
Machine Learning Mastery Keras 深度学习教程(三)
本教程分为三个部分;多输出回归多输出神经网络多输出回归的神经网络在本教程中,您发现了如何为多输出回归开发深度学习模型。多输出回归是一项预测建模任务,涉及两个或多个数值输出变量。可以为多输出回归任务配置神经网络模型。如何评价多输出回归的神经网络并对新数据进行预测?你有什么问题吗?在下面的评论中提问,我会尽力回答。本教程分为 4 个部分;伍兹乳房 x 线摄影数据集神经网络学习动力学稳健模型评估最终模型
用于多输出回归的深度学习模型
原文:https://machinelearningmastery.com/deep-learning-models-for-multi-output-regression/
最后更新于 2020 年 8 月 28 日
多输出回归包括预测两个或多个数值变量。
与为每个样本预测单个值的正常回归不同,多输出回归需要支持为每个预测输出多个变量的专门机器学习算法。
深度学习神经网络是原生支持多输出回归问题的算法的一个例子。使用 Keras 深度学习库可以轻松定义和评估多输出回归任务的神经网络模型。
在本教程中,您将发现如何为多输出回归开发深度学习模型。
完成本教程后,您将知道:
- 多输出回归是一项预测建模任务,涉及两个或多个数值输出变量。
- 可以为多输出回归任务配置神经网络模型。
- 如何评价多输出回归的神经网络并对新数据进行预测?
我们开始吧。

多输出回归的深度学习模型
图片由克里斯蒂安·科林斯提供,版权所有。
教程概述
本教程分为三个部分;它们是:
- 多输出回归
- 多输出神经网络
- 多输出回归的神经网络
多输出回归
回归是一项预测建模任务,包括在给定输入的情况下预测数值输出。
它不同于涉及预测类别标签的分类任务。
通常,回归任务包括预测单个数值。但是,有些任务需要预测多个数值。这些任务被称为多输出回归,简称多输出回归。
在多输出回归中,每个输入样本需要两个或多个输出,并且同时需要输出。假设输出是输入的函数。
我们可以使用 Sklearn 库中的make _ revolution()函数创建一个合成的多输出回归数据集。
我们的数据集将有 1000 个样本,包含 10 个输入要素,其中 5 个与输出相关,5 个是冗余的。对于每个样本,数据集将有三个数字输出。
下面列出了创建和总结合成多输出回归数据集的完整示例。
# example of a multi-output regression problem
from sklearn.datasets import make_regression
# create dataset
X, y = make_regression(n_samples=1000, n_features=10, n_informative=5, n_targets=3, random_state=2)
# summarize shape
print(X.shape, y.shape)
运行该示例将创建数据集并总结输入和输出元素的形状。
我们可以看到,正如预期的那样,有 1000 个样本,每个样本有 10 个输入特征和 3 个输出特征。
(1000, 10) (1000, 3)
接下来,让我们看看如何为多输出回归任务开发神经网络模型。
多输出神经网络
许多机器学习算法本身支持多输出回归。
常见的例子是决策树和决策树的集合。用于多输出回归的决策树的一个限制是输入和输出之间的关系可以是块状的或者基于训练数据的高度结构化的。
神经网络模型还支持多输出回归,并且具有学习连续函数的好处,该函数可以在输入和输出的变化之间建立更优美的关系。
只要将问题中存在的目标变量的数量指定为输出层中的节点数量,神经网络就可以直接支持多输出回归。例如,具有三个输出变量的任务将需要一个神经网络输出层,在输出层中有三个节点,每个节点都具有线性(默认)激活函数。
我们可以使用 Keras 深度学习库来演示这一点。
我们将为上一节中定义的多输出回归任务定义一个多层感知机(MLP)模型。
每个样本有 10 个输入和 3 个输出,因此,网络需要一个输入层,它期望通过第一个隐藏层中的“ input_dim ”参数和输出层中的 3 个节点指定 10 个输入。
我们将使用隐藏层中流行的 ReLU 激活函数。隐藏层有 20 个节点,这些节点是经过反复试验选择的。我们将使用平均绝对误差损失和随机梯度下降的亚当版本来拟合模型。
下面列出了多输出回归任务的网络定义。
...
# define the model
model = Sequential()
model.add(Dense(20, input_dim=10, kernel_initializer='he_uniform', activation='relu'))
model.add(Dense(3))
model.compile(loss='mae', optimizer='adam')
您可能希望将此模型用于自己的多输出回归任务,因此,我们可以创建一个函数来定义和返回模型,其中输入变量的数量和输出变量的数量作为参数提供。
# get the model
def get_model(n_inputs, n_outputs):
model = Sequential()
model.add(Dense(20, input_dim=n_inputs, kernel_initializer='he_uniform', activation='relu'))
model.add(Dense(n_outputs))
model.compile(loss='mae', optimizer='adam')
return model
现在我们已经熟悉了如何定义多输出回归的 MLP,让我们来探索如何评估这个模型。
多输出回归的神经网络
如果数据集很小,最好在同一数据集上重复评估神经网络模型,并报告重复的平均表现。
这是因为学习算法的随机性。
此外,在对新数据进行预测时,最好使用 k 倍交叉验证代替数据集的训练/测试分割,以获得模型表现的无偏估计。同样,只有当没有太多的数据并且该过程可以在合理的时间内完成时。
考虑到这一点,我们将使用 10 倍和 3 倍重复的重复 k 倍交叉验证来评估多输出回归任务的 MLP 模型。
模型的每个折叠都被定义、拟合和评估。收集分数,并通过报告平均值和标准偏差进行汇总。
下面的 evaluate_model() 函数获取数据集,对模型进行评估,并返回评估分数列表,在本例中为 MAE 分数。
# evaluate a model using repeated k-fold cross-validation
def evaluate_model(X, y):
results = list()
n_inputs, n_outputs = X.shape[1], y.shape[1]
# define evaluation procedure
cv = RepeatedKFold(n_splits=10, n_repeats=3, random_state=1)
# enumerate folds
for train_ix, test_ix in cv.split(X):
# prepare data
X_train, X_test = X[train_ix], X[test_ix]
y_train, y_test = y[train_ix], y[test_ix]
# define model
model = get_model(n_inputs, n_outputs)
# fit model
model.fit(X_train, y_train, verbose=0, epochs=100)
# evaluate model on test set
mae = model.evaluate(X_test, y_test, verbose=0)
# store result
print('>%.3f' % mae)
results.append(mae)
return results
然后,我们可以加载数据集,评估模型,并报告平均表现。
将这些联系在一起,完整的示例如下所示。
# mlp for multi-output regression
from numpy import mean
from numpy import std
from sklearn.datasets import make_regression
from sklearn.model_selection import RepeatedKFold
from keras.models import Sequential
from keras.layers import Dense
# get the dataset
def get_dataset():
X, y = make_regression(n_samples=1000, n_features=10, n_informative=5, n_targets=3, random_state=2)
return X, y
# get the model
def get_model(n_inputs, n_outputs):
model = Sequential()
model.add(Dense(20, input_dim=n_inputs, kernel_initializer='he_uniform', activation='relu'))
model.add(Dense(n_outputs))
model.compile(loss='mae', optimizer='adam')
return model
# evaluate a model using repeated k-fold cross-validation
def evaluate_model(X, y):
results = list()
n_inputs, n_outputs = X.shape[1], y.shape[1]
# define evaluation procedure
cv = RepeatedKFold(n_splits=10, n_repeats=3, random_state=1)
# enumerate folds
for train_ix, test_ix in cv.split(X):
# prepare data
X_train, X_test = X[train_ix], X[test_ix]
y_train, y_test = y[train_ix], y[test_ix]
# define model
model = get_model(n_inputs, n_outputs)
# fit model
model.fit(X_train, y_train, verbose=0, epochs=100)
# evaluate model on test set
mae = model.evaluate(X_test, y_test, verbose=0)
# store result
print('>%.3f' % mae)
results.append(mae)
return results
# load dataset
X, y = get_dataset()
# evaluate model
results = evaluate_model(X, y)
# summarize performance
print('MAE: %.3f (%.3f)' % (mean(results), std(results)))
运行该示例报告每个折叠和每个重复的 MAE,以给出评估进度的想法。
注:考虑到算法或评估程序的随机性,或数值精确率的差异,您的结果可能会有所不同。考虑运行该示例几次,并比较平均结果。
最后,报告了平均和标准差。在这种情况下,该模型显示的 MAE 约为 8.184。
您可以使用此代码作为模板,在自己的多输出回归任务中评估 MLP 模型。模型中节点和图层的数量可以根据数据集的复杂性轻松调整和定制。
...
>8.054
>7.562
>9.026
>8.541
>6.744
MAE: 8.184 (1.032)
一旦选择了模型配置,我们就可以使用它来拟合所有可用数据的最终模型,并对新数据进行预测。
下面的示例演示了这一点,首先在整个多输出回归数据集上拟合 MLP 模型,然后在保存的模型上调用 predict() 函数,以便对新的数据行进行预测。
# use mlp for prediction on multi-output regression
from numpy import asarray
from sklearn.datasets import make_regression
from keras.models import Sequential
from keras.layers import Dense
# get the dataset
def get_dataset():
X, y = make_regression(n_samples=1000, n_features=10, n_informative=5, n_targets=3, random_state=2)
return X, y
# get the model
def get_model(n_inputs, n_outputs):
model = Sequential()
model.add(Dense(20, input_dim=n_inputs, kernel_initializer='he_uniform', activation='relu'))
model.add(Dense(n_outputs, kernel_initializer='he_uniform'))
model.compile(loss='mae', optimizer='adam')
return model
# load dataset
X, y = get_dataset()
n_inputs, n_outputs = X.shape[1], y.shape[1]
# get model
model = get_model(n_inputs, n_outputs)
# fit the model on all data
model.fit(X, y, verbose=0, epochs=100)
# make a prediction for new data
row = [-0.99859353,2.19284309,-0.42632569,-0.21043258,-1.13655612,-0.55671602,-0.63169045,-0.87625098,-0.99445578,-0.3677487]
newX = asarray([row])
yhat = model.predict(newX)
print('Predicted: %s' % yhat[0])
运行该示例符合模型,并对新行进行预测。
注:考虑到算法或评估程序的随机性,或数值精确率的差异,您的结果可能会有所不同。考虑运行该示例几次,并比较平均结果。
正如预期的那样,预测包含多输出回归任务所需的三个输出变量。
Predicted: [-152.22713 -78.04891 -91.97194]
进一步阅读
如果您想更深入地了解这个主题,本节将提供更多资源。
摘要
在本教程中,您发现了如何为多输出回归开发深度学习模型。
具体来说,您了解到:
- 多输出回归是一项预测建模任务,涉及两个或多个数值输出变量。
- 可以为多输出回归任务配置神经网络模型。
- 如何评价多输出回归的神经网络并对新数据进行预测?
你有什么问题吗?
在下面的评论中提问,我会尽力回答。
为伍兹乳腺摄影数据集开发神经网络
原文:https://machinelearningmastery.com/develop-a-neural-network-for-woods-mammography-dataset/
为新数据集开发神经网络预测模型可能具有挑战性。
一种方法是首先检查数据集,并为哪些模型可能起作用提出想法,然后探索数据集上简单模型的学习动态,最后利用强大的测试工具为数据集开发和调整模型。
该过程可用于开发用于分类和回归预测建模问题的有效神经网络模型。
在本教程中,您将发现如何为伍德的乳腺摄影分类数据集开发多层感知机神经网络模型。
完成本教程后,您将知道:
- 如何加载和总结伍德的乳腺摄影数据集,并使用结果建议数据准备和模型配置使用。
- 如何探索数据集上简单 MLP 模型的学习动态。
- 如何对模型表现进行稳健的估计,调整模型表现并对新数据进行预测。
我们开始吧。

