线性回归算法
这种最小二乘法估计,其实我们就可以认为,假定了误差服从正太分布,认为样本误差的出现是随机的,独立的,使用最大似然估计思 想,利用损失函数最小化 MSE 就能求出最优解!所以反过来说,如果我们的数据误差不是互相独立的,或者不是随机出现的,那么就不适合 去假设为正太分布,就不能去用正太分布的概率密度函数带入到总似然的函数中,故而就不能用 MSE 作为损失函数去求解最优解了!所以, 最小二乘法不是万能的
1、多元线性回归
1.1 概念
线性回归是机器学习中有监督机器学习下的一种算法。 回归问题主要关注的是因变量(需要预测的值,可以是一个也可以是多个)和一个 或多个数值型的自变量(预测变量)之间的关系。
需要预测的值:即目标变量,target,y,连续值预测变量。
影响目标变量的因素: ... ,可以是连续值也可以是离散值。
因变量和自变量之间的关系:即模型,model,是我们要求解的。

1.2、简单线性回归


1.3、最优解
Actual value:真实值,一般使用 y 表示。
Predicted value:预测值,是把已知的 x 带入到公式里面和猜出来的参数 w,b 计算得到的,一般使用 表示。
Error:误差,预测值和真实值的差距,一般使用 表示。
最优解:尽可能的找到一个模型使得整体的误差最小,整体的误差通常叫做损失 Loss。
Loss:整体的误差,Loss 通过损失函数 Loss function 计算得到。
2、正规方程
2.1 最小二乘法矩阵表示



X = np.array([[1,1],[2,-1]]) X
array([[ 1, 1], [ 2, -1]])
y = np.array([14,10]) y
array([14, 10])
# linalg 线性代数,slove计算线性回归问题 np.linalg.solve(X,y)
array([8., 6.])
2.2 矩阵转置公式与求导公式

2.3 推导正规方程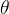 的解
的解

2.4 凸函数判定



3、线性回归算法推导
3.1 深入理解回归
回归简单来说就是“回归平均值”(regression to the mean)。但是这里的 mean 并不是把 历史数据直接当成未来的预测值,而是会把期 望值当作预测值。 追根溯源回归这个词是一个叫高尔顿的人发明的,他通过大量观察数据发现:父亲比较高,儿子也比较高;父亲比较矮,那 么儿子也比较矮!正所谓“龙生龙凤生凤老鼠的儿子会打洞”!但是会存在一定偏差~
父亲是 1.98,儿子肯定很高,但有可能不会达到1.98
父亲是 1.69,儿子肯定不高,但是有可能比 1.69 高
大自然让我们回归到一定的区间之内,这就是大自然神奇的力量。
高尔顿是谁?达尔文的表弟,这下可以相信他说的十有八九是对的了吧!
人类社会很多事情都被大自然这种神奇的力量只配置:身高、体重、智商、相貌......

3.2 误差分析

3.3 最大似然估计
最大似然估计(maximum likelihood estimation, MLE)一种重要而普遍的求估计量的方法。最大似然估计明确地使用概率模型,其目标是寻找能够以较高概率产生观察数据的系统发生树。最大似然估计是一类完全基于统计的系统发生树重建方法的代表。
是不是,有点看不懂,太学术了,我们举例说明~
假如有一个罐子,里面有黑白两种颜色的球,数目多少不知,两种颜色的比例也不知。我们想知道罐中白球和黑球的比例,但我们不能 把罐中的球全部拿出来数。现在我们可以每次任意从已经摇匀的罐中拿一个球出来,记录球的颜色,然后把拿出来的球再放回罐中。这个过 程可以重复,我们可以用记录的球的颜色来估计罐中黑白球的比例。假如在前面的一百次重复记录中,有七十次是白球,请问罐中白球所占 的比例最有可能是多少?

