playwright连接已有浏览器操作
之前有写过一篇selenium打开指定浏览器进行自动化操作的文章(链接见后文),但那篇需要自己通过bat文件去启动浏览器。而且还要下载对应的驱动。playwright就不需要下载驱动,它自己有,你浏览器版本可以不用管了,而且这个时候,你可以通过launch_persistent_context方法直接在代码中添加已有缓存的谷歌浏览器,并且指定端口打开,你以后全部由代码来跑就可以了。
前置准备
# 安装playwright的python版本
pip install playwright
# 安装playwright自带的浏览器和ffmepg,此步骤耗时较长
playwright install
打开本地已有缓存的Chrome(理解)
之前有写过一篇selenium打开指定浏览器进行自动化操作的文章(链接见后文),但那篇需要自己通过bat文件去启动浏览器。而且还要下载对应的驱动。
playwright就不需要下载驱动,它自己有,你浏览器版本可以不用管了,而且这个时候,你可以通过launch_persistent_context方法直接在代码中添加已有缓存的谷歌浏览器,并且指定端口打开,你以后全部由代码来跑就可以了。
# -*- coding: utf-8 -*-
'''
@Time : 2023/4/28 12:29
@Author : Vincent.xiaozai
@Email : Lvan826199@163.com
@File : playwright_demo1.py
'''
__author__ = "梦无矶小仔"
import time
from playwright.sync_api import Playwright,sync_playwright
# C:\Users\xiaozai\AppData\Local\ms-playwright
with sync_playwright() as playwright:
browser = playwright.chromium.launch_persistent_context(
# 指定本机用户缓存地址
user_data_dir=r"C:\Users\xiaozai\AppData\Local\Google\Chrome\User Data",
# 指定本机google客户端exe的路径
executable_path=r"C:\Users\xiaozai\AppData\Local\Google\Chrome\Application\chrome.exe",
# 要想通过这个下载文件这个必然要开 默认是False
accept_downloads=True,
# 设置不是无头模式
headless=False,
bypass_csp=True,
slow_mo=10,
# 跳过检测
args = ['--disable-blink-features=AutomationControlled','--remote-debugging-port=9222']
)
page = browser.new_page()
page.goto("https://www.baidu.com/")
print(page.title())
time.sleep(200)
browser.close()
user_data_dir:此文件夹就是你电脑本地所在的缓存文件夹,可以是系统默认的,也可以是你自己新建的
args处常用参数请参考下表。
| 序号 | 参数 | 说明 |
|---|---|---|
| 1 | --allow-outdated-plugins | 不停用过期的插件。 |
| 2 | --allow-running-insecure-content | 默认情况下,https 页面不允许从 http 链接引用 javascript/css/plug-ins。添加这一参数会放行这些内容。 |
| 3 | --allow-scripting-gallery | 允许拓展脚本在官方应用中心生效。默认情况下,出于安全因素考虑这些脚本都会被阻止。 |
| 4 | --disable-desktop-notifications | 禁用桌面通知,在 Windows 中桌面通知默认是启用的。 |
| 5 | --disable-file-system | 停用 FileSystem API。 |
| 6 | --disable-preconnect | 停用 TCP/IP 预连接。 |
| 7 | --disable-remote-fonts | 关闭远程字体支持。SVG 中字体不受此参数影响。 |
| 8 | --disable-web-security | 不遵守同源策略。 |
| 9 | --disk-cache-dir | 将缓存设置在给定的路径。 |
| 10 | --disk-cache-size | 设置缓存大小上限,以字节为单位。 |
| 11 | --dns-prefetch-disable | 停用DNS预读。 |
| 12 | --enable-print-preview | 启用打印预览。 |
| 13 | --extensions-update-frequency | 设定拓展自动更新频率,以秒为单位。 |
| 14 | --incognito | 让浏览器直接以隐身模式启动。 |
| 15 | --keep-alive-for-test | 最后一个标签关闭后仍保持浏览器进程。(某种意义上可以提高热启动速度,不过你最好得有充足的内存) |
| 16 | --kiosk | 启用kiosk模式。(一种类似于全屏的浏览模式) |
| 17 | --lang | 使用指定的语言。 |
