【毕业设计】基于机器学习的海洋鱼类识别 目标检测 机器视觉 深度学习 人工智能 Python
毕业设计:深海鱼类数据集是一个涵盖多个鱼类家族的数据资源,包括刺尾鱼科、炮弹鱼科、鲹科、翼鱼科、隆头鱼科、笛鲷科、刺尾天使鱼科、双鞭鱼科、鹦鹉鱼科、鲣鱼科、石斑鱼科、鲨鱼和莲鱼科等。这个数据集的图像和标注信息可用于深海生物学研究、生态保护等领域。研究人员和爱好者可以通过这些数据深入了解深海鱼类的多样性和生态特征,推动相关领域的发展和保护工作。
一、背景意义
随着全球海洋生态环境的变化,深海鱼类的监测和研究变得愈加重要。深海鱼类在维持海洋生态平衡、促进生物多样性方面发挥着关键作用。传统的鱼类识别方法往往依赖人工观测,效率低且容易受到主观因素的影响。随着深度学习技术的发展,利用计算机视觉和图像识别方法对深海鱼类进行自动检测和分类,已成为一个重要的研究方向。深海鱼类数据集的构建能够支持深度学习模型的训练,自动化鱼类识别过程,提高监测效率,减少人工成本。准确识别和分类深海鱼类有助于科学家更好地理解鱼类的生态习性和分布情况,为海洋生态保护政策的制定提供数据支持。
二、数据集
2.1数据采集
首先,需要大量的深海鱼类图像。为了获取这些数据,可以采取了以下几种方式:
-
网络爬虫:使用Python的
BeautifulSoup和Selenium编写了一个网络爬虫,从公开的图片网站、社交媒体和一些开源图片库中抓取了大量图片。在抓取过程中,确保每张图片都有清晰的目标物体,并且避免重复图片。 -
开源数据集:从网上下载了一些公开的数据集。这些数据集为项目提供了一个良好的起点,尤其在数据量不足时,它们可以极大地提高模型训练的效果。
-
自定义照片:为了增加数据的多样性,还拍摄了一些照片,包括不同的品种、背景和光照条件,以确保数据的丰富性和代表性。
在收集到大量图片后,对这些原始数据进行了清洗和筛选:
-
去除低质量图片:一些图像模糊、分辨率过低或者有其他物体干扰的图片被剔除掉。确保每张图片都能清晰地展示深海鱼类特征是数据质量的关键。
-
统一格式:将所有图片转换为统一的JPEG格式,并将图片的分辨率统一到256x256像素,这样可以在后续的训练中减少不必要的图像缩放操作,保证数据的一致性。
-
分类整理:将所有图片按照类别进行分类,分别放入对应文件夹中。每个类别的文件夹下严格只包含对应的图片,避免数据集出现混乱。
2.2数据标注
收集的数据通常是未经处理的原始数据,需要进行标注以便模型训练。数据标注的方式取决于任务的类型:
- 分类任务:为每个数据样本分配类别标签。
- 目标检测:标注图像中的每个目标,通常使用边界框。
- 语义分割:为每个像素分配一个类别标签。
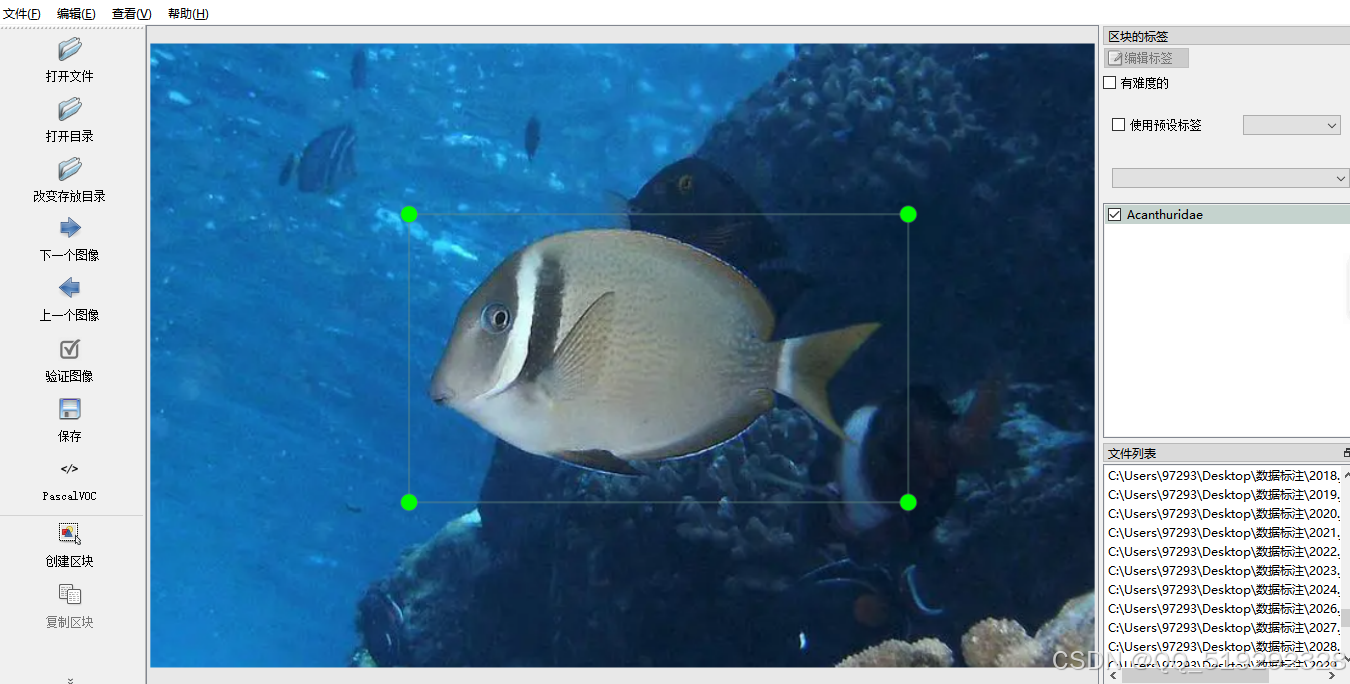
