
python代码加密执行(如何保护你的Python源码)
在软件开发中,代码安全是一个重要的课题。Python 代码由于以源码形式直接部署到服务器并通过解释器执行,容易暴露其中的敏感信息,如 API 密钥、加密盐等。为了解决这一问题,开发者需要采取有效的措施对代码进行加密或保护。本文将详细探讨几种常见的方案,包括编译为可执行文件、生成字节码文件、代码混淆以及基于动态解密的自定义解释器等。这些方法各有特点,可根据实际需求选择适合的方案。第一种方法是编译为可
摘要
在软件开发中,代码安全是一个重要的课题。Python 代码由于以源码形式直接部署到服务器并通过解释器执行,容易暴露其中的敏感信息,如 API 密钥、加密盐等。为了解决这一问题,开发者需要采取有效的措施对代码进行加密或保护。本文将详细探讨几种常见的方案,包括编译为可执行文件、生成字节码文件、代码混淆以及基于动态解密的自定义解释器等。这些方法各有特点,可根据实际需求选择适合的方案。
第一种方法是编译为可执行文件,通过工具(如 PyInstaller、py2exe)将 Python 源码打包为平台相关的可执行文件,避免直接暴露源码。这种方法简单易用,但存在逆向工程的风险。
第二种方法是将代码编译为 pyc 文件,即 Python 的字节码文件。这可以通过 python -m compileall 等工具生成。虽然 pyc 文件在一定程度上隐藏了源码,但也容易被反编译工具(如 uncompyle6)还原,安全性有限。
第三种方法是代码混淆,利用工具(如 pyarmor)对源码进行逻辑混淆或变量重命名,使其变得难以理解。这种方法可以提高代码的逆向难度,但仍无法完全杜绝还原的可能。
第四种方法是Cython库加密代码,Cython 的主要目的是带来性能的提升,但是基于它的原理:将 .py/.pyx 编译为 .c 文件,再将 .c 文件编译为 .so(Unix) 或 .pyd(Windows),其带来的另一个好处就是难以破解。
最后一种方法是修改 Python 解释器源码,实现动态解密机制。通过这种方式,源码以加密形式存储,只有在执行时由自定义的 Python 解释器解密。这种方案复杂度较高,但安全性相对较强。
本文还将对比这些方法的优缺点,包括其易用性、性能影响、安全性和适用场景,帮助开发者选择合适的解决方案。同时,我们还会介绍如何结合多种方法提升代码保护效果,以最大限度地降低代码被盗用或敏感信息泄露的风险。
编译原理简介
日常开发过程中我们使用的语言一般都是高级语法比如 JAVA、Python、PHP、JavaScript等等,但是计算机只能识别0、1这样的机器码。那么这些高级语言是如何翻译成机器能识别的0、1等呢?
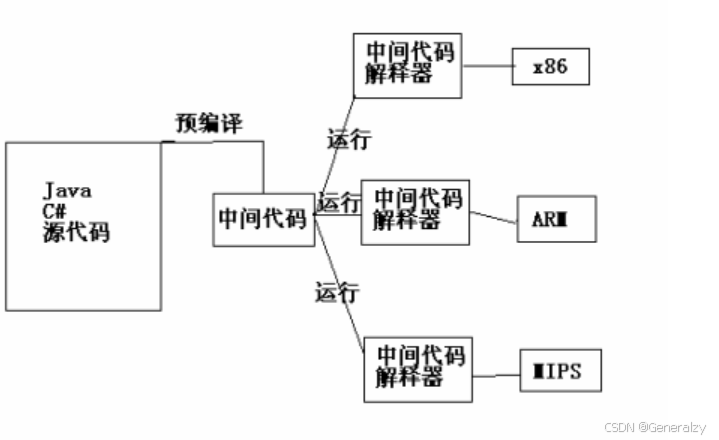
这就用的了编译,首先我们通过下面这幅图看下编译与计算机程序语言的关系,有助于我们直观的了解编译的作用。
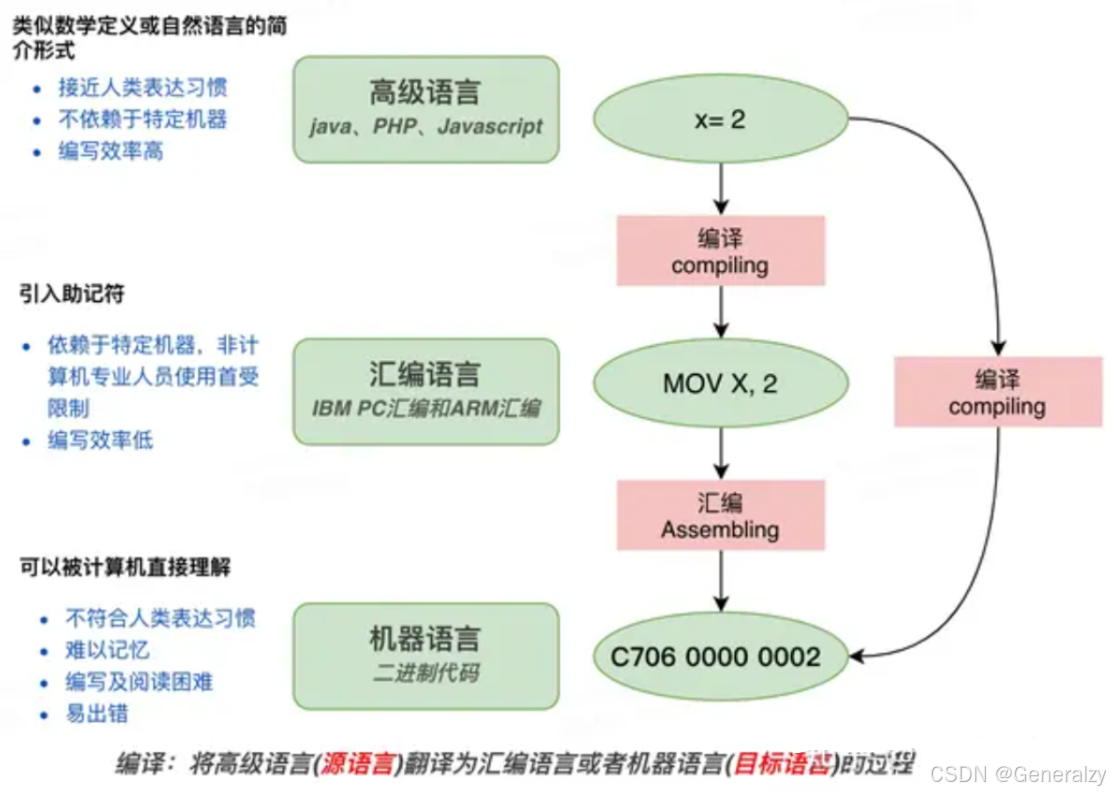
注意:每种机器都对应一种汇编语言,即汇编语言和机器架构是紧密耦合的,不能跨机器通用。每种机器架构的设计决定了其汇编语言的指令集,程序员在编写低级程序时必须根据具体机器的架构选择合适的汇编语言。
不同的计算机硬件架构(如x86、ARM、RISC-V等)对应的汇编语言是不同的。原因在于,汇编语言是机器码的文本化表达形式,而机器码直接依赖于具体硬件的指令集架构(ISA,Instruction Set Architecture)。以下是一些关键点来解释这句话的含义:
机器码与指令集架构(ISA)相关联 每种硬件架构都有一套独特的指令集,规定了处理器如何解释和执行二进制指令。比如,x86 架构和 ARM
架构的指令集不同,因此它们的机器码格式也不相同。汇编语言是机器码的可读形式 汇编语言提供了对机器码的更人性化的表示,用助记符(如
MOV、ADD等)替代二进制指令,同时还支持一些伪指令和注释,便于程序员编写和阅读。但这些汇编指令的具体含义和语法完全依赖于底层硬件架构。每种机器对应一种汇编语言 由于机器码和指令集是由硬件架构决定的,因此汇编语言必须匹配相应的机器架构。例如:
- 在 x86 上,
MOV AX, BX是合法的汇编指令。- 在 ARM 上,可能需要用
MOV R0, R1来完成类似的操作。 不同架构之间的汇编代码通常不可直接移植。假设有两台不同架构的机器:
- 机器 A 使用 x86 架构,其指令集支持
MOV AX, BX将寄存器 BX 的值移动到寄存器 AX。- 机器 B 使用 ARM 架构,其指令集支持
MOV R0, R1完成类似操作。 由于两台机器的硬件设计不同,汇编语言的语法、指令和功能也会不同。
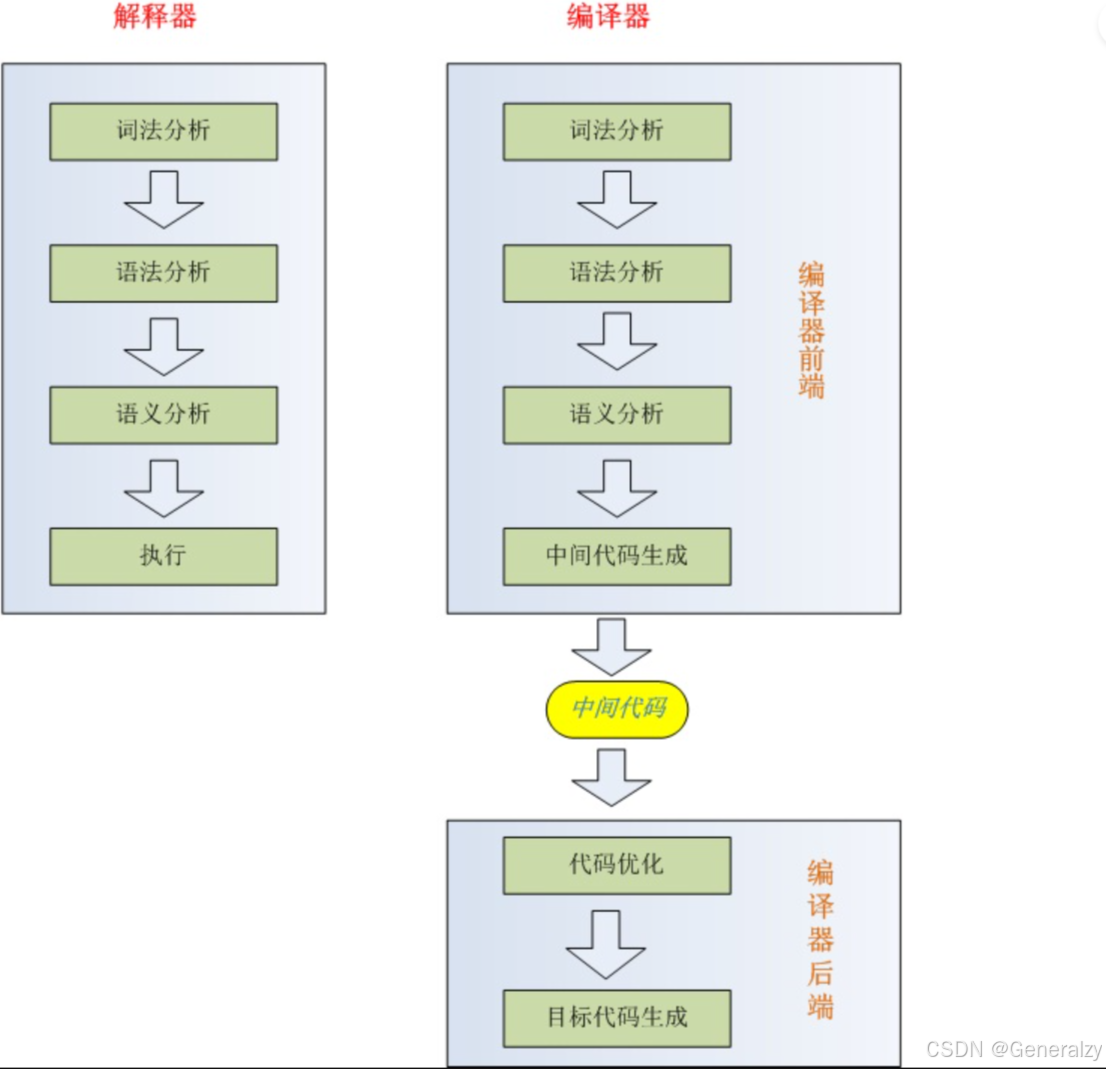
程序设计语言的转换方式真正的实现有两种方式,编译及解释:
-
编译:专指由高级语言转换为低级语言,整个程序翻译。常用的例如: c、c++,delphi,Fortran、Pascal、Ada
-
解释:接受某种高级语言的一个语句输入,进行解释并控制计算机执行,马上得到这个句子的执行结果,然后再接受下一个语句。类似口译,一句一句进行解释。常用的例如:python。解释以源程序作为输入,不产生目标程序,一边解释一边执行。优点:直观易懂,结构简单,易于实现人机对话。缺点:效率低(不产生目标程序,每次都需要重新执行,速度慢)
解释器的优点是比较容易让用户实现自己跨平台的代码,比如java,php等,同一套代码可以在几乎所有的操作系统上执行,而无需根据操作系统做修改;
编译器的目的就是生成目标代码再由连接器生成可执行的机器码,这样的话需要根据不同的操作系统编制代码,虽然有像Qt这样的源代码级跨平台的编程工具库,但在不同的平台上仍然需要重新编译连接成可执行文件,但其执行效率要远远高于解释运行的程序。
源代码被编译成机器码,在CPU上运行: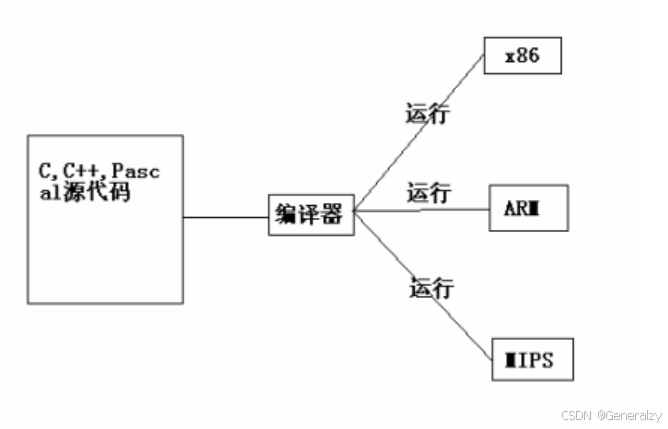
而解释器是这样的:
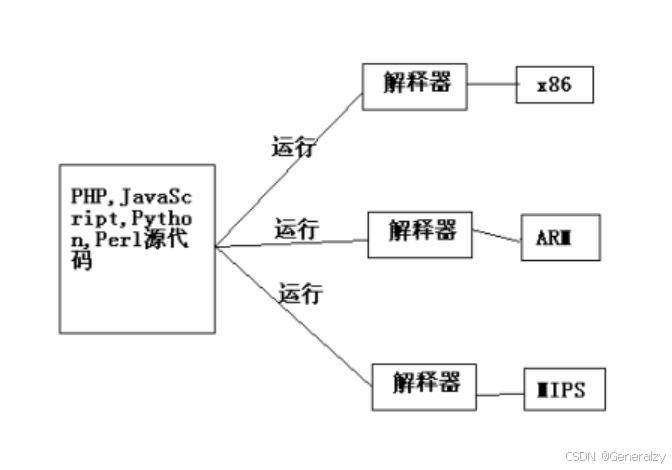
用解释器很方便,只需要直接“运行”就好了,不用像C那样有编译链接的工序。
为什么说这些语言是跨平台的?因为你写了程序以后,如果这个平台上有这种语言的解释器,只需要拿到这个平台上直接运行就可以了。你可以理解为:解释器是在“一边编译,一边运行”,它只是把以前程序员手工做的编译过程放在了运行程序的时候进行。
为什么我们一般说解释器的效率比较低?你也可以想象的是,一段程序在解释器中运行时可能会被编译多次,因为每次运行到这段程序时,都会重新编译一次,这样的开销是很大的。
所以很多如java,python这样的解释型语言引入了预编译的概念,
python解释器工作原理
Python 不是纯解释型语言,它确实引入了类似预编译的概念。这是 Python 工作机制中的一个重要特点。虽然 Python 通常被归类为解释型语言,但它的运行流程并不仅仅是逐行解释源码,而是分为以下几个步骤:
-
源码编译为字节码
当执行 Python 脚本时,Python 会先将.py源文件编译为中间形式的字节码(.pyc文件)。这个过程类似于编译语言的预编译阶段,但与传统编译语言(如 C/C++)不同,Python 的字节码不是直接面向硬件的机器码,而是一种抽象的中间表示。特性:
- 字节码是一种面向 Python 虚拟机(PVM)的指令集。
- 编译的过程通常是自动完成的,开发者无需手动干预。
示例:
python -m compileall script.py上述命令会生成
script.py的字节码文件。 -
Python 虚拟机(PVM)解释执行字节码
Python 使用虚拟机(PVM, Python Virtual Machine)加载并逐条解释执行字节码。这是 Python 的解释过程,因此它仍然保留了解释型语言的特性。 -
缓存机制
Python 会将编译生成的字节码缓存为.pyc文件,存储在__pycache__目录下。如果再次运行相同的脚本且源码没有更改,Python 会直接加载.pyc文件,而无需重新编译,从而提升执行效率。
为什么说 Python 不是纯解释型语言?
-
引入了编译阶段
在运行之前,Python 的确会先将源码编译为字节码(.pyc),这与纯粹逐行解释执行的语言(如传统的 BASIC)有显著区别。 -
存在中间代码表示(字节码)
字节码是一种预处理后的中间代码,脱离了具体的源码形式,可以被直接加载和执行。这种机制类似于 Java 的字节码(.class文件)被 JVM 执行。 -
提升性能的优化
通过字节码缓存(.pyc文件),Python 避免了每次执行都重新编译的开销,这是一种折中方式,兼顾了开发效率和执行效率。
虽然 Python 的核心运行机制依赖于解释器,但它并不是“逐行解释源码”的纯解释型语言。通过编译为字节码的预处理阶段,Python 结合了编译型语言的某些特性。可以将其理解为一种**“半编译型语言”**,介于传统编译型和纯解释型语言之间。这样的设计既保留了开发灵活性,又在性能上进行了优化。
pyc 文件是什么?
.pyc 文件是 Python 编译器生成的字节码文件**,它是对 Python 源代码(.py 文件)的编译结果。字节码是一种中间形式的代码,它既不是源码,也不是机器码,而是介于两者之间的一个中间表示。Python 在解释执行脚本时,会首先将 .py 文件编译成字节码文件(.pyc),然后由 Python 虚拟机(PVM, Python Virtual Machine)对字节码进行逐行解释执行。
通常,.pyc 文件会被存放在 __pycache__ 目录中,文件名后会带有 Python 版本信息。例如,example.cpython-310.pyc 表示由 CPython 3.10 生成的字节码。
pyc 文件有什么作用?
-
提高程序启动速度
当 Python 脚本被多次运行时,.pyc文件可以避免重复编译源码为字节码的过程。Python 会直接加载已存在的.pyc文件,从而节省启动时间,提高运行效率。 -
隐藏源码
在一定程度上,.pyc文件可以隐藏源码逻辑。因为.pyc是字节码形式,普通用户无法直接查看源码内容,但需要注意的是,.pyc文件并不完全安全,可以通过反编译工具(如uncompyle6)还原为可读的源码。 -
跨平台兼容性
.pyc文件是与 Python 版本相关的字节码文件,但通常与操作系统无关。因此,只要目标机器上安装了相同版本的 Python,.pyc文件就可以在不同操作系统上运行。 -
模块导入的优化
当导入一个模块时,Python 会首先查找.pyc文件(而不是.py文件),如果.pyc文件存在且未过期(源码未修改),Python 会直接加载.pyc文件,跳过源码编译过程。
使用 pyc 文件的注意事项?
-
与 Python 版本兼容性
.pyc文件是针对特定 Python 版本生成的。如果尝试用不同版本的 Python 运行.pyc文件,可能会导致不兼容错误。 -
易被反编译
.pyc文件只是源码的中间形式,虽然比源码难以直接阅读,但仍然可以通过工具还原为接近原始代码的形式。因此,不能单纯依赖.pyc文件来保护代码安全。 -
缓存文件清理
在开发过程中,.pyc文件可能会随着代码的修改而变得过时。为了避免加载旧的.pyc文件,开发者可以定期清理__pycache__目录或使用工具(如python -B)禁用字节码缓存。
代码加密执行
初步了解完解释器和编译器后,回归到我们的正题:代码加密执行。
为了控制变量python项目将采用简单的WEB服务:
代码如下:
# urls.py
from flask import Flask
from apps.user.view import login_view
# url:view map
urls = {
"/api/v1/login": (["POST"], login_view),
}
def register_url(router: Flask):
for url, view_func in urls.items():
if router.debug:
router.logger.debug("[DEBUG] register url %s", url)
router.add_url_rule(rule=url, endpoint=view_func[-1].__name__, view_func=view_func[-1], methods=view_func[0])
# main.py
from flask import Flask
from urls import register_url
app = Flask(__name__)
app.debug = True
register_url(app)
if __name__ == '__main__':
app.run(port=8080)
# view.py
import requests
from flask import request
from datetime import datetime
def login_view():
params = request.json # type:dict
username, password = params['username'], params['password']
now_date = datetime.now().date()
print(f"http://timor.tech/api/holiday/info/{now_date.year}-{now_date.month}-{now_date.day}")
resp = requests.get(
f"http://timor.tech/api/holiday/info/{now_date.year}-{now_date.month}-{now_date.day}",
headers={
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/130.0.0.0 Safari/537.36 Edg/130.0.0.0"
}
)
data = dict()
data.update({
"remote": resp.status_code,
"username": username,
"password": password,
"message": "login success!"
