通过MindSpore API实现深度学习模型
简单的理解这个过程,首先加载数据集,配置网络,然后进行模型训练,经过不断的训练提高准确度,尝试去保存模型,方便下次使用,然后试着加载模型。看看实际操作结果如果。整个过程顺风顺水还是非常方便的操作。
快速入门
将相应的包逐一导入到项目中,这是制作项目的第一步。
import mindspore
from mindspore import nn
from mindspore.dataset import vision, transforms
from mindspore.dataset import MnistDataset处理数据集
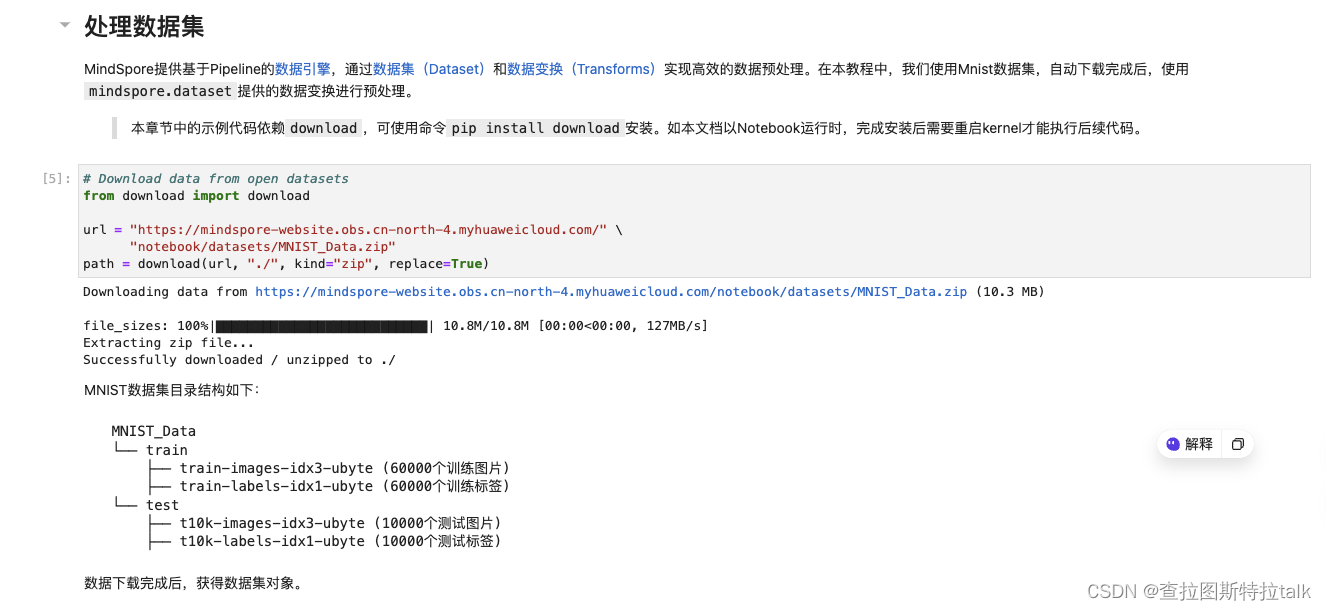
先从网上下载对应的数据集文件,MindSpore提供基于Pipeline的数据引擎,通过数据集(Dataset)和数据变换(Transforms)实现高效的数据预处理
