深度学习系列(一)【人类语言处理--引言】
本文主要是对李宏毅教授的《Deep Learning for Human Language Processing (2020,Spring)》这门课程笔记。所有课程资料可以在以下链接中找到:http://speech.ee.ntu.edu.tw/~tlkagk/courses_DLHLP20.html。 语言可以分为自然语言处理(NLP)和机器语言。自然语言就是人类日常交流中的语言,...
本文主要是对李宏毅教授的《Deep Learning for Human Language Processing (2020,Spring)》这门课程笔记。
- 所有课程资料可以在以下链接中找到:http://speech.ee.ntu.edu.tw/~tlkagk/courses_DLHLP20.html。
语言可以分为自然语言处理(NLP)和机器语言。自然语言就是人类日常交流中的语言,像中文、英文这样。而机器语言是人类发明的,像Java、Python这种计算机语言。而人类的语言交流又可以分为书写的语言和说的语言,从而有了机器学习中的两大分支,文本处理、语音处理。其二者又具有极大的相关性,导致很多处理方法都可以相互借鉴。
处理这种结构化的数据比处理一般的机器学习满足独立同分布的数据要困难地多。其数据量也比较大。1s的语音信号采样,可以得到16k个采样点,每个采样点有256种可能的取值。并且这些信号之间的上下文关系又极具关联性,因此处理起来需要考虑诸多因素。并且语音信号无重复性,文本内容形式又多种多样。这是由每个人独一无二的个性化所决定的。

因此人类语言处理是人工智能的圣杯,需要一定的智慧。之后的课程大纲大致可以分为以下几个部分:
- 输入语音,输出文字
这种情况下的主要应用是语音辨识Automatic Speech Recognition (ASR)。传统的方法会做很多特征工程,做很多model然后合成,如下图所示:
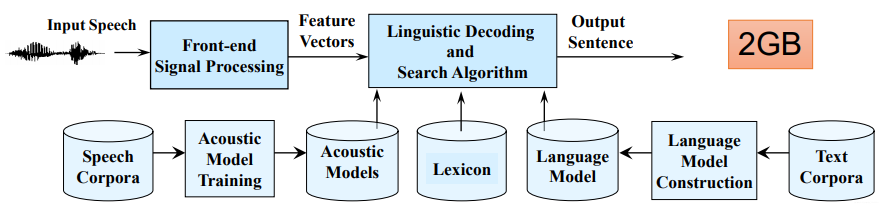
而Google的基于全神经网络的语音辨识系统已经用在移动设备上了:

具体细节可以参考:https://ai.googleblog.com/2019/03/an-all-neural-on-device-speech.html
- 输入文字,输出语音
这种情况下的主要应用是语音合成,像谷歌小姐这样类似的应用。但是并非说这里面的所有问题都被解决掉了,就像有时候语音对某些词的单个读音不准确,但是对一个句子中某个词的读音会很准确一样。我们也不知道为什么,因为神经网络像一个黑盒,我们并不知道里面具体做了什么。
- 输入语音,输出语音
这种情况下的主要应用是语音分离、去噪等等。或者语音中的风格转换(Voice Conversion)。

当然还有一些问答系统,聊天机器人也都属于这一类。
- 输入语音,输出语音所属类别
这种主要是语者辨认(Speaker Recognition),辨认是谁说的。或者检测这个句子里面有没有某个关键字(Keyword Spotting),最常用的就是语音唤醒功能。
- 输入文字,输出文字
与这相关的工作主要有以下四种:

- 输入文字,输出文字所属类别
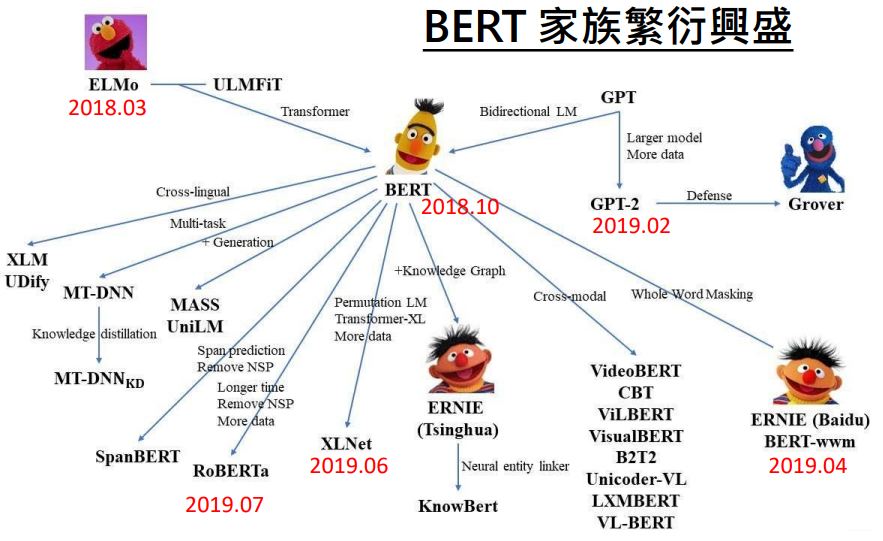
当然上述所说的方法你可以说用一个Sequence to Sequence的网络硬Train一下得到,但是目前已有很多先进的算法,有很多`trick,是很有必要学一下。不管是做强化学习还是人类语言处理,还是机器学习、深度学习,或者说数据挖掘,其算法背后的本质思想都是相同的,因此虽然我是做强化学习和智能决策为主的,但是我还是要好好学一下,学算法背后的思维才是我们所需要的,需要具备洞察算法背后本质思想的能力,共勉!·
最后分享这个必读的预训练语言模型,项目:

- 项目链接:https://github.com/thunlp/PLMpapers
参考
【1】李宏毅-基于深度学习的人类自然语言处理
我的微信公众号名称:小小何先生
公众号介绍:主要研究分享深度学习、机器博弈、强化学习等相关内容!期待您的关注,欢迎一起学习交流进步!

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐



 1
1 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)