:
port: 8081
spring:
jackson:
date-format: yyyy-MM-dd HH:mm:ss
time-zone: GMT+8
default-property-inclusion: non_null
canal.conf:
mode: tcp #tcp kafka rocketMQ rabbitMQ
flatMessage: true
zookeeperHosts:
syncBatchSize: 1000
retries: 0
timeout:
accessKey:
secretKey:
consumerProperties:
# canal tcp consumer
canal.tcp.server.host: canal115:11111
canal.tcp.zookeeper.hosts:
canal.tcp.batch.size: 500
canal.tcp.username:
canal.tcp.password:
srcDataSources:
defaultDS:
# 注意mysql容器中需要存在es_demo数据库,否则重启会报错
url: jdbc:mysql://mysql5736:3306/es_demo?useUnicode=true
username: root
password: 123456
canalAdapters:
- instance: example # canal instance Name or mq topic name
groups:
- groupId: g1
outerAdapters:
- name: logger
- name: es7
hosts: es7162:9200 # 127.0.0.1:9200 for rest mode
properties:
mode: rest
# security.auth: test:123456 # only used for rest mode
cluster.name: fox-es
🍀 与 mysql、es、canal-server 依旧不在同一台服务器时的application.yml信息配置:
server:
port: 8081
spring:
jackson:
date-format: yyyy-MM-dd HH:mm:ss
time-zone: GMT+8
default-property-inclusion: non_null
canal.conf:
mode: tcp #tcp kafka rocketMQ rabbitMQ
flatMessage: true
zookeeperHosts:
syncBatchSize: 1000
retries: 0
timeout:
accessKey:
secretKey:
consumerProperties:
# canal tcp consumer,这个192.168.65.133就是我前三个容器所在虚拟机的IP
canal.tcp.server.host: 192.168.65.133:11111
canal.tcp.zookeeper.hosts:
canal.tcp.batch.size: 500
canal.tcp.username:
canal.tcp.password:
srcDataSources:
defaultDS:
# 这个192.168.65.133就是我前三个容器所在虚拟机的IP,注意mysql容器中需要存在es_demo数据库,否则重启会报错
url: jdbc:mysql://192.168.65.133:3306/es_demo?useUnicode=true
username: root
password: 123456
canalAdapters:
- instance: example # canal instance Name or mq topic name
groups:
- groupId: g1
outerAdapters:
- name: logger
- name: es7
# 这个192.168.65.133就是我前三个容器所在虚拟机的IP
hosts: 192.168.65.133:9200 # 127.0.0.1:9200 for rest mode
properties:
mode: rest
# security.auth: test:123456 # only used for rest mode
cluster.name: fox-es
# 7.进入到 es7 目录下,注意此时依旧在容器中
cd /opt/canal-adapter/conf/es7
# 8.删除该目录下所有配置文件
rm -rf biz_order.yml customer.yml mytest_user.yml
# 9.新建配置文件
vi es_demo_collect.yml
dataSourceKey: defaultDS
destination: example
groupId: g1
esMapping:
_index: es_demo_collect
_id: _id
_type: _doc
upsert: true
# pk: id
# 这里的select语句会与数据库表设计的SQL相关联,我会创建两张表user和blog,创建的SQL我会在后面的操作中写到
sql: "
SELECT
b.id AS _id,
b.user_id AS userId,
b.title AS title,
b.tags AS tags,
b.introduce AS introduce,
b.content AS content,
b.create_time AS createTime,
b.update_time AS updateTime,
u.icon AS userIcon,
u.username AS username
FROM
blog b
LEFT JOIN user u
ON b.user_id = u.id
"
# objFields:
# _labels: array:;
# etlCondition: "where c.c_time>={}"
commitBatch: 3000
注意对于时间类型,在后端一定要使用LocalDateTime或者LocalDate类型,如果是Date类型,需要自己手动设置格式。
# 10.退出容器
exit
# 11.重启容器
sudo docker restart adapter115
# 12.查看日志信息
sudo docker logs --tail 100 adapter115

8.实战开发-创建es索引与映射
使用Apipost建立索引与映射:【PUT】 http://192.168.65.133:9200/es_demo_collect
{
"settings": {
"number_of_shards": 1,
"number_of_replicas": 0
},
"mappings": {
"properties": {
"userId": {
"type": "long"
},
"username":{
"analyzer": "ik_max_word",
"search_analyzer": "ik_smart",
"type": "text"
},
"userIcon":{
"type": "keyword",
"index": false
},
"title": {
"analyzer": "ik_max_word",
"search_analyzer": "ik_smart",
"type": "text"
},
"tags": {
"analyzer": "ik_max_word",
"search_analyzer": "ik_smart",
"type": "text"
},
"introduce":{
"analyzer": "ik_max_word",
"search_analyzer": "ik_smart",
"type": "text"
},
"content":{
"analyzer": "ik_max_word",
"search_analyzer": "ik_smart",