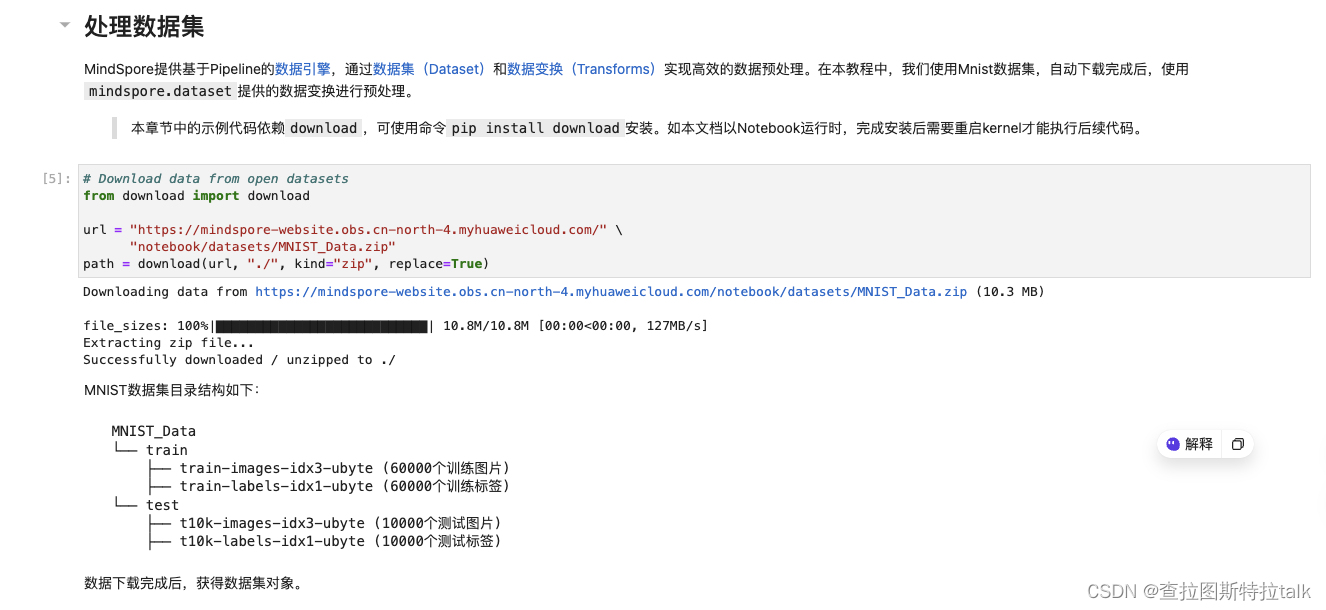
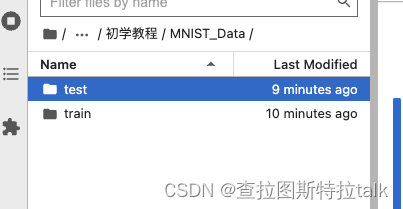
下载完,你就可以看到对应的文件了,获得数据集对象
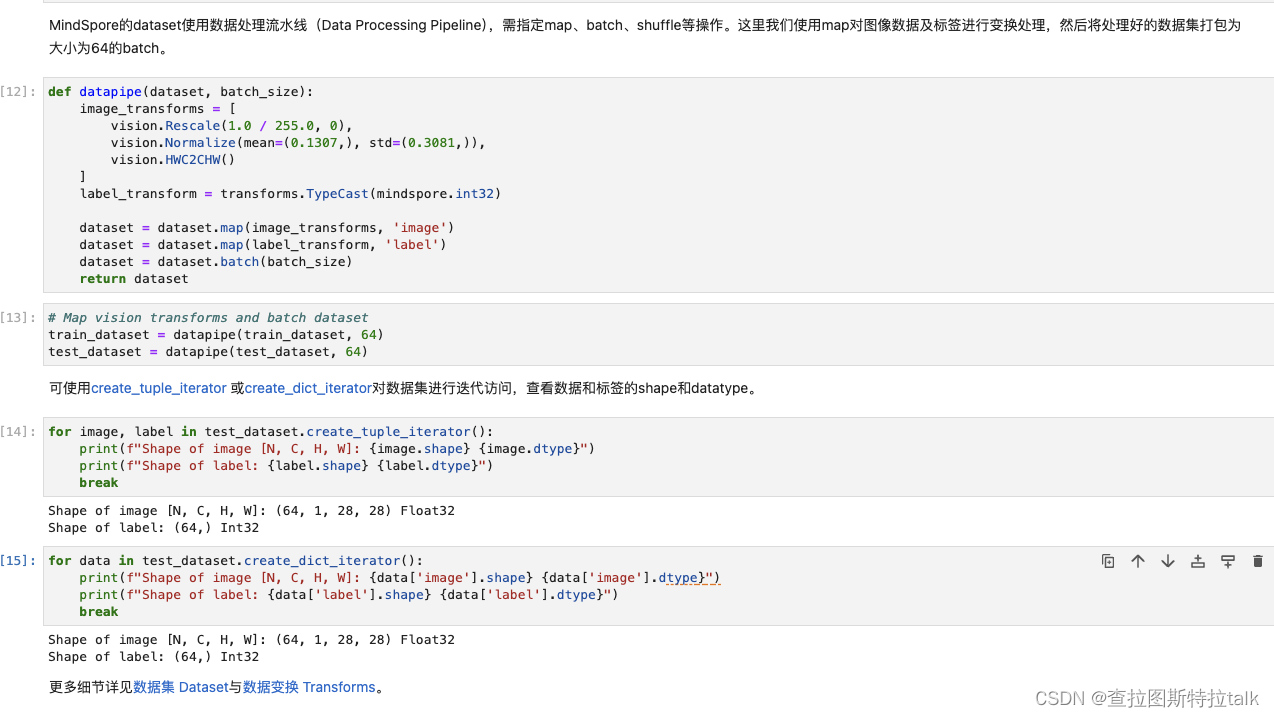
MindSpore的dataset使用数据处理流水线(Data Processing Pipeline),需指定map、batch、shuffle等操作。这里我们使用map对图像数据及标签进行变换处理,然后将处理好的数据集打包为大小为64的batch。
网络构建
mindspore.nn 类是构建网络的基类,也是网络的基本单元。用户可以继承 nn.Cell 类,并重写 __init__ 方法和 construct 方法来自定义网络。在 __init__ 中定义网络层,在 construct 中进行数据的变换。
