
【PyTorch 实战4:DeepLabv3+图像分割模型】10min揭秘 DeepLabv3+ 分割网络架构、工作原理以及pytorch代码实现(附代码实现!)
本文将详细介绍DeepLabv3+这一图像分割模型的基本原理、关键公式,并给出了PyTorch的实现代码
PyTorch实战技术博客:图像分割模型DeepLab的详解与实现
一、背景
在深度学习领域,图像分割是一项重要的任务,与图像分类不同,它要求算法对图像中的每个像素进行分类,以识别不同的对象或区域。DeepLab系列模型是这一领域的佼佼者,以其对复杂场景的出色理解能力和对物体边缘的精准捕捉而著称。本文将详细介绍DeepLabv3+这一版本模型的基本原理、关键公式,并给出了PyTorch的实现代码。
二、原理

DeepLabv3+模型的整体框架图如上所示,其的核心思想是利用深度卷积神经网络(CNN)提取图像特征,并结合空洞卷积(Atrous Convolution,也称为扩张卷积)和空洞空间金字塔池化(Atrous Spatial Pyramid Pooling,ASPP)等技术,以捕获多尺度上下文信息,利用编码-解码结构,提高模型对图像中不同大小物体的分割能力。

如图所示,空洞卷积可以理解为“规则地选择性读取特征层信息”,与传统地padding不同,它通过在卷积核中插入零值来增大感受野,从而在不增加计算量的前提下,获取更多的上下文信息。而ASPP模块则通过并行使用不同扩张率的空洞卷积层,以捕获不同尺度的特征信息,并通过全局平均池化层获取整体图像特征,最后将这些特征进行融合,以提高模型对复杂场景的适应能力。
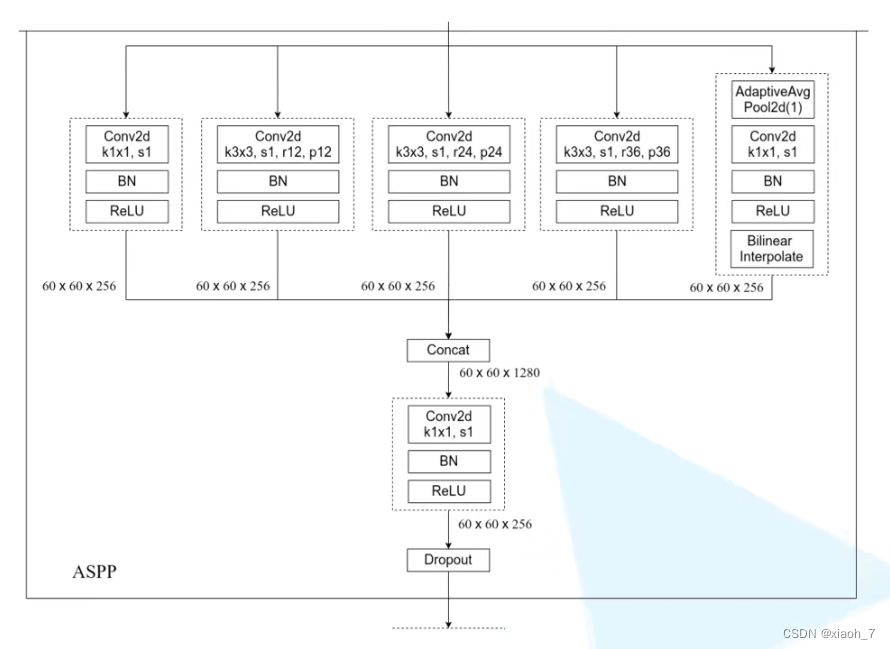
三、公式
在DeepLab模型中,空洞卷积的计算公式如下:
[ y[i] = \sum_{k} x[i + r \cdot k] \cdot w[k] ]
其中, x x x 是输入特征图, y y y 是输出特征图, w w w 是卷积核, r r r 是扩张率, k k k 是卷积核的索引。通过调整扩张率 r r r,可以改变空洞卷积的感受野大小。
ASPP模块中的全局平均池化层则是对输入特征图进行全局平均操作,得到整体图像特征。其计算公式如下:
[ z_i = \frac{1}{H \times W} \sum_{j=1}^{H} \sum_{k=1}^{W} x_{ijk} ]
其中, x x x 是输入特征图, z z z 是全局平均池化后的特征图, H H H 和 W W W 分别是特征图的高度和宽度。
四、实现代码
- Backbone部分的代码(以mobilenet v2为backbone)
class MobileNetV2(nn.Module):
def __init__(self, downsample_factor=8, pretrained=True):
super(MobileNetV2, self).__init__()
from functools import partial
model = mobilenetv2(pretrained)
self.features = model.features[:-1]
self.total_idx = len(self.features)
self.down_idx = [2, 4, 7, 14]
if downsample_factor == 8:
for i in range(self.down_idx[-2], self.down_idx[-1]):
self.features[i].apply(
partial(self._nostride_dilate, dilate=2)
)
for i in range(self.down_idx[-1], self.total_idx):
self.features[i].apply(
partial(self._nostride_dilate, dilate=4)
)
elif downsample_factor == 16:
for i in range(self.down_idx[-1], self.total_idx):
self.features[i].apply(
partial(self._nostride_dilate, dilate=2)
)
def _nostride_dilate(self, m, dilate):
classname = m.__class__.__name__
if classname.find('Conv') != -1:
if m.stride == (2, 2):
m.stride = (1, 1)
if m.kernel_size == (3, 3):
m.dilation = (dilate // 2, dilate // 2)
m.padding = (dilate // 2, dilate // 2)
else:
if m.kernel_size == (3, 3):
m.dilation = (dilate, dilate)
m.padding = (dilate, dilate)
def forward(self, x):
low_level_features = self.features[:4](x)
x = self.features[4:](low_level_features)
