
实战:java基础系列之【 Nio:zero copy零拷贝MappedByteBuffer和FileChannel】
从前面文章我们可以知道,零拷贝是Linux提供的io性能优化技术,而java并不完全都支持。目前只支持两种:内存映射(mmap)和发送文件(sendfile)。其方法都在java.nio包下面,对应java.nio.channels.FileChannel和java.nio.MappedByteBuffer;对应底层实现是两个核心本地方法:transferTo0、map0。总结:利用 FileCh
概叙
科普文:软件架构Linux系列之【零拷贝-zero copy】-CSDN博客
科普文:BIO、NIO和AIO小结_bio和nio-CSDN博客
从前面文章我们可以知道,零拷贝是Linux提供的io性能优化技术,零拷贝技术通过减少数据在内核态和用户态之间的拷贝次数,显著提升了I/O操作的性能;而java并不完全都支持。
目前只支持两种:内存映射(mmap)和发送文件(sendfile)。其方法都在java.nio包下面,对应java.nio.channels.FileChannel和java.nio.MappedByteBuffer;对应底层实现是两个核心本地方法:transferTo0、map0。
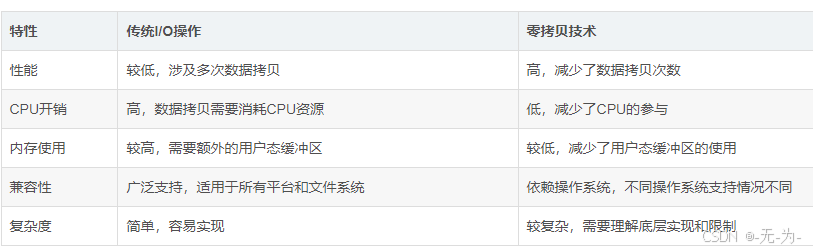
零拷贝的优缺点对比
零拷贝技术虽然在性能上有显著优势,但也有其局限性。以下是传统I/O操作和零拷贝技术的优缺点对比:
零拷贝的使用场景
零拷贝技术适用于需要处理大量数据传输的场景,如:
- 文件服务器:将文件从磁盘传输到网络客户端。
- 视频流媒体服务器:高效地传输视频数据。
- 日志处理系统:将日志文件从一个存储位置移动到另一个存储位置。
注意事项
尽管零拷贝技术在性能上有显著优势,但在实际应用中需要考虑以下几点:
- 操作系统支持:不同操作系统对零拷贝的支持情况不同,需要确认目标操作系统是否支持零拷贝。
- 文件类型:零拷贝主要适用于常规文件,对于一些特殊文件(如套接字文件),可能需要额外处理。
- 错误处理:在实现零拷贝时,需要注意错误处理和边界条件,如文件大小变化、读写权限等。
JVM 层面零拷贝原理
我们在上面看到两个核心本地方法:transferTo0、map0,前者用于在操作系统上直接传输文件到target缓冲区中,map0用于进行数据映射。本节就详细说明这两个函数在JNI层面上的实现原理。
JNI原理之transferTo0方法原理
我们这里直接看Linux的实现,该方法用C的宏定义来选择不同平台下的函数实现,我们这里只考虑Linux内核的实现,我们看到这里直接调用Linux内核的sendfile64函数进行实现。详细如下。
JNIEXPORT jlong JNICALL Java_sun_nio_ch_FileChannelImpl_transferTo0(JNIEnv *env, jobject this,
jint srcFD,
jlong position, jlong count,
jint dstFD)
{
off64_t offset = (off64_t)position;
jlong n = sendfile64(dstFD, // 目标描述符
srcFD, // 源描述符
&offset, // 源传送偏移量
(size_t)count); // 传送大小
...
return n;
}
JNI原理之map0方法原理
我们看到该函数首先获取映射文件的fd,随后设置映射的保护权限protections和映射属性flags,然后调用内核的mmap64函数进行映射。详细实现如下。
JNIEXPORT jlong JNICALL Java_sun_nio_ch_FileChannelImpl_map0(JNIEnv *env, jobject this,
jint prot, jlong off, jlong len){
void *mapAddress = 0;
jobject fdo = (*env)->GetObjectField(env, this, chan_fd);
jint fd = fdval(env, fdo);
int protections = 0;
int flags = 0;
// 设置映射 标志位
if (prot == sun_nio_ch_FileChannelImpl_MAP_RO) {
// 只读映射
protections = PROT_READ;
flags = MAP_SHARED;
} else if (prot == sun_nio_ch_FileChannelImpl_MAP_RW) {
// 读写映射
protections = PROT_WRITE | PROT_READ;
flags = MAP_SHARED;
} else if (prot == sun_nio_ch_FileChannelImpl_MAP_PV) {
// 私有映射
protections = PROT_WRITE | PROT_READ;
flags = MAP_PRIVATE;
}
// 使用Linux mmap64函数进行映射
mapAddress = mmap64(
0, // 传入期望映射地址为0,表明让内核决定映射起始虚拟地址
len, // 映射的长度
protections, // 映射地址权限:读、读写
flags, // 是否为私有映射
fd, // 映射的文件描述符
off); // 映射的文件数据偏移量
...
return ((jlong) (unsigned long) mapAddress);
}Java支持哪些零拷贝?