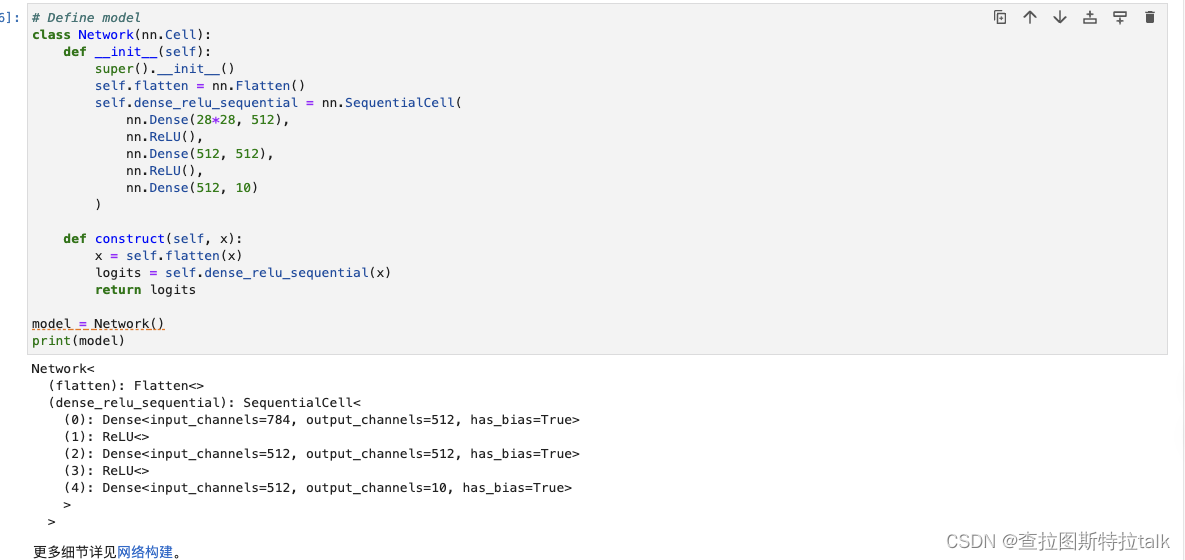
模型训练
在模型训练中,一个完整的训练过程(step)需要实现以下三步:
- 正向计算:模型预测结果(logits),并与正确标签(label)求预测损失(loss)。
- 反向传播:利用自动微分机制,自动求模型参数(parameters)对于loss的梯度(gradients)。
- 参数优化:将梯度更新到参数上。
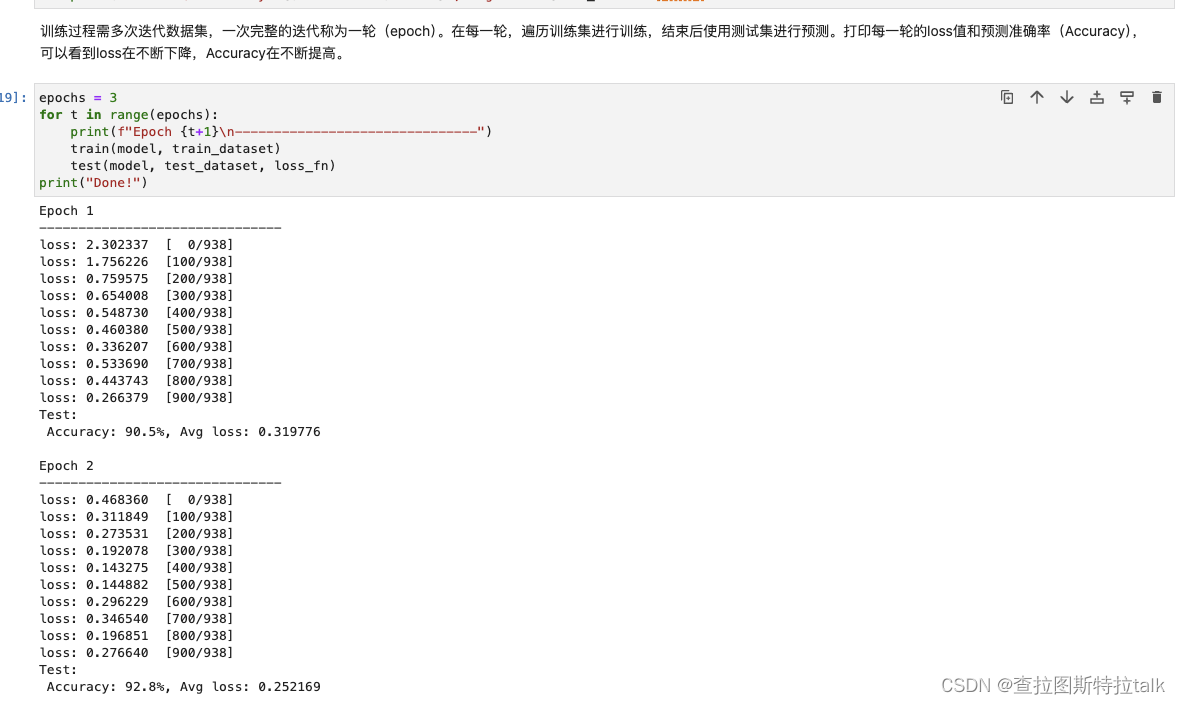

除训练外,我们定义测试函数,用来评估模型的性能。训练模型需要多次迭代数据集,每次完整的迭代称为一轮。在每一轮中,遍历训练集进行训练,然后使用测试集进行预测。打印每一轮的loss值和预测准确率,可以观察到loss在不断下降,准确率在不断提高。
保存模型
