【MCP基础概念】开放连接未来:深入解读模型上下文协议
在 AI 助手迅猛发展的今天,我们迎来了一个重大里程碑 —— 模型上下文协议(Model Context Protocol,简称 MCP) 的开源发布。它是一项旨在打破信息孤岛、统一 AI 与数据系统连接方式的开放标准,为 AI 系统提供更可靠的数据访问路径,释放出前沿模型的真正潜力。
目录
6.2 基于SSE的Remote模式(MCP标准(2025-03-26版之前))
6.3 Streamable HTTP模式(MCP标准(2025-03-26版))

一、MCP简介
在 AI 助手迅猛发展的今天,我们迎来了一个重大里程碑 —— 模型上下文协议(Model Context Protocol,简称 MCP) 的开源发布。它是一项旨在打破信息孤岛、统一 AI 与数据系统连接方式的开放标准,为 AI 系统提供更可靠的数据访问路径,释放出前沿模型的真正潜力。
1.1 为什么需要 MCP?
尽管 AI 模型(如 Claude 3.5 Sonnet)在推理能力和回答质量上取得了惊人的进步,但它们仍然面临着一个关键挑战:与数据的连接受限。
-
每接入一个新数据源都需定制开发,难以维护和扩展;
-
模型“困”在孤立的内容库、业务工具和遗留系统中,无法实时了解用户上下文;
-
当前的集成方案碎片化、脆弱,阻碍了 AI 的深入应用。
MCP 的目标是:用一个通用协议解决所有数据连接问题,让 AI 系统随时理解用户所在的数据语境。
1.2 MCP 是什么?
MCP(Model Context Protocol)是一个开放标准协议,让开发者可以在 AI 工具 和 数据系统 之间构建安全的双向连接。它包含三大关键组件:
-
MCP 规范与 SDK
开发者可基于统一的协议标准快速构建连接器。 -
Claude Desktop 内置的 MCP 本地服务器
支持本地测试连接,保障数据隐私。 -
MCP 服务器开源实现
提供开箱即用的连接器,如:Google Drive、Slack、GitHub、Git、Postgres、Puppeteer 等。
AI 系统通过MCP 客户端连接 MCP 服务器,从而访问实际数据源。
1.3 谁在用 MCP?
-
Block 与 Apollo 等公司已将 MCP 集成到其 AI 系统中;
-
Zed、Replit、Codeium、Sourcegraph 等开发者工具平台正通过 MCP 让 AI 更深入理解开发上下文;
-
Claude 3.5 Sonnet 模型本身也擅长快速搭建 MCP 接口。
Block CTO Dhanji R. Prasanna 表示:
“像 MCP 这样的开放技术是将 AI 与现实世界连接起来的桥梁,让我们专注于创造性工作而非重复劳动。”
1.4 MCP 能做什么?
借助 MCP,AI 系统可以:
-
实时访问用户的文档、代码库、数据库等数据;
-
在不同工具之间保持上下文一致性;
-
用更可持续的架构替代零散集成,统一标准提升可维护性;
-
快速接入企业现有数据系统,加速 AI 工具落地。
1.5 如何开始使用 MCP?
你可以立刻开始构建和测试 MCP 服务:
-
✅ 安装并运行预构建的 MCP 本地服务器(通过 Claude Desktop)
-
📚 跟随官方快速入门指南搭建自己的 MCP 服务
-
🌍 参与 MCP 开源社区,为更多连接器贡献力量
所有 Claude.ai 用户均支持 MCP,本地试验从现在开始,企业版用户还可接入私有系统。
1.6 向未来进发:构建上下文感知的 AI
MCP 不仅是一个技术协议,它更代表着一种范式转变 —— 从“模型孤岛”迈向“上下文协同”,从“定制集成”迈向“开放连接”。
对于开发者、企业和 AI 工具构建者而言,MCP 意味着:
-
更低的集成门槛;
-
更高效的上下文获取;
-
更快速的 AI 赋能落地。
无论你是开发者、初创企业,还是大型组织,MCP 都是你拥抱上下文感知 AI 未来的桥梁。
1.7 传统大模型数据连接方式 vs MCP 的整合能力
🎯 传统大模型的数据连接方式:
📌 特点:
-
每个数据源(如数据库、文档系统、代码库)都需要手动定制开发适配器;
-
没有统一接口协议,彼此之间无法互通;