return low_level_features, x
- ASPP部分的代码
class ASPP(nn.Module):
def __init__(self, dim_in, dim_out, rate=1, bn_mom=0.1):
super(ASPP, self).__init__()
self.branch1 = nn.Sequential(
nn.Conv2d(dim_in, dim_out, 1, 1, padding=0, dilation=rate, bias=True),
nn.BatchNorm2d(dim_out, momentum=bn_mom),
nn.ReLU(inplace=True),
)
self.branch2 = nn.Sequential(
nn.Conv2d(dim_in, dim_out, 3, 1, padding=6 * rate, dilation=6 * rate, bias=True),
nn.BatchNorm2d(dim_out, momentum=bn_mom),
nn.ReLU(inplace=True),
)
self.branch3 = nn.Sequential(
nn.Conv2d(dim_in, dim_out, 3, 1, padding=12 * rate, dilation=12 * rate, bias=True),
nn.BatchNorm2d(dim_out, momentum=bn_mom),
nn.ReLU(inplace=True),
)
self.branch4 = nn.Sequential(
nn.Conv2d(dim_in, dim_out, 3, 1, padding=18 * rate, dilation=18 * rate, bias=True),
nn.BatchNorm2d(dim_out, momentum=bn_mom),
nn.ReLU(inplace=True),
)
self.branch5_conv = nn.Conv2d(dim_in, dim_out, 1, 1, 0, bias=True)
self.branch5_bn = nn.BatchNorm2d(dim_out, momentum=bn_mom)
self.branch5_relu = nn.ReLU(inplace=True)
self.conv_cat = nn.Sequential(
nn.Conv2d(dim_out * 5, dim_out, 1, 1, padding=0, bias=True),
nn.BatchNorm2d(dim_out, momentum=bn_mom),
nn.ReLU(inplace=True),
)
def forward(self, x):
[b, c, row, col] = x.size()
# 一共五个分支
conv1x1 = self.branch1(x)
conv3x3_1 = self.branch2(x)
conv3x3_2 = self.branch3(x)
conv3x3_3 = self.branch4(x)
# -----------------------------------------#
# 第五个分支,全局平均池化+卷积
# -----------------------------------------#
global_feature = torch.mean(x, 2, True)
global_feature = torch.mean(global_feature, 3, True)
global_feature = self.branch5_conv(global_feature)
global_feature = self.branch5_bn(global_feature)
global_feature = self.branch5_relu(global_feature)
global_feature = F.interpolate(global_feature, (row, col), None, 'bilinear', True)
# -----------------------------------------#
# 将五个分支的内容堆叠起来
# 然后1x1卷积整合特征。
# -----------------------------------------#
feature_cat = torch.cat([conv1x1, conv3x3_1, conv3x3_2, conv3x3_3, global_feature], dim=1)
result = self.conv_cat(feature_cat)
return result
- 基于PyTorch实现的DeepLabV3+模型的整体简化版代码示例:
import torch
import torch.nn as nn
class ASPP(nn.Module):
def __init__(self, in_channels, out_channels):
super(ASPP, self).__init__()
# ... 定义不同扩张率的空洞卷积层和全局平均池化层 ...
def forward(self, x):
