基础的视觉神经网络
笔记:
参考:
1.这篇文章的第四阶段
【计算机视觉知识库】CV学习路线/从头学系列【持续更新】_计算机cv怎么学-CSDN博客
2.介绍了一些基本的图像分类神经网络模型
1.损失函数
2.梯度下降法
常见图像分类网络的学习
参考文章:
【OpenMMLab实践】02MMClassification理论(传统视觉思路以及CNN分类网络的模型修改策略总结-上)_cnn回归和分类修改-CSDN博客
视频:
25-1讲解-fastRCNN的损失函数_哔哩哔哩_bilibili
一、图像分类
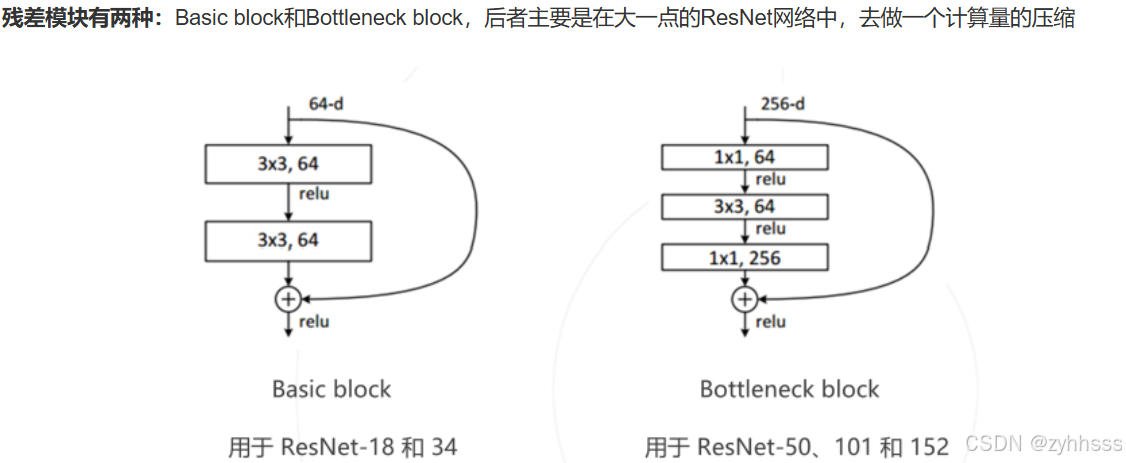
1.ResNet与ResNeXt
分组卷积
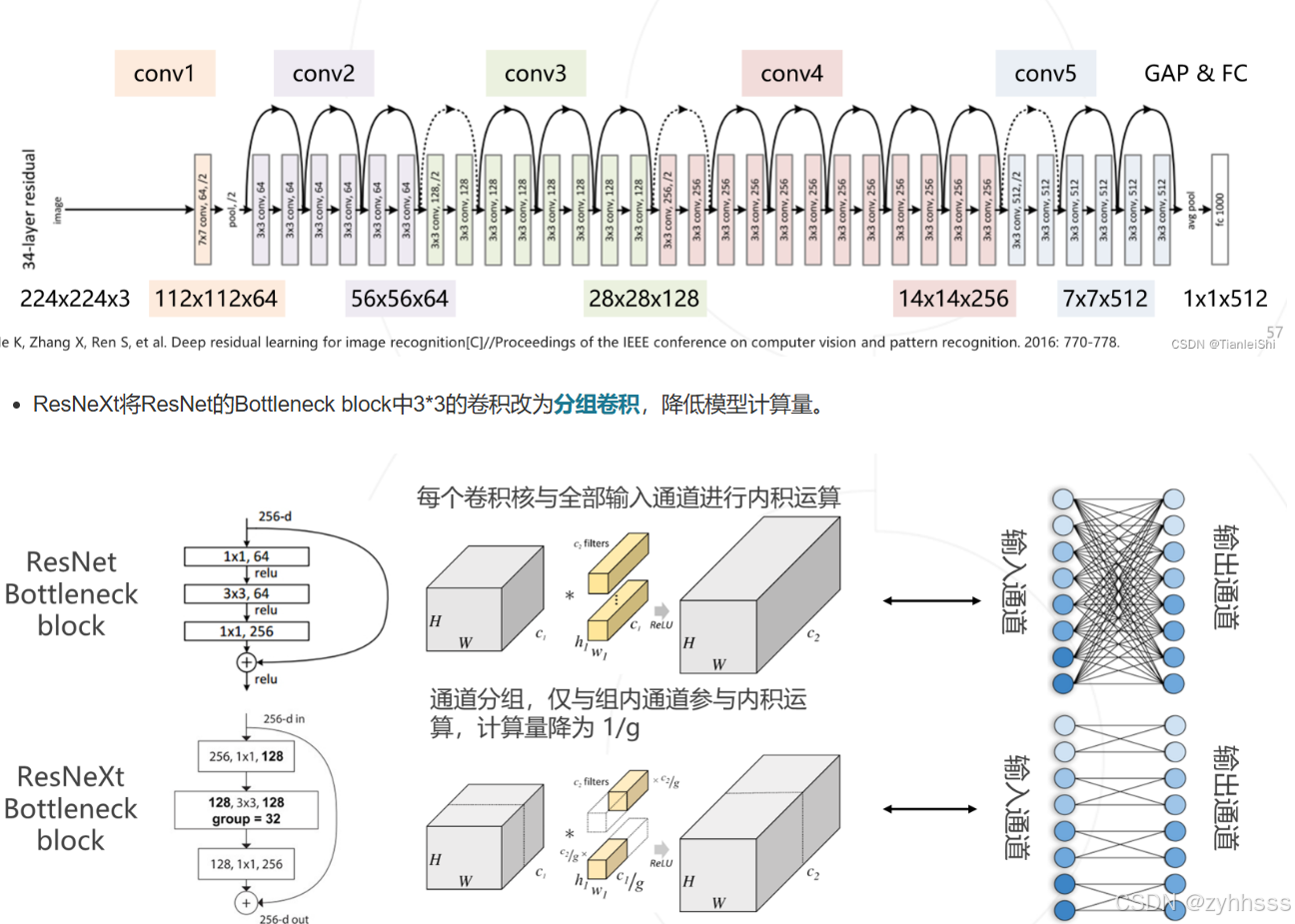
在标准的卷积层中,一个滤波器会与输入特征图的所有通道进行卷积。而在分组卷积中,输入特征图被分成几个组,每个组使用不同的滤波器进行卷积。最后,这些组的输出会被拼接在一起形成最终的输出特征图。
例如,假设你有一个128通道的输入特征图,并且你想使用32个滤波器来进行3x3的卷积。如果你设置分组数为4,那么:
- 输入特征图会被分成4个组,每组32个通道。
- 你会有4组滤波器,每组8个滤波器(总共32个滤波器)。
- 每个滤波器组只与其对应的输入特征图组进行卷积。
- 最后,这4组输出特征图会被拼接在一起,形成最终的32通道输出特征图。
ResNeXt中的Bottleneck Block
在ResNet中,Bottleneck Block通常包含以下几层:
- 1x1卷积(降维)
- 3x3卷积
- 1x1卷积(升维)
在ResNeXt中,中间的3x3卷积层被替换为一组分组卷积。具体来说,ResNeXt的Bottleneck Block可以描述如下:
- 1x1卷积(降维),减少特征图的通道数。
- 多个并行的3x3分组卷积,每个组独立处理一部分通道。
- 1x1卷积(升维),恢复特征图的通道数。
降低计算量
通过使用分组卷积,ResNeXt能够在以下几个方面降低计算量:
-
减少参数数量:由于每个组内的卷积核只与该组的输入通道进行卷积,所以总的参数数量减少了。例如,如果分组数为G,那么参数数量大约会减少到原来的1/G。
-
减少计算量:每个组内的卷积操作是独立的,因此总的计算量也会相应减少。这对于大规模网络尤其重要,因为它可以显著加快训练和推理的速度。
-
增加多样性:分组卷积使得网络能够学习更多样化的特征表示,因为每个组可以专注于不同的特征子集。这有助于提高模型的泛化能力。
示例
假设我们有一个Bottleneck Block,输入特征图的通道数为256,输出通道数也为256。在标准的ResNet中,这个Block可能包含以下层:
- 1x1卷积,输出64个通道
- 3x3卷积,输出64个通道
- 1x1卷积,输出256个通道
在ResNeXt中,我们可以将3x3卷积改为分组卷积,比如设置分组数为32。那么这个Block可能变成:
- 1x1卷积,输出128个通道
- 32个并行的3x3卷积,每个卷积处理4个通道(128/32=4),输出4个通道
- 1x1卷积,输出256个通道
这样,虽然总的输出通道数不变,但中间层的计算量和参数数量都大大减少了。
通过这种方式,ResNeXt能够在保持或提高模型性能的同时,显著降低计算成本。
2.SENet
SENet(Squeeze-and-Excitation Networks)是一种引入了注意力机制的卷积神经网络架构,它通过自适应地重新校准特征图的通道权重来提高模型的性能。SENet在2017年的ImageNet图像识别挑战赛中获得了第一名,并且在多个视觉任务中表现出色。
Squeeze-and-Excitation (SE) Block
SENet的核心是Squeeze-and-Excitation (SE) Block,它可以插入到现有的网络架构中的任意位置,通常是在残差块或Inception块之后。SE Block包含两个主要步骤:Squeeze(压缩)和Excitation(激励)。
1. Squeeze(压缩)
- 全局信息嵌入:SE Block首先对输入特征图进行全局平均池化(Global Average Pooling, GAP),将每个通道的空间维度压缩为一个单一的值。这样,每个通道就变成了一个代表整个特征图全局分布的描述符。
- 输出形状:假设输入特征图的形状是 (C, H, W),其中 C 是通道数,H 和 W 分别是高度和宽度。经过全局平均池化后,输出的形状变为 (C, 1, 1)。
2. Excitation(激励)
- 全连接层:接下来,SE Block使用两个全连接层(FC Layers)来学习不同通道之间的相互依赖关系。第一个全连接层通常会减少通道数,而第二个全连接层则恢复到原始的通道数。
- 激活函数:在两个全连接层之间,通常会使用ReLU激活函数。而在最后一个全连接层之后,会使用Sigmoid激活函数来生成每个通道的权重。
- 通道重标定:最后,这些权重被用于重新校准输入特征图的通道。具体来说,就是将这些权重与输入特征图的每个通道相乘,从而增强重要的通道并抑制不重要的通道。
SE Block的工作流程
- 输入特征图:假设输入特征图的形状是 (C, H, W)。
- 全局平均池化:对输入特征图进行全局平均池化,得到形状为 (C, 1, 1) 的向量。
- 降维全连接层:通过一个全连接层(通常是缩小比例的,例如缩小4倍),将 (C, 1, 1) 的向量映射到 (C/r, 1, 1),其中 r 是缩小的比例。
