
模型训练-Tricks-提升鲁棒性(1):对抗训练【FGM、PGD、FGSM、FreeLB、AWP】
对抗训练中关键的是需要找到对抗样本(尽量让模型预测出错的样本),通常是对原始的输入添加一定的扰动来构造,然后用来给模型训练.【炼丹技巧】功守道:NLP中的对抗训练 + PyTorch实现 - 知乎一文搞懂NLP中的对抗训练FGSM/FGM/PGD/FreeAT/YOPO/FreeLB/SMART - 知乎FGM对抗训练_Mr.奇的博客-CSDN博客对抗训练fgm、fgsm和pgd原理和源码分析_谈
当前,在各大NLP竞赛中,对抗训练已然成为上分神器,尤其是fgm和pgd使用较多,下面来说说吧。对抗训练是一种引入噪声的训练方式,可以对参数进行正则化,提升模型鲁棒性和泛化能力。
对抗样本:对输入增加微小扰动得到的样本。旨在增加模型损失。
对抗训练:训练模型去区分样例是真实样例还是对抗样本的过程。对抗训练不仅可以提升模型对对抗样本的防御能力,还能提升对原始样本的泛化能力。
一、FGM(Fast Gradient Method)
FSGM是每个方向上都走相同的一步,2017年Goodfellow后续提出的FGM则是根据具体的梯度进行scale,得到更好的对抗样本:
对于每个x:
1.计算x的前向loss、反向传播得到梯度
2.根据embedding矩阵的梯度计算出r,并加到当前embedding上,相当于x+r
3.计算x+r的前向loss,反向传播得到对抗的梯度,累加到(1)的梯度上
4.将embedding恢复为(1)时的值
5.根据(3)的梯度对参数进行更新Pytorch实现
class FGM():
""" 快速梯度对抗训练
"""
def __init__(self, model):
self.model = model
self.backup = {}
def attack(self, epsilon=1., emb_name='word_embeddings'):
# emb_name这个参数要换成你模型中embedding的参数名
for name, param in self.model.named_parameters():
if param.requires_grad and emb_name in name:
param_data = param.data
param_grad = param.grad
self.backup[name] = param_data.clone() # 保存原始参数,用于后续恢复 torch.Size([vocab_size, hidden_size])<---->torch.Size([21128, 768])
norm = torch.norm(param_grad)
if norm != 0 and not torch.isnan(norm):
r_at = epsilon * param_grad / norm
param.data.add_(r_at)
def restore(self, emb_name='word_embeddings'):
# emb_name这个参数要换成你模型中embedding的参数名
for name, param in self.model.named_parameters():
if param.requires_grad and emb_name in name:
assert name in self.backup
param.data = self.backup[name]
self.backup = {}使用Demo
import torch
import torch.nn as nn
import argparse
from transformers import WEIGHTS_NAME, AdamW, get_linear_schedule_with_warmup
from bert4keras.tokenizers import Tokenizer
from sklearn.model_selection import KFold
from model import GRTE
from util import *
from tqdm import tqdm
import os
import json
from transformers import BertModel, BertConfig, BertPreTrainedModel
class FGM():
"""
快速梯度对抗训练
"""
def __init__(self, model):
self.model = model
self.backup = {}
def attack(self, epsilon=1.0, emb_name='word_embeddings'):
# emb_name这个参数要换成你模型中embedding的参数名
# name:
# 'bert.embeddings.word_embeddings.weight'
# 'bert.embeddings.position_embeddings.weight'
# 'bert.embeddings.token_type_embeddings.weight'
# 'bert.embeddings.LayerNorm.weight'
# 'bert.embeddings.LayerNorm.bias'
# 'bert.encoder.layer.0.attention.self.query.weight'
# for param_tuple in self.model.named_parameters():
# name, param = param_tuple
# print("name = ", name)
# print("-" * 100)
for name, param in self.model.named_parameters():
if param.requires_grad and emb_name in name:
param_data = param.data # torch.Size([vocab_size, hidden_size])<---->torch.Size([21128, 768])
param_grad = param.grad # torch.Size([vocab_size, hidden_size])<---->torch.Size([21128, 768])
self.backup[name] = param_data.clone() # 保存原始参数,用于后续恢复
norm = torch.norm(param_grad) # tensor(2.2943e+09, device='cuda:0')