3.4、高斯分布-概率密度函数


3.5、误差总似然


3.6、最小二乘法MSE


3.7、归纳总结升华
这种最小二乘法估计,其实我们就可以认为,假定了误差服从正太分布,认为样本误差的出现是随机的,独立的,使用最大似然估计思 想,利用损失函数最小化 MSE 就能求出最优解!所以反过来说,如果我们的数据误差不是互相独立的,或者不是随机出现的,那么就不适合 去假设为正太分布,就不能去用正太分布的概率密度函数带入到总似然的函数中,故而就不能用 MSE 作为损失函数去求解最优解了!所以, 最小二乘法不是万能的~
还有譬如假设误差服从泊松分布,或其他分布那就得用其他分布的概率密度函数去推导出损失函数了。
所以有时我们也可以把线性回归看成是广义线性回归。比如,逻辑回归,泊松回归都属于广义线性回归的一种,这里我们线性回归可以说是最小二乘线性回归。
4、机器学习库scikit-learn
4.1 scikit-learn简介
https://scikit-learn.org/stable/index.html
4.2 scikit-learn实现简单线性回归
from sklearn.linear_model
import LinearRegression
import numpy as np
import matplotlib.pyplot as plt
# 转化成矩阵X = np.linspace(0,10,num = 30).reshape(-1,1) # 斜率和截距,随机生成
w = np.random.randint(1,5,size = 1)
b = np.random.randint(1,10,size = 1)# 根据一元一次方程计算目标值y,并加上“噪声”,数据有上下波动~ y = X * w + b + np.random.randn(30,1) plt.scatter(X,y)
# 使用scikit-learn中的线性回归求解model = LinearRegression() model.fit(X,y)
w_ = model.coef_
b_ = model.intercept_print('一元一次方程真实的斜率和截距是:',w, b)
print('通过scikit-learn求解的斜率和截距是:',w_,b_)
plt.plot(X,X.dot(w_) + b_,color = 'green')

4.3 scikit-learn实现多元线性回归
import numpy as np
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d.axes3d import Axes3D
# 转化成矩阵
x1 = np.random.randint(-150,150,size = (300,1))
x2 = np.random.randint(0,300,size = (300,1))
# 斜率和截距,随机生成
w = np.random.randint(1,5,size = 2)
b = np.random.randint(1,10,size = 1)
# 根据二元一次方程计算目标值y,并加上“噪声”,数据有上下波动~
y = x1 * w[0] + x2 * w[1] + b + np.random.randn(300,1)
fig = plt.figure(figsize=(9,6))
ax = Axes3D(fig)
ax.scatter(x1,x2,y) # 三维散点图
ax.view_init(elev=10, azim=-20) # 调整视角
# 重新构造X,将x1、x2以及截距b,相当于系数w0,前面统一乘以1进行数据合并 X = np.concatenate([x1,x2],axis = 1)
# 使用scikit-learn中的线性回归求解
model = LinearRegression()
model.fit(X,y)
w_ = model.coef_.reshape(-1)
b_ = model.intercept_ print('二元一次方程真实的斜率和截距是:',w,b) print('通过scikit-learn求解的斜率和截距是:',w_,b_)
# # 根据求解的斜率和截距绘制线性回归线型图
x = np.linspace(-150,150,100)
y = np.linspace(0,300,100)
z = x * w_[0] + y * w_[1] + b_
ax.plot(x,y,z ,color = 'green')