- ReLU激活:应用ReLU激活函数。
- 升维全连接层:通过另一个全连接层,将 (C/r, 1, 1) 的向量映射回 (C, 1, 1)。
- Sigmoid激活:应用Sigmoid激活函数,得到范围在 [0, 1] 之间的权重。
- 通道重标定:将这些权重与输入特征图的每个通道相乘,得到新的特征图。
注意力机制的效果
- 动态调整通道重要性:SE Block能够根据输入特征图的内容动态地调整每个通道的重要性,使得网络能够更加关注有用的特征,忽略无用的特征。
- 参数效率:尽管增加了额外的计算开销,但SE Block的参数数量相对较少,因为它只作用于通道维度。
- 性能提升:通过引入这种注意力机制,SENet能够在多种视觉任务中显著提高模型的性能,尤其是在分类任务中。
示例
假设你有一个ResNet的Bottleneck Block,你可以在这个Block后面添加一个SE Block:
import torch
import torch.nn as nn
import torch.nn.functional as F
class SEBlock(nn.Module):
def __init__(self, channel, reduction=16):
super(SEBlock, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.fc = nn.Sequential(
nn.Linear(channel, channel // reduction, bias=False),
nn.ReLU(inplace=True),
nn.Linear(channel // reduction, channel, bias=False),
nn.Sigmoid()
)
def forward(self, x):
b, c, _, _ = x.size()
y = self.avg_pool(x).view(b, c)
y = self.fc(y).view(b, c, 1, 1)
return x * y.expand_as(x)
# 假设你有一个ResNet的Bottleneck Block
class BottleneckBlock(nn.Module):
def __init__(self, in_channels, out_channels, reduction=16):
super(BottleneckBlock, self).__init__()
self.conv1 = nn.Conv2d(in_channels, out_channels, kernel_size=1)
self.bn1 = nn.BatchNorm2d(out_channels)
self.conv2 = nn.Conv2d(out_channels, out_channels, kernel_size=3, padding=1)
self.bn2 = nn.BatchNorm2d(out_channels)
self.conv3 = nn.Conv2d(out_channels, out_channels, kernel_size=1)
self.bn3 = nn.BatchNorm2d(out_channels)
self.se = SEBlock(out_channels, reduction)
self.relu = nn.ReLU(inplace=True)
def forward(self, x):
residual = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.bn3(out)
out = self.se(out) # 应用SE Block
out += residual
out = self.relu(out)
return outview方法:
import torch
import torch.nn as nn
# 创建一个形状为 (32, 3, 224, 224) 的张量
x = torch.randn(32, 3, 224, 224)
# 定义全局平均池化层
avg_pool = nn.AdaptiveAvgPool2d((1, 1))
# 获取 x 的尺寸
b, c, _, _ = x.size()
# 进行全局平均池化
pooled = avg_pool(x)
# 使用 view 改变形状
y = pooled.view(b, c)
print(f"Original shape: {x.shape}") # 输出: Original shape: torch.Size([32, 3, 224, 224])
print(f"Pooled shape: {pooled.shape}") # 输出: Pooled shape: torch.Size([32, 3, 1, 1])
print(f"Viewed shape: {y.shape}") # 输出: Viewed shape: torch.Size([32, 3])3.MobileNet
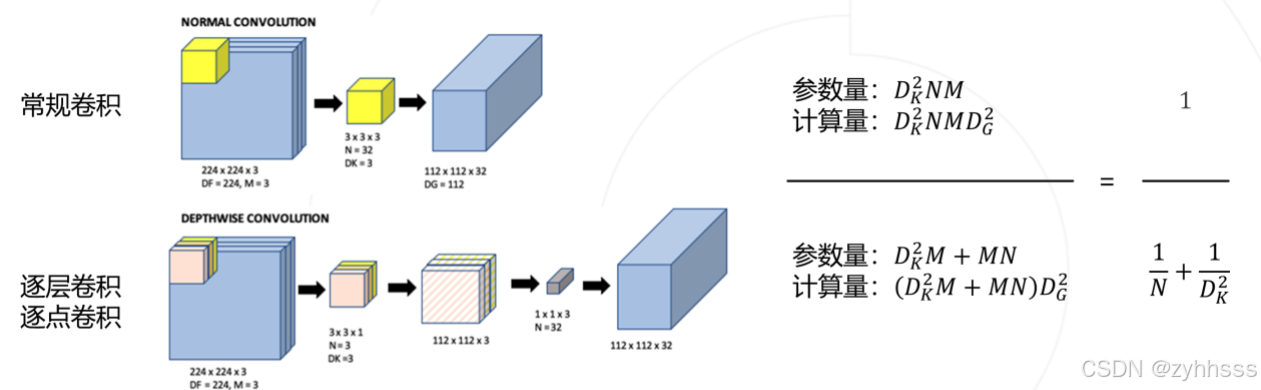
逐层卷积(Depthwise Convolution)是轻量级神经网络架构中常用的一种操作,它在每个输入通道上独立地应用一个单独的滤波器。这样做的好处是可以大大减少参数数量和计算量。下面是一个简单的逐层卷积的例子:
假设我们有一个大小为 16x16x3 的输入特征图,即宽度16像素、高度16像素、3个颜色通道。如果我们使用一组3x3的逐层卷积核,那么对于每个输入通道,我们会用一个3x3的卷积核进行卷积操作。因此,我们需要3个这样的卷积核来处理3个输入通道。