"type": "text"
},
"createTime":{
"format": "date_optional_time||epoch_millis",
"type": "date"
},
"updateTime":{
"format": "date_optional_time||epoch_millis",
"type": "date"
}
}
}
}
删除索引:DELETE http://192.168.65.133:9200/es_demo_collect
9.效果测试
9.1 新增记录测试
在 canal-adapter 容器所在虚拟器上执行:
# 实时检测 adapter 信息
sudo docker logs --tail 100 -f adapter115
对数据库进行如下SQL操作:
# 在建表时,我们两张表的自增主键id都是从1000开始的,因此在插入时 user_id 的测试数据也是从1000开始
INSERT INTO `user` VALUES(NULL,'狐狸半面添','https://sangxin-fox');
INSERT INTO `user` VALUES(NULL,'逐浪者','https://zhulang-fox');
INSERT INTO `blog`(`user_id`,`title`,`tags`,`introduce`,`content`) VALUES
(1001,'Java语言','编程,java,语言','Java的起源','Java最初是由任职于太阳微系统的詹姆斯-高斯林(James-Gosling)等人于1990年代初开发。最初被命名为Oak;当时发现Oak被其他公司注册了,不得不重新起名,当时他们正在咖啡馆喝着印尼爪哇(JAVA)岛出产的咖啡,有人提议就叫JAVA怎么样,然后就这样定下来了。'),
(1000,'C语言','编程,C,语言','C的起源','C语言是由美国贝尔实验室的Dennis Ritchie于1972年设计发明的,最初在UNIX操作系统的DEC PDP-11计算机上使用。它由早期的编程语言BCPL(Basic Combind Programming Language)发展演变而来。');
查看 adapter 日志信息:

查看 es 信息,使用 apipost 发送请求:【GET】http://192.168.65.133:9200/es_demo_collect/_search
// 以下是该请求需要携带的json数据,表示查询es_demo_collect索引中的全部文档数据
{
"query": {
"match_all": {}
}
}

9.2 修改记录信息测试
同时,我们可以再测试修改,我们将用户头像路径进行修改,看看 es 是否同步了新的数据:
UPDATE `user` SET icon='https:///langlang' WHERE id=1001
查看 es 信息,使用 apipost 发送请求:【GET】http://192.168.65.133:9200/es_demo_collect/_search
// 以下是该请求需要携带的json数据,表示查询es_demo_collect索引中的全部文档数据
{
"query": {
"match_all": {}
}
}

10.实战开发-后端代码
以下只展示我认为比较与本文相关的比较重要的文件,完整源码的获取链接我会放在文章的最后。
10.1 pom.xml依赖
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.fox</groupId>
<artifactId>elasticsearch-canal-demo</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
<version>2.6.3</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.24</version>
</dependency>
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
<version>7.8.0</version>
</dependency>
<!--fastjson依赖-->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.33</version>
</dependency>
<dependency>
<groupId>cn.hutool</groupId>
<artifactId>hutool-all</artifactId>
<version>5.8.7</version>
</dependency>
</dependencies>
</project>
10.2 application.yml配置
server:
# 服务端口
port: 9999
elasticsearch:
# es访问ip
hostname: 192.168.65.133
# es访问port
port: 9200
blog:
# 访问索引
index: es_demo_collect
# 搜索返回字段
source_fields: userId,title,username,userIcon,introduce,createTime,updateTime
10.3 ElasticsearchConfig.java配置类
package com.fox.es.config;
import org.apache.http.HttpHost;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestClientBuilder;
import org.elasticsearch.client.RestHighLevelClient;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
/**
* @author 狐狸半面添
* @create 2023-03-22 17:51
*/
@Configuration
public class ElasticsearchConfig {
@Value("${elasticsearch.hostname}")
private String hostname;
@Value("${elasticsearch.port}")
private Integer port;
@Bean
public RestHighLevelClient restHighLevelClient() {
RestClientBuilder builder = RestClient.builder(
new HttpHost(hostname, port, "http")
);
return new RestHighLevelClient(builder);
}
}
10.4 ⭐测试是否连接 es 成功
package com.fox.es.controller;
import com.fox.es.entity.Result;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.client.core.MainResponse;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RestController;
import javax.annotation.Resource;
import java.io.IOException;
/**
* @author 狐狸半面添
* @create 2023-03-22 18:33
*/
@RestController
public class TestController {
@Resource
private RestHighLevelClient restHighLevelClient;
/**
* 用于测试是否连接 es 成功
*
* @return 返回 es 的基本信息,等价于访问:http://127.0.0.1:9200