})
return data
包之间的依赖:
- 依赖外部requests库
- main.py同级依赖url.py
- url.py依赖apps下的子包
方法1:编译为可执行程序
将 Python 项目编译为可执行文件,并且支持跨平台,以下是几款常用且强大的工具。每种工具都有其特点,适合不同的场景需求。
- 综合推荐: PyInstaller 和 Nuitka 是最适合日常开发和多平台发布的工具。
- 高性能需求: Nuitka 或 PyOxidizer 更适合需要优化性能的场景。
- Windows 专用: py2exe 是为 Windows 平台量身打造的选择。
根据项目需求选择合适的工具,同时注意测试生成的可执行文件是否在目标平台上正常运行。
同时,有一些跨平台打包的注意事项:
-
依赖项的兼容性:
- 确保第三方库在目标平台上也有支持。
- 尽量避免平台相关的代码,例如特定于 Windows 的库(如
win32com)。
-
虚拟机和容器工具:
- 借助 Docker 或虚拟机,可以在同一开发环境中构建跨平台的可执行文件。
-
静态链接依赖:
- 对于需要更高性能和独立运行的文件,选择 Nuitka 或 PyOxidizer 可能更适合。
PyInstaller
PyInstaller 是最流行的工具之一,用于将 Python 脚本打包为独立的可执行文件,支持 Windows、Linux 和 macOS。
特点:
- 自动检测依赖项,无需手动配置。
- 支持将脚本打包成单文件或目录形式。
- 支持跨平台操作。
- 可处理复杂的项目结构和第三方依赖。
用法:
pyinstaller --onefile --hidden-import <module_name> main.py
--onefile: 将所有文件打包为单个可执行文件。--noconsole: 隐藏控制台窗口(GUI 程序)。--hidden-import: 手动指定 PyInstaller 未自动检测到的模块。--add-data: 包含额外的资源文件。
如果依赖复杂,建议创建 .spec 文件并手动编辑,例如:
block_cipher = None
a = Analysis(
['main.py'],
pathex=['.'], # 添加搜索路径
hiddenimports=['module_a', 'utils.helper'], # 手动指定依赖模块
datas=[('config.json', '.')], # 添加配置文件
...
)
然后运行:
pyinstaller main.spec
跨平台支持:
- 需要在目标平台上运行 PyInstaller 进行打包,例如在 Windows 上生成
.exe文件,在 macOS 上生成.app文件。 - 使用 Docker 或虚拟机可以实现间接跨平台打包。
执行pyinstaller --onefile main.py后自动检测依赖文件,然后生成build,dist,.spec目录或文件,在dist下面可以看到一个可执行文件:mian.exe
点击执行后效果如下,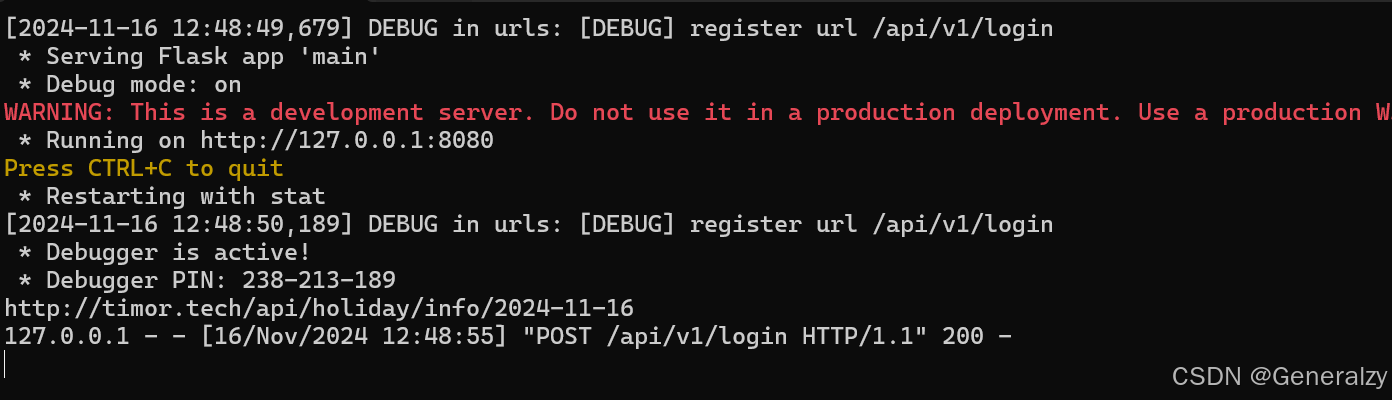
为确保跨平台编译也没问题,将代码传输到远程linux服务器再次构建:
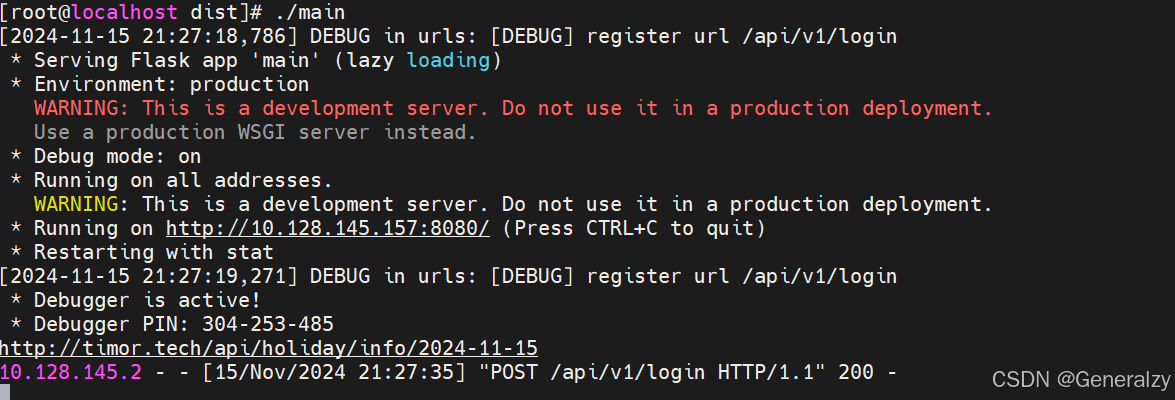
请求一下试试,BingGo!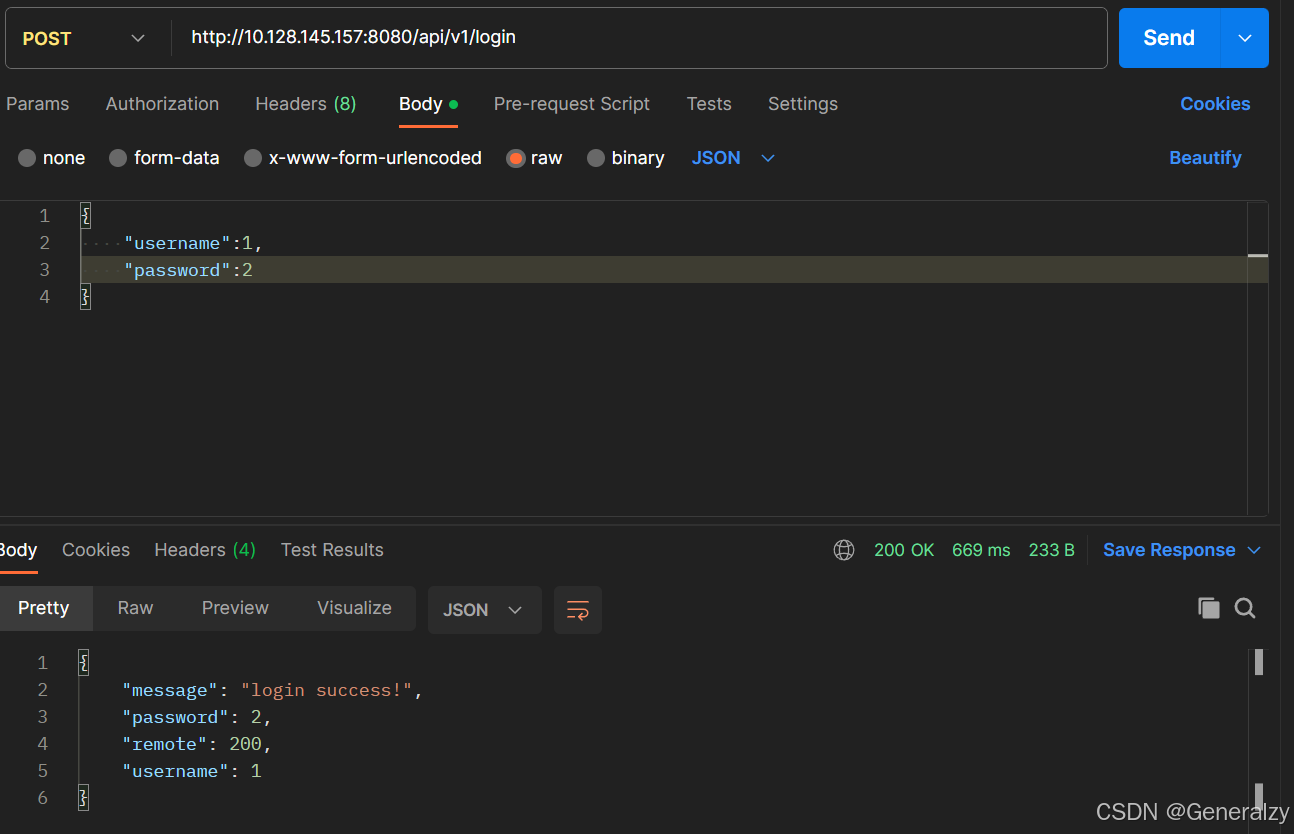
cx_Freeze
cx_Freeze 是一个轻量级的打包工具,支持将 Python 脚本编译为可执行文件,兼容 Windows、Linux 和 macOS。
特点:
- 支持不同平台的可执行文件生成。
- 可通过配置文件(setup.py)进行自定义打包设置。
- 专为 Python 脚本设计,适合中小型项目。
用法:
创建一个 setup.py 文件:
from cx_Freeze import setup, Executable
setup(
name="My Project",
version="1.0",
description="My Python Project",
options={
'build_exe': {
'packages': ['os', 'requests'], # 手动指定需要的包
'includes': ['module_a', 'utils.helper'], # 手动包含模块
'include_files': ['config.json'], # 添加额外的文件
}
},
executables=[Executable('main.py')],
)
打包命令:
python setup.py build
跨平台支持:
- 类似于 PyInstaller,需要在目标平台上运行工具进行打包。
Nuitka
Nuitka 是一个 Python 到 C 的编译器,可以将 Python 项目编译为原生的 C 可执行文件,具有更好的性能优化,使用pip命令即可安装:python -m pip install -U nuitka
特点:
- 生成高性能的二进制文件,比 PyInstaller 生成的文件更快。
- 完整支持 Python 语法和标准库。
- 支持大部分第三方模块。
用法:
nuitka --onefile --standalone your_script.py
--onefile: 将文件打包成单个可执行文件。--standalone: 打包为独立的可执行文件,包括所有依赖项。
如果 Nuitka 未检测到某些模块,可以显式指定:
nuitka --standalone --include-module=module_a --include-package=utils main.py
跨平台支持: Nuitka 支持跨平台编译,但需要安装目标平台的编译器(如 GCC)。Nuitka 本身不具备直接的跨平台编译能力,但它可以借助平台本地的编译器(如 GCC、Clang 或 MSVC),在不同的平台上编译生成目标可执行文件。
因此,要实现跨平台编译,需要准备每个目标平台的编译环境:
Nuitka 本身不具备直接的跨平台编译能力,但它可以借助平台本地的编译器(如 GCC、Clang 或 MSVC),在不同的平台上编译生成目标可执行文件。因此,要实现跨平台编译,您需要准备每个目标平台的编译环境。以下是如何在不同平台上使用 Nuitka 编译的详细步骤。
Windows 平台编译
Nuitka 需要本地编译器:
- 推荐使用 MSVC:
- 安装 Visual Studio(推荐社区版)。
- 在安装时选择 C++ Desktop Development 工具集。
- 或者,安装 MinGW(适合轻量化需求):
pacman -S mingw-w64-x86_64-gcc
在命令行中导航到 Python 脚本所在目录,运行:
python -m nuitka --standalone --onefile your_script.py
这将在 Windows 平台上生成 .exe 文件。
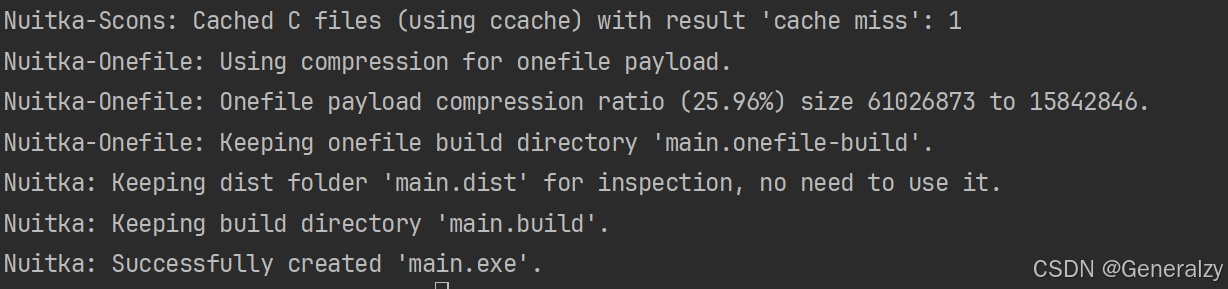
执行main.exe:

Linux 平台编译
安装编译器(GCC 或 Clang):
- Ubuntu/Debian:
sudo apt install gcc g++ - CentOS/RHEL:
sudo yum install gcc gcc-c++
在终端中导航到 Python 脚本所在目录,运行:
python3 -m nuitka --standalone --onefile your_script.py
这将在 Linux 平台上生成可执行文件(通常无扩展名)。
macOS 平台编译
macOS 自带 Clang 编译器,确保其可用:
clang --version
如果不可用,安装 Xcode 命令行工具:
xcode-select --install
在终端中导航到 Python 脚本所在目录,运行:
python3 -m nuitka --standalone --onefile your_script.py
这将在 macOS 平台上生成 .bin 文件。
py2exe
py2exe 是专为 Windows 设计的工具,用于将 Python 脚本转换为 Windows 的可执行文件(.exe)。
特点:
- 简单易用,适合 Windows 平台开发者。
- 配置灵活,可通过 setup 文件自定义打包过程。
用法:
创建一个 setup.py 文件:
from distutils.core import setup
import py2exe
