基于100万某宝用户的1亿条行为数据分析
基于一亿数据量的淘宝用户购物行为的数据分析,分析用户的行为数据,电商平台可以深入了解用户的购物习惯、偏好和需求,例如,哪些商品类别最受欢迎、用户在何时何地进行购物等分析整体用户行为数据来把握市场趋势,调整产品线和库存策略,揭示消费者自己尚未意识到的需求,引导他们发现新的商品或服务。

数据集介绍
UserBehavior.csv
本数据集包含了2017年11月25日至2017年12月3日之间,有行为的约一百万随机用户的所有行为(行为包括点击、购买、加购、喜欢)。数据集的组织形式和MovieLens-20M类似,即数据集的每一行表示一条用户行为,由用户ID、商品ID、商品类目ID、行为类型和时间戳组成,并以逗号分隔。关于数据集中每一列的详细描述如下:

背景意义及目的
一、对电商平台的意义
- 用户行为理解:通过分析用户的行为数据,电商平台可以深入了解用户的购物习惯、偏好和需求。例如,哪些商品类别最受欢迎、用户在何时何地进行购物等。
- 个性化推荐优化:利用这些数据,平台可以构建更加精准的个性化推荐系统,提高用户的购物体验和满意度。
- 营销策略调整:数据分析可以帮助电商平台调整营销策略,比如确定最佳的促销时段、针对特定用户群体的促销活动等。
- 风险管理与防范:识别异常行为模式,如刷单、欺诈等,及时采取措施保护平台和用户的权益。
二、对商家的意义
- 市场趋势把握:商家可以通过分析整体用户行为数据来把握市场趋势,调整产品线和库存策略。
- 竞品分析:了解竞争对手的商品表现,调整自身产品定位和营销策略。
- 客户细分与精准营销:基于用户行为数据对客户进行细分,实现更精准的目标市场定位和营销。
三、对消费者的意义
- 提升购物体验:个性化推荐使得消费者能够更快地找到自己感兴趣的商品,提升购物效率和满意度。
- 发现潜在需求:数据分析可能揭示消费者自己尚未意识到的需求,引导他们发现新的商品或服务。
四、对研究人员的意义
- 社会科学研究:用户行为数据是社会科学研究的宝贵资源,可以用来研究消费行为、社会网络、信息传播等多个领域。
- 数据科学与算法发展:大规模的用户行为数据为机器学习算法和数据挖掘技术提供了丰富的实验场,推动了相关技术的发展。
实验环境准备:
一:MySQL的安装:
MySQL是开源的,用户可以免费获取和使用MySQL数据库。 2. 可移植性:MySQL可以在多种操作系统上运行,包括Linux、Windows、Mac OS等。 3. 高性能:MySQL具有高效的性能和快速的查询处理能力,能够处理大规模的数据。 4. 可靠性:MySQL具有良好的稳定性和可靠性,能够保证数据的安全性和完整性。 5. 安全性:MySQL提供了多种安全特性,包括用户权限管理、数据加密等,保护数据库免受未经授权的访问和恶意攻击。 6. 灵活性:MySQL支持多种存储引擎,包括InnoDB、MyISAM等,用户可以根据需求选择合适的存储引擎。 7. 可扩展性:MySQL支持集群和分布式架构,能够满足不断增长的数据需求。
在此之前我已进行了安装,具体可以查看其他作者的安装教程:

二:Navicat Premium 17的安装:
我使用的是试用版(先体验在后续长期),大家可以通过教程去下载破解版,或者某宝购买

数据库准备:
一:在MySQL中创建相关数据库
create database taobao;
use taobao;
create table user_behavior (user_id int(9), item_id int(9), category_id int(9), behavior_type varchar(5), timestamp int(14) );
二:在Navicat Premium 通过导入向导将数据导入(但是数据量可能过大,会导致导入速度很慢)

PS:你可以通过kettle以及安装必要的JDK,通过设置运行kettle来进行数据传输,具体看官方介绍:
Kettle中文网 – Kettle安装、Kettle使用、Kettle中文 http://www.kettle.org.cn/
http://www.kettle.org.cn/
导入成功后可以看到如下:<此时的timestamp已经变成了timestamps,因为这张图是后面截取的>

