

vulkan算法加速
动手教程(Hands-on Tutorials)
Recently, the world has seen various defining milestones in both, the gaming industry and the AI sector. In only a couple of weeks, we have seen major financial announcements in the gaming industry including Unity’s $1.3 Billion IPO and Epic Games’ $1.78B Investment. The AI sector has also been catching up with its hype, reaching a $60+ Billion Market in 2020, and bringing mind blowing applications in the intersection of AI and Gaming, including AlphaGo’s famous victory over Champion Lee Sedol, as well as deep learning powered games such as AI Dungeon (and many more applications).
最近,世界在游戏产业和AI领域都看到了各种具有里程碑意义的里程碑。 在短短几周内,我们已经看到了游戏行业的主要财务公告,包括Unity的13亿美元IPO和Epic Games的1.78BB投资。 人工智能领域也一直在追赶,到2020年将达到600亿美元的市场,并在人工智能和游戏的交汇领域带来令人瞩目的应用,包括AlphaGo击败冠军Lee Sedol的著名胜利以及深度学习驱动的游戏如AI Dungeon (以及更多应用程序)。
This article provides a technical deep dive into this intersection between the two fields, applied artificial intelligence and game development. We delve specifically into how you can leverage the power of the cross-vendor / mobile GPU frameworks for accelerated processing of machine learning and advanced data processing use-cases.
本文对应用人工智能和游戏开发这两个领域之间的交叉点进行了技术上的深入探讨。 我们专门研究如何利用跨供应商/移动GPU框架的功能来加速机器学习和高级数据处理用例的处理。

In this tutorial you’ll learn how to use the Kompute framework to build GPU optimized code inside the popular open source Godot Game Engine.
在本教程中,您将学习如何使用Kompute框架在流行的开源Godot Game Engine中构建GPU优化的代码。
You will understand how machine learning and advanced GPU compute can be leveraged in game development through the Godot Game engine.
您将了解如何通过Godot Game引擎在游戏开发中利用机器学习和高级GPU计算。
No background knowledge beyond programming experience is required, but if you are curious about the underlying AI / GPU compute concepts referenced, we suggest checking out our previous article, “Machine Learning in Mobile & Cross-Vendor GPUs Made Simple With Kompute & Vulkan”.
不需要具备编程经验的背景知识,但是如果您对所引用的基础AI / GPU计算概念感到好奇,我们建议您参考我们之前的文章“使用Kompute和Vulkan使移动和跨供应商GPU变得简单的机器学习”。
You can find the full code in the example folder in the repository, together with the GDNative Library implementation and the Godot Custom Module implementation.
您可以在存储库的示例文件夹中找到完整的代码,以及GDNative库实现和Godot自定义模块实现。
Godot游戏引擎 (The Godot Game Engine)

With over 30k github stars and more than 1k contributors Godot is the most popular OSS game engine. Godot caters for 2D and 3D development, and has been used for a broad range of mobile, desktop, console and web compatible games / applications. Godot is built in C++ making it fast and light — it’s only a 40MB download.
Godot是最受欢迎的OSS游戏引擎,拥有超过3万个github明星和超过1000个贡献者。 Godot可以满足2D和3D开发的需要,并且已被广泛用于与移动,台式机,主机和Web兼容的游戏/应用程序。 Godot是用C ++内置的,使它变得又快又轻便-仅40MB下载。
Godot is very intuitive for newcomers through robust design principles, and support for high-level languages, including its domain-specific-language GdScript which has a Python-like syntax, making it very easy to adopt. It is also possible to develop using C#, Python, Visual Scripting, C++, etc.
Godot通过健壮的设计原则对新手非常直观,并支持高级语言,包括其具有特定领域语言的GdScript (具有类似于Python的语法),因此非常易于采用。 也可以使用C#,Python,Visual Scripting,C ++等进行开发。
In this tutorial we will be building a Game using the editor, using GdScript to trigger the ML training / inference, and C++ to develop the core processing components under-the-hood.