setup(console=['your_script.py'])
打包命令:
python setup.py py2exe
跨平台支持:
- 仅支持 Windows,不适合需要多平台部署的项目。
PyOxidizer
PyOxidizer 是一个现代化的 Python 打包工具,可以将 Python 脚本编译为高效的独立二进制文件。
特点:
- 支持将 Python 解释器和脚本静态链接为单个文件。
- 更注重性能,生成的可执行文件体积较小。
- 支持嵌入式资源(如 HTML 文件、图片等)的打包。
用法:
创建 pyoxidizer.toml 配置文件:
[package]
name = "my_project"
version = "1.0"
[python]
distribution = "stable"
[files]
include = [
"config.json",
"utils/",
]
运行打包命令:
pyoxidizer build
跨平台支持:
- 支持 Windows、Linux 和 macOS,但可能需要额外配置。
总结
- 简单项目: PyInstaller 是首选,自动化程度高,适合快速打包。
- 复杂项目: Nuitka 或 cx_Freeze 提供更强大的依赖控制和性能优化。
- 需要高性能和小体积: PyOxidizer 或 Nuitka 更适合。
方案2:将代码编译为 pyc 文件
.pyc 文件是 Python 的一种字节码缓存文件,它的主要作用是提高程序运行效率,避免重复编译,但它并不是一种安全的代码保护手段。对于重要代码,建议结合其他手段(如混淆、加密)进一步加强保护。
编译 Python 代码为 .pyc
Python 提供了标准库 py_compile,可以用来编译 .py 文件为 .pyc 文件。
import py_compile
# 编译单个文件
py_compile.compile('example.py', cfile='example.pyc')
# 编译文件并指定输出目录
py_compile.compile('example.py', cfile='output_dir/example.pyc')
也可以直接使用命令行工具 python -m py_compile:
python -m py_compile example.py
生成的 .pyc 文件会默认存放在 __pycache__ 目录中,例如 __pycache__/example.cpython-312.pyc。
compileall 模块可以递归编译指定目录下的所有 .py 文件,在项目根目录运行以下命令:
python -m compileall .
如果项目目录结构如下:
project/
├── main.py
├── module1.py
└── subdir/
└── module2.py
运行命令后,生成的 .pyc 文件路径为:
project/
├── __pycache__/
│ ├── main.cpython-312.pyc
│ └── module1.cpython-312.pyc
└── subdir/
└── __pycache__/
└── module2.cpython-312.pyc
如果想通过脚本实现批量编译,也可以使用 compileall.compile_dir():
import compileall
# 批量编译当前目录下的所有 .py 文件
# force=True 强制重新编译,即使 .pyc 文件已经存在。
compileall.compile_dir('.', force=True)
如果不希望生成 __pycache__ 文件夹,可以将 .pyc 文件输出到指定目录。
import py_compile
import os
def compile_project_to_dir(src_dir, dest_dir):
if not os.path.exists(dest_dir):
os.makedirs(dest_dir)
for root, _, files in os.walk(src_dir):
for file in files:
if file.endswith(".py"):
src_file = os.path.join(root, file)
rel_path = os.path.relpath(src_file, src_dir)
compiled_file = os.path.join(dest_dir, rel_path + 'c')
compiled_dir = os.path.dirname(compiled_file)
if not os.path.exists(compiled_dir):
os.makedirs(compiled_dir)
py_compile.compile(src_file, cfile=compiled_file)
# 将项目目录 src/ 编译到 pyc_output/
compile_project_to_dir('src', 'pyc_output')
在编译 .pyc 文件时,可以通过 -O 或 -OO 设置优化级别:
- -O:移除断言语句(assert)。
- -OO:移除断言语句和
__doc__字符串(文档字符串)。
python -O -m compileall .
或
import compileall
# 编译时设置优化级别
compileall.compile_dir('.', optimize=2)
生成的 .pyc 文件会在名称中包含优化信息:
module.cpython-312.opt-2.pyc
.pyc 文件与 Python 版本绑定,例如 Python 3.12 的 .pyc 文件不能被 Python 3.8 使用。
如果你打算只部署 .pyc 文件,可以在生成后删除 .py 文件:
find . -name "*.py" -type f -delete
执行 .pyc 文件的方式与执行普通的 .py 文件类似,但需要注意几点:首先,.pyc 文件是编译过的字节码文件,它们并不包含可直接执行的文件路径信息。其次,.pyc 文件的路径必须正确,并且要与 Python 版本匹配。
执行单个 .pyc 文件可以通过 python 命令指定 .pyc 文件路径:
python /path/to/your/project/__pycache__/module_name.cpython-312.pyc
要启动一个复杂的项目并让它完全运行,即使所有的 .py 文件都被编译成 .pyc 文件,关键在于正确设置模块路径 和 入口文件,否则会报各种路径错误!!
为了确保路径不会有问题,可以选择性的在开头把根目录加入python环境:
import sys
import os
# 项目根目录
project_root = os.path.dirname(os.path.abspath(__file__))
sys.path.insert(0, project_root)
执行python -O -m compileall .重新编译后,将py文件删掉,然后把pyc文件移动到原来py文件的位置,并且将中间的python版本和优化信息删掉,改为xxx.pyc文件:

然后执行程序入口文件即可,
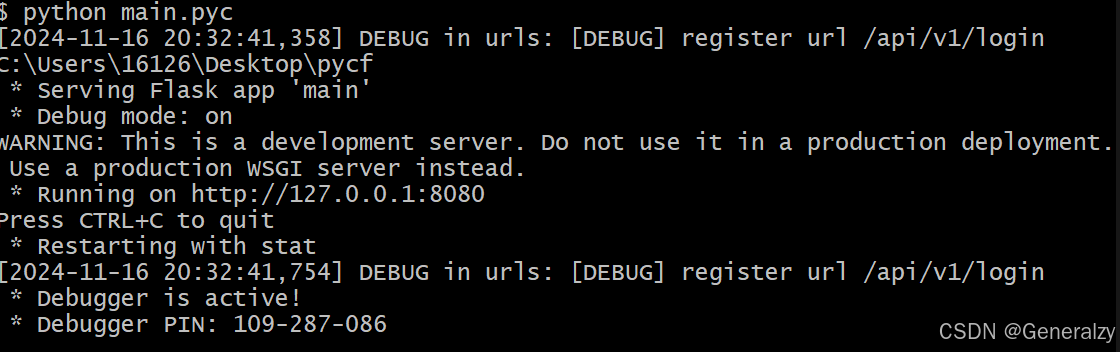
为什么不直接用python执行__pycache__下的pyc呢? 原因就一个,路径会改变,哪怕py编译成pyc也是有from xx import xx的语义的,你的xx变成了__pycache__/xx,但你没写到代码里啊,所以就找不到包,继而报错:no module named xxx。
最后,其实不推荐这种方法去保护py源文件,正如我开头所说,.pyc 文件是 Python 的一种字节码缓存文件,它的主要作用是提高程序运行效率,避免重复编译,但它并不是一种安全的代码保护手段。对于重要代码,建议结合其他手段(如混淆、加密)进一步加强保护。
方案3:代码混淆
Python代码混淆是一种对源代码进行改写以提高其逆向工程难度的方法,特别是保护敏感信息(如API密钥、算法逻辑等)。以下是常见的混淆工具和方法,以及保证混淆代码可执行的策略。
PyArmor是广泛使用的混淆工具,支持保护 .py 文件和生成 .pyc 文件,同时可以加入运行时校验。
安装 pyarmor:pip install pyarmor
支持跨平台:生成的混淆代码可以指定目标平台的Python版本。
Python Obfuscator:以代码重排和重命名为主要混淆手段。(经本人确认无法下载!)