数据处理与分析
一:数据预处理

1.首先我们改变字段名:将timestamp改为timestamps,避免与数据类型混淆
PS:上图是过程中的图,已经改过了 
2.接着我们检查空值项:(并没有存在)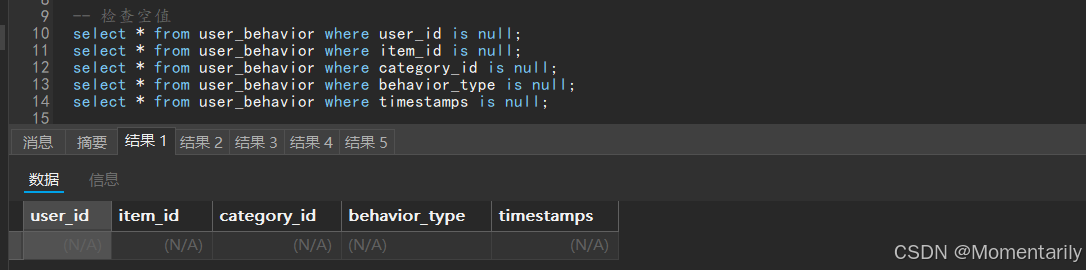
3.在去重前,我们将每一条记录添加一个id,并设置为主键
4.主键id自增后,我们可以看到相应的id数值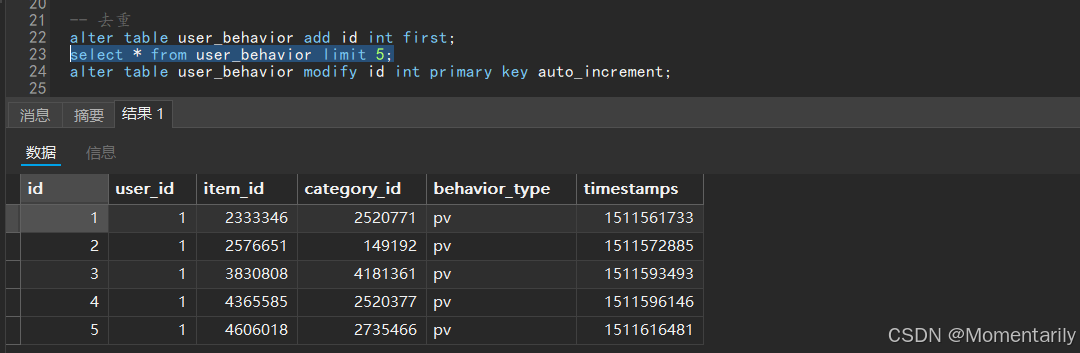
5.为了加快处理速度,我们增大buffer的值
-- 更改buffer值
show VARIABLES like '%_buffer%';
set GLOBAL innodb_buffer_pool_size=1070000000;
6.新增datetimes字段
-- datetime
alter table user_behavior add datetimes TIMESTAMP(0);
update user_behavior set datetimes=FROM_UNIXTIME(timestamps);
select * from user_behavior limit 5;
7.同理,我们添加data,time,以及hours字段(此过程非常漫长,因为我们处理的是一亿级别的数据量)

>>>>>>>>>>>>注:直接运行注释的这个,分别运行三个花费时间太长了
--在代码中直接运行这个
update user_behavior set dates=substring(datetimes,1,10),times=substring(datetimes,12,8),hours=substring(datetimes,12,2);
--不要运行这个
update user_behavior set dates=substring(datetimes,1,10);
update user_behavior set times=substring(datetimes,12,8);
update user_behavior set hours=substring(datetimes,12,2);8.最终添加了各个时间字段维度处理结果如下
9.查询一下数据的时间段,通过查看最大和最小时间段,
这里就存在异常数据>>>>>2037-04-09以及1970-01-01<<<<<<<
10.我们删除时间段不在2017-11-25 00:00:00和2017-12-03 23:59:59之间的时间段
保留从 2017-11-25 00:00:00 到 2017-12-03 23:59:59 之间共处理了5万多条数据
最终处理完的数据如下:


查看处理后最终还有多少数据>>>>>>>100095495条记录

数据预处理的SQL总体代码如下:
use taobao;
desc user_behavior;
select * from user_behavior limit 5;
-- 改变字段名
alter table user_behavior change timestamp timestamps int(14);
desc user_behavior;
-- 检查空值
select * from user_behavior where user_id is null;
select * from user_behavior where item_id is null;
select * from user_behavior where category_id is null;
select * from user_behavior where behavior_type is null;
select * from user_behavior where timestamps is null;
-- 检查重复值
select user_id,item_id,timestamps from user_behavior
group by user_id,item_id,timestamps
having count(*)>1;
-- 去重
alter table user_behavior add id int first;
select * from user_behavior limit 5;
alter table user_behavior modify id int primary key auto_increment;
delete user_behavior from
user_behavior,
(
select user_id,item_id,timestamps,min(id) id from user_behavior
group by user_id,item_id,timestamps
having count(*)>1
) t2
where user_behavior.user_id=t2.user_id
and user_behavior.item_id=t2.item_id
and user_behavior.timestamps=t2.timestamps
and user_behavior.id>t2.id;
-- 新增日期:date time hour
-- 更改buffer值
show VARIABLES like '%_buffer%';
set GLOBAL innodb_buffer_pool_size=1070000000;
-- datetime
alter table user_behavior add datetimes TIMESTAMP(0);
update user_behavior set datetimes=FROM_UNIXTIME(timestamps);
select * from user_behavior limit 5;
-- date
alter table user_behavior add dates char(10);
alter table user_behavior add times char(8);
alter table user_behavior add hours char(2);
-- update user_behavior set dates=substring(datetimes,1,10),times=substring(datetimes,12,8),hours=substring(datetimes,12,2);
update user_behavior set dates=substring(datetimes,1,10);
update user_behavior set times=substring(datetimes,12,8);
update user_behavior set hours=substring(datetimes,12,2);
select * from user_behavior limit 5;
-- 去异常
select max(datetimes),min(datetimes) from user_behavior;
delete from user_behavior
where datetimes < '2017-11-25 00:00:00'
or datetimes > '2017-12-03 23:59:59';
-- 数据概览
desc user_behavior;
select * from user_behavior limit 5;
SELECT count(1) from user_behavior; -- 100095496条记录
二:获客情况
1.首先创建temp_behavior临时表来拉取储存来自user_behavior中的10万条数据,通过小样本数据来处理避免出现失误,造成数据破坏,带来不必要的麻烦
temp_behavior临时表如下
2.首先处理临时表上的 pv,uv以及浏览深度pv/uv
3.我们对原表进行处理-- 处理真实数据user_behavior
-- 创建pv_uv_puv来存储页面浏览量,独立访客数以及浏览深度pv/uv