在标注深海鱼类数据集的过程中,每一张图像都展示了不同种类的鱼,如刺尾鱼、触须鱼和鲷鱼等,形态各异,颜色和纹理丰富。为了准确标注,需要仔细观察每条鱼的特征,确保边界框紧密包围目标,避免误标和漏标。然而,图像拍摄条件多变,有时光线不足或背景复杂,增加了标注的难度。标注过程中,逐一打开图像,使用标注工具绘制边界框,切换标签,准确性要求极高。随着工作量的增加,这项任务不仅考验耐心和细致,还需要对鱼类有深入的了解。经过反复检查标注结果,以确保数据的质量,这一过程虽然繁琐,却为深度学习模型的训练提供了可靠基础,助力深海生态研究的深入开展。
包含680张观赏鱼图片,数据集中包含以下几种类别
- 刺尾鱼:体型扁平,身体呈椭圆形,色彩鲜艳,常见的有蓝色、黄色和绿色等。
- 触须鱼:体型较小,身体呈圆形或长方形,具有坚硬的鳞片和明显的触须。
- 鲹鱼:体型流线型,游速较快,通常呈银色,适合在深海中游动。
- 扁鱼:体型扁平,背鳍和腹鳍发达,颜色多为明亮的黄色或蓝色。
- 隆头鱼:外形多样,身体长而侧扁,色彩鲜艳,栖息于珊瑚礁。
- 鲷鱼:体型较大,呈长椭圆形,嘴部突出,具有尖锐的牙齿。
- 天使鱼:色彩斑斓,身体呈椭圆形,通常有明显的条纹或斑点。
- 小丑鱼:体型较小,呈橙色,身体两侧有明显的黑色条纹,活泼好动。
- 鹦嘴鱼:嘴部喙状,体型较大,颜色鲜艳,以藻类为主食。
- 鲔鱼:体型流线型,游速极快,通常呈银色或蓝色,是重要的经济鱼类。
- 石斑鱼:体型较大,形状扁平,颜色斑驳,性格好斗,领地性强。
- 鲨鱼:顶级捕食者,体型巨大,流线型,具有强大的牙齿和敏锐的嗅觉。
- 摩尔鱼:外形独特,体型扁平,呈现鲜艳的颜色,性格温和。
2.3数据预处理
数据预处理是海洋鱼类数据集制作过程中至关重要的一步,旨在为后续模型训练做好充分准备。首先,通过统一图像尺寸,确保所有输入数据维度一致,以便模型能够高效处理。接着,采用数据增强技术,如旋转、翻转、裁剪和颜色调整,来增加数据集的多样性,从而提高模型的泛化能力,这些变换使得模型能够学习到不同视角和环境下的鱼类特征。
规范化分类标签格式确保每个图像的标签与其对应的边界框一致,便于在训练过程中快速读取和校验。最后,数据集应按照训练集、验证集和测试集的比例进行合理划分,通常采用70%、15%、15%的分配方式,这样既能保证模型在训练期间学习到丰富的特征,又能在验证和测试阶段有效评估其性能。通过这些系统的预处理步骤,最终得到的数据集将具备良好的结构和高质量的样本,为深度学习模型的训练提供坚实的基础,从而提升模型在实际应用中的准确性和可靠性,确保其在复杂海洋环境下的有效性。
标注格式:
- VOC格式 (XML)
- YOLO格式 (TXT)
yolo_dataset/
│
├── train/
│ ├── images/
│ │ ├── image1.jpg
│ │ ├── image2.jpg
│ │ ├── ...