安装:pip install py-obfuscate
主流的工具就Obfuscator和PyArmor,下面将详细解析这两款工具。
PyArmor8
从 PyArmor 8.0 开始,命令行工具的结构简化为三个主要命令:gen、reg 和 cfg,用户通过配置文件和命令组合实现复杂功能。
gen 命令用于生成混淆后的代码、运行时许可证或项目密钥等。
混淆代码:pyarmor gen --src my_project --output dist
- src:指定要混淆的源代码目录。
- output:指定输出目录,默认为当前目录。
生成运行时许可证:pyarmor gen license --output licenses
- output:许可证保存位置。
生成项目密钥:pyarmor gen key --output keys
reg 命令用于注册运行时许可证,如果你的混淆代码需要特定许可证才能运行,可以使用以下命令注册:
pyarmor reg licenses/my_license.lic
cfg 命令用于配置项目的混淆规则、运行时策略等。
配置混淆规则:
pyarmor cfg obfuscate --advanced-mode 1 --recursive 1
- advanced-mode:启用高级混淆。
- recursive:递归处理子目录。
配置运行时策略:pyarmor cfg runtime --disable-runtime-check 0
- disable-runtime-check:是否禁用运行时环境校验(默认启用)。
假设项目结构如下:
my_project/
├── main.py
├── app/
│ ├── __init__.py
│ ├── views.py
│ └── models.py
PyArmor 8.0+ 推荐通过配置文件设置混淆选项。手动创建一个名为 pyarmor.cfg 的文件,内容如下:
[obfuscate]
recursive = 1
advanced-mode = 1
使用以下命令加载配置文件并执行混淆:
pyarmor gen ./
混淆成功后代码会被混淆输出到 dist 目录。确保部署时将 pytransform 模块和运行时许可证一并打包。
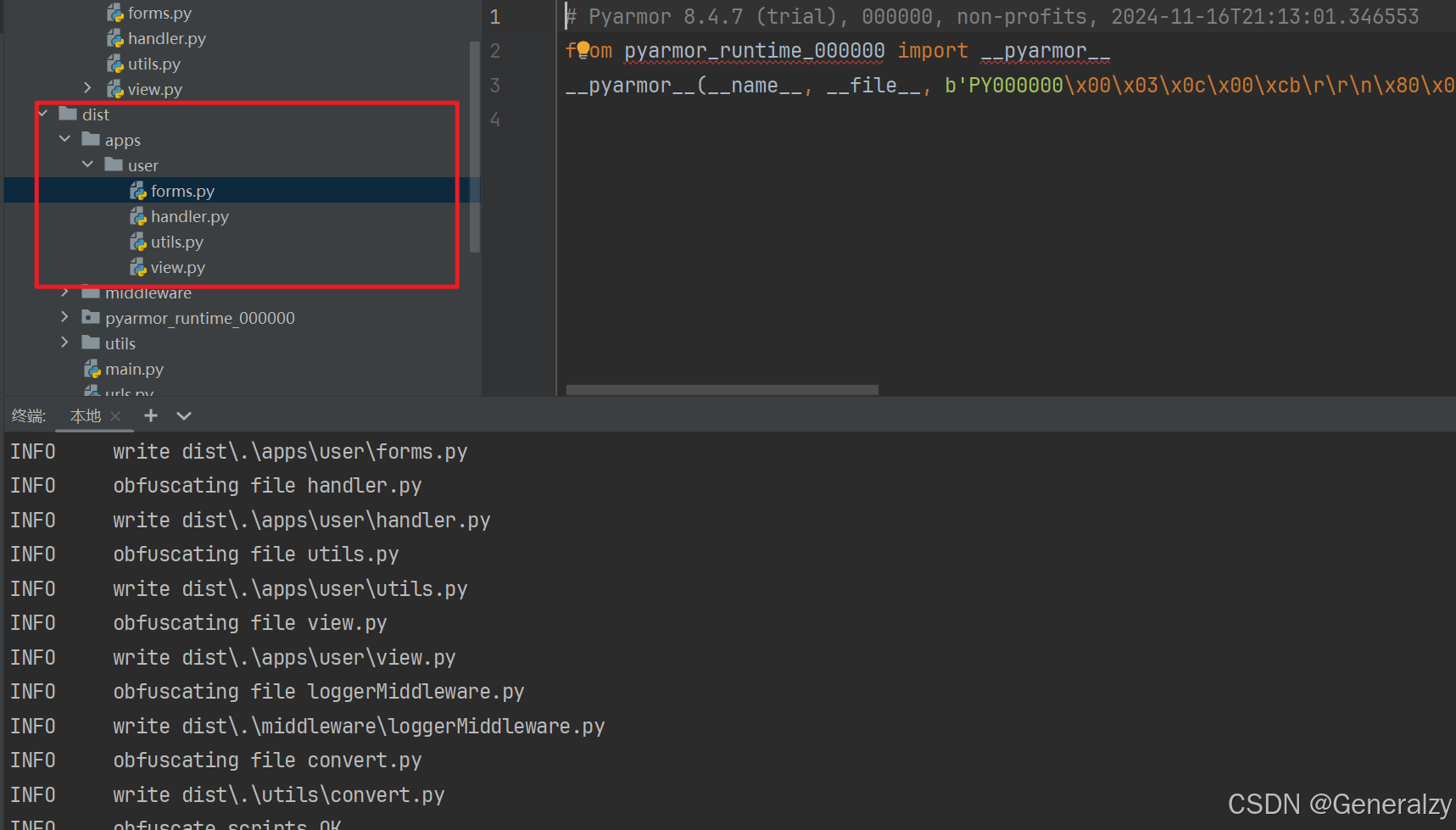
详细使用说明请参考官方文档:https://pyarmor.readthedocs.io/en/latest/how-to/register.html#upgrade-to-pyarmor-9
方案4:Cython库加密代码
Cython 是一个基于 Python 的扩展语言,它旨在将 Python 代码转换为 C 语言代码,从而提高代码的执行效率,同时保持 Python 代码的可读性。它使得 Python 程序员能够通过直接嵌入 C 语言代码,来优化 Python 代码的性能,特别是在计算密集型的任务中。
Cython 的作用
-
提高执行性能:
Cython 最常见的用途是通过将 Python 代码编译成 C 扩展,从而显著提升程序的执行速度。Python 本身的执行速度较慢,因为它是解释型语言,且在运行时会进行动态类型检查。Cython 通过静态类型声明和将 Python 代码编译成 C 代码,消除了许多动态类型带来的开销,从而加速程序运行。例如,如果你有一个数值密集型的循环,可以通过 Cython 将其加速数倍。
-
C 扩展支持:
Cython 允许你在 Python 代码中直接嵌入 C 语言代码。这意味着你可以直接调用 C 语言库和 C 代码,而不必编写复杂的 Python C API 代码。这种能力使得 Python 开发者能够轻松利用 C 语言的高性能同时仍然享受 Python 的易用性。 -
无缝与 Python 集成:
Cython 提供了一个简单的 Python 语法扩展,允许开发者直接在 Python 中编写 C 语言代码并进行编译。这使得开发者不需要掌握深入的 C 语言知识,也可以利用 C 语言的速度优势。 -
与现有 Python 代码兼容:
Cython 允许你逐步迁移 Python 代码到 Cython,既不会破坏现有的 Python 代码,也能够逐步提升性能。它能够兼容大部分 Python 标准库,因此,你可以在不改变太多现有代码的情况下提高性能。 -
支持并发和多线程:
Cython 支持 GIL(全局解释器锁)外的并发和多线程操作,在某些场景下,Cython 可以绕过 GIL 提高多核处理器的并发性能。 -
支持加密和代码保护:
Cython 编译后的 C 扩展文件是二进制文件,相比纯 Python 文件,它更难以被反编译查看源码。这使得 Cython 成为保护 Python 代码的一个有效手段,尽管它不能完全阻止反编译,但相较于源代码,二进制文件更不容易被直接查看。
Cython 的主要特点
-
增强的性能:通过将 Python 代码转化为 C 代码,Cython 可以在许多情况下大幅提高代码的执行速度,尤其是在涉及大量计算的任务中。
-
与 C 语言兼容:Cython 允许直接调用 C 函数和库,这使得你能够利用现有的 C 代码和高效的 C 库(例如 NumPy)来加速 Python 程序。
-
逐步过渡:你可以从纯 Python 代码开始,逐步添加 Cython 优化代码,无需完全重写整个项目。
-
Python 兼容:Cython 编写的代码依然是 Python 程序,因此你可以像使用普通 Python 模块一样使用 Cython 编译的扩展模块。
Cython 的应用场景
- 加速计算密集型任务:如数学计算、图像处理、数值分析等。