1. NIO提供的内存映射 MappedByteBuffer(java.nio.MappedByteBuffer)
首先需要说明的是,在Java NIO中,Channel(通道)相当于操作系统中的内核缓冲区,可能是读缓冲区,也可能是网络缓冲区。而Buffer则相当于操作系统中的用户缓冲区。
- java NIO的零拷贝MappedByteBuffer实现是基于mmap+write方式
- FileChannel的map方法产生的MappedByteBuffer
FileChannel提供了map()方法,该方法可以在一个打开的文件和MappedByteBuffer之间建立一个虚拟内存映射,MappedByteBuffer继承于ByteBuffer;该缓冲器的内存是一个文件的内存映射区域。map方法底层是通过mmap实现的,因此将文件内存从磁盘读取到内核缓冲区后,用户空间和内核空间共享该缓冲区。
MappedByteBuffer mappedByteBuffer = new RandomAccessFile(file, "r")
.getChannel()
.map(FileChannel.MapMode.READ_ONLY, 0, len);
NIO中的FileChannel.map()方法是一个非常有用的方法,它采用了操作系统中的内存映射方式,底层实现是调用Linux mmap()。该方法将内核缓冲区的内存和用户缓冲区的内存做了一个地址映射,这种方式适合读取大文件。此外,该方法还能够对文件内容进行更改,因此也可以用于写入大文件。
需要注意的是,虽然该方法可以实现零拷贝,但如果要通过SocketChannel发送,则仍然需要CPU进行数据拷贝。此外,MappedByteBuffer只能通过调用FileChannel的map()方法来获取,没有其他方式。FileChannel.map()是一个抽象方法,在 FileChannelImpl.c 中有具体的实现,它的map0()方法是通过调用Linux内核的mmap API实现的。
在使用MappedByteBuffer时,需要注意一些细节。首先,mmap的文件映射会在进行full gc时才会被释放,因此需要谨慎使用。同时,在调用close()方法时需要手动清除内存映射文件,可以反射调用sun.misc.Cleaner方法。
2. NIO提供的sendfile(java.nio.channels.FileChannel)
- FileChannel.transferTo() 方法可以直接将当前通道内容传输到另一个通道,而无需涉及到Buffer的任何操作。在NIO中,Buffer可以是JVM堆内存,也可以是堆外内存。但无论哪种方式,它们都是操作系统内核空间的内存。
- transferTo() 方法的实现方式是通过系统调用 sendfile(),当然这是 Linux 中的系统调用。
//使用sendfile:读取磁盘文件,并网络发送
FileChannel sourceChannel = new RandomAccessFile(source, "rw").getChannel();
SocketChannel socketChannel = SocketChannel.open(sa);
sourceChannel.transferTo(0, sourceChannel.size(), socketChannel);
ZeroCopyFile实现文件复制
class ZeroCopyFile {
public void copyFile(File src, File dest) {
try (FileChannel srcChannel = new FileInputStream(src).getChannel();
FileChannel destChannel = new FileInputStream(dest).getChannel()) {
srcChannel.transferTo(0, srcChannel.size(), destChannel);
} catch (IOException e) {
e.printStackTrace();
}
}
}
注意:Java NIO提供的FileChannel.transferTo和transferFrom并不能保证一定能使用零拷贝。实际上,能否使用零拷贝取决于操作系统是否提供了sendfile等零拷贝系统调用。如果操作系统提供这样的系统调用,则这两个方法可以通过它们来充分利用零拷贝的优势;否则,它们本身无法实现零拷贝。
3. Kafka中的零拷贝
在 Kafka 中,生产者将数据存到 Broker,消费者从 Broker 读取数据。这两个过程都使用了操作系统层面的零拷贝技术。具体来说,生产者将数据通过 mmap 文件映射实现顺序的快速写入到 Broker 中。而消费者则通过 sendfile 技术,将磁盘文件读取到操作系统内核缓冲区中,然后直接将其转移到 socket buffer 中进行网络发送。
RocketMQ和Kafka的比较
- RocketMQ选择了mmap+write这种零拷贝方式,适用于业务级消息这种小块文件的数据持久化和传输。这种方式将磁盘文件直接映射到内存中,从而避免了不必要的数据拷贝。RocketMQ的实现方式使其在小型消息传递场景中表现出色。
- Kafka则采用了sendfile这种零拷贝方式,适用于系统日志消息这种高吞吐量的大块文件的数据持久化和传输。这种方式通过将磁盘文件直接传输到网络套接字缓冲区中,从而避免了不必要的数据拷贝。Kafka的实现方式使其在大型消息传递场景中表现出色。
值得注意的是,Kafka的索引文件使用的是mmap+write方式,数据文件使用的是sendfile方式。这种混合实现方式可以在同时具有高性能和高吞吐量的情况下,提供更好的存储效率。
| 消息队列 | 零拷贝方式 | 优点 | 缺点 |
|---|---|---|---|
| RocketMQ | mmap + write | 适用于小块文件传输;如果调用频繁,效率很高 | 不能很好的利用DMA方式,会比sendfile多消耗CPU,内存安全性控制复杂,需要避免JVM Crash问题 |
| Kafka | sendfile | 可以利用DMA方式,消耗CPU较少,大块文件传输效率高,无内存安全问题 | 小块文件效率低于mmap方式,只能是BIO传输,不能使用NIO方式 |
4. Netty中的零拷贝
Netty中的Zero-copy与我们之前提到的OS层面的Zero-copy略有不同,Netty的Zero-copy完全是在用户态(Java层面)实现的,它更多地偏向于优化数据操作。相比于操作系统层面的零拷贝技术,Netty的Zero-copy技术更多地使用在应用层面,通过减少数据拷贝来提高数据操作的效率。
在Netty中,Zero-copy技术体现在以下几个方面:
- Netty提供了CompositeByteBuf类,它可以将多个ByteBuf合并为一个逻辑上的ByteBuf,避免了各个ByteBuf之间的拷贝。这种方式类似于将分散的多个ByteBuf通过引用连接起来,从而形成一个逻辑上的大区域。在实际数据读取时,还是会去各自每一小块上读取,但是通过这种方式可以减少数据拷贝,从而提高数据操作的效率。
- 通过wrap操作,我们可以将byte[]数组、ByteBuf、ByteBuffer等包装成一个Netty ByteBuf对象,从而避免了拷贝操作。这个操作比较简单,通过Unpooled.wrappedBuffer方法将bytes包装成为一个UnpooledHeapByteBuf对象,在包装的过程中是不会有拷贝操作的。因此,最后生成的ByteBuf对象和bytes数组共用了同一个存储空间,对bytes的修改也会反映到ByteBuf对象中。
- ByteBuf支持slice操作,可以将ByteBuf分解为多个共享同一个存储区域的ByteBuf,避免了内存的拷贝。slice恰好是将一整块区域划分成逻辑上独立的小区域,在读取每个逻辑小区域时,实际会去按slice(int index, int length) index和length去读取原内存buffer的数据。这种方式可以在一定程度上减少数据拷贝,提高数据操作的效率。
- 通过FileRegion包装的FileChannel.tranferTo实现文件传输,可以直接将文件缓冲区的数据发送到目标Channel,避免了传统的循环write方式导致的内存拷贝问题。这种操作是操作系统级别的零拷贝,可以进一步减少数据拷贝,提高数据操作的效率。