经过逐层卷积后,如果步幅为1且没有填充,输出特征图的尺寸将是 14x14x3(因为每个卷积核会减少2像素的边缘)。这里的关键点是,逐层卷积并没有改变特征图的通道数,只是对每个通道进行了独立的卷积。
接下来,通常还会接一个逐点卷积(Pointwise Convolution),这是一种1x1的卷积,它的目的是跨通道线性组合信息并增加或减少通道数。比如,我们可以使用一个1x1x32的卷积核将上述的 14x14x3 输出转换为 14x14x32。
逐层卷积+逐点卷积:
import torch
import torch.nn as nn
import torch.nn.functional as F
# 定义一个简单的网络类
class SimpleConvNet(nn.Module):
def __init__(self):
super(SimpleConvNet, self).__init__()
# 逐层卷积 (Depthwise Convolution)
# groups 参数设置为输入通道数,以实现逐层卷积
self.depthwise_conv = nn.Conv2d(in_channels=3, out_channels=3, kernel_size=3, stride=1, padding=0, groups=3)
# 逐点卷积 (Pointwise Convolution)
# 使用1x1的卷积核改变通道数
self.pointwise_conv = nn.Conv2d(in_channels=3, out_channels=32, kernel_size=1, stride=1, padding=0)
def forward(self, x):
# 通过逐层卷积
x = F.relu(self.depthwise_conv(x))
# 通过逐点卷积
x = F.relu(self.pointwise_conv(x))
return x
# 创建模型实例
model = SimpleConvNet()
# 打印模型结构
print(model)
# 假设有一个大小为 (batch_size, 3, 16, 16) 的输入张量
input_tensor = torch.randn(1, 3, 16, 16)
# 将输入传递给模型
output = model(input_tensor)
# 输出形状应该为 (batch_size, 32, 14, 14),因为步幅为1且没有填充
print(output.shape)通过卷积改变通道:
import torch
import torch.nn as nn
import torch.nn.functional as F
# 定义输入特征图
input_tensor = torch.randn(1, 3, 224, 224) # 形状为 (batch_size, channels, height, width)
# 定义卷积层
conv_layer = nn.Conv2d(in_channels=3, out_channels=32, kernel_size=3, stride=1, padding=1)
# 应用卷积层
output_tensor = conv_layer(input_tensor)
# 打印输入和输出的形状
print(f"Input shape: {input_tensor.shape}") # 输出: Input shape: torch.Size([1, 3, 224, 224])
print(f"Output shape: {output_tensor.shape}") # 输出: Output shape: torch.Size([1, 32, 224, 224])
4.ShuffleNet
二、目标检测
参考:
【深度学习进阶】01目标检测理论:R-CNN、Fast R-CNN、Faster R-CNN系列以及FPN结构_fast rcnn 绿豆-CSDN博客
目标检测任务简介
目标检测任务主要有两个问题需要解决:识别目标类别(分类),确定目标位置(回归)。分类问题很好理解,就是确定检测到的目标属于哪一类。回归问题是为了确定目标的位置,因为我们需要一个矩形框来框住所检测到的目标,这就需要调整矩形框的中心坐标以及宽和高到最优的位置,坐标点以及宽和高的变化是连续的,因此是回归问题。基于深度学习的目标检测算法主要分为两类Two Stage 和 One Stage。本文主要介绍Two、Stage算法
Two Stage算法有:R-CNN、Fast R-CNN、Faster R-CNN、SPPNet
One Stage算法有:YOLO系列、SSD、RetinaNet、SqueezeDet、DetectNet、OverFeat
1.R-CNN
算法流程
- 算法流程
- 使用SS算法,将一张图像生成1k到2k个候选区域(proposal)
- 对每个候选区域,使用深度网络(Backnone:AlexNet)提取特征
- 将特征送入每一类的SVM分类器,判别是否属于该类
- 使用回归器精细修正候选框位置
SS算法
选择性搜索算法的具体操作
-
初始化:
- 使用一种快速的分割方法(如Felzenszwalb和Huttenlocher提出的基于图的方法)对图像进行初始分割,得到一系列小区域。
-
计算相似度:
- 对于每一对相邻区域,根据颜色、纹理、大小和形状等特征计算相似度。
-
排序并合并:
- 将所有相邻区域对按照相似度降序排列。
- 从最相似的区域对开始,逐步合并它们,并更新相似度列表。
- 每次合并后,重新计算与新合并区域相邻的其他区域之间的相似度。
-
多样化策略:
- 在合并过程中采用多种策略(如不同的颜色空间、不同尺度的分割)以确保生成多样化的候选区域。
-
输出结果:
- 最终得到一组可能包含物体的候选区域。
import cv2
import numpy as np
def selective_search(image, strategy='fast'):
# 创建选择性搜索对象
ss = cv2.ximgproc.segmentation.createSelectiveSearchSegmentation()
# 设置基础图像
ss.setBaseImage(image)
if strategy == 'fast':
# 使用快速模式
ss.switchToSelectiveSearchFast()
elif strategy == 'quality':
# 使用高质量模式
ss.switchToSelectiveSearchQuality()
else:
raise ValueError("Strategy must be either 'fast' or 'quality'")
# 运行选择性搜索算法
rects = ss.process()
return rects
# 加载图像
image_path = r'D:\python_ws\code\pytorch-3.8.0\opencv_learn\data\card1.png'
image = cv2.imread(image_path)
# 获取选择性搜索区域
rects = selective_search(image, strategy='fast')
# 绘制矩形框
for (x, y, w, h) in rects[:200]: # 只绘制前200个提议区域
cv2.rectangle(image, (x, y), (x + w, y + h), (0, 255, 0), 2, cv2.LINE_AA)
# 显示图像
cv2.imshow("Output", image)
cv2.waitKey(0)
cv2.destroyAllWindows()
1. 特征提取
- 输入:选择性搜索生成的每个候选区域。
- 处理:将每个候选区域缩放到固定的尺寸(例如227x227像素),以适应预训练的CNN模型(如AlexNet)的输入要求。
- 输出:每个候选区域通过CNN提取得到的固定长度的特征向量(例如4096维)。
注:简单的cnn为每一个区域生成一个特征向量。
SVM 基本概念
-
超平面:
- 在二维空间中,超平面是一条直线;在三维空间中,超平面是一个平面;在更高维度的空间中,超平面是一个高维的平面。
- 超平面可以表示为 w⋅x+b=0w⋅x+b=0,其中 ww 是权重向量,xx 是输入向量,bb 是偏置项。
-
支持向量:
- 支持向量是最接近决策边界的样本点。它们决定了超平面的位置,因为只有这些点对决策边界有直接影响。
-
间隔(Margin):
- 间隔是指最近的支持向量到超平面的距离。SVM 试图最大化这个间隔,以提高模型的泛化能力。
-
软间隔(Soft Margin):
- 在实际应用中,数据往往不是完全线性可分的。软间隔允许一些数据点位于错误的一侧,但会引入惩罚项来控制这种偏差的程度。
-
核函数(Kernel Function):
- 对于非线性可分的数据,可以通过核函数将数据映射到高维空间,在高维空间中寻找一个线性可分的超平面。
- 常见的核函数包括线性核、多项式核、RBF(径向基函数)核等。

代码:
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.svm import SVC
from sklearn.metrics import accuracy_score
# 加载数据集
iris = datasets.load_iris()
X = iris.data
y = iris.target
# 将数据集分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 数据预处理
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)
# 创建 SVM 分类器
svm_classifier = SVC(kernel='linear', C=1.0, random_state=42)
# 训练 SVM 分类器
svm_classifier.fit(X_train, y_train)
# 预测
y_pred = svm_classifier.predict(X_test)
# 评估准确率
accuracy = accuracy_score(y_test, y_pred)
print(f"Accuracy: {accuracy:.2f}")2. SVM分类
-
训练阶段:
- 准备数据:收集大量带标注的数据集,每个图像包含多个物体和相应的类别标签。
- 特征提取:对每个候选区域使用预训练的CNN提取特征。
- 训练SVM:为每个类别训练一个二元SVM分类器。具体来说,对于每个类别,将所有正样本(属于该类别的候选区域)和负样本(不属于该类别的候选区域)的特征向量作为训练数据。通常会使用硬负挖掘(Hard Negative Mining)来提高分类器的性能。
-
测试阶段:
- 输入:从选择性搜索生成的候选区域中提取的特征向量。
