java的消息处理神器:kafka
Apache Kafka 是一个分布式发布-订阅消息系统,最初由 LinkedIn 公司开发,并在 2010 年贡献给了 Apache 基金会,成为顶级开源项目。
·
Apache Kafka 是一个分布式发布-订阅消息系统,最初由 LinkedIn 公司开发,并在 2010 年贡献给了 Apache 基金会,成为顶级开源项目。以下是 Kafka 的详细介绍:
Kafka 的核心特性:
- 高吞吐量、低延迟:Kafka 能够每秒处理数十万条消息,延迟最低可达几毫秒。
- 可扩展性:Kafka 集群支持热扩展,易于向外扩展,所有的 Producer、Broker 和 Consumer 都会有多个,均为分布式的。
- 持久性、可靠性:消息被持久化到本地磁盘,并且支持数据备份,防止数据丢失。
- 容错性:允许集群中节点失败(若副本数量为 n,则允许 n-1 个节点失败)。
- 高并发:支持数千个客户端同时读写。
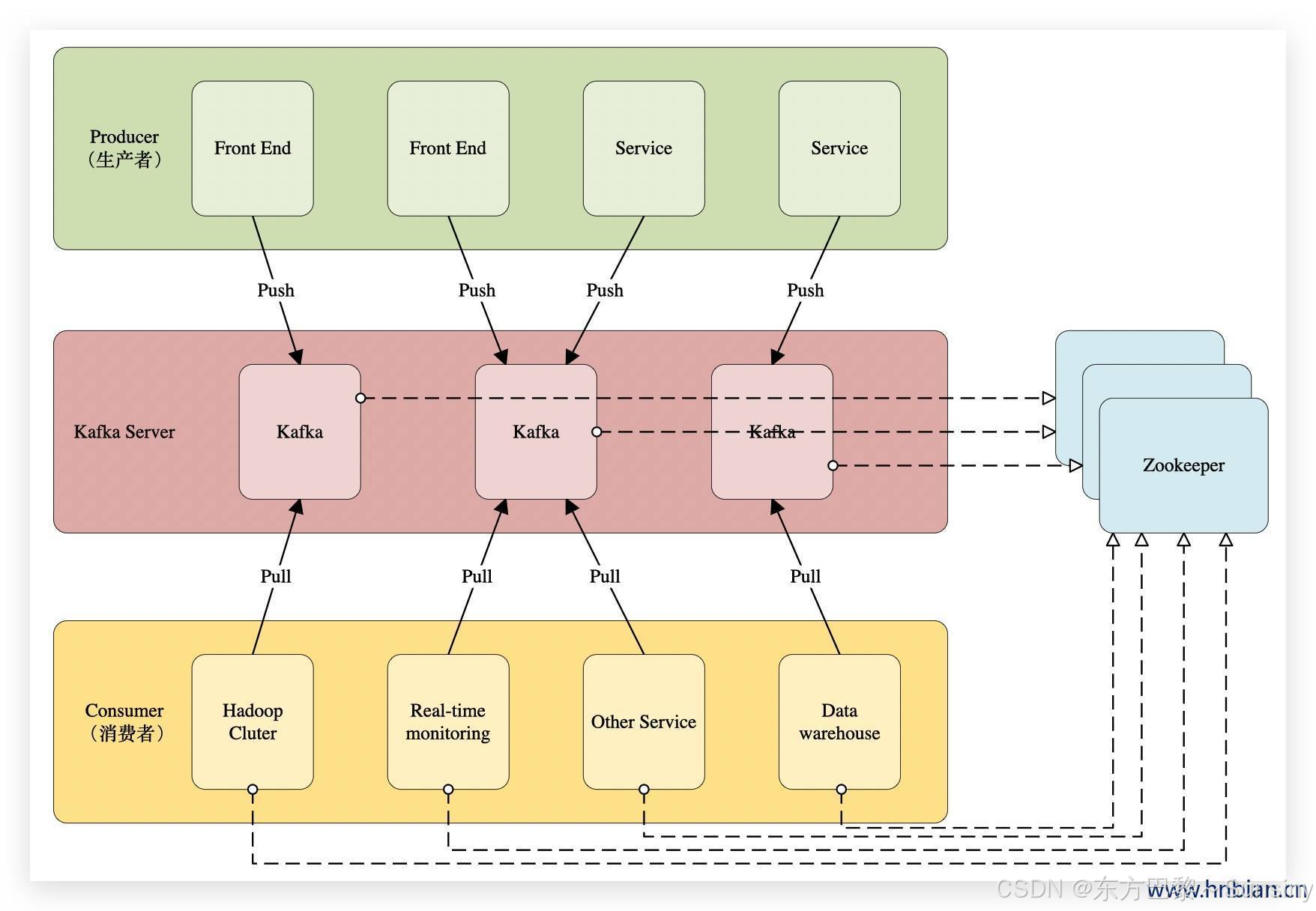
Kafka 的基本架构:
- Topic(主题):消息以流的形式存储在主题中,主题是消息的分类名。
- Producer(生产者):负责往 Kafka 集群中发送消息。
- Broker(服务代理):已发布的消息保存在一组服务器中,这些服务器被称为代理(Broker)或 Kafka 集群。
- Consumer(消费者):可以订阅一个或多个主题,并从 Broker 拉取数据,从而消费这些已发布的消息。
- Consumer Group(消费者组):每个 Consumer 属于一个特定的 Consumer Group,组内多个的 Consumer 可以共用一个 Consumer Id,组内所有的 Consumer 只能注册到一个分区上去消费。
Kafka 的工作原理:
- 生产者发布消息:应用程序作为 Kafka 的生产者,将消息发布到一个指定的主题。生产者可以选择将消息发送到特定的分区中,也可以让 Kafka 使用默认的分区选择策略。
- 消息存储:一旦生产者将消息发送到 Kafka,Kafka 将这些消息持久化存储在主题的一个或多个分区中。每个分区都是一个有序的、不可变的消息日志。
- 消息复制:Kafka 支持多副本复制机制,每个分区的消息可以有多个副本存储在不同的 Broker 上,提供高可用性和容错性。
- 消费者订阅主题:应用程序作为 Kafka 的消费者,可以订阅一个或多个主题,并从中读取消息。消费者可以以不同的消费组形式组织,每个消费组可以有多个消费者,但一个分区的消息只能被一个消费组中的一个消费者消费。
- 消费者消费消息:每个消费者维护自己的偏移量(Offset),表示它在分区中消费的位置。消费者通过轮询或订阅通知的方式从 Broker 中拉取消息,并将偏移量保存在外部存储中。
Kafka 的应用场景:
- 消息队列:Kafka 作为消息队列,实现不同系统间的解耦和异步通信。
- 日志处理与分析:Kafka 用于收集各种服务的日志,如 ELK(Elastic-Logstash-Kibana)。
- 推荐数据流:与流处理框架(如 Spark Streaming、Storm、Flink 等)集成,处理大数据领域的流式处理。
- 事件溯源:在微服务架构中,Kafka 记录微服务间的事件,如订单创建、支付完成、发货通知等。
Kafka 结合了消息队列、日志系统和流处理平台的功能,使其成为一个强大的事件流平台。
kafka搭建就自己去网上搜索吧,一大堆
代码案例
依赖
<!-- kafka-->
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>3.2.0</version>
</dependency>
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>
生产者
package com.mita.web.core.config.kafka;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.Producer;
import org.apache.kafka.clients.producer.ProducerRecord;
import java.util.Properties;
/**
* @author sunpeiyang
* @date 2024/11/12 14:52
*/
public class KafkaProducerDemo {
public static void main(String[] args) {
// 配置生产者属性
Properties props = new Properties();