a.Netty中的 CompositeByteBuf 可以实现零拷贝。
Netty提供的 CompositeByteBuf 类型是一种可以将多个 ByteBuf 合并为一个逻辑上的 ByteBuf 的工具。它类似于用一个链表将分散的多个 ByteBuf 通过引用连接起来,从而形成一个逻辑上的大区域。在实际数据读取时,仍然会去各自的每一小块上读取,但是通过这种方式可以减少数据拷贝,从而提高数据操作的效率。
使用 CompositeByteBuf 时,我们可以通过 addComponents() 方法将多个子缓冲区添加到 CompositeByteBuf 中。第一个参数 true 指定是否要将所有子缓冲区的内容合并到一个连续的内存块中(在这里我们将其设置为 true)。如果设置为 false,则子缓冲区的内容将保持原样。
最后,我们将 CompositeByteBuf 写入网络套接字中。这将自动将所有子缓冲区的内容写入套接字,而无需将它们复制到一个连续的内存块中。
使用 CompositeByteBuf 的好处是它可以减少不必要的数据拷贝,从而提高数据操作的效率。它是一种非常有用的工具,特别是在处理大规模数据时,可以显著提高性能。
// 创建两个ByteBuf
ByteBuf buf1 = Unpooled.buffer(10);
ByteBuf buf2 = Unpooled.buffer(20);
// 写入一些数据到buf1和buf2中
// 创建CompositeByteBuf并将buf1和buf2添加到其中
CompositeByteBuf compBuf = Unpooled.compositeBuffer();
compBuf.addComponents(true, buf1, buf2);
// 将CompositeByteBuf写入网络套接字中
Channel channel = ...; // 获取网络套接字Channel
channel.write(compBuf);
b. Netty中使用wrap机制实现的零拷贝
"wrap"机制是Netty中实现零拷贝的一种方式。它允许将一个原始的字节数组或ByteBuffer包装成一个ByteBuf,而无需将数据复制到新的缓冲区中。这种技术可以在网络传输时大大减少数据的复制,从而提高性能和减少内存使用。
下面是一个简单的使用wrap机制的示例,它将一个字节数组包装成一个ByteBuf并将其写入套接字中:
byte[] data = ...; // 获取待发送的数据
Channel channel = ...; // 获取网络套接字Channel
// 将字节数组包装成一个ByteBuf
ByteBuf buf = Unpooled.wrappedBuffer(data);
// 将ByteBuf写入网络套接字中
channel.write(buf);
在上面的代码中,我们使用Unpooled.wrappedBuffer()方法将字节数组包装成一个ByteBuf。这不会创建一个新的缓冲区,而是返回一个包装了原始字节数组的ByteBuf。然后我们将这个ByteBuf写入网络套接字中,而无需将数据复制到一个新的缓冲区中。
需要注意的是,使用wrap机制的一个限制是,在原始字节数组或ByteBuffer被修改时,它所包装的ByteBuf也会被修改。因此,在使用wrap机制时需要确保原始字节数组或ByteBuffer不会被修改,或者在修改它们时确保对应的ByteBuf也被正确地更新。
fastJson2 中使用warp机制实现的的零拷贝
/*
* Package private constructor which shares value array for speed.
* this constructor is always expected to be called with share==true.
* a separate constructor is needed because we already have a public
* String(char[]) constructor that makes a copy of the given char[].
*/
String(char[] value, boolean share) {
// assert share : "unshared not supported";
this.value = value;
}
对比平时使用的构造方法
/**
* Allocates a new {@code String} so that it represents the sequence of
* characters currently contained in the character array argument. The
* contents of the character array are copied; subsequent modification of
* the character array does not affect the newly created string.
*
* @param value
* The initial value of the string
*/
public String(char value[]) {
this.value = Arrays.copyOf(value, value.length);
}
c. Netty中使用slice机制实现零拷贝
在Netty中,通过slice操作也可以实现零拷贝。
slice操作可以从一个大的ByteBuf中创建一个新的ByteBuf,该新的ByteBuf仍然引用原始的ByteBuf的内存,但是它只表示原始ByteBuf的一部分数据。这意味着在使用slice操作时不需要将数据复制到一个新的缓冲区中。
以下是一个具体的示例代码,它使用slice操作将一个大的ByteBuf切分成多个小的ByteBuf,而不涉及数据的复制:
ByteBuf bigBuf = ...; // 获取大的ByteBuf
int chunkSize = 1024; // 每个小的ByteBuf的大小
// 将大的ByteBuf切分成多个小的ByteBuf
List<ByteBuf> chunks = new ArrayList<>();
for (int i = 0; i < bigBuf.capacity(); i += chunkSize) {
int length = Math.min(chunkSize, bigBuf.capacity() - i);
ByteBuf chunk = bigBuf.slice(i, length);
chunks.add(chunk);
}
// 将小的ByteBuf写入网络套接字中
Channel channel = ...; // 获取网络套接字Channel
for (ByteBuf chunk : chunks) {
channel.write(chunk);
}
在上面的代码中,我们将一个大的ByteBuf切分成多个小的ByteBuf,每个小的ByteBuf的大小为chunkSize。我们使用slice操作从大的ByteBuf中创建每个小的ByteBuf。这不会复制数据,而是返回一个新的ByteBuf,它与原始ByteBuf共享相同的内存块。
最后,我们将所有小的ByteBuf写入网络套接字中,这样就可以在不涉及数据复制的情况下进行零拷贝的网络传输。需要注意的是,使用slice操作时需要确保原始ByteBuf的生命周期不会比切分出的小的ByteBuf更短,否则可能会导致内存泄漏等问题。
d. Netty中使用FileRegion实现零拷贝
在Netty中,通过使用FileRegion可以实现零拷贝的文件传输。
FileRegion是Netty中一个专门用于进行文件传输的接口。它可以在传输文件时使用操作系统提供的零拷贝机制,从而避免在用户空间和内核空间之间进行数据的复制。
以下是一个具体的示例代码,它使用FileRegion将一个文件写入到网络套接字中,而不涉及数据的复制:
File file = ...; // 获取待发送的文件
Channel channel = ...; // 获取网络套接字Channel
// 创建一个DefaultFileRegion,用于将文件传输到网络套接字中
