Apache Paimon-流数据湖
1、统一批处理和流处理:Paimon支持批写和批读,以及流式写更改和流式读表更改日志。2、数据湖:Paimon具有成本低、可靠性高、元数据可扩展等优点,具有数据湖存储的所有优势。3、合并引擎:Paimon支持丰富的合并引擎。缺省情况下,保留主键的最后一项记录,可以“部分更新”或“聚合”。4、变更日志生成:Paimon支持丰富的Changelog producer例如“lookup”和“full-c
Apache Paimon-流数据湖
1、概述
1.1、核心功能
1、统一批处理和流处理:Paimon支持批写和批读,以及流式写更改和流式读表更改日志。
2、数据湖:Paimon具有成本低、可靠性高、元数据可扩展等优点,具有数据湖存储的所有优势。
3、合并引擎:Paimon支持丰富的合并引擎。缺省情况下,保留主键的最后一项记录,可以“部分更新”或“聚合”。
4、变更日志生成:Paimon支持丰富的Changelog producer例如“lookup”和“full-compaction”,可以从任何数据源生成正确且完整的变更日志从而简化流管道的构建。
5、丰富的表类型: 除了主键表,Paimon还支持append-only只追加表,自动压缩小文件,并提供有序的流读取来替换消息队列。
6、模式演化:支持完整的模式演化,例如可以重新命名列和重新排序。
1.2、适合场景
Apache Paimon 适用于需要在流数据上进行实时查询和分析的场景。它可以帮助用户更容易地构建流式数据湖,实现高吞吐、低延迟的数据摄入、流式订阅以及实时查询能力。例如在金融、电子商务、物联网等行业中,可以使用 Apache Paimon 来实现实时推荐、欺诈检测、异常检测等应用。
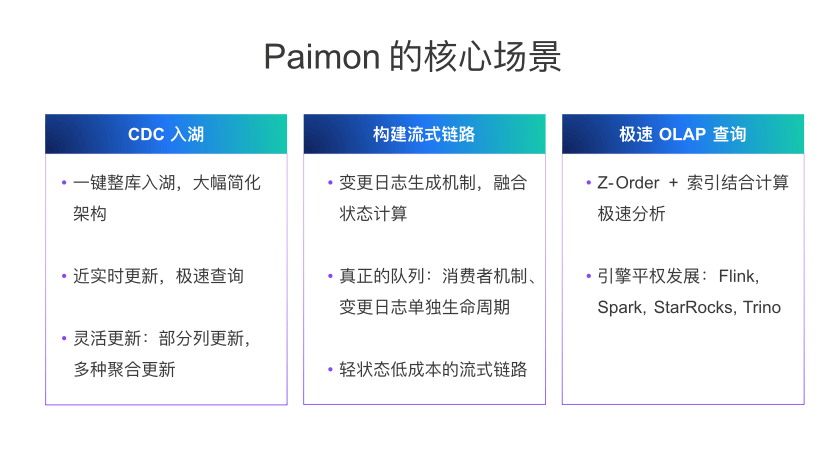
(1)CDC入湖
Paimon 对此做了相当多的优化,来保证更简化的架构、更好的性能与实时性。具体有:一键整库入湖,大幅简化架构;也可达到实时更新、极速查询的场景,且在此基础上成本不高;可以灵活更新,定义部分列更新、多种聚合更新。
(2)构建流式链路
可以用 Paimon 来构建完整的 Streaming 链路,有以下几个支撑的场景:第一,可生成变更日志,在流读时就能拿到已更新好的全行的 Record 数据,这非常有利于 Streaming 链路的构建;第二,Paimon 也朝着变成真正的队列的方式向前发展,有消费者机制,在最新版本当中,有变更日志单独生命周期管理,可像 Kafka 一样定义更长的变更日志的生命周期,比如 Kafka 保存一天以上或者三天;在此基础上,构成了轻状态低成本的流式链路。
(3)极速OLAP查询
支持多种执行引擎查询。
1.3、架构原理
1.3.1、总体架构
Paimon 创新的结合了湖存储 + LSM + 列式格式 (ORC, Parquet),为湖存储带来大规模实时更新能力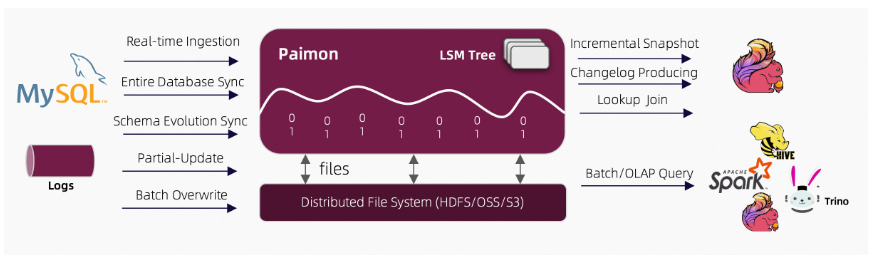
1.3.2、文件布局
表的所有文件都存储在一个基本目录下。Paimon文件以分层的方式组织。下图说明了文件布局。从快照文件开始,Paimon读取器可以递归地访问表中的所有记录。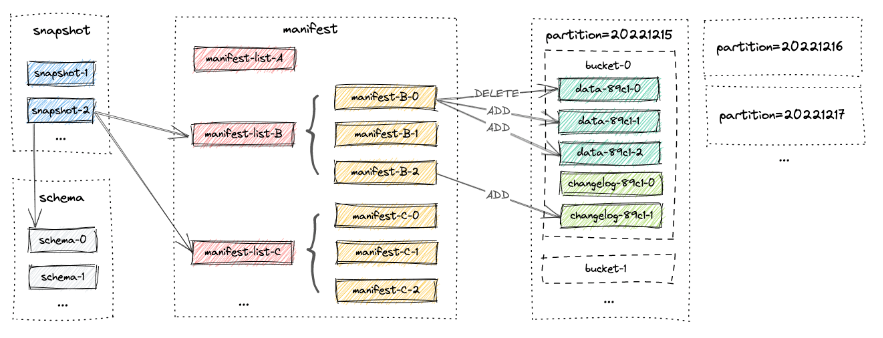
快照文件 :所有快照文件都保存在快照目录下。快照文件是一个JSON文件,其中包含有关该快照的信息,包括架构文件使用包含此快照的所有更改的清单列表。
Manifest文件:所有清单列表和清单文件都存储在manifest目录中。清单列表是清单文件名的列表,清单文件是包含有关LSM数据文件和更改日志文件的更改的文件。例如在相应的快照中创建了哪个LSM数据文件,删除了哪个文件。
数据文件:数据文件按分区和桶分组。每个桶目录包含一个LSM树及其变更日志文件。目前,Paimon支持使用orc(默认)、parquet和avro作为数据文件格式。