5、梯度下降
5.1 线性回归房价预测






5.2 无约束最优化问题











import numpy as np
import matplotlib.pyplot as plt
f = lambda x : (x - 3.5)**2 -4.5*x + 10
# 导函数
d = lambda x :2*(x - 3.5) - 4.5 # 梯度 == 导数
# 梯度下降的步幅,比例,(学习率,幅度)
step = 0.1
# 求解当x等于多少的时候,函数值最小。求解目标值:随机生成的
# 相等于:'瞎蒙' ----> 方法 ----> 优化
x = np.random.randint(0,12,size = 1)[0]
# 梯度下降,每下降一步,每走一步,目标值,都会更新。
# 更新的这个新值和上一步的值,差异,如果差异很小(万分之一)
# 梯度下降退出
last_x = x + 0.02 # 记录上一步的值,首先让last_x和x有一定的差异!!! # 精确率,真实计算,都是有误差,自己定义
precision = 1e-4
print('+++++++++++++++++++++', x)
x_ = [x]
while True:# 退出条件,精确度,满足了
if np.abs(x - last_x) < precision:break
# 更新
last_x = x
x -= step*d(x) # 更新,减法:最小值 x_.append(x) print('--------------------',x)# 数据可视化
plt.rcParams['font.family'] = 'Kaiti SC' plt.figure(figsize=(9,6))
x = np.linspace(5.75 - 5, 5.75 + 5, 100)
y = f(x)
plt.plot(x,y,color = 'green') plt.title('梯度下降',size = 24,pad = 15)
x_ = np.array(x_)
y_ = f(x_)
plt.scatter(x_, y_,color = 'red') plt.savefig('./图片/5-梯度下降.jpg',dpi = 200)
函数的最优解是:5.75。你可以发现,随机赋值的变量 x ,无论大于5.75,还是小于5.75,经过梯度下降,最终都慢慢靠近5.75这个最优 解!


5.3 梯度下降的方法












5.4 代码实战梯度下降
5.4.1 批量梯度下降BGD
![]()
import numpy as np
# 1、创建数据集X,y
X = np.random.rand(100, 1)
w,b = np.random.randint(1,10,size = 2)
y = w * X + b + np.random.randn(100, 1)# 2、使用偏置项x_0 = 1,更新X
X = np.c_[X,np.ones((100, 1))]# 3、创建超参数轮次 epoches = 10000
# 4、定义一个函数来调整学习率
t0, t1 = 5, 1000
def learning_rate_schedule(t):return t0/(t+t1)
# 5、初始化 W0...Wn,标准正太分布创建Wθ = np.random.randn(2, 1)
# 6、判断是否收敛,一般不会去设定阈值,而是直接采用设置相对大的迭代次数保证可以收敛 for i in range(epoches):
# 根据公式计算梯度
g = X.T.dot(X.dot(θ) - y)
# 应用梯度下降的公式去调整 θ 值
learning_rate = learning_rate_schedule(i) θ = θ - learning_rate * gprint('真实斜率和截距是:',w,b) print('梯度下降计算斜率和截距是:',θ)
![]()
import numpy as np
# 1、创建数据集X,y
X = np.random.rand(100, 3)
w = np.random.randint(1,10,size = (3,1))
b = np.random.randint(1,10,size = 1)
y = X.dot(w) + b + np.random.randn(100, 1)# 2、使用偏置项x_0 = 1,更新X
X = np.c_[X,np.ones((100, 1))]# 3、创建超参数轮次 epoches = 10000
# 4、定义一个函数来调整学习率
t0, t1 = 5, 500
def learning_rate_schedule(t):return t0/(t+t1)
# 5、初始化 W0...Wn,标准正太分布创建Wθ = np.random.randn(4, 1)
# 6、判断是否收敛,一般不会去设定阈值,而是直接采用设置相对大的迭代次数保证可以收敛 for i in range(epoches):
# 根据公式计算梯度
g = X.T.dot(X.dot(θ) - y)
# 应用梯度下降的公式去调整 θ 值
learning_rate = learning_rate_schedule(i) θ = θ - learning_rate * gprint('真实斜率和截距是:',w,b) print('梯度下降计算斜率和截距是:',θ)
5.4.2 随机梯度下降SGD