- 封装 C 库:如果你有 C 语言的库或函数需要在 Python 中调用,Cython 可以让这变得非常简单。
- Python 与 C 语言的混合编程:例如,在某些性能要求较高的场景中,可以将性能瓶颈部分的代码用 Cython 实现,而其他部分仍然保持用 Python 编写。
- 加密与保护源码:将 Python 代码编译为 C 扩展后,源码不容易直接暴露,适用于有一定保护需求的场景。
Cython 的使用示例
假设你有一个计算斐波那契数列的函数,用纯 Python 实现可能如下所示:
# fibonacci.py
def fibonacci(n):
if n <= 1:
return n
else:
return fibonacci(n-1) + fibonacci(n-2)
如果你希望通过 Cython 来提高这个代码的执行效率,可以将其转换为 fibonacci.pyx 文件并添加静态类型声明:
# fibonacci.pyx
def fibonacci(int n):
if n <= 1:
return n
else:
return fibonacci(n-1) + fibonacci(n-2)
然后你可以编写 setup.py 文件来编译这个 Cython 文件:
from setuptools import setup
from Cython.Build import cythonize
setup(
ext_modules = cythonize("fibonacci.pyx")
)
接着,通过运行 python setup.py build_ext --inplace 编译 Cython 代码,生成 .so 或 .pyd 扩展模块。
最后,你可以像普通 Python 模块一样使用编译后的 fibonacci 模块:
import fibonacci
print(fibonacci.fibonacci(10)) # 输出斐波那契数列的第 10 个数
可以看到同时目录下出现了build目录和.c文件:
- build 文件夹是由 Python setuptools 或 distutils 在编译和构建 C 扩展模块时自动生成的一个临时文件夹。它包含了编译过程中的中间文件和构建结果,通常用于存放编译生成的中间文件(如 C 源代码、编译后的 .o 文件、临时的编译器输出等)以及最终的扩展模块(如 .pyd、.so 或 .dll 文件)。
- 使用 Cython 编译 .pyx 文件时,Cython 会首先将其转换为 C 语言源代码文件(即 .c 文件),然后再通过 C 编译器将这些 .c 文件编译成平台特定的扩展模块(如 .pyd、.so 或 .dll 文件)。
这两者都可以删除掉,可以使用 --no-build 选项跳过构建步骤,然后手动删除c文件。
Cython 加密&提速示例项目
Cython 不会自动处理依赖,它并不像 Python 解释器那样自动解析和处理模块间的依赖关系。并且Cython一般用来处理有性能瓶颈的代码,像IO密集型,转为C性能的提升也不会太大:
app/
├── user/
│ ├── __init__.py
│ ├── forms.py
│ ├── views.py
│ ├── utils.py
├── urls.py
示例中的代码,可以完全只编译views.py,这是因为 Cython 编译的 .pyd 或 .so 文件会作为 Python 模块加载,而 Python 本身在运行时会正常处理导入的其他 Python 文件。
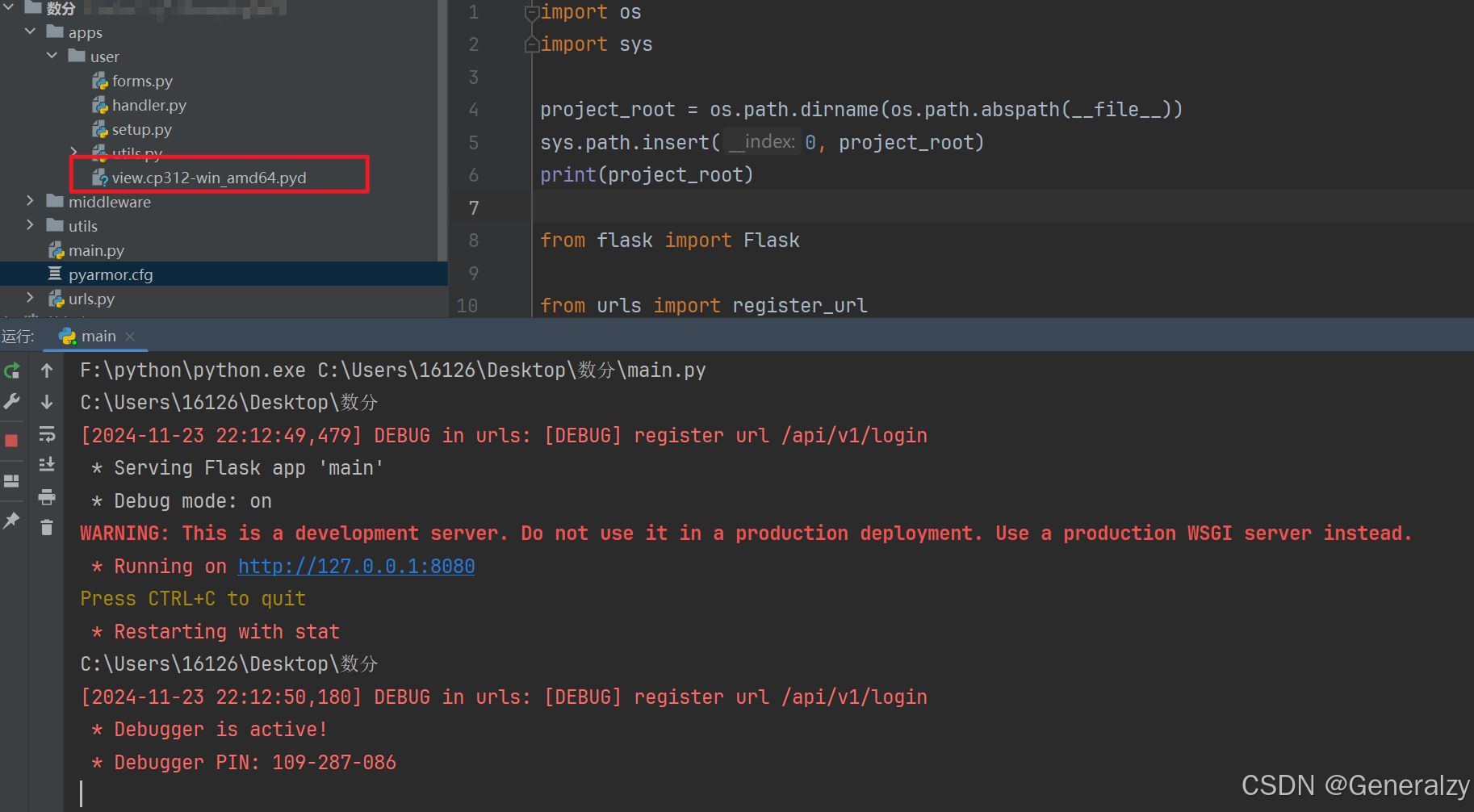
显然我们的代码没有受到任何影响。
方案5:修改 Python 解释器源码
通过修改 Python 解释器源码,实现动态解密和解释代码核心思想在于:
- 代码加密: 使用对称加密算法(如 AES),将 Python 源代码加密保存,避免直接暴露代码。
- 动态解密: 修改 Python 解释器源码,让解释器在运行时自动解密加密后的代码,并执行。
- 分发安全性: 只分发加密后的代码和修改后的解释器,保证源码不会直接泄露。
现在,我们去github python仓库官方下载解释器源码:
Python源码概览
进入源码目录,我们可以看到该目录下主要 包含以下文件(夹):
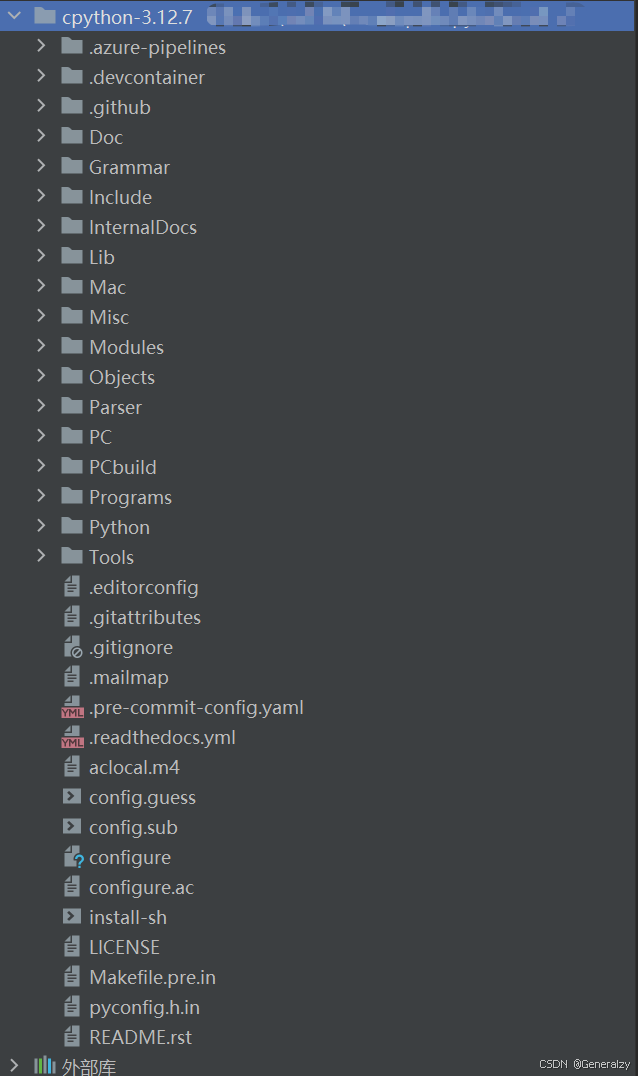
目录结构:
Doc
官方文档。这就是 https://docs.python.org/ 使用的文档。也可以查看“构建文档”。
Grammar
包含Python的EBNF语法文件。
Include
包含所有解释器范围内的头文件。
Lib
由纯Python实现的标准库部分。
Mac
与Mac相关的代码(例如,将IDLE用作macOS应用程序)。
Misc
不属于其他地方的内容。通常是各种与开发人员相关的文档。
Modules
由C实现的标准库部分(以及一些其他代码)。包含了所有用 C 语言编写的模块,比如 math、hashlib 等。它们都是那些对速度要求非常严格的模块。而相比而言,Lib 目录下则是存放一些对速度没有太严格要求的模块,比如 os。
Objects
所有内建类型的代码。包含了所有 Python 的内建对象,包括整数、list、dict 等。同时,该目录还包括了 Python 在运行时需要的所有的内部使用对象的实现。
PC
Windows特定的代码。
PCbuild
为当前在python.org提供的Windows安装程序使用的MSVC版本构建的文件。研究 Python 源代码就从这里开始。
Parser