- 分类:将每个特征向量送入每个类别的SVM分类器,计算其属于该类别的概率或置信度。
- 结果:如果某个候选区域在某一类别的SVM分类器中的得分高于设定的阈值,则认为该候选区域属于该类别。
import numpy as np
from sklearn.svm import SVC
from sklearn.externals import joblib # 用于加载保存的SVM模型
# 假设你已经有了提取的特征向量
features = np.load('path_to_extracted_features.npy')
# 加载训练好的SVM分类器
svm_classifiers = {}
for class_name in ['cat', 'dog', 'car']: # 假设有三个类别
svm_classifiers[class_name] = joblib.load(f'svm_{class_name}.pkl')
# 对每个候选区域进行分类
def classify_regions(features, svm_classifiers):
results = []
for feature in features:
region_results = {}
for class_name, svm in svm_classifiers.items():
score = svm.decision_function([feature])[0]
if score > 0: # 假设正类的阈值为0
region_results[class_name] = score
results.append(region_results)
return results
# 分类
classification_results = classify_regions(features, svm_classifiers)
# 打印结果
for i, result in enumerate(classification_results):
print(f"Region {i}: {result}")非极大值抑制(NMS)
应用NMS
假设我们的IoU阈值设定为0.5,即如果两个建议框的IoU大于或等于0.5,则认为它们重叠过多。
- 按照得分排序:A(0.9), B(0.85), C(0.7)
- 选择得分最高的A。
- 检查A与剩下的所有建议框的IoU:
- A与B的IoU < 0.5,保留B。
- A与C的IoU = 0,保留C。
- 由于没有其他建议框被A抑制,接下来检查B。
- 选择B。
- 检查B与剩下的C的IoU:
- B与C的IoU = 0,保留C。
- 最后选择C。
在这个简化例子中,所有的建议框都被保留了,因为它们之间的IoU都小于设定的阈值0.5。在实际情况中,如果有建议框的IoU超过阈值,那么得分较低的那个就会被剔除。例如,如果A与B的IoU超过了0.5,那么B就会被剔除,因为它得分低于A。
3. 回归器精细修正候选框位置
-
训练阶段:
- 准备数据:同样需要大量的带标注数据集,每个图像包含多个物体及其精确的位置信息(边界框)。
- 特征提取:与分类相同,使用预训练的CNN提取每个候选区域的特征。
- 训练回归器:训练一个线性回归模型,输入是候选区域的特征向量,输出是预测的边界框坐标偏移量(相对于原始候选区域)。
-
测试阶段:
- 输入:已经分类后的候选区域及其特征向量。
- 修正位置:将特征向量送入训练好的回归器,得到预测的边界框坐标偏移量。
- 调整边界框:根据预测的偏移量调整候选区域的边界框,使其更紧密地贴合实际物体的位置。
import numpy as np
# 假设的NMS后边界框数据
# 每个类别的边界框列表 [x_min, y_min, x_max, y_max, score]
nms_boxes = {
0: np.array([[10, 10, 20, 20, 0.9], [15, 15, 25, 25, 0.85], [30, 30, 40, 40, 0.7]]),
1: np.array([[50, 50, 60, 60, 0.95], [55, 55, 65, 65, 0.9], [70, 70, 80, 80, 0.8]]),
2: np.array([[90, 90, 100, 100, 0.85], [95, 95, 105, 105, 0.8], [110, 110, 120, 120, 0.75]]),
3: np.array([[130, 130, 140, 140, 0.75], [135, 135, 145, 145, 0.7], [150, 150, 160, 160, 0.65]]),
4: np.array([[170, 170, 180, 180, 0.6], [175, 175, 185, 185, 0.55], [190, 190, 200, 200, 0.5]])
}
# 假设我们有预训练好的回归器,这里用随机函数代替实际的回归模型
def regressor(class_id, box_features):
# 这里应该加载对应的回归器并预测调整量
# 为了简化,我们随机生成一些调整量
adjustments = np.random.rand(3) * 2 - 1 # [-1, 1]范围内的随机数
return adjustments
# 定义一个函数来应用回归器并调整边界框
def adjust_bounding_boxes(nms_boxes):
adjusted_boxes = {}
