强化学习(3) PPO pytorch实例
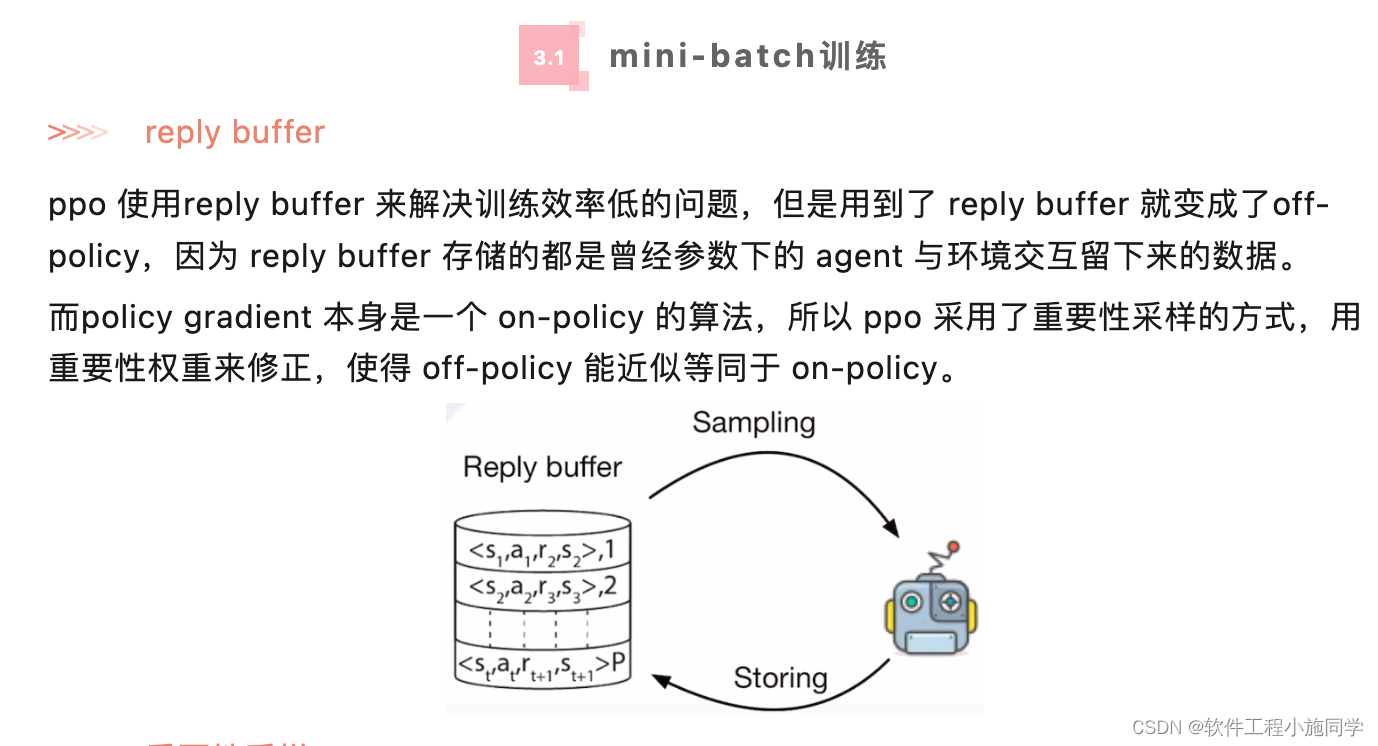
邻近策略优化(Proximal Policy Optimization,PPO)算法解决的问题是离散动作空间和连续动作空间的强化学习问题,是on-policy的强化学习算法。算法主要思想:策略pi接受状态s,输出动作概率分布,在动作概率分布中采样动作,执行动作,得到回报,跳到下一个状态。在这样的步骤下,我们可以使用策略pi收集一批样本,然后使用梯度下降算法学习这些样本,但是当策略pi的参数更新后,
背景介绍
邻近策略优化(Proximal Policy Optimization,PPO)算法解决的问题是离散动作空间和连续动作空间的强化学习问题,是on-policy的强化学习算法。
算法主要思想:
策略pi接受状态s,输出动作概率分布,在动作概率分布中采样动作,执行动作,得到回报,跳到下一个状态。
在这样的步骤下,我们可以使用策略pi收集一批样本,然后使用梯度下降算法学习这些样本,但是当策略pi的参数更新后,这些样本不能继续被使用,还要重新使用策略pi与环境互动收集数据,真的非常耗时。因此采用重要性采样,使这些样本可以被重复使用。
1. 模型结构


PPO是基于Actor-Critic架构的,这个架构的优势是解决了连续动作空间的问题。
- actor网络的输入为状态,输出为动作概率(对于离散动作空间而言)或者动作概率分布参数(对于连续动作空间而言);
- critic网络的输入为状态,输出为状态的价值。
actor网络输出的动作使优势越大越好,critic网络输出的状态价值越准确越好。
2. 产生experience的过程
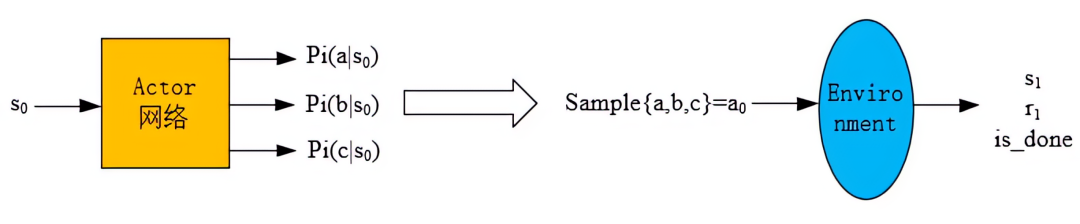
已知一个状态s0,
- 通过 actor网络得到所有动作的概率(图中以三个动作:a,b,c为例),
- 然后依概率采样得到动作a0,
- 然后将a0输入到环境中得到s1和r1,
- 状态价值v(s0)通过critic网络输出得到,
这样就得到一个experience: (s0,a0,r1,v(s0,logP(a0|s0)),然后将experience放入经验池中。
以上是离散动作的情况,如果是连续动作,就输出概率分布的参数(比如高斯分布的均值和方差),然后按照概率分布去采样得到动作a0。
经验池的意义是为了更方便的计算一条轨迹上状态的累积折扣回报v(st)以及优势A(st,at),而不是消除experience的相关性。
3. 网络更新
3.1 actor网络的更新流程
优势函数A的定义为:
优势函数:表示在状态s下采取动作a,相较于其他动作有多少优势,如果>0,则当前动作比平均动作好,反之,则差
![]()
因为Actor网络需要输出的动作优势尽可能地大,所以它的训练需要用以下表达式作为Loss函数:

其中rt(θ)反映了新旧策略差异的程度。

对于上式等价于如下形式:
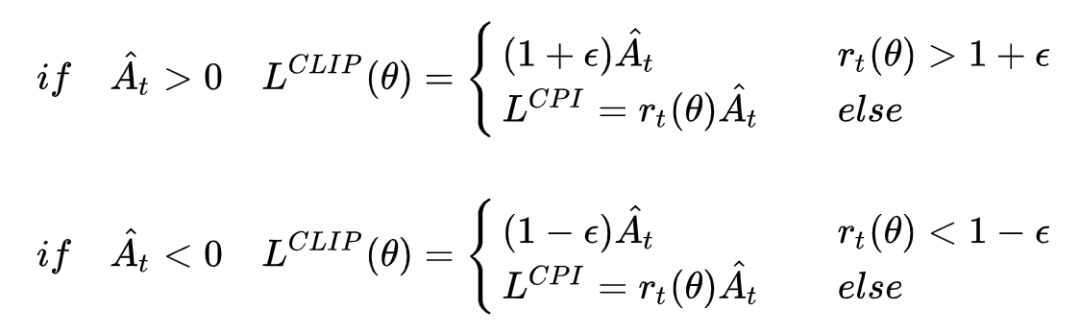
A大于0表示此时策略更好,要加大优化力度。目标函数取最大,那么就会尽量取大的r值,但如果更新力度过大,新旧策略差异就会太大,即
![]()
,那么clip操作和min操作会进行限制,防止了过度优化。
PPO算法使用多步TD,因此它需要跑完一条轨迹后,才开始计算各个状态的累积回报和动作的优势。具体而言,状态价值是通过critic网络输出得到的,动作优势是通过先计算
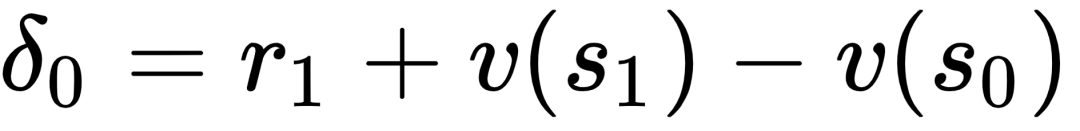
,然后用
![]()
作为折扣因子去计算动作优势,公式如下:
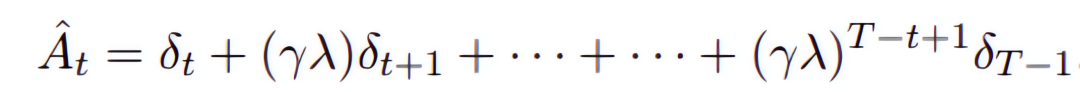
3.2 Critic网络的更新流程
Actor网络更新后,接着拿从经验池buffer中采出的数据进行Critic网络的更新(数据已经计算了状态价值,折扣回报Gt的计算是基于多步TD的方法,从那个状态开始,用每一步环境返回的奖励R与折扣因子相乘后累加,即:

其中
![]()
为网络的估计值,
更新方式为:计算好的折扣回报与Critic网络预测当前状态价值做差,用MSEloss作为Loss函数,对神经网络进行训练。
算法流程如下:

算法 1 PPO,Actor-Critic 风格
for iteration=1,2,... do // 对于每次迭代 iteration,从1到无穷
for actor=1,2,...,N do // 对于每个演员(actor),从1到N
Run policy π_old in environment for T timesteps // 在环境中使用旧策略 π_old 运行 T 个时间步
Compute advantage estimates Â_1, ..., Â_T // 计算优势估计值 Â_1 到 Â_T
end for
Optimize surrogate L wrt θ, with K epochs and minibatch size M ≤ NT // 用 K 个周期和小批量大小 M ≤ NT 优化关于 θ 的替代函数 L
θ_old ← θ // 更新旧的策略参数 θ_old 为当前的 θ
end for // 结束迭代

参考:
代码实例
小C开讲了 | 强化学习详解(下),内含代码、课件和文献和小C一起学强化学习 https://mp.weixin.qq.com/s/MJpGUSxvkMyWU4SEtF8HUQ
https://mp.weixin.qq.com/s/MJpGUSxvkMyWU4SEtF8HUQ
PPO.py
import torch
import torch.nn as nn
from torch.distributions import MultivariateNormal, Categorical
################################## set device ##################################
print("============================================================================================")
# 设置设备为CPU或CUDA
device = torch.device('cpu') # 默认设备是CPU
if(torch.cuda.is_available()): # 检查CUDA是否可用
device = torch.device('cuda:0') # 如果可用,则设置设备为第一个CUDA设备
torch.cuda.empty_cache() # 清空CUDA缓存
print("Device set to : " + str(torch.cuda.get_device_name(device))) # 输出当前CUDA设备名称
else:
print("Device set to : cpu") # 如果CUDA不可用,输出设备为CPU
print("============================================================================================")
################################## PPO Policy ##################################
class RolloutBuffer:
"""
用于存储回合数据的缓冲区
"""
def __init__(self):
self.actions = [] # 动作
self.states = [] # 状态
self.logprobs = [] # 动作的对数概率
self.rewards = [] # 奖励
self.is_terminals = [] # 终止标志
def clear(self):
"""
清空缓冲区
"""
del self.actions[:]
del self.states[:]
del self.logprobs[:]
del self.rewards[:]
del self.is_terminals[:]
class ActorCritic(nn.Module):
"""