if norm != 0 and not torch.isnan(norm): # 检查张量 norm 中的每个元素是否为NaN
r_at = epsilon * param_grad / norm
param.data.add_(r_at)
def restore(self, emb_name='word_embeddings'):
# emb_name这个参数要换成你模型中embedding的参数名
for name, param in self.model.named_parameters():
if param.requires_grad and emb_name in name:
assert name in self.backup
param.data = self.backup[name]
self.backup = {}
def train():
set_seed()
output_path = os.path.join(args.output_path) # 'output'
train_path = os.path.join(args.base_path, args.dataset, "train_不包含spo为空的样本_修复下标_len200_all_relation.json") # 'data/bdci/train_不包含spo为空的样本_修复下标_len200_all_relation.json'
rel2id_path = os.path.join(args.base_path, args.dataset, "rel2id.json") # 'data/bdci/rel2id.json'
log_path = os.path.join(output_path, "log.txt") # 'output/log.txt'
if not os.path.exists(output_path):
os.makedirs(output_path)
if not os.path.exists(args.result_path):
os.makedirs(args.result_path)
# label:
# 第1个字母表示当前元素所属的“头实体”的第一个字或最后一个字,且M表示当前头实体是多字词(M)或单字词(S);
# 第2个字母表示当前元素对应的“尾实体”的第一个字或最后一个字,且M表示当前尾实体是多字词(M)或单字词(S);
# 第3个字母代表当前元素对应的“头实体”与“尾实体”的第一个字或“头实体”与“尾实体”的最后一个字
# "SMH", "SMT"是一组;
# "SS"是一组;
# "MMH", "MMT"是一组;
# "MSH", "MST"是一组;
label_list = ["N/A", "SMH", "SMT", "SS", "MMH", "MMT", "MSH", "MST"]
id2label, label2id = {}, {}
for idx, label in enumerate(label_list):
id2label[str(idx)] = label
label2id[label] = idx
train_data = json.load(open(train_path))
id2rel, rel2id = json.load(open(rel2id_path))
all_data = np.array(train_data)
kf = KFold(n_splits=args.k_num, shuffle=True, random_state=42)
fold = 0
for train_index, val_index in kf.split(all_data):
fold += 1
test_pred_path = os.path.join(args.result_path, f"{fold}.json") # 'result/1.json'
print("="*80)
print(f"正在训练第 {fold} 折的数据")
train_data = all_data[train_index]
val_data = all_data[val_index]
# 加载分词器
tokenizer = Tokenizer(args.bert_vocab_path)
# 参数设置
config = BertConfig.from_pretrained(args.pretrained_model_path) # bert的原有参数
config.num_relation = len(id2rel) # 关系数量:4
config.num_label = len(label_list) # 标签数量:8
config.rounds = args.rounds # GRTE模型内部GFM模块循环次数
config.fix_bert_embeddings = args.fix_bert_embeddings # 是否冻结预训练语言模型参数
# 'pretrain_models/roberta_wwm_large'
grte_model = GRTE.from_pretrained(pretrained_model_name_or_path=args.pretrained_model_path, config=config)
grte_model.to("cuda")
# 初始化对抗训练
fgm = FGM(grte_model)
scaler = torch.cuda.amp.GradScaler() # 梯度缩放
# 数据加载
train_dataloader = data_generator(args=args, data=train_data, tokenizer=tokenizer, relation_map=[rel2id, id2rel], label_map=[label2id, id2label], batch_size=args.batch_size, random=True)
val_dataloader = data_generator(args=args, data=val_data, tokenizer=tokenizer, relation_map=[rel2id, id2rel], label_map=[label2id, id2label], batch_size=args.val_batch_size, random=False, is_train=False)
# 优化器设置
len_train_dataloader = len(train_dataloader) # 1232
t_total = len_train_dataloader * args.num_train_epochs
no_decay = ["bias", "LayerNorm.weight"]