FileRegion region = new DefaultFileRegion(file.getChannel(), 0, file.length());
// 将文件传输到网络套接字中
channel.write(region);
在上面的代码中,我们使用DefaultFileRegion类将一个文件传输到网络套接字中。DefaultFileRegion类的构造函数需要一个FileChannel对象和文件的起始位置和长度,它将使用操作系统提供的零拷贝机制将文件传输到网络套接字中。最后,我们将FileRegion对象写入网络套接字中。
需要注意的是,使用FileRegion时需要确保文件的生命周期不会比FileRegion对象更短,否则可能会导致内存泄漏等问题。此外,使用FileRegion的限制是,它只能用于文件传输,而不能用于传输内存中的数据。
MappedByteBuffer内存映射(mmap)实现零拷贝
Bytebuffer分为两种:间接地和直接的,所谓直接就是指MappedByteBuffer,直接使用内存映射(java的话就意味着在JVM之外分配虚拟地址空间);而间接的ByteBuffer是在JVM的堆上面的。
间接缓冲区就是我们通常说的堆缓冲区。
直接缓冲区 java内部是使用 DirectByteBuffer 来实现的。
堆缓冲区java内部是使用 HeapByteBuffer 来实现的。
class DirectByteBuffer extends MappedByteBuffer implements DirectBuffer {}
class HeapByteBuffer extends ByteBuffer {}映射的字节缓冲区(MappedByteBuffer ) 不提供关闭或销毁方法。也就是说,创建完直接缓冲区,就一直有效,直到缓冲区本身被垃圾收集。
映射字节缓冲区的内容可以在任何时间改变,例如,如果映射的文件的对应区域的内容由该程序或其他程序改变。无论这种变化是否发生,当它们发生时,都是依赖于操作系统的,因此不明确。
映射的字节缓冲区的全部或部分可能在任何时间变得不可访问,例如映射的文件被截断。试图访问映射字节缓冲区的不可访问区域不会改变缓冲区的内容,并且会导致在访问时或稍后某个时间抛出一个未指定的异常。因此,强烈建议采取适当的预防措施,以避免由该程序或由同时运行的程序操纵映射文件,除了读取或写入文件的内容。
MappedByteBuffer底层原理
MappedByteBuffer 是 Java NIO 中的一个用于内存映射文件的类。
NIO中的FileChannel.map()方法是一个非常有用的方法,它采用了操作系统中的内存映射方式,底层实现是调用Linux mmap()。该方法将内核缓冲区的内存和用户缓冲区的内存做了一个地址映射,这种方式适合读取大文件。此外,该方法还能够对文件内容进行更改,因此也可以用于写入大文件。
Java NIO中也提供了MappedByteBuffer来处理文件映射,使用MappedByteBuffer向网络中发送数据的过程如下:
-
使用MappedByteBuffer建立文件映射,用户空间可以通过虚拟地址直接访问映射的文件数据;
-
将映射的文件数据拷贝到socket网络缓冲区(CPU复制);
-
DMA将socket缓冲区的数据拷贝到网卡(DMA复制);
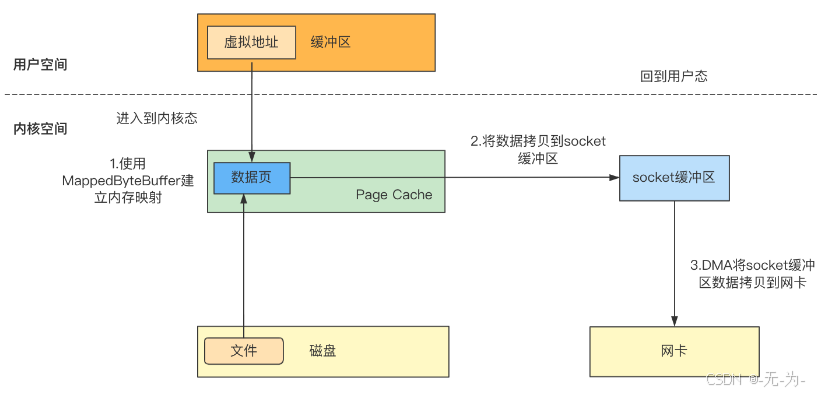
内存映射文件允许我们把一个文件或者其它对象的部分直接映射到内存中,这样我们就可以像操作内存一样直接操作文件了。这种方式提供了一种便捷的方法来处理大型文件。
MappedByteBuffer 的底层实现涉及到操作系统的内存管理机制,它通过 Java 的 Native Interface (JNI) 与操作系统层面的内存管理功能进行交互。
ByteBuffer 是 Java NIO 中的一个用于字节缓冲区操作的抽象类。它有多个实现类,如 HeapByteBuffer、DirectByteBuffer 等,分别代表了不同的缓冲区类型:堆缓冲区和直接缓冲区。
堆缓冲区:数据存储在 JVM 的堆空间中,适用于小数据量操作,但可能会导致 JVM 的垃圾收集影响性能。
直接缓冲区:数据存储在 JVM 的堆外内存中,可以直接通过系统调用进行 I/O 操作,因此适用于大数据量操作,且对 GC 影响较小。
MappedByteBuffer 类结构
public abstract class MappedByteBuffer extends ByteBuffer {
public final MappedByteBuffer load( )
public final boolean isLoaded( )
public final MappedByteBuffer force( )
}可以看到MappedByteBuffer 继承了 ByteBuffer 。其主要方法如下:
MappedByteBuffer没有构造函数(不可new MappedByteBuffer ( )来构造一个MappedByteBuffer( ),我们需要借助FileChannel提供的map方法把文件映射为MappedByteBuffer-->MappedByteBuffer map(int mode, long position, long size);其实就是Map把文件的内容被映像到计算机虚拟内存的一块区域,这样就可以直接操作内存当中的数据而无需操作的时候每次都通过IO去物理硬盘读取文件,所以效率高。
参数 int mode的三种写法:
1、MapMode. READ_ ONLY(只读)
2、MapMode. READ_WRITE(读/写)
3、MapMode PRIVATE
long position和 long size:把文件的从position开始的size大小的区域映射为内存映像文件。
MappedByteBuffer比 ByteBuffer多的三个方法:
1、fore( )缓冲区是READ_WRITE模式下,此方法对缓冲区内容的修改强行写入文件
2、load( )将缓冲区的内容载入内存,并返回该缓冲区的引用
3、isloaded( )如果缓冲区的内容在物理内存中,则返回真,否则返回假。
如果只需要读时可以使用FileInputStream,写映射文件时一定要使用随机( RandomAccessFile)访问文件。
load() 方法
load( )方法会整个文件加载到内存中。
此方法尽最大努力确保当它返回时,该缓冲区的内容驻留在物理内存中。调用此方法可能会导致一些页面错误和I/O操作发生。
操作系统会采用虚拟内存映射,把缓冲区和文件建立虚拟内存映射。此映射使得操作系统的底层虚拟内存子系统可以根据需要将文件中相应区块的数据读进内存。已经在内存中或通过验证的页会占用实际内存空间,并且在它们被读进 RAM 时会挤出最近较少使用的其他内存页。(swap in,swap out)
在一个映射缓冲区上调用 load( )方法会是一个代价高的操作,因为它会导致大量的页调入(page-in),具体数量取决于文件中被映射区域的实际大小。
然而,load( )方法返回并不能保证文件就会完全加载到内存,这是由于请求页面调入是动态的。
具体结果会因某些因素而有所差异,这些因素包括:操作系统、文件系统,可用 Java 虚拟机内存,最大 Java 虚拟机内存,垃圾收集器实现过程等等。
请小心使用 load( )方法,它可能会导致您不希望出现的结果。
该方法的主要作用是为提前加载文件埋单,以便后续的访问速度可以尽可能的快。
对于那些要求近乎实时访问的程序,解决方案就是预加载。但是请记住,不能保证全部页都加载到内存,不管怎样,之后可能还会有页调入发生(操作系统自己维护,依赖操作系统的实现)。内存页什么时候swap in 和 swap out 受多个因素影响,这些因素中的许多都是不受 Java 虚拟机控制的。 JDK 1.4 的 NIO 并没有提供一个可以把页面固定到物理内存上的API,尽管一些操作系统是支持这样做的。对于大多数程序,特别是交互性的或其他事件驱动(event-driven)的程序而言,为提前加载文件消耗资源是不划算的。在实际访问时分摊页调入开销才是更好的选择。让操作系统根据需要来调入页意味着不访问的页永远不需要被加载。同预加载整个被映射的文件相比,这很容易减少 I/O 活动总次数。操作系统已经有一个复杂的内存管理系统了,就让它来替您完成此工作吧!