Actor-Critic 网络模型
"""
def __init__(self, state_dim, action_dim, has_continuous_action_space, action_std_init):
"""
初始化ActorCritic模型
参数:
state_dim: 状态维度
action_dim: 动作维度
has_continuous_action_space: 是否为连续动作空间
action_std_init: 动作标准差的初始值
"""
# 调用父类的方法来初始化父类的部分
super(ActorCritic, self).__init__()
self.has_continuous_action_space = has_continuous_action_space # 动作空间类型标志
if has_continuous_action_space:
self.action_dim = action_dim
# 初始化动作方差,用于后续的策略评估和更新。
# torch.full(size, fill_value) 用于创建一个指定形状的张量,并用给定的 fill_value 来填充每个元素。
# (1,) 是一个包含一个元素的元组,而 (1) 只是一个括号中的整数,不是元组。
self.action_var = torch.full((action_dim,), action_std_init * action_std_init).to(device)
# 定义actor网络
if has_continuous_action_space :
self.actor = nn.Sequential(
nn.Linear(state_dim, 64), # 输入层到隐藏层
nn.Tanh(), # 激活函数
nn.Linear(64, 64), # 隐藏层
nn.Tanh(), # 激活函数
nn.Linear(64, action_dim), # 输出层
)
else:
self.actor = nn.Sequential(
nn.Linear(state_dim, 64), # 输入层到隐藏层
nn.Tanh(), # 激活函数
nn.Linear(64, 64), # 隐藏层
nn.Tanh(), # 激活函数
nn.Linear(64, action_dim), # 输出层
nn.Softmax(dim=-1) # 对输出动作使用Softmax函数,Actor 网络的输出是每个动作的得分,通过 Softmax 转换为概率。dim=-1 表示在最后一个维度上应用 Softmax 函数
)
# 定义critic网络
self.critic = nn.Sequential(
nn.Linear(state_dim, 64), # 输入层到隐藏层
nn.Tanh(), # 激活函数
nn.Linear(64, 64), # 隐藏层
nn.Tanh(), # 激活函数
nn.Linear(64, 1) # 输出层
)
def set_action_std(self, new_action_std):
"""
设置新的动作标准差
参数:
new_action_std: 新的动作标准差
"""
if self.has_continuous_action_space:
self.action_var = torch.full((self.action_dim,), new_action_std * new_action_std).to(device)
else:
print("--------------------------------------------------------------------------------------------")
print("WARNING : Calling ActorCritic::set_action_std() on discrete action space policy")
print("--------------------------------------------------------------------------------------------")
def forward(self):
raise NotImplementedError
def act(self, state):
"""
根据给定状态选择动作
参数:
state: 当前状态
返回:
action: 选择的动作
action_logprob: 动作的对数概率
"""
if self.has_continuous_action_space:
action_mean = self.actor(state) # 计算动作均值
cov_mat = torch.diag(self.action_var).unsqueeze(dim=0) # 计算协方差矩阵
dist = MultivariateNormal(action_mean, cov_mat) # 多变量正态分布
else:
action_probs = self.actor(state) # 动作概率
dist = Categorical(action_probs) # 分类分布
action = dist.sample() # 采样动作
action_logprob = dist.log_prob(action) # 计算动作的对数概率
return action.detach(), action_logprob.detach()
def evaluate(self, state, action):
"""
评估给定状态和动作的值
参数:
state: 状态
action: 动作
返回:
action_logprobs: 动作的对数概率
state_values: 状态值
dist_entropy: 分布熵
"""
if self.has_continuous_action_space:
action_mean = self.actor(state) # 计算动作均值
action_var = self.action_var.expand_as(action_mean) # 扩展动作方差
cov_mat = torch.diag_embed(action_var).to(device) # 计算协方差矩阵
dist = MultivariateNormal(action_mean, cov_mat) # 多变量正态分布
# 针对单一动作的环境
if self.action_dim == 1:
action = action.reshape(-1, self.action_dim)
else:
action_probs = self.actor(state) # 动作概率
dist = Categorical(action_probs) # 分类分布
action_logprobs = dist.log_prob(action) # 动作的对数概率
dist_entropy = dist.entropy() # 分布熵
state_values = self.critic(state) # 状态值
return action_logprobs, state_values, dist_entropy
class PPO:
def __init__(self, state_dim, action_dim, lr_actor, lr_critic, gamma, K_epochs, eps_clip, has_continuous_action_space, action_std_init=0.6):
"""
PPO算法的初始化函数
参数:
state_dim: 状态维度
action_dim: 动作维度
lr_actor: Actor网络的学习率
lr_critic: Critic网络的学习率
gamma: 折扣因子
K_epochs: 每次更新中进行的epoch数
eps_clip: PPO中裁剪的epsilon值
has_continuous_action_space: 是否为连续动作空间
action_std_init: 动作标准差的初始值(用于连续动作空间)
"""
self.has_continuous_action_space = has_continuous_action_space