在本教程中,我们将使用编辑器来构建游戏,使用GdScript触发ML训练/推理,并使用C ++在后台开发核心处理组件。
Vulkan Kompute (Vulkan Kompute)

Vulkan is an Open Source project led by the Khronos Group, a consortium of a very large number of tech companies who have come together to work towards defining and advancing the open standards for mobile and desktop media (and compute) technologies.
Vulkan是一个由Khronos Group领导的开源项目, Khronos Group是由许多技术公司组成的财团,它们共同致力于为移动和桌面媒体(和计算)技术定义和推进开放标准。
Large number of high profile (and new) frameworks have been adopting Vulkan as their core GPU processing SDK. The Godot Engine itself is working on a major 4.0 update that will bring Vulkan as its core rendering engine.
大量高端(和新的)框架已采用Vulkan作为其核心GPU处理SDK。 Godot引擎本身正在进行4.0的主要更新,它将把Vulkan作为其核心渲染引擎。
As you can imagine, the Vulkan SDK provides very low-level access to GPUs, which allows for very specialized optimizations. This is a great asset for data processing and GPU developers — the main disadvantage is the verbosity involved, requiring 500–2000+ lines of code to only get the base boilerplate required to even start writing the application logic. This can result in expensive developer cycles and errors that can lead to larger problems. This was one of the main motivations for us to start the Vulkan Kompute project.
您可以想象,Vulkan SDK提供了对GPU的低级访问,从而可以进行非常专业的优化。 对于数据处理和GPU开发人员来说,这是一笔巨大的财富-主要缺点是涉及冗长,需要500-2000 +行代码才能获得甚至开始编写应用程序逻辑所需的基础样板。 这会导致昂贵的开发人员周期和错误,从而导致更大的问题。 这是我们启动Vulkan Kompute项目的主要动机之一。
Vulkan Kompute is a framework built on top of the Vulkan SDK, specifically designed to extend its compute capabilities as a simple to use, highly optimized, and mobile friendly General Purpose GPU computing framework.
Vulkan Kompute是在Vulkan SDK之上构建的框架,专门设计用于扩展其计算功能,使其成为易于使用,高度优化和移动友好的通用GPU计算框架。

Kompute was not built to hide any of the core Vulkan concepts — the core Vulkan API is very well designed. Instead it augments Vulkan’s computing capabilities with a BYOV (bring your own Vulkan) design, enabling developers by reducing boilerplate code required and automating some of the more common workflows involved in writing Vulkan applications.
Kompute并不是为了隐藏任何Vulkan核心概念而构建的-核心Vulkan API的设计非常好。 相反,它通过BYOV(带上您自己的Vulkan)设计增强了Vulkan的计算能力,从而通过减少所需的样板代码并自动执行编写Vulkan应用程序所涉及的一些更常见的工作流程,使开发人员能够使用。
For new developers curious to learn more, it provides a solid base to get started into GPU computing. For more advanced Vulkan developers, Kompute allows them to integrate it into their existing Vulkan applications, and perform very granular optimizations by getting access to all of the Vulkan internals when required. The project is fully open source, and we welcome bug reports, documentation extensions, new examples or suggestions — please feel free to open an issue in the repo.
对于渴望了解更多信息的新开发人员,它为入门GPU计算提供了坚实的基础。 对于更高级的Vulkan开发人员,Kompute允许他们将其集成到现有的Vulkan应用程序中,并通过在需要时访问所有Vulkan内部组件来执行非常精细的优化。 该项目是完全开源的,我们欢迎错误报告,文档扩展,新示例或建议-请随时在存储库中打开一个问题。
游戏开发中的人工智能 (Artificial Intelligence in Game Development)
In this post we will be building upon the Machine Learning use-case we created in the “Machine Learning in Mobile & Cross-Vendor GPUs Made Simple With Kompute & Vulkan” article. We will not be covering the underlying concepts in as much detail as in that article, but we’ll still introduce the high level intuition required in this section.