获客情况的SQL总代码如下
-- 创建临时表temp_behavior
create table temp_behavior like user_behavior;
-- 截取数据
insert into temp_behavior
select * from user_behavior limit 100000;
select * from temp_behavior;
-- 临时表上的页面浏览量 pv
select dates
,count(*) 'pv'
from temp_behavior
where behavior_type='pv'
GROUP BY dates;
-- 临时表上的独立访客数 uv
select dates
,count(distinct user_id) 'pv'
from temp_behavior
where behavior_type='pv'
GROUP BY dates;
-- 临时表上的 pv,uv以及浏览深度pv/uv
select dates
,count(*) 'pv'
,count(distinct user_id) 'uv'
,round(count(*)/count(distinct user_id),1) 'pv/uv'
from temp_behavior
where behavior_type='pv'
GROUP BY dates;
-- 处理真实数据user_behavior
-- 创建pv_uv_puv来存储页面浏览量,独立访客数以及浏览深度pv/uv
create table pv_uv_puv (
dates char(10),
pv int(9),
uv int(9),
puv decimal(10,1)
);
insert into pv_uv_puv
select dates
,count(*) 'pv'
,count(distinct user_id) 'uv'
,round(count(*)/count(distinct user_id),1) 'pv/uv'
from user_behavior
where behavior_type='pv'
GROUP BY dates;
select * from pv_uv_puv
delete from pv_uv_puv where dates is null;

三:留存情况
1.在获客最后统计后出现了第一行空值,通过查看,可以看到
存在一部分异常值,时间戳为负值,data time为null

2.将这一部分异常值去除

-3- 获取每个用户分别活跃的日期

4.通过自关联 来求取同一用户活跃的天数和其他天数对应 5. 初步筛选使B的date>A的Date,以便于后面做差值,求留存
5. 初步筛选使B的date>A的Date,以便于后面做差值,求留存
6.留存数 通过减法来获取前后两天差值为0,1,3及其它,来作为当天,次日,日,三日及七日留存率

7.留存率,通过对当天,次日以及三日的留存数除以最开始的活跃用户
>>>>>本次求取次日的留存率
建立一个retention_rate表来保存留存率的数据
8.跳失用户:在这段时间内只浏览一次的用户
 查询浏览用户的总数(用户总访问量)
查询浏览用户的总数(用户总访问量)
-- 所以用户的跳失率为 88/89660667还是非常极低,几乎忽略

留存情况分析SQL代码如下
select * from user_behavior where dates is null;
delete from user_behavior where dates is null;
select user_id,dates
from temp_behavior
group by user_id,dates;
-- 自关联
select * from
(select user_id,dates
from temp_behavior
group by user_id,dates
) a
,(select user_id,dates
from temp_behavior
group by user_id,dates
) b
where a.user_id=b.user_id;
-- 筛选
select * from
(select user_id,dates
from temp_behavior
group by user_id,dates
) a
,(select user_id,dates
from temp_behavior
group by user_id,dates
) b
where a.user_id=b.user_id and a.dates<b.dates;
-- 留存数
select a.dates
,count(if(datediff(b.dates,a.dates)=0,b.user_id,null)) retention_0
,count(if(datediff(b.dates,a.dates)=1,b.user_id,null)) retention_1
,count(if(datediff(b.dates,a.dates)=3,b.user_id,null)) retention_3 from
(select user_id,dates
from temp_behavior
group by user_id,dates
) a
,(select user_id,dates
from temp_behavior
group by user_id,dates
) b
where a.user_id=b.user_id and a.dates<=b.dates
group by a.dates
-- 留存率
select a.dates
,count(if(datediff(b.dates,a.dates)=1,b.user_id,null))/count(if(datediff(b.dates,a.dates)=0,b.user_id,null)) retention_1
from
(select user_id,dates
from temp_behavior
group by user_id,dates
) a
,(select user_id,dates
from temp_behavior
group by user_id,dates
) b
where a.user_id=b.user_id and a.dates<=b.dates
group by a.dates
-- 保存结果
create table retention_rate (
dates char(10),
retention_1 float
);
insert into retention_rate
select a.dates
,count(if(datediff(b.dates,a.dates)=1,b.user_id,null))/count(if(datediff(b.dates,a.dates)=0,b.user_id,null)) retention_1
from
(select user_id,dates
-- from temp_behavior
-- 纠错,这里漏改为原表了
from user_behavior
group by user_id,dates
) a
,(select user_id,dates
from user_behavior
group by user_id,dates
) b
where a.user_id=b.user_id and a.dates<=b.dates
group by a.dates
select * from retention_rate
-- 跳失率
-- 跳失用户 -- 88
select count(*)
from
(
select user_id from user_behavior
group by user_id
having count(behavior_type)=1
) a
select sum(pv) from pv_uv_puv; -- 89660670
-- 88/89660670
四:时间序列分析