if has_continuous_action_space:
self.action_std = action_std_init # 初始化动作标准差
self.gamma = gamma # 折扣因子
self.eps_clip = eps_clip # PPO裁剪参数
self.K_epochs = K_epochs # 每次更新中的epoch数
self.buffer = RolloutBuffer() # 回合缓冲区
# 初始化当前策略网络
self.policy = ActorCritic(state_dim, action_dim, has_continuous_action_space, action_std_init).to(device)
self.optimizer = torch.optim.Adam([
{'params': self.policy.actor.parameters(), 'lr': lr_actor},
{'params': self.policy.critic.parameters(), 'lr': lr_critic}
])
# 初始化旧策略网络
self.policy_old = ActorCritic(state_dim, action_dim, has_continuous_action_space, action_std_init).to(device)
self.policy_old.load_state_dict(self.policy.state_dict())
self.MseLoss = nn.MSELoss() # 均方误差损失函数
def set_action_std(self, new_action_std):
"""
设置新的动作标准差
参数:
new_action_std: 新的动作标准差
"""
if self.has_continuous_action_space:
self.action_std = new_action_std
self.policy.set_action_std(new_action_std)
self.policy_old.set_action_std(new_action_std)
else:
print("--------------------------------------------------------------------------------------------")
print("WARNING : Calling PPO::set_action_std() on discrete action space policy")
print("--------------------------------------------------------------------------------------------")
def decay_action_std(self, action_std_decay_rate, min_action_std):
"""
逐步衰减动作标准差
参数:
action_std_decay_rate: 动作标准差的衰减率
min_action_std: 动作标准差的最小值
"""
print("--------------------------------------------------------------------------------------------")
if self.has_continuous_action_space:
self.action_std = self.action_std - action_std_decay_rate
self.action_std = round(self.action_std, 4)
if (self.action_std <= min_action_std):
self.action_std = min_action_std
print("setting actor output action_std to min_action_std : ", self.action_std)
else:
print("setting actor output action_std to : ", self.action_std)
self.set_action_std(self.action_std)
else:
print("WARNING : Calling PPO::decay_action_std() on discrete action space policy")
print("--------------------------------------------------------------------------------------------")
def select_action(self, state):
"""
根据当前状态选择动作
参数:
state: 当前状态
返回:
action: 选择的动作
"""
if self.has_continuous_action_space:
with torch.no_grad():
state = torch.FloatTensor(state).to(device)
action, action_logprob = self.policy_old.act(state)
self.buffer.states.append(state) # 保存状态
self.buffer.actions.append(action) # 保存动作
self.buffer.logprobs.append(action_logprob) # 保存动作的对数概率
return action.detach().cpu().numpy().flatten()
else:
with torch.no_grad():
state = torch.FloatTensor(state).to(device)
action, action_logprob = self.policy_old.act(state)
self.buffer.states.append(state) # 保存状态
self.buffer.actions.append(action) # 保存动作
self.buffer.logprobs.append(action_logprob) # 保存动作的对数概率
return action.item()
def update(self):
"""
更新策略
"""
# 计算回报的蒙特卡罗估计
rewards = []
discounted_reward = 0
for reward, is_terminal in zip(reversed(self.buffer.rewards), reversed(self.buffer.is_terminals)):
if is_terminal:
discounted_reward = 0
discounted_reward = reward + (self.gamma * discounted_reward)
rewards.insert(0, discounted_reward)
# 标准化回报
rewards = torch.tensor(rewards, dtype=torch.float32).to(device)
rewards = (rewards - rewards.mean()) / (rewards.std() + 1e-7)
# 将列表转换为张量
old_states = torch.squeeze(torch.stack(self.buffer.states, dim=0)).detach().to(device)
old_actions = torch.squeeze(torch.stack(self.buffer.actions, dim=0)).detach().to(device)
old_logprobs = torch.squeeze(torch.stack(self.buffer.logprobs, dim=0)).detach().to(device)
# 优化策略 K 轮
for _ in range(self.K_epochs):