为伍兹乳腺摄影数据集开发神经网络
图片由拉里·罗提供,保留部分权利。
教程概述
本教程分为 4 个部分;它们是:
- 伍兹乳房 x 线摄影数据集
- 神经网络学习动力学
- 稳健模型评估
- 最终模型和做出预测
伍兹乳房 x 线摄影数据集
第一步是定义和探索数据集。
我们将使用“乳腺摄影”标准二进制分类数据集,有时称为“伍兹乳腺摄影”。
该数据集归功于 Kevin Woods 等人和 1993 年发表的题为“乳腺摄影中检测微钙化的模式识别技术的比较评估”的论文
问题的焦点是从放射扫描中检测乳腺癌,特别是在乳房 x 光片上看起来明亮的微钙化簇的存在。
有两类,目标是使用给定分割对象的特征来区分微钙化和非微钙化。
- 非微钙化:阴性,或多数类。
- 微钙化:阳性病例,或少数民族。
乳腺摄影数据集是一个广泛使用的标准机器学习数据集,用于探索和演示许多专门为不平衡分类设计的技术。
注:说得再清楚不过了,我们是不是“解决乳腺癌”。我们正在探索一个标准的分类数据集。
下面是数据集前 5 行的示例
0.23001961,5.0725783,-0.27606055,0.83244412,-0.37786573,0.4803223,'-1'
0.15549112,-0.16939038,0.67065219,-0.85955255,-0.37786573,-0.94572324,'-1'
-0.78441482,-0.44365372,5.6747053,-0.85955255,-0.37786573,-0.94572324,'-1'
0.54608818,0.13141457,-0.45638679,-0.85955255,-0.37786573,-0.94572324,'-1'
-0.10298725,-0.3949941,-0.14081588,0.97970269,-0.37786573,1.0135658,'-1'
...
您可以在此了解有关数据集的更多信息:
我们可以直接从网址将数据集加载为熊猫数据帧;例如:
# load the mammography dataset and summarize the shape
from pandas import read_csv
# define the location of the dataset
url = 'https://raw.githubusercontent.com/jbrownlee/Datasets/master/mammography.csv'
# load the dataset
df = read_csv(url, header=None)
# summarize shape
print(df.shape)
运行该示例直接从 URL 加载数据集,并报告数据集的形状。
在这种情况下,我们可以确认数据集有 7 个变量(6 个输入和 1 个输出),并且数据集有 11,183 行数据。
这是一个中等大小的神经网络数据集,建议使用小型网络。
它还建议使用 k 倍交叉验证将是一个好主意,因为它将给出比训练/测试分割更可靠的模型表现估计,并且因为单个模型将在几秒钟内适合最大数据集,而不是几小时或几天。
(11183, 7)
接下来,我们可以通过查看汇总统计数据和数据图来了解更多关于数据集的信息。
# show summary statistics and plots of the mammography dataset
from pandas import read_csv
from matplotlib import pyplot
# define the location of the dataset
url = 'https://raw.githubusercontent.com/jbrownlee/Datasets/master/mammography.csv'
# load the dataset
df = read_csv(url, header=None)
# show summary statistics
print(df.describe())
# plot histograms
df.hist()
pyplot.show()
运行该示例首先加载之前的数据,然后打印每个变量的汇总统计信息。
我们可以看到这些值通常很小,平均值接近于零。
0 1 ... 4 5
count 1.118300e+04 1.118300e+04 ... 1.118300e+04 1.118300e+04
mean 1.096535e-10 1.297595e-09 ... -1.120680e-09 1.459483e-09
std 1.000000e+00 1.000000e+00 ... 1.000000e+00 1.000000e+00
min -7.844148e-01 -4.701953e-01 ... -3.778657e-01 -9.457232e-01
25% -7.844148e-01 -4.701953e-01 ... -3.778657e-01 -9.457232e-01
50% -1.085769e-01 -3.949941e-01 ... -3.778657e-01 -9.457232e-01
75% 3.139489e-01 -7.649473e-02 ... -3.778657e-01 1.016613e+00
max 3.150844e+01 5.085849e+00 ... 2.361712e+01 1.949027e+00
然后为每个变量创建直方图。
我们可以看到,也许大多数变量具有指数分布,也许变量 5(最后一个输入变量)是具有异常值/缺失值的高斯分布。
我们在每个变量上使用幂变换可能会有一些好处,以便使概率分布不那么偏斜,这可能会提高模型表现。
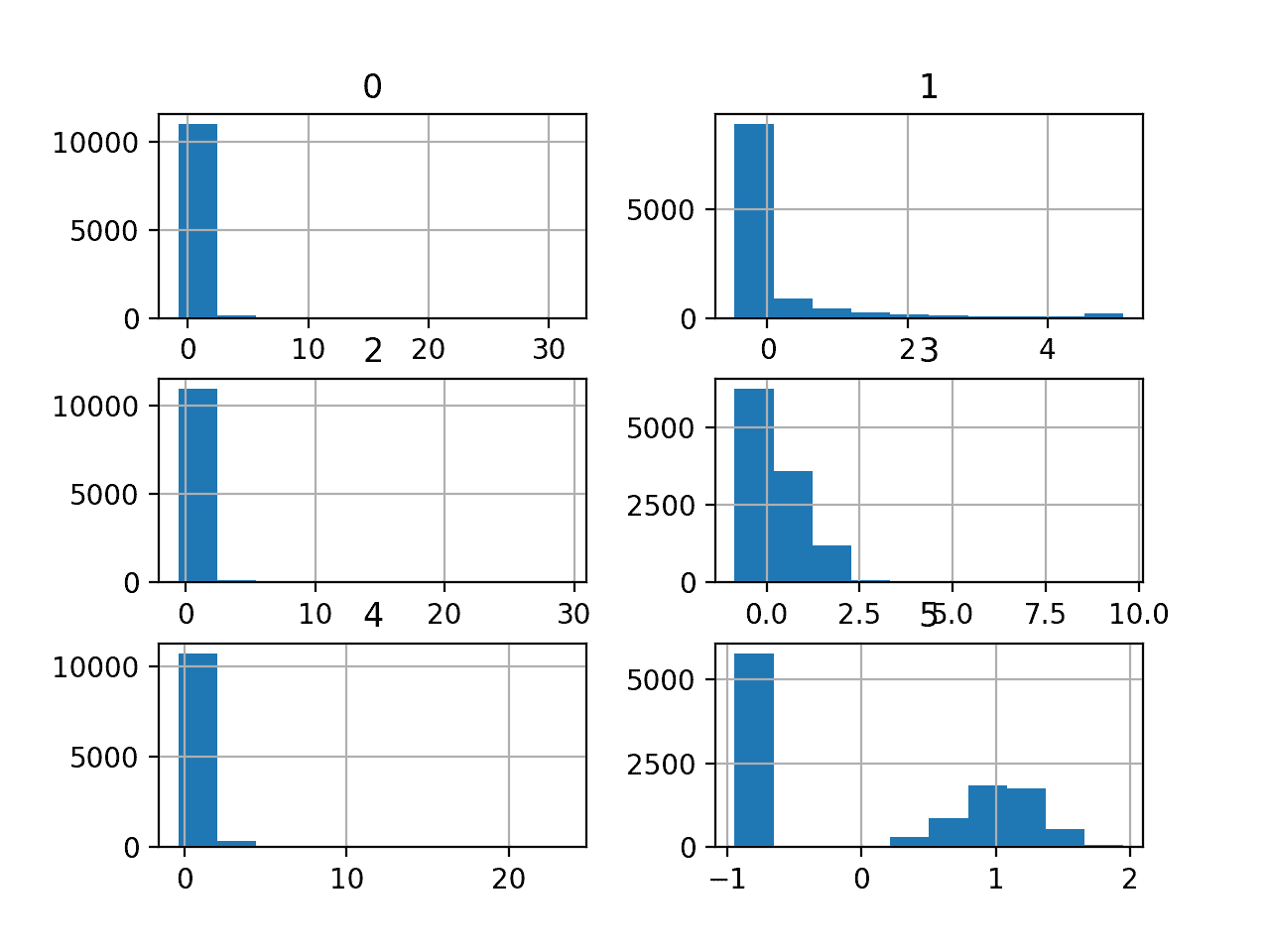
乳腺摄影分类数据集的直方图
了解数据集实际上有多不平衡可能会有所帮助。
我们可以使用 Counter 对象来统计每个类中的示例数量,然后使用这些计数来总结分布。
下面列出了完整的示例。
# summarize the class ratio of the mammography dataset
from pandas import read_csv
from collections import Counter
# define the location of the dataset
url = 'https://raw.githubusercontent.com/jbrownlee/Datasets/master/mammography.csv'
# load the csv file as a data frame
dataframe = read_csv(url, header=None)
# summarize the class distribution
target = dataframe.values[:,-1]
counter = Counter(target)
for k,v in counter.items():
per = v / len(target) * 100
print('Class=%s, Count=%d, Percentage=%.3f%%' % (k, v, per))
运行该示例总结了类别分布,确认了严重的类别不平衡,多数类别(无癌症)约为 98%,少数类别(癌症)约为 2%。
Class='-1', Count=10923, Percentage=97.675%
Class='1', Count=260, Percentage=2.325%
这是有帮助的,因为如果我们使用分类精确率,那么任何达到低于约 97.7%的精确率的模型都没有这个数据集的技能。
现在我们已经熟悉了数据集,让我们探索如何开发一个神经网络模型。
神经网络学习动力学
我们将使用张量流为数据集开发一个多层感知机(MLP)模型。
我们无法知道什么样的学习超参数的模型架构对这个数据集是好的或最好的,所以我们必须实验并发现什么是好的。
假设数据集很小,小批量可能是个好主意,例如 16 或 32 行。开始时使用亚当版本的随机梯度下降是一个好主意,因为它会自动调整学习速率,并且在大多数数据集上运行良好。
在我们认真评估模型之前,最好回顾学习动态,调整模型架构和学习配置,直到我们有稳定的学习动态,然后看看如何从模型中获得最大收益。
我们可以通过使用简单的数据训练/测试分割和学习曲线的回顾图来做到这一点。这将有助于我们了解自己是学习过度还是学习不足;然后我们可以相应地调整配置。
首先,我们必须确保所有输入变量都是浮点值,并将目标标签编码为整数值 0 和 1。
...
# ensure all data are floating point values
X = X.astype('float32')
# encode strings to integer
y = LabelEncoder().fit_transform(y)
接下来,我们可以将数据集分成输入和输出变量,然后分成 67/33 训练集和测试集。
我们必须确保按类对拆分进行分层,确保训练集和测试集具有与主数据集相同的类标签分布。
...
# split into input and output columns
X, y = df.values[:, :-1], df.values[:, -1]
# split into train and test datasets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.5, stratify=y, random_state=1)
我们可以定义一个最小 MLP 模型。
在这种情况下,我们将使用一个具有 50 个节点的隐藏层和一个输出层(任意选择)。我们将使用隐藏层中的 ReLU 激活函数和“he _ normal”权重初始化,作为一个整体,它们是一个很好的实践。
模型的输出是用于二进制分类的 sigmoid 激活,我们将最小化二进制交叉熵损失。
...
# define model
model = Sequential()
model.add(Dense(50, activation='relu', kernel_initializer='he_normal', input_shape=(n_features,)))
model.add(Dense(1, activation='sigmoid'))
# compile the model
model.compile(optimizer='adam', loss='binary_crossentropy')
我们将使模型适合 300 个训练时期(任意选择),批量大小为 32,因为它是一个中等大小的数据集。
我们正在原始数据上拟合模型,我们认为这可能是一个好主意,但这是一个重要的起点。
...
history = model.fit(X_train, y_train, epochs=300, batch_size=32, verbose=0, validation_data=(X_test,y_test))
在训练结束时,我们将评估模型在测试数据集上的表现,并将表现报告为分类精确率。
...
# predict test set
yhat = model.predict_classes(X_test)
# evaluate predictions
score = accuracy_score(y_test, yhat)
print('Accuracy: %.3f' % score)
最后,我们将绘制训练和测试集上交叉熵损失的学习曲线。
...
# plot learning curves
pyplot.title('Learning Curves')
pyplot.xlabel('Epoch')
pyplot.ylabel('Cross Entropy')
pyplot.plot(history.history['loss'], label='train')
pyplot.plot(history.history['val_loss'], label='val')
pyplot.legend()
pyplot.show()
将所有这些结合起来,下面列出了在癌症存活数据集上评估我们的第一个 MLP 的完整示例。
# fit a simple mlp model on the mammography and review learning curves
from pandas import read_csv
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelEncoder
from sklearn.metrics import accuracy_score
from tensorflow.keras import Sequential
from tensorflow.keras.layers import Dense
from matplotlib import pyplot
# load the dataset
path = 'https://raw.githubusercontent.com/jbrownlee/Datasets/master/mammography.csv'
df = read_csv(path, header=None)
# split into input and output columns
X, y = df.values[:, :-1], df.values[:, -1]
# ensure all data are floating point values
X = X.astype('float32')
# encode strings to integer
y = LabelEncoder().fit_transform(y)
# split into train and test datasets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.5, stratify=y, random_state=1)
# determine the number of input features
n_features = X.shape[1]
# define model
model = Sequential()
model.add(Dense(50, activation='relu', kernel_initializer='he_normal', input_shape=(n_features,)))
model.add(Dense(1, activation='sigmoid'))
# compile the model
model.compile(optimizer='adam', loss='binary_crossentropy')
# fit the model
history = model.fit(X_train, y_train, epochs=300, batch_size=32, verbose=0, validation_data=(X_test,y_test))
# predict test set
yhat = model.predict_classes(X_test)
# evaluate predictions
score = accuracy_score(y_test, yhat)
print('Accuracy: %.3f' % score)
# plot learning curves
pyplot.title('Learning Curves')
pyplot.xlabel('Epoch')
pyplot.ylabel('Cross Entropy')
pyplot.plot(history.history['loss'], label='train')
pyplot.plot(history.history['val_loss'], label='val')
pyplot.legend()
pyplot.show()
运行该示例首先在训练数据集上拟合模型,然后在测试数据集上报告分类精确率。
注:考虑到算法或评估程序的随机性,或数值精确率的差异,您的结果可能会有所不同。考虑运行该示例几次,并比较平均结果。
在这种情况下,我们可以看到该模型比无技能模型表现得更好,假设准确率在大约 97.7%以上,在这种情况下达到大约 98.8%的准确率。
Accuracy: 0.988
然后创建列车和测试集上的损耗线图。
我们可以看到,模型很快在数据集上找到了一个很好的拟合,并且看起来没有过度拟合或拟合不足。
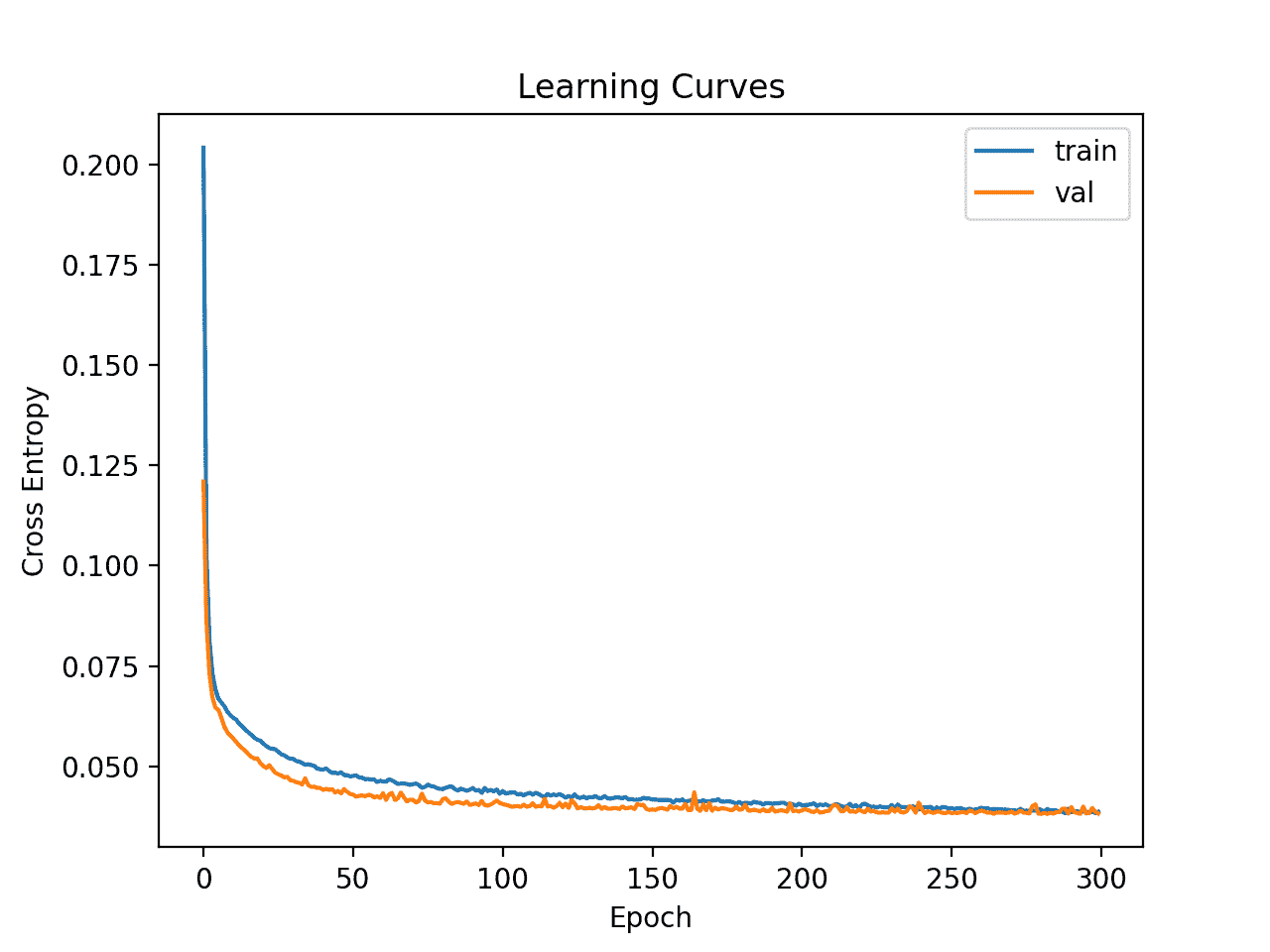
乳腺摄影数据集上简单多层感知机的学习曲线
现在,我们已经对数据集上的简单 MLP 模型的学习动态有了一些了解,我们可以考虑对数据集上的模型表现进行更稳健的评估。
稳健模型评估
k 倍交叉验证程序可以提供更可靠的 MLP 表现估计,尽管它可能非常慢。
这是因为 k 模型必须被拟合和评估。当数据集规模较小时,例如癌症存活数据集,这不是问题。
我们可以使用stratifiedfold类手动枚举每个折叠,拟合模型,对其进行评估,然后在程序结束时报告评估分数的平均值。
...
# prepare cross validation
kfold = KFold(10)
# enumerate splits
scores = list()
for train_ix, test_ix in kfold.split(X, y):
# fit and evaluate the model...
...
...
# summarize all scores
print('Mean Accuracy: %.3f (%.3f)' % (mean(scores), std(scores)))
我们可以使用这个框架,利用我们的基本配置,甚至利用一系列不同的数据准备、模型架构和学习配置,来开发 MLP 模型表现的可靠估计。
重要的是,在使用 k-fold 交叉验证来估计表现之前,我们首先了解了上一节中模型在数据集上的学习动态。如果我们开始直接调整模型,我们可能会得到好的结果,但如果没有,我们可能不知道为什么,例如,模型过度或拟合不足。
如果我们再次对模型进行大的更改,最好返回并确认模型正在适当收敛。
下面列出了评估前一节中的基本 MLP 模型的框架的完整示例。
# k-fold cross-validation of base model for the mammography dataset
from numpy import mean
from numpy import std
from pandas import read_csv
from sklearn.model_selection import StratifiedKFold
from sklearn.preprocessing import LabelEncoder
from sklearn.metrics import accuracy_score
from tensorflow.keras import Sequential
from tensorflow.keras.layers import Dense
from matplotlib import pyplot
# load the dataset
path = 'https://raw.githubusercontent.com/jbrownlee/Datasets/master/mammography.csv'
df = read_csv(path, header=None)
# split into input and output columns
X, y = df.values[:, :-1], df.values[:, -1]
# ensure all data are floating point values
X = X.astype('float32')
# encode strings to integer
y = LabelEncoder().fit_transform(y)
# prepare cross validation
kfold = StratifiedKFold(10, random_state=1)
# enumerate splits
scores = list()
for train_ix, test_ix in kfold.split(X, y):
# split data
X_train, X_test, y_train, y_test = X[train_ix], X[test_ix], y[train_ix], y[test_ix]
# determine the number of input features
n_features = X.shape[1]
# define model
model = Sequential()
model.add(Dense(50, activation='relu', kernel_initializer='he_normal', input_shape=(n_features,)))
model.add(Dense(1, activation='sigmoid'))
# compile the model
model.compile(optimizer='adam', loss='binary_crossentropy')
# fit the model
model.fit(X_train, y_train, epochs=300, batch_size=32, verbose=0)
# predict test set
yhat = model.predict_classes(X_test)
# evaluate predictions
score = accuracy_score(y_test, yhat)
print('>%.3f' % score)
scores.append(score)
# summarize all scores
print('Mean Accuracy: %.3f (%.3f)' % (mean(scores), std(scores)))
运行该示例会报告评估程序每次迭代的模型表现,并在运行结束时报告分类精确率的平均值和标准偏差。
注:考虑到算法或评估程序的随机性,或数值精确率的差异,您的结果可能会有所不同。考虑运行该示例几次,并比较平均结果。
在这种情况下,我们可以看到 MLP 模型获得了大约 98.7%的平均精确率,这与我们在前面部分中的粗略估计非常接近。
这证实了我们的预期,即对于这个数据集,基本模型配置可能比简单模型工作得更好
>0.987
>0.986
>0.989
>0.987
>0.986
>0.988
>0.989
>0.989
>0.983
>0.988
Mean Accuracy: 0.987 (0.002)
接下来,让我们看看如何拟合最终模型并使用它进行预测。
最终模型和做出预测
一旦我们选择了一个模型配置,我们就可以在所有可用的数据上训练一个最终模型,并使用它来对新数据进行预测。
在这种情况下,我们将使用具有脱落和小批量的模型作为最终模型。
我们可以像以前一样准备数据并拟合模型,尽管是在整个数据集上,而不是数据集的训练子集上。
...
# split into input and output columns
X, y = df.values[:, :-1], df.values[:, -1]
# ensure all data are floating point values
X = X.astype('float32')
# encode strings to integer
le = LabelEncoder()
y = le.fit_transform(y)
# determine the number of input features
n_features = X.shape[1]
# define model
model = Sequential()
model.add(Dense(50, activation='relu', kernel_initializer='he_normal', input_shape=(n_features,)))
model.add(Dense(1, activation='sigmoid'))
# compile the model
model.compile(optimizer='adam', loss='binary_crossentropy')
然后,我们可以使用这个模型对新数据进行预测。
首先,我们可以定义一行新数据。
...
# define a row of new data
row = [0.23001961,5.0725783,-0.27606055,0.83244412,-0.37786573,0.4803223]
注意:我从数据集的第一行提取了这一行,预期的标签是“-1”。
然后我们可以做一个预测。
...
# make prediction
yhat = model.predict_classes([row])
然后反转预测上的转换,这样我们就可以使用或解释正确标签中的结果(对于这个数据集,它只是一个整数)。
...
# invert transform to get label for class
yhat = le.inverse_transform(yhat)
在这种情况下,我们将简单地报告预测。
...
# report prediction
print('Predicted: %s' % (yhat[0]))
将所有这些结合起来,下面列出了为乳腺摄影数据集拟合最终模型并使用它对新数据进行预测的完整示例。
# fit a final model and make predictions on new data for the mammography dataset
from pandas import read_csv
from sklearn.preprocessing import LabelEncoder
from sklearn.metrics import accuracy_score
from tensorflow.keras import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras.layers import Dropout
# load the dataset
path = 'https://raw.githubusercontent.com/jbrownlee/Datasets/master/mammography.csv'
df = read_csv(path, header=None)
# split into input and output columns
X, y = df.values[:, :-1], df.values[:, -1]
# ensure all data are floating point values
X = X.astype('float32')
# encode strings to integer
le = LabelEncoder()
y = le.fit_transform(y)
# determine the number of input features
n_features = X.shape[1]
# define model
model = Sequential()
model.add(Dense(50, activation='relu', kernel_initializer='he_normal', input_shape=(n_features,)))
model.add(Dense(1, activation='sigmoid'))
# compile the model
model.compile(optimizer='adam', loss='binary_crossentropy')
# fit the model
model.fit(X, y, epochs=300, batch_size=32, verbose=0)
# define a row of new data
row = [0.23001961,5.0725783,-0.27606055,0.83244412,-0.37786573,0.4803223]
# make prediction
yhat = model.predict_classes([row])
# invert transform to get label for class
yhat = le.inverse_transform(yhat)
# report prediction
print('Predicted: %s' % (yhat[0]))
运行该示例使模型适合整个数据集,并对单行新数据进行预测。
注:考虑到算法或评估程序的随机性,或数值精确率的差异,您的结果可能会有所不同。考虑运行该示例几次,并比较平均结果。
在这种情况下,我们可以看到模型为输入行预测了一个“-1”标签。
Predicted: '-1'
进一步阅读
如果您想更深入地了解这个主题,本节将提供更多资源。
教程
摘要
在本教程中,您发现了如何为伍德的乳腺摄影分类数据集开发多层感知机神经网络模型。
具体来说,您了解到:
- 如何加载和总结伍德的乳腺摄影数据集,并使用结果建议数据准备和模型配置使用。
- 如何探索数据集上简单 MLP 模型的学习动态。
- 如何对模型表现进行稳健的估计,调整模型表现并对新数据进行预测。
你有什么问题吗?
在下面的评论中提问,我会尽力回答。
如何设置 Amazon AWS EC2 GPU 来训练 Keras 深度学习模型(分步)
原文:
machinelearningmastery.com/develop-evaluate-large-deep-learning-models-keras-amazon-web-services/
Keras 是一个 Python 深度学习库,可以轻松方便地访问功能强大的数学库 Theano 和 TensorFlow.
大型深度学习模型需要大量的计算时间才能运行,您可以在 CPU 上运行它们,但可能需要数小时或数天才能获得结果,如果您可以访问远程桌面上的 GPU,则可以大大加快深度学习模型的训练时间。
在本文中,您将了解如何使用 Amazon Web Service(AWS)基础结构访问 GPU 以加速深度学习模型的训练,每小时不到 1 美元,通常便宜很多,您可以在笔记本或工作站上使用这项服务。
让我们开始吧!
- 2016 年 10 月更新:更新了 Keras 1.1.0 的示例。
- 2017 年 3 月更新:更新后使用新的 AMI,Keras 2.0.2 和 TensorFlow 1.0。
- 2002 年 2 月更新:已更新以使用新的"深度学习 AMI"和"p3.2xlarge"。