for class_id, boxes in nms_boxes.items():
adjusted_class_boxes = []
for box in boxes:
# 提取特征,这里简化为直接使用box坐标
box_features = box[:4]
# 使用对应类别的回归器得到调整量
adjustment = regressor(class_id, box_features)
# 调整边界框的位置
adjusted_box = box.copy()
adjusted_box[:4] += adjustment
adjusted_class_boxes.append(adjusted_box)
adjusted_boxes[class_id] = np.array(adjusted_class_boxes)
return adjusted_boxes
# 应用回归器调整边界框
adjusted_boxes = adjust_bounding_boxes(nms_boxes)
# 打印结果
for class_id, boxes in adjusted_boxes.items():
print(f"Class {class_id} Adjusted Boxes:")
print(boxes)import torch
import torch.nn as nn
import torch.optim as optim
import numpy as np
# 定义一个简单的全连接神经网络回归器
class BoundingBoxRegressor(nn.Module):
def __init__(self):
super(BoundingBoxRegressor, self).__init__()
# 输入是4个特征 (x_min, y_min, x_max, y_max)
# 输出是3个调整值 (dx, dy, dw/dh),分别对应中心点坐标偏移和宽高比的变化
self.fc1 = nn.Linear(4, 8) # 第一层有8个神经元
self.fc2 = nn.Linear(8, 3) # 输出层有3个神经元
def forward(self, x):
x = torch.relu(self.fc1(x))
x = self.fc2(x)
return x
# 假设我们已经训练好了模型并保存了权重
# 这里我们用随机初始化的权重来代替实际的预训练权重
regressors = [BoundingBoxRegressor() for _ in range(5)] # 为每个类别创建一个回归器
for regressor in regressors:
regressor.eval() # 设置模型为评估模式
# 定义一个函数来应用回归器并调整边界框
def adjust_bounding_boxes(nms_boxes, regressors):
adjusted_boxes = {}
for class_id, boxes in nms_boxes.items():
adjusted_class_boxes = []
for box in boxes:
# 提取特征,这里是边界框的坐标
box_features = torch.tensor(box[:4], dtype=torch.float32).unsqueeze(0)
# 使用对应类别的回归器得到调整量
with torch.no_grad(): # 不需要计算梯度
adjustment = regressors[class_id](box_features)
# 调整边界框的位置
# 假设adjustment包含(dx, dy, log(dw/dh)),其中log(dw/dh)用于调整宽度和高度
dx, dy, log_dwh = adjustment[0].numpy()
# 计算新的边界框
w = box[2] - box[0]
h = box[3] - box[1]
new_w = w * np.exp(log_dwh)
new_h = h * np.exp(log_dwh)
new_x_min = box[0] + dx
new_y_min = box[1] + dy
new_x_max = new_x_min + new_w
new_y_max = new_y_min + new_h
adjusted_box = np.array([new_x_min, new_y_min, new_x_max, new_y_max, box[4]])
adjusted_class_boxes.append(adjusted_box)
adjusted_boxes[class_id] = np.array(adjusted_class_boxes)
return adjusted_boxes
# 应用回归器调整边界框
adjusted_boxes = adjust_bounding_boxes(nms_boxes, regressors)
# 打印结果
for class_id, boxes in adjusted_boxes.items():
print(f"Class {class_id} Adjusted Boxes:")
print(boxes)回归器类似于把那个框移动到最中心,通过神经网络训练5个网络。
2.Fast R-CNN(2015)
Fast R-CNN(2015) 算法流程
- 候选区域生成:同样使用选择性搜索或其他区域建议算法生成候选区域。
- 整图特征提取:与R-CNN不同,Fast R-CNN只需要将整张图像输入到一个共享的CNN中,得到一个全局的特征图。