# 评估旧动作和价值
logprobs, state_values, dist_entropy = self.policy.evaluate(old_states, old_actions)
# 匹配 state_values 张量的维度与 rewards 张量
state_values = torch.squeeze(state_values)
# 计算比率 (pi_theta / pi_theta__old)
ratios = torch.exp(logprobs - old_logprobs.detach())
# 计算代理损失
advantages = rewards - state_values.detach()
surr1 = ratios * advantages
surr2 = torch.clamp(ratios, 1-self.eps_clip, 1+self.eps_clip) * advantages
# 最终的 PPO 损失
loss = -torch.min(surr1, surr2) + 0.5 * self.MseLoss(state_values, rewards) - 0.01 * dist_entropy
# 进行梯度下降
self.optimizer.zero_grad()
loss.mean().backward()
self.optimizer.step()
# 将新权重复制到旧策略
self.policy_old.load_state_dict(self.policy.state_dict())
# 清空缓冲区
self.buffer.clear()
def save(self, checkpoint_path):
"""
保存模型
参数:
checkpoint_path: 模型保存路径
"""
torch.save(self.policy_old.state_dict(), checkpoint_path)
def load(self, checkpoint_path):
"""
加载模型
参数:
checkpoint_path: 模型加载路径
"""
self.policy_old.load_state_dict(torch.load(checkpoint_path, map_location=lambda storage, loc: storage))
self.policy.load_state_dict(torch.load(checkpoint_path, map_location=lambda storage, loc: storage))
train.py
# '''
# @misc{pytorch_minimal_ppo,
# author = {Barhate, Nikhil},
# title = {Minimal PyTorch Implementation of Proximal Policy Optimization},
# year = {2021},
# publisher = {GitHub},
# journal = {GitHub repository},
# howpublished = {\url{https://github.com/nikhilbarhate99/PPO-PyTorch}},
# }
# '''
import os
import glob
import time
from datetime import datetime
import torch
import numpy as np
import gym
#import roboschool
from PPO import PPO
################################### Training ###################################
def train():
print("============================================================================================")
####### initialize environment hyperparameters ######
env_name = "CartPole-v1"
has_continuous_action_space = False # continuous action space; else discrete
max_ep_len = 1000 # max timesteps in one episode
max_training_timesteps = int(1e5) # break training loop if timeteps > max_training_timesteps
print_freq = max_ep_len * 10 # print avg reward in the interval (in num timesteps)
log_freq = max_ep_len * 2 # log avg reward in the interval (in num timesteps)
save_model_freq = int(1e5) # save model frequency (in num timesteps)
action_std = 0.6 # starting std for action distribution (Multivariate Normal)
action_std_decay_rate = 0.05 # linearly decay action_std (action_std = action_std - action_std_decay_rate)
min_action_std = 0.1 # minimum action_std (stop decay after action_std <= min_action_std)
action_std_decay_freq = int(2.5e5) # action_std decay frequency (in num timesteps)
#####################################################
## Note : print/log frequencies should be > than max_ep_len
################ PPO hyperparameters ################
update_timestep = max_ep_len * 4 # update policy every n timesteps
K_epochs = 80 # update policy for K epochs in one PPO update
eps_clip = 0.2 # clip parameter for PPO
gamma = 0.99 # discount factor
lr_actor = 0.0003 # learning rate for actor network
lr_critic = 0.001 # learning rate for critic network
random_seed = 0 # set random seed if required (0 = no random seed)
#####################################################
print("training environment name : " + env_name)
env = gym.make(env_name)
# state space dimension
state_dim = env.observation_space.shape[0]
# action space dimension
if has_continuous_action_space:
action_dim = env.action_space.shape[0]
else:
action_dim = env.action_space.n
###################### logging ######################