与解析器相关的代码。AST节点的定义也保存在这里。包含了 Python 解释器中的 Scanner 和 Parser 部分,即对 Python 源代码进行词法分析和语法分析的部分。除此以外,此目录还包含了一些有用的工具,这些工具能够根据 Python 语言的语法自动生成 Python 语言的词法和语法分析器,与 YACC 非常类似。
Programs
C语言可执行文件的源代码,包括CPython解释器的主函数。
Python
构成核心CPython运行时的代码。包括编译器、eval循环以及各种内建模块。包含了 Python 解释器中的 Compiler 和执行引擎部分,是 Python 运行的核心所在。
Tools
用于(或曾用于)维护Python的各种工具。包含了 Python 二进制可执行文件的源码。
Windows编译Python
进入 Python 源码根目录,双击打开 PCbuild\pcbiuld.sln 解决方案,而后进行一些设置:
在左侧的解决方案目录的顶端,右键选择“属性”,以打开属性界面(如下图所示)。
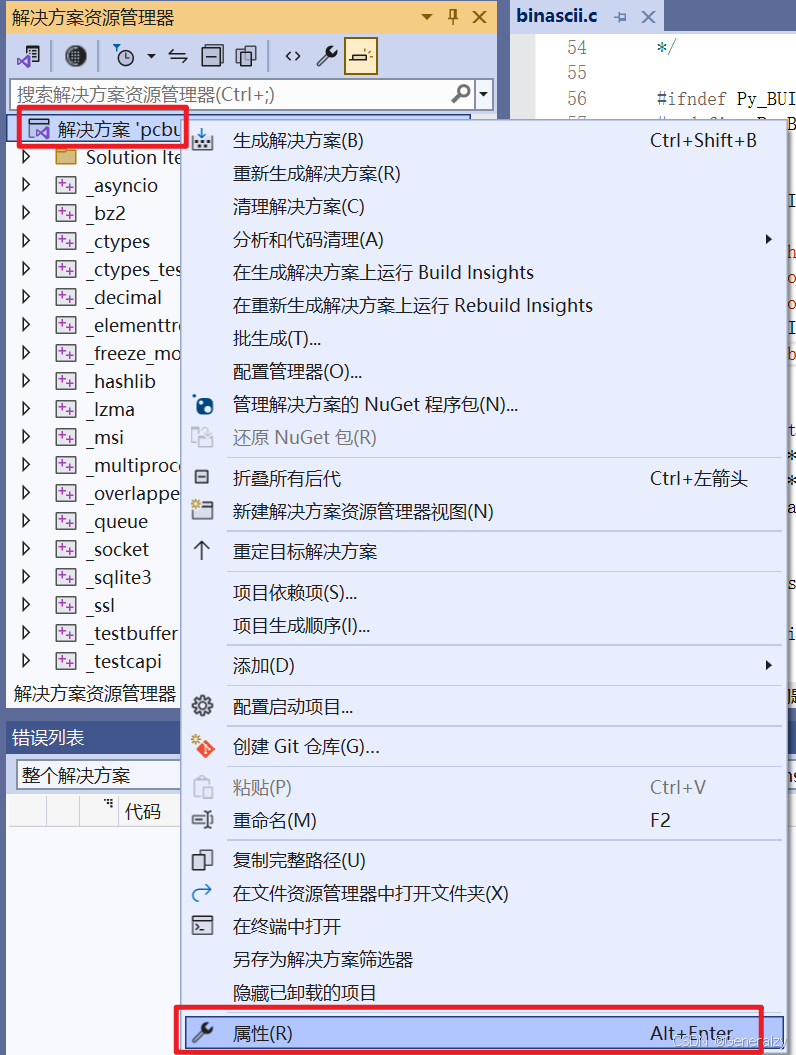
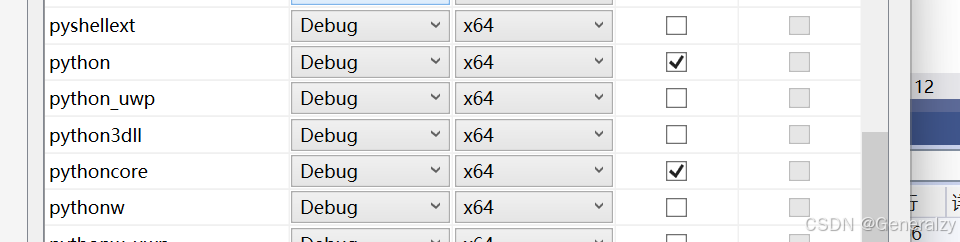
由于我们只是研究 Python 的核心部分,可以选择不编译标准库和外部依赖,在“配置属性”->“配置”中仅勾选 python 和 pythoncore,然后点击“确定”(如下图所示)。
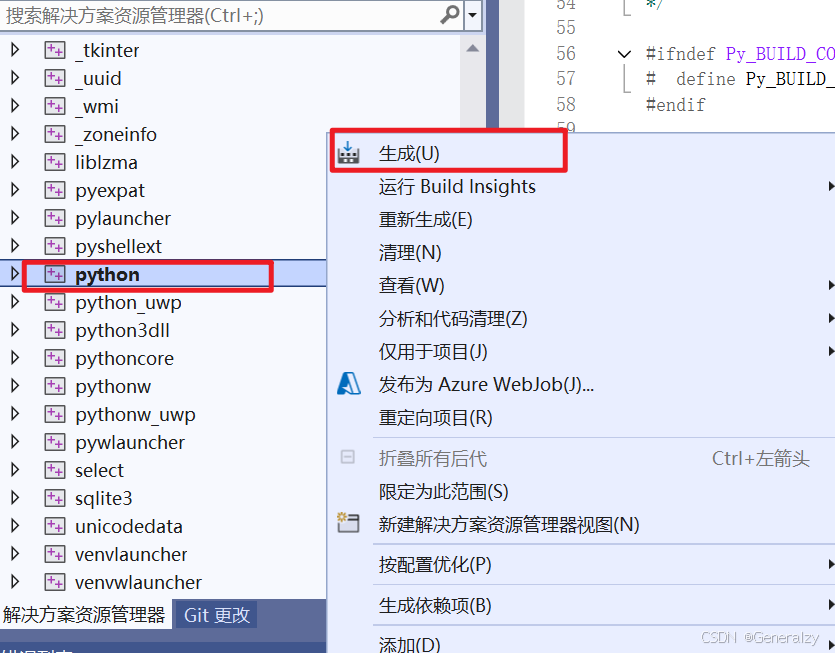
点击应用保存后,在左侧的解决方案目录中选择 python,右键选择“生成”,以进行编译:
如果报错缺失zlib.h可以选择下载微软包管理器安装zlib:
git clone https://github.com/microsoft/vcpkg
在 vcpkg 根目录下,运行 vcpkg 引导程序命令(bootstrap-vcpkg.bat),在目录下看到vcpkg文件则算安装成功,然将其添加到环境变量:

为了在Visual Studio中使用vcpkg,只需要vcpkg integrate install即可。
| Command | 描述 |
|---|---|
vcpkg search [pat] |
搜索可安装的包 |
vcpkg install <pkg>... |
安装包 |
vcpkg remove <pkg>... |
卸载包 |
vcpkg remove --outdated |
卸载所有过期包 |
vcpkg list |
列出已安装的包 |
vcpkg update |
显示用于更新的包列表 |
vcpkg upgrade |
重新生成所有过期包 |
vcpkg hash <file> [alg] |
通过特定算法对文件执行哈希操作,默认为 SHA512 |
vcpkg integrate install |
使已安装包在用户范围内可用。 首次使用时需要管理权限 |
vcpkg integrate remove |
删除用户范围的集成 |
vcpkg integrate project |
为使用单个 VS 项目生成引用 NuGet 包 |
vcpkg export <pkg>... [opt]... |
导出包 |
vcpkg edit <pkg> |
打开端口进行编辑(使用 %EDITOR%,默认为“code”) |
vcpkg create <pkg> <url> [archivename] |
创建新程序包 |
vcpkg cache |
列出缓存的已编译包 |
vcpkg version |
显示版本信息 |
vcpkg contact --survey |
显示联系信息,以便发送反馈。 |
然后我们安装zlib包:vcpkg install zlib
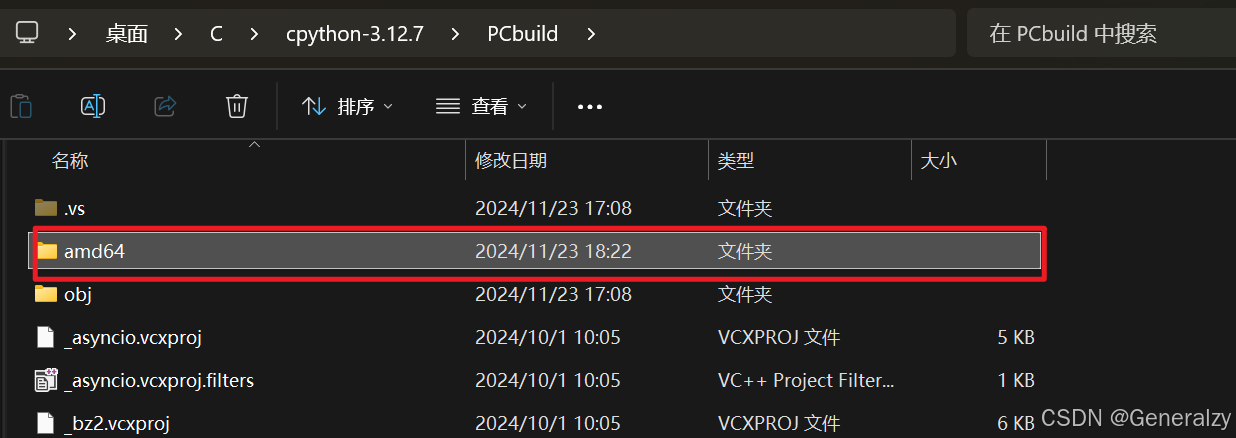
编译结束后,生成的文件存放在PCbuild\{arch}目录下(如下图所示,比如我的在amd64下),打开python_d即可打开新生成的 Python 解释器。
接下来让我做个小demo验证下解释器是否可以按照我们的想法运行!
我们来修改Objects/longobject.c,这是python内置对象的文件,
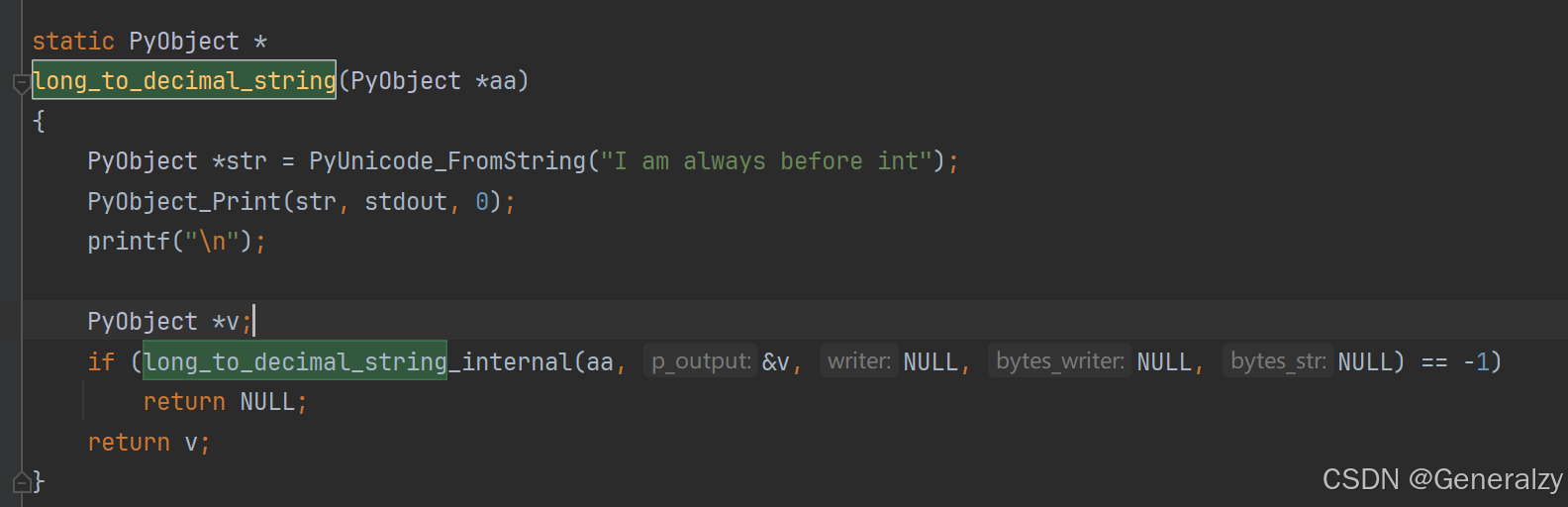
比如,我们希望在解释器交互界面中打印整数值的时候输出一段字符串,则我们可以修改如下函数:
static PyObject *
long_to_decimal_string(PyObject *aa)
{
PyObject *str = PyUnicode_FromString("I am always before int");
PyObject_Print(str, stdout, 0);
printf("\n");
PyObject *v;
if (long_to_decimal_string_internal(aa, &v, NULL, NULL, NULL) == -1)
return NULL;
return v;
}
函数实现中的前 3 行为我们加入的代码,其中:
- PyUnicode_FromString 用于把 C 中的原生字符数组转换为出 Python 中的字符串(Unicode)对象
- PyObject_Print 则将转换好的字符串对象打印至我们指定的标准输出(stdout)
对 Python 重新进行编译,运行编译后的 Python,输入 print 语句即可看到我们希望的结果:
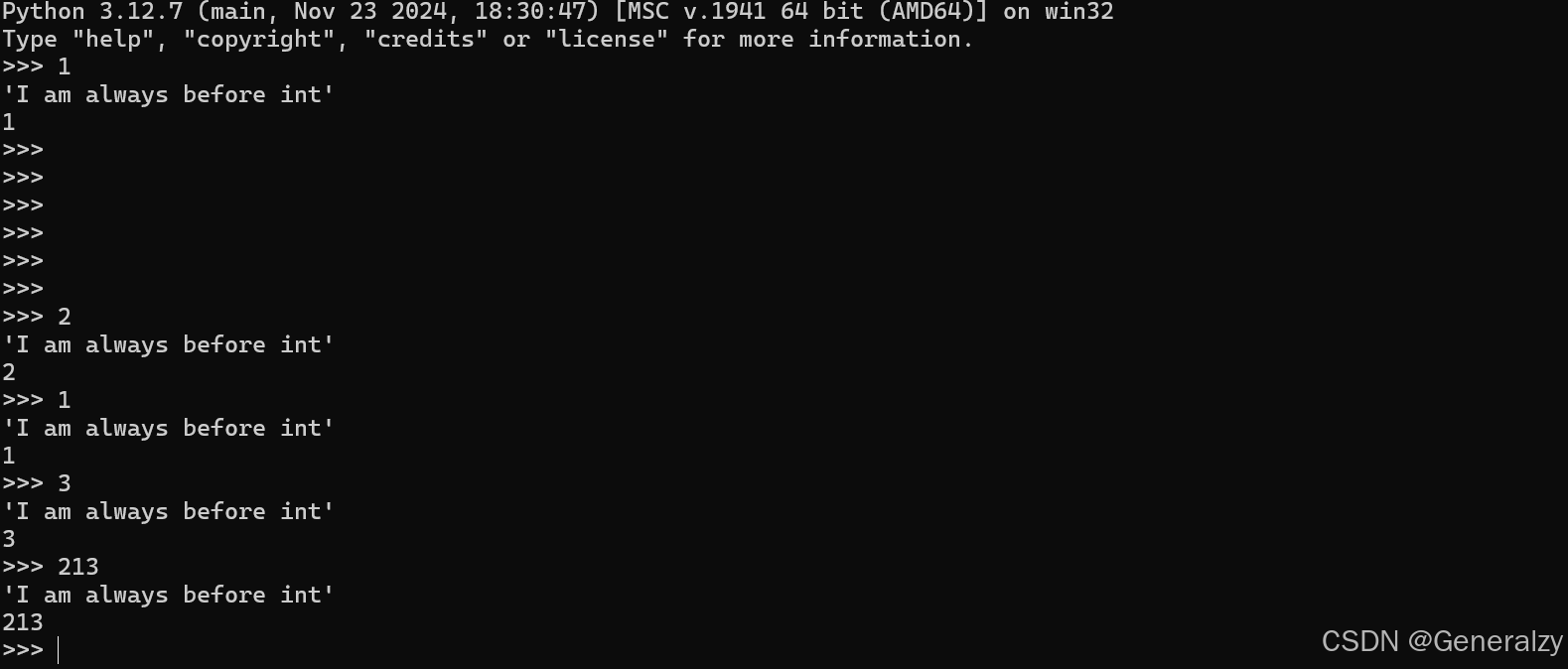
可以看到,python的行为被我们修改了!