亚马逊的网络服务
摄影:Andrew Mager ,保留所属权利
教程概述
这个过程非常简单,因为大部分工作已经为我们完成了。
以下是该过程的概述:
- 设置您的 AWS 账户。
- 启动您的 AWS 实例。
- 登录并运行您的代码。
- 关闭您的 AWS 实例。
注意,在 Amazon 上使用虚拟服务器实例需要花钱,临时模型开发的成本很低(例如每小时不到一美元),虽然它不是免费的,但确实非常吸引人。
服务器实例运行于 Linux 平台,虽然您可能不知道如何使用 Linux 或者类 Unix 系统,但我们只是运行我们的 Python 脚本,因此不需要高级技能,所以选用 Linux 平台是可取的行为。
1.设置您的 AWS 账户
您需要在 Amazon Web Services 上拥有一个帐户。
- 1.您可以通过亚马逊网络服务门户创建一个帐户,然后单击“登录到控制台”,从那里,您可以使用现有的亚马逊帐户登录或创建新帐户。
AWS 登录按钮
- 2.您需要提供您的详细信息以及为亚马逊可以支付的有效信用卡,如果您已经是亚马逊客户并且已将您的信用卡存档,那么此过程会快得多。
AWS 登录表单
拥有帐户后,您可以登录 Amazon Web Services 控制台。
您将看到一系列可以访问的不同服务。
2.启动您的 AWS 实例
现在您已拥有 AWS 账户,您可以启动并运行 Keras 的 EC2 虚拟服务器实例。
启动实例就像选择要加载和启动虚拟服务器的映像一样简单,值得庆幸的是,已经有一个亚马逊创建并维护的实例,被称作深度学习 AMI(亚马逊 Linux),这是一个可用镜像,几乎有我们所需要的一切东西,您可以直接运行这个示例。
- 1.如果您尚未登录 AWS 控制台,请登录。

AWS 控制台
- 2.单击 EC2 以启动新的虚拟服务器。
- 3.从右上角的下拉列表中选择“US West Oregon”,这很重要,否则您将无法找到我们计划使用的镜像。
- 4.单击“启动实例”按钮。
- 5.单击“社区 AMI”。 AMI 是亚马逊机器镜像,这是服务器的固有·实例,您可以在新虚拟服务器上进行选择和实例化。
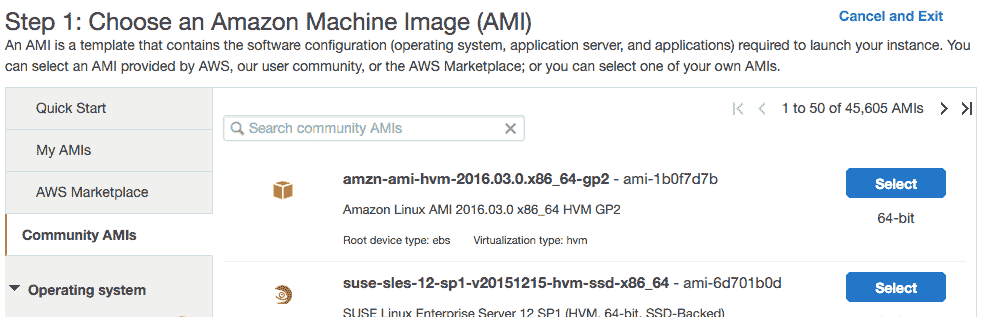
社区 AMI
- 6.在“搜索社区 AMI”搜索框中输入“深度学习 AMI ”,然后按 Enter 键。