-
模型访问这些数据通常是单向、离线或一次性的提取(如数据预处理阶段);
-
缺乏上下文保持能力,不同数据源上下文无法自动共享或融合;
-
在实际运行中,模型往往只能看见部分静态信息,而非实时动态上下文。
🚫 结果:
各个数据源像一堆“孤岛”,大模型虽能分别访问,但难以统一整合和动态调用,更无法跨数据源“理解上下文”。
✅ MCP 模型上下文协议的能力:
📌 特点:
-
所有数据源通过统一协议(MCP Server)暴露接口;
-
MCP Client(如 Claude)可以动态调用多个 MCP Server,实时访问不同系统的数据;
-
所有连接是基于统一标准,上下文可跨工具共享;
-
支持实时、可持续的数据流访问,不是一次性拉取;
-
AI 助手可以在不同任务间保持连续语境,理解“你在看哪段代码,读哪份文档”。
✅ 结果:
数据源不再是孤岛,AI 能像人一样在多个应用中穿梭并保持语境一致,实现真正的“全局上下文感知”。
举个例子来类比:
-
传统方式就像你用耳机听音乐,但每个播放器(微信、QQ音乐、网易云)都需要买一个不同插头的耳机,互不兼容;
-
MCP 就是定义了一种通用蓝牙协议,你只需一个耳机,就能无缝切换音乐源,并记住你上次听到哪。
1.8 MCP优势
MCP 相对于传统大模型接入方式的优势:
✅ 传统大模型的数据连接方式:
-
每接入一个数据源(如数据库、GitHub、Notion)都需要定制化开发;
-
没有统一标准,每个连接器是一次性、割裂的;
-
数据连接过程复杂、难以维护和扩展;
-
很难在多个工具之间共享上下文。
✅ MCP 模型上下文协议的优势:
-
提供一个统一的开放协议接口(类似统一端口);
-
支持所有数据源通过标准化的 MCP 服务器接入;
-
AI 助手(MCP 客户端)可以安全地双向访问多个数据源;
-
更容易扩展,多个系统间共享上下文成为可能;
-
大幅降低了连接成本,提升 AI 的“数据理解力”。
🔁 简单类比总结:
传统方式就像每连一个设备都要做一根专用线,而 MCP 就像定义了一种标准接口(比如 USB),所有设备都能通过同一协议插上就用,更简单、更通用、更智能。
1.9 延伸阅读与资源
MCP 是连接数据与智能的“协议之桥”,让 AI 真正“知道你在干什么”,并为你做得更多。
二、MCP 的数据流结构(简化版)
[Claude 或其他 AI 客户端]
↓ (通过标准协议请求)
[MCP Client SDK]
↓
🔌 连接到 MCP Server
↓
[数据仍保留在原系统:数据库、文档库、代码仓库等]
关键点说明:
1、数据不集中到 MCP 平台或模型本身
▲数据永远保存在你自己的系统里(比如公司内部 Postgres 数据库、GitHub 仓库、Google Drive 文件夹等)。
2、MCP Server = 中间桥梁
▲MCP Server 是你构建的一个接口服务,用来在原系统和 AI 客户端之间建立安全的数据通信通道;
▲你可以决定暴露哪些数据,是否支持读写,以及是否加权限控制。
3、Claude、Mistral 等 AI 模型通过 MCP 客户端 SDK 发起请求
▲这些请求是按需实时进行的;
▲数据不会被缓存或长期存储,除非你自定义做了这部分逻辑。
三、数据安全方面说明
-
本地测试时 MCP Server 可部署在自己电脑(如 Claude Desktop 内置的 MCP Server);
-
企业场景中 MCP Server 可以部署在私有网络中;
-
你完全控制数据暴露内容、权限和调用逻辑。
🧠 举个例子:
假设你让 Claude 通过 MCP 接入了一个 GitHub 仓库:
代码文件仍在 GitHub;
你搭建了一个 MCP Server,它通过 GitHub API 去读取代码内容;
当你提问“这段函数是做什么的?”时,Claude 就会调用 MCP 客户端去访问该 MCP Server,获取你仓库中对应文件内容;
全程数据没有存入 Claude,也没有脱离你的系统环境。
✅ 总结一句话:
✅ 数据本身依旧存储在原有数据库、文件系统或工具中(如 Postgres、GitHub、Notion 等);
✅ MCP 只是作为一个统一的“数据访问接口”,让大模型能够实时、标准、安全地访问这些数据。