在时间序列下对用户的行为进行分析,包括:
| 行为类型 | 说明 |
| pv | 商品详情页pv,等价于点击 |
| buy | 商品购买 |
| cart | 将商品加入购物车 |
| fav | 收藏商品 |
在一天中的24个小时的时间段中用户的各个行为统计,如下
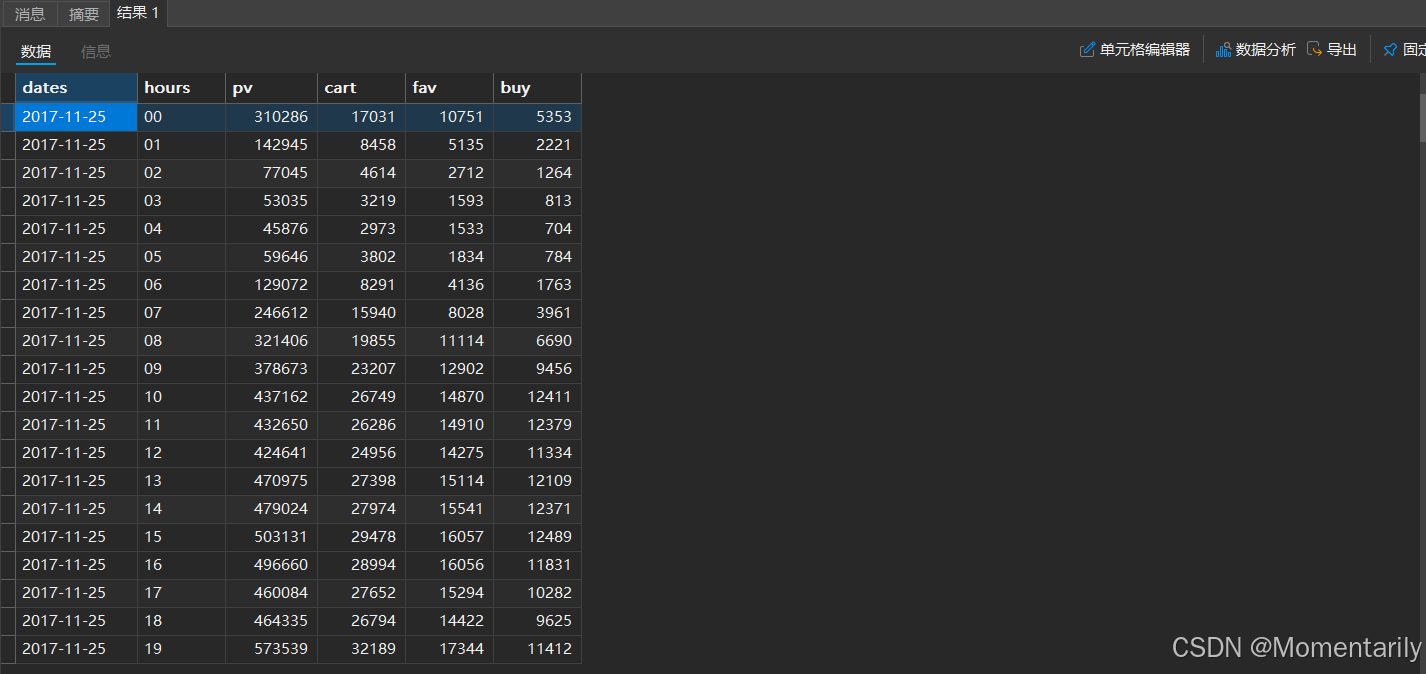

时间序列分析SQL代码:
-- 统计日期-小时的行为
select dates,hours
,count(if(behavior_type='pv',behavior_type,null)) 'pv'
,count(if(behavior_type='cart',behavior_type,null)) 'cart'
,count(if(behavior_type='fav',behavior_type,null)) 'fav'
,count(if(behavior_type='buy',behavior_type,null)) 'buy'
from temp_behavior
group by dates,hours
order by dates,hours
-- 存储
create table date_hour_behavior(
dates char(10),
hours char(2),
pv int,
cart int,
fav int,
buy int);
-- 结果插入
insert into date_hour_behavior
select dates,hours
,count(if(behavior_type='pv',behavior_type,null)) 'pv'
,count(if(behavior_type='cart',behavior_type,null)) 'cart'
,count(if(behavior_type='fav',behavior_type,null)) 'fav'
,count(if(behavior_type='buy',behavior_type,null)) 'buy'
from user_behavior
group by dates,hours
order by dates,hours
select * from date_hour_behavior;
五:用户转化率分析

