从C/C++源代码到可执行文件
工具类底层编程知识,了解编程语言到可执行文件的步骤和过程
1、程序编译流程
-
HelloWorld的C程序: hello.c
#include <stdio.h> int main(){ printf("Hello World.\n"); return 0; }
-
从C/C++源代码到可执行文件四个过程
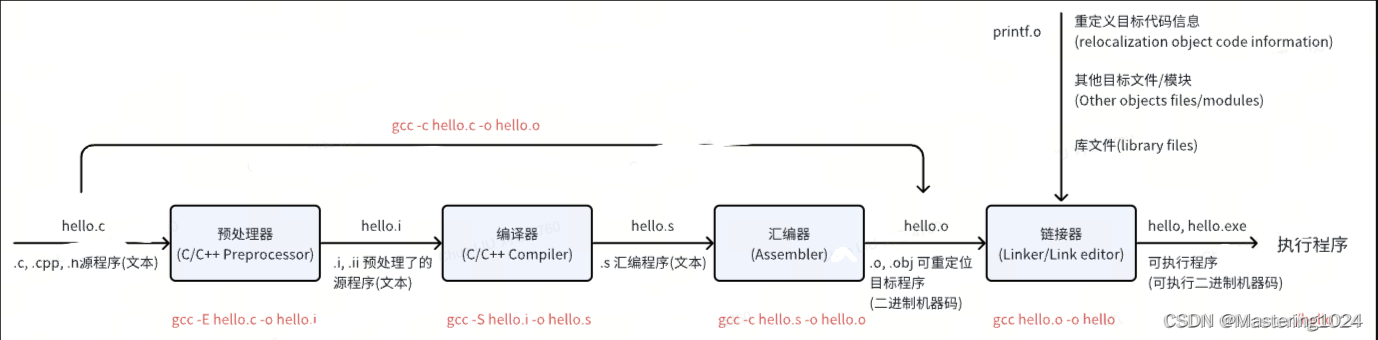
-
如果是cpp,指令中的gcc用g++代替;
-
将编译过程拆解为这几个步骤,有助于提高编译效率和程序的可维护性。
1.1 预处理
-
指令:gcc -E hello.c -o hello.i (假设当前要编译的文件是hello.c)
-
功能:预处理相当于根据预处理指令组装新的C/C++程序,经过预处理,会产生一个没有宏定义,没有条件编译指令,没有特殊符号的输出文件;这个文件的含义与原本的文件无异,只是内容上有所不同。也叫做将源文件转换为翻译单元的过程。
-
作用:防止头文件被循环展开;有助于减少重复代码和提高代码复用性。
-
具体内容:
-
将所有的#define删除,并展开所有的宏定义;
-
处理所有的条件编译指令,例如:#if, #ifdef, #elif, #else, #endif等;这些伪指令的引入使得程序员可以通过定义不同的宏来决定编译程序对哪些代码进行处理。预编译程序将根据有关文件,将那些不必要的代码过滤掉。
-
处理#include预编译指令,将被包含的文件插入到该预编译指令位置。注:这个过程可能是递归进行的,也就是说被包含的文件可能还包含其他文件。
-
删除所有注释。
-
添加行号和文件名标识;以便编译时编译器产生调试用的行号信息,以及用于编译时产生的编译错误或警告时能够显示行号。
-
保留所有的#pragma编译器指令;在编写程序的时候,我们可能用到#pragma指令来设定编译器状态或指定编译器完成一些特定的动作。
-
生成.i文件
-
翻译单元 = 源文件 + 相关头文件 - 应该忽略的预处理语句;
1.2 编译
1. 指令:gcc -S hello.i -o hello.s
2. 功能:将预处理完的文件,进行语法语义分析,以及优化(Debug、Release)后,产生相应的汇编语言表示。
其实编译器不仅仅是处理一个源文件,实际上是对一个个翻译单元进行处理;
注:有时候一个cpp内可能会包含其他cpp文件,变成一个大的cpp,但仍然只对应一个翻译单元,生成一个目标文件;因此,一个cpp未必对应一个翻译单元。
3. 作用:编译器在这个过程会检查语法、类型匹配等问题,如果发现错误,编译器会报告并终止编译过程;编译过程还包括优化代码,例如删除无用代码、循环展开等,以提高程序运行时的性能;将源代码转化为汇编代码有助于提高代码生成的灵活性,因为不同的目标平台可能需要不同的汇编指令集。汇编入门必备 | xindong
4. 具体内容:
i. 扫描,语法分析,语义分析,源代码优化,目标代码生成,目标代码优化;
ii. 生成汇编代码;
iii. 汇总符号;
iv. 生成.s文件;
1.3 汇编
-
指令:gcc -c hello.s -o hello.o
-
功能:将编译完的汇编代码文件翻译成机器指令,并生成可重定位目标程序的.o文件,该文件为二进制文件,字节编码是机器指令。这些目标文件包含可执行程序所需的机器指令、数据和符号信息。(汇编器将汇编代码转变为机器可以执行的指令,每一个汇编语句几乎都对应一条机器指令。所以汇编器的汇编过程相对于编译器来讲比较简单,它没有复杂的语法,也没有语义,也不需要做指令优化,只是根据汇编指令和机器指令的对照表一一翻译即可。)