| 18 | --no-displaying-insecure-content | 默认情况下,https 页面允许从 http 链接引用图片/字体/框架。添加这一参数会阻止这些内容。 |
| 19 | --no-referrers | 不发送 Http-Referer 头。 |
| 20 | --no-startup-window | 启动时不建立窗口。 |
| 21 | --proxy-server | 使用给定的代理服务器,这个参数只对 http 和 https 有效。 |
| 22 | --start-maximized | 启动时最大化。 |
| 23 | --single-process | 以单进程模式运行 Chromium。(启动时浏览器会给出不安全警告)。 |
| 24 | --user-agent | 使用给定的 User-Agent 字符串。 |
| 25 | --process-per-tab | 每个分页使用单独进程。 |
| 26 | --process-per-site | 每个站点使用单独进程。 |
| 27 | --in-process-plugins | 插件不启用单独进程。 |
| 28 | --disable-popup-blocking | 禁用弹出拦截。 |
| 29 | --disable-javascript | 禁用JavaScript。 |
| 30 | --disable-java | 禁用Java。 |
| 31 | --disable-plugins | 禁用插件。 |
| 32 | –disable-images | 禁用图像。 |
| 33 | --remote-debugging-port | 在指定端口上启用HTTP远程调试 |
launch_persistent_context可填参数可以查看源码,playwright -> sync_api -> _generated.py
运行效果展示:
看到右上角了吗?是登陆状态的,说明加载了我的用户信息,你可以打开一个新的标签页,你还会发现里面有你的标签。
指定端口打开浏览器
就字面意思,emmmm,貌似目前我还没有遇到需要用这个的场景。还是用前面那个方法结合着用好。
from playwright.sync_api import sync_playwright
playwright = sync_playwright().start()
# 指定端口打开浏览器
browser = playwright.chromium.launch(headless=False, args=['--remote-debugging-port=9001'])
time.sleep(10)
page = browser.new_page()
page.goto("https://www.baidu.com/")
print(page.title())
time.sleep(10)
browser.close()
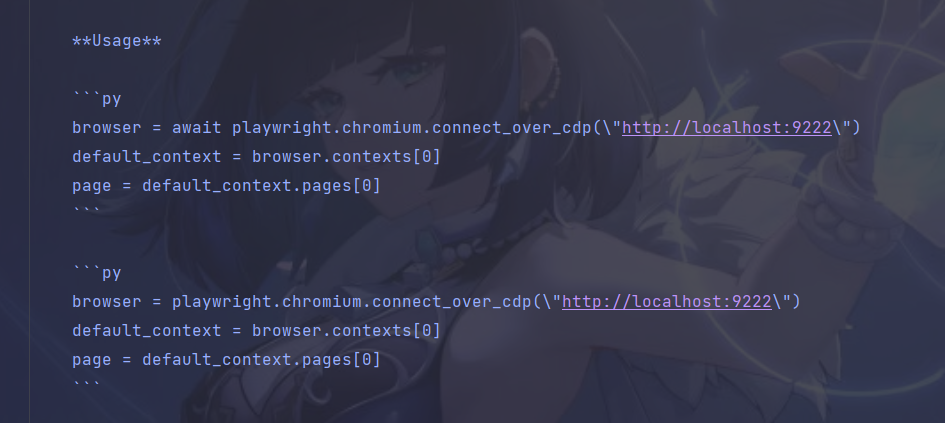
连接指定端口已启动浏览器(推荐)
这个方案就是不使用launch_persistent_context方法,需要自己手动启动一个浏览器(或者使用命令),之后让playwright连接上这个浏览器进行自动化操作。
「前置操作」
需要通过命令启动一个特定的浏览器,这里我做了一个bat文件,详细方法参考之前的文章:
公众号:伤心的辣条
@echo off
chrome.exe --remote-debugging-port=9222 --user-data-dir="C:\selenium\AutomationProfile"
我们先通过该命令快捷启动浏览器,之后就可以通过代码连接上该浏览器了。
# 可以使用bat手动打开该浏览器,也可以通过如下命令打开
command = r"C:\Users\xiaozai\AppData\Local\Google\Chrome\Application\chrome.exe --remote-debugging-port=9222 --user-data-dir=C:\selenium\AutomationProfile"
subprocess.Popen(command)
time.sleep(5)
playwright = sync_playwright().start()
# 连接已打开浏览器,找好端口
browser = playwright.chromium.connect_over_cdp("http://127.0.0.1:9222")
default_context = browser.contexts[0] # 注意这里不是browser.new_page()了
page = default_context.pages[0]
page.goto("https://www.baidu.com/")
print(page.title()) #百度一下,你就知道
后面打开page这里为什么是这样写呢?我抄的源码示列的,诶嘿嘿
关键字:浏览器上下文

最后启动的浏览器效果和前面的展示效果都是一样的
最后: 下方这份完整的软件测试视频学习教程已经整理上传完成,朋友们如果需要可以自行免费领取【保证100%免费】

这些资料,对于【软件测试】的朋友来说应该是最全面最完整的备战仓库,这个仓库也陪伴上万个测试工程师们走过最艰难的路程,希望也能帮助到你!



腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 5
5 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)