isLoaded() 方法
我们可以通过调用 isLoaded( )方法来判断一个被映射的文件是否完全加载内存了。 如果该方法返回ture,意味着该缓冲区中的所有数据很可能完全加载到物理内存中了,因此可以在不产生任何虚拟内存页错误或I/O操作的情况下访问。 不过,该方法返回false,并不一定意味着缓冲区的内容没有加载到物理内存中。
返回值是一个提示,而不是一个保证,因为底层操作系统在调用该方法返回的时候可能已经分出了一些缓冲区的数据。
force() 方法
该方法会强制将此缓冲区上的任何更改写入映射到永久磁盘存储器上。
如果映射到该缓冲区的文件驻留在本地存储设备上,那么当该方法返回时,它保证对创建的缓冲区进行的所有更改,或者自上次调用该方法后,将被写入该设备。 如果文件不驻留在本地设备上,则不提供这样的保证。
当用 MappedByteBuffer 对象来更新一个文件,您应该总是使用 MappedByteBuffer.force( )而非 FileChannel.force( ),因为通道对象可能 不清楚通过映射缓冲区做出的文件的全部更改。MappedByteBuffer 没有不更新文件元数据的选项——元数据总是会同时被更新的。
如果映射是以 MapMode.READ_ONLY 或 MAP_MODE.PRIVATE 模式建立的,那么调用 force( ) 方法将不起任何作用,因为永远不会有更改需要应用到磁盘上(但是这样做也是没有害处的)。
FileChannel发送文件(sendfile)实现零拷贝
在Linux 2.1内核引入了sendfile函数用于将文件通过socket传送。
- 发起sendfile系统调用,进入到内核空间;
- DMA从磁盘读取文件到内核缓冲区(DMA复制);
- 将内核缓冲区数据拷贝到socket缓冲区(CPU复制);
- 将socket缓冲区数据拷贝到网卡(DMA复制),之后切换回用户空间;
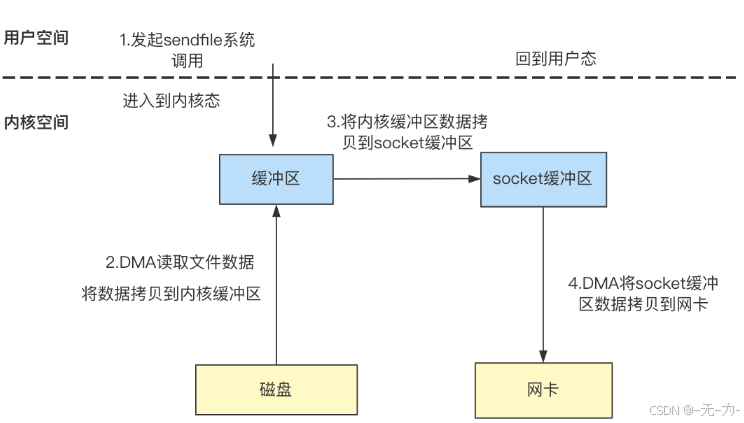
sendfile的主要特点是在内核空间中通过DMA将数据从磁盘文件拷贝到内核缓存区,然后可以直接将内核缓存区中的数据在CPU控制下将数据复制到socket缓存区,最终在DMA的控制下将socketbufer中拷贝到协议引擎,然后经网卡传输到目标端。
sendfile的优势(特点):
- 一次sendfile调用会只设计两次上下文切换,比read+write减少两次上下文切换。
- 一次sendfile会存在3次copy,其中一次CPU拷贝,两次DMA拷贝。
FileChannel底层原理
FileChannel“零拷贝”的方法transferTo,用来在在不同channel之间传递数据。
FileChannel的transferTo、transferFrom
如果操作系统底层支持的话,transferTo、transferFrom也会使用相关的零拷贝技术来实现数据的传输。
零拷贝是指在操作系统层面直接将数据从一个文件描述符传输到另一个文件描述符,避免了用户空间和内核空间之间的数据拷贝,从而提高了文件传输的效率。Java NIO中的FileChannel的transferTo方法就是基于操作系统的sendfile系统调用实现的零拷贝。
在Linux系统中,sendfile系统调用是在2.1版本引入的,它通过DMA引擎将数据从一个文件描述符直接传输到另一个文件描述符,不需要经过用户空间的缓冲区。这样,数据就可以直接在内核空间内传输,避免了用户态和内核态之间的数据拷贝,大大提高了文件传输的效率。
以下是使用Java NIO的FileChannel的transferTo方法进行零拷贝操作的示例代码:
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.nio.channels.FileChannel;
public class ZeroCopyExample {
public static void main(String[] args) {
try (FileInputStream fis = new FileInputStream("source.txt");
FileOutputStream fos = new FileOutputStream("dest.txt");
FileChannel sourceChannel = fis.getChannel();
FileChannel destChannel = fos.getChannel()) {
long position = 0;
long count = sourceChannel.size();
// 将数据从sourceChannel传输到destChannel,使用零拷贝技术
destChannel.transferFrom(sourceChannel, position, count);
} catch (Exception e) {
e.printStackTrace();
}
}
}在这个例子中,transferFrom方法实现了将数据从sourceChannel通过零拷贝传输到destChannel的操作。这样,源文件的数据就不需要在用户空间和内核空间之间拷贝,而是直接在内核空间内传输,从而达到了零拷贝的目的。
FileChannel类结构
FileChannel零拷贝支撑之transferTo方法
transferTo 方法定义
我们知道FileChannel通道对象的transferTo方法可以用于将文件直接传输给target变量所指的可写通道中,通常我们可以使用此方法完成对sendfile函数的调用,当然这个调用是通过JNI 来调用的,我们可以将该方法与SocketChannel一起使用来避免数据先从磁盘传输到用户空间,然后再写回内核,最后放入socket的缓冲区增加性能。我们先来看该方法的定义,参数position用于表示当前FileChannel操作文件的位置,count为需要传输到target中的数量,target为目标通道对象。详细实现如下。
public abstract class FileChannel
extends AbstractInterruptibleChannel
implements SeekableByteChannel, GatheringByteChannel, ScatteringByteChannel
{
public abstract long transferTo(long position, long count,
WritableByteChannel target)
throws IOException;
}transferTo 方法实现原理
接下来我们来看FileChannelImpl类对于FileChannel类的transferTo方法实现,这里我们省略了对于参数和通道的校验,我们直接关注核心方法,
我们看到有三种传输方式,
第一种需要操作系统接口支持,通过操作系统直接传送数据,
第二种通过mmap的方式共享内存传送数据,
第三种最慢,为通用的传统方式进行传输,这三种方式逐个进行尝试。
详细实现如下。
public class FileChannelImpl extends FileChannel{
public long transferTo(long position, long count,
WritableByteChannel target)
throws IOException
{
... // 参数校验
long n;
// 尝试直接传输,需要内核支持
if ((n = transferToDirectly(position, icount, target)) >= 0)
return n;
// 尝试通过mmap共享内存的方式进行可信通道的传输
if ((n = transferToTrustedChannel(position, icount, target)) >= 0)
return n;
// 否则通过传统方式进行传输,这种方式最慢
return transferToArbitraryChannel(position, icount, target);
}
