我用Python爬虫爬取并分析了C站前100用户最高访问的2000篇文章_查询csdn阅读量靠前的python文章
别在网上瞎学了,我最近也做了一些资源的更新,只要你是我的粉丝,这期福利你都可拿走。我先来介绍一下这些东西怎么用,文末抱走。这是我花了几天的时间去把Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。最近我才对这些路线做了一下新的更新,知识体系更全面了。
做了那么多年开发,自学了很多门编程语言,我很明白学习资源对于学一门新语言的重要性,这些年也收藏了不少的Python干货,对我来说这些东西确实已经用不到了,但对于准备自学Python的人来说,或许它就是一个宝藏,可以给你省去很多的时间和精力。
别在网上瞎学了,我最近也做了一些资源的更新,只要你是我的粉丝,这期福利你都可拿走。
我先来介绍一下这些东西怎么用,文末抱走。
(1)Python所有方向的学习路线(新版)
这是我花了几天的时间去把Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。
最近我才对这些路线做了一下新的更新,知识体系更全面了。

(2)Python学习视频
包含了Python入门、爬虫、数据分析和web开发的学习视频,总共100多个,虽然没有那么全面,但是对于入门来说是没问题的,学完这些之后,你可以按照我上面的学习路线去网上找其他的知识资源进行进阶。

(3)100多个练手项目
我们在看视频学习的时候,不能光动眼动脑不动手,比较科学的学习方法是在理解之后运用它们,这时候练手项目就很适合了,只是里面的项目比较多,水平也是参差不齐,大家可以挑自己能做的项目去练练。

(4)200多本电子书
这些年我也收藏了很多电子书,大概200多本,有时候带实体书不方便的话,我就会去打开电子书看看,书籍可不一定比视频教程差,尤其是权威的技术书籍。
基本上主流的和经典的都有,这里我就不放图了,版权问题,个人看看是没有问题的。
(5)Python知识点汇总
知识点汇总有点像学习路线,但与学习路线不同的点就在于,知识点汇总更为细致,里面包含了对具体知识点的简单说明,而我们的学习路线则更为抽象和简单,只是为了方便大家只是某个领域你应该学习哪些技术栈。

(6)其他资料
还有其他的一些东西,比如说我自己出的Python入门图文类教程,没有电脑的时候用手机也可以学习知识,学会了理论之后再去敲代码实践验证,还有Python中文版的库资料、MySQL和HTML标签大全等等,这些都是可以送给粉丝们的东西。

这些都不是什么非常值钱的东西,但对于没有资源或者资源不是很好的学习者来说确实很不错,你要是用得到的话都可以直接抱走,关注过我的人都知道,这些都是可以拿到的。
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
将文本数据存成csv格式,先设计表头:
if not os.path.exists("articalInfo.csv"):
#创建存储csv文件存储数据
with open('articalInfo.csv', "w", encoding="utf-8-sig", newline='') as f:
csv_head = csv.writer(f)
csv_head.writerow(['title', 'viewCnt'])
注意编码格式为utf-8-sig,否则会乱码
接下来存数据:
length = len(info.titleList)
for i in range(length):
if info.titleList[i]:
with open('articalInfo.csv', 'a+', encoding='utf-8-sig') as f:
f.write(info.titleList[i] + ',' + info.viewCntList[i] + '\n')
总体数据可视化
新建一个模块专门用于可视化数据,与爬虫分离开,因为爬虫是慢IO过程,会影响调试效率,后面可以试试用协程来处理爬虫。
首先,把爬虫的信息读取到txt文件去
df = pd.read_csv('articalInfoNor.csv', encoding='utf-8-sig',usecols=['title', 'viewCnt'])
titleList = ','.join(df['title'].values)
with open('text.txt','a+', encoding='utf-8-sig') as f:
f.writelines(titleList)
如何返回分词结果:
def getKeyWordText():
# 读取文件信息
file = open(path.join(path.dirname(__file__), 'text.txt'), encoding='utf-8-sig').read()
return ' '.join(jieba.cut(file))
借助词云库可视化一下:
bg_pic = imread('2.jpg')
#生成词云
wordcloud = WordCloud(font_path=r'C:\Windows\Fonts\simsun.ttc',mask=bg_pic,background_color='white',scale=1.5).generate(text)
image_colors = ImageColorGenerator(bg_pic)
#显示词云图片
plt.imshow(wordcloud)
plt.axis('off')
plt.show()
#保存图片
wordcloud.to_file('test.jpg')