// 自己的服务器ip
props.put("bootstrap.servers", "127.0.0.0.1:9092");
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
// 创建生产者实例
Producer<String, String> producer = new KafkaProducer<>(props);
// 发送消息
for (int i = 0; i < 1000000; i++) {
String key = "案例1=====" + i;
System.out.println("key:"+key);
String value = "Spring AI Alibaba 实现了与阿里云通义模型的完整适配,接下来,我们将学习如何使用 spring ai alibaba 开发一个基于通义模型服务的智能聊天应用" + i;
ProducerRecord<String, String> record = new ProducerRecord<>("test-topic", key, value);
producer.send(record);
}
// 关闭生产者
producer.close();
}
}
消费者
package com.mita.web.core.config.kafka;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import java.time.Duration;
import java.util.Collections;
import java.util.Properties;
/**
* @author sunpeiyang
* @date 2024/11/12 14:54
*/
public class KafkaConsumerDemo {
public static void main(String[] args) {
int numConsumers = 5; // 增加消费者的数量
for (int i = 0; i < numConsumers; i++) {
new Thread(new KafkaConsumerThread()).start();
}
}
static class KafkaConsumerThread implements Runnable {
@Override
public void run() {
// 配置消费者属性
Properties props = new Properties();
// 自己的服务器ip
props.put("bootstrap.servers", "127.0.0.0.1:9092");
props.put("group.id", "test-group");
props.put("enable.auto.commit", "true");
props.put("auto.commit.interval.ms", "1000");
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
// 调整消费者配置
props.put("fetch.min.bytes", "1024"); // 最小获取1KB的数据
props.put("fetch.max.wait.ms", "500"); // 最大等待500ms
// 创建消费者实例
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
// 订阅主题
consumer.subscribe(Collections.singletonList("test-topic"));
// 消费消息; 如果消息处理逻辑允许,可以批量处理消息,而不是逐条处理
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(500));
if (!records.isEmpty()) {
for (ConsumerRecord<String, String> record : records) {
System.out.printf("offset = %d, key = %s, value = %s%n", record.offset(), record.key(), record.value());
}
// 批量提交偏移量
consumer.commitSync();
}
}
}
}
}

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐



 17
17 0
0- 0



 已为社区贡献14条内容
已为社区贡献14条内容

所有评论(0)