【透彻】java关于HashMap多线程扩容导致死循环(JDK1.7)的详细过程
本篇主要通过图解的方式,解释了为什么JDK1.7中的HashMap在多线程情况下扩容可能死循环,也解释了JDK1.8如何解决这个问题。不得不说,画图是个很好的分析方式,根据代码,一步一步把结构图画出来,比对着代码瞎琢磨效果好多了。我在原文基础上把第二张图(多线程那张图)修改了一下,因为原作者画的图有些问题(原图的最后9个隔断应该是newTable的,而原作者给画成了table的)HashMap多线
# 前言
JDK1.7中的HashMap在多线程情况下扩容可能会导致死循环。本文就这个问题进行讲解。
# 扩容死循环
这里回顾一下HashMap1.7扩容的过程,在扩容过程中,单链表的表现,相关的代码如下:
Jdk1.7:
void resize(int newCapacity) {
Entry[] oldTable = table;
int oldCapacity = oldTable.length;
//如果旧容量已经达到了最大,将阈值设置为最大值,与1.8相同
if (oldCapacity == MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return;
}//创建新哈希表
Entry[] newTable = new Entry[newCapacity];
//将旧表的数据转移到新的哈希表
transfer(newTable, initHashSeedAsNeeded(newCapacity));
//替换掉原“全局所有线程共享的table”
table = newTable;
//更新阈值
threshold = (int)Math.min(newCapacity * loadFactor, MAXIMUM_CAPACITY + 1);
}
其中最重要的就是transfer()方法:
void transfer(Entry[] newTable, boolean rehash) {
int newCapacity = newTable.length;
// 外层循环遍历数组槽(slot)
for (Entry<K,V> e : table) {
// 内层循环遍历单链表
while(null != e) {
// 记录当前节点的next节点
Entry<K,V> next = e.next;
if (rehash) {
e.hash = null == e.key ? 0 : hash(e.key);
}
// 找到元素在新数组中的槽(slot)
int i = indexFor(e.hash, newCapacity);
// 用头插法将元素插入新的数组
e.next = newTable[i];