初步分析

通过统计各类行为的用户数量
具体如表:
| behavior_type | user_num |
| pv(商品详情页pv,等价于点击) | 984105 |
| fav(收藏商品) | 389823 |
| cart(将商品加入购物车) | 738996 |
| buy(商品购买) | 672404 |
统计各类行为的数量 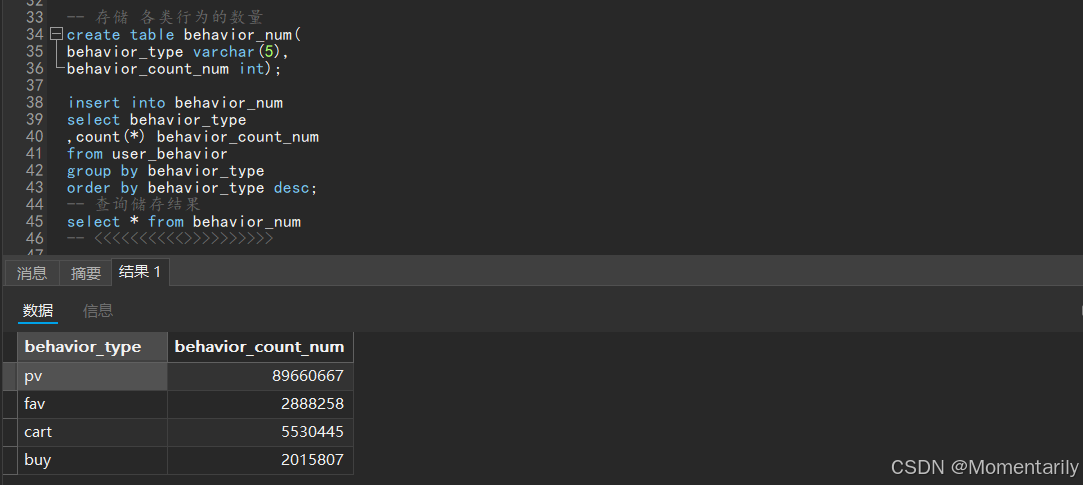
具体如表:
| behavior_type | behavior_count_num |
| pv(商品详情页pv,等价于点击) | 89660667 |
| fav(收藏商品) | 2888258 |
| cart(将商品加入购物车) | 5530445 |
| buy(购买商品) | 2015807 |
初步简易计算购买和收藏加购率


用户转化率分析SQL代码
-- 统计各类行为用户数
select behavior_type
,count(DISTINCT user_id) user_num
from temp_behavior
group by behavior_type
order by behavior_type desc;
-- 存储
create table behavior_user_num(
behavior_type varchar(5),
user_num int);
insert into behavior_user_num
select behavior_type
,count(DISTINCT user_id) user_num
from user_behavior
group by behavior_type
order by behavior_type desc;
select * from behavior_user_num
select 672404/984105 -- 这段时间购买过商品的用户的比例
-- 统计各类行为的数量
select behavior_type
,count(*) user_num
from temp_behavior
group by behavior_type
order by behavior_type desc;
-- 存储
create table behavior_num(
behavior_type varchar(5),
behavior_count_num int);
insert into behavior_num
select behavior_type
,count(*) behavior_count_num
from user_behavior
group by behavior_type
order by behavior_type desc;
select * from behavior_num
select 2015807/89660670 -- 购买率
select (2888255+5530446)/89660670 -- 收藏加购率
六:行为路径分析