import numpy as np
# 1、创建数据集X,y
X = 2*np.random.rand(100, 1)
w,b = np.random.randint(1,10,size = 2)y = w * X + b + np.random.randn(100, 1)
# 2、使用偏置项x_0 = 1,更新X
X = np.c_[X, np.ones((100, 1))]# 3、创建超参数轮次、样本数量 epochs = 10000
n = 100# 4、定义一个函数来调整学习率
t0, t1 = 5, 500
def learning_rate_schedule(t):return t0/(t+t1)
# 5、初始化 W0...Wn,标准正太分布创建Wθ = np.random.randn(2, 1)
# 6、多次for循环实现梯度下降,最终结果收敛
for epoch in range(epochs):
# 在双层for循环之间,每个轮次开始分批次迭代之前打乱数据索引顺序 index = np.arange(n) # 0 ~99
np.random.shuffle(index)
X = y = for
X[index] # 打乱顺序 y[index]
i in range(n):
y_i = y[[i]]
g = X_i.T.dot(X_i.dot(θ)-y_i)
learning_rate = learning_rate_schedule(epoch*n + i) θ = θ - learning_rate * gprint('真实斜率和截距是:',w,b)
print('梯度下降计算斜率和截距是:',θ)

import numpy as np
# 1、创建数据集X,y
X = 2*np.random.rand(100, 5)
w = np.random.randint(1,10,size = (5,1))
b = np.random.randint(1,10,size = 1)
y = X.dot(w) + b + np.random.randn(100, 1)# 2、使用偏置项x_0 = 1,更新X
X = np.c_[X, np.ones((100, 1))]# 3、创建超参数轮次、样本数量 epochs = 10000
n = 100# 4、定义一个函数来调整学习率
t0, t1 = 5, 500
def learning_rate_schedule(t):return t0/(t+t1)
# 5、初始化 W0...Wn,标准正太分布创建Wθ = np.random.randn(6, 1)
# 6、多次for循环实现梯度下降,最终结果收敛
for epoch in range(epochs):
# 在双层for循环之间,每个轮次开始分批次迭代之前打乱数据索引顺序 index = np.arange(n) # 0 ~99
np.random.shuffle(index)X = y = for
X[index] # 打乱顺序
y[index]
i in range(n):
X_i = X[[i]]y_i = y[[i]]
g = X_i.T.dot(X_i.dot(θ)-y_i)
learning_rate = learning_rate_schedule(epoch*n + i) θ = θ - learning_rate * gprint('真实斜率和截距是:',w,b)
print('梯度下降计算斜率和截距是:',θ)
5.4.3 小批量梯度下降MBGD
![]()
import numpy as np
# 1、创建数据集X,y
X = np.random.rand(100, 1)
w,b = np.random.randint(1,10,size = 2) y = w * X + b + np.random.randn(100, 1)# 2、使用偏置项x_0 = 1,更新X
X = np.c_[X, np.ones((100, 1))]# 3、定义一个函数来调整学习率
t0, t1 = 5, 500
def learning_rate_schedule(t):return t0/(t+t1)
# 4、创建超参数轮次、样本数量、小批量数量 epochs = 100
n = 100
batch_size = 16num_batches = int(n / batch_size) # 5、初始化 W0...Wn,标准正太分布创建W
θ = np.random.randn(2, 1)
# 6、多次for循环实现梯度下降,最终结果收敛
for epoch in range(epochs):
# 在双层for循环之间,每个轮次开始分批次迭代之前打乱数据索引顺序
index = np.arange(n) np.random.shuffle(index)
X = X[index]
y = y[index]
for i in range(num_batches):
# 一次取一批数据16个样本
X_batch = X[i * batch_size : (i + 1)*batch_size]y_batch = y[i * batch_size : (i + 1)*batch_size]
g = X_batch.T.dot(X_batch.dot(θ)-y_batch)learning_rate = learning_rate_schedule(epoch * n + i)
θ = θ - learning_rate * g
print('真实斜率和截距是:',w,b)
print('梯度下降计算斜率和截距是:',θ)