optimizer_grouped_parameters = [
{
"params": [p for n, p in grte_model.named_parameters() if not any(nd in n for nd in no_decay)],
"weight_decay": args.weight_decay,
},
{"params": [p for n, p in grte_model.named_parameters() if any(nd in n for nd in no_decay)],
"weight_decay": 0.0},
]
optimizer = AdamW(optimizer_grouped_parameters, lr=args.learning_rate, eps=args.min_num)
scheduler = get_linear_schedule_with_warmup(optimizer, num_warmup_steps=args.warmup * t_total, num_training_steps=t_total)
# 损失函数
crossentropy = nn.CrossEntropyLoss(reduction="none")
# 开始训练
best_f1 = -1.0
step = 0
for epoch in range(args.num_train_epochs):
print("current epoch:", epoch)
grte_model.train()
epoch_loss = 0
with tqdm(total=train_dataloader.__len__()) as t:
for idx, batch_data in enumerate(train_dataloader):
# [batch_token_ids, batch_mask, batch_label, batch_mask_label, batch_samples]
batch = [torch.tensor(d).to("cuda") for d in batch_data[:-1]]
# torch.Size([2, 91]), torch.Size([2, 91]), torch.Size([2, 91, 91, 4]), torch.Size([2, 91, 91, 4])
batch_token_ids, batch_mask, batch_label, batch_mask_label = batch
batch_label = batch_label.reshape([-1]) # torch.Size([batch_size, seq_len, seq_len, num_rel])---->torch.Size([batch_size*seq_len*seq_len*num_rel])
# =====================================================================================
# 正常训练
# =====================================================================================
# torch.Size([batch_size, seq_len])---->torch.Size([batch_size, seq_len, seq_len, num_rel, num_label])
table = grte_model(batch_token_ids, batch_mask) # torch.Size([2, 91])---->torch.Size([2, 91, 91, 4, 8])
# torch.Size([batch_size, seq_len, seq_len, num_rel, num_label])---->torch.Size([batch_size*seq_len*seq_len*num_rel, num_label])
table = table.reshape([-1, len(label_list)]) # torch.Size([2, 91, 91, 4, 8])---->torch.Size([66248, 8])
loss = crossentropy(table, batch_label.long()) # torch.Size([batch_size*seq_len*seq_len*num_rel, num_label]), torch.Size([batch_size*seq_len*seq_len*num_rel])---->torch.Size([batch_size*seq_len*seq_len*num_rel])
loss = (loss * batch_mask_label.reshape([-1])).sum()
scaler.scale(loss).backward() # Scales loss. 为了梯度放大.
# =====================================================================================
# 对抗训练【要使用对抗训练,需要将fix_bert_embeddings设置为False】
# =====================================================================================
fgm.attack() # 对抗训练:在embedding上添加对抗扰动
table_adv = grte_model(batch_token_ids, batch_mask)
table_adv = table_adv.reshape([-1, len(label_list)])
loss_adv = crossentropy(table_adv, batch_label.long())
loss_adv = (loss_adv * batch_mask_label.reshape([-1])).sum()
scaler.scale(loss_adv).backward() # Scales loss. 为了梯度放大.
fgm.restore() # 对抗训练:恢复embedding参数
step += 1
epoch_loss += loss.item()
scaler.unscale_(optimizer)
torch.nn.utils.clip_grad_norm_(grte_model.parameters(), args.max_grad_norm)