类比理解:
可以把 MCP 理解成一个智能“数据网关”,就像:
-
数据库的 API 网关:统一暴露各种表和字段的数据读取、写入能力;
-
文件系统的访问控制层:你决定模型能访问哪些路径和内容;
-
多工具的“翻译器”:无论数据源是结构化(数据库)、半结构化(JSON、YAML)、非结构化(PDF、Word),MCP 都能以统一格式提供给模型。
四、MCP 的核心价值
4.1 传统集成 VS MCP模式
| 对比点 | 传统集成 | MCP 模式 |
|---|---|---|
| 数据位置 | 分布在多个系统,独立管理 | 同样分布在系统中,不迁移 |
| 接入方式 | 每个系统都要写一个适配器 | 用统一协议暴露数据接口 |
| 连接标准 | 无统一标准,定制开发 | MCP 协议定义统一标准 |
| 上下文共享 | 难以实现 | 可以统一供模型访问、共享上下文 |
| 数据安全 | 易被复制或脱管 | 由原系统控制,安全可控 |
【名词解析】
适配器(Adapter) 是在两个系统之间做“翻译”和“桥接”的代码或模块,让它们能够彼此通信、互操作。
举个现实中的例子:
你买了一个美版笔记本,它的电源插头是扁的,但你在中国,插座是圆孔的。这时你需要一个 电源适配器,把两者连接起来 ——适配器不改变设备或插座本身,只是“让它们能搭上线”。
一句话再说清楚:
适配器就是连接 AI 与数据源的“翻译器”,而 MCP 就是把这些翻译器变成了“统一语言”的标准插件系统,省事、省心、可拓展。
【传统集成方式】

【MCP模式】
4.2 传统 AI 数据集成模式
-
假设你想让大模型访问 GitHub 上的代码内容;
-
你需要写一个GitHub 适配器:调用 GitHub API,获取指定 repo 的代码内容;
-
如果还想连接数据库,还得再写一个 Postgres 适配器;
-
想连 Notion?再写个 Notion API 的适配器……
🔁 结果是每接一个系统就得开发一个新的“适配器”,重复劳动、维护成本高。
4.3 MCP 解决了什么问题?
MCP 的目标就是让这些“适配器”变得标准化!
-
MCP Server 本质上就是一个标准的适配器容器;
-
你只需按照 MCP 协议暴露接口,不需要每次都从零写“翻译逻辑”;
-
Claude(或其他 AI 客户端)只需要学会与 MCP 对话,而不需要学 GitHub 的 API、Postgres 的语法等。
4.4 小结
| 项目 | 传统方式 | MCP方式 |
|---|---|---|
| 每个系统接入方式 | 各写各的适配器,互不通用 | 全都通过 MCP Server 适配 |
| 调用接口方式 | 多套逻辑、格式不统一 | 统一协议、一次接入多处复用 |
| AI 对接工作量 | 高(每接一处写一套) | 低(只需支持 MCP 协议) |
传统方式因为每个数据源都需要单独的适配器,接口风格和数据结构各不相同,导致上下文无法统一表示、共享和整合,模型只能“看见碎片”,难以形成全局理解。
✅ 1. 多个适配器 = 多种数据风格
| 数据源 | 自定义适配器返回的数据格式 |
|---|---|
| GitHub | 文件结构 + PR 信息(JSON) |
| Postgres | SQL 查询结果(DataFrame/表格) |
| Notion | 块级内容 + 标签(嵌套 JSON) |
| Google Drive | 文件元数据 + 内容片段 |
🔁 每个接口风格不同、语义不同,模型很难自动把这些内容“组合理解”成一个连贯上下文。
✅ 2. 无统一语义标准
传统方式中:
-
GitHub 的“issue” vs Notion 的“任务卡片”可能表示同一业务概念,但结构完全不同;
-
数据没有统一字段定义,也没有上下文提示 → 模型处理时无法知道它们有关联。
✅ 3. 上下文无法贯通
因为数据是割裂地从不同适配器返回:
-
模型在处理数据库内容时,看不到你当前在编辑的 PR;
-
回答一个用户问题时,可能不能结合任务进度、客户信息等多源上下文。
这就导致 响应片面、不准确、无法贴合用户的真实意图。
✅ 4、MCP 如何解决这个问题?