深度学习 AMI
- 7.单击“选择”以在搜索结果中选择 AMI。
- 8.现在您需要选择运行映像的硬件,向下滚动并选择“ p3.2xlarge ”硬件(我以前推荐 g2 或 g3 实例和 p2 实例,但 p3 实例更新更快,这包括一个 Tesla V100 GPU,我们可以用它来显着提高我们模型的训练速度,它还包括 8 个 CPU 内核,61GB 内存和 16GB GPU 内存,注意:使用此实例将花费约 3 美元/小时。

p3.2xlarge EC2 实例
- 9.单击“查看并启动”以完成服务器实例的配置。
- 10.单击“启动”按钮。
- 11.选择您的密钥对。
- 如果您之前使用过 EC2,则选择“选择现有密钥对”并从列表中选择密钥对,然后检查“我”确认…“。
- 如果您没有密钥对,请选择“创建新密钥对”选项并输入“密钥对名称”,例如 keras-keypair,并单击“下载密钥对”按钮。
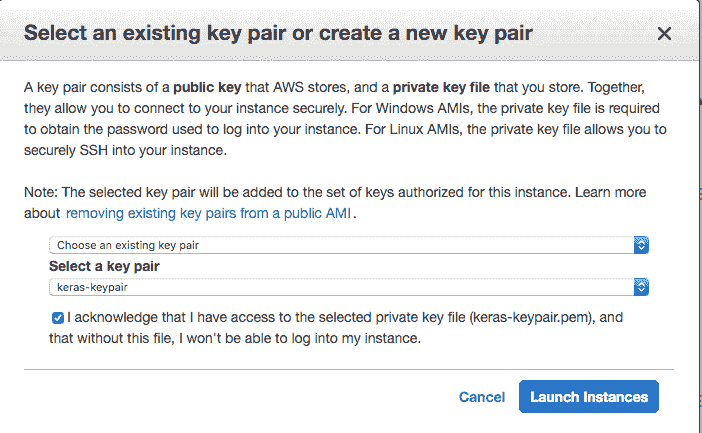
选择您的密钥对
- 12.打开终端并将目录更改为您下载密钥对的位置。
- 13.如果尚未执行此操作,请限制密钥对文件的访问权限,这也是通过 SSH 访问服务器的一部分,示例如下:
cd Downloads
chmod 600 keras-aws-keypair.pem
- 14.单击“启动实例”。如果这是您第一次使用 AWS,亚马逊可能必须验证您的请求,这可能需要长达 2 个小时(通常只需几分钟)。
- 15.可以通过单击“查看实例”以查看实例的状态。
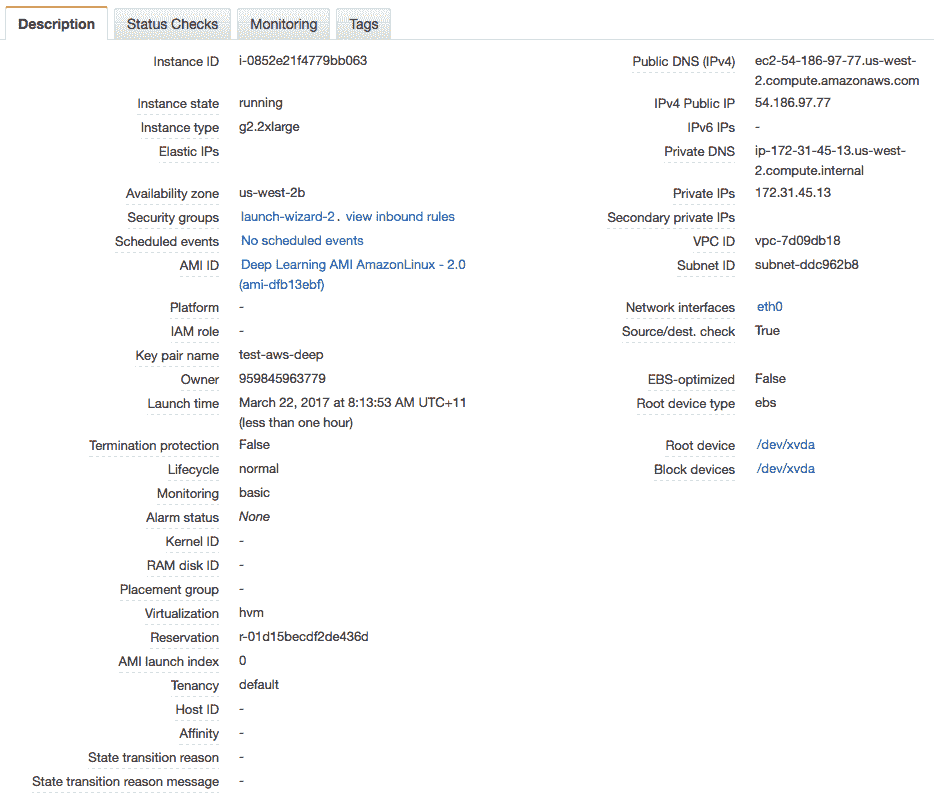
深度学习 AMI 状态
您的服务器现在正在运行,可以登录。
3.登录,配置和运行
现在您已经启动了服务器实例,现在可以登录并开始使用它了。
- 1.如果您还没有,请单击 Amazon EC2 控制台中的“查看实例”。
- 2.将“公共 IP”(在“描述”中的屏幕底部)复制到剪贴板。在此示例中,我的 IP 地址是 54.186.97.77。 请勿使用此 IP 地址,您的 IP 地址会有所不同。
- 3.打开终端并将目录更改为您下载密钥对的位置。使用 SSH 登录您的服务器,例如:
ssh -i keras-aws-keypair.pem ec2-user@54.186.97.77
- 4.出现提示时,键入
yes并按 Enter 键。
您现在已登录到您的服务器。
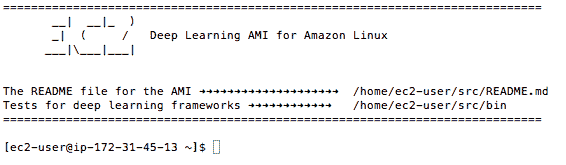
通过终端登录深度学习 AMI
该实例将询问您希望使用的 Python 环境。我建议使用:
- TensorFlow(+ Keras2)与 Python3(CUDA 9.0 和英特尔 MKL-DNN)
您可以键入以下内容来激活此虚拟环境:
source activate tensorflow_p36
这只需要一分钟。
您现在可以开始训练深度学习神经网络模型了。
想要尝试新实例,请参阅本教程:
4.关闭您的 AWS 实例
完成工作后,您必须关闭实例。
请记住,您需要按照使用该实例的时间收费,它很便宜,但如果你不使用它,请关闭该实例。
- 1.在终端注销您的实例,例如您可以输入:
exit
- 2.使用 Web 浏览器登录 AWS 账户。
- 3.单击 EC2。
- 4.单击左侧菜单中的“Instances”。
查看运行实例列表
- 5.从列表中选择正在运行的实例(如果您只有一个正在运行的实例,则可能已选中该实例)。

选择您正在运行的 AWS 实例
- 6.单击“操作”按钮并选择“实例状态”,然后选择“终止”。确认您要终止正在运行的实例。
实例可能需要几秒钟才能关闭并从实例列表中删除。
在 AWS 上使用 Keras 的提示和技巧
以下是在 AWS 实例上充分利用 Keras 的一些提示和技巧。
- 设计一套预先运行的实验: 实验可能需要很长时间才能运行,而您需要为使用时间付费,花时间设计一批在可以在 AWS 上运行的实验,将每个文件放在一个单独的文件中,并依次从另一个脚本调用它们,这样可以在一个长期的运行过程(也许是一个晚上)中解决您的多个问题。
- 运行脚本作为后台进程:这样您就可以在实验运行时关闭终端并关闭计算机。
您可以轻松地执行以下操作:
nohup /path/to/script >/path/to/script.log 2>&1 < /dev/null &
然后,您可以稍后在 script.log 文件中检查状态和结果。 了解有关 nohup 的更多信息。
- 在实验结束时始终关闭您的实例:如果您不想对亚马逊高额的账单感到惊讶,请在实验结束时关闭您的实例。
- 尝试使用更便宜但不太可靠的选项:亚马逊可以以更便宜的价格在硬件上出售未使用的时间,但代价可能是您的实例会在任意时刻被关闭,如果您正在学习或您的实验并不重要,这可能是您的理想选择,您可以从 EC2 Web 控制台左侧菜单中的“竞价型实例”选项选择竞价型实例。
有关在 AWS 上使用的命令行重新复制的更多帮助,请参阅帖子:
更多有关 AWS 深度学习的资源
以下是有关 AWS 的更多信息以及在云中构建深度学习的资源列表。
- 亚马逊弹性计算云(EC2)(如果您是所有这方面的新手)
- 亚马逊机器图像(AMI)简介
- AMI 市场上的深度学习 AMI(亚马逊 Linux)。
- P3 EC2 实例
摘要
在这篇文章中,您了解了如何使用 Amazon Web Service 上的 GPU 在 Keras 中开发和评估您的大型深度学习模型,你学习到了:
- 使用 Elastic Compute Cloud 的 Amazon Web Services 提供了一种在 GPU 硬件上运行大型深度学习模型的经济实惠方式。
- 如何为深度学习实验设置和启动 EC2 服务器。
- 如何更新服务器上的 Keras 版本并确认系统正常运行。
- 如何在 AWS 实例上批量运行 Keras 实验作为后台任务。
您对在 AWS 或此帖子上运行模型有任何疑问吗?在评论中提出您的问题,我会尽力回答。
神经网络中批量和周期之间的区别是什么?
原文:
machinelearningmastery.com/difference-between-a-batch-and-an-epoch/
随机梯度下降是一种学习算法,具有许多超参数。
两个经常让初学者感到困惑的超参数是批次和周期次数。它们都是整数值,似乎做同样的事情。
在这篇文章中,您将了解随机梯度下降中批次和周期次数之间的差异。
阅读这篇文章后,你会知道:
- 随机梯度下降是一种周期学习算法,它使用训练数据集来更新模型。
- 批量尺寸是梯度下降的超参数,用来控制在模型的内部参数更新之前训练样本的数量。
- 周期次数是梯度下降的超参数,用来控制完成对训练数据集进行完整训练的循环次数。
让我们开始吧。

神经网络中批量和周期之间的区别是什么?
Graham Cook 的照片,保留一些权利。
概述
这篇文章分为五个部分;他们是:
- 随机梯度下降
- 什么是样品?
- 什么是批次?
- 什么是周期次数?
- Batch 和 Epoch 有什么区别?
随机梯度下降
随机梯度下降(Stochastic Gradient Descent,简称 SGD)是一种用于训练机器学习算法的优化算法,最常使用在深度学习中的人工神经网络。
该算法的作用是找到一组内部模型参数,这些参数的运用使得模型的衡量指标很优秀,例如对数损失或均方误差。
优化是一种搜索过程,您可以将此搜索视为学习。优化算法称为“_ 梯度下降 ”,其中“ 梯度 _”是指误差梯度或误差斜率的计算,“下降”是指沿着该斜率向下移动朝着某种最低程度的错误。
该算法是周期的。这意味着搜索过程发生在多个不连续的步骤上,每个步骤都希望略微改进模型参数。
每个步骤都涉及将模型与当前内部参数集一起使用,以对某些样本做出预测,将预测结果与实际的进行比较,计算误差,并使用误差更新内部模型参数。
该更新过程对于不同的算法是不同的,但是在人工神经网络的情况下,使用反向传播更新算法。
在我们深入研究批次和时代之前,让我们来看看样本的含义。
了解有关梯度下降的更多信息:
什么是样品?
样本是单行数据。
它包含输入算法的输入和用于与预测进行比较并计算错误的输出。
训练数据集由许多行数据组成,例如,很多样品。样本也可以称为实例,观测值,输入向量或特征向量。
现在我们知道了样本是什么,再让我们定义一个批次。
什么是批次?
批量大小是一个超参数,用于定义在更新内部模型参数之前要处理的样本数。
将批量视为对一个或多个样本进行周期并做出预测的循环。在批量结束时,将预测与预期输出变量进行比较,并计算误差。从该错误中,更新算法用于改进模型,例如,沿误差梯度向下移动。
训练数据集可以分为一个或多个批次。
当所有训练样本用于创建一个批次时,学习算法称为批量梯度下降。当批量是一个样本的大小时,学习算法称为随机梯度下降。当批量大小超过一个样本且小于训练数据集的大小时,学习算法称为小批量梯度下降。
- 批量梯度下降。批量大小=训练集的大小
- 随机梯度下降。批量大小= 1
- 小批量梯度下降 。 1&lt;批量大小&lt;训练集的大小
在小批量梯度下降的情况下,常用的批量大小包括 32,64 和 128 个样本。您可能会在文献和教程中看到这些值经常在模型中使用。
如果数据集不能按批量大小均匀分配怎么办?
在训练模型时,这可能并且确实经常发生。它只是意味着最终批次的样品数量少于其他批次。
或者,您可以从数据集中删除一些样本或更改批量大小,以便数据集中的样本数按批次大小均匀划分。
有关这些梯度下降变化之间差异的更多信息,请参阅帖子:
批量涉及使用样本更新模型;接下来,让我们来看一个周期周期。
什么是周期周期?
周期数是一个超参数,它定义了学习算法在整个训练数据集中的工作次数。
一个完整的周期意味着训练数据集中的每个样本都有机会更新内部模型参数。一个周期由一个或多个批次组成。例如,如上所述,具有一批的时期称为批量梯度下降学习算法。
您可以考虑在进行的周期周期个 for 循环,每次循环中都会遍历训练集样本。在这个 for 循环中是另一个嵌套的 for 循环,它遍历每批样本,其中一个批次具有指定的“批量大小”样本数。
周期的数量传统上很大,通常是数百或数千,允许学习算法运行直到模型的误差被充分最小化。您可能会看到文献和教程设置为 10,100,500,1000 和更大的时期数量的示例。
通常创建线图:在 x 轴上显示的是周期周期数,在 y 轴上显示的是模型的误差或评估能力。这些图有时称为学习曲线。这些图可以帮助诊断模型是否已经过度学习,学习不足或是否适合训练数据集。
有关使用 LSTM 网络学习曲线的诊断信息,请参阅帖子:
如果仍然不清楚,让我们看看批次和时代之间的差异。
Batch 和 Epoch 有什么区别?
批量大小是在更新模型之前处理的多个样本的个数。
周期次数是对训练数据集的进行完整训练的循环次数。
批量的大小必须大于或等于 1 且小于或等于训练数据集中的样本数。
周期次数可以设置为 1 和无穷大之间的整数值。您可以根据需要设定运行算法的次数,甚至可以使用除固定数量的周期之外的其他标准来停止算法,例如模型错误随时间的变化(或缺少更改)。
它们都是整数值,并且它们都是学习算法的超参数,例如,学习过程的参数,而不是学习过程中找到的内部模型参数。
您必须为学习算法指定批次大小和周期数。
如何配置这些参数没有固定的规则。您必须尝试不同的值,看看哪种方法最适合您的问题。
工作示例
最后,让我们用一个小例子来具体化这些概念。
假设您有一个包含 200 个样本(数据行)的数据集,并且您选择的批量大小为 5 和 1,000 次周期。
这意味着数据集将分为 40 个批次,每个批次有 5 个样本。对每批样本训练后,模型权重将更新。
这也意味着一次周期将涉及 40 个批次或 40 个模型更新。
1000 次周期意味着模型将传递整个数据集 1,000 次。则在整个训练过程中总共有 40,000 批次。
进一步阅读
如果您希望深入了解,本节将提供有关该主题的更多资源。
总结
在这篇文章中,您发现了随机梯度下降中批次和周期次数之间的差异。
具体来说,你学到了:
- 随机梯度下降是一种周期学习算法,它使用训练数据集来更新模型。
- 批量大小是梯度下降的超参数,在模型的内部参数更新之前控制训练样本的数量。
- 时期数是梯度下降的超参数表示训练整个数据集的次数。
你有任何问题吗?
在下面的评论中提出您的问题,我会尽力回答。
反向传播和随机梯度下降的区别
最后更新于 2021 年 2 月 1 日
对于初学者来说,关于使用什么算法来训练深度学习神经网络模型有很多困惑。
经常听到神经网络使用误差反向传播算法或随机梯度下降算法学习有时,这些算法中的任何一种都被用作神经网络如何适合训练数据集的简写,尽管在许多情况下,对于这些算法是什么、它们如何相关以及它们如何协同工作有着深刻的困惑。
本教程旨在明确随机梯度下降和反向传播算法在网络间训练中的作用。
在本教程中,您将发现随机梯度下降和反向传播算法之间的区别。
完成本教程后,您将知道:
- 随机梯度下降是一种优化算法,用于最小化预测模型相对于训练数据集的损失。
- 反向传播是一种自动微分算法,用于计算神经网络图结构中权重的梯度。
- 随机梯度下降和误差算法的反向传播一起用于训练神经网络模型。
我们开始吧。