* @throws IOException 异常信息
*/
@GetMapping("/getEsInfo")
public Result getEsInfo() throws IOException {
MainResponse info = restHighLevelClient.info(RequestOptions.DEFAULT);
return Result.ok(info);
}
}
浏览器访问:http://localhost:9999/getEsInfo

10.5 ⭐搜索服务
10.5.1 controller层
package com.fox.es_canal.controller;
import com.fox.es_canal.constant.BlogConstants;
import com.fox.es_canal.entity.Result;
import com.fox.es_canal.service.BlogService;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;
import javax.annotation.Resource;
/**
* @author 狐狸半面添
* @create 2023-03-22 20:16
*/
@RestController
@RequestMapping("/blog")
public class BlogController {
@Resource
private BlogService blogService;
/**
* 通过关键词获取数据列表
*
* @param keyWords 关键词
* @param pageNo 页码
* @return 数据列表,按照相关性从高到低进行排序
*/
@GetMapping("/list")
public Result list(@RequestParam("keyWords") String keyWords,
@RequestParam("pageNo") Integer pageNo) {
// BlogConstants是我写的一个常量类,里面定义了一个变量 SEARCH_PAGE_NUM = 15
return blogService.list(keyWords, pageNo, BlogConstants.SEARCH_PAGE_NUM);
}
}
10.5.2 service接口层
package com.fox.es_canal.service;
import com.fox.es_canal.entity.Result;
/**
* @author 狐狸半面添
* @create 2023-03-22 20:18
*/
public interface BlogService {
/**
* 通过关键词获取数据列表
*
* @param keyWords 关键词
* @param pageNo 页码
* @param pageSize 每页大小
* @return 数据列表,按照相关性从高到低进行排序
*/
Result list(String keyWords, int pageNo, int pageSize);
}
10.5.3 service实现层
package com.fox.es_canal.service.impl;
import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.JSONObject;
import com.fox.es_canal.dto.BlogSimpleInfoDTO;
import com.fox.es_canal.entity.Result;
import com.fox.es_canal.service.BlogService;
import lombok.extern.slf4j.Slf4j;
import org.elasticsearch.action.search.SearchRequest;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.common.text.Text;
import org.elasticsearch.index.query.BoolQueryBuilder;
import org.elasticsearch.index.query.MultiMatchQueryBuilder;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.search.SearchHit;
import org.elasticsearch.search.SearchHits;
import org.elasticsearch.search.builder.SearchSourceBuilder;
import org.elasticsearch.search.fetch.subphase.highlight.HighlightBuilder;
import org.elasticsearch.search.fetch.subphase.highlight.HighlightField;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.stereotype.Service;
import org.springframework.util.StringUtils;
import javax.annotation.Resource;
import java.io.IOException;
import java.time.LocalDateTime;
import java.time.format.DateTimeFormatter;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
/**
* @author 狐狸半面添
* @create 2023-03-22 20:18
*/
@Slf4j
@Service
public class BlogServiceImpl implements BlogService {
@Resource
private RestHighLevelClient restHighLevelClient;
@Value("${elasticsearch.blog.index}")
private String blogIndexStore;
@Value("${elasticsearch.blog.source_fields}")
private String blogFields;
public Result list(String keyWords, int pageNo, int pageSize) {
// 1.设置索引 - blog
SearchRequest searchRequest = new SearchRequest(blogIndexStore);
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery();
// 2.source源字段过虑
String[] sourceFieldsArray = blogFields.split(",");
searchSourceBuilder.fetchSource(sourceFieldsArray, new String[]{});
// 3.关键字
if (StringUtils.hasText(keyWords)) {
// 哪些字段匹配关键字
MultiMatchQueryBuilder multiMatchQueryBuilder = QueryBuilders.multiMatchQuery(keyWords, "title", "tags", "username", "introduce", "content");
// 设置匹配占比(表示最少匹配的子句个数,例如有五个可选子句,最少的匹配个数为5*70%=3.5.向下取整为3,这就表示五个子句最少要匹配其中三个才能查到)