import numpy as np
# 1、创建数据集X,y
X = np.random.rand(100, 3)
w = np.random.randint(1,10,size = (3,1))
b = np.random.randint(1,10,size = 1)
y = X.dot(w) + b + np.random.randn(100, 1)# 2、使用偏置项 X_0 = 1,更新X
X = np.c_[X, np.ones((100, 1))]# 3、定义一个函数来调整学习率
t0, t1 = 5, 500
def learning_rate_schedule(t):return t0/(t+t1)
# 4、创建超参数轮次、样本数量、小批量数量 epochs = 10000
n = 100
batch_size = 16num_batches = int(n / batch_size) # 5、初始化 W0...Wn,标准正太分布创建W
θ = np.random.randn(4, 1)
# 6、多次for循环实现梯度下降,最终结果收敛
for epoch in range(epochs):
# 在双层for循环之间,每个轮次开始分批次迭代之前打乱数据索引顺序
index = np.arange(n)
np.random.shuffle(index)
X = X[index]y = y[index]
for i in range(num_batches):# 一次取一批数据16个样本
X_batch = X[i * batch_size : (i + 1)*batch_size]y_batch = y[i * batch_size : (i + 1)*batch_size]
g = X_batch.T.dot(X_batch.dot(θ)-y_batch)learning_rate = learning_rate_schedule(epoch * n + i) θ = θ - learning_rate * g
print('真实斜率和截距是:',w,b)
print('梯度下降计算斜率和截距是:',θ)
6、梯度下降的归一化
6.1 归一化的目的

6.2 归一化的本质

6.3 最大值和最小值归一化

import numpy as np
x_1 = np.random.randint(1,10,size = 10)
x_2 = np.random.randint(100,300,size = 10)
x = np.c_[x_1,x_2]
print('归一化之前的数据:')
display(x)
x_ = (x - x.min(axis = 0)) / (x.max(axis = 0) - x.min(axis = 0))
print('归一化之后的数据:')
display(x_)使用scikit-learn函数:
import numpy as np
from sklearn.preprocessing import MinMaxScaler
x_1 = np.random.randint(1,10,size = 10)
x_2 = np.random.randint(100,300,size = 10)
x = np.c_[x_1,x_2]
print('归一化之前的数据:')
display(x)
min_max_scaler = MinMaxScaler()
x_ = min_max_scaler.fit_transform(x)
print('归一化之后的数据:')
display(x_)6.4 0-均值标准化 (Z-score归一化)

import numpy as np
x_1 = np.random.randint(1,10,size = 10)
x_2 = np.random.randint(100,300,size = 10)
x = np.c_[x_1,x_2]
print('归一化之前的数据:')
display(x)
x_ = (x - x.mean(axis = 0)) / x.std(axis = 0)print('归一化之后的数据:')
display(x_)
使用scikit-learn函数:
import numpy as np
from sklearn.preprocessing import StandardScalerx_1 = np.random.randint(1,10,size = 10)
x_2 = np.random.randint(100,300,size = 10)
x = np.c_[x_1,x_2]
print('归一化之前的数据:')
display(x)
standard_scaler = StandardScaler()
x_ = standard_scaler.fit_transform(x) print('归一化之后的数据:')
display(x_)


6.5 正则化 Regularization
6.5.1 过拟合欠拟合
-
欠拟合(under fit):还没有拟合到位,训练集和测试集的准确率都还没有到达最高,学的还不到位。
-
过拟合(over fit):拟合过度,训练集的准确率升高的同时,测试集的准确率反而降低。学的过度了(走火入魔),做过的卷子都能
再次答对(死记硬背),考试碰到新的没见过的题就考不好(不会举一反三)。
-
恰到好处(just right):过拟合前,训练集和测试集准确率都达到巅峰。好比,学习并不需要花费很多时间,理解的很好,考试的时候
可以很好的把知识举一反三。



6.5.2 套索回归(Lasso)


