
【毕业设计】基于机器学习的护目镜佩戴识别分类 人工智能 深度学习 Python 目标检测 数据集
毕业设计:工人护目镜佩戴识别数据集包含多种场景下的图像,明确标注了工人佩戴护目镜(mask)和未佩戴护目镜(no-mask)两类。每张图像均经过精心处理,确保在不同光照、角度和背景条件下的有效性,适合用于深度学习模型的训练和测试。通过使用YOLO等先进的深度学习技术,研究人员可以快速准确地识别工人护目镜的佩戴状态,从而实现实时监控。这一数据集不仅为护目镜佩戴的自动检测提供了丰富的基础数据,还为企业
一、背景意义
在工业生产和建筑施工等高风险环境中,工人面临着多种安全隐患,尤其是眼部受伤的风险。护目镜作为个人防护装备的重要组成部分,能够有效保护工人的眼睛免受飞溅物、化学品和有害光线的伤害。然而,尽管护目镜的使用至关重要,但在实际工作中,部分工人由于疏忽或不适应而未能正确佩戴护目镜。为了提高工人的安全意识和保护水平,开发一个自动识别工人佩戴护目镜的系统显得尤为必要。随着深度学习技术的迅猛发展,计算机视觉在安全监控和智能识别领域的应用逐渐增多。通过建立工人护目镜佩戴识别系统,可以实时监测工人的佩戴状态,及时发出警示,从而有效减少因未佩戴护目镜而导致的事故。
二、数据集
2.1数据采集
首先,需要大量的护目镜佩戴图像。为了获取这些数据,可以采取了以下几种方式:
-
网络爬虫:使用Python的
BeautifulSoup和Selenium编写了一个网络爬虫,从公开的图片网站、社交媒体和一些开源图片库中抓取了大量图片。在抓取过程中,确保每张图片都有清晰的目标物体,并且避免重复图片。 -
开源数据集:从网上下载了一些公开的数据集。这些数据集为项目提供了一个良好的起点,尤其在数据量不足时,它们可以极大地提高模型训练的效果。
-
自定义照片:为了增加数据的多样性,还拍摄了一些照片,包括不同的品种、背景和光照条件,以确保数据的丰富性和代表性。
在收集到大量图片后,对这些原始数据进行了清洗和筛选:
-
去除低质量图片:一些图像模糊、分辨率过低或者有其他物体干扰的图片被剔除掉。确保每张图片都能清晰地展示护目镜佩戴特征是数据质量的关键。
-
统一格式:将所有图片转换为统一的JPEG格式,并将图片的分辨率统一到256x256像素,这样可以在后续的训练中减少不必要的图像缩放操作,保证数据的一致性。
-
分类整理:将所有图片按照类别进行分类,分别放入对应文件夹中。每个类别的文件夹下严格只包含对应的图片,避免数据集出现混乱。
2.2数据标注
收集的数据通常是未经处理的原始数据,需要进行标注以便模型训练。数据标注的方式取决于任务的类型:
- 分类任务:为每个数据样本分配类别标签。
- 目标检测:标注图像中的每个目标,通常使用边界框。
- 语义分割:为每个像素分配一个类别标签。
在使用LabelImg标注护目镜佩戴数据集的过程中,标注任务的复杂性和工作量非常大。首先,用户需准备包含佩戴和未佩戴护目镜的多张图像,这些图像可能来自不同的环境和角度,背景复杂且光照条件各异,增加了标注的难度。使用LabelImg时,用户需要逐张图像进行处理,准确绘制边界框并为每个实例分配相应的标签,确保标注的准确性。此外,由于数据集包含多个不同的佩戴状态,标注工作量庞大,可能需要数小时甚至几天才能完成。标注结束后,还需进行严格的质量检查,以确保每个标签的一致性和有效性。
包含6283张护目镜图片,数据集中包含以下几种类别
- 护目镜:戴着护目镜的状态。
- 未戴护目镜:没有戴护目镜的状态。
2.3数据预处理
在标注完成后,数据通常还需要进行预处理以确保其适合模型的输入格式。常见的预处理步骤包括:
- 数据清洗:去除重复、无效或有噪声的数据。
- 数据标准化:例如,对图像进行尺寸调整、归一化,对文本进行分词和清洗。
- 数据增强:通过旋转、缩放、裁剪等方法增加数据的多样性,防止模型过拟合。
- 数据集划分:将数据集划分为训练集、验证集和测试集,确保模型的泛化能力。
在使用深度学习进行训练任务时,通常需要将数据集划分为训练集、验证集和测试集。这种划分是为了评估模型的性能并确保模型的泛化能力。数据集划分为训练集、验证集和测试集的比例。常见的比例为 70% 训练集、20% 验证集和 10% 测试集,也就是7:2:1。数据集已经按照标准比例进行划分。
标注格式:
- VOC格式 (XML)
- YOLO格式 (TXT)
yolo_dataset/
│
├── train/
│ ├── images/
│ │ ├── image1.jpg
│ │ ├── image2.jpg
│ │ ├── ...