在这篇文章中,我们将基于在“使用Kompute和Vulkan简化了移动和跨供应商GPU的机器学习”一文中创建的机器学习用例。 我们不会像那篇文章那样详细介绍底层概念,但是我们仍将介绍本节中所需要的高级直觉。
To start with, we will need an interface that allows us to expose our Machine Learning logic, which will require primarily two functions:
首先,我们需要一个接口,使我们可以暴露我们的机器学习逻辑,这主要需要两个功能:
train(…)— function which will allow the machine learning model to learn to predict outputs from the inputs providedtrain(…)—将使机器学习模型能够学习根据提供的输入预测输出的功能predict(...)— function that will predict the output of an unknown instance. This can be visualised in the two workflows outlined in the image below.predict(...)-将预测未知实例的输出的函数。 可以在下图中概述的两个工作流程中将其可视化。

Particularly in game development, this would also be a common pattern for machine learning workflows, for both predictive and explanatory modelling use cases. This often consists of leveraging data generated by your users as they interact directly (or indirectly) with the game itself. This data can then serve as training features for machine learning models. Training of new models can be performed through manual “offline” workflows that data scientists would carry out, or alternatively through automated triggers retraining models.
特别是在游戏开发中,对于预测和解释性建模用例,这也是机器学习工作流程的通用模式。 这通常包括利用用户在与游戏本身直接(或间接)交互时生成的数据。 然后,这些数据可以用作机器学习模型的训练功能。 新模型的训练可以通过数据科学家将执行的手动“离线”工作流执行,也可以通过自动触发器重新训练模型来执行。
Godot的机器学习项目 (Machine Learning Project in Godot)
We will start by providing a high level overview of how our Vulkan Kompute bindings will be used in our game in Godot. We will create a simple project and train the ML model we created, which will run in the GPU. In this section we will already have the custom KomputeModelML Godot class accessible — details on how to build it and import it into the godot project are covered in a latter section.
我们将首先概述如何在Godot中的游戏中使用Vulkan Kompute绑定。 我们将创建一个简单的项目并训练我们创建的ML模型,该模型将在GPU中运行。 在本节中,我们已经可以访问自定义的KomputeModelML Godot类-在下一节中将详细介绍如何构建它并将其导入到godot项目中。

For this we are using Godot version 3.2.3 stable. Create a new project and a new 2D scene. You should see a blank project with a top level 2D node, as per the image on the left.
为此,我们使用Godot 3.2.3稳定版。 创建一个新项目和一个新的2D场景。 如左图所示,您应该看到一个带有顶级2D节点的空白项目。
Now we’ll be able to start adding resources to our game. We will start by creating a simple UI interface / menu consisting of inputs for the machine learning model that reflects the workflows covered in the previous architecture diagram.
现在,我们可以开始向游戏添加资源了。 我们将首先创建一个简单的UI界面/菜单,其中包含针对机器学习模型的输入,这些输入反映了先前体系结构图中涵盖的工作流程。
We will have two input LineEdit text boxes for the data X_i and X_j, and one input LineEdit text box for the Y expected predictions. The image below shows the node structure used to build the UI. You can also access the full godot project in the repo by importing the project.godot file. The nodes will be referenced to read the input data and display the output predictions (and learned parameters).