│ │
│ └── labels/
│ ├── image1.txt
│ ├── image2.txt
│ ├── ...
│
└── test...
└── valid...
voc_dataset/
│
├── train/
│ ├───├
│ │ ├── image1.xml
│ │ ├── image2.xml
│ │ ├── ...
│ │
│ └───├
│ ├── image1.jpg
│ ├── image2.jpg
│ ├── ...
│
└── test...
└── valid...三、模型训练
3.1理论技术
在深度学习中,卷积神经网络(CNN)是一种非常适合海洋鱼类检测的算法。CNN因其在图像处理和分类任务中的出色表现,广泛应用于物体识别、图像分割以及其他计算机视觉任务。卷积神经网络主要由以下几层组成:
- 输入层:接收原始图像数据,通常为三维张量(宽度、高度、通道数)。
- 卷积层:使用卷积操作提取图像特征,通过多个滤波器(卷积核)对输入图像进行卷积运算,生成特征图。这一层能够捕捉图像中的局部特征,如边缘、纹理等。
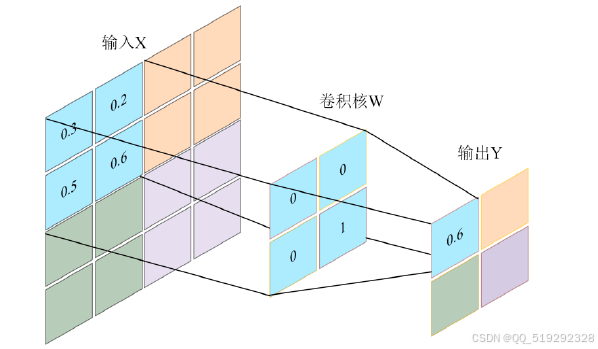
- 激活层:通常使用非线性激活函数(如ReLU)增加网络的非线性表达能力,使其能够学习更复杂的特征。

- 池化层:通过下采样操作(如最大池化或平均池化)减少特征图的尺寸,从而降低计算复杂度,减轻过拟合,并保留重要特征。
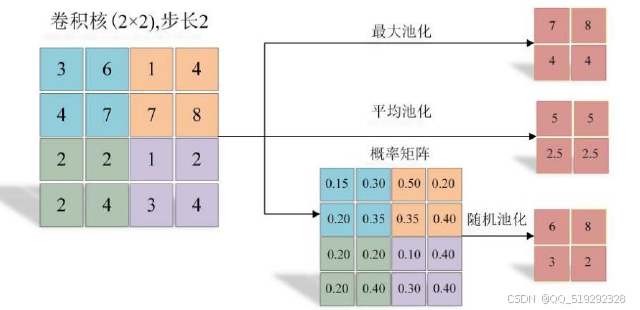
- 全连接层:将提取的特征进行整合,进行最终分类或回归,通常位于网络的最后部分。
卷积神经网络在海洋鱼类检测中具备多种优势,使其成为理想的选择:
- 特征自动学习:CNN能够自动从输入图像中学习有效特征,无需手动设计特征提取方法,特别适合处理复杂的海洋环境和多样化的鱼类特征。
- 局部连接与权重共享:通过局部连接,CNN显著减少了参数数量,提高了训练效率。此外,权重共享机制降低了计算成本,使模型在面对大规模数据集时更加高效。
- 平移不变性:CNN能够处理图像中物体的平移变换,即使鱼类在图像中的位置发生变化,模型仍然能够准确识别。这一特性在处理动态水下环境时尤为重要。
- 深层次特征表示:随着网络深度的增加,CNN能够提取更高层次的抽象特征,使得模型能够理解复杂的图像内容,提升识别精度。

卷积神经网络因其强大的特征学习能力和高效的处理方式,成为海洋鱼类检测中最为适合的深度学习算法。通过深入理解CNN的基本结构和优势,结合实际应用场景,研究人员能够更好地利用这一技术,提高鱼类识别的准确性和效率,为海洋生态保护与管理提供有力支持。
3.2模型训练
步骤一:数据集准备
在项目开发中,首先需要准备深海鱼类数据集。这包括下载数据集并按照 YOLO 格式标注每张图片,确保每张图片对应一个.txt文件,其中包含物体类别和位置信息。此外,还需要将数据集划分为训练集和测试集,以便进行模型训练和评估。
def download_dataset(url):
# 实现下载数据集的代码
pass
dataset_url = "http://example.com/deep_sea_fish_dataset.zip"
download_dataset(dataset_url)
# 标注图片
# 假设每张图片都有对应的标注文件,可以使用标注工具进行标注
# 划分数据集为训练集和测试集
# 假设有一个函数可以帮助划分数据集
def split_dataset(dataset_path, train_ratio=0.8):
# 实现数据集划分的代码
pass
dataset_path = "/path/to/deep_sea_fish_dataset"
train_ratio = 0.8 # 80% 的数据用于训练