# scaler.step() 首先把梯度的值unscale回来.
# 如果梯度的值不是 infs 或者 NaNs, 那么调用optimizer.step()来更新权重,
# 否则,忽略step调用,从而保证权重不更新(不被破坏)
scaler.step(optimizer)
# 准备着,看是否要增大scaler
scaler.update()
scheduler.step() # Update learning rate schedule
grte_model.zero_grad()
t.set_postfix(loss="%.4lf" % (loss.cpu().item()))
t.update(1)
f1, precision, recall = evaluate(args, tokenizer, id2rel, id2label, label2id, grte_model, val_dataloader, test_pred_path)
if f1 > best_f1:
# Save model checkpoint
best_f1 = f1
torch.save(grte_model.state_dict(), f=f"{args.output_path}/model_{fold}.pth")
epoch_loss = epoch_loss / train_dataloader.__len__()
with open(log_path, "a", encoding="utf-8") as f:
print("epoch is:%d\tloss is:%f\tf1 is:%f\tprecision is:%f\trecall is:%f\tbest_f1 is:%f\t" % (int(epoch), epoch_loss, f1, precision, recall, best_f1), file=f)
grte_model.load_state_dict(torch.load(f"{args.output_path}/model_{fold}.pth", map_location="cuda"))
f1, precision, recall = evaluate(args, tokenizer, id2rel, id2label, label2id, grte_model, val_dataloader, test_pred_path)
print("best model test: f1:%f\tprecision:%f\trecall:%f" % (f1, precision, recall))
torch.cuda.empty_cache()
del grte_model
def evaluate(args, tokenizer, id2rel, id2label, label2id, model, dataloader, evl_path):
X, Y, Z = 1e-10, 1e-10, 1e-10
f = open(evl_path, 'w', encoding='utf-8') # 'result/1.json'
pbar = tqdm()
for batch_idx, batch in enumerate(dataloader):
batch_samples = batch[-1]
# 只提取 batch_token_ids, batch_mask
batch = [torch.tensor(d).to("cuda") for d in batch[:-1]]
batch_token_ids, batch_mask = batch
# if isinstance(model, torch.nn.DataParallel):
# model = model.module
# model.to("cuda")
# model.eval()
# with torch.no_grad():
# table = model(batch_token_ids, batch_mask) # (batch_size, max_len, max_len, num_rels, num_labels) (2, 128, 128, 4, 8)
# table = table.cpu().detach().numpy()
# args, table, tokenizer, id2rel, id2label, label2id, model, batch_samples
batch_spo = extract_spo_list(args, tokenizer, id2rel, id2label,
label2id, model, batch_samples, batch_token_ids, batch_mask)
for sample_idx, sample in enumerate(batch_samples):
spos_for_curr_sample = batch_spo[sample_idx]
spos_set_predict = set(
[(tuple(spo[0]), spo[1], tuple(spo[2])) for spo in spos_for_curr_sample])
spos_set_true = set(
[(tuple(spo[0]), spo[1], tuple(spo[2])) for spo in sample['spos']])
X += len(spos_set_predict & spos_set_true)
Y += len(spos_set_predict)
Z += len(spos_set_true)
precision, recall, f1 = X / Y, X / Z, 2 * X / (Y + Z)
pbar.update()
pbar.set_description(
'f1: %.5f, precision: %.5f, recall: %.5f' % (f1, precision, recall))
s = json.dumps({'text': sample['text'], 'spos': list(spos_set_true), 'spos_pred': list(spos_set_predict), 'new': list(
spos_set_predict - spos_set_true), 'lack': list(spos_set_true - spos_set_predict)}, ensure_ascii=False)
f.write(s + '\n')
pbar.close()
f.close()
precision, recall, f1 = X / Y, X / Z, 2 * X / (Y + Z)
return f1, precision, recall
if __name__ == '__main__':
parser = argparse.ArgumentParser(description='Model Controller')
parser.add_argument('--rounds', default=4, type=int) # 用于模型中的循环
parser.add_argument('--k_num', default=3, type=int) # 3折训练
parser.add_argument('--max_len', default=200, type=int) # 文本最长长度
parser.add_argument('--dataset', default='bdci', type=str) # 数据集名称
parser.add_argument('--batch_size', default=2, type=int) # 4
parser.add_argument('--val_batch_size', default=2, type=int) # 4
parser.add_argument('--learning_rate', default=2e-5, type=float)