-
作用:将源码转换为机器语言代码使得程序能够在特定的硬件平台上运行。汇编过程使编译过程与目标平台的底层硬件实现解耦,提高了编译器的可移植性。
-
具体内容:
-
根据汇编指令和特定平台,把汇编指令翻译成二进制形式;
-
合并各个section,合并符号表;
-
生成.o文件。
-
合并section和符号表具体指怎么查看
1.4 链接
1. 指令:gcc hello.o -o hello
2. 功能:链接器将一个个编译好的.o文件、系统库的.o文件和库文件链接在一起生成一个完整的可执行程序。由汇编程序生成的目标文件并不能立即就被执行,其中可能还有许多没有解决的问题:
i. 如,某个源文件中的函数引用了另一个源文件中定义的某个符号(如变量或函数调用等);在程序中可能调用了某个库文件中的函数等等。所有的这些问题,都需要经链接程序的处理方能解决。
ii. 链接器的主要工作就是将有关的目标文件彼此相连接,也就是将一个文件中引用的符号,同该符号在另外一个文件中的定义连接起来。
3. 作用:链接过程允许将程序分割成多个独立的源代码文件和库文件,便于模块化开发、代码重用和程序维护。链接器还会处理动态库和静态库的依赖关系,确保程序在运行时能够正确地加载和使用这些库文件。
4. 具体内容:(链接就是进行符号解析和重定位的过程)
i. 符号解析:在链接中,将函数和变量统称为符号,函数名和变量名统称为符号名,每个目标文件要提供两个符号表给连接器使用
· 未解决符号表:本编译单元里有引用但是不在本单元定义的符号及其对应的地址
· 导出符号表:本单元定义,并且可以提供给其他单元使用的符号及其在本单元对应地址。
可以用nm命令查出二进制文件包含的符号表
符号解析时,链接器根据目标文件提供的未解决符号表,去所有的编译单元的导出符号表中去查找与这个未解决符号相匹配的符号名。如果找到,就把这个符号的地址填到未解决符号的地址处,如果没有找到,就会报链接错误。
ii. 重定位:多个编译单元的符号地址可能是相同的,比如都从(0x0000)开始,那么最终多个目标文件链接时就会导致地址重复。
所以链接器在链接时,就会对每个目标文件的地址进行调整,这个调整的过程就是重定位。
iii. 链接过程:
· 链接器首先决定各个目标文件在最终可执行文件里的位置。然后访问所有目标文件的地址重定义表,对其中记录的地址进行重定向(加上一个偏移量,即该编译单元在可执行文件上的起始地址)。
· 遍历所有目标文件的未解决符号表,并且在所有的导出符号表里查找匹配的符号,并在未解决符号表中所记录的位置上填写实现地址。
· 最后把所有的目标文件的内容写在各自的位置上,就生成一个可执行文件。
由哪些链接方式(动/静态链接)和对应的链接文件类型(.o、.so等)?
各个链接文件的生成和链接方式对应CMakeList里的哪些指令?
实操
- 源码
#include <iostream>
int main(){
std::cout << "Hello World!" << std::endl;
return 0;
}-
指令
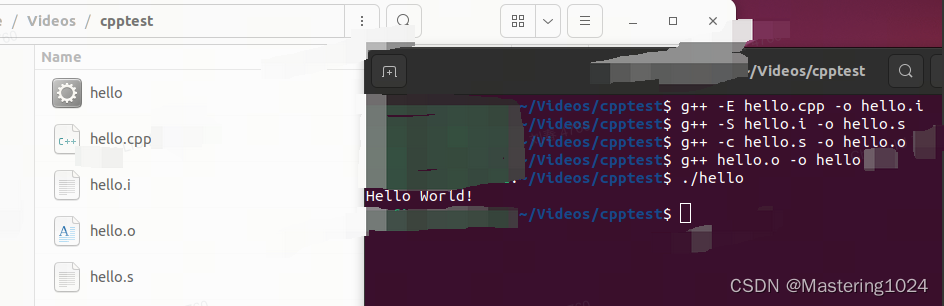
扩展
为什么要分为这样的四个流程?这样的处理流程,对我们coding的启发?