}transferToDirectly 方法实现原理
接下来我们来看transferToDirectly 直接通过操作系统传送的原理,这种方式也是最快的零拷贝支持,注意这里的零拷贝指的是需要传送的文件内容不需要从操作系统拷贝到用户空间,然后再写入到socket缓冲区中。其中我们省略了校验操作,同样我们关注核心操作,首先我们获取到了当前文件通道和目标通道对象的fd,然后根据是否对position上锁调用transferToDirectlyInternal方法完成数据传送。详细实现如下。
private long transferToDirectly(long position, int icount,WritableByteChannel target) throws IOException {
...
// 获取当前文件通道和目标通道对象的fd
int thisFDVal = IOUtil.fdVal(fd);
int targetFDVal = IOUtil.fdVal(targetFD);
if (thisFDVal == targetFDVal) // 不允许自己传送给自己
return IOStatus.UNSUPPORTED;
// 如果需要使用position锁,那么获取该锁调用transferToDirectlyInternal方法完成数据传送,通常transferToDirectlyNeedsPositionLock方法始终返回true
if (nd.transferToDirectlyNeedsPositionLock()) {
synchronized (positionLock) {
long pos = position();
try {
return transferToDirectlyInternal(position, icount,
target, targetFD);
} finally {
position(pos);
}
}
} else {
return transferToDirectlyInternal(position, icount, target, targetFD);
}
}我们接着看transferToDirectlyInternal方法的实现,我们看到这里我们看到最终通过JNI调用本地方法transferTo0完成传送。详细实现如下。
private long transferToDirectlyInternal(long position, int icount, WritableByteChannel target,FileDescriptor targetFD) throws IOException{
...
do {
// JNI调用本地方法transferTo0完成传送
n = transferTo0(fd, position, icount, targetFD);
} while ((n == IOStatus.INTERRUPTED) && isOpen());
...
}
// 如果操作系统不支持,那么将会返回-2
private native long transferTo0(FileDescriptor src, long position,
long count, FileDescriptor dst);transferToTrustedChannel方法实现原理
transferToTrustedChannel方法用于在可信通道中,使用mmap操作通过共享内存的方式进行数据传送。我们看到设置了最大mmap的大小为MAPPED_TRANSFER_SIZE 8M,如果需要传送的文件数据大于这个值,那么我们需要分阶段映射,获取到MappedByteBuffer文件映射缓冲区后,我们调用目标通道的write方法完成数据写入。注意我们这里使用的是映射缓冲区,所以此时并不存在两次拷贝,此时只存在数据放入页缓存中,通过mmap映射到进程的虚拟地址空间,而write函数将会直接使用映射的数据,所以不存在拷贝到JVM的堆内存空间,随后再拷贝到内核。详细实现如下。
private long transferToTrustedChannel(long position, long count,WritableByteChannel target)throws IOException{
...
long remaining = count;
// 我们这里设置了最大mmap的大小为MAPPED_TRANSFER_SIZE 8M,如果需要传送的文件数据大于这个值,那么我们需要分阶段映射
while (remaining > 0L) {
long size = Math.min(remaining, MAPPED_TRANSFER_SIZE);
try {
// 获取当前文件映射缓冲区
MappedByteBuffer dbb = map(MapMode.READ_ONLY, position, size);
try {
// 调用目标通道进行数据写入
int n = target.write(dbb);
...
} finally {
// 写入完成,结束内存映射
unmap(dbb);
}
} catch (ClosedByInterruptException e) {
...
} catch (IOException ioe) {
...
}
}
return count - remaining;
}我们接着看map方法原理,我们这里直接调用mapInternal方法进行映射。详细实现如下。
public MappedByteBuffer map(MapMode mode, long position, long size) throws IOException {
...
// 映射并且返回解除映射对象
Unmapper unmapper = mapInternal(mode, position, size, prot, isSync);
// 根据模式构建只读MappedByteBufferR或者读写MappedByteBuffer
if (unmapper == null) {
FileDescriptor dummy = new FileDescriptor();
if ((!writable) || (prot == MAP_RO))
return Util.newMappedByteBufferR(0, 0, dummy, null, isSync);
else
return Util.newMappedByteBuffer(0, 0, dummy, null, isSync);
} else if ((!writable) || (prot == MAP_RO)) {
return Util.newMappedByteBufferR((int)unmapper.cap,
unmapper.address + unmapper.pagePosition,
unmapper.fd,
unmapper, isSync);
} else {
return Util.newMappedByteBuffer((int)unmapper.cap,
unmapper.address + unmapper.pagePosition,
unmapper.fd,
unmapper, isSync);
}
}我们继续看mapInternal方法,该方法通过JNI调用本地方法完成映射,同时创建了解除映射对象,这里我们使用DefaultUnmapper,详细实现如下。
private Unmapper mapInternal(MapMode mode, long position, long size, int prot, boolean isSync)
throws IOException
{
...
long addr = -1;
int ti = -1;
try {
...
synchronized (positionLock) {
...
try {
// JNI调用本地方法完成映射
addr = map0(prot, mapPosition, mapSize, isSync);
} catch (OutOfMemoryError x) {
...