对用户id和商品id进行分组,统计两者之间发生各类行为的数量
 用户行为标准化,当用户行为(pv,fav,cart,buy)大于1时记为true值"1",否者为"0"
用户行为标准化,当用户行为(pv,fav,cart,buy)大于1时记为true值"1",否者为"0"
 将0&1拼接成行为路径,以便于后续
将0&1拼接成行为路径,以便于后续
 统计各类购买行为数量
统计各类购买行为数量
 将含有0和1的数据转为人理解的意思
将含有0和1的数据转为人理解的意思
具体表达意思为
| path_type | description |
| 0001 | 直接购买了 |
| 1001 | 浏览后购买了 |
| 0011 | 加购后购买了 |
| 1011 | 浏览加购后购买了 |
| 0101 | 收藏后购买了 |
| 1101 | 浏览收藏后购买了 |
| 0111 | 收藏加购后购买了 |
| 1111 | 浏览收藏加购后购买了 |
将表与行为次数的表拼接起来,可以看到用户通过什么行为路径方式购买商品的频次
通过这种方式我们将其用到整个数据集,可以得到
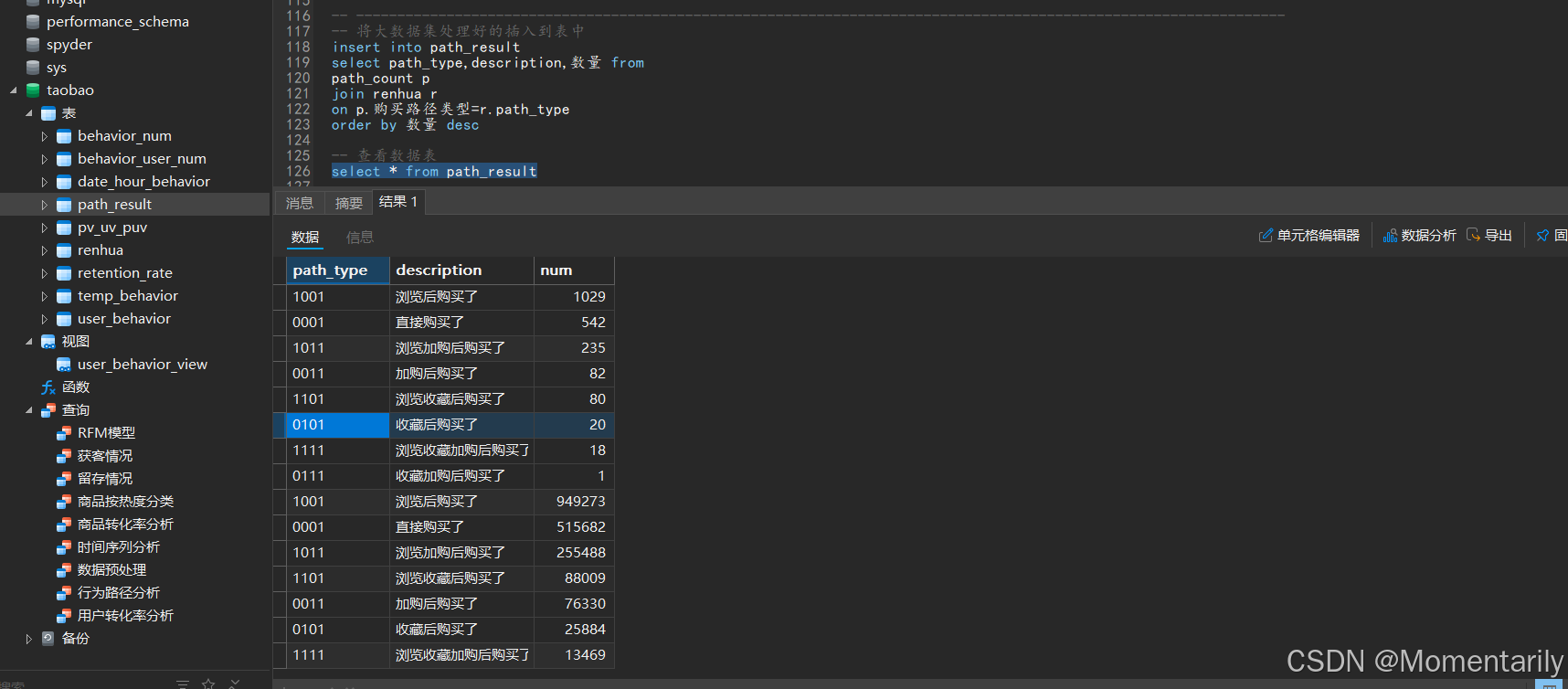
回到用户转化率部分,当时只是初步分析,我们要考虑到用户到购买这个行为中间有多种操作
首先获取直接浏览后购买量,没有在加购和收藏情况下再购买的总数
总购买量减去浏览后购买量(1528016)等于487791-----该数值为浏览后加购和收藏情况后的购买总数 大概用户行为下购买数据转化的流向
大概用户行为下购买数据转化的流向

用户行为路径分析SQL代码如下:
-- -对用户id和商品id进行分组,统计两者之间发生各类行为的数量---------------------------------------------------------------------
-- ----------------------以下操作是在小样本表上操作
create view user_behavior_view as
select user_id,item_id
,count(if(behavior_type='pv',behavior_type,null)) 'pv'
,count(if(behavior_type='fav',behavior_type,null)) 'fav'
,count(if(behavior_type='cart',behavior_type,null)) 'cart'
,count(if(behavior_type='buy',behavior_type,null)) 'buy'
from temp_behavior
group by user_id,item_id
-- 用户行为标准化,当用户行为(pv,fav,cart,buy)大于1时记为true值"1",否者为"0"
create view user_behavior_standard as
select user_id
,item_id
,(case when pv>0 then 1 else 0 end) 浏览了
,(case when fav>0 then 1 else 0 end) 收藏了
,(case when cart>0 then 1 else 0 end) 加购了
,(case when buy>0 then 1 else 0 end) 购买了
from user_behavior_view
-- 路径类型
create view user_behavior_path as
select *,
concat(浏览了,收藏了,加购了,购买了) 购买路径类型
from user_behavior_standard as a
where a.购买了>0
-- 统计各类购买行为数量
create view path_count as
select 购买路径类型
,count(*) 数量
from user_behavior_path
group by 购买路径类型
order by 数量 desc
-- 人话表
create table renhua(
path_type char(4),
description varchar(40));
insert into renhua
values('0001','直接购买了'),
('1001','浏览后购买了'),
('0011','加购后购买了'),
('1011','浏览加购后购买了'),
('0101','收藏后购买了'),
('1101','浏览收藏后购买了'),
('0111','收藏加购后购买了'),
('1111','浏览收藏加购后购买了')
select * from renhua
select * from path_count p
join renhua r
on p.购买路径类型=r.path_type
order by 数量 desc
-- ----存储
create table path_result(
path_type char(4),
description varchar(40),
num int);
-- -----------------------------------------------------------------------------------------------------
-- -以下开始在正式表上操作
-- 先删除小样本的视图
drop view user_behavior_view
drop view user_behavior_standard
drop view user_behavior_path
drop view path_count
-- -对用户id和商品id进行分组,统计两者之间发生各类行为的数量
create view user_behavior_view as
select user_id,item_id
,count(if(behavior_type='pv',behavior_type,null)) 'pv'
,count(if(behavior_type='fav',behavior_type,null)) 'fav'
,count(if(behavior_type='cart',behavior_type,null)) 'cart'
,count(if(behavior_type='buy',behavior_type,null)) 'buy'
from user_behavior
group by user_id,item_id
-- ---用户行为标准化
create view user_behavior_standard as
select user_id
,item_id
,(case when pv>0 then 1 else 0 end) 浏览了
,(case when fav>0 then 1 else 0 end) 收藏了
,(case when cart>0 then 1 else 0 end) 加购了
,(case when buy>0 then 1 else 0 end) 购买了
from user_behavior_view
-- -----路径类型
create view user_behavior_path as
select *,
concat(浏览了,收藏了,加购了,购买了) 购买路径类型
from user_behavior_standard as a
where a.购买了>0
-- ----统计各类购买行为数量
create view path_count as
select 购买路径类型
,count(*) 数量
from user_behavior_path
group by 购买路径类型
order by 数量 desc
-- -----------------------------------------------------------------------------------------------------------------
-- 将大数据集处理好的插入到表中
insert into path_result
select path_type,description,数量 from
path_count p
join renhua r
on p.购买路径类型=r.path_type
order by 数量 desc
-- 查看数据表
select * from path_result
-- 单独购买量,没有加购和收藏情况下的购买总数
select sum(buy)
from user_behavior_view
where buy>0 and fav=0 and cart=0
-- 1528016
select 2015807-1528016 AS 浏览后收藏和加购后购买量,487791/(2888258+5530445) AS 收藏和加购行为的转化率
-- 总购买量 减去 浏览后的购买量 = 收藏加购后购买的数量487791
-- 487791为为收藏加购后购买的数量 2888258+5530445为总的收藏加购数量
七:RFM模型
R值的计算:
对用户的id分组来通过用户的购买行为下所有时间中的最大时间作为最近一次购买的时间