- 区域池化(RoI Pooling):将候选区域投影到这个全局特征图上,并使用RoI Pooling层将每个候选区域对应的特征图部分转换成固定大小的特征向量(通常是7x7)。这样就避免了多次运行CNN。
- 分类与回归:这些固定大小的特征向量被送入两个并行的全连接层,一个用于分类(通常使用softmax而不是SVM),另一个用于边界框回归。
存在的问题
- 仍然依赖于外部的区域建议算法:Fast R-CNN依然需要依赖如选择性搜索这样的外部算法来生成候选区域,这增加了整体系统的复杂性和运行时间。
- RoI Pooling层的量化误差:RoI Pooling层可能会引入一些量化误差,因为它是将连续的空间坐标强制映射到离散的网格单元上。
区别总结
- 特征提取方式:R-CNN对每个候选区域单独进行特征提取,而Fast R-CNN则是在整张图像上一次性提取特征,然后通过RoI Pooling来获取每个候选区域的特征。
- 计算效率:Fast R-CNN显著提高了计算效率,因为它减少了重复的特征提取步骤。
- 模型集成度:Fast R-CNN将分类和回归任务整合到了同一个端到端可训练的网络中,简化了训练过程。
- 性能:Fast R-CNN在保持甚至提高检测精度的同时,大幅降低了检测所需的时间。
Fast R-CNN通过减少重复计算和优化网络结构,解决了R-CNN的主要瓶颈,但在区域建议阶段仍有改进空间,这也是后续Faster R-CNN引入区域建议网络(RPN)的原因之一。
RoI Pooling
def roi_pooling(feature_map, rois, output_size):
num_rois, _ = rois.size()
batch_size, num_channels, input_height, input_width = feature_map.size()
# 初始化输出张量
pooled_features = torch.zeros(num_rois, num_channels, *output_size)
for i in range(num_rois):
# 获取当前RoI信息
batch_idx, x1, y1, x2, y2 = rois[i]
# 计算每个输出单元对应于原始RoI的区域大小
bin_w, bin_h = (x2 - x1) / output_size[1], (y2 - y1) / output_size[0]
for ph in range(output_size[0]):
for pw in range(output_size[1]):
# 计算当前bin对应的特征图上的区域
start_h, end_h = int(ph * bin_h + y1), int((ph + 1) * bin_h + y1)
start_w, end_w = int(pw * bin_w + x1), int((pw + 1) * bin_w + x1)
# 确保不超出边界
start_h, end_h = max(0, min(start_h, input_height-1)), max(0, min(end_h, input_height-1))
start_w, end_w = max(0, min(start_w, input_width-1)), max(0, min(end_w, input_width-1))
# 执行最大池化
if start_h < end_h and start_w < end_w:
pooled_features[i, :, ph, pw] = torch.max(
feature_map[int(batch_idx), :, start_h:end_h, start_w:end_w].view(num_channels, -1),
dim=1
)[0]
return pooled_features
# 应用RoI Pooling
pooled_features = roi_pooling(feature_map, roi.unsqueeze(0), output_size)
# 打印结果
print(pooled_features)整体流程:
import torch
import torch.nn as nn
import torch.nn.functional as F
class FastRCNN(nn.Module):
def __init__(self, num_classes, feature_dim=512, roi_size=(7, 7)):
super(FastRCNN, self).__init__()
# 假设输入特征图的通道数为feature_dim
self.feature_dim = feature_dim
self.roi_size = roi_size
self.num_classes = num_classes
# 全连接层的输入维度
fc_input_dim = feature_dim * roi_size[0] * roi_size[1]
# 分类分支
self.fc_cls = nn.Sequential(
nn.Linear(fc_input_dim, 4096),
nn.ReLU(inplace=True),
nn.Linear(4096, 4096),
nn.ReLU(inplace=True),
nn.Linear(4096, num_classes) # 输出每个类别的概率
)
# 回归分支
self.fc_reg = nn.Sequential(