multiMatchQueryBuilder.minimumShouldMatch("70%");
// 提升字段的Boost值
multiMatchQueryBuilder.field("title", 15);
multiMatchQueryBuilder.field("tags", 10);
multiMatchQueryBuilder.field("introduce", 7);
multiMatchQueryBuilder.field("content", 3);
multiMatchQueryBuilder.field("username", 3);
boolQueryBuilder.must(multiMatchQueryBuilder);
}
// 4.分页
int start = (pageNo - 1) * pageSize;
searchSourceBuilder.from(start);
searchSourceBuilder.size(pageSize);
// 布尔查询
searchSourceBuilder.query(boolQueryBuilder);
// 6.高亮设置
HighlightBuilder highlightBuilder = new HighlightBuilder();
highlightBuilder.preTags("<font color='red'>");
highlightBuilder.postTags("</font>");
// 设置高亮字段
ArrayList<HighlightBuilder.Field> fields = new ArrayList<>();
fields.add(new HighlightBuilder.Field("title"));
fields.add(new HighlightBuilder.Field("introduce"));
fields.add(new HighlightBuilder.Field("username"));
highlightBuilder.fields().addAll(fields);
searchSourceBuilder.highlighter(highlightBuilder);
// 请求搜索
searchRequest.source(searchSourceBuilder);
SearchResponse searchResponse;
try {
searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
} catch (IOException e) {
log.error("博客搜索异常:{}", e.getMessage());
return Result.error(e.getMessage());
}
// 结果集处理
SearchHits hits = searchResponse.getHits();
SearchHit[] searchHits = hits.getHits();
// 记录总数
long totalHitsCount = hits.getTotalHits().value;
// 数据列表
List<BlogSimpleInfoDTO> list = new ArrayList<>();
for (SearchHit hit : searchHits) {
JSONObject jsonObject = JSONObject.parseObject(hit.getSourceAsString());
BlogSimpleInfoDTO blog = new BlogSimpleInfoDTO();
blog.setId(Integer.parseInt(hit.getId()));
blog.setUsername(jsonObject.getString("username"));
blog.setTitle(jsonObject.getString("title"));
blog.setUserId(Long.parseLong(jsonObject.getString("userId")));
blog.setUserIcon(jsonObject.getString("userIcon"));
blog.setIntroduce(jsonObject.getString("introduce"));
blog.setCreateTime(LocalDateTime.parse(jsonObject.getString("createTime"), DateTimeFormatter.ISO_OFFSET_DATE_TIME));
blog.setUpdateTime(LocalDateTime.parse(jsonObject.getString("updateTime"), DateTimeFormatter.ISO_OFFSET_DATE_TIME));
// 取出高亮字段内容
Map<String, HighlightField> highlightFields = hit.getHighlightFields();
if (highlightFields != null) {
blog.setTitle(parseHighlightStr(blog.getTitle(), highlightFields.get("title")));
blog.setIntroduce(parseHighlightStr(blog.getIntroduce(), highlightFields.get("introduce")));
blog.setUsername(parseHighlightStr(blog.getUsername(), highlightFields.get("username")));
}
list.add(blog);
}
// 封装信息返回前端
HashMap<String, Object> resultMap = new HashMap<>(4);
// 页码
resultMap.put("pageNo", pageNo);
// 每页记录数量
resultMap.put("pageSize", pageSize);
// 总记录数
resultMap.put("total", totalHitsCount);
// 该页信息
resultMap.put("items", list);
return Result.ok(resultMap);
}
public String parseHighlightStr(String text, HighlightField field) {
if (field != null) {
Text[] fragments = field.getFragments();
StringBuilder stringBuilder = new StringBuilder();
for (Text str : fragments) {
stringBuilder.append(str.string());
}
return stringBuilder.toString();
} else {
return text;
}
}
}
10.5.4 效果测试
这里我们使用 apipost7 或浏览器 进行测试:


11.源码获取
Java源码地址:Mr-Write/SpringbootDemo: 各种demo案例 (github.com)
对应的是 elasticsearch-canal-demo 包模块。
12.其它说明
当我们在Java中写出往MySQL数据库添加、删除、修改博客记录的操作接口时,会同时通过 Canal 同步到es中,因为 canal 同步的本质还是去读 MySQL的 binlog 日志。由于比较简单,在这里就不做演示了。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 5
5 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)