【科研小白系列】模型训练已经停止(强行中断)了,可GPU不释放显存,如何解决?
最近好不容易用服务器把模型跑起来了,美滋滋地看他一轮一轮训练,感觉应该没啥问题,想着一个晚上训练完肯定没问题!结果第二条早上来一看:main()这不是说我显存不够了吗!使用nvidia-smi命令查看服务器显卡使用情况:没错,我用的就是0号显卡,难道是实验室师兄师姐在训练模型?不应该呀!这个显存占用量和我模型训练的显存占用量极为相似,何况师兄师姐他们训练模型之前肯定会查看显卡的使用情况的!

- 博主简介:努力学习的22级计算机科学与技术本科生一枚🌸
- 博主主页: @Yaoyao2024
- 往期回顾: 【科研小白系列】如何远程连接实验室服务器跑代码?
- 每日一言🌼: 寂静的光辉平铺的一刻,地上的每一个坎坷都被映照得灿烂。
—— 史铁生《我与地坛》
0、前言(问题描述)
最近好不容易用服务器把模型跑起来了,美滋滋地看他一轮一轮训练,感觉应该没啥问题,想着一个晚上训练完肯定没问题!
结果第二条早上来一看:

报错信息来看:
Traceback (most recent call last):
File "myTrain.py", line 424, in <module>
main()
File "myTrain.py", line 140, in main
scores_list, test_imgs, gt_list, gt_mask_list = test(models, inference_round, fixed_fewshot_list,
File "myTrain.py", line 389, in test
embedding_vectors = embedding_concat(embedding_vectors, test_outputs[layer_name], True)
File "/Workpace_data/hfy_data/RegAD/utils/funcs.py", line 33, in embedding_concat
z = F.fold(z, kernel_size=s, output_size=(H1, W1), stride=s)
File "/home/lmf/anaconda3/env/anaconda/envs/unetr_pp/lib/python3.8/site-packages/torch/nn/functional.py", line 4811, in fold
return torch._C._nn.col2im(
torch.cuda.OutOfMemoryError: CUDA out of memory. Tried to allocate 3.71 GiB. GPU 0 has a total capacity of 47.45 GiB of which 2.01 GiB is free. Process 2244006 has 26.29 GiB memory in use. Including non-PyTorch memory, this process has 19.12 GiB memory in use. Of the allocated memory 10.43 GiB is allocated by PyTorch, and 7.42 GiB is reserved by PyTorch but unallocated. If reserved but unallocated memory is large try setting PYTORCH_CUDA_ALLOC_CONF=expandable_segments:True to avoid fragmentation. See documentation for Memory Management (https://pytorch.org/docs/stable/notes/cuda.html#environment-variables)
这不是说我显存不够了吗!
使用nvidia-smi命令查看服务器显卡使用情况:

没错,我用的就是0号显卡,难道是实验室师兄师姐在训练模型?不应该呀!这个显存占用量和我模型训练的显存占用量极为相似,何况师兄师姐他们训练模型之前肯定会查看显卡的使用情况的!
后来我又尝试运行了一下模型训练,果不其然,又报错说显存容量不足,我强行终止程序后,再查看显卡情况:
噫噫噫,这不是我程序开始运行时占用的显存吗?
哦~原来是强行终止模型训练,GPU没有释放显存的原因
一、解决方法
1、查看当前用户占用GPU情况
其实通过我前言部分的检查,大概可以证实是我强行终止程序而没有释放显存,但是以防万一,可以使用以下命令查看一下线程(看看是哪些用户在使用GPU):
top