# ... 对输入特征图应用空洞卷积和全局平均池化 ...
# ... 将得到的特征进行融合 ...
return fused_features
class DeepLabV3Plus(nn.Module):
def __init__(self, num_classes):
super(DeepLabV3Plus, self).__init__()
# ... 定义骨干网络(如ResNet50)和ASPP模块 ...
def forward(self, x):
# ... 骨干网络提取特征 ...
features = self.backbone(x)
# ... ASPP模块捕获多尺度上下文信息 ...
aspp_features = self.aspp(features)
# ... 解码器模块生成分割结果 ...
# ... ...
return segmentation_map
# 实例化模型并传入输入数据
model = DeepLabV3Plus(num_classes=21) # 假设有21个类别
input_tensor = torch.randn(1, 3, 512, 512) # 假设输入为1张512x512的RGB图像
output = model(input_tensor)
- 完整代码
class DeepLab(nn.Module):
def __init__(self, num_classes, backbone="mobilenet", pretrained=True, downsample_factor=16):
super(DeepLab, self).__init__()
if backbone == "xception":
# ----------------------------------#
# 获得两个特征层
# 浅层特征 [128,128,256]
# 主干部分 [30,30,2048]
# ----------------------------------#
self.backbone = xception(downsample_factor=downsample_factor, pretrained=pretrained)
in_channels = 2048
low_level_channels = 256
elif backbone == "mobilenet":
# ----------------------------------#
# 获得两个特征层
# 浅层特征 [128,128,24]
# 主干部分 [30,30,320]
# ----------------------------------#
self.backbone = MobileNetV2(downsample_factor=downsample_factor, pretrained=pretrained)
in_channels = 320
low_level_channels = 24
else:
raise ValueError('Unsupported backbone - `{}`, Use mobilenet, xception.'.format(backbone))
# -----------------------------------------#
# ASPP特征提取模块
# 利用不同膨胀率的膨胀卷积进行特征提取
# -----------------------------------------#
self.aspp = ASPP(dim_in=in_channels, dim_out=256, rate=16 // downsample_factor)
# ----------------------------------#
# 浅层特征边
# ----------------------------------#
self.shortcut_conv = nn.Sequential(
nn.Conv2d(low_level_channels, 48, 1),
nn.BatchNorm2d(48),
nn.ReLU(inplace=True)
)
self.cat_conv = nn.Sequential(
nn.Conv2d(48 + 256, 256, 3, stride=1, padding=1),
nn.BatchNorm2d(256),
nn.ReLU(inplace=True),
nn.Dropout(0.5),
nn.Conv2d(256, 256, 3, stride=1, padding=1),
nn.BatchNorm2d(256),
nn.ReLU(inplace=True),
nn.Dropout(0.1),
)
self.cls_conv = nn.Conv2d(256, num_classes, 1, stride=1)
def forward(self, x):
H, W = x.size(2), x.size(3)
# -----------------------------------------#
# 获得两个特征层
# low_level_features: 浅层特征-进行卷积处理
# x : 主干部分-利用ASPP结构进行加强特征提取
# -----------------------------------------#
low_level_features, x = self.backbone(x)
x = self.aspp(x)
low_level_features = self.shortcut_conv(low_level_features)
# -----------------------------------------#
# 将加强特征边上采样
# 与浅层特征堆叠后利用卷积进行特征提取
# zykandqss
# -----------------------------------------#
x = F.interpolate(x, size=(low_level_features.size(2), low_level_features.size(3)), mode='bilinear',
align_corners=True)
x = self.cat_conv(torch.cat((x, low_level_features), dim=1))
x = self.cls_conv(x)
x = F.interpolate(x, size=(H, W), mode='bilinear', align_corners=True)
return x
五、结果
通过在PASCAL VOC等数据集上进行训练和测试,我们可以得到DeepLabV3+模型的性能评估结果。通常,我们会使用像素精度(Pixel Accuracy)、均方误差(Mean Squared Error, MSE)、交并比(Intersection over Union, IoU)等指标来衡量模型的性能。在PASCAL VOC数据集上,DeepLabV3+模型通常能够取得较高的像素精度和IoU值,表现出色。
六、参考资料
- Liang-Chieh Chen, et al. “DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs.” IEEE
- 博客:《憨批的语义分割重制版9——Pytorch 搭建自己的DeeplabV3+语义分割平台》
版权声明
本博客内容仅供学习交流,转载请注明出处。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐


 28
28 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)