我们将为数据X_i和X_j提供两个输入LineEdit文本框,并为Y预期预测提供一个输入LineEdit文本框。 下图显示了用于构建UI的节点结构。 您还可以通过导入project.godot文件来访问回购中的完整godot项目。 将引用这些节点以读取输入数据并显示输出预测(以及学习的参数)。
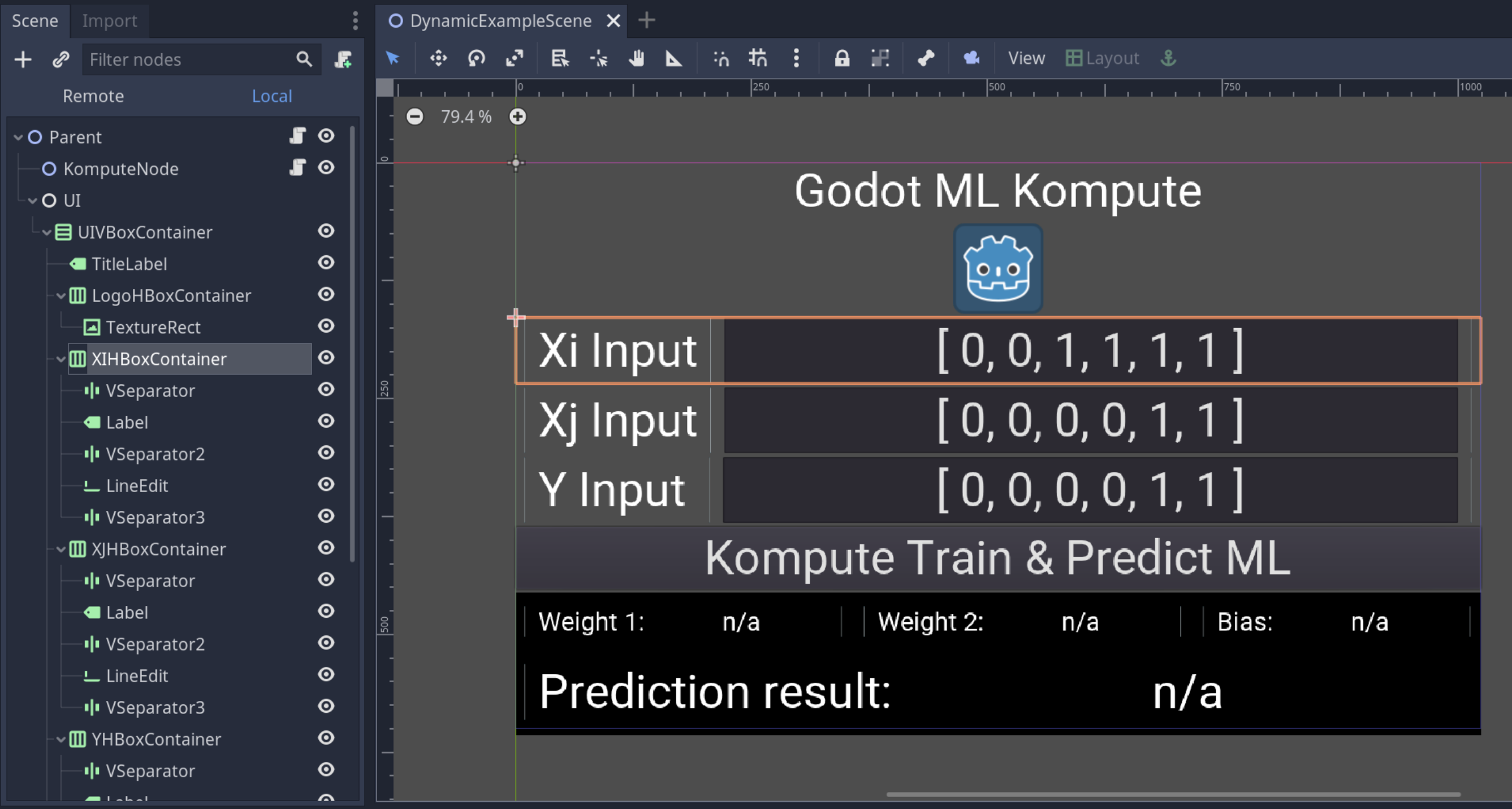
We will now be able to add the GdScript code in Godot which will allow us to read the inputs, train the model and perform predictions — this script is created under the Parentnode.
现在,我们将能够在Godot中添加GdScript代码,这将使我们能够读取输入,训练模型并执行预测-该脚本在Parent节点下创建。
Below is the full script that we are using to perform the processing, which is using the KomputeModelML custom Godot class we build in the next section. We’ll break down each of the different areas of the code below.
下面是我们用来执行处理的完整脚本,该脚本使用了我们在下一节中构建的KomputeModelML自定义Godot类。 我们将在下面的代码中分解每个不同的区域。
First we define variables to make the referencing of Godot Editor nodes simpler. This can be done with the dollar sign syntax $NODE/PATH as implemented in the snipped below.