}
}
...
// 构建解除映射对象,这里我们使用DefaultUnmapper
Unmapper um = (isSync
? new SyncUnmapper(addr, mapSize, size, mfd, pagePosition)
: new DefaultUnmapper(addr, mapSize, size, mfd, pagePosition));
return um;
} finally {
...
}
}
private native long map0(int prot, long position, long length, boolean isSync)
throws IOException;transferToArbitraryChannel方法实现原理
transferToArbitraryChannel方法用于完成最慢的传统传输方式,我们首先创建默认为TRANSFER_SIZE 8KB的堆内缓冲区,随后调用read函数将文件数据读入到该缓冲区中,接着调用目标target.write方法完成对数据的传送。我们看到这里发生了多次拷贝操作,磁盘文件到页缓存,页缓存到JVM内存,JVM内存到堆内内存多次拷贝,所以性能最差。详细实现如下
private long transferToArbitraryChannel(long position, int icount, WritableByteChannel target)throws IOException{
int c = Math.min(icount, TRANSFER_SIZE);
// 创建堆内缓冲区
ByteBuffer bb = ByteBuffer.allocate(c);
long tw = 0; // 总写入数据
long pos = position;
try {
// 循环写入
while (tw < icount) {
// 将文件数据读入到堆内缓冲区中
bb.limit(Math.min((int)(icount - tw), TRANSFER_SIZE));
int nr = read(bb, pos);
if (nr <= 0)
break;
// 反转模式,从读模式切换到写模式
bb.flip();
// 将文件数据写入到堆内缓冲区中
int nw = target.write(bb);
tw += nw;
if (nw != nr)
break;
pos += nw;
// 清空缓冲区,方便下一次读取
bb.clear();
}
return tw;
} catch (IOException x) {
...
}
}实战:MappedByteBuffer+FileChannel
1. JAVA多线程并发写FileChannel不是线程安全的。FileChannel不是线程安全的,多线程同时写同一个文件Channel可能会导致数据混乱。
2. 要实现零拷贝,可以使用MappedByteBuffer。
步骤如下:
- 获取FileChannel,通过FileChannel.map()方法映射文件,获取MappedByteBuffer。
- MappedByteBuffer底层使用OS的mmap功能,可以直接在内核空间和用户空间内存之间进行数据拷贝,避免了应用空间和内核空间之间的数据拷贝。
- 多个线程可以共享同一个MappedByteBuffer,通过position和limit来控制不同线程的读写范围,实现零拷贝。
package com.zxx.study.base.io.nio.zerocopy;
import com.zxx.study.base.util.FileUtils;
import com.zxx.study.base.util.ZhouxxTool;
import java.io.*;
import java.nio.ByteBuffer;
import java.nio.MappedByteBuffer;
import java.nio.channels.FileChannel;
/**
* @author zhouxx
* @create 2024-10-23 12:19
*/
public class MappedByteBufferDemo {
static int _1MBLength = 1048576; // 1MB:一个英文字符占1B,1MB=1024*1024Byte=1,048,576Byte
public static void main(String[] args) throws Exception {
// 准备文件
String filepath1="D:/tmp/test1G-1.txt";
writeFile(filepath1,1024);//1024MB
// String filepath2="D:/tmp/test1G-2.txt";
// writeFile(filepath2,1024);//1024MB
//
// String filepath3="D:/tmp/test1G-3.txt";
// writeFile(filepath3,1024);//1024MB
//
// String filepath4="D:/tmp/test1G-4.txt";
// writeFile(filepath4,1024);//1024MB
//
// String filepath5="D:/tmp/test1G-5.txt";
// writeFile(filepath5,1024);//1024MB
/**
* testIO耗时=11931ms
* testMappedByteBuffer耗时=3804ms
* testFileChannel耗时=2154ms
* testFileChannelByteBuffer耗时=1924ms ==cnt1025
* testFileChannelByteBuffer2耗时=22775ms ==cnt2
* */
long start = System.currentTimeMillis();
// 调用普通io
testIO(filepath1,"D:/tmp/dest1G-1.txt");
long end = System.currentTimeMillis();
ZhouxxTool.printTimeAndThread("testIO耗时=" + (end - start) + "ms");
start = System.currentTimeMillis();
// 调用MappedByteBuffer
testMappedByteBuffer(filepath1,"D:/tmp/dest1G-2.txt");
end = System.currentTimeMillis();
ZhouxxTool.printTimeAndThread("testMappedByteBuffer耗时=" + (end - start) + "ms");
start = System.currentTimeMillis();
// 调用 testFileChannel()
testFileChannel(filepath1,"D:/tmp/dest1G-3.txt");
end = System.currentTimeMillis();
ZhouxxTool.printTimeAndThread("testFileChannel耗时=" + (end - start) + "ms");
start = System.currentTimeMillis();
// 调用 testFileChannelByteBuffer()
testFileChannelByteBuffer(filepath1,"D:/tmp/dest1G-4.txt");
end = System.currentTimeMillis();
ZhouxxTool.printTimeAndThread("testFileChannelByteBuffer耗时=" + (end - start) + "ms");
start = System.currentTimeMillis();
// 调用 testFileChannelByteBuffer()
testFileChannelByteBuffer2(filepath1,"D:/tmp/dest1G-5.txt");
end = System.currentTimeMillis();
ZhouxxTool.printTimeAndThread("testFileChannelByteBuffer2耗时=" + (end - start) + "ms");
}
public static boolean writeFile(String filepath,int mb) throws Exception {
FileUtils.deleteFile(filepath);
FileUtils.createFile(filepath);
// 为了以可读可写的方式打开文件,我们使用RandomAccessFile来创建文件
FileChannel fc = new RandomAccessFile(filepath, "rw").getChannel();
long length=_1MBLength*mb;
ZhouxxTool.printTimeAndThread("size=" +length+ " Byte");
//文件通道的可读可写要建立在文件流本身可读写的基础之上
MappedByteBuffer mbb = fc.map(FileChannel.MapMode.READ_WRITE, 0, length);
//写1M的内容*(a)