创建rfm_model表来存储用户id和行为次数以及最近的时间
添加一列来进行评价F值分数 根据购买次数使用分数对用户进行分层
打分规则如图:
| Frequency | Fscore |
| between 100 and 262 | 5 |
| between 50 and 99 | 4 |
| between 20 and 49 | 3 |
| between 5 and 19 | 2 |
| else 1 | 1 |
添加一列来进行评价R值分数 根据最近购买时间使用分数对用户进行分层
打分规则如图:
| recent time | rscore |
| 2017-12-03 | 5 |
| 2017-12-01----2017-12-02 | 4 |
| 2017-11-29----2017-11-30 | 3 |
| '2017-11-27---2017-11-28 | 2 |
| else | 1 |
打完分后,可以看到

通过分数可以将用户分为四种用户
用户评级标准:
| 分数标准 | 用户定位 |
| fscore>@f_avg and rscore>@r_avg | 价值用户 |
| fscore>@f_avg and rscore<@r_avg | 保持用户 |
| fscore<@f_avg and rscore>@r_avg | 发展用户 |
| fscore<@f_avg and rscore<@r_avg | 挽留用户 |

统计各分区的用户数


RFM模型分析SQL代码如下
-- 最近购买时间
select user_id
,max(dates) '最近购买时间'
from temp_behavior
where behavior_type='buy'
group by user_id
order by 2 desc;
-- 购买次数
select user_id
,count(user_id) '购买次数'
from temp_behavior
where behavior_type='buy'
group by user_id
order by 2 desc;
-- 统一
select user_id
,count(user_id) '购买次数'
,max(dates) '最近购买时间'
from user_behavior
where behavior_type='buy'
group by user_id
order by 2 desc,3 desc;
-- 存储
drop table if exists rfm_model;
create table rfm_model(
user_id int,
frequency int,
recent char(10)
);
insert into rfm_model
select user_id
,count(user_id) '购买次数'
,max(dates) '最近购买时间'
from user_behavior
where behavior_type='buy'
group by user_id
order by 2 desc,3 desc;
-- 根据购买次数对用户进行分层
alter table rfm_model add column fscore int;
update rfm_model
set fscore = case
when frequency between 100 and 262 then 5
when frequency between 50 and 99 then 4
when frequency between 20 and 49 then 3
when frequency between 5 and 20 then 2
else 1
end
-- 根据最近购买时间对用户进行分层
alter table rfm_model add column rscore int;
update rfm_model
set rscore = case
when recent = '2017-12-03' then 5
when recent in ('2017-12-01','2017-12-02') then 4
when recent in ('2017-11-29','2017-11-30') then 3
when recent in ('2017-11-27','2017-11-28') then 2
else 1
end
select * from rfm_model
-- 分层
set @f_avg=null;
set @r_avg=null;
select avg(fscore) into @f_avg from rfm_model;
select avg(rscore) into @r_avg from rfm_model;
select *
,(case
when fscore>@f_avg and rscore>@r_avg then '价值用户'
when fscore>@f_avg and rscore<@r_avg then '保持用户'
when fscore<@f_avg and rscore>@r_avg then '发展用户'
when fscore<@f_avg and rscore<@r_avg then '挽留用户'
end) class
from rfm_model
-- 插入
alter table rfm_model add column class varchar(40);
update rfm_model
set class = case
when fscore>@f_avg and rscore>@r_avg then '价值用户'
when fscore>@f_avg and rscore<@r_avg then '保持用户'
when fscore<@f_avg and rscore>@r_avg then '发展用户'
when fscore<@f_avg and rscore<@r_avg then '挽留用户'
end
-- 统计各分区用户数
select class,count(user_id) from rfm_model
group by class
八:商品按热度分类