首先,我们定义变量以简化对Godot Editor节点的引用。 可以使用以下摘录中实现的美元符号语法$NODE/PATH来完成此操作。
The compute_ml() function below contains the logic for the machine learning training and predictions. We start by reading the inputs from the text boxes using the Godot editor node references.
下面的compute_ml()函数包含用于机器学习训练和预测的逻辑。 我们首先使用Godot编辑器节点引用从文本框中读取输入。
We now can create an instance from the C++ class bindings that we will be constructing in the next section. This is the class that exposes the training and prediction functions that we will be using for machine learning inference.
现在,我们可以从下一部分将要构造的C ++类绑定中创建一个实例。 这是一门课程,介绍了我们将用于机器学习推理的训练和预测功能。
We now can train our model by passing the inputs and the expected predictions. The ML model underneath is a logistic regression model, which will adjust its internal parameters to fit the inputs and outputs best, resulting in a model that is then able to predict unseen datapoints.
现在,我们可以通过传递输入和预期的预测来训练模型。 下方的ML模型是逻辑回归模型,该模型将调整其内部参数以使其最适合输入和输出,从而生成一个模型,该模型随后可以预测看不见的数据点。
Now that we have trained our model, we can perform predictions on unseen data-points. For simplicity, we will pass in the same inputs we used for testing, however you could pass completely new arrays and see what predictions it produces. We can then display the results in the preds_node reference node variable that we defined, which will show in the display.
现在我们已经训练了模型,我们可以在看不见的数据点上进行预测。 为简单起见,我们将传递用于测试的相同输入,但是您可以传递全新的数组并查看其产生的预测。 然后,我们可以在定义的preds_node参考节点变量中显示结果,该变量将显示在显示屏中。
Finally we want to also display the learned parameters, which in this case it includes w1 , w2 and the bias . We are able to display the weights and bias in the respective labels.
最后,我们还要显示学习的参数,在这种情况下,它包括w1 , w2和bias 。 我们能够在各个标签中显示权重和偏差。
The final thing to set up is to connect the “Kompute Train & Predict” button into the compute_ml function, which can be done by setting up a signal that points to the function itself via the editor.
设置的最后一件事情是将“ Kompute Train&Predict”按钮连接到compute_ml函数,这可以通过设置一个通过编辑器指向函数本身的信号来完成。

Once this is all set up, we can run the Game and trigger the training and prediction using the provided inputs. We can then see the learned parameters as well as the prediction outputs. It is also possible to see how the learned parameters change as we modify the inputs y, xi and xj.
一旦设置完成,我们就可以运行游戏并使用提供的输入触发训练和预测。 然后,我们可以看到学习到的参数以及预测输出。 还可能看到随着我们修改输入y , xi和xj ,学习到的参数如何变化。

Vulkan Kompute ML实施 (Vulkan Kompute ML Implementation)
Now that there is an intuition on what is happening in the game level, we are able to code our underlying C++ class to create the Godot bindings using the Vulkan Kompute framework.
既然已经对游戏级别发生了什么有了直觉,我们就可以使用Vulkan Kompute框架对基础C ++类进行编码,以创建Godot绑定。

We will be following the design principles of Kompute which are outlined in this accompanying diagram showing the different components. We will be following this workflow to load the data in the GPU and perform the training.
我们将遵循Kompute的设计原理,该原理在此附图中概述,显示了不同的组件。 我们将遵循此工作流程,以将数据加载到GPU中并进行培训。
The header file for the Godot class binding implementation is outlined below, which we will break down in detail. As you can see creating a C++ class with bindings is quite intuitive, and you can see the same functions that we used to call from our Godot GdScript above.