LSM树:Paimon采用LSM树(日志结构的合并树)作为文件存储的数据结构。数据文件中的记录按其主键排序;在Sorted Runs中,数据文件的主键范围从不重叠。不同Sorted Runs可能有重叠的主键范围,甚至可能包含相同的主键。在查询LSM树时,必须将所有Sorted Runs组合起来,并且必须根据用户指定的合并引擎和每条记录的时间戳合并具有相同主键的所有记录。写入LSM树的新记录将首先在内存中进行缓冲。当内存缓冲区已满时,将对内存中的所有记录进行排序并刷新到磁盘。得益于 LSM 数据结构的追加写能力,Paimon 在大规模的更新数据输入的场景中提供了出色的性能。
Sorted Runs:LSM 树将文件组织成多个Sorted Run。Sorted Run由一个或多个数据文件组成,并且每个数据文件恰好属于一个Sorted Run,数据文件中的记录按其主键排序。
合并(Compaction):当越来越多的记录写入LSM树时,Sorted Runs次数将会增加。因为查询LSM树需要将所有Sorted Runs组合在一起,太多的Sorted Runs将导致查询性能差,甚至导致内存不足。为了限制排序运行的次数,必须偶尔将几个Sorted Runs合并为一个大的Sorted Runs,这个过程称为合并或压缩,合并是一个资源密集型过程,它会消耗一定的CPU时间和磁盘IO,因此过于频繁的压缩可能会导致写速度变慢。这是查询性能和写性能之间的权衡。目前,Paimon采用了一种与Rocksdb的通用压实类似的压实策略。默认情况下,当Paimon将记录追加到LSM树时,它还将根据需要执行压缩,还可以选择在专用压缩作业中执行所有压缩。
2、集成FLink和Spark
支持通过Flink SQL对Paimon进行读写操作。下文通过实例介绍Flink SQL对Paimon进行读写操作。
2.1、Flink SQL集成Paimon
2.1.1、Catalog配置
通过Flink SQL对Paimon进行读写操作的三种方法:Filesystem Catalog、Hive Catalog和DLF Catalog:
启动FLink SQL:
sql-client.sh
(1)Filesystem Catalog
Filesystem Catalog仅将元数据保存在文件系统或对象存储中。
(需要注意的是:如果warehouse是首次制定,会在当前sql session中创建;如果是非首次,会在当前sql session中映射出之前首次创建Catalog)
CREATE CATALOG test_catalog WITH (
'type' = 'paimon',
'metastore' = 'filesystem',
'warehouse' = 'oss://<yourBucketName>/warehouse'
);
(2)Hive Catalog
CREATE CATALOG test_catalog WITH (
'type' = 'paimon',
'metastore' = 'hive',
'uri' = 'thrift://master-1-1:9083', -- uri参数指向Hive metastore service的地址。
'warehouse' = 'oss://<yourBucketName>/warehouse'
);
(3)DLF Catalog (阿里云数据湖构建(Data Lake Formation,简称DLF))
CREATE CATALOG test_catalog WITH (
'type' = 'paimon',
'metastore' = 'dlf',
'hive-conf-dir' = '/etc/taihao-apps/flink-conf',
'warehouse' = 'oss://<yourBucketName>/warehouse'
);
2.1.2、流作业读写Paimon
执行以下Flink SQL语句,在Catalog中创建一张表,并读写表中的数据。
-- 设置为流作业。