这个大大的“的”是什么鬼?显然高频关键词里有太多语气助词、连接词,我们最好设置一个停用词列表把这些明显不需要的词屏蔽掉。我这里采用修饰器的方法让代码更简洁,关于修饰器的内容可以参考Python修饰器
def splitText(mode):
stopWords = ["的","与","和","建议","收藏","使用","了","实现","我","中","你","在","之","年","月","日"]
def warpper(func):
def warp():
textSplit = func()
if mode:
temp = [word for word in textSplit if word not in stopWords]
return ' '.join(temp)
else:
return ' '.join(textSplit)
return warp
return warpper
当mode=True时启用屏蔽,否则关闭屏蔽,那么之前的函数应该修改为:
# 返回关键词文本
@splitText(False)
def getKeyWordText():
# 读取文件信息
file = open(path.join(path.dirname(__file__), 'text.txt'), encoding='utf-8-sig').read()
return jieba.cut(file)
再来一次:

现在就正常多了。可以看到Python和Java是绝对的领先,之后是各位总结的方法论等等,算法的词频反而不高?
数据分组
我把数据进一步分层为
1、访问量>10W
2、访问量5W~10W
3、访问量1W~5W
4、访问量5K~1W
5、访问量5K以下
先来看看数据分布情况:
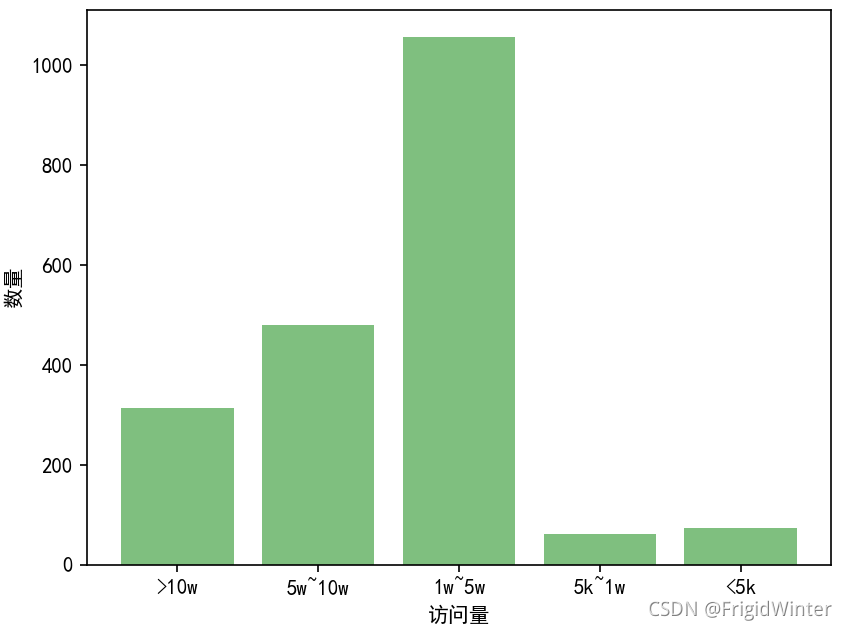
我猜如果分段分得再细一点可能趋于正态分布~
分组可视化看看:

10W的词云

5~10W的词云

1~5W的词云

5k~1W的词云
感觉从这里开始更百花齐放一些,似乎也更关注具体问题的解决

5k以下的词云
不得不感叹python在每个阶段都是牌面
完整代码
import requests
from bs4 import BeautifulSoup
import os, json, re, csv
class GetInfo:
def \_\_init\_\_(self) -> None:
# 请求头
self.headers = {
'User-Agent':
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'
}
# 排行榜url
self.rankUrl = "https://blog.csdn.net/phoenix/web/blog/all-rank?page={}&pageSize=20"
# 按访问量排行的文章列表
self.mostViewArtical = "https://blog.csdn.net/community/home-api/v1/get-business-list?page=1&size=20&businessType=blog&orderby=ViewCount&noMore=false&username={}"
self.userNames = self.__initRankUsrName()
self.titleList, self.viewCntList = self.__initArticalInfo(
self.userNames)
def \_\_initArticalInfo(self, usrList):
titleList = []
viewCntList = []
for name in usrList:
url = self.mostViewArtical.format(name)
# print(url)
response = requests.get(url=url, headers=self.headers)
response.encoding = 'utf-8'
response.raise_for_status()
titleList.extend(re.findall(r"\"title\":\"(.\*?)\"", response.text))
viewCntList.extend(
re.findall(r"\"viewCount\":(.\*?),", response.text))
return titleList, viewCntList
def \_\_initRankUsrName(self):
usrNameList = []
for i in range(5):
response = requests.get(url=self.rankUrl.format(i),
headers=self.headers)
response.encoding = 'utf-8'
response.raise_for_status()
soup = BeautifulSoup(response.text, 'html.parser')
information = json.loads(str(soup))
for item in information['data']['allRankListItem']:
usrNameList.append(item['userName'])
return usrNameList
info = GetInfo()
if not os.path.exists("articalInfo.csv"):
#创建存储csv文件存储数据
with open('articalInfo.csv', "w", encoding="utf-8-sig", newline='') as f:
csv_head = csv.writer(f)
csv_head.writerow(['title', 'viewCnt'])
length = len(info.titleList)
for i in range(length):
if info.titleList[i]:
with open('articalInfo.csv', 'a+', encoding='utf-8-sig') as f:
f.write(info.titleList[i] + ',' + info.viewCntList[i] + '\n')
from wordcloud import WordCloud,ImageColorGenerator
import matplotlib.pyplot as plt
from imageio import imread
import jieba
import pandas as pd
from os import path
df = pd.read_csv('articalInfoCom.csv', encoding='utf-8-sig',usecols=['title', 'viewCnt'])
titleList = ','.join(df['title'].values)
with open('text.txt','a+', encoding='utf-8-sig') as f:
f.writelines(titleList)
def splitText(mode):
stopWords = ["的","与","和","建议","收藏","使用","了","实现","我","中","你","在","之","年","月","日"]
def warpper(func):
def warp():
textSplit = func()
if mode:
temp = [word for word in textSplit if word not in stopWords]
return ' '.join(temp)
else:
return ' '.join(textSplit)
return warp
return warpper
# 返回关键词文本
@splitText(True)
def getKeyWordText():
# 读取文件信息
file = open(path.join(path.dirname(__file__), 'text.txt'), encoding='utf-8-sig').read()
return jieba.cut(file)
text = getKeyWordText()
#读取txt文件、背景图片
bg_pic = imread('2.jpg')
#生成词云
wordcloud = WordCloud(font_path=r'C:\Windows\Fonts\simsun.ttc',mask=bg_pic,background_color='white',scale=1.5).generate(text)
image_colors = ImageColorGenerator(bg_pic)
#显示词云图片
plt.imshow(wordcloud)
plt.axis('off')
plt.show()
#保存图片
wordcloud.to_file('test.jpg')
🔥 更多精彩专栏:
👇源码获取 · 技术交流 · 抱团学习 · 咨询分享 请联系👇
一、Python所有方向的学习路线
Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照下面的知识点去找对应的学习资源,保证自己学得较为全面。


二、Python必备开发工具
工具都帮大家整理好了,安装就可直接上手!
三、最新Python学习笔记
当我学到一定基础,有自己的理解能力的时候,会去阅读一些前辈整理的书籍或者手写的笔记资料,这些笔记详细记载了他们对一些技术点的理解,这些理解是比较独到,可以学到不一样的思路。

四、Python视频合集
观看全面零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

五、实战案例
纸上得来终觉浅,要学会跟着视频一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。
六、面试宝典


简历模板
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 22
22 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)