for (int i = 0; i < length; i++) {
mbb.put((byte) 'a');
}
mbb.clear();
fc.close();
return true;
}
/**
* 测试1G文件,IO的效率
*
* @throws IOException
*/
private static void testIO(String filepath,String destfile) throws IOException {
File sourceFile = new File(filepath);
byte[] bytes = new byte[1024]; // 和下面方式创建byte[]效率基本一样
// byte[] bytes = new byte[(int) sourceFile.length()];
FileInputStream fis = new FileInputStream(sourceFile);
FileOutputStream fos = new FileOutputStream(destfile);
int len = -1;
while ((len = fis.read(bytes)) != -1) {
fos.write(bytes, 0, len); // 写入数据
}
fis.close();
fos.close();
}
/**
* 测试1G文件,MappedByteBuffer的效率
*
* @throws IOException
*/
private static void testMappedByteBuffer(String filepath,String destfile) throws IOException {
File sourceFile = new File(filepath);
// byte[] bytes = new byte[1024]; // 和下面方式创建byte[]效率基本一样
byte[] bytes = new byte[(int) sourceFile.length()];
RandomAccessFile ra_read = new RandomAccessFile(sourceFile, "r");
FileChannel fc = new RandomAccessFile(destfile, "rw").getChannel();
MappedByteBuffer map = fc.map(FileChannel.MapMode.READ_WRITE, 0, sourceFile.length());
int len = -1;
while ((len = ra_read.read(bytes)) != -1) {
map.put(bytes, 0, len); // 写入数据
}
map.clear();
ra_read.close();
fc.close();
}
/**
* 测试1G文件,FileChannel的效率
*
* @throws IOException
*/
private static void testFileChannel(String filepath,String destfile) throws IOException {
FileInputStream fis = new FileInputStream(filepath);
FileChannel fisChannel = fis.getChannel();
FileOutputStream fos = new FileOutputStream(destfile);
FileChannel fosChannel = fos.getChannel();
fisChannel.transferTo(0, fisChannel.size(), fosChannel);
fosChannel.close();
fisChannel.close();
fis.close();
fos.close();
}
/**
* 测试1G文件,FileChannel的效率
*
* @throws IOException
*/
private static void testFileChannelByteBuffer2(String filepath,String destfile) throws IOException {
File sourceFile = new File(filepath);
try (FileChannel from = new FileInputStream(sourceFile).getChannel();
FileChannel to = new FileOutputStream(destfile).getChannel();
) {
int cnt=0;
//testFileChannelByteBuffer2==cnt2
//testFileChannelByteBuffer2耗时=22775ms
// ByteBuffer bb = ByteBuffer.allocateDirect(1024 * 1024);
ByteBuffer bb = ByteBuffer.allocateDirect((int)sourceFile.length());
while (true) {
cnt++;
int len = from.read(bb);
if (len == -1) {
break;
}
bb.flip(); // 调用flip之后,读写指针指到缓存头部,切换成读模式
to.write(bb);
bb.clear(); // 切换成写模式
}
bb.clear();
to.close();
from.close();
ZhouxxTool.printTimeAndThread("testFileChannelByteBuffer2==cnt"+cnt);
} catch (IOException e) {
e.printStackTrace();
}
}
/**
* 测试1G文件,FileChannel的效率
*
* @throws IOException
*/
private static void testFileChannelByteBuffer(String filepath,String destfile) throws IOException {
try (FileChannel from = new FileInputStream(filepath).getChannel();
FileChannel to = new FileOutputStream(destfile).getChannel();
) {
int cnt=0;
// testFileChannelByteBuffer==cnt1025
//testFileChannelByteBuffer耗时=1924ms
ByteBuffer bb = ByteBuffer.allocateDirect(1024 * 1024);
while (true) {
cnt++;
int len = from.read(bb);
if (len == -1) {
break;
}
bb.flip(); // 调用flip之后,读写指针指到缓存头部,切换成读模式
to.write(bb);
bb.clear(); // 切换成写模式
}
bb.clear();
to.close();
from.close();
ZhouxxTool.printTimeAndThread("testFileChannelByteBuffer==cnt"+cnt);
} catch (IOException e) {
e.printStackTrace();
}
}
}
执行结果如下:
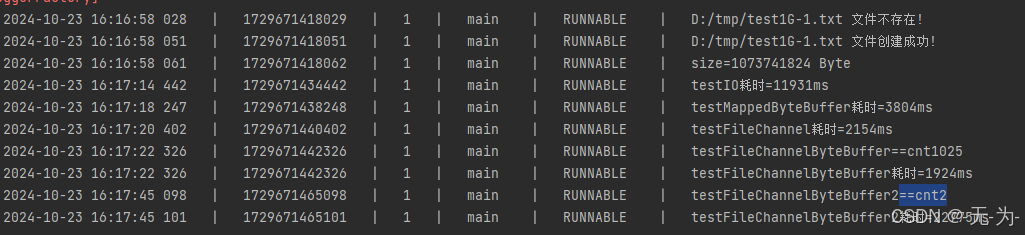
调用 testIO( )打印内容:耗时=11931ms;
调用 testMappedByteBuffer( )打印内容:耗时=3804ms
调用testFileChannel耗时=2154ms
调用testFileChannelByteBuffer耗时=1924ms(cnt1025;拆了1024次)
调用testFileChannelByteBuffer2耗时=22775ms(cnt2;拆了1次)
总结:利用 FileChannel获取MappedByteBuffer操作大文件效率明显高于普通IO流。
文件过大时会报错( Exception in threadmainjava. lang Negative Array Size Exception),遇到报错就要做文件分片、分块了。
注意:要先分块才能使用MappedByteBuffer写操作。MappedByteBuffer其实就是文件映射,不能把一个大文件用MappedByteBuffer进行分块。
注意:创建了一个1024Mb的文件,如果一次性读到内存可能导致内存溢出,这里访问好像只是一瞬间的事,这是因为真正调入内存的只是其中的一小部分,其余部分则被放在交换文件上。这样你就很方便地修改超大型的文件了(最大可以到2GB,基本上超过1.5G就可以考恵使用分块操作了)。Java是调用操作系统的“文件映射机制(file- mapping facility)”来提升性能的。如果是操作小文件,就用基本的O就可以了( FileInputStream,FileOutputStream)。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐



 35
35 0
0- 0



 已为社区贡献22条内容
已为社区贡献22条内容

所有评论(0)