SET 'execution.runtime-mode' = 'streaming';
-- Paimon在流作业中需要设置checkpoint。
SET 'execution.checkpointing.interval' = '10s';
-- 使用之前创建的catalog。
USE CATALOG test_catalog;
-- 创建并使用一个测试database。
CREATE DATABASE test_db;
USE test_db;
-- 用datagen产生随机数据。
CREATE TEMPORARY TABLE datagen_source (
uuid int,
kind int,
price int
) WITH (
'connector' = 'datagen',
'fields.kind.min' = '0',
'fields.kind.max' = '9',
'rows-per-second' = '10'
);
-- 创建Paimon表。
CREATE TABLE test_tbl (
uuid int,
kind int,
price int,
PRIMARY KEY (uuid) NOT ENFORCED
);
-- 向Paimon中写入数据。
INSERT INTO test_tbl SELECT * FROM datagen_source;
-- 读取表中的数据。
-- 流式查询作业运行的过程中,上面触发的流式写入作业仍在运行。
-- 您需要保证Flink集群有足够的资源(task slot)同时运行两个作业,否则无法查到数据。
SELECT kind, SUM(price) FROM test_tbl GROUP BY kind;
2.1.3、OLAP查询Paimon
执行以下Flink SQL语句,对刚才创建的表进行OLAP查询。
-- 设置为批作业。
RESET 'execution.checkpointing.interval';
SET 'execution.runtime-mode' = 'batch';
-- 使用tableau展示模式,在命令行中直接打出结果。
SET 'sql-client.execution.result-mode' = 'tableau';
-- 对表中数据进行查询。
SELECT kind, SUM(price) FROM test_tbl GROUP BY kind;
2.2、Spark SQL集成Paimon
通过Spark SQL对Paimon进行读写操作。
2.2.1、创建Catalog
通过Spark SQL对Paimon进行读写操作的三种方法:Filesystem Catalog、Hive Catalog和DLF Catalog:
(1)Filesystem Catalog
Filesystem Catalog仅将元数据保存在文件系统或对象存储中。
sh spark-sql --conf spark.sql.catalog.paimon=org.apache.paimon.spark.SparkCatalog \
--conf spark.sql.catalog.paimon.metastore=filesystem \
--conf spark.sql.catalog.paimon.warehouse=oss://<yourBucketName>/warehouse \
--conf spark.sql.extensions=org.apache.paimon.spark.extensions.PaimonSparkSessionExtensions
(2)Hive Catalog
sh spark-sql --conf spark.sql.catalog.paimon=org.apache.paimon.spark.SparkCatalog \
--conf spark.sql.catalog.paimon.metastore=hive \
--conf spark.sql.catalog.paimon.uri=thrift://master-1-1:9083 \