newTable[i] = e;
// 遍历下一个节点
e = next;
}
}
}
一、先看单线程
在单线程情况下,假设A、B、C三个节点处在一个链表上,扩容后依然处在一个链表上,代码执行过程如下:
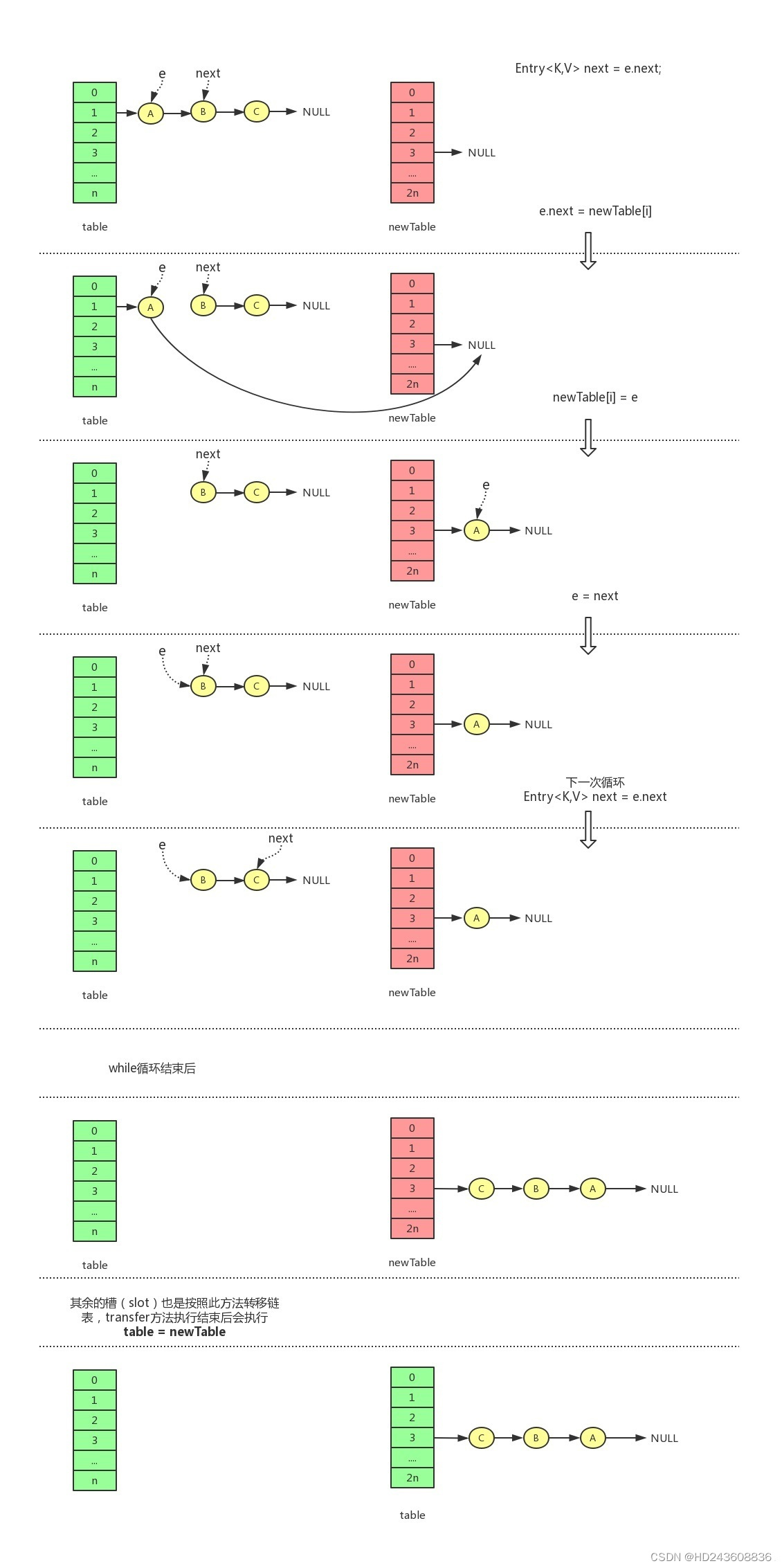
需要注意的几点是:
- 单链表在转移的过程中会被反转
table是线程共享的,而newTable是不共享的(线程私有的)- 执行
table = newTable后,其他线程就立即可以看到转移线程转移后的结果了
二、再看多线程
理解了单线程下链表在扩容时的行为,再来看多线程的情况就比较容易了。还是关注transfer方法这段代码:
void transfer(Entry[] newTable, boolean rehash) {
int newCapacity = newTable.length;
for (Entry<K,V> e : table) {
while(null != e) {
Entry<K,V> next = e.next;
if (rehash) {
e.hash = null == e.key ? 0 : hash(e.key);
}
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e; // *线程1在这行暂停(尚未执行该行)
e = next;
}
}
}
代码执行过程如下:
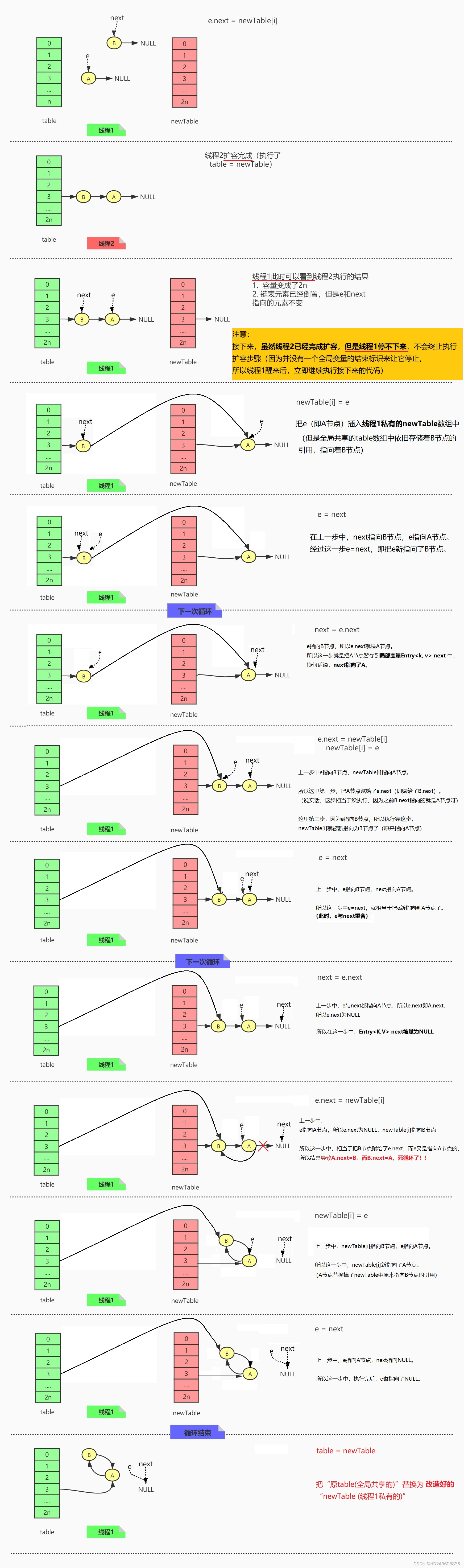
- 线程1执行
newTable[i] = e时暂停(未执行) - 线程2直接扩容完成
- 线程1继续执行,此时线程1可以看到线程2扩容后的结果。但是线程1却停不下来,最终导致死循环。
图中已经画出了每一行代码执行后,
HashMap的结构图,仔细观察图中的结构变化,就能理解为什么会死循环。
由此,完完整整的解释了为什么多线程情况下,JDK1.7版本的HashMap扩容有可能出现死循环。
# 补充:
JDK1.8改进
JDK1.8中扩容的方法是resize,对应的代码是(HashMap中第715行至第742行):
// 低位链表头节点,尾结点
// 低位链表就是扩容前后,所处的槽(slot)的下标不变
// 如果扩容前处于table[n],扩容后还是处于table[n]
Node<K,V> loHead = null, loTail = null;
// 高位链表头节点,尾结点
// 高位链表就是扩容后所处槽(slot)的下标 = 原来的下标 + 新容量的一半
// 如果扩容前处于table[n],扩容后处于table[n + newCapacity / 2]
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