L1 = |w1|+|w2| f(x,y) = |x| + |y|
# 令f(x,y) =1 绘制徒刑在平面中
# |x| + |y| = 1
'''
假设x,y等于1
1 = x+y
y = 1-x
'''
fun1 = lambda x:1-x
x1 = np.linspace(0,1,50)
y1 = fun1(x1)
plt.figure(figsize = (6,6))
plt.plot(x1,y1)
plt.xlim(-2,2)
plt.ylim(-2,2)
ax = plt.gca() # 获取当前视图
ax.spines['right'].set_color('None')
ax.spines['top'].set_color('None')
ax.spines['bottom'].set_position(('data',0))
ax.spines['left'].set_position(('data',0))
'''
假设x,y都是小于0
1 = -x-y
y = -1-x
'''
fun2 = lambda x:-x-1
x2 = np.linspace(-1,0,50)
y2 = fun2(x2)
plt.plot(x2,y2)
'''
假设x大于0,y都是小于0
1 = x-y
y = x-1
'''
fun3 = lambda x:x-1
x3 = np.linspace(0,1,50)
y3 = fun3(x3)
plt.plot(x3,y3)
# 假设x小于0,y大于0
# 1 = -x + y
fun4 = lambda x : 1 + x
x4 = np.linspace(-1,0,50)
y4 = fun4(x4)
plt.plot(x4,y4,color ='k')


6.5.3 岭回归




6.5.4 线性回归衍生算法
1、Redge算法使用:

import numpy as np
from sklearn.linear_model import Ridge
from sklearn.linear_model import SGDRegressor
# 1、创建数据集X,y
X = 2*np.random.rand(100, 5)
w = np.random.randint(1,10,size = (5,1))
b = np.random.randint(1,10,size = 1)
y = X.dot(w) + b + np.random.randn(100, 1)
print('原始方程的斜率:',w.ravel())
print('原始方程的截距:',b)
ridge = Ridge(alpha= 1, solver='sag')
ridge.fit(X, y) print('岭回归求解的斜率:',ridge.coef_)
print('岭回归求解的截距:',ridge.intercept_)
# 线性回归梯度下降方法
sgd = SGDRegressor(penalty='l2',alpha=0,l1_ratio=0)
sgd.fit(X, y.reshape(-1,))
print('随机梯度下降求解的斜率是:',sgd.coef_)
print('随机梯度下降求解的截距是:',sgd.intercept_)
2、lasso算法使用:

import numpy as np
from sklearn.linear_model import Lasso
from sklearn.linear_model import SGDRegressor
# 1、创建数据集X,y
X = 2*np.random.rand(100, 20)
w = np.random.randn(20,1)
b = np.random.randint(1,10,size = 1)
y = X.dot(w) + b + np.random.randn(100, 1)
print('原始方程的斜率:',w.ravel())
print('原始方程的截距:',b)
lasso = Lasso(alpha= 0.5)
lasso.fit(X, y)
print('套索回归求解的斜率:',lasso.coef_)
print('套索回归求解的截距:',lasso.intercept_)
# 线性回归梯度下降方法
sgd = SGDRegressor(penalty='l2',alpha=0, l1_ratio=0)
sgd.fit(X, y.reshape(-1,))
print('随机梯度下降求解的斜率是:',sgd.coef_)
print('随机梯度下降求解的截距是:',sgd.intercept_)
3、Elastic-Net算法使用:

import numpy as np
from sklearn.linear_model import ElasticNet
from sklearn.linear_model import SGDRegressor
# 1、创建数据集X,y
X = 2*np.random.rand(100, 20)
w = np.random.randn(20,1)
b = np.random.randint(1,10,size = 1)
y = X.dot(w) + b + np.random.randn(100, 1)
print('原始方程的斜率:',w.ravel())
print('原始方程的截距:',b)
model = ElasticNet(alpha= 1, l1_ratio = 0.7)
model.fit(X, y)
print('弹性网络回归求解的斜率:',model.coef_)
print('弹性网络回归求解的截距:',model.intercept_)
# 线性回归梯度下降方法
sgd = SGDRegressor(penalty='l2',alpha=0, l1_ratio=0)
sgd.fit(X, y.reshape(-1,))
print('随机梯度下降求解的斜率是:',sgd.coef_)
print('随机梯度下降求解的截距是:',sgd.intercept_)

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐


 22
22 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)