│ │
│ └── labels/
│ ├── image1.txt
│ ├── image2.txt
│ ├── ...
│
└── test...
└── valid...
voc_dataset/
│
├── train/
│ ├───├
│ │ ├── image1.xml
│ │ ├── image2.xml
│ │ ├── ...
│ │
│ └───├
│ ├── image1.jpg
│ ├── image2.jpg
│ ├── ...
│
└── test...
└── valid...三、模型训练
3.1理论技术
卷积神经网络(CNN)在护目镜佩戴识别中发挥着重要作用,其强大的特征提取能力使得模型能够有效识别佩戴护目镜的状态。通过构建包含多种场景和佩戴状态的图像数据集,并进行精确标注,CNN能够学习到护目镜的形状、颜色和佩戴位置等关键特征。训练过程中,采用深度学习框架对模型进行优化,并使用交叉验证评估其性能,以确保高识别精度。最终,训练好的CNN模型可以集成到实时监控系统中,自动识别工作人员是否正确佩戴护目镜,从而提高工业安全、建筑工地和实验室等高风险环境的安全性。
卷积神经网络(CNN)通常由三个主要组成部分构成,分别是输入层、隐藏层和输出层。输入层直接处理图像信号,无需将其转换为一维形式,显著提高了数据处理的效率。隐藏层由多个卷积层和池化层组成,其中卷积层负责特征提取,通过卷积操作捕捉图像中的重要特征;而池化层则实现特征降维,减少计算复杂度并增强模型的鲁棒性。最后,输出层由全连接网络分类器构成,用于对处理后的数据进行分类或回归任务。
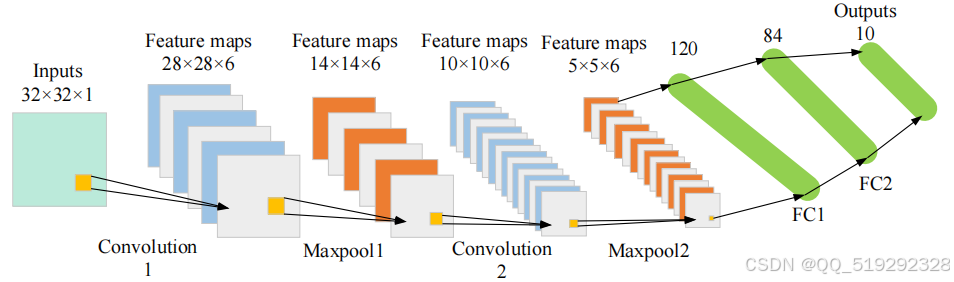
卷积神经网络(CNN)在处理计算量较大的图像识别任务中表现优异,其核心组件是卷积层。与传统的数学卷积不同,CNN中的卷积操作主要针对两个矩阵,采用滑动窗口机制,通过乘法和加法提取输入信号中的关键信息。这种高效的特征提取方法使得CNN能够有效学习图像中的复杂模式,从而在识别任务中取得更好的结果。
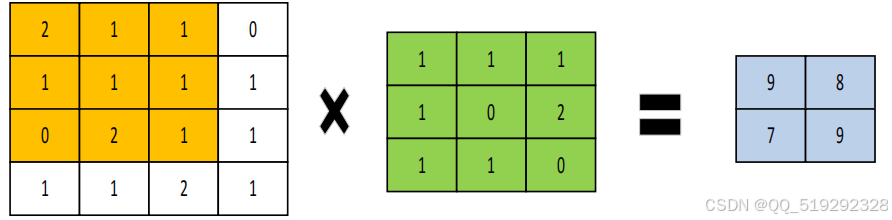
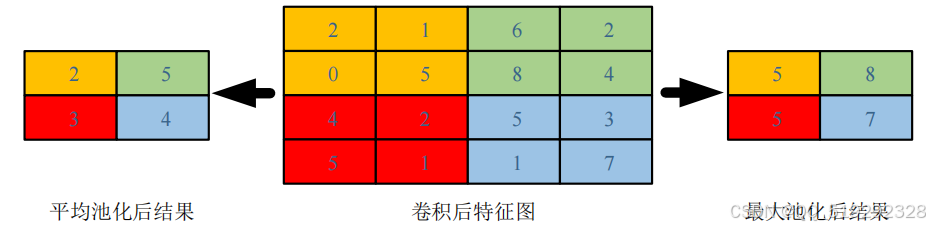
池化层是CNN的重要组成部分,通常用于卷积操作之后。它的主要作用是降低特征图的分辨率,从而减少网络的计算量和参数量。在训练和测试阶段,过多的参数和计算会导致时间消耗过大,池化层通过有效保留原有信息并剔除冗余信息,提升了网络对特征信息的提取能力。此外,池化层的引入可以缓解梯度消失的问题,保持网络的学习能力。
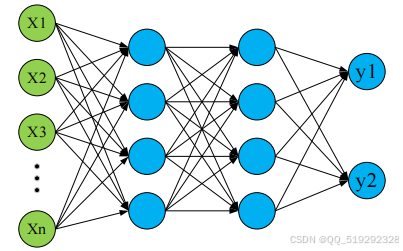
全连接层通常是CNN的最后一部分,用于接收来自卷积或池化层提取的特征信息。在传递到全连接层之前,需要将3维信号通过铺平(Flatten)处理成1维信号。虽然全连接层的输出大小取决于标签数量,但在某些情况下,尤其是进行分割任务时,可以选择不使用全连接层。由于全连接层的计算参数较多,可能对网络性能产生负面影响,因此在实际应用中,通常只会使用少量的全连接层,以达到最佳的性能与效率平衡。
3.2模型训练
1. 环境配置
在开始之前,首先需要配置开发环境,确保安装所需的库和工具。YOLOv5是一个常用的YOLO实现,使用Python和PyTorch。以下是设置环境的步骤:
# 克隆YOLOv5代码库
git clone https://github.com/ultralytics/yolov5.git
cd yolov5
# 安装依赖项
pip install -r requirements.txt
# 如果使用GPU,确保安装CUDA和cuDNN
2. 模型选择与配置
选择一个合适的YOLO模型并进行配置。YOLOv5提供了多种模型变种(如YOLOv5s、YOLOv5m等)。接下来,创建一个自定义配置文件,定义护目镜佩戴的类别。
# custom_yolov5.yaml
nc: 2 # 类别数量
names: ['mask', 'no-mask'] # 类别名称
3. 数据预处理
确保数据集符合YOLO要求的格式。数据集应包括图像和相应的标签文件。创建一个数据集配置文件,内容如下:
# goggles_dataset.yaml
train: ../data/train/images # 训练集图像路径
val: ../data/val/images # 验证集图像路径
nc: 2 # 类别数量
names: ['mask', 'no-mask'] # 类别名称
4. 训练与推理
使用YOLOv5的训练脚本进行模型训练。以下命令用于开始训练:
# 开始训练
python train.py --img 640 --batch 16 --epochs 50 --data goggles_dataset.yaml --cfg custom_yolov5.yaml --weights yolov5s.pt --name goggles_detection
训练完成后,可以使用训练好的模型进行推理。以下是推理的示例代码:
import torch
from pathlib import Path
import cv2
# 加载训练好的模型
model = torch.hub.load('ultralytics/yolov5', 'custom', path='runs/train/goggles_detection/weights/best.pt')
# 读取待检测图像
img_path = 'path/to/test/image.jpg'
img = cv2.imread(img_path)
# 推理
results = model(img)
# 可视化结果
results.show()
results.save(Path('results')) # 保存推理结果四、总结
随着工业安全意识的提高,工人护目镜的佩戴成为保障作业安全的重要措施。利用深度学习技术,通过实时图像分析,能够快速识别工人在工作场所的护目镜佩戴状态,从而提高安全管理的效率。在数据集准备完成后,系统开发分为几个关键步骤。首先是环境配置,确保系统可以运行YOLOv5模型。接着,选择适合项目需求的YOLO模型,并进行相应的配置,定义护目镜佩戴的类别。然后,进行数据预处理,确保图像和标签符合YOLO要求的格式,创建相应的数据集配置文件。在训练阶段,使用准备好的数据集对YOLO模型进行训练,调整参数以优化模型性能。训练完成后,使用验证集评估模型效果,并进行必要的调优。最终,利用训练好的模型进行推理,实时监控工人护目镜的佩戴情况。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐



 8
8 0
0- 0



 已为社区贡献19条内容
已为社区贡献19条内容

所有评论(0)