下面概述了Godot类绑定实现的头文件,我们将对其进行详细介绍。 如您所见,使用绑定创建C ++类非常直观,并且您可以看到上面从Godot GdScript调用过的相同函数。
The initial section of the class header file includes:
类头文件的初始部分包括:
Import of the
Kompute.hppheader containing all the Vulkan Kompute dependencies that we’ll use in this project导入包含将在本项目中使用的所有Vulkan Kompute依赖项的
Kompute.hpp标头The top-level
Godot.hppimport is required to ensure all Godot components are available.需要顶层
Godot.hpp导入,以确保所有Godot组件均可用。Node2D is the resource that we will be inheriting from, but you can inherit from other classes in the inheritance tree depending on how you plan to use your custom Godot class
For data passing across the application, we will be using a Godot
Arraywhich will handle transfer between GdScript and the Naive C++, as well as a KomputeTensorwhich will handle the GPU data management.对于在整个应用程序中传递的数据,我们将使用Godot
Array用于处理GdScript和Naive C ++之间的传输)以及KomputeTensor用于处理GPU数据管理)。- The GODOT_CLASS macro definition extends the class by adding extra Godot related functionality. As we will see below, you will need to use GDCLASS instead when building as a Godot custom module. GODOT_CLASS宏定义通过添加额外的Godot相关功能来扩展类。 正如我们将在下面看到的那样,在构建为Godot自定义模块时,您将需要使用GDCLASS。
Following the base functionality, we have to define the core logic:
遵循基本功能,我们必须定义核心逻辑:
void train(Array y, Array xI, Array xJ)—Trains the machine learning model using the GPU native code for the logistic regression model. It takes the input array(s)X, and the arrayycontaining the expected outputs.void train(Array y, Array xI, Array xJ)使用GPU本机代码对逻辑回归模型训练机器学习模型。 它接受输入数组X和包含预期输出的数组y。Array predict(Array xI, Array xJ)—Perform the inference request. In this implementation it is not using GPU code as generally there tends to be less performance gains through parallelization on the inference side. However there are still expected performance gains if multiple inputs are processed in parallel (which this function allows for).Array predict(Array xI, Array xJ)执行推理请求。 在此实现中,它不使用GPU代码,因为通常在推理端通过并行化会获得较少的性能提升。 但是,如果并行处理多个输入(此功能允许),仍然会获得预期的性能提升。Array get_params()—Returns an array containing the learned parameters in the format of[ <weight_1>, <weight_2>, <bias> ].Array get_params()—以[ <weight_1>, <weight_2>, <bias> ]的格式返回包含学习到的参数的数组。
We then are able to declare the methods that will be bound between the C++ and the high level GdScript Godot Engine, and accessible to the editor and broader Game in general. We’ll look briefly below at the code required to register a function.
然后,我们可以声明将在C ++和高级GdScript Godot引擎之间绑定的方法,并且通常可供编辑器和更广泛的Game访问。 我们将在下面简要介绍注册功能所需的代码。
For data management we will be using Kompute tensors as well as Arrays — in this case we will only need to “learn” and “persist” the weights and biases of our logistic regression model.
对于数据管理,我们将使用Kompute张量和数组-在这种情况下,我们仅需要“学习”和“坚持”我们逻辑回归模型的权重和偏差。
Finally, we also define the shader code, which is basically the code that will be executed as machine code inside of the GPU. Kompute allows us to pass a string containing the code, however for production deployments it is possible to convert the shaders to binary, and also use the utilities available to convert into header files.
最后,我们还定义了着色器代码,该代码基本上是将作为GPU内部的机器代码执行的代码。 Kompute允许我们传递包含代码的字符串,但是对于生产部署,可以将着色器转换为二进制,也可以使用可用的实用程序将其转换为头文件。
If you are interested in the full implementation you can find all the files in the gdnative implementation and custom module implementation folders. Furthermore if you are interested in the theoretical and underlying foundational concepts of these techniques, this is covered fully in our previous post.