MCP 用统一协议解决这一碎片化问题:
-
所有 MCP Server 都遵循相同的接口规范(请求方式、数据格式、语义结构);
-
MCP 客户端可以整合多个数据源的上下文,在语义层面建立统一表示;
-
模型可以像“浏览人类工作空间”一样在多个系统中穿梭,动态组合上下文内容进行响应。
✅ 5、举个简单类比
传统方式是你去不同城市出差,每个城市讲不同语言,你得雇不同翻译才能沟通;
MCP 就是大家都说英语(统一协议),你可以自由穿梭各地,一套语言走天下,还能把来自不同地方的信息整合成一本完整的“出差笔记”。
一句话理解 :
传统方式因适配器各异,造成数据格式割裂,难以共享上下文;而 MCP 通过统一协议让模型像人一样看懂不同系统中的信息,并形成“整体语境”来做出智能决策。
五、基于MCP的集成架构
5.1 MCP集成架构图
基于MCP将LLM应用与外部资源集成的架构可用下图表示:

【名词解析】
1、【STDIO】
是 standard input/output(标准输入输出) 的缩写,它是操作系统中用于进程间通信的一种基础机制,尤其常用于 一个程序与另一个程序之间交换数据。
▲在 MCP 架构中的作用
在这张 MCP 架构图中,MCP Client 与 MCP Server 之间通过
STDIO通信,表示它们通过标准输入输出管道来传递数据,而不是走网络端口。这意味着:
特点 说明 📦 进程通信 MCP Server 是一个子进程(独立程序),它从 MCP Client 那接收数据(标准输入),处理后再把结果输出(标准输出) 🔒 安全性高 不依赖端口监听,不容易被外部攻击 ⚡ 性能高 本地通信,开销小、速度快、延迟低 🛠️ 简单部署 不需要额外配置 HTTP 服务或端口转发
▲类比理解
你可以把它想象成:
MCP Client 给 MCP Server 发一条信息(写进它的“耳朵”,也就是标准输入),
然后 MCP Server 处理完之后,把结果大声说出来(通过“嘴巴”,也就是标准输出),
MCP Client 再听回来处理。
▲总结一句话
stdio是模型与本地 MCP Server 之间通信的“数据管道”,它通过标准输入输出传递消息,不需要网络端口,简单、高效、安全。
2、【HTTP SSE】
SSE是 Server-Sent Events 的缩写,意思是“服务器推送事件”。它是一种 单向、实时的通信机制:
服务器通过 HTTP 连接持续不断地向客户端“推送”数据更新。
▲和 WebSocket 的区别
特性 SSE(Server-Sent Events) WebSocket 通信方向 单向(服务器 → 客户端) 双向 使用协议 HTTP(长连接) 独立的 WebSocket 协议 支持重连 ✅ 自动重连 需手动处理 简单易用 ✅(浏览器直接支持) ❌(需要额外封装) 场景适合 服务器主动推送消息(如日志、通知、实时数据) 实时互动,如在线游戏、聊天 ▲在 MCP 中的作用
在这张架构图中,远程 MCP Server(remote) 与 MCP Client 是通过 HTTP SSE 建立连接的,它的作用如下:
角色 描述 MCP Client 向远程 MCP Server 发起 HTTP 请求,监听事件流 MCP Server(remote) 在准备好数据时,主动将结果通过 SSE 通道推送回来 示例 Claude 向远程 GitHub MCP Server 发起“查某个 repo 文件内容”的请求 → 等待对方推送回来结果 ▲一个简单的数据流示例
Client 请求: GET /events HTTP/1.1 Accept: text/event-stream Server 持续推送: data: {"event": "tool_result", "result": "文件内容如下..."} data: {"event": "log", "result": "执行完毕"}只要连接不断,服务器可以随时推送多条
data:消息给客户端。▲总结一句话
HTTP SSE 是 MCP Client 与远程 MCP Server 之间的“实时单向通道”,让远程服务可以在准备好数据后自动推送给模型客户端,适合异步、低延迟场景。
5.1.1 架构图拆解解析
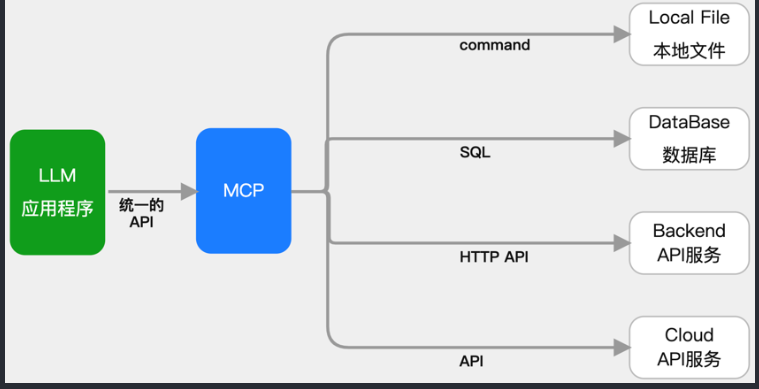
1、
LLM 应用程序(绿色部分)这是运行大模型的应用进程,比如:
Claude 桌面版
自建的 AI 助理
它里面维护了多个 MCP Client 实例,每个用于连接一个 MCP Server。
2、本地的多个 MCP Server(蓝色方框)
每个 MCP Server 都是一个独立的数据连接“适配器”
通过 MCP 协议暴露工具接口
它们可能连接不同的数据源,比如:
本地文件系统(Local File)