split_dataset(dataset_path, train_ratio)步骤二:模型训练
在数据集准备好后,接下来是模型训练阶段。使用 YOLO 框架,如 Darknet 或 YOLOv5,进行模型训练。这涉及配置相应的.cfg文件和.data文件,并开始训练模型,调整参数如图像大小、批量大小、训练周期等以获得最佳性能。
# 使用 YOLOv5 进行模型训练
# 这里假设已经准备好数据集并且已经配置好.cfg和.data文件
# 导入必要的库
from yolov5 import train
# 配置文件路径
cfg_file = "/path/to/your/yolov5.cfg"
data_file = "/path/to/your/data.yaml"
# 开始模型训练
train(cfg=cfg_file, data=data_file, img_size=416, batch_size=16, epochs=50)步骤三:模型评估
在模型训练完成后,需要在测试集上对训练好的模型进行评估。这包括计算模型在测试集上的性能指标,如 mAP(平均精度均值),以评估模型的准确性和泛化能力。
# 在测试集上评估训练好的模型
# 这里假设已经训练好了模型并且有测试集数据
# 导入必要的库
from yolov5 import evaluate
# 配置文件路径
cfg_file = "/path/to/your/yolov5.cfg"
data_file = "/path/to/your/data.yaml"
weights_file = "/path/to/your/trained_model_weights.pt"
# 进行模型评估
evaluate(cfg=cfg_file, data=data_file, weights=weights_file)步骤四:模型部署
最后一步是将训练好的模型部署到生产环境中进行推理。可以使用 OpenCV 或其他库加载模型进行推理,针对深海环境的特点进行必要的优化和调整,确保模型在实际应用中表现良好。
# 加载模型进行推理
# 这里假设已经训练好了模型并且准备将其部署到生产环境中
# 导入必要的库
import cv2
import torch
from yolov5 import Model
# 加载训练好的模型
model_path = "/path/to/your/trained_model_weights.pt"
model = Model(model_path)
# 进行推理
def inference(image_path):
img = cv2.imread(image_path)
results = model.predict(img)
return results
# 示例图片路径
image_path = "/path/to/your/test_image.jpg"
results = inference(image_path)
print(results)四、总结
海洋鱼类识别技术正在快速发展,旨在自动识别和分类各类海洋鱼类。深海鱼类数据集是一个涵盖多个鱼类家族的数据资源,包括刺尾鱼科、炮弹鱼科、鲹科、翼鱼科、隆头鱼科、笛鲷科、刺尾天使鱼科、双鞭鱼科、鹦鹉鱼科、鲣鱼科、石斑鱼科、鲨鱼和莲鱼科等。通过构建涵盖多种鱼类的丰富数据集,并进行精确标注,研究人员可以利用深度学习算法(如卷积神经网络)进行高效的图像分类和识别。研究人员和爱好者可以通过这些数据深入了解深海鱼类的多样性和生态特征,推动相关领域的发展和保护工作。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐



 26
26 0
0- 0



 已为社区贡献19条内容
已为社区贡献19条内容

所有评论(0)