品类浏览量:统计每个品类对应id的点击次数来评判热度的高低,显示前十的品类id
 商品浏览量:统计每个商品对应id的点击次数来评判热度的高低,显示前十的商品id
商品浏览量:统计每个商品对应id的点击次数来评判热度的高低,显示前十的商品id

品类商品浏览量:同理在热门品类中的热门商品的热度同样用pv来判断,使用品类进行分组


商品热度分析的SQL代码:
-- 统计商品的热门品类、热门商品、热门品类热门商品
-- 小样本数据查看
select category_id
,count(if(behavior_type='pv',behavior_type,null)) '品类浏览量'
from temp_behavior
GROUP BY category_id
order by 2 desc
limit 10
select item_id
,count(if(behavior_type='pv',behavior_type,null)) '商品浏览量'
from temp_behavior
GROUP BY item_id
order by 2 desc
limit 10
select category_id,item_id,
品类商品浏览量 from
(
select category_id,item_id
,count(if(behavior_type='pv',behavior_type,null)) '品类商品浏览量'
-- ,rank()over(partition by category_id order by '品类商品浏览量' desc) r
-- 纠错,'品类商品浏览量'这里不能指代count(if(behavior_type='pv',behavior_type,null))因为还没返回
,rank()over(partition by category_id order by count(if(behavior_type='pv',behavior_type,null)) desc) r
from temp_behavior
GROUP BY category_id,item_id
order by 3 desc
) a
where a.r = 1
order by a.品类商品浏览量 desc
limit 10
-- ----------大数据集存储 -----------------------------------------------------------------------------------
create table popular_categories(
category_id int,
pv int);
create table popular_items(
item_id int,
pv int);
create table popular_cateitems(
category_id int,
item_id int,
pv int);
insert into popular_categories -- .................................
select category_id
,count(if(behavior_type='pv',behavior_type,null)) '品类浏览量'
from user_behavior
GROUP BY category_id
order by 2 desc
limit 10;
insert into popular_items -- .................................
select item_id
,count(if(behavior_type='pv',behavior_type,null)) '商品浏览量'
from user_behavior
GROUP BY item_id
order by 2 desc
limit 10;
insert into popular_cateitems -- .................................
select category_id,item_id,
品类商品浏览量 from
(
select category_id,item_id
,count(if(behavior_type='pv',behavior_type,null)) '品类商品浏览量'
,rank()over(partition by category_id order by count(if(behavior_type='pv',behavior_type,null)) desc) r
from user_behavior
GROUP BY category_id,item_id
order by 3 desc
) a
where a.r = 1
order by a.品类商品浏览量 desc
limit 10
-- 查看表数据.................................
select * from popular_categories;
select * from popular_items;
select * from popular_cateitems;
九:商品转化率分析
对特定商品的转化率:吸引用户占总用户的比例,也就是将付费用户id去重后的数量除以总的用户数量,并根据商品转化率进行排序
同理,如法炮制对特定品类的转化率:吸引用户占总用户的比例,也就是将付费用户id去重后的数量除以总的用户数量,并根据商品转化率进行排序

商品转化率分析的SQL代码:
-- 特定商品转化率--------------------------------------------------------
select item_id
,count(if(behavior_type='pv',behavior_type,null)) 'pv'
,count(if(behavior_type='fav',behavior_type,null)) 'fav'
,count(if(behavior_type='cart',behavior_type,null)) 'cart'
,count(if(behavior_type='buy',behavior_type,null)) 'buy'
,count(distinct if(behavior_type='buy',user_id,null))/count(distinct user_id) 商品转化率
from temp_behavior
group by item_id
order by 商品转化率 desc
-- 保存 -------------------------------------------------------------------
create table item_detail(
item_id int,
pv int,
fav int,
cart int,
buy int,
user_buy_rate float);
insert into item_detail-- ------------------------------------------------
select item_id
,count(if(behavior_type='pv',behavior_type,null)) 'pv'
,count(if(behavior_type='fav',behavior_type,null)) 'fav'
,count(if(behavior_type='cart',behavior_type,null)) 'cart'
,count(if(behavior_type='buy',behavior_type,null)) 'buy'
,count(distinct if(behavior_type='buy',user_id,null))/count(distinct user_id) 商品转化率
from user_behavior
group by item_id
order by 商品转化率 desc;
-- 查询表------------------
select * from item_detail;
-- 品类转化率 --------------------------------------------------------------
create table category_detail(
category_id int,
pv int,
fav int,
cart int,
buy int,
user_buy_rate float);
insert into category_detail-- ----------------------------------------------
select category_id
,count(if(behavior_type='pv',behavior_type,null)) 'pv'
,count(if(behavior_type='fav',behavior_type,null)) 'fav'
,count(if(behavior_type='cart',behavior_type,null)) 'cart'
,count(if(behavior_type='buy',behavior_type,null)) 'buy'
,count(distinct if(behavior_type='buy',user_id,null))/count(distinct user_id) 品类转化率
from user_behavior
group by category_id
order by 品类转化率 desc;
-- 查询表----------------------
select * from category_detail;
十:商品特征分析

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐


 26
26 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)