反向传播和随机梯度下降的区别
图片由克里斯蒂安·科林斯提供,保留部分权利。
教程概述
本教程分为三个部分;它们是:
- 随机梯度下降
- 反向传播算法
- 带反向传播的随机梯度下降
随机梯度下降
梯度下降是一种优化算法,它为目标函数寻找一组输入变量,得到目标函数的最小值,称为函数的最小值。
顾名思义,梯度下降涉及计算目标函数的梯度。
你可能还记得微积分中,函数的一阶导数计算函数在给定点的斜率或曲率。从左向右读,正导数表示目标函数是上坡的,负导数表示目标函数是下坡的。
- 导数:目标函数相对于该函数特定输入值的斜率或曲率。
如果目标函数接受多个输入变量,它们可以一起作为变量向量。处理向量和矩阵被称为线性代数,用线性代数的结构做微积分被称为矩阵微积分或向量微积分。在向量微积分中,一阶导数(偏导数)的向量一般称为目标函数的梯度。
- 梯度:目标函数相对于输入变量的偏导数向量。
梯度下降算法需要计算目标函数相对于输入值的特定值的梯度。梯度指向上坡,因此每个输入变量的负梯度跟随下坡,以产生每个变量的新值,这导致目标函数的较低评估。
步长用于缩放梯度,并控制每个输入变量相对于梯度的变化程度。
- 步长:学习率或α,一个超参数,用于控制每个输入变量相对于梯度的变化量。
重复该过程,直到找到目标函数的最小值,评估出最大数量的候选解,或者某个其他停止条件。
梯度下降可适用于最小化训练数据集中预测模型的损失函数,例如分类或回归模型。这种适应被称为随机梯度下降。
- 随机梯度下降:梯度下降优化算法的扩展,用于最小化训练数据集上预测模型的损失函数。
目标函数作为数据集上的损失或误差函数,如回归的均方误差或分类的交叉熵。模型的参数被作为目标函数的输入变量。
- 损失功能:正在最小化的目标功能。
- 模型参数:正在优化的损耗函数的输入参数。
由于目标函数相对于输入变量的梯度是有噪声的(例如概率近似),因此该算法被称为“T0”随机。这意味着梯度的评估可能具有统计噪声,该噪声可能会模糊真实的潜在梯度信号,这是由于训练数据集中的稀疏性和噪声造成的。
随机梯度下降的观点是梯度是一种期望。可以使用一小组样本来近似估计期望值。
—第 151 页,深度学习,2016。
随机梯度下降可以用于训练(优化)许多不同的模型类型,如线性回归和逻辑回归,尽管通常已经发现了更有效的优化算法,并且应该被使用。
随机梯度下降(SGD)及其变体可能是机器学习,特别是深度学习中最常用的优化算法。
—第 294 页,深度学习,2016。
随机梯度下降是发现的用于训练人工神经网络的最有效算法,其中权重是模型参数,目标损失函数是在整个训练数据集的一个子集(批次)上平均的预测误差。
几乎所有的深度学习都是由一个非常重要的算法提供动力的:随机梯度下降或 SGD。
—第 151 页,深度学习,2016。
随机梯度下降有许多流行的扩展,旨在改进优化过程(在更少的迭代中损失相同或更好),例如动量、均方根传播(RMSProp)和自适应运动估计(Adam) 。
当使用随机梯度下降来训练神经网络时,一个挑战是如何计算网络中隐藏层中节点的梯度,例如距离模型输出层一步或多步的节点。
这需要微积分中一种称为链式规则的特定技术,以及一种实现链式规则的有效算法,该算法可用于计算网络中任何参数的梯度。这种算法被称为反向传播。
反向传播算法
反向传播,也称为“反向传播,或简称为“反向传播,是一种计算损失函数相对于模型变量的梯度的算法。
- 反向传播:计算损失函数相对于模型变量的梯度的算法。
你可能会从微积分中回想起,一个输入变量的特定值的函数的一阶导数是该输入的函数的变化率或曲率。当我们有一个函数的多个输入变量时,它们形成一个向量,一阶导数(偏导数)的向量称为梯度(即向量微积分)。
- 梯度:特定输入值相对于目标函数的偏导数向量。
在训练神经网络模型时使用反向传播来计算网络模型中每个权重的梯度。然后,优化算法使用梯度来更新模型权重。
该算法被明确开发用于计算图结构中变量的梯度,从图的输出朝图的输入反向工作,传播用于计算每个变量梯度的预测输出中的误差。
反向传播算法,通常简称为反向传播,允许来自成本的信息通过网络反向流动,以计算梯度。
—第 204 页,深度学习,2016。
损失函数表示模型或误差函数的误差,权重是函数的变量,因此误差函数相对于权重的梯度被称为误差梯度。
- 误差函数:训练神经网络时损失函数最小。
- 权重:网络参数作为损耗函数的输入值。
- 误差梯度:损耗函数相对于参数的一阶导数。
这给算法起了个名字“反向传播”,或者有时是“误差反向传播”或者是“误差反向传播”
- 误差反向传播:评论如何从输出层开始通过网络图递归反向计算梯度。
该算法涉及微积分中链规则的递归应用(不同于概率中的链规则),该规则用于在已知导数的母函数导数的情况下计算子函数的导数。
微积分的链式法则用来计算由导数已知的其他函数组成的函数的导数。反向传播是一种计算链规则的算法,具有高效的特定操作顺序。
—第 205 页,深度学习,2016。
- 链式法则:利用导数已知的相关函数计算函数导数的微积分公式。
还有其他算法来计算链规则,但是反向传播算法是使用神经网络构造的特定图的有效算法。
公平地说,反向传播算法是自动微分算法的一种,属于一类叫做反向累加的微分技术。
这里描述的反向传播算法只是自动微分的一种方法。这是一种更广泛的称为反向模式积累技术的特殊情况。
—第 222 页,深度学习,2016。
虽然反向传播是为了训练神经网络模型而发展起来的,但无论是特定的反向传播算法,还是其高效实现的链式规则公式,都可以更普遍地用于计算函数的导数。
此外,反向传播经常被误解为特定于多层神经网络,但原则上它可以计算任何函数的导数…
—第 204 页,深度学习,2016。
带反向传播的随机梯度下降
随机梯度下降是一种优化算法,可用于训练神经网络模型。
随机梯度下降算法要求为模型中的每个变量计算梯度,以便可以计算变量的新值。
反向传播是一种自动微分算法,可用于计算神经网络中参数的梯度。
反向传播算法和随机梯度下降算法可以一起用于训练神经网络。我们可以称之为“反向传播的随机梯度下降”
- 带反向传播的随机梯度下降:参考优化算法和梯度计算算法,对用于训练神经网络的一般算法的更完整描述。
从业者经常说他们使用反向传播来训练他们的模型。从技术上讲,这是不正确的。即使作为一个空头,这也是不正确的。反向传播不是优化算法,不能用于训练模型。
反向传播这个术语经常被误解为多层神经网络的整个学习算法。实际上,反向传播仅指计算梯度的方法,而另一种算法,如随机梯度下降,用于使用该梯度执行学习。
—第 204 页,深度学习,2016。
公平地说,神经网络是使用随机梯度下降作为速记来训练或学习的,因为假设反向传播算法被用来计算梯度作为优化过程的一部分。
也就是说,可以使用不同的算法来优化神经网络的参数,例如不需要梯度的遗传算法。如果使用随机梯度下降优化算法,可以使用不同的算法来计算损失函数相对于模型参数的梯度,例如实现链式规则的替代算法。
然而,带反向传播的“*随机梯度下降”*组合被广泛使用,因为它是迄今为止为拟合神经网络模型而开发的最有效的通用方法。
进一步阅读
如果您想更深入地了解这个主题,本节将提供更多资源。
书
- 深度学习,2016 年。
- 用于模式识别的神经网络,1995。
- 模式识别与机器学习,2006。
文章
摘要
在本教程中,您发现了随机梯度下降和反向传播算法之间的区别。
具体来说,您了解到:
- 随机梯度下降是一种优化算法,用于最小化预测模型相对于训练数据集的损失。
- 反向传播是一种自动微分算法,用于计算神经网络图结构中权重的梯度。
- 随机梯度下降和误差算法的反向传播一起用于训练神经网络模型。
你有什么问题吗?
在下面的评论中提问,我会尽力回答。
在 Keras 中展示深度学习模型训练历史
原文:
machinelearningmastery.com/display-deep-learning-model-training-history-in-keras/
您可以通过观察他们在训练期间随时间的表现来学习很多关于神经网络和深度学习模型的知识。
Keras 是一个功能强大的 Python 库,它提供了一个简洁的交互方式用来创建深度学习模型,并包含更高技术的 TensorFlow 和 Theano 后端。
在本文中,您将了解如何在使用 Keras 进行 Python 训练期间查看和可视化深度学习模型的表现表现。
让我们开始吧。
- **2017 年 3 月更新:**更新了 Keras 2.0.2,TensorFlow 1.0.1 和 Theano 0.9.0 的示例。
- 更新 March / 2018 :添加了备用链接以下载数据集,因为原始图像已被删除。