nn.Linear(fc_input_dim, 4096),
nn.ReLU(inplace=True),
nn.Linear(4096, 4096),
nn.ReLU(inplace=True),
nn.Linear(4096, num_classes * 4) # 每个类别有4个回归参数 (dx, dy, dw, dh)
)
def forward(self, x, rois):
"""
x: 特征图 [batch_size, channels, height, width]
rois: RoI坐标 [num_rois, 5] (batch_index, x1, y1, x2, y2)
"""
batch_size, _, _, _ = x.size()
num_rois, _ = rois.size()
# 使用RoI Pooling层
pooled_features = self.roi_pooling(x, rois)
# 展平特征
pooled_features = pooled_features.view(num_rois, -1)
# 分类分支
cls_scores = self.fc_cls(pooled_features)
# 回归分支
bbox_deltas = self.fc_reg(pooled_features)
return cls_scores, bbox_deltas
def roi_pooling(self, feature_map, rois):
"""
简单的RoI Pooling实现
feature_map: [batch_size, channels, height, width]
rois: [num_rois, 5] (batch_index, x1, y1, x2, y2)
"""
num_rois, _ = rois.size()
batch_size, num_channels, input_height, input_width = feature_map.size()
output_size = self.roi_size
pooled_features = torch.zeros(num_rois, num_channels, *output_size).to(feature_map.device)
for i in range(num_rois):
batch_idx, x1, y1, x2, y2 = rois[i].int()
# 计算每个输出单元对应于原始RoI的区域大小
bin_w, bin_h = (x2 - x1) / output_size[1], (y2 - y1) / output_size[0]
for ph in range(output_size[0]):
for pw in range(output_size[1]):
# 计算当前bin对应的特征图上的区域
start_h, end_h = int(ph * bin_h + y1), int((ph + 1) * bin_h + y1)
start_w, end_w = int(pw * bin_w + x1), int((pw + 1) * bin_w + x1)
# 确保不超出边界
start_h, end_h = max(0, min(start_h, input_height-1)), max(0, min(end_h, input_height-1))
start_w, end_w = max(0, min(start_w, input_width-1)), max(0, min(end_w, input_width-1))
if start_h < end_h and start_w < end_w:
pooled_features[i, :, ph, pw] = torch.max(
feature_map[int(batch_idx), :, start_h:end_h, start_w:end_w].view(num_channels, -1),
dim=1
)[0]
return pooled_features
# 示例
if __name__ == "__main__":
# 假设特征图
feature_map = torch.randn(1, 512, 8, 8) # [batch_size, channels, height, width]
# 假设RoIs
rois = torch.tensor([[0, 1, 1, 6, 6], [0, 2, 2, 5, 5]]) # [num_rois, 5] (batch_index, x1, y1, x2, y2)
# 创建模型
model = FastRCNN(num_classes=21)
# 前向传播
cls_scores, bbox_deltas = model(feature_map, rois)
print("Classification Scores:", cls_scores)
print("Bounding Box Deltas:", bbox_deltas)3. Faster R-CNN网络(2016年)
学习视频(推荐看一下讲的很好):
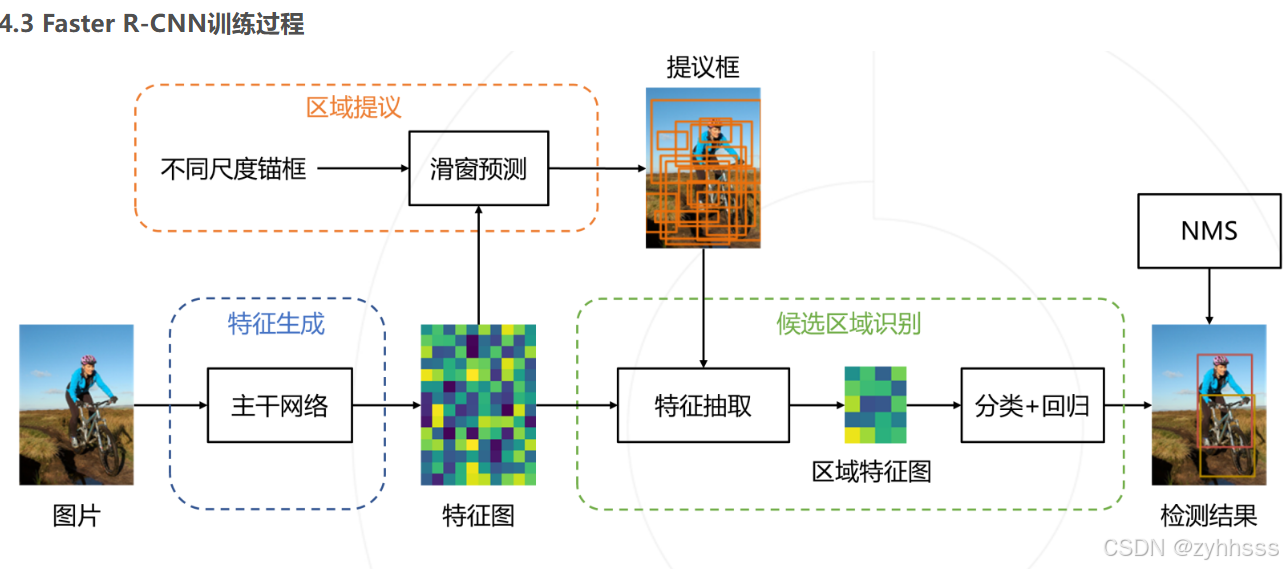
2016加入RPN网络(区域提议网络)
通过(VGG或类似的)提取的特征图。按照比例,尺度生成锚点框。
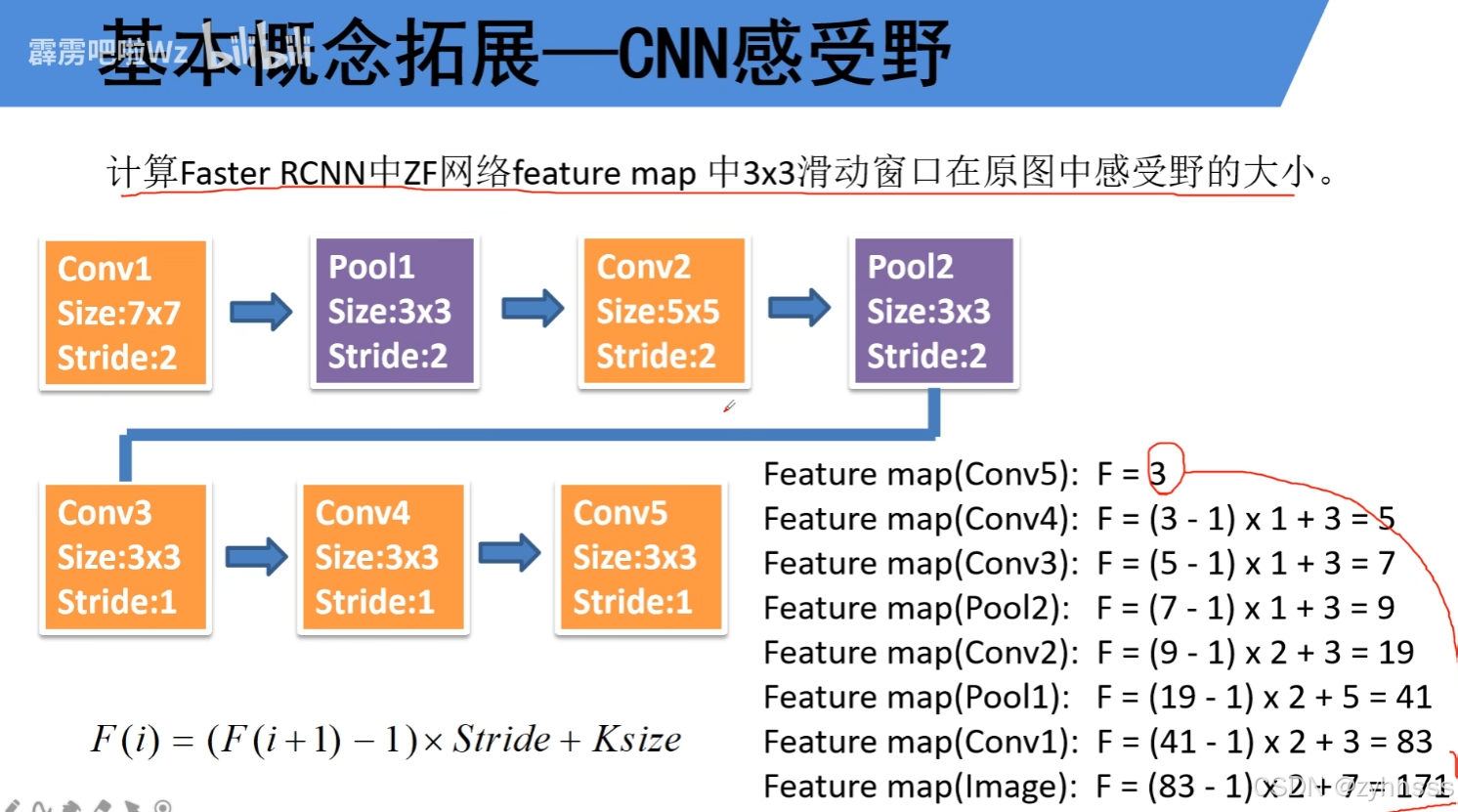
ZF感受野:
整体流程:
