视觉学习——MaixCam_示例代码
定义应用程序ID,用于标识当前应用程序# 定义回显命令常量,值为0x01# 初始化通信方法,用于发送数据# 发送数据的方法,目前为空实现pass# 初始化通信方法,用于读取数据# 读取数据的方法,目前返回空字节串return b''# 设置应用程序ID,便于在响应消息中使用# 创建协议对象,缓冲区大小为1024字节# 主循环,直到应用程序需要退出# 初始化发送数据变量为None# 调用read()
2024_7_28
2024_11_5
MaixCam学习日志
一、audio(音频)
(一)、asr
1.1—asr—asr_digit.py(使用语音模型识别数字)
# 导入maix库中的app, nn, 和time模块
from maix import app, nn, time
# 创建一个Speech对象,用于加载和初始化语音识别模型
# 这里加载的模型文件位于"/root/models/am_3332_192_int8.mud"
speech = nn.Speech("/root/models/am_3332_192_int8.mud")
# 使用麦克风作为输入设备,并指定硬件设备为"hw:0,0"
# 这通常指的是声卡的第一个设备
speech.init(nn.SpeechDevice.DEVICE_MIC, "hw:0,0")
# 定义一个回调函数digit_callback,用于处理语音识别的结果
# data参数是识别出的语音数据,len参数是数据的长度
def digit_callback(data, len: int):
# 在回调函数中,打印出识别到的数据
print(data)
# 使用digit方法开始语音识别过程
# 640可能是识别的阈值或配置参数,digit_callback是识别结果的回调函数
speech.digit(640, digit_callback)
# 进入一个循环,只要app.need_exit()返回False,即程序没有请求退出,循环就会继续
while not app.need_exit():
# 调用speech对象的run方法,处理1帧的语音数据
# frames变量会存储run方法的返回值,表示处理的帧数
frames = speech.run(1)
# 如果frames小于1,表示没有有效的语音帧被处理,可能是没有检测到语音或者识别结束
if frames < 1:
# 打印"run out",表示语音识别过程可能已经结束或者没有更多的语音数据可以处理
print("run out\n")
# 跳出循环,结束程序
break1.2—asr—asr_kws.py(使用语音模型识别预定语句)
# 导入maix库中的app, nn, 和time模块
from maix import app, nn, time
# 创建一个Speech对象,用于加载和初始化语音识别模型
# 这里加载的模型文件位于"/root/models/am_3332_192_int8.mud"
speech = nn.Speech("/root/models/am_3332_192_int8.mud")
# 使用麦克风作为输入设备,并指定硬件设备为"hw:0,0"
# 这通常指的是声卡的第一个设备
speech.init(nn.SpeechDevice.DEVICE_MIC, "hw:0,0")
# 定义关键词表,包含三个关键词
kw_tbl = ['xiao3 ai4 tong2 xue2', # 小爱同学
'tian1 mao1 jing1 ling2', # 天猫精灵
'tian1 qi4 zen3 me yang4'] # 天气怎么样
# 定义关键词门限值,每个关键词的识别阈值
kw_gate = [0.1, 0.1, 0.1]
# 定义相似字符表,用于处理发音相似的关键词
similar_char = ['xin1', 'ting1', 'jin1']
# 定义关键词识别回调函数kws_callback
# data参数是每个关键词的识别分数列表,len参数是列表的长度
def kws_callback(data:list[float], len: int):
maxp = -1 # 初始化最大识别分数为-1
# 遍历每个关键词的识别分数
for i in range(len):
# 打印每个关键词的识别分数,保留三位小数
print(f"\tkw{i}: {data[i]:.3f};", end=' ')
# 如果当前关键词的分数大于已知的最大分数,则更新最大分数
if data[i] > maxp:
maxp = data[i]
# 打印换行符,结束当前行的打印
print("\n")
# 使用kws方法开始关键词识别过程
# kw_tbl是关键词表,kw_gate是关键词门限值,kws_callback是识别结果的回调函数
# True表示开启相似字符处理
speech.kws(kw_tbl, kw_gate, kws_callback, True)
# 进入一个循环,只要app.need_exit()返回False,即程序没有请求退出,循环就会继续
while not app.need_exit():
# 调用speech对象的run方法,处理1帧的语音数据
# frames变量会存储run方法的返回值,表示处理的帧数
frames = speech.run(1)
# 如果frames小于1,表示没有有效的语音帧被处理,可能是没有检测到语音或者识别结束
if frames < 1:
# 打印"run out",表示语音识别过程可能已经结束或者没有更多的语音数据可以处理
print("run out\n")
# 跳出循环,结束程序
break1.3—asr—asr_lvcsr.py(使用语音模型识别中文)
(二)、audio_play
audio_playback.py
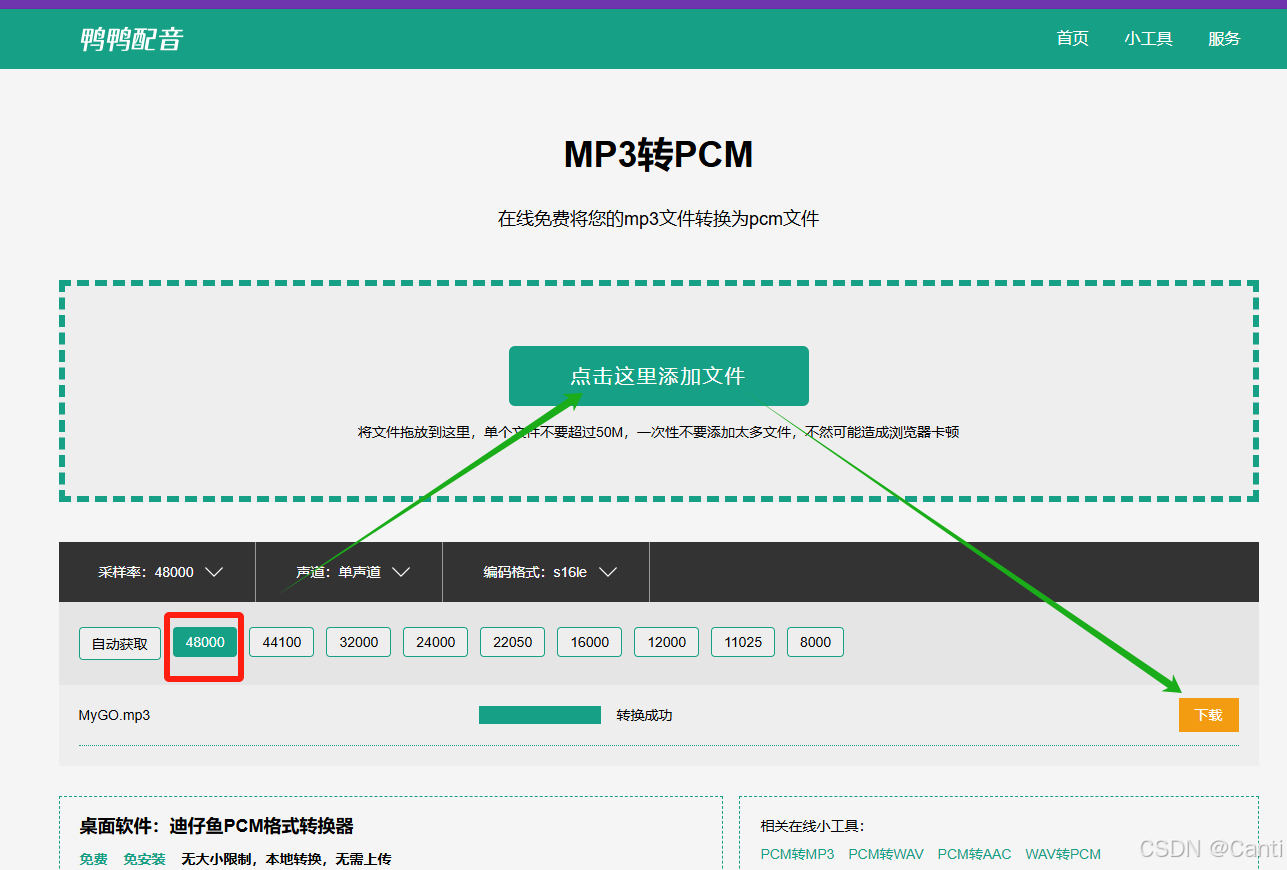
1.获取 ” MyGO.pcm “ 格式音频文件
先下载mp3格式文件,再转成pcm格式下载
MP3转PCM - MP3转PCM在线格式转换器 - 鸭鸭配音
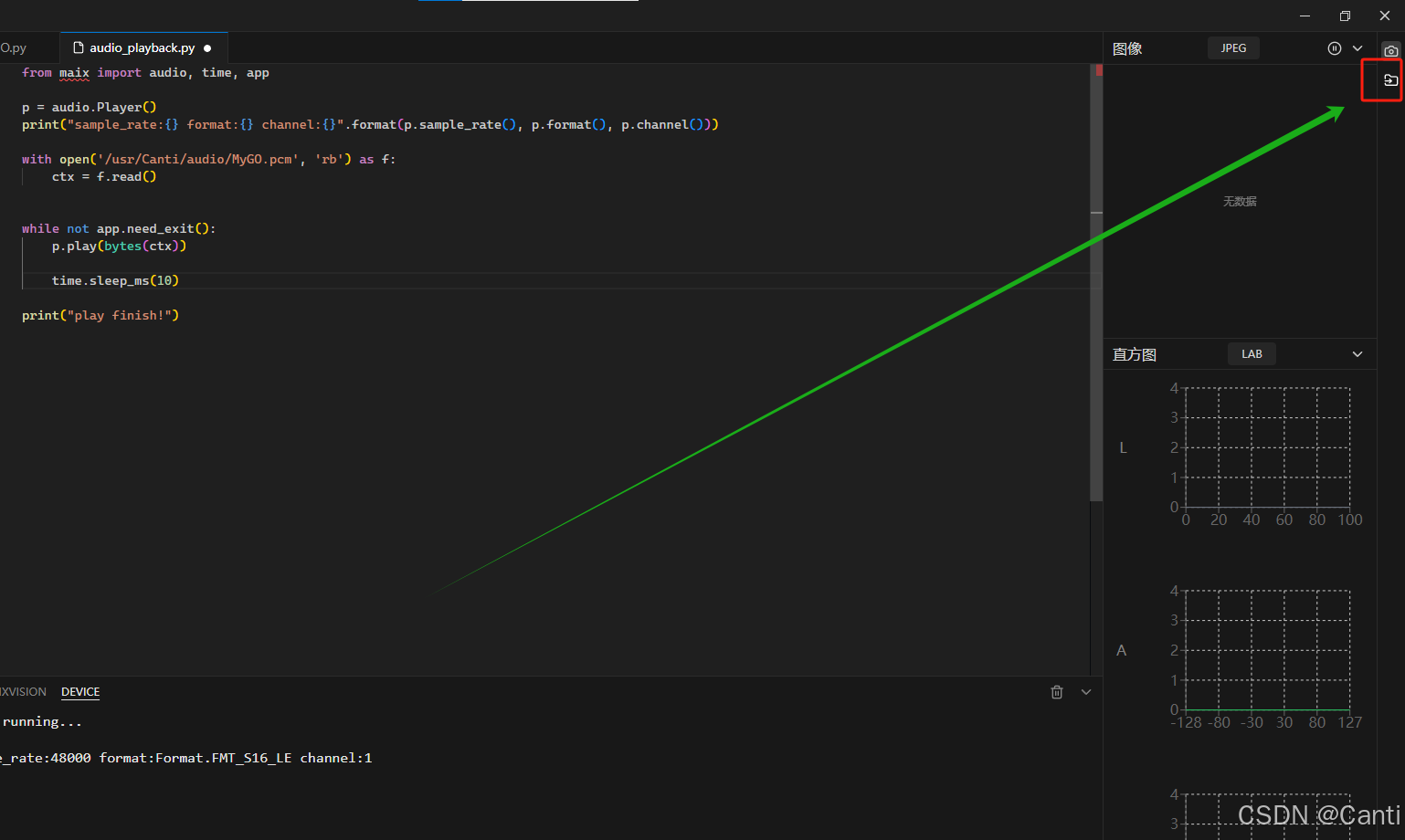
2.保存到cam目录
链接到系统目录
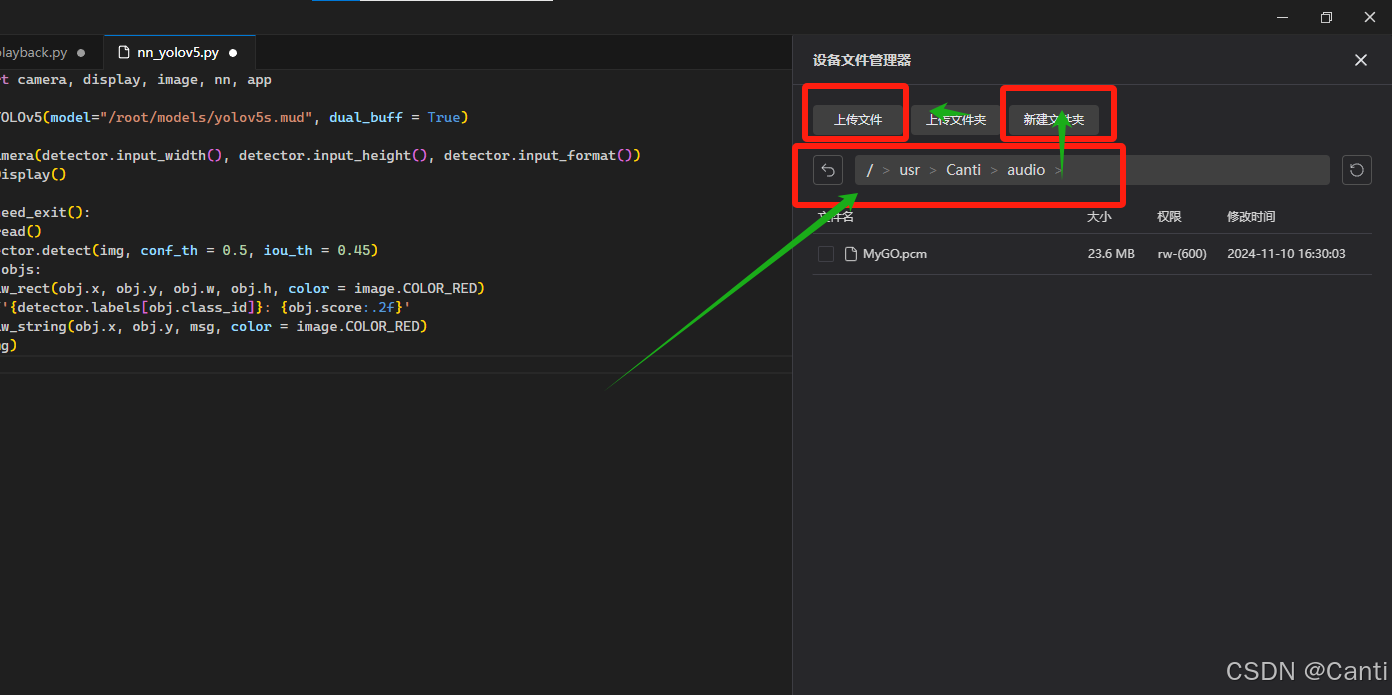
在目录中新建路径,并上传音频文件
3.使用示例代码
# 导入MaixPy模块中的audio、time和app模块
from maix import audio, time, app
# 创建一个音频播放器对象
p = audio.Player()
# 打印音频播放器的采样率、格式和通道数
# 这些信息对于理解音频文件的属性很重要
print("sample_rate:{} format:{} channel:{}".format(p.sample_rate(), p.format(), p.channel()))
# 打开PCM音频文件,这里假设文件位于'/usr/Canti/audio/MyGO.pcm'路径下
# 'rb'模式表示以二进制读取模式打开文件
with open('/usr/Canti/audio/MyGO.pcm', 'rb') as f:
# 读取文件内容到变量ctx中
ctx = f.read()
# 使用音频播放器对象p播放音频文件内容
# bytes(ctx)将读取的文件内容转换为字节类型,这是play方法需要的格式
p.play(bytes(ctx))
# 播放结束后,再次播放相同的音频文件内容
# 这里使用time.sleep_ms(10)等待10毫秒,可能用于确保音频播放完成或其他目的
time.sleep_ms(10)
p.play(bytes(ctx))
# 进入一个循环,只要app.need_exit()返回False,即没有接收到退出信号,就继续循环
while not app.need_exit():
# 在循环中,每次循环暂停10毫秒,减少CPU占用,同时检查是否有退出信号
time.sleep_ms(10)
# 当循环结束,即接收到退出信号后,打印“play finish!”表示播放结束
print("play finish!")二、basic(一些python中类与对象的封装举例)
三、sxt_dev(bm8653)
bmp8653_rw_example.py(设置和读取实时时钟的时间)
# 导入maix库中的ext_dev, pinmap, err, 和time模块
from maix import ext_dev, pinmap, err, time
### Enable I2C
# 以下代码被注释掉了,它们的作用是设置特定的引脚为I2C的时钟线(SCL)和数据线(SDA)。
# 这些代码在实际使用中需要根据硬件连接的引脚来设置"PIN_NAME"。
# ret = pinmap.set_pin_function("PIN_NAME", "I2Cx_SCL")
# if ret != err.Err.ERR_NONE:
# print("Failed in function pinmap...")
# exit(-1)
# ret = pinmap.set_pin_function("PIN_NAME", "I2Cx_SDA")
# if ret != err.Err.ERR_NONE:
# print("Failed in function pinmap...")
# exit(-1)
# 定义I2C总线编号,这里使用的是I2C总线4
BM8653_I2CBUS_NUM = 4
# 创建BM8563 RTC对象,传入I2C总线编号
rtc = ext_dev.bm8563.BM8563(BM8653_I2CBUS_NUM)
### 设置时间为2020年12月31日23时59分45秒
t = [2020, 12, 31, 23, 59, 45]
# 通过RTC对象设置时间
rtc.datetime(t)
# 进入一个无限循环,不断地读取和打印当前时间
while True:
# 从RTC读取当前时间
rtc_now = rtc.datetime()
# 如果读取失败(返回空列表),打印错误信息并继续循环
if rtc_now == []:
print("Read failed, continue")
continue
# 打印当前时间,格式为年-月-日 时:分:秒
print(f"{rtc_now[0]}-{rtc_now[1]}-{rtc_now[2]} {rtc_now[3]}:{rtc_now[4]}:{rtc_now[5]}")
# 休眠1秒
time.sleep(1)bmp8653_sync_example.py(从网络更新时间,时区好像不是东八)
# 导入maix库中的ext_dev, pinmap, err, 和time模块
from maix import ext_dev, pinmap, err, time
### Enable I2C
# 以下代码被注释掉了,它们的作用是设置特定的引脚为I2C的时钟线(SCL)和数据线(SDA)。
# 这些代码在实际使用中需要根据硬件连接的引脚来设置"PIN_NAME"。
# ret = pinmap.set_pin_function("PIN_NAME", "I2Cx_SCL")
# if ret != err.Err.ERR_NONE:
# print("Failed in function pinmap...")
# exit(-1)
# ret = pinmap.set_pin_function("PIN_NAME", "I2Cx_SDA")
# if ret != err.Err.ERR_NONE:
# print("Failed in function pinmap...")
# exit(-1)
# 定义I2C总线编号,这里使用的是I2C总线4
BM8653_I2CBUS_NUM = 4
# 创建BM8563 RTC对象,传入I2C总线编号
rtc = ext_dev.bm8563.BM8563(BM8653_I2CBUS_NUM)
### Update RTC time from system
# 从系统时间更新RTC时间
rtc.systohc()
### Update system time from RTC
# 从RTC更新系统时间(这行代码被注释掉了)
# rtc.hctosys()
# 进入一个无限循环,不断地读取和打印当前时间
while True:
# 从RTC读取当前时间
rtc_now = rtc.datetime()
# 打印当前时间,格式为年-月-日 时:分:秒
print(f"{rtc_now[0]}-{rtc_now[1]}-{rtc_now[2]} {rtc_now[3]}:{rtc_now[4]}:{rtc_now[5]}")
# 休眠1秒
time.sleep(1)四、gui(屏幕UI显示)
(一)、i18n_demo
(一)、i18n_display.py
# 导入maix模块中的一些功能,包括国际化(i18n)、图像(image)、显示(display)、应用(app)和时间(time)模块。
from maix import i18n, image, display, app, time
# 创建一个字典,用于存储不同语言的翻译。
trans_dict = {
"zh": { # 简体中文
"hello": "你好" # "hello"的中文翻译是"你好"
},
"en": { # 英语,这里没有提供翻译,所以默认为空
}
}
# 使用上面创建的字典初始化一个国际化翻译对象。
trans = i18n.Trans(trans_dict)
tr = trans.tr # 获取翻译函数的引用,用于获取翻译后的字符串。
# 设置当前语言环境为简体中文。
trans.set_locale("zh")
# 创建一个显示对象,用于控制屏幕显示。
disp = display.Display()
# 加载中文字体,并设置字体大小为24。
image.load_font("sourcehansans", "/maixapp/share/font/SourceHanSansCN-Regular.otf", size = 24)
image.set_default_font("sourcehansans") # 设置默认字体为刚加载的中文字体。
# 创建一个图像对象,大小与屏幕分辨率相同。
img = image.Image(disp.width(), disp.height())
# 在图像上绘制字符串"你好",位置在(10, 10),颜色为白色,字体缩放比例为2。
img.draw_string(10, 10, tr("hello"), image.COLOR_WHITE, scale=2)
disp.show(img) # 将图像显示在屏幕上。
# 进入一个循环,只要应用没有退出,就持续显示图像。
while not app.need_exit():
time.sleep_ms(100) # 每次循环暂停100毫秒,减少CPU占用。五、maixpy_v1
六、network (网络)
七、peripheral (外设)
( 八 )、uart
8.1—uart—comm_uart.py
from maix import app, uart, pinmap, time
import sys
# 列出所有UART设备
# ports = uart.list_devices()
# 设置引脚功能,将A16设置为UART0的TX(发送)引脚,将A17设置为UART0的RX(接收)引脚
# pinmap.set_pin_function("A16", "UART0_TX")
# pinmap.set_pin_function("A17", "UART0_RX")
# 指定UART设备
device = "/dev/ttyS0"
# 初始化UART设备,波特率为115200
serial0 = uart.UART(device, 115200)
# 发送字符串"hello 1"并换行
serial0.write("hello 1\r\n".encode())
# 发送字符串"hello 2"并换行
serial0.write_str("hello 2\r\n")
# 主循环,直到应用程序需要退出
while not app.need_exit():
# 从UART读取数据
data = serial0.read()
if data:
# 如果有数据,打印数据类型、长度和内容
print("Received, type: {}, len: {}, data: {}".format(type(data), len(data), data))
# 将接收到的数据回传
serial0.write(data)
# 休眠1毫秒,让CPU空闲
time.sleep_ms(1)
八、protocol()
4.1—comm_protocol_custom_method.py(编写自定义通讯协议)
from maix import protocol
from maix import app
from maix.err import Err
# 定义应用程序ID,用于标识当前应用程序
APP_ID = "my_app1"
# 定义回显命令常量,值为0x01
APP_CMD_ECHO = 0x01
# 初始化通信方法,用于发送数据
def send(data:bytes):
# 发送数据的方法,目前为空实现
pass
# 初始化通信方法,用于读取数据
def read():
# 读取数据的方法,目前返回空字节串
return b''
# 设置应用程序ID,便于在响应消息中使用
app.set_app_id(APP_ID)
# 创建协议对象,缓冲区大小为1024字节
p = protocol.Protocol(buff_size = 1024)
# 主循环,直到应用程序需要退出
while not app.need_exit():
# 初始化发送数据变量为None
send_data = None
# 调用read()方法读取数据
data = read()
# 使用协议对象解码读取的数据,得到消息对象
msg = p.decode(data)
# 如果消息对象存在且是请求消息
if msg and msg.is_req:
# 如果消息命令是回显命令
if msg.cmd == APP_CMD_ECHO:
# 创建响应消息,内容为"echo from app {app_id}"
resp_msg = "echo from app {}".format(app.app_id())
# 使用协议对象编码响应消息,表示成功响应
send_data = msg.encode_resp_ok(resp_msg.encode())
# 如果消息命令是设置报告命令
elif msg.cmd == protocol.CMD.CMD_SET_REPORT:
# 使用协议对象编码错误响应消息,表示命令未实现
send_data = msg.encode_resp_err(Err.ERR_NOT_IMPL, "this cmd not support auto upload".encode())
# 如果有发送数据,调用send()方法发送响应数据
if send_data:
send(send_data)
4.2—comm_protocol_yolov5.py()
import struct
from maix import camera, display, image, nn, app
from maix import comm, protocol
from maix.err import Err
# 初始化YOLOv5对象检测模型
detector = nn.YOLOv5(model="/root/models/yolov5s.mud")
# 初始化摄像头,分辨率和格式与模型输入一致
cam = camera.Camera(detector.input_width(), detector.input_height(), detector.input_format())
# 初始化显示屏
dis = display.Display()
# 定义应用程序命令常量
APP_CMD_ECHO = 0x01
APP_CMD_DETECT_RES = 0x02
# 初始化报告开关
report_on = True
def encode_objs(objs):
'''
将对象信息编码为字节数据,用于协议传输
每个对象编码为:2字节x(小端序)+ 2字节y(小端序)+ 2字节w(小端序)+ 2字节h(小端序)+ 2字节class_id(小端序)
'''
body = b''
for obj in objs:
body += struct.pack("<hhHHH", obj.x, obj.y, obj.w, obj.h, obj.class_id)
return body
def decode_objs(body):
'''
将字节数据解码为对象信息,根据指定的协议格式
每个对象编码为:2字节x(有符号,小端序),2字节y(有符号,小端序),2字节w(无符号,小端序),
2字节h(无符号,小端序),2字节class_id(无符号,小端序)
'''
objs = []
i = 0
obj_size = struct.calcsize("<hhHHH") # 计算每个对象数据块的大小
while i < len(body):
# 根据指定格式解码数据
x, y, w, h, class_id = struct.unpack_from("<hhHHH", body, i)
objs.append({'x': x, 'y': y, 'w': w, 'h': h, 'class_id': class_id})
i += obj_size # 移动索引到下一个对象的起始位置
return objs
# 初始化通信对象,根据系统配置初始化UART或TCP服务器
# 可以通过maix.app.get_sys_config_kv("comm", "method")获取当前设置
p = comm.CommProtocol(buff_size = 1024)
while not app.need_exit():
# 接收并解码来自对端的消息
msg = p.get_msg()
if msg and msg.is_req: # 找到消息并且是请求
if msg.cmd == APP_CMD_ECHO:
# 处理回显命令,生成响应消息
resp_msg = "echo from app {}".format(app.app_id())
p.resp_ok(msg.cmd, resp_msg.encode())
elif msg.cmd == protocol.CMD.CMD_SET_REPORT:
# 处理设置报告命令
body = msg.get_body()
report_on = body[0] == 1 # 消息体的第一个字节为0x01表示自动报告,否则禁用报告
resp_body = b'\x01' # 0x01表示设置成功
p.resp_ok(msg.cmd, resp_body)
elif msg and msg.is_report and msg.cmd == APP_CMD_DETECT_RES:
# 处理检测结果报告
print("receive objs:", decode_objs(msg.get_body()))
p.resp_ok(msg.cmd, b'1')
# 检测对象
img = cam.read()
objs = detector.detect(img, conf_th = 0.5, iou_th = 0.45)
# 编码对象信息并发送
if len(objs) > 0 and report_on:
body = encode_objs(objs)
p.report(APP_CMD_DETECT_RES, body)
# 在屏幕上绘制检测结果
for obj in objs:
img.draw_rect(obj.x, obj.y, obj.w, obj.h, color = image.COLOR_RED)
msg = f'{detector.labels[obj.class_id]}: {obj.score:.2f}'
img.draw_string(obj.x, obj.y, msg, color = image.COLOR_RED)
dis.show(img)
九、sensors(传感器)
十、tools(工具)
十一、vision(视觉)
(一)、
1.1—ai_vision—nn_classifier.py
使用一个预训练的模型对从相机捕获的图像进行分类,并将分类结果显示在屏幕上
# 导入MaixPy库中的一些模块
from maix import camera, display, image, nn, app
# 创建一个分类器对象,该对象使用了预训练的MobileNetV2模型
classifier = nn.Classifier(model="/root/models/mobilenetv2.mud")
# 初始化一个相机对象,相机的分辨率和格式与分类器的输入匹配
cam = camera.Camera(classifier.input_width(), classifier.input_height(), classifier.input_format())
# 初始化一个显示对象,用于在屏幕上显示图像
disp = display.Display()
# 开始一个循环,只要应用程序没有收到退出信号,就会一直运行
while not app.need_exit():
# 从相机读取一帧图像
img = cam.read()
# 使用分类器对读取的图像进行分类
res = classifier.classify(img)
# 获取分类结果中概率最高的类别的索引和概率
max_idx, max_prob = res[0]
# 生成一个字符串,包含了最可能的类别的概率和标签
msg = f"{max_prob:5.2f}: {classifier.labels[max_idx]}"
# 在图像上绘制一个红色的字符串,显示了分类结果
img.draw_string(10, 10, msg, image.COLOR_RED)
# 将图像的大小调整为显示器的大小
img = img.resize(disp.width(), disp.height(), image.Fit.FIT_CONTAIN)
# 将调整大小后的图像显示在屏幕上
disp.show(img)
1.2—ai_vision—nn_face_recognize.py(人脸追踪)
1.3—ai_vision—nn_facedecedector.py(人脸特征提取)
1.4—ai_vision—nn_forward(评估模型的实时性能)
代码中的输出语句 print(f"forward complete, average forward time: {t} ms\n") 和 print(f"forward dual buff mode complete, average forward time: {t} ms\n")
会打印出两个平均时间,分别对应非双缓冲模式和双缓冲模式下的推理时间。(推理速度受到多种因素的影响,包括模型的复杂度、输入数据的大小、硬件的计算能力以及软件优化等。)
输出信息:
-- [I] load cvimodel from: /root/models/yolov8n.cvimodel
version: 1.4.0
yolov8n_320x224 Build at 2024-06-12 16:25:34 For platform cv181x
这部分表明模型文件从 /root/models/yolov8n.cvimodel 路径加载。
version: 1.4.0 表示模型文件的版本是 1.4.0。
yolov8n_320x224 是模型的名称,表明这是一个 YOLOv8 的变种,输入图像尺寸为 320x224 像素。
Build at 2024-06-12 16:25:34 表示模型文件是在 2024 年 6 月 12 日 16:25:34 构建的。
For platform cv181x 表示这个模型是为 cv181x 平台(Sipeed Maix 系列开发板)优化的。
Max SharedMem size:588000
inputs:
LayerInfo(name='images', dtype=int8, shape=[1, 3, 224, 320])
inputs: 表示接下来的信息是关于模型输入的。
LayerInfo 是一个包含输入层信息的对象。
name='images' 表示输入层的名称是 images。
dtype=int8 表示输入数据的数据类型是 8 位整数。
shape=[1, 3, 224, 320] 表示输入数据的形状,其中:
1 是批次大小(batch size),表示一次推理处理一个图像。
3 是颜色通道数,表示输入图像是彩色的(RGB)。
224 和 320 分别是输入图像的高度和宽度。forward now
find shared memory(588000), saved:588000
forward complete, average forward time: 12.4 ms
forward now 表示开始进行前向推理。
find shared memory(588000), saved:588000 表示找到了 588000 字节的共享内存,并成功节省了这部分内存。
forward complete, average forward time: 12.4 ms 表示完成一次前向推理的平均时间是 12.4 毫秒。
forward dual buff mode now
forward dual buff mode complete, average forward time: 8.6 ms
out [/model.22/Sigmoid_output_0_Sigmoid_f32], shape: (1, 80, 1470, 1)
out [/model.22/dfl/conv/Conv_output_0_Conv_f32], shape: (1, 1, 4, 1470)
end
(1, 80, 1470, 1):
第一个维度 1 表示批次大小(batch size),这里为1,意味着每次推理处理一个输入样本。
第二个维度 80 通常表示输出的类别数加上背景(如果有的话)。在目标检测模型中,这可能表示每个检测框预测的类别数加上一个表示是否为背景的额外类别。
第三个维度 1470 表示在特征图上的位置数。这个数字取决于输入图像的尺寸和模型的架构。在这个例子中,它可能是模型在某个中间层的特征图尺寸,乘以宽度和高度。
第四个维度 1 通常表示每个位置的预测框数。在目标检测中,这意味着模型预测了每个位置的一个或多个边界框。
1.5—ai_vision—nn_model_info(显示模型文件信息)
start running...
-- [I] load cvimodel from: /root/models/yolov8n.cvimodel
version: 1.4.0
yolov8n_320x224 Build at 2024-06-12 16:25:34 For platform cv181x
Max SharedMem size:588000
这表明程序开始运行。
这是一个信息提示,表示程序正在从指定路径加载一个.cvimodel格式的模型文件。
这行显示了模型文件的版本号,这里是1.4.0。
这里提供了模型的名称(yolov8n_320x224),表明这是一个YOLOv8模型,输入图像尺寸为320x224像素。同时显示了模型构建的时间和目标平台(cv181x)。
这行显示了最大共享内存的大小,这里是588000字节。inputs:
LayerInfo(name='images', dtype=int8, shape=[1, 3, 224, 320])
这里显示了模型输入层的信息:
name='images':输入层的名称是images。
dtype=int8:输入数据的类型是8位整数。
shape=[1, 3, 224, 320]:输入数据的形状,表示批次大小为1,颜色通道数为3(RGB),图像高度为224像素,宽度为320像素。outputs:
LayerInfo(name='/model.22/dfl/conv/Conv_output_0_Conv_f32', dtype=int8, shape=[1, 1, 4, 1470])
LayerInfo(name='/model.22/Sigmoid_output_0_Sigmoid_f32', dtype=int8, shape=[1, 80, 1470, 1])
这里显示了模型的两个输出层信息:
第一个输出层/model.22/dfl/conv/Conv_output_0_Conv_f32的形状是[1, 1, 4, 1470],可能表示每个位置的边界框坐标。
第二个输出层/model.22/Sigmoid_output_0_Sigmoid_f32的形状是[1, 80, 1470, 1],可能表示每个位置的类别概率。extra info:
[input_type]: rgb
[labels]: person, bicycle, car, motorcycle, airplane, ...
[mean]: 0, 0, 0
[model_type]: yolov8
[scale]: 0.00392156862745098, 0.00392156862745098, 0.00392156862745098
显示了模型的一些额外信息:
[input_type]: rgb:输入图像的类型是RGB。
[labels]:列出了模型可以识别的所有类别标签,如人、自行车、汽车等。
[mean]:显示了输入数据的均值,这里是0,表示输入数据没有经过均值归一化。
[model_type]:表明模型的类型是YOLOv8。
[scale]:显示了输入数据的缩放因子,这里是0.00392156862745098,用于归一化输入数据。1.6—ai_vision—nn_pp_ocr.py
1.7—ai_vision—nn_self_learn_classifier_cam.py
1.8—ai_vision—nn_self_learn_classifier.py
1.9—ai_vision—nn_self_learn_tracker.py
1.10—ai_vision—nn_self_yolov5.py
# 导入 MaixPy 库中的相关模块
from maix import camera, display, image, nn, app
# 创建一个 YOLOv5 神经网络检测器对象,加载模型文件,并启用双缓冲
detector = nn.YOLOv5(model="/root/models/yolov5s.mud", dual_buff=True)
# 初始化相机,设置输入的宽度、高度和格式,这些参数由检测器对象提供
cam = camera.Camera(detector.input_width(), detector.input_height(), detector.input_format())
# 初始化显示屏
dis = display.Display()
# 创建一个循环,只要应用程序没有请求退出,就继续运行
while not app.need_exit():
# 从相机读取一帧图像
img = cam.read()
# 使用检测器对象对图像进行物体检测,设置置信度阈值为 0.5 和交并比阈值为 0.45
objs = detector.detect(img, conf_th=0.5, iou_th=0.45)
# 遍历检测到的所有物体
for obj in objs:
# 在图像上绘制一个矩形框,表示检测到的物体的位置
img.draw_rect(obj.x, obj.y, obj.w, obj.h, color=image.COLOR_RED)
# 创建一个字符串消息,包含物体的类别和置信度
msg = f'{detector.labels[obj.class_id]}: {obj.score:.2f}'
# 在图像上绘制文本消息
img.draw_string(obj.x, obj.y, msg, color=image.COLOR_RED)
# 1.11—ai_vision—nn_self_yolov8_face.py
1.12—ai_vision—nn_self_yolov8_pose.py
1.13—ai_vision—nn_self_yolov8_seg.py
1.14—ai_vision—nn_self_yolov8.py
2.1—audio—audioplayback.py(播放音频)
# 导入MaixPy库中的一些模块
from maix import audio, time, app
# 创建一个音频播放器对象
p = audio.Player()
# 打印播放器的采样率、格式和通道数
print("sample_rate:{} format:{} channel:{}".format(p.sample_rate(), p.format(), p.channel()))
# 打开一个音频文件,并读取其内容
with open('/root/output.pcm', 'rb') as f:
ctx = f.read()
# 使用播放器播放读取的音频数据
p.play(bytes(ctx))
# 开始一个循环,只要应用程序没有收到退出信号,就会一直运行
while not app.need_exit():
# 暂停10毫秒
time.sleep_ms(10)
# 打印播放完成的消息
print("play finish!")
3 —camera—camera_capture.py(拍照)
# 导入MaixPy库中的一些模块
from maix import camera, display, time, app
# 创建一个相机对象,手动设置分辨率为512x320,因为默认的分辨率太大了
cam = camera.Camera(512, 320)
# 创建一个显示对象,MaixCAM的默认分辨率是552x368
disp = display.Display()
# 开始一个循环,只要应用程序没有收到退出信号,就会一直运行
while not app.need_exit():
# 记录当前的时间
t = time.ticks_ms()
# 从相机读取一帧图像,相机的最大帧率由相机硬件和驱动设置决定
img = cam.read()
# 在显示器上显示图像
disp.show(img)
# 打印出读取和显示图像所花费的时间,以及帧率
print(f"time: {time.ticks_ms() - t}ms, fps: {1000 / (time.ticks_ms() - t)}")
4.1 —display—display_backlight.py(屏幕背光设置)
# 导入MaixPy库中的一些模块
from maix import pwm, time, display, image
# 创建一个显示对象
disp = display.Display()
# 定义一个函数,用于在显示器上显示一个红色的圆和一个字符串
def show(i):
# 创建一个图像对象,大小与显示器的大小相同
img = image.Image(disp.width(), disp.height())
# 在图像上绘制一个红色的圆,圆心位于图像的中心,半径为50
img.draw_circle(disp.width() // 2, disp.height() //2, 50, image.COLOR_RED, thickness=-1)
# 在图像上绘制一个字符串,显示当前的亮度百分比
img.draw_string(2, 2, f"{i}%", image.COLOR_WHITE, scale=2)
# 在显示器上显示图像
disp.show(img)
# 循环100次,每次将显示器的背光亮度增加1%,并显示当前的亮度百分比
for i in range(100):
disp.set_backlight(i)
show(i)
time.sleep_ms(50)
# 循环100次,每次将显示器的背光亮度减少1%,并显示当前的亮度百分比
for i in range(100):
disp.set_backlight(100 - i)
show(100 - i)
time.sleep_ms(50)
4.2 —display—display_backlight.py(屏幕图像显示)
# 导入MaixPy库中的一些模块
from maix import display, app, image
# 创建一个显示对象
disp = display.Display()
# 打印出显示器初始化完成的消息
print("display init done")
# 打印出显示器的大小
print(f"display size: {disp.width()}x{disp.height()}")
# 初始化一个变量y,用于控制文本的垂直位置
y = 0
# 定义要显示的文本
text = "Hello, MaixPy!"
# 开始一个循环,只要应用程序没有收到退出信号,就会一直运行
while not app.need_exit():
# 创建一个新的图像对象,大小与显示器的大小相同,格式为RGB888
img = image.Image(disp.width(), disp.height(), image.Format.FMT_RGB888)
# 在图像上绘制一个红色的矩形,位置由变量y控制,宽度为文本的宽度加10,高度为80
img.draw_rect(0, y, image.string_size(text, scale=2).width() + 10, 80, color=image.Color.from_rgb(255, 0, 0), thickness=-1)
# 在图像上绘制文本,位置由变量y控制,颜色为白色,缩放因子为2
img.draw_string(4, y + 4, text, color=image.Color.from_rgb(255, 255, 255), scale=2)
# 在显示器上显示图像
disp.show(img)
# 更新变量y的值,使其在每次循环时增加1,当达到显示器的高度时回到0
y = (y + 1) % disp.height()
5.1 —image_basic—binary.py(图像处理常见预处理——图像二值化处理)
# 导入MaixPy库中的图像模块
from maix import image
# 1. 加载图像
# 使用image.load函数加载一个名为"test.jpg"的图像文件
src_img = image.load("test.jpg")
# 如果加载失败,则抛出异常
if src_img is None:
raise Exception(f"load image {file_path} failed")
# 2. 对图像进行二值化
# 定义一个阈值元组,用于二值化操作
thresholds = ((0, 100, 20, 80, 10, 80))
# 创建一个源图像的副本
img = src_img.copy()
# 使用binary函数对图像进行二值化操作
img.binary(thresholds)
# 将二值化后的图像保存为"binary.jpg"
img.save("binary.jpg")
5.2 —image_basic—draw_transparent_image.py(图像显示—多图层)
# 导入MaixPy库中的一些模块
from maix import display, image, app, time
# 定义要加载的图像文件的路径
file_path = "/maixapp/share/icon/detector.png"
# 加载图像文件,如果文件的扩展名是.png,则格式为RGBA8888,否则为RGB888
img = image.load(file_path, format = image.Format.FMT_RGBA8888 if file_path.endswith(".png") else image.Format.FMT_RGB888)
# 如果加载图像失败,则抛出异常
if img is None:
raise Exception(f"load image {file_path} failed")
# 创建一个显示对象
disp = display.Display()
# 创建一个新的图像对象,大小与显示器的大小相同,格式为RGBA8888
img_show = image.Image(disp.width(), disp.height(), image.Format.FMT_RGBA8888)
# 在新的图像对象上绘制一个紫色的矩形,覆盖整个图像
img_show.draw_rect(0, 0, img_show.width(), img_show.height(), image.COLOR_PURPLE, thickness=-1)
# 在新的图像对象上绘制加载的图像
img_show.draw_image(0, 0, img)
# 在显示器上显示新的图像对象
disp.show(img_show)
# 开始一个循环,只要应用程序没有收到退出信号,就会一直运行
while not app.need_exit():
# 暂停100毫秒
time.sleep_ms(100)
img是背景图层;img_show是绘图图层
5.3 —image_basic—find_apriltags.py(识别Apriltag信息)
# 导入MaixPy库中的一些模块
from maix import camera, display, image
# 导入ApriltagFamilies模块,这个模块包含了各种Apriltag的定义
from maix.image import ApriltagFamilies
# 创建一个相机对象,分辨率为160x120
cam = camera.Camera(160, 120)
# 创建一个显示对象
disp = display.Display()
# 定义要寻找的Apriltag的类型
families = ApriltagFamilies.TAG36H11
# 开始一个无限循环
while 1:
# 从相机读取一帧图像
img = cam.read()
# 在图像中寻找Apriltags
apriltags = img.find_apriltags(families=ApriltagFamilies.TAG36H11)
# 对于找到的每一个Apriltag
for a in apriltags:
# 获取Apriltag的四个角点
corners = a.corners()
# 对于每一个角点
for i in range(4):
# 在图像上绘制一条连接两个角点的绿色线段
img.draw_line(corners[i][0], corners[i][1], corners[(i + 1) % 4][0], corners[(i + 1) % 4][1], image.COLOR_GREEN, 2)
# 在显示器上显示图像
disp.show(img)
Apriltag:贴在设备上标识设备的空间位置
5.4 —image_basic—find_barcode.py(识别条形码信息)
# 导入MaixPy库中的一些模块
from maix import camera, display, image
# 创建一个相机对象,分辨率为320x240
cam = camera.Camera(320, 240)
# 创建一个显示对象
disp = display.Display()
# 开始一个无限循环
while 1:
# 从相机读取一帧图像
img = cam.read()
# 在图像中寻找条形码
barcodes = img.find_barcodes()
# 对于找到的每一个条形码
for b in barcodes:
# 获取条形码的矩形区域
rect = b.rect()
# 在图像上绘制一个蓝色的矩形,表示条形码的位置
img.draw_rect(rect[0], rect[1], rect[2], rect[3], image.COLOR_BLUE, 2)
# 在图像上绘制一个字符串,显示条形码的内容
img.draw_string(0, 0, "payload: " + b.payload(), image.COLOR_GREEN)
# 在显示器上显示图像
disp.show(img)
barcodes = img.find_barcodes():识别条形码
5.5 —image_basic—find_blobs.py(识别色块)
from maix import camera, display, image # 导入maix模块中的camera,display和image类。
cam = camera.Camera(320, 240) # 创建一个Camera对象,分辨率为320x240。
disp = display.Display() # 创建一个Display对象,用于在屏幕上显示图像。
area_threshold = 1000 # 设置颜色块的最小面积阈值。
pixels_threshold = 1000 # 设置颜色块的最小像素数阈值。
thresholds = [[0, 80, -120, -10, 0, 30]] # 设置颜色阈值,用于在图像中查找特定颜色的区域。这里的阈值是为了查找绿色的区域。
while 1: # 无限循环,不断地从摄像头读取图像。
img = cam.read() # 从摄像头读取图像。
blobs = img.find_blobs(thresholds, area_threshold = 1000, pixels_threshold = 1000) # 在图像中查找满足颜色和大小阈值的区域,并返回一个包含这些区域信息的列表。
for b in blobs: # 遍历每个找到的颜色块。
corners = b.corners() # 获取颜色块的角点。
for i in range(4): # 遍历每个角点。
img.draw_line(corners[i][0], corners[i][1], corners[(i + 1) % 4][0], corners[(i + 1) % 4][1], image.COLOR_RED) # 用红线连接角点,在图像上高亮显示颜色块。
disp.show(img) # 将处理后的图像显示在屏幕上。
5.6 —image_basic—find_edges.py(图像处理常见预处理——Canny边缘检测)
from maix import camera, display # 导入maix模块中的camera和display类。
from maix.image import EdgeDetector # 导入maix.image模块中的EdgeDetector类。
cam = camera.Camera(320, 240) # 创建一个Camera对象,分辨率为320x240。
disp = display.Display() # 创建一个Display对象,用于在屏幕上显示图像。
edge_type = EdgeDetector.EDGE_CANNY # 设置边缘检测的类型为Canny边缘检测。
while 1: # 无限循环,不断地从摄像头读取图像。
img = cam.read() # 从摄像头读取图像。
img.find_edges(edge_type, threshold=[50, 100]) # 在图像中查找边缘,使用Canny边缘检测,阈值设置为[50, 100]。
disp.show(img) # 将处理后的图像显示在屏幕上。
# 设置边缘检测的类型为Canny边缘检测。
edge_type = EdgeDetector.EDGE_CANNY
# 在图像中查找边缘,使用Canny边缘检测,阈值设置为[50, 100]。
img.find_edges(edge_type, threshold=[50, 100])
5.7 —image_basic—find_lines.py(图像处理常见预处理——线条检测)
from maix import camera, display, image # 导入maix模块中的camera,display和image类。
import math # 导入math模块,用于进行数学运算。
cam = camera.Camera(320, 240) # 创建一个Camera对象,分辨率为320x240。
disp = display.Display() # 创建一个Display对象,用于在屏幕上显示图像。
threshold = 2000 # 设置线条检测的阈值。
while 1: # 无限循环,不断地从摄像头读取图像。
img = cam.read() # 从摄像头读取图像。
lines = img.find_lines(threshold=2000) # 在图像中查找线条,阈值设置为2000。
for a in lines: # 遍历每个找到的线条。
img.draw_line(a.x1(), a.y1(), a.x2(), a.y2(), image.COLOR_RED, 2) # 在图像上画出线条,线条的颜色设置为红色,线宽设置为2。
theta = a.theta() # 获取线条的角度。
rho = a.rho() # 获取线条的长度。
angle_in_radians = math.radians(theta) # 将角度转换为弧度。
x = int(math.cos(angle_in_radians) * rho) # 计算x坐标。
y = int(math.sin(angle_in_radians) * rho) # 计算y坐标。
img.draw_line(0, 0, x, y, image.COLOR_GREEN, 2) # 在图像上画出从原点到(x, y)的线条,线条的颜色设置为绿色,线宽设置为2。
img.draw_string(x, y, "theta: " + str(theta) + "," + "rho: " + str(rho), image.COLOR_GREEN) # 在图像上的(x, y)位置显示线条的角度和长度,文本的颜色设置为绿色。
disp.show(img) # 将处理后的图像显示在屏幕上。
# 在图像中查找线条,阈值设置为2000。
lines = img.find_lines(threshold=2000)
检测更细微的线条——降低阈值;只关心更明显的线条——提高阈值
红线的起点和终点就是检测到的线条的两个端点;绿线则是用来表示线条的极坐标表示的,
在极坐标系中,一个点可以通过一个长度(rho)和一个角度(theta)来表示。
5.8 —image_basic—find_qrcodes.py(识别二维码)
from maix import camera, display, image # 导入maix模块中的camera,display和image类。
cam = camera.Camera(320, 240) # 创建一个Camera对象,分辨率为320x240。
disp = display.Display() # 创建一个Display对象,用于在屏幕上显示图像。
while 1: # 无限循环,不断地从摄像头读取图像。
img = cam.read() # 从摄像头读取图像。
qrcodes = img.find_qrcodes() # 在图像中查找二维码,并返回一个包含这些二维码的列表。
for q in qrcodes: # 遍历每个找到的二维码。
corners = q.corners() # 获取二维码的角点。
for i in range(4): # 遍历每个角点。
img.draw_line(corners[i][0], corners[i][1], corners[(i + 1) % 4][0], corners[(i + 1) % 4][1], image.COLOR_RED) # 用红线连接角点,在图像上高亮显示二维码。
img.draw_string(0, 0, "payload: " + q.payload(), image.COLOR_BLUE) # 在图像上的(0, 0)位置显示二维码的内容(payload),文本的颜色设置为蓝色。
disp.show(img) # 将处理后的图像显示在屏幕上。
qrcodes = img.find_qrcodes() # 在图像中查找二维码,并返回一个包含这些二维码的列表。
5.9 —image_basic—image_load_font.py(屏幕显示字符,可设置字体和大小)
from maix import image, display, app, time # 导入maix模块中的image,display,app和time类。
image.load_font("sourcehansans", "/maixapp/share/font/SourceHanSansCN-Regular.otf", size = 32) # 加载名为"sourcehansans"的字体,字体文件位于"/maixapp/share/font/SourceHanSansCN-Regular.otf",字体大小为32。
print("fonts:", image.fonts()) # 打印当前加载的所有字体。
image.set_default_font("sourcehansans") # 将默认字体设置为"sourcehansans"。
disp = display.Display() # 创建一个Display对象,用于在屏幕上显示图像。
img = image.Image(disp.width(), disp.height()) # 创建一个Image对象,大小为屏幕的宽度和高度。
img.draw_string(2, 2, "你好!Hello, world!", image.Color.from_rgb(255, 0, 0)) # 在图像上的(2, 2)位置绘制一段文本,文本的颜色设置为红色。
disp.show(img) # 将处理后的图像显示在屏幕上。
while not app.need_exit(): # 无限循环,直到应用需要退出。
time.sleep(1) # 每次循环后暂停1秒。
5.10 —image_basic—image_load.py(屏幕显示图片)
from maix import display, image, app, time # 导入maix模块中的display,image,app和time类。
file_path = "/maixapp/share/icon/detector.png" # 图片文件的路径。
# 加载图片文件。如果文件路径以".png"结尾,则格式设置为RGBA8888,否则设置为RGB888。
img = image.load(file_path, format = image.Format.FMT_RGBA8888 if file_path.endswith(".png") else image.Format.FMT_RGB888)
if img is None: # 如果加载图片失败,则抛出异常。
raise Exception(f"load image {file_path} failed")
disp = display.Display() # 创建一个Display对象,用于在屏幕上显示图像。
disp.show(img, fit = image.Fit.FIT_CONTAIN) # 将图片显示在屏幕上,图片的大小会被调整以适应屏幕的大小。
while not app.need_exit(): # 无限循环,直到应用需要退出。
time.sleep_ms(100) # 每次循环后暂停100毫秒。
5.11 —image_basic—image_ops.py(用于创建、调整和保存图像)
from maix import image # 导入maix模块中的image类。
img = image.Image(640, 480) # 创建一个Image对象,大小为640x480。
img = img.resize(320, 240) # 将图像的大小调整为320x240。
img.save("test.jpg") # 将图像保存为名为"test.jpg"的文件。
jpg = img.to_jpeg(quality = 95) # 将图像转换为JPEG格式,质量设置为95。
print(jpg.data_size()) # 打印JPEG图像的数据大小。
用于创建、调整和保存图像。
5.12 —image_basic—line_tracking.py(屏幕显示图片)
from maix import camera, display, image # 导入maix模块中的camera,display和image类。
cam = camera.Camera(320, 240) # 创建一个Camera对象,分辨率为320x240。
disp = display.Display() # 创建一个Display对象,用于在屏幕上显示图像。
# thresholds = [[0, 80, 40, 80, 10, 80]] # 红色阈值
thresholds = [[0, 80, -120, -10, 0, 30]] # 绿色阈值
# thresholds = [[0, 80, 30, 100, -120, -60]] # 蓝色阈值
while 1: # 无限循环,不断地从摄像头读取图像。
img = cam.read() # 从摄像头读取图像。
lines = img.get_regression(thresholds, area_threshold = 100) # 在图像中查找满足颜色阈值和面积阈值的线条回归。
for a in lines: # 遍历每个找到的线条回归。
img.draw_line(a.x1(), a.y1(), a.x2(), a.y2(), image.COLOR_GREEN, 2) # 在图像上画出线条,线条的颜色设置为绿色,线宽设置为2。
theta = a.theta() # 获取线条的角度。
rho = a.rho() # 获取线条的长度。
if theta > 90: # 如果角度大于90度。
theta = 270 - theta # 计算新的角度。
else: # 如果角度小于等于90度。
theta = 90 - theta # 计算新的角度。
img.draw_string(0, 0, "theta: " + str(theta) + ", rho: " + str(rho), image.COLOR_BLUE) # 在图像上的(0, 0)位置显示线条的角度和长度,文本的颜色设置为蓝色。
disp.show(img) # 将处理后的图像显示在屏幕上。
get_regression()使用颜色阈值和面积阈值来查找特定颜色的线条,并提供线条的角度和长度等信息。find_lines()使用边缘检测技术来查找所有的线条,而不考虑颜色,只提供线条的起点和终点坐标。
6.1 —opencv—opencv_camera.py(边缘检测)
from maix import image, display, app, time, camera # 导入maix模块中的image,display,app,time和camera类。
import cv2 # 导入OpenCV库。
disp = display.Display() # 创建一个Display对象,用于在屏幕上显示图像。
cam = camera.Camera(320, 240) # 创建一个Camera对象,分辨率为320x240。
while not app.need_exit(): # 无限循环,直到应用需要退出。
img = cam.read() # 从摄像头读取图像。
t = time.ticks_ms() # 获取当前时间(毫秒)。
img = image.image2cv(img) # 将maix.image.Image对象转换为numpy.ndarray对象。
print("time: ", time.ticks_ms() - t) # 打印转换所花费的时间。
edged = cv2.Canny(img, 180, 60) # 使用Canny方法检测图像中的边缘。
img_show = image.cv2image(edged) # 将numpy.ndarray对象转换为maix.image.Image对象。
disp.show(img_show) # 将处理后的图像显示在屏幕上。
6.2 —opencv—opencv_show.py(边缘检测)

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 21
21 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)