照片由 Gordon Robertson 拍摄,并保留所属权利。
Keras 中的访问模型训练历史
Keras 提供了在训练深度学习模型时注册回调的功能。
训练所有深度学习模型时注册的默认回调之一是历史回调,它记录每个迭代期间的训练指标,这包括损失和精确性(对于分类问题)以及验证数据集的损失和准确率(如果已设置)。
历史对象从调用返回到用于训练模型的fit()函数返回,度量标准存储在返回对象的历史成员中的字典中。
例如,您可以在训练模型后使用以下代码段列出历史记录对象中收集的指标:
# 列出历史对象的所有数据
print(history.history.keys())
例如,对于使用验证数据集训练分类问题的模型,这可能会产生以下列表:
['acc', 'loss', 'val_acc', 'val_loss']
我们可以使用历史对象中收集的数据来创建绘图。
这些图可以提供有关模型训练的有用信息的指示,例如:
- 整个迭代期间的的收敛速度(曲线坡度)。
- 模型是否已经收敛(平缓的曲线)。
- 模型是否可能过度学习训练数据(验证集曲线的拐点)。
等等。
可视化 Keras 中的模型训练历史
我们可以从收集的历史数据中创建图形。
在下面的例子中,我们创建了一个小型网络来模拟皮马印第安人糖尿病二分类问题。这是一个可从 UCI 机器学习库获得的小型数据集,您可以下载数据集并将其保存为当前工作目录中的 pima-indians-diabetes.csv (更新:从此处下载)。
该示例收集从训练模型返回的历史记录并创建两个图表:
- 训练时期训练和验证数据集的准确率图。
- 训练和验证数据集在训练时期的损失图。
# 可视化训练历史
from keras.models import Sequential
from keras.layers import Dense
import matplotlib.pyplot as plt
import numpy
# 固定随机种子再现性
seed = 7
numpy.random.seed(seed)
# 加载数据集
dataset = numpy.loadtxt("pima-indians-diabetes.csv", delimiter=",")
# 将数据集划分为输入变量和输出变量
X = dataset[:,0:8]
Y = dataset[:,8]
# 创建模型
model = Sequential()
model.add(Dense(12, input_dim=8, kernel_initializer='uniform', activation='relu'))
model.add(Dense(8, kernel_initializer='uniform', activation='relu'))
model.add(Dense(1, kernel_initializer='uniform', activation='sigmoid'))
# 编译模型
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
# 拟合模型
history = model.fit(X, Y, validation_split=0.33, epochs=150, batch_size=10, verbose=0)
# 列出所有的训练历史数据
print(history.history.keys())
# 总结精确度历史
plt.plot(history.history['acc'])
plt.plot(history.history['val_acc'])
plt.title('model accuracy')
plt.ylabel('accuracy')
plt.xlabel('epoch')
plt.legend(['train', 'test'], loc='upper left')
plt.show()
# 总结损失历史
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.title('model loss')
plt.ylabel('loss')
plt.xlabel('epoch')
plt.legend(['train', 'test'], loc='upper left')
plt.show()
如下图所示,验证数据集的历史记录按照模型的测试数据集的惯例被标记为测试数据。
从精度图中我们可以看到,由于两个数据集的精度趋势在过去几个训练迭代中仍在上升,因此模型可能可以受到更多的训练,我们还可以看到,两个数据集可比较的技巧,显示了模型尚未过度学习训练数据集。
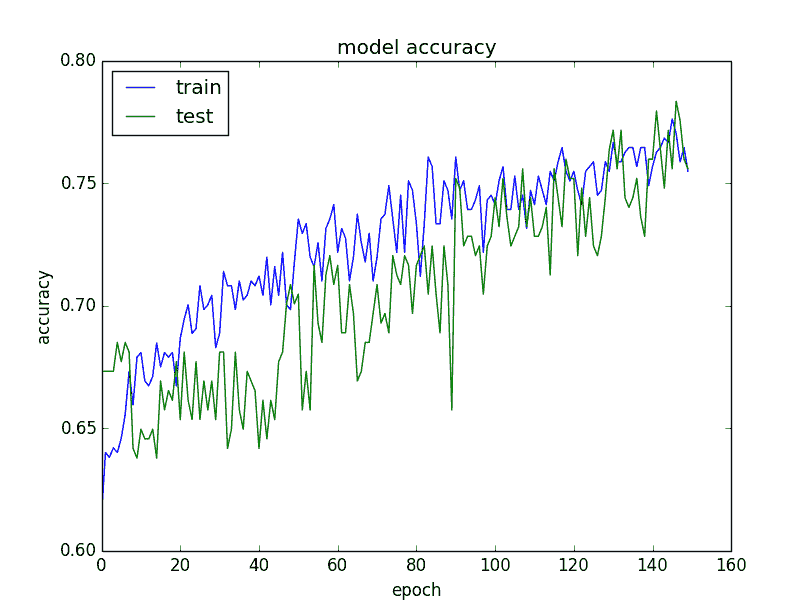
图:训练和验证数据集的模型准确率图
从损失图中我们可以看到,模型在训练和验证数据集(标记测试)上具有可比较的表现,如果这些相互平行图开始一较为一致的分散,这可能是一个模型过早停止训练的信号。

图:关于训练和验证数据集的模型损失图
摘要
在这篇文章中,您了解了了在深度学习模型训练过程中收集和检查指标的重要性。
您了解了 Keras 中的历史回调以及它是如何从调用fit()函数返回以训练模型的,您学习了如何根据训练期间收集的历史数据创建绘图。
您对模型训练历史或这篇文章有任何疑问吗?在评论中提出您的问题,我会尽力回答。
Keras 深度学习模型中的丢弃正则化
原文:
machinelearningmastery.com/dropout-regularization-deep-learning-models-keras/
神经网络和深度学习模型的简单而强大的正则化技术是 dropout。
在这篇文章中,您将了解 dropout 正则化技术以及如何将其应用于使用 Keras 用 Python 编写的模型中。
阅读这篇文章后你会知道:
- dropout 正则化技术原理。
- 如何在输入层上使用 dropout。
- 如何在隐藏层上使用 dropout。
- 如何针对具体问题对 dropout 调优
让我们开始吧。
- 2016 年 10 月更新:更新了 Keras 1.1.0,TensorFlow 0.10.0 和 scikit-learn v0.18 的示例。
- 2017 年 3 月更新:更新了 Keras 2.0.2,TensorFlow 1.0.1 和 Theano 0.9.0 的示例。

使用 Keras 的深度学习模型中的 dropout 正规化
照片由 Trekking Rinjani ,保留一些权利。
神经网络的 dropout 正则化
Dropout 是 Srivastava 等人提出的神经网络模型的正则化技术。在他们的 2014 年论文dropout:一种防止神经网络过拟合的简单方法(下载 PDF )。
dropout 是一种在训练过程中忽略随机选择的神经元的技术。这些神经元被随机“dropout“,这意味着它们对激活下一层神经元的贡献在正向传递时暂时消除,并且在反向传递时任何权重更新也不会应用于这些神经元。
当神经网络学习时,网络中的神经元的权重将进行调整重置。神经元的权重针对某些特征进行调优,具有一些特殊化。周围的神经元则会依赖于这种特殊化,如果过于特殊化,模型会因为对训练数据过拟合而变得脆弱不堪。神经元在训练过程中的这种依赖于上下文的现象被称为复杂的协同适应(complex co-adaptations)。
你可以想象到如果神经元在训练过程中被随机丢弃,那么其他神经元因缺失神经元不得不介入并替代缺失神经元的那部分表征,为预测结果提供信息。人们认为这样网络模型可以学到多种相互独立的内部表征。
其结果是网络对神经元的特定权重变得不那么敏感。这反过来使得网络能够更好地泛化,减少了过拟合训练数据的可能性。
Keras 的 dropout 规范化
通过以每轮权重更新时的给定概率(例如 20%)随机选择要丢弃的节点、。这就是在 Keras 实现 Dropout 的方式。 Dropout 仅在模型训练期间使用,在评估模型的表现时不使用。
接下来,我们将探讨在 Keras 中使用 Dropout 的几种不同方法。
这些示例将使用 Sonar 数据集。这是一个二分类问题,其目标是利用声纳打印正确识别岩石和模拟地雷。它是神经网络的一个很好的测试数据集,因为所有输入值都是数字的并且具有相同的量纲。
数据集可以是从 UCI 机器学习库下载的。您可以将声纳数据集放在当前工作目录中,文件名为 sonar.csv。
我们将使用带有 10 折交叉验证的 scikit-learn 来评估模型的质量,以便更好地梳理结果中的差异。
有 60 个输入值和一个输出值,输入值在用于网络之前已归一化。基准神经网络模型具有两个隐藏层,第一个具有 60 个单元,第二个具有 30 个。随机梯度下降用于训练具有相对低的学习率和冲量的模型。
下面列出了完整的基线模型。
# Baseline Model on the Sonar Dataset
import numpy
from pandas import read_csv
from keras.models import Sequential
from keras.layers import Dense
from keras.layers import Dropout
from keras.wrappers.scikit_learn import KerasClassifier
from keras.constraints import maxnorm
from keras.optimizers import SGD
from sklearn.model_selection import cross_val_score
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import StratifiedKFold
from sklearn.preprocessing import StandardScaler
from sklearn.pipeline import Pipeline
# fix random seed for reproducibility
seed = 7
numpy.random.seed(seed)
# load dataset
dataframe = read_csv("sonar.csv", header=None)
dataset = dataframe.values
# split into input (X) and output (Y) variables
X = dataset[:,0:60].astype(float)
Y = dataset[:,60]
# encode class values as integers
encoder = LabelEncoder()
encoder.fit(Y)
encoded_Y = encoder.transform(Y)
# baseline
def create_baseline():
# create model
model = Sequential()
model.add(Dense(60, input_dim=60, kernel_initializer='normal', activation='relu'))
model.add(Dense(30, kernel_initializer='normal', activation='relu'))
model.add(Dense(1, kernel_initializer='normal', activation='sigmoid'))
# Compile model
sgd = SGD(lr=0.01, momentum=0.8, decay=0.0, nesterov=False)
model.compile(loss='binary_crossentropy', optimizer=sgd, metrics=['accuracy'])
return model
numpy.random.seed(seed)
estimators = []
estimators.append(('standardize', StandardScaler()))
estimators.append(('mlp', KerasClassifier(build_fn=create_baseline, epochs=300, batch_size=16, verbose=0)))
pipeline = Pipeline(estimators)
kfold = StratifiedKFold(n_splits=10, shuffle=True, random_state=seed)
results = cross_val_score(pipeline, X, encoded_Y, cv=kfold)
print("Baseline: %.2f%% (%.2f%%)" % (results.mean()*100, results.std()*100))
运行该示例可生成 分类准确度约为 86%。
Baseline: 86.04% (4.58%)
在可见层上使用 Dropout
Dropout 可以应用于称为可见层的输入神经元。
在下面的示例中,我们在输入(或可见层)和第一个隐藏层之间添加一个新的 Dropout 层。dropout 率设置为 20%,这意味着每个更新周期中将随机丢弃五分之一输入。
此外,正如 Dropout 那篇论文中所建议的那样,对每个隐藏层的权重施加约束,确保权重的最大范数不超过值 3.这可以通过在构造模型层时设置 kernel_constraint 参数来完成。
学习率提高了一个数量级,冲量增加到 0.9。 这也是 Dropout 论文中推荐的做法。
继续上面的基准示例,下面的代码使用输入层 dropout 的网络模型。
# dropout in the input layer with weight constraint
def create_model():
# create model
model = Sequential()
model.add(Dropout(0.2, input_shape=(60,)))
model.add(Dense(60, kernel_initializer='normal', activation='relu', kernel_constraint=maxnorm(3)))
model.add(Dense(30, kernel_initializer='normal', activation='relu', kernel_constraint=maxnorm(3)))
model.add(Dense(1, kernel_initializer='normal', activation='sigmoid'))
# Compile model
sgd = SGD(lr=0.1, momentum=0.9, decay=0.0, nesterov=False)
model.compile(loss='binary_crossentropy', optimizer=sgd, metrics=['accuracy'])
return model
numpy.random.seed(seed)
estimators = []
estimators.append(('standardize', StandardScaler()))
estimators.append(('mlp', KerasClassifier(build_fn=create_model, epochs=300, batch_size=16, verbose=0)))
pipeline = Pipeline(estimators)
kfold = StratifiedKFold(n_splits=10, shuffle=True, random_state=seed)
results = cross_val_score(pipeline, X, encoded_Y, cv=kfold)
print("Visible: %.2f%% (%.2f%%)" % (results.mean()*100, results.std()*100))
运行该示例在单次测试运行中分类精度小幅下降。
Visible: 83.52% (7.68%)
在隐藏层上使用 Dropout
Dropout 可以应用于网络模型内的隐藏层节点。
在下面的示例中,Dropout 应用于两个隐藏层之间以及最后一个隐藏层和输出层之间。再次使用 20%的 dropout 率,并且对这些层进行权重约束。
# dropout in hidden layers with weight constraint
def create_model():
# create model
model = Sequential()
model.add(Dense(60, input_dim=60, kernel_initializer='normal', activation='relu', kernel_constraint=maxnorm(3)))
model.add(Dropout(0.2))
model.add(Dense(30, kernel_initializer='normal', activation='relu', kernel_constraint=maxnorm(3)))
model.add(Dropout(0.2))
model.add(Dense(1, kernel_initializer='normal', activation='sigmoid'))
# Compile model
sgd = SGD(lr=0.1, momentum=0.9, decay=0.0, nesterov=False)
model.compile(loss='binary_crossentropy', optimizer=sgd, metrics=['accuracy'])
return model
numpy.random.seed(seed)
estimators = []
estimators.append(('standardize', StandardScaler()))
estimators.append(('mlp', KerasClassifier(build_fn=create_model, epochs=300, batch_size=16, verbose=0)))
pipeline = Pipeline(estimators)
kfold = StratifiedKFold(n_splits=10, shuffle=True, random_state=seed)
results = cross_val_score(pipeline, X, encoded_Y, cv=kfold)
print("Hidden: %.2f%% (%.2f%%)" % (results.mean()*100, results.std()*100))
我们可以看到,针对此问题以及所选模型配置参数,在隐藏层中使用 dropout 并未提升模型效果。事实上,表现比基准差。
可能需要更多的训练迭代次数或者需要进一步调整学习率。
Hidden: 83.59% (7.31%)
使用 Dropout 的技巧
关于 Dropout 的原始论文提供了一套标准机器学习问题的实践性结论。因此在运用 dropout 时,会带来很多帮助。
- 通常,使用 20%-50%神经元的小 dropout 值,20%可作为良好的起点。比例太低具有最小的影响比列太高会导致模型的欠学习。
- 使用更大的网络。当在较大的网络上使用 dropout 时,模型可能会获得更好的表现,模型有更多的机会学习到多种独立的表征。
- 在输入层(可见层)和隐藏层都使用 dropout。在网络的每一层应用 dropout 已被证明具有良好的结果。
- 增加学习率和冲量。将学习率提高 10 到 100 倍,并使用 0.9 或 0.99 的高冲量值。
- 限制网络模型权重的大小。较大的学习率可能导致非常大的权重值。对网络的权重值做最大范数正则化等方法,例如大小为 4 或 5 的最大范数正则化已被证明可以改善结果。
关于 dropout 的更多资源
以下是一些资源,您可以用它们来了解有关神经网络和深度学习模型中的 dropout 的更多信息。
总结
在这篇文章中,您了解了深度学习模型的 dropout 正则化技术。你了解到:
- dropout 含义和原理。
- 如何在自己的深度学习模型中使用 dropout。
- 使用 dropout 的技巧。
您对 dropout 或这篇文章有任何疑问吗?在评论中提出您的问题,我会尽力回答。
评估 Keras 中深度学习模型的表现
原文:
machinelearningmastery.com/evaluate-performance-deep-learning-models-keras/
Keras 是一个易于使用且功能强大被用于深度学习的 Python 库。
在设计和配置深度学习模型时,需要做出许多决策,这些决策大多必须通过反复试验和根据真实数据进行评估,以经验方式解决。
因此,有一种强大的方法来评估神经网络和深度学习模型的表现至关重要。
在这篇文章中,您将发现使用 Keras 评估模型表现的几种方法。
让我们开始吧。
- 2016 年 10 月更新:更新了 Keras 1.1.0 和 scikit-learn v0.18 的示例。
- 2017 年 3 月更新:更新了 Keras 2.0.2,TensorFlow 1.0.1 和 Theano 0.9.0 的示例。
- 更新 March / 2018 :添加了备用链接以下载数据集,因为原始图像已被删除。