第三方 API(Backend API 服务)
本地数据库
这些 MCP Server 与 MCP Client 之间通过
STDIO通信(标准输入输出管道),通信安全、轻量、速度快。3、远程 MCP Server(remote)
有些 MCP Server 部署在网络或云端,比如:
GitHub MCP Server
Google Drive MCP Server
这类服务器通过 HTTP SSE(Server Sent Events)协议 与 MCP Client 通信
MCP Client 会异步接收它发来的数据响应
5.1.2 图示的数据流说明
LLM 应用
↓ (通过 MCP SDK 创建连接)
MCP Client ───── STDIO ─────► MCP Server (本地/远程)
↓
▼
获取工具/执行指令/读数据
然后 MCP Server 去执行实际的任务,比如:
-
打开本地文件读取内容
-
查询数据库
-
调用外部 API
-
等等...
返回的数据会被 MCP Client 接收,提供给模型处理,形成更准确、更上下文丰富的回复。
5.1.3 举个通俗的比喻
想象一个 AI 员工(LLM 应用),它手边有多个专门的助理(MCP Client),每个助理负责联系不同的信息系统(MCP Server):
| 助理编号 | MCP Server 对应数据 | 数据来源 |
|---|---|---|
| 助理A | 本地项目文档 | Local File |
| 助理B | 公司数据库 | Backend API |
| 助理C | GitHub 代码库 | Remote MCP |
| 助理D | Slack 消息 | Remote MCP |
AI 员工只要吩咐助理去拿对应的数据,助理就会帮它打通系统接口,标准化拿回来,交给 AI 使用。
✅ 总结一句话:
LLM 应用通过 MCP Client 与多个 MCP Server 建立连接,每个 Server 负责对接一个数据源,统一通过 MCP 协议传递上下文信息,使模型能安全、标准、实时地使用各类工具与数据。
5.2 MCP Client
MCP Client是由LLM应用程序使用MCP SDK创建并维护的一个Server会话,就像在程序中维护一个数据库的Connection一样,借助MCP SDK可以与MCP Server通信,如查看Server的Tools。在本地模式下,Client与Server是一对一的关系。如果需要连接多个MCP Server,需要自行维护多个Session。
✅ 通俗解释:
如果你希望模型同时访问多个系统,比如:
一个 MCP Server 连接公司数据库;
一个 MCP Server 连接 GitHub;
一个 MCP Server 连接 Notion。
那你就需要在 MCP Client 这边分别创建多个连接对象,类似:
client1 = MCPClient(server_url_1) # 对应数据库 client2 = MCPClient(server_url_2) # 对应 GitHub client3 = MCPClient(server_url_3) # 对应 Notion每个连接各自维护自己的“上下文会话”。
5.3 举个现实例子类比
假设你在用 Claude 来帮你写报告:
| 组件 | 现实含义 | 对应角色 |
|---|---|---|
| Claude 模型 | 报告撰写者 | 使用 MCP Client 的 AI |
| MCP Server A | 财务数据库接口 | Claude 用来查财务数据的桥梁 |
| MCP Server B | 项目管理系统接口 | Claude 查任务进度 |
| MCP Client | Claude 与这些系统建立连接的“翻译耳机” | 一边连 Claude,一边连各 MCP Server |
5.4 总结一句话
MCP Client 就像是大模型与 MCP Server 之间的连接器,它通过 MCP SDK 建立“连接会话”,让模型能发现并使用 MCP Server 暴露出的工具;如果模型需要连接多个 Server,就要分别管理多个连接对象。
六、 MCP两大基础协议介绍
6.1 消息协议:JSON-RPC 2.0
在MCP中规定了唯一的标准消息格式,就是JSON-RPC 2.0
JSON-RPC 2.0是一种轻量级的、用于远程过程调用(RPC)的消息交换协议,使用JSON作为数据格式
注意: 它不是一个底层通信协议,只是一个应用层的消息格式标准。这种消息协议的好处,与语言无关(还有语言不支持JSON吗)、简单易用(结构简单,天然可读,易于调试)、轻量灵活(可以适配各种传输方式)
6.2 基于SSE的Remote模式(MCP标准(2025-03-26版之前))