#### log files for multiple runs are NOT overwritten
log_dir = "PPO_logs"
if not os.path.exists(log_dir):
os.makedirs(log_dir)
log_dir = log_dir + '/' + env_name + '/'
if not os.path.exists(log_dir):
os.makedirs(log_dir)
#### get number of log files in log directory
run_num = 0
current_num_files = next(os.walk(log_dir))[2]
run_num = len(current_num_files)
#### create new log file for each run
log_f_name = log_dir + '/PPO_' + env_name + "_log_" + str(run_num) + ".csv"
print("current logging run number for " + env_name + " : ", run_num)
print("logging at : " + log_f_name)
#####################################################
################### checkpointing ###################
run_num_pretrained = 0 #### change this to prevent overwriting weights in same env_name folder
directory = "PPO_preTrained"
if not os.path.exists(directory):
os.makedirs(directory)
directory = directory + '/' + env_name + '/'
if not os.path.exists(directory):
os.makedirs(directory)
checkpoint_path = directory + "PPO_{}_{}_{}.pth".format(env_name, random_seed, run_num_pretrained)
print("save checkpoint path : " + checkpoint_path)
#####################################################
############# print all hyperparameters #############
print("--------------------------------------------------------------------------------------------")
print("max training timesteps : ", max_training_timesteps)
print("max timesteps per episode : ", max_ep_len)
print("model saving frequency : " + str(save_model_freq) + " timesteps")
print("log frequency : " + str(log_freq) + " timesteps")
print("printing average reward over episodes in last : " + str(print_freq) + " timesteps")
print("--------------------------------------------------------------------------------------------")
print("state space dimension : ", state_dim)
print("action space dimension : ", action_dim)
print("--------------------------------------------------------------------------------------------")
if has_continuous_action_space:
print("Initializing a continuous action space policy")
print("--------------------------------------------------------------------------------------------")
print("starting std of action distribution : ", action_std)
print("decay rate of std of action distribution : ", action_std_decay_rate)
print("minimum std of action distribution : ", min_action_std)
print("decay frequency of std of action distribution : " + str(action_std_decay_freq) + " timesteps")
else:
print("Initializing a discrete action space policy")
print("--------------------------------------------------------------------------------------------")
print("PPO update frequency : " + str(update_timestep) + " timesteps")
print("PPO K epochs : ", K_epochs)
print("PPO epsilon clip : ", eps_clip)
print("discount factor (gamma) : ", gamma)
print("--------------------------------------------------------------------------------------------")
print("optimizer learning rate actor : ", lr_actor)
print("optimizer learning rate critic : ", lr_critic)
if random_seed:
print("--------------------------------------------------------------------------------------------")
print("setting random seed to ", random_seed)
torch.manual_seed(random_seed)
env.seed(random_seed)
np.random.seed(random_seed)
#####################################################
print("============================================================================================")
################# training procedure ################
# initialize a PPO agent
ppo_agent = PPO(state_dim, action_dim, lr_actor, lr_critic, gamma, K_epochs, eps_clip, has_continuous_action_space, action_std)