模型训练完成后,需要将其参数进行保存,留着下次继续使用。
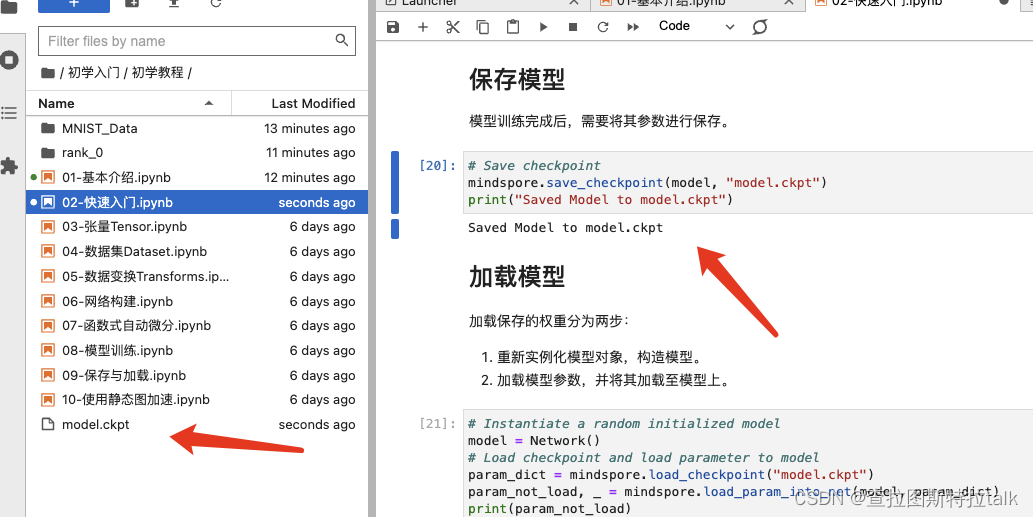
加载模型
加载保存的权重分为两步:
- 重新实例化模型对象,构造模型。
- 加载模型参数,并将其加载至模型上。
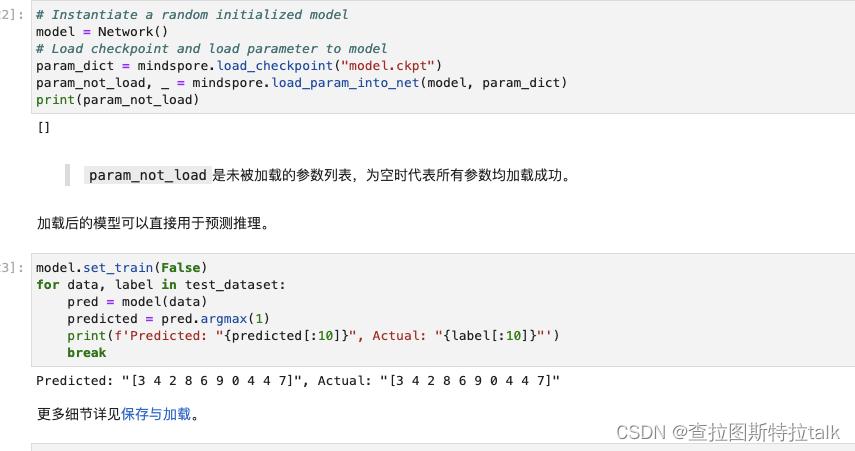
加载后的模型可以直接用于预测推理,继续对结果进行训练。
总结
简单的理解这个过程,首先加载数据集,配置网络,然后进行模型训练,经过不断的训练提高准确度,尝试去保存模型,方便下次使用,然后试着加载模型。看看实际操作结果如果。整个过程顺风顺水还是非常方便的操作。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐



 7
7 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)