25/1/16号记录|今天是来到新实验室的第13天,居然又遇上了这个问题,这次处理方法比上次略有不同但是更合理了.
- 首先使用
htop命令,查看当前所有用户程序占用显存的情况: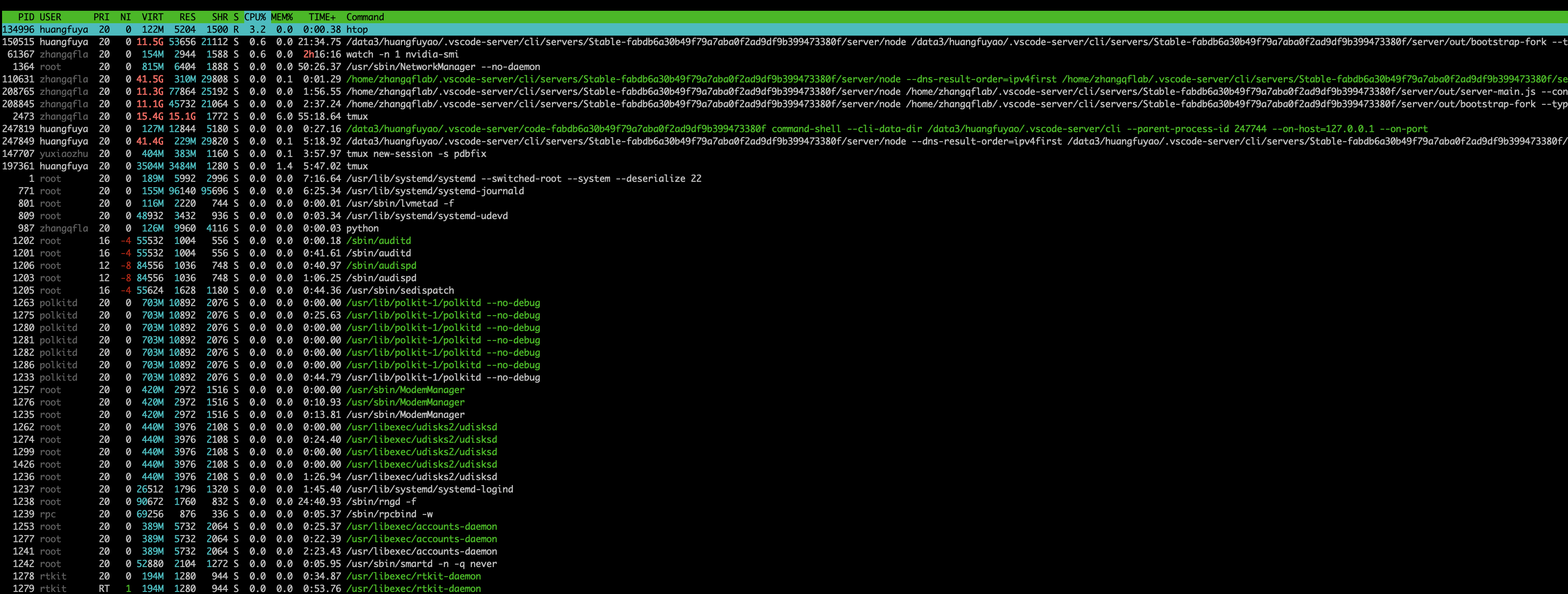
- 过滤用户进程:
按u键,选择你的用户名,htop会只显示该用户的进程。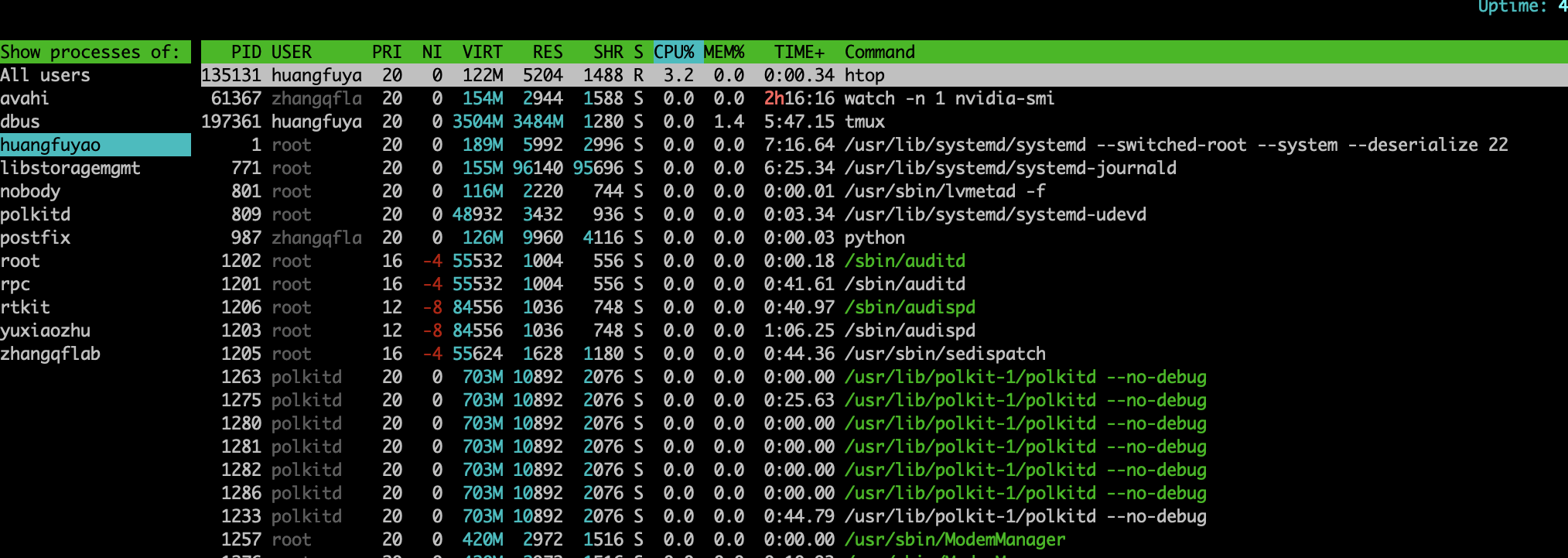
3.杀死进程
-
选择进程:用上下箭头键选中目标进程。
-
杀死进程:按
F9键,选择信号(如 SIGTERM 或 SIGKILL),然后回车确认。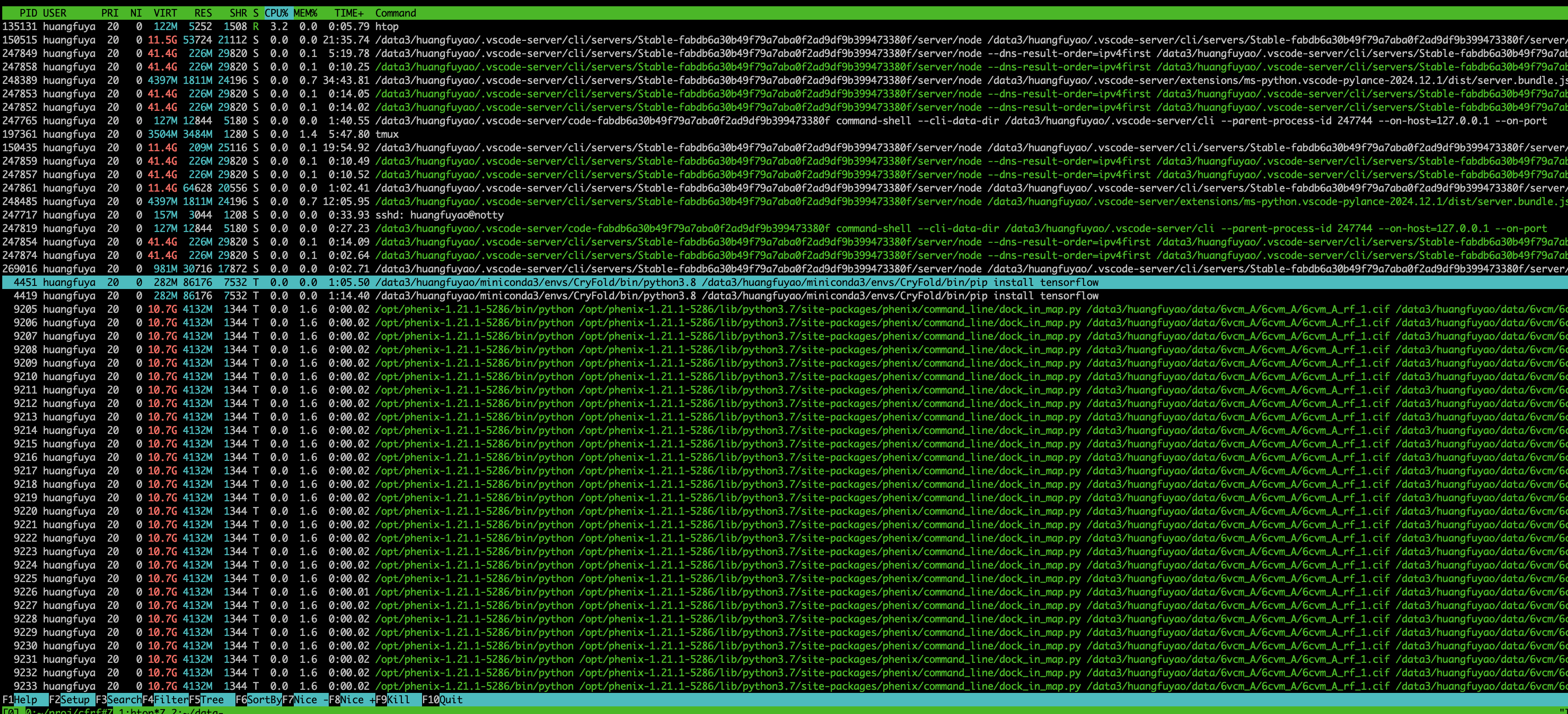
我这里选择的是
SIGKILL含义:强制终止进程。行为:进程无法捕获或忽略,会立即被终止。适用场景:进程无响应或需要立即终止时使用。
2、查看占用显卡的进程
输入以下命令,看看有哪些进程在占用哪个显卡:
nvidia-smi
可以看到,主要是以下两个程序占用了我的0号显卡:

3、kill杀死进程
采用以下命令强行终止占用GPU的进程:
kill -9 进程的PID编号
上图可以看到,我需要强行终止的是2244006和2252511号进程:
于是我依次输入以下命令即可:
kill -9 2244006
kill -9 2252511
再次查看显卡使用情况,可以看到显存已经成功被释放:

二、切换GPU
如果确实是其他人在占用GPU,可以使用以下代码来切GPU:

# 手动指定GPU设备ID,例如使用 GPU 1 和 GPU 2
os.environ["CUDA_VISIBLE_DEVICES"] = "1,2"
# 检查是否可以使用CUDA
use_cuda = torch.cuda.is_available()
# 检查GPU数量并手动选择某个GPU(例如 GPU 0)
if use_cuda:
if torch.cuda.device_count() > 1:
print(f"使用 {torch.cuda.device_count()} 个 GPUs!")
device = torch.device('cuda') # 使用所有可见的GPU
else:
device = torch.device('cuda:2') # 使用 GPU 2
else:
device = torch.device('cpu') # 如果没有CUDA则使用CPU
# 打印当前选择的设备
print(f"正在使用的设备: {device}")
可以看到成功切换到2号显卡了:

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐


 5
5 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)