# track total training time
start_time = datetime.now().replace(microsecond=0)
print("Started training at (GMT) : ", start_time)
print("============================================================================================")
# logging file
log_f = open(log_f_name,"w+")
log_f.write('episode,timestep,reward\n')
# printing and logging variables
print_running_reward = 0
print_running_episodes = 0
log_running_reward = 0
log_running_episodes = 0
time_step = 0
i_episode = 0
# training loop
while time_step <= max_training_timesteps:
state = env.reset()
current_ep_reward = 0
for t in range(1, max_ep_len+1):
# select action with policy
action = ppo_agent.select_action(state)
state, reward, done, _ = env.step(action)
# saving reward and is_terminals
ppo_agent.buffer.rewards.append(reward)
ppo_agent.buffer.is_terminals.append(done)
time_step +=1
current_ep_reward += reward
# update PPO agent
if time_step % update_timestep == 0:
ppo_agent.update()
# if continuous action space; then decay action std of ouput action distribution
if has_continuous_action_space and time_step % action_std_decay_freq == 0:
ppo_agent.decay_action_std(action_std_decay_rate, min_action_std)
# log in logging file
if time_step % log_freq == 0:
# log average reward till last episode
log_avg_reward = log_running_reward / log_running_episodes
log_avg_reward = round(log_avg_reward, 4)
log_f.write('{},{},{}\n'.format(i_episode, time_step, log_avg_reward))
log_f.flush()
log_running_reward = 0
log_running_episodes = 0
# printing average reward
if time_step % print_freq == 0:
# print average reward till last episode
print_avg_reward = print_running_reward / print_running_episodes
print_avg_reward = round(print_avg_reward, 2)
print("Episode : {} \t\t Timestep : {} \t\t Average Reward : {}".format(i_episode, time_step, print_avg_reward))
print_running_reward = 0
print_running_episodes = 0
# save model weights
if time_step % save_model_freq == 0:
print("--------------------------------------------------------------------------------------------")
print("saving model at : " + checkpoint_path)
ppo_agent.save(checkpoint_path)
print("model saved")
print("Elapsed Time : ", datetime.now().replace(microsecond=0) - start_time)
print("--------------------------------------------------------------------------------------------")
# break; if the episode is over
if done:
break
print_running_reward += current_ep_reward
print_running_episodes += 1
log_running_reward += current_ep_reward
log_running_episodes += 1
i_episode += 1
log_f.close()
env.close()
# print total training time
print("============================================================================================")
end_time = datetime.now().replace(microsecond=0)
print("Started training at (GMT) : ", start_time)
print("Finished training at (GMT) : ", end_time)
print("Total training time : ", end_time - start_time)
print("============================================================================================")
if __name__ == '__main__':
train()
make_gif.py
import os
import glob
import time
from datetime import datetime
import torch
import numpy as np
from PIL import Image
import gym
#import roboschool
from PPO import PPO
"""
One frame corresponding to each timestep is saved in a folder :
PPO_gif_images/env_name/000001.jpg
PPO_gif_images/env_name/000002.jpg
PPO_gif_images/env_name/000003.jpg
...
...
...
if this section is run multiple times or for multiple episodes for the same env_name;
then the saved images will be overwritten.
"""
############################# save images for gif ##############################
def save_gif_images(env_name, has_continuous_action_space, max_ep_len, action_std):
print("============================================================================================")
total_test_episodes = 1 # save gif for only one episode
K_epochs = 80 # update policy for K epochs
eps_clip = 0.2 # clip parameter for PPO
gamma = 0.99 # discount factor
lr_actor = 0.0003 # learning rate for actor
lr_critic = 0.001 # learning rate for critic
env = gym.make(env_name)
# state space dimension
state_dim = env.observation_space.shape[0]
# action space dimension
if has_continuous_action_space:
action_dim = env.action_space.shape[0]
else:
action_dim = env.action_space.n
# make directory for saving gif images
gif_images_dir = "PPO_gif_images" + '/'
if not os.path.exists(gif_images_dir):
os.makedirs(gif_images_dir)
# make environment directory for saving gif images
gif_images_dir = gif_images_dir + '/' + env_name + '/'
if not os.path.exists(gif_images_dir):
os.makedirs(gif_images_dir)
# make directory for gif
gif_dir = "PPO_gifs" + '/'
if not os.path.exists(gif_dir):
os.makedirs(gif_dir)
# make environment directory for gif
gif_dir = gif_dir + '/' + env_name + '/'
if not os.path.exists(gif_dir):
os.makedirs(gif_dir)
ppo_agent = PPO(state_dim, action_dim, lr_actor, lr_critic, gamma, K_epochs, eps_clip, has_continuous_action_space, action_std)
# preTrained weights directory
random_seed = 0 #### set this to load a particular checkpoint trained on random seed
run_num_pretrained = 0 #### set this to load a particular checkpoint num
directory = "PPO_preTrained" + '/' + env_name + '/'
checkpoint_path = directory + "PPO_{}_{}_{}.pth".format(env_name, random_seed, run_num_pretrained)
print("loading network from : " + checkpoint_path)
ppo_agent.load(checkpoint_path)
print("--------------------------------------------------------------------------------------------")
test_running_reward = 0
for ep in range(1, total_test_episodes+1):
ep_reward = 0
state = env.reset()
for t in range(1, max_ep_len+1):
action = ppo_agent.select_action(state)
state, reward, done, _ = env.step(action)
ep_reward += reward
img = env.render(mode = 'rgb_array')
img = Image.fromarray(img)
img.save(gif_images_dir + '/' + str(t).zfill(6) + '.jpg')
if done:
break
# clear buffer
ppo_agent.buffer.clear()
test_running_reward += ep_reward
print('Episode: {} \t\t Reward: {}'.format(ep, round(ep_reward, 2)))
ep_reward = 0
env.close()
print("============================================================================================")
print("total number of frames / timesteps / images saved : ", t)
avg_test_reward = test_running_reward / total_test_episodes
avg_test_reward = round(avg_test_reward, 2)
print("average test reward : " + str(avg_test_reward))
print("============================================================================================")
######################## generate gif from saved images ########################
def save_gif(env_name):
print("============================================================================================")
gif_num = 0 #### change this to prevent overwriting gifs in same env_name folder
# adjust following parameters to get desired duration, size (bytes) and smoothness of gif
total_timesteps = 300
step = 10
frame_duration = 150
# input images
gif_images_dir = "PPO_gif_images/" + env_name + '/*.jpg'
# ouput gif path
gif_dir = "PPO_gifs"
if not os.path.exists(gif_dir):
os.makedirs(gif_dir)
gif_dir = gif_dir + '/' + env_name
if not os.path.exists(gif_dir):
os.makedirs(gif_dir)
gif_path = gif_dir + '/PPO_' + env_name + '_gif_' + str(gif_num) + '.gif'
img_paths = sorted(glob.glob(gif_images_dir))
img_paths = img_paths[:total_timesteps]
img_paths = img_paths[::step]
print("total frames in gif : ", len(img_paths))
print("total duration of gif : " + str(round(len(img_paths) * frame_duration / 1000, 2)) + " seconds")
# save gif
img, *imgs = [Image.open(f) for f in img_paths]
img.save(fp=gif_path, format='GIF', append_images=imgs, save_all=True, optimize=True, duration=frame_duration, loop=0)
print("saved gif at : ", gif_path)
print("============================================================================================")
############################# check gif byte size ##############################
def list_gif_size(env_name):
print("============================================================================================")
gif_dir = "PPO_gifs/" + env_name + '/*.gif'
gif_paths = sorted(glob.glob(gif_dir))
for gif_path in gif_paths:
file_size = os.path.getsize(gif_path)
print(gif_path + '\t\t' + str(round(file_size / (1024 * 1024), 2)) + " MB")
print("============================================================================================")
if __name__ == '__main__':
env_name = "CartPole-v1"
has_continuous_action_space = False
max_ep_len = 400
action_std = None