照片由 Thomas Leuthard 拍摄,保留所属权利
根据经验评估网络配置
在设计和配置深度学习模型时,必须做出很多决策。
其中许多决策可以通过复制其他人的网络结构并使用启发式方法来解。最终,最好的技术是根据实际设计小型实验并使用实际数据凭经验评估相关选项。
这包括高级决策,例如网络中层的数量,大小和类型,它还包括较低级别的决策,如损失函数的选择,激活函数,优化过程和迭代次数。
深度学习通常用于具有非常大的数据集的问题,例如有数万或数十万个实例。
因此,您需要拥有一个强大的测试工具,可以让您评估给定配置在不可见的数据上的表现,并将较为可靠的表现表现与其他配置进行比较。
数据拆分
大量数据和复杂的模型需要非常长的训练时间。
因此,通常将数据分为测试数据集和验证数据集。
Keras 提供了两种方便的方式来评估您的深度学习算法:
- 使用自动验证数据集。
- 使用手动验证数据集。
使用自动验证数据集
Keras 可以将训练数据的一部分划分为为验证数据集,并在每个迭代中评估模型在该验证数据集上的表现。
您可以通过将fit()函数上的 validation_split 参数设置为训练数据集大小的百分比来完成此操作。
例如,20%的合理值可能是 0.2 或 0.33,或者为了验证而将验证数据集的数量选择的训练数据集的 33%。
下面的示例演示了如何在小二分类问题上使用自动验证数据集。本文中的所有实例均使用皮马印第安人糖尿病数据集。您可以从 UCI 机器学习库下载,并使用文件名 pima-indians-diabetes.csv 将数据文件保存到当前工作目录中(更新:从这里)。
# 使用自动验证集的 MLP
from keras.models import Sequential
from keras.layers import Dense
import numpy
#固定随机种子再现性
numpy.random.seed(7)
# 加载数据集
dataset = numpy.loadtxt("pima-indians-diabetes.csv", delimiter=",")
# 将数据集划分为输入变量和输出变量
X = dataset[:,0:8]
Y = dataset[:,8]
# 创建模型
model = Sequential()
model.add(Dense(12, input_dim=8, activation='relu'))
model.add(Dense(8, activation='relu'))
model.add(Dense(1, activation='sigmoid'))
# 编译模型
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
# 拟合模型
model.fit(X, Y, validation_split=0.33, epochs=150, batch_size=10)
运行该示例,您可以看到每个时期的详细输出显示了训练数据集和验证数据集的损失和准确率。
...
Epoch 145/150
514/514 [==============================] - 0s - loss: 0.5252 - acc: 0.7335 - val_loss: 0.5489 - val_acc: 0.7244
Epoch 146/150
514/514 [==============================] - 0s - loss: 0.5198 - acc: 0.7296 - val_loss: 0.5918 - val_acc: 0.7244
Epoch 147/150
514/514 [==============================] - 0s - loss: 0.5175 - acc: 0.7335 - val_loss: 0.5365 - val_acc: 0.7441
Epoch 148/150
514/514 [==============================] - 0s - loss: 0.5219 - acc: 0.7354 - val_loss: 0.5414 - val_acc: 0.7520
Epoch 149/150
514/514 [==============================] - 0s - loss: 0.5089 - acc: 0.7432 - val_loss: 0.5417 - val_acc: 0.7520
Epoch 150/150
514/514 [==============================] - 0s - loss: 0.5148 - acc: 0.7490 - val_loss: 0.5549 - val_acc: 0.7520
使用手动验证数据集
Keras 还允许您手动指定在训练期间用于验证的数据集。
在这个例子中,我们使用 Python scikit-learn 机器学习库中方便的 train_test_split()函数将我们的数据分成训练和测试数据集。我们使用 67%用于训练,剩余 33%用于验证。
可以通过 validation_data 参数将验证数据集指定给 Keras 中的fit()函数,该函数输出和输入的数据类型是数据集中的元组类型。
# 使用手动验证集的 MLP
from keras.models import Sequential
from keras.layers import Dense
from sklearn.model_selection import train_test_split
import numpy
#固定随机种子再现性
seed = 7
numpy.random.seed(seed)
# 加载数据集
dataset = numpy.loadtxt("pima-indians-diabetes.csv", delimiter=",")
# 将数据集划分为输入变量 X 和输出变量 Y
X = dataset[:,0:8]
Y = dataset[:,8]
# 将数据集划分为 67%的训练集和 33%的测试集
X_train, X_test, y_train, y_test = train_test_split(X, Y, test_size=0.33, random_state=seed)
# 创建模型
model = Sequential()
model.add(Dense(12, input_dim=8, activation='relu'))
model.add(Dense(8, activation='relu'))
model.add(Dense(1, activation='sigmoid'))
# 编译模型
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
# 拟合模型
model.fit(X_train, y_train, validation_data=(X_test,y_test), epochs=150, batch_size=10)
与之前一样,运行该示例提供了详细的训练输出数据,其中包括模型在每个迭代期间在训练集和验证数据集上的损失和精确度。
...
Epoch 145/150
514/514 [==============================] - 0s - loss: 0.4847 - acc: 0.7704 - val_loss: 0.5668 - val_acc: 0.7323
Epoch 146/150
514/514 [==============================] - 0s - loss: 0.4853 - acc: 0.7549 - val_loss: 0.5768 - val_acc: 0.7087
Epoch 147/150
514/514 [==============================] - 0s - loss: 0.4864 - acc: 0.7743 - val_loss: 0.5604 - val_acc: 0.7244
Epoch 148/150
514/514 [==============================] - 0s - loss: 0.4831 - acc: 0.7665 - val_loss: 0.5589 - val_acc: 0.7126
Epoch 149/150
514/514 [==============================] - 0s - loss: 0.4961 - acc: 0.7782 - val_loss: 0.5663 - val_acc: 0.7126
Epoch 150/150
514/514 [==============================] - 0s - loss: 0.4967 - acc: 0.7588 - val_loss: 0.5810 - val_acc: 0.6929
手动 k-fold 交叉验证
机器学习模型评估的黄金标准是 [k 折交叉验证](https://en.wikipedia.org/wiki/Cross-validation_(statistics)。
它提供了模型对不可见数据的表现的可靠估计,它通过将训练数据集拆分为 k 子集来实现此,并对所有子集(除保留的子集外)轮流训练模型,并评估已保留验证数据集上的模型表现,该过程将重复,直到所有子集都有机会成为已执行的验证集。然后,在创建的所有模型中对表现度量值进行平均。
交叉验证通常不用于评估深度学习模型,因为计算的花费会更高。例如,k 折交叉验证通常用于 5 或 10 折,因此,必须构造和评估 5 或 10 个模型,从而大大增加了模型的评估时间。
然而,当问题足够小或者你有足够的计算资源时,k-fold 交叉验证可以让你对模型的表现进行较少的偏差估计。
在下面的例子中,我们使用来自 scikit-learn Python 机器学习库的方便的 StratifiedKFold 类将训练数据集分成 10 折,折叠是分层的,这意味着算法试图平衡每个折叠中每个类的实例数。
该示例使用数据的 10 个拆分创建评估 10 个模型,并收集所有的表现分数,并通过将verbose=0传递给模型上的fit()函数和evaluate()函数,并将每个迭代期间的详细输出关闭。
为每个模型存储和打印相关的表现数据,然后,在运行结束时打印模型表现的平均差和标准差,以提供对模型准确率的可靠估计。
# 为 Pima Indians 数据集使用 10 折交叉验证的 MLP
from keras.models import Sequential
from keras.layers import Dense
from sklearn.model_selection import StratifiedKFold
import numpy
# 固定随机种子再现性
seed = 7
numpy.random.seed(seed)
# 加载数据集
dataset = numpy.loadtxt("pima-indians-diabetes.csv", delimiter=",")
# 将数据集划分为输入数据 X 和输出数据 Y
X = dataset[:,0:8]
Y = dataset[:,8]
# 定义 10 折交叉验证测试线束
kfold = StratifiedKFold(n_splits=10, shuffle=True, random_state=seed)
cvscores = []
for train, test in kfold.split(X, Y):
# 创建模型
model = Sequential()
model.add(Dense(12, input_dim=8, activation='relu'))
model.add(Dense(8, activation='relu'))
model.add(Dense(1, activation='sigmoid'))
# 编译模型
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
# 拟合模型
model.fit(X[train], Y[train], epochs=150, batch_size=10, verbose=0)
# 评估模型
scores = model.evaluate(X[test], Y[test], verbose=0)
print("%s: %.2f%%" % (model.metrics_names[1], scores[1]*100))
cvscores.append(scores[1] * 100)
print("%.2f%% (+/- %.2f%%)" % (numpy.mean(cvscores), numpy.std(cvscores)))
运行该示例将花费不到一分钟,并将产生以下输出:
acc: 77.92%
acc: 68.83%
acc: 72.73%
acc: 64.94%
acc: 77.92%
acc: 35.06%
acc: 74.03%
acc: 68.83%
acc: 34.21%
acc: 72.37%
64.68% (+/- 15.50%)
摘要
在这篇文章中,您发现了使用一种强大的方法来估计深度学习模型在不可见数据集上的模型表现的重要性。
您发现了三种使用 Keras 库在 Python 中估计深度学习模型表现的方法:
- 使用自动验证数据集。
- 使用手动验证数据集。
- 使用手动 k-fold 交叉验证。
您对 Keras 深度学习或者此文章还有疑问吗?在评论中提出您的问题,我会尽力回答。
如何评估深度学习模型的表现
原文:
machinelearningmastery.com/evaluate-skill-deep-learning-models/
我经常看到从业者对如何评估深度学习模型表示困惑。
从以下问题中可以看出这一点:
- 我应该使用什么随机种子?
- 我需要随机种子吗?
- 为什么我在后续运行中得不到相同的结果?
在这篇文章中,您将发现可用于评估深度学习模型的过程以及使用它的基本原理。
您还将发现有用的相关统计量,您可以计算这些统计量以显示模型表现的技巧,例如标准偏差,标准误差和置信区间。
让我们开始吧!

照片由 Allagash Brewing提供,并保留所属权利。
初学者易犯的错误
您将在训练数据集上拟合您的模型并且在测试数据集上评估您的模型,然后做出模型特性的报告。
也许您会使用 k 折交叉验证来评估模型,报告关于改进模型表现的技巧。
这是初学者常犯的错误。
看起来你做的是正确的事情,但有一个关键问题是你没有考虑到:
深度学习模型是随机的。
人工神经网络在拟合数据集时是随机性的,例如在每个迭代期间随机清洗数据,每个随机梯度下降期间随机初始化权重。
这意味着每次相同的模型拟合相同的数据时,它可能会给出不同的预测,从而具有不同的表现。
评估模型的技巧
(_ 模型方差控制 _)
我们可能没有所有的数据,如果有,我们就不需要做出预测。
通常情况下,我们有一个有限的数据样本,我们需要利用这些数据拟合出最好的模型。
使用训练测试拆分
我们通过将数据分成两部分来做到这一点,在数据的第一部分拟合模型或特定模型配置,并使用拟合后的模型对其余部分做出预测,然后评估这些预测的表现,这中技巧被称为训练测试分割,我们使用该技能评估模型对新数据做出预测时在实践中的表现。
例如,这里有一些用于使用训练测试分割来评估模型的伪代码:
train, test = split(data)
model = fit(train.X, train.y)
predictions = model.predict(test.X)
skill = compare(test.y, predictions)
如果您有大量数据或需要对非常慢的模型进行训练,训练测试分割是一种很好的方法,但由于数据的随机性(模型的方差),模型的最终表现分数会很混乱。
这意味着拟合不同数据的相同模型将给出不同的模型表现分数。
使用 k-fold 交叉验证
我们通常可以使用 k-fold 交叉验证等技术来加强这一点,并更准确地估计模型行表现,这是一种系统地将可用数据分成 k 重折叠,在 k-1 折上训练数据以拟合模型,在保持折叠上进行评估模型,并对每个折叠重复此过程的技术。
这导致 k 个不同的模型具有 k 个不同的预测集合,并且反过来具有 k 个不同的表现分数。
例如,这里有一些使用 k 折交叉验证评估模型的伪代码:
scores = list()
for i in k:
train, test = split_old(data, i)
model = fit(train.X, train.y)
predictions = model.predict(test.X)
skill = compare(test.y, predictions)
scores.append(skill)
技能分数更有用,因为我们可以采用均值并报告模型的平均预期表现,这可能更接近实际模型的实际表现。例如:
mean_skill = sum(scores) / count(scores)
我们还可以使用 mean_skill 计算标准偏差,以了解 mean_skill 周围的平均分数差异:
standard_deviation = sqrt(1/count(scores) * sum( (score - mean_skill)² ))
评估随机模型的表现
(_ 控制模型稳定性 _)
一些随机模型,如深度神经网络,增加了一个额外的随机源。
这种额外的随机性使得模型在学习时具有更大的灵活性,但也可能会使模型更不稳定(例如,当在相同数据上训练相同模型时会有不同的结果)。
这与模型方的差不同,模型的方差通常是当在不同数据上训练相同模型时,模型方差给出不同的结果。
为了得到随机模型表现的可靠估计,我们必须考虑这个额外的方差来源并且我们必须控制它。
固定随机种子
一种方法是每次模型拟合时使用相同的随机数,我们可以通过固定系统使用的随机数种子然后评估或拟合模型来做到这一点。例如:
seed(1)
scores = list()
for i in k:
train, test = split_old(data, i)
model = fit(train.X, train.y)
predictions = model.predict(test.X)
skill = compare(test.y, predictions)
scores.append(skill)
这在每次运行代码或都需要相同的结果时,非常适合教程和演示。
这中做法是不稳定的,不建议用于评估模型。
如下文章所示:
- 在机器学习中拥抱随机性
- 如何使用 Keras 获得可重现的结果
重复评估实验
更强大的方法是重复多次评估非随机模型的实验。
例如:
scores = list()
for i in repeats:
run_scores = list()
for j in k:
train, test = split_old(data, j)
model = fit(train.X, train.y)
predictions = model.predict(test.X)
skill = compare(test.y, predictions)
run_scores.append(skill)
scores.append(mean(run_scores))
注意,我们计算估计的平均模型技能的平均值,即所谓的宏均值。
这是我推荐的评估深度学习模型技能的程序。
因为重复通常次数>=30,所以我们可以很容易地计算出平均模型表现的标准误差,即模型表现得分的估计平均值与未知的实际平均模型技能的差异(例如,mean_skill 的差值会有多大)
standard_error = standard_deviation / sqrt(count(scores))
此外,我们可以使用 standard_error 来计算 mean_skill 的置信区间,假设结果的分布是高斯分布,您可以通过查看直方图,Q-Q 图或对收集的分数使用统计检验来检查。
例如,计算 95%左右的间隔是平均表现的指标(1.96 *标准误差)。
interval = standard_error * 1.96
lower_interval = mean_skill - interval
upper_interval = mean_skill + interval
与使用大均值的标准误差相比,还有其他可能在统计上更稳健的计算置信区间的方法,例如:
神经网络有多不稳定?
这取决于您的问题,网络和配置。
我建议进行敏感性分析以找出答案。
在同一数据上多次(30,100 或数千)评估相同的模型,只改变随机数生成器的种子。
然后检查所产生表现分数的均值和标准差,标准偏差(分数与平均分数的平均距离)将让您了解模型的不稳定程度。
多少次重复?
我建议至少 30,也许 100,甚至数千,仅限于你的时间和计算机资源,以及递减的回馈(例如,mean_skill 上的标准误差)。
更为严格地说,我建议进行一个实验,研究对估计模型技能的影响与重复次数的影响以及标准误差的计算(平均估计表现与真实基本总体平均值相差多少)。
进一步阅读
- 在机器学习中拥抱随机性
- 如何训练最终机器学习模型
- 比较不同种类的交叉验证
- 人工智能的经验方法,Cohen,1995。
- 维基百科上的标准错误
摘要
在这篇文章中,您发现了如何评估深度学习模型的技能。
具体来说,你学到了:
- 初学者在评估深度学习模型时常犯的错误。
- 使用重复 k 倍交叉验证来评估深度学习模型的基本原理。
- 如何计算相关的模型技能统计量,例如标准差,标准误差和置信区间。
您对估算深度学习模型的技能有任何疑问吗?
请在评论中发表您的问题,我会尽力回答。
小批量梯度下降的简要介绍以及如何配置批量大小
原文:
machinelearningmastery.com/gentle-introduction-mini-batch-gradient-descent-configure-batch-size/
随机梯度下降是用于训练深度学习模型的主要方法。
梯度下降有三种主要变体,可能会混淆哪一种使用。
在这篇文章中,您将发现一般应该使用的一种梯度下降以及如何配置它。
完成这篇文章后,你会知道:
- 什么梯度下降以及它如何从高层起作用。
- 什么批次,随机和小批量梯度下降以及每种方法的优点和局限性。
- 这种小批量梯度下降是首选方法,以及如何在您的应用程序上配置它。
让我们开始吧。
- Update Apr / 2018 :添加了额外的参考,以支持批量大小为 32。