修改 Python源码
python 在加载模块时使用 import.c 和 marshal.c,因此我们选择阅读这块代码并修改:
- Python/import.c:负责模块导入。
- Python/marshal.c:处理字节码加载。
我们首先尝试加密单一文件,然后再解密!
首先准备一个最简单的helloworld.py文件
print("hello world")
然后用go语言编写加密工具:
package main
import (
"bytes"
"crypto/aes"
"crypto/cipher"
"encoding/hex"
"fmt"
"io"
"os"
)
var (
// KEY 加密key,可以使用openssl rand -hex 32生成
KEY, _ = hex.DecodeString("78205a2ec9bf5128efa0e1e54485294ed5c99f11b8c8b79d7aa7f964e8c90f90")
// IV 加密iv,可以使用openssl rand -hex 16生成
IV, _ = hex.DecodeString("8784292a84cee6dceacb49a1a4be7264")
)
func LoadFile(filename string) ([]byte, error) {
fd, err := os.Open(filename)
if err != nil {
return nil, err
}
defer fd.Close()
return io.ReadAll(fd)
}
func Pad(data []byte, blockSize int) []byte {
padding := blockSize - len(data)%blockSize
padText := bytes.Repeat([]byte{byte(padding)}, padding)
return append(data, padText...)
}
func UnPad(data []byte) []byte {
length := len(data)
unPadding := int(data[length-1])
return data[:(length - unPadding)]
}
func Encrypt(content []byte) ([]byte, error) {
block, err := aes.NewCipher([]byte(KEY))
if err != nil {
return nil, err
}
content = Pad(content, block.BlockSize())
// 使用 CBC 模式加密
mode := cipher.NewCBCEncrypter(block, []byte(IV))
cipherText := make([]byte, len(content))
mode.CryptBlocks(cipherText, content)
// 返回 Base64 编码的结果(包含 IV)
return cipherText, nil
}
func EncryptToFile(filename string) error {
content, err := LoadFile(filename)
if err != nil {
return err
}
cipherText, err := Encrypt(content)
if err != nil {
return err
}
// 转为string后存储
if err = os.WriteFile(filename, cipherText, 0666); err != nil {
return err
}
return nil
}
func Decrypt(content []byte) ([]byte, error) {
block, err := aes.NewCipher(KEY)
if err != nil {
return nil, err
}
// 使用 CBC 模式解密
mode := cipher.NewCBCDecrypter(block, IV)
plainText := make([]byte, len(content))
mode.CryptBlocks(plainText, content)
return plainText, nil
}
func DecryptToFile(filename string) error {
content, err := LoadFile(filename)
if err != nil {
return err
}
cipherText, err := Decrypt(content)
if err != nil {
return err
}
if err = os.WriteFile(filename, UnPad(cipherText), 0666); err != nil {
return err
}
return nil
}
func main() {
// fmt.Println(EncryptToFile("main.py"))
fmt.Println(DecryptToFile("main.py"))
}
这是我们加密后的main.py文件(其实就是一行print(“hello world”)):
然后我们把解密用C语言再实现一遍:
#include <openssl/evp.h>
#include <openssl/rand.h>
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
// AES 密钥和 IV
unsigned char KEY[32] = {
0x78, 0x20, 0x5a, 0x2e, 0xc9, 0xbf, 0x51, 0x28,
0xef, 0xa0, 0xe1, 0xe5, 0x44, 0x85, 0x29, 0x4e,
0xd5, 0xc9, 0x9f, 0x11, 0xb8, 0xc8, 0xb7, 0x9d,
0x7a, 0xa7, 0xf9, 0x64, 0xe8, 0xc9, 0x0f, 0x90
};
unsigned char IV[16] = {
0x87, 0x84, 0x29, 0x2a, 0x84, 0xce, 0xe6, 0xdc,
0xea, 0xcb, 0x49, 0xa1, 0xa4, 0xbe, 0x72, 0x64
};
// 加载文件内容
unsigned char* load_file(const char* filename, size_t* file_size) {
FILE* file = fopen(filename, "rb");
if (!file) {
perror("Failed to open file");
return NULL;
}
fseek(file, 0, SEEK_END);
*file_size = ftell(file);
rewind(file);
unsigned char* buffer = (unsigned char*)malloc(*file_size);
if (!buffer) {
perror("Failed to allocate memory");
fclose(file);
return NULL;
}
fread(buffer, 1, *file_size, file);
fclose(file);
return buffer;
}
// 写入文件
int write_file(const char* filename, const unsigned char* data, size_t size) {
FILE* file = fopen(filename, "wb");
if (!file) {
perror("Failed to open file for writing");
return -1;
}
fwrite(data, 1, size, file);
fclose(file);
return 0;
}
// PKCS#7 解填充
size_t unpad_data(unsigned char* data, size_t size) {
if (size == 0) return 0;
unsigned char padding = data[size - 1];
if (padding > size) return size; // 防止填充错误
return size - padding;
}
// AES CBC 解密
unsigned char* decrypt_aes_cbc(const unsigned char* cipher_text, size_t cipher_text_len, size_t* plain_text_len) {
EVP_CIPHER_CTX *ctx = EVP_CIPHER_CTX_new();
if (!ctx) {
perror("Failed to create EVP_CIPHER_CTX");
return NULL;
}
// 初始化解密上下文,选择 AES-256-CBC 模式
if (!EVP_DecryptInit_ex(ctx, EVP_aes_256_cbc(), NULL, KEY, IV)) {
perror("EVP_DecryptInit_ex failed");
EVP_CIPHER_CTX_free(ctx);
return NULL;
}
unsigned char* plain_text = (unsigned char*)malloc(cipher_text_len);
if (!plain_text) {
perror("Failed to allocate memory for plaintext");
EVP_CIPHER_CTX_free(ctx);
return NULL;
}
// 解密过程
int len, plain_text_len_local;
if (!EVP_DecryptUpdate(ctx, plain_text, &len, cipher_text, cipher_text_len)) {
perror("EVP_DecryptUpdate failed");
EVP_CIPHER_CTX_free(ctx);
free(plain_text);
return NULL;
}
plain_text_len_local = len;
// 结束解密过程
if (!EVP_DecryptFinal_ex(ctx, plain_text + len, &len)) {
perror("EVP_DecryptFinal_ex failed");
EVP_CIPHER_CTX_free(ctx);
free(plain_text);
return NULL;
}
plain_text_len_local += len;
plain_text[plain_text_len_local] = '\0'; // Null-terminate the plaintext for safety
EVP_CIPHER_CTX_free(ctx);
*plain_text_len = plain_text_len_local;
return plain_text;
}
// 文件解密函数
int decrypt_file(const char* filename) {
size_t cipher_text_len;
unsigned char* cipher_text = load_file(filename, &cipher_text_len);
if (!cipher_text) return -1;
size_t plain_text_len;
unsigned char* plain_text = decrypt_aes_cbc(cipher_text, cipher_text_len, &plain_text_len);
free(cipher_text);
if (!plain_text) return -1;
if (write_file(filename, plain_text, plain_text_len) != 0) {
free(plain_text);
return -1;
}
free(plain_text);
return 0;
}
int main() {
const char* filename = "main.py";
if (decrypt_file(filename) == 0) {
printf("File decrypted successfully.\n");
} else {
fprintf(stderr, "Failed to decrypt the file.\n");
}
return 0;
}
然后使用gcc进行编译,一定要注意路径和dll文件名称:
gcc -o aes_decrypt main.c -I"G:/openssl/OpenSSL-Win64/include" -L"G:/openssl/OpenSSL-Win64" -llibcrypto-3-x64
-I 用于指定编译器在查找头文件时需要搜索的目录路径。头文件是 C/C++ 程序中引用的 .h 文件,它们通常包含函数声明、结构体定义等信息。
用法:-I<路径>
作用:告诉编译器在哪些目录下查找头文件。
-L 用于指定链接器(linker)在查找库文件时需要搜索的目录路径。库文件通常是 .a(静态库)或 .so(动态库,Linux)或 .dll(动态链接库,Windows)等。
用法:-L<路径>
作用:告诉链接器在哪些目录下查找库文件。
-l 用来告诉链接器要链接的库的名称。通常,它会自动去查找 .a 或 .so 文件。例如,-lcrypto 表示链接 libcrypto.a 或 libcrypto.so(在 Windows 上是 libcrypto-3-x64.dll)库文件。
编译为可执行文件后,解密一下上文加密后的文件:
然后我们试一下把pyc文件加密再解密后python是否可以执行!
首先执行python -m compileall .,得到main.xxx.pyc,然后改为main.pyc并且从__pycaache__中拷贝出来,
删除py文件后,直接用python执行pyc文件:
然后加密pyc,交到C程序解密再执行:

显然没什么问题,那就剩下最后一步,将解密代码移植到python解释器里面去,然后编译成一个全新的python,替换系统中的python。
但有一点需要注意,因为python解释器是先处理pyc,然后再处理py文件,如果你直接加密py文件,然后给python解释器加了几行解密代码,python解释器可能会先解密py文件然后编译成pyc,等于啥都没做,这个pyc和未加密的py文件编译的pyc是一样的。
所以,加密的文件应该是pyc,即我们部署的最终是一堆pyc文件,至于项目引入的三方包,里面没有我们项目内部的一些敏感信息,因此不需要做任何处理。
写在最后
鉴于作者能力微薄,无法实现修改 Python 解释器源码来保护代码。
当我发现自己无法实现这种方法时,随便在网上浏览同类型解决方案,无意中发现另外一个大佬的文章:如何保护你的 Python 代码 (二)—— 定制 Python 解释器,这位大佬采用的方法是:在python执行py文件时,调用解密函数,将加密code解密到内存中,然后使用p = fmemopen(plaintext, plainlen, "r")将code伪装为文件句柄传递给python解释器以实现代码动态解密。
为了防止python将解密后的代码生成pyc,大佬禁用了一切可以生成pyc的控制变量。
这不失为一种极佳的解决方案。
对于两个同样的项目,一个编译为pyc后删除py文件进行部署;另一个禁用pyc直接部署py文件,并且禁止生成pyc,执行时间效率可以断言为:每次执行时,Python 需要读取 .py 文件,解析代码,并将其编译为字节码。对于较小的项目,这个过程可能不会太慢,但随着项目的规模增大,编译过程会变得显著拖慢启动时间。
考虑到执行py文件和执行pyc文件的速度,以及python解释器现在会首先判断pyc的更新时间对py重新编译生成新的pyc,然后执行pyc文件(.pyc 文件启动更快,因为跳过了源代码解析和编译的步骤),所以我想:能否在解释器处理pyc的时候抢先读取文件内容,然后解码,将code传给python下文,以便快速执行。
正如我开头所说,本人能力有限,没能实现这种方法,非常遗憾。
参考文档

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐



 10
10 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)