# env_name = "LunarLander-v2"
# has_continuous_action_space = False
# max_ep_len = 500
# action_std = None
# env_name = "BipedalWalker-v2"
# has_continuous_action_space = True
# max_ep_len = 1500 # max timesteps in one episode
# action_std = 0.1 # set same std for action distribution which was used while saving
# env_name = "RoboschoolWalker2d-v1"
# has_continuous_action_space = True
# max_ep_len = 1000 # max timesteps in one episode
# action_std = 0.1 # set same std for action distribution which was used while saving
# env_name = "RoboschoolHalfCheetah-v1"
# has_continuous_action_space = True
# max_ep_len = 1000 # max timesteps in one episode
# action_std = 0.1 # set same std for action distribution which was used while saving
# env_name = "RoboschoolHopper-v1"
# has_continuous_action_space = True
# max_ep_len = 1000 # max timesteps in one episode
# action_std = 0.1 # set same std for action distribution which was used while saving
# save .jpg images in PPO_gif_images folder
save_gif_images(env_name, has_continuous_action_space, max_ep_len, action_std)
# save .gif in PPO_gifs folder using .jpg images
save_gif(env_name)
# list byte size (in MB) of gifs in one "PPO_gif/env_name/" folder
list_gif_size(env_name)
plot_graph.py
import os
import pandas as pd
import matplotlib.pyplot as plt
def save_graph():
print("============================================================================================")
env_name = 'CartPole-v1'
# env_name = 'LunarLander-v2'
# env_name = 'BipedalWalker-v2'
# env_name = 'RoboschoolWalker2d-v1'
fig_num = 0 #### change this to prevent overwriting figures in same env_name folder
plot_avg = True # plot average of all runs; else plot all runs separately
fig_width = 10
fig_height = 6
# smooth out rewards to get a smooth and a less smooth (var) plot lines
window_len_smooth = 20
min_window_len_smooth = 1
linewidth_smooth = 1.5
alpha_smooth = 1
window_len_var = 5
min_window_len_var = 1
linewidth_var = 2
alpha_var = 0.1
colors = ['red', 'blue', 'green', 'orange', 'purple', 'olive', 'brown', 'magenta', 'cyan', 'crimson','gray', 'black']
# make directory for saving figures
figures_dir = "PPO_figs"
if not os.path.exists(figures_dir):
os.makedirs(figures_dir)
# make environment directory for saving figures
figures_dir = figures_dir + '/' + env_name + '/'
if not os.path.exists(figures_dir):
os.makedirs(figures_dir)
fig_save_path = figures_dir + '/PPO_' + env_name + '_fig_' + str(fig_num) + '.png'
# get number of log files in directory
log_dir = "PPO_logs" + '/' + env_name + '/'
print(log_dir)
current_num_files = next(os.walk(log_dir))[2]
num_runs = len(current_num_files)
all_runs = []
for run_num in range(num_runs):
log_f_name = log_dir + '/PPO_' + env_name + "_log_" + str(run_num) + ".csv"
print("loading data from : " + log_f_name)
data = pd.read_csv(log_f_name)
data = pd.DataFrame(data)
print("data shape : ", data.shape)
all_runs.append(data)
print("--------------------------------------------------------------------------------------------")
ax = plt.gca()
if plot_avg:
# average all runs
df_concat = pd.concat(all_runs)
df_concat_groupby = df_concat.groupby(df_concat.index)
data_avg = df_concat_groupby.mean()
# smooth out rewards to get a smooth and a less smooth (var) plot lines
data_avg['reward_smooth'] = data_avg['reward'].rolling(window=window_len_smooth, win_type='triang', min_periods=min_window_len_smooth).mean()
data_avg['reward_var'] = data_avg['reward'].rolling(window=window_len_var, win_type='triang', min_periods=min_window_len_var).mean()
data_avg.plot(kind='line', x='timestep' , y='reward_smooth',ax=ax,color=colors[0], linewidth=linewidth_smooth, alpha=alpha_smooth)
data_avg.plot(kind='line', x='timestep' , y='reward_var',ax=ax,color=colors[0], linewidth=linewidth_var, alpha=alpha_var)
# keep only reward_smooth in the legend and rename it
handles, labels = ax.get_legend_handles_labels()
ax.legend([handles[0]], ["reward_avg_" + str(len(all_runs)) + "_runs"], loc=2)
else:
for i, run in enumerate(all_runs):
# smooth out rewards to get a smooth and a less smooth (var) plot lines
run['reward_smooth_' + str(i)] = run['reward'].rolling(window=window_len_smooth, win_type='triang', min_periods=min_window_len_smooth).mean()
run['reward_var_' + str(i)] = run['reward'].rolling(window=window_len_var, win_type='triang', min_periods=min_window_len_var).mean()
# plot the lines
run.plot(kind='line', x='timestep' , y='reward_smooth_' + str(i),ax=ax,color=colors[i % len(colors)], linewidth=linewidth_smooth, alpha=alpha_smooth)
run.plot(kind='line', x='timestep' , y='reward_var_' + str(i),ax=ax,color=colors[i % len(colors)], linewidth=linewidth_var, alpha=alpha_var)
# keep alternate elements (reward_smooth_i) in the legend
handles, labels = ax.get_legend_handles_labels()
new_handles = []
new_labels = []
for i in range(len(handles)):
if(i%2 == 0):
new_handles.append(handles[i])
new_labels.append(labels[i])
ax.legend(new_handles, new_labels, loc=2)
# ax.set_yticks(np.arange(0, 1800, 200))
# ax.set_xticks(np.arange(0, int(4e6), int(5e5)))
ax.grid(color='gray', linestyle='-', linewidth=1, alpha=0.2)
ax.set_xlabel("Timesteps", fontsize=12)
ax.set_ylabel("Rewards", fontsize=12)
plt.title(env_name, fontsize=14)
fig = plt.gcf()
fig.set_size_inches(fig_width, fig_height)
print("============================================================================================")
plt.savefig(fig_save_path)
print("figure saved at : ", fig_save_path)
print("============================================================================================")
plt.show()
if __name__ == '__main__':
save_graph()
运行命令
!python train.py
!python make_gif.py
!python plot_graph.py
on-policy和off-policy的区别

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐


 3
3 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)