parser.add_argument('--num_train_epochs', default=30, type=int)
parser.add_argument('--fix_bert_embeddings', default=False, type=bool) # 冻结预训练模型参数
parser.add_argument('--bert_vocab_path', default="pretrain_models/bert_base_chinese/vocab.txt", type=str) # chinese_pretrain_mrc_macbert_large
parser.add_argument('--pretrained_model_path', default="pretrain_models/bert_base_chinese", type=str) # chinese_pretrain_mrc_macbert_large
parser.add_argument('--warmup', default=0.0, type=float) # 0.0
parser.add_argument('--weight_decay', default=0.0, type=float) # 0.0
parser.add_argument('--max_grad_norm', default=1.0, type=float)
parser.add_argument('--min_num', default=1e-7, type=float)
parser.add_argument('--base_path', default="data", type=str)
parser.add_argument('--output_path', default="output", type=str)
parser.add_argument('--result_path', default="result", type=str)
args = parser.parse_args()
train()二、PGD(Projected Gradient Descent)
内部max的过程,本质上是一个非凹的约束优化问题,FGM解决的思路其实就是梯度上升,那么FGM简单粗暴的“一步到位”,是不是有可能并不能走到约束内的最优点呢?当然是有可能的。
于是,一个很intuitive的改进诞生了:Madry在18年的ICLR中[8],提出了用Projected Gradient Descent(PGD)的方法,简单的说,就是“小步走,多走几步”,如果走出了扰动半径为 ϵ 的空间,就映射回“球面”上,以保证扰动不要过大:

import torch
class PGD():
def __init__(self, model):
self.model = model
self.emb_backup = {}
self.grad_backup = {}
def attack(self, epsilon=1., alpha=0.3, emb_name='emb.', is_first_attack=False):
# emb_name这个参数要换成你模型中embedding的参数名
for name, param in self.model.named_parameters():
if param.requires_grad and emb_name in name:
if is_first_attack:
self.emb_backup[name] = param.data.clone()
norm = torch.norm(param.grad)
if norm != 0 and not torch.isnan(norm):
r_at = alpha * param.grad / norm
param.data.add_(r_at)
param.data = self.project(name, param.data, epsilon)
def restore(self, emb_name='emb.'):
# emb_name这个参数要换成你模型中embedding的参数名
for name, param in self.model.named_parameters():
if param.requires_grad and emb_name in name:
assert name in self.emb_backup
param.data = self.emb_backup[name]
self.emb_backup = {}
def project(self, param_name, param_data, epsilon):
r = param_data - self.emb_backup[param_name]
if torch.norm(r) > epsilon:
r = epsilon * r / torch.norm(r)
return self.emb_backup[param_name] + r
def backup_grad(self):
for name, param in self.model.named_parameters():
if param.requires_grad:
self.grad_backup[name] = param.grad.clone()
def restore_grad(self):
for name, param in self.model.named_parameters():
if param.requires_grad:
param.grad = self.grad_backup[name]使用的时候,要麻烦一点:
pgd = PGD(model)
K = 3
for batch_input, batch_label in data:
# 正常训练
loss = model(batch_input, batch_label)
loss.backward() # 反向传播,得到正常的grad
pgd.backup_grad()
# 对抗训练
for t in range(K):
pgd.attack(is_first_attack=(t==0)) # 在embedding上添加对抗扰动, first attack时备份param.data
if t != K-1:
model.zero_grad()
else:
pgd.restore_grad()
loss_adv = model(batch_input, batch_label)
loss_adv.backward() # 反向传播,并在正常的grad基础上,累加对抗训练的梯度
pgd.restore() # 恢复embedding参数
# 梯度下降,更新参数
optimizer.step()
model.zero_grad()在[8]中,作者将这一类通过一阶梯度得到的对抗样本称之为“一阶对抗”,在实验中,作者发现,经过PGD训练过的模型,对于所有的一阶对抗都能得到一个低且集中的损失值,如下图所示:
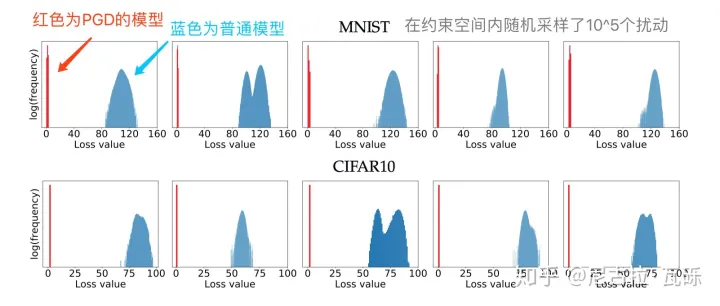
我们可以看到,面对约束空间 S 内随机采样的十万个扰动,PGD模型能够得到一个非常低且集中的loss分布,因此,在论文中,作者称PGD为“一阶最强对抗”。也就是说,只要能搞定PGD对抗,别的一阶对抗就不在话下了。
三、总结
对抗训练中关键的是需要找到对抗样本(尽量让模型预测出错的样本),通常是对原始的输入添加一定的扰动来构造,然后用来给模型训练.
【炼丹技巧】功守道:NLP中的对抗训练 + PyTorch实现 - 知乎

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐



 2
2 0
0- 0



 已为社区贡献52条内容
已为社区贡献52条内容

所有评论(0)