如果您对完整的实现感兴趣,则可以在gdnative实现和自定义模块实现文件夹中找到所有文件。 此外,如果您对这些技术的理论和基础概念感兴趣,请在我们的上一篇文章中全面介绍。
编译并集成到Godot中 (Compiling and Integrating into Godot)
Now that we have the base code for our GPU optimized machine learning model, we are now able to proceed to running it in our Godot game engine. There are two main ways in which Godot allows us to add C++ code into our projects:
现在,我们有了优化GPU的机器学习模型的基本代码,现在我们可以继续在Godot游戏引擎中运行它了。 Godot允许我们通过两种主要方式将C ++代码添加到我们的项目中:
GdNative Library Build Instructions — In Godot you can add your own “GdNative scripts” which are basically C++ classes with bindings to GdScript, which means these can be used and referenced dynamically in the project. This approach works with the standard Godot installation and doesn’t require re-compiling the full editor like the 2nd option.
GdNative库构建说明—在Godot中,您可以添加自己的“ GdNative脚本”,这些脚本基本上是具有与GdScript绑定的C ++类,这意味着它们可以在项目中动态使用和引用。 这种方法适用于标准的Godot安装,不需要像2nd选项那样重新编译完整的编辑器。
Custom Module Build Instructions— In Godot only the underlying core classes are part of the “core” components; everything else — the UI, the editor, the GdScript language, the networking capabilities — are custom models. Writing a custom module is easy, and this is how we are able to expose some of the core Kompute functionality. This option requires the full Godot C++ project to be recompiled with the custom module.
定制模块构建说明-在Godot中,仅基础核心类是“核心”组件的一部分; 用户界面,编辑器,GdScript语言,网络功能等所有其他东西都是自定义模型。 编写自定义模块很容易,这就是我们能够公开一些Kompute核心功能的方式。 此选项要求使用自定义模块重新编译完整的Godot C ++项目。

Once you set one of these methods through the instructions, you will be able to access the custom object from within Godot. There are some nuanced implementation differences between each approach.
一旦按照说明设置了这些方法之一,便可以从Godot中访问自定义对象。 每种方法之间存在细微的实现差异。
We won’t be covering specific build details in the blog post, but you will be able to find the exact code and build instructions in the GdNative Library / Custom Module links above.
我们不会在博客文章中介绍特定的构建细节,但是您将能够在上面的GdNative库/自定义模块链接中找到确切的代码并构建说明。
下一步是什么? (What’s next?)
Congratulations, you’ve made it all the way to the end! Although there was a broad range of topics covered in this post, there is a massive amount of concepts that were skimmed through. These include the underlying Vulkan concepts, GPU computing fundamentals, machine learning best practices, and more advanced Vulkan Kompute concepts. Luckily, there are resources online to expand your knowledge on each of these. Here are some links I recommend for further reading:
恭喜,您已经做到了一切! 尽管本文涵盖了广泛的主题,但也有大量的概念。 其中包括基本的Vulkan概念,GPU计算基础,机器学习最佳实践以及更高级的Vulkan Kompute概念。 幸运的是,在线上有资源可以扩展您的知识。 以下是一些我建议您进一步阅读的链接:
“Machine Learning in Mobile & Cross-Vendor GPUs Made Simple With Kompute & Vulkan” article with a deeper dive in theory and concepts
“使用Kompute和Vulkan使移动和跨供应商GPU中的机器学习变得简单”,文章深入探讨了理论和概念
Vulkan Kompute Documentation for more details and further examples
Vulkan Kompute文档以获取更多详细信息和更多示例
The Machine Learning Engineer Newsletter if you want to keep updated on articles around Machine Learning
机器学习工程师通讯,如果您想随时了解有关机器学习的文章
Awesome Production Machine Learning list for open source tools to deploy, monitor, version and scale your machine learning
很棒的生产机器学习列表,提供了用于部署,监视,版本化和扩展机器学习的开源工具
Introduction to ML for Coders course by FastAI to learn further machine learning concepts
FastAI的ML for Coders课程简介,以学习更多的机器学习概念
Vulkan SDK Tutorial for a deep dive into the underlying Vulkan components
Vulkan SDK教程,深入了解底层Vulkan组件
vulkan算法加速






 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)