-
模块化和分层
-
效率和可扩展性
-
跨平台兼容性
-
错误诊断和调试
增量编译 vs 全部编译:
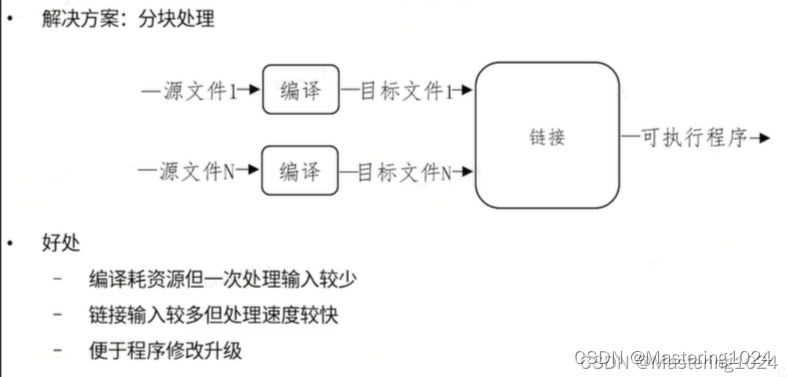
-
增量编译:假如有1~N个源文件,根据当前编译-链接过程,如果只修改了源文件1那么只需对源文件1重新编译,而最后链接即可;源文件2~N都不需要任何修改或是重新编译。(通过目标文件和源文件修改时间戳比较可检查出来)
-
全量编译:如果我们修改了头文件,则检查出源文件和目标文件的时间戳无效;有的开发环境会同时检查源文件包含的头文件,但是有的开发环境不会检查,则需要全部编译。
编译过程中,代码优化Debug/Release的区别?
-
选择Debug/Release后对调试输出log、core文件的区别?
-
怎样在程序运行时,开Debug/Release模式输出log?
可重定位目标程序的.o文件,可重定位目标程序具体指的什么功能和意思?
-
与可执行文件相比,可重定位目标文件并不包含绝对地址,而是使用相对地址和符号引用来表示各个代码段之间的关系。
由哪些链接方式(动/静态链接)和对应的链接文件类型(.o、.so等)?
库文件符号重名
可执行文件如果依赖的多个库文件中,有符号重名时,静态库和动态库分别是
1、静态库间符号重名:链接失败,编译报错
2、动态库符号重名:根据链接顺序,先被链接的动态库符号占用,后被链接的忽略
-
静态链接:静态链接在编译阶段就将库文件的所有代码加到可执行文件中,因此生成的程序体积更大,其后缀名一般为.a。静态库的优点:
-
代码装载速度比动态库快,执行效率也略高。
-
不依赖于外部库安装环境,部署方便。
-
静态库链接顺序:gcc链接库的顺序是从右到左的,假设main.cpp依赖liba.a,liba.a依赖libb.a,则链接顺序为g++ main.cpp liba.a libb.a,如果修改顺序就会链接报错。
-
动态链接:动态链接在编译链接时并不会把库文件加到可执行文件中,而是运行时加载所需的动态库,后缀名一般为.so,动态库的优点:
-
生成的可执行程序更小
-
共享库是通过mmap映射的方式实现文件共享,多进程运行时更加节省内存
-
库文件修改时,可执行文件不需要重新编译,只需要重启即可
-
如果库文件有接口函数和变量修改,是需要重新编译可执行文件!
-
-
2、 待解答
2.1 用vscode的launch.json和CMakeList.txt构建项目
- 各个链接文件的生成和链接方式对应CMakeList里的哪些指令?
- launch.json的语法和意思解析;最小功能形态
- CMakeList.txt的语法和使用解析;最小功能形态
2.3 程序出现coredump,排查工具和方法
- release和debug运行输出信息的差别;怎么配置debug输出
- gbd查看工具
3、 参考链接

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐

 26
26 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)