do {
next = e.next;
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
if (loTail != null) {
loTail.next = null;
// 低位链表在扩容后,所处槽的下标不变
newTab[j] = loHead;
}
if (hiTail != null) {
hiTail.next = null;
// 高位链表在扩容后,所处槽的下标 = 原来的下标 + 扩容前的容量(也就是扩容后容量的一半)
newTab[j + oldCap] = hiHead;
}注意第12行的代码(e.hash & oldCap) == 0就可以判断,当前槽上的链表在扩容前和扩容后,所在的槽(slot)下标是否一致。举个例子:
假如一个key的hash值为1001 1100,转换成十进制就是156,数组长度为1000,转换成十进制就是8。
1001 1100
& 0000 1000
--------------
0000 1000也就是(e.hash & oldCap) != 0,很容易计算出,扩容前这个key的下标是4(156 % 8 = 4),扩容后下标是12(156 % 16 = 12)即:12 = 4 + 16 / 2,满足n = n + newCapacity / 2,由此可以看出这种计算方式非常巧妙。至于第12行之后的代码就是基本的单链表操作了,只是一个单链表同时具有头指针和尾指针,等到链表被分成高位链表和低位链表后,再一次性转移到新的table。这样就完成了单链表在扩容过程中的转移,使用两条链表的好处就是转移前后的链表不会倒置,更不会因为多线程扩容而导致死循环。
总结
- jdk7使用头插法,在扩容时,旧数组(n)向新数组(2n)转移过程中,会导致改变链表上元素的先后顺序(反转)。
- jdk8使用尾插法,在扩容时,会保持链表元素原本的顺序。就不会出现链表“成环”的问题了。
本篇主要通过图解的方式,解释了为什么JDK1.7中的HashMap在多线程情况下扩容可能死循环,也解释了JDK1.8如何解决这个问题。不得不说,画图是个很好的分析方式,根据代码,一步一步把结构图画出来,比对着代码瞎琢磨效果好多了。
我在原文基础上把第二张图(多线程那张图)修改了一下。因为原作者画的图有些问题(原图的最后9个隔断应该是newTable的,而原作者给画成了table的)。
感谢知乎原文评论 @成都锅锅小蓝田 的提醒!!

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐



 6
6 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)