小批量梯度下降和如何配置批量大小的温和介绍
照片由 Brian Smithson ,保留一些权利。
教程概述
本教程分为 3 个部分;他们是:
- 什么是梯度下降?
- 对比 3 种类型的梯度下降
- 如何配置 Mini-Batch Gradient Descent
什么是梯度下降?
梯度下降是一种优化算法,通常用于查找机器学习算法的权重或系数,例如人工神经网络和逻辑回归。
它的工作原理是让模型对训练数据做出预测,并使用预测误差来更新模型,以减少错误。
该算法的目标是找到最小化训练数据集上的模型的误差的模型参数(例如,系数或权重)。它通过对模型进行更改来实现此目的,该模型将其沿着梯度或误差斜率向下移动到最小误差值。这使算法的名称为“梯度下降”。
下面的伪代码草图总结了梯度下降算法:
model = initialization(...)
n_epochs = ...
train_data = ...
for i in n_epochs:
train_data = shuffle(train_data)
X, y = split(train_data)
predictions = predict(X, model)
error = calculate_error(y, predictions)
model = update_model(model, error)
有关更多信息,请参阅帖子:
对比 3 种类型的梯度下降
梯度下降可以根据用于计算误差的训练模式的数量而变化;而这又用于更新模型。
用于计算误差的模式数包括用于更新模型的梯度的稳定性。我们将看到计算效率的梯度下降配置和误差梯度的保真度存在张力。
梯度下降的三种主要风格是批量,随机和小批量。
让我们仔细看看每一个。
什么是随机梯度下降?
随机梯度下降(通常缩写为 SGD)是梯度下降算法的变体,其计算误差并更新训练数据集中每个示例的模型。
每个训练样例的模型更新意味着随机梯度下降通常被称为在线机器学习算法。
上升空间
- 频繁更新可立即深入了解模型的表现和改进速度。
- 这种梯度下降的变体可能是最容易理解和实现的,特别是对于初学者。
- 增加的模型更新频率可以更快地学习某些问题。
- 噪声更新过程可以允许模型避免局部最小值(例如,早熟收敛)。
缺点
- 如此频繁地更新模型在计算上比其他梯度下降配置更昂贵,在大型数据集上训练模型需要更长的时间。
- 频繁更新可能导致噪声梯度信号,这可能导致模型参数并且反过来模型误差跳跃(在训练时期上具有更高的方差)。
- 沿着误差梯度的噪声学习过程也可能使算法难以确定模型的最小误差。
什么是批量梯度下降?
批量梯度下降是梯度下降算法的变体,其计算训练数据集中每个示例的误差,但仅在评估了所有训练样本之后更新模型。
整个训练数据集的一个周期称为训练时期。因此,经常说批量梯度下降在每个训练时期结束时执行模型更新。
上升空间
- 对模型的更新较少意味着这种梯度下降变体在计算上比随机梯度下降更有效。
- 降低的更新频率导致更稳定的误差梯度,并且可以在一些问题上导致更稳定的收敛。
- 预测误差的计算与模型更新的分离使算法成为基于并行处理的实现。
缺点
- 更稳定的误差梯度可能导致模型过早收敛到不太理想的参数组。
- 训练时期结束时的更新需要在所有训练样例中累积预测误差的额外复杂性。
- 通常,批量梯度下降以这样的方式实现,即它需要存储器中的整个训练数据集并且可用于算法。
- 对于大型数据集,模型更新以及训练速度可能变得非常慢。
什么是 Mini-Batch Gradient Descent?
小批量梯度下降是梯度下降算法的变体,其将训练数据集分成小批量,用于计算模型误差和更新模型系数。
实现可以选择对小批量的梯度求和或者取梯度的平均值,这进一步减小了梯度的方差。
小批量梯度下降试图在随机梯度下降的稳健性和批量梯度下降的效率之间找到平衡。它是深度学习领域中最常用的梯度下降实现。
上升空间
- 模型更新频率高于批量梯度下降,这允许更稳健的收敛,避免局部最小值。
- 与随机梯度下降相比,批量更新提供了计算上更有效的过程。
- 批量允许在内存和算法实现中不具有所有训练数据的效率。
缺点
- 小批量需要为学习算法配置额外的“小批量大小”超参数。
- 错误信息必须在批量梯度下降等小批量训练示例中累积。
如何配置 Mini-Batch Gradient Descent
对于大多数应用,小批量梯度下降是梯度下降的推荐变体,特别是在深度学习中。
为简洁起见,通常称为“批量大小”的小批量大小通常被调整到正在执行实现的计算架构的一个方面。例如 2 的幂,适合 GPU 或 CPU 硬件的内存要求,如 32,64,128,256 等。
批量大小是学习过程中的滑块。
- 较小的值使学习过程在训练过程中以噪声成本快速收敛。
- 较大的值使学习过程缓慢收敛,并准确估计误差梯度。
提示 1:批量大小的良好默认值可能是 32.
… [批量大小]通常在 1 到几百之间选择,例如, [批量大小] = 32 是一个很好的默认值,其值大于 10,利用了矩阵 - 矩阵乘积相对于矩阵向量乘积的加速。
- 深层架构基于梯度的训练的实用建议,2012
更新 2018 :这是支持批量大小为 32 的另一篇论文,这里是引用(m 是批量大小):
所呈现的结果证实,对于给定的计算成本,在大范围的实验中使用小批量尺寸实现了最佳的训练稳定性和泛化表现。在所有情况下,已经获得了最佳结果,批量大小 m = 32 或更小,通常小到 m = 2 或 m = 4。
- 重新审视深度神经网络的小批量训练,2018 年。
提示 2:在调整批量大小时,最好在不同批量大小的情况下查看模型验证错误与训练时间的学习曲线。
…在选择了其他超参数(学习率除外)之后,通过比较训练曲线(训练和验证误差与训练时间量),可以分别优化其他超参数。
提示 3:在调整所有其他超参数后调整批量大小和学习率。
… [批量大小]和[学习率]可能会与其他超参数稍微交互,因此两者都应在最后重新优化。一旦选择[批量大小],通常可以固定,而其他超参数可以进一步优化(动量超参数除外,如果使用的话)。
进一步阅读
如果您要深入了解,本节将提供有关该主题的更多资源。
相关文章
补充阅读
- 维基百科上的随机梯度下降
- 维基百科上的在线机器学习
- 梯度下降优化算法概述
- 深层架构基于梯度的训练的实用建议,2012
- 随机优化的高效小批量训练,2014 年
- 在深度学习中,为什么我们不使用整个训练集来计算梯度? Quora 上的
- 大规模机器学习的优化方法,2016
摘要
在这篇文章中,您发现了梯度下降算法以及您应该在实践中使用的版本。
具体来说,你学到了:
- 什么梯度下降以及它如何从高层起作用。
- 什么批次,随机和小批量梯度下降以及每种方法的优点和局限性。
- 这种小批量梯度下降是首选方法,以及如何在您的应用程序上配置它。
你有任何问题吗?
在下面的评论中提出您的问题,我会尽力回答。
在 Keras 深度学习中获得帮助的 9 种方法
Keras 是一个 Python 深度学习库,可以使用高效的 Theano 或 TensorFlow 符号数学库作为后端。
Keras 非常易于使用,您可以在几分钟内开发出您的第一个多层感知机,卷积神经网络或 LSTM 递归神经网络。
当您开始使用 Keras 时,您可能会遇到技术问题,这时候您可能需要一些帮助。
在这篇文章中,您将会发现在 Keras 开发深度学习模型遇到问题时可以提供解决方案的 9 种途径。
让我们现在开始吧!
如何最好地使用这些资源
第一步是了解此从哪里可以获得帮助,但除此之外您需要知道如何充分利用这些资源。
以下是您可以使用的一些提示:
- 将您的问题简化为最简单的形式,例如:不应该是“_ 我的模型不起作用 _” 而是转化为 “_x 如何工作 _”。
- 在提问之前搜索答案。
- 提供尽可能小的工作示例来演示您的问题。
1. Keras 用户 Google Group
Keras 用户 Google Group
也许向 Keras 社区提问的最直接的地方就是在 Google 群组(旧的 usenet)上的 Keras Users 群组上。
在这里,你不需要接受任何电子邮件,你可以直接在线访问,我推荐以下方式:
2. Keras Slack Channel
也许 Keras Slacks 频道是可以直接聊聊 Keras 和相关问题的最佳方式。
这种方式现在基本上取代了 IM 和 IIRC。
不过,您必须先提交要求加入的申请。
3. Gitter 上的 Keras
另一个交流 Keras 的好地方是 Keras Giiter,尽管组织比较松散,但这个平台上仍然有大量的人。
尽管在这个论坛里尽情“遨游”吧!
4. StackOverflow 上的 Keras 标签
StackOverflow 是一个致力于编程问题的问答网站,在这里有大量有关深度学习和与 Keras 相关的问题,我建议您可以直接搜索带有“Keras”标签的相关回答。
- StackOverflow 上的 Keras 标签
5. CrossValidated 上的 Keras 标签
CrossValidated 是一个致力于机器学习的问答网站,并且有很多关于 Keras 相关的问题,但它们可能多的是一些理论上的问题集合,而不是专注于代码和编程。
同样,我建议搜索并访问使用“keras”标签的问题。
- CrossValidated 上的 Keras 标签
6.数据科学上的 Keras 标签
支持 StackOverflow 和 CrossValidated 的 StackExchange 网站也有一个专用于 DataScience 的站点。
它现在仍处于测试阶段,尚未成为该网站的正式成员,尽管如此,该网站上还是有很多关于 Keras 的话题。
与其他两个站点不同,这些话题可能更多的以过程导向为主。
同样,我建议搜索并访问带有“keras”标签的话题。
7. Quora 上的 Keras 主题
Quora 是一个大型的通用问答网站(类似于中国的知乎),虽然它是通用的,但是仍然拥有很多技术相关的话题,包括 Keras 和深度学习。
这些问题的重点更多是基于文本解释和说明性的,您可能会获得有关技术的更多详细信息,而不是实现细节。
我建议您直接在“Keras”主题中搜索和提问。
- 关于 Quora 的 Keras 主题
8. Keras Github 问题
Keras 是一个在 GitHub 上托管的开源项目。
GitHub 提供了一个基本的问题管理系统,Keras 项目报告了很多问题,虽然问题应该仅限于代码的技术问题,但在这些问题上对 Keras 的讨论却令人惊讶。
我建议您搜索 Keras 问题,但只有您在发现错误或有新功能请求时才发布您的问题(请参阅指南)。
9.Twitter 上的 Keras 问题
您可以直接在 Twitter 上快速获有关 Keras 的相关问题。
我建议您直接在 Twitter 搜索“keras”。
我建议您还可以使用“keras”标签进行搜索并发布新的问题。
- Twitter 上的 Keras 话题标签
您也可以通过关注 Keras 背后的创造者和首席开发人员,FrançoisChollet来获得对于 Keras 更深刻的理解。
其他 Keras 站点
以下是其他 Keras 网站,您可以在此获得相关帮助。
摘要
在这篇文章中,您了解了可以在全网范围内获得有关 Keras 深度学习的问答网站。
你有没有使用过这些资源?你是怎么做到的?
您是否想在其他地方获得有关 Keras 的帮助?请在下面的评论中告诉我。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐



 8
8 0
0- 0



 已为社区贡献34条内容
已为社区贡献34条内容

所有评论(0)