--conf spark.sql.catalog.paimon.warehouse=oss://<yourBucketName>/warehouse \
--conf spark.sql.extensions=org.apache.paimon.spark.extensions.PaimonSparkSessionExtensions
(3)DLF Catalog
sh spark-sql --conf spark.sql.catalog.paimon=org.apache.paimon.spark.SparkCatalog \
--conf spark.sql.catalog.paimon.metastore=dlf \
--conf spark.sql.catalog.paimon.warehouse=oss://<yourBucketName>/warehouse \
--conf spark.sql.extensions=org.apache.paimon.spark.extensions.PaimonSparkSessionExtensions
2.2.2、Spark SQL读写Paimon
-- 切换到paimon catalog
USE paimon;
-- 在之前创建的paimon的Catalog中,创建并使用一个测试DATABASE。
CREATE DATABASE test_db;
USE test_db;
-- 创建Paimon表。
CREATE TABLE test_tbl (
uuid int,
name string,
price double
) TBLPROPERTIES (
'primary-key' = 'uuid'
);
-- 向Paimon表中写入数据。
INSERT INTO test_tbl VALUES (1, 'apple', 3.5), (2, 'banana', 4.0), (3, 'cherry', 20.5);
-- 读取表中的数据。
SELECT * FROM test_tbl;
2.2.3、通过Spark CLI读Paimon中的数据
val dataset = spark.read.format("paimon").load("oss://<yourBucketName>/warehouse/test_db.db/test_tbl")
dataset.createOrReplaceTempView("test_tbl")
spark.sql("SELECT * FROM test_tbl").show()
3、FLink写入性能优化
(1)检查点设置
Paimon的写入性能与检查点密切相关。若需要更大的写入吞吐量,则:
1、增加检查点间隔,或者仅使用批处理模式。
2、增加写入缓冲区大小。
3、启用写缓冲区溢出。
4、如果您使用固定存储桶模式,请重新调整存储桶数量。
(2)并行度设置
建议sink的并行度小于等于bucket的数量,最好相等。
(3)Compaction
当Sorted Run数量较少时,Paimon writer 将在单独的线程中异步执行压缩,因此记录可以连续写入表中。然而,为了避免Sorted Runs的无限增长,当Sorted Run的数量达到阈值时,writer将不得不暂停写入。下表属性确定阈值。
当 num-sorted-run.stop-trigger 变大时,写入停顿将变得不那么频繁,从而提高写入性能。但是,如果该值变得太大,则查询表时将需要更多内存和 CPU 时间。如果您担心内存 OOM,请配置sort-spill-threshold。它的值取决于你的内存大小。
4、FLink读取性能优化

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐



 18
18 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)