SSE(服务器发送事件)是一种基于HTTP协议的单向通信技术,允许Server主动实时向Client推送消息,Client只需建立一次连接即可持续接收消息。它的特点是:
- 单向(仅Server → Client)
- 基于HTTP协议,一般借助一次HTTP Get请求建立连接
- 适合实时消息推送场景(如进度更新、实时数据流等)
由于SSE是一种单向通信的模式,所以它需要配合HTTP Post来实现Client与Server的双向通信
严格的说,这是一种HTTP Post(Client->Server)+ HTTP SSE(Server -> Client)的伪双工通信模式
这种传输模式下:
- 一个HTTP Post通道,用于Client发送请求。比如调用MCP Server中的Tools并传递参数。注意,此时Server会立即返回
- 一个HTTP SSE通道,用于Server推送数据,比如返回调用结果或更新进度
- 两个通道通过session_id来关联,而请求与响应则通过消息中的id来对应
其基本通信过程如下:

详细描述如下:
- 连接建立: Client首先请求建立 SSE 连接,Server“同意”,然后生成并推送唯一的Session ID
- 请求发送: Client通过 HTTP POST 发送 JSON-RPC2.0 请求(请求中会带有Session ID 和Request ID信息)
- 请求接收确认: Server接收请求后立即返回 202(Accepted)状态码,表示已接受请求
- 异步处理: Server应用框架会自动处理请求,根据请求中的参数,决定调用某个工具或资源
- 结果推送: 处理完成后,Server通过 SSE 通道推送 JSON-RPC2.0 响应,其中带有对应的Request ID
- 结果匹配: Client的SSE连接侦听接收到数据流后,会根据Request ID 将接收到的响应与之前的请求匹配
- 重复处理: 循环2-6这个过程。这里面包含一个MCP的初始化过程
- 连接断开: 在Client完成所有请求后,可以选择断开SSE连接,会话结束
简单总结:通过HTTP Post发送请求,但通过SSE的长连接异步获得Server的响应结果
6.3 Streamable HTTP模式(MCP标准(2025-03-26版))
在MCP新标准(2025-03-26版)中,MCP引入了新的Streamable HTTP远程传输机制来代替之前的HTTP+SSE的远程传输模式,STDIO的本地模式不变
该新标准还在OAuth2.1的授权框架、JSON-RPC批处理、增强工具注解等方面进行增加和调整,且在2025.05.08号发布的MCP SDK 1.8.0版本中正式支持了Streamable HTTP
HTTP+SSE这种方式存在问题有:
- 需要维护两个独立的连接端点
- 有较高的连接可靠性要求。一旦SSE连接断开,Client无法自动恢复,需要重新建立新连接,导致上下文丢失
- Server必须为每个Client维持一个高可用长连接,对可用性和伸缩性提出挑战
- 强制所有Server向Client的消息都经由SSE单向推送,缺乏灵活性
其主要变化部分的基本通信过程如下:

这里的主要变化包括:
- Server只需一个统一的HTTP端点(/messages)用于通信
- Client可以完全无状态的方式与Server进行交互,即Restful HTTP Post方式
- 必要时Client也可以在单次请求中获得SSE方式响应,如:一个需要进度通知的长时间运行的任务,可以借助SSE不断推送进度
- Client也可以通过HTTP Get请求来打开一个长连接的SSE流,这种方式与当前的HTTP+SSE模式类似
- 增强的Session管理。Server会在初始化时返回Mcp-Session-Id,后续Client在每次请求中需要携带该MCP-Session-Id。这个Mcp-Session-Id作用是用来关联一次会话的多次交互;Server可以用Session-Id来终止会话,要求Client开启新会话;Client也可以用HTTP Delete请求来终止会话
Streamable HTTP在旧方案的基础上,提升了传输层的灵活性与健壮性:
- 允许无状态的Server存在,不依赖长连接。有更好的部署灵活性与扩展能力
- 对Server中间件的兼容性更好,只需要支持HTTP即可,无需做SSE处理
- 允许根据自身需要开启SSE响应或长连接,保留了现有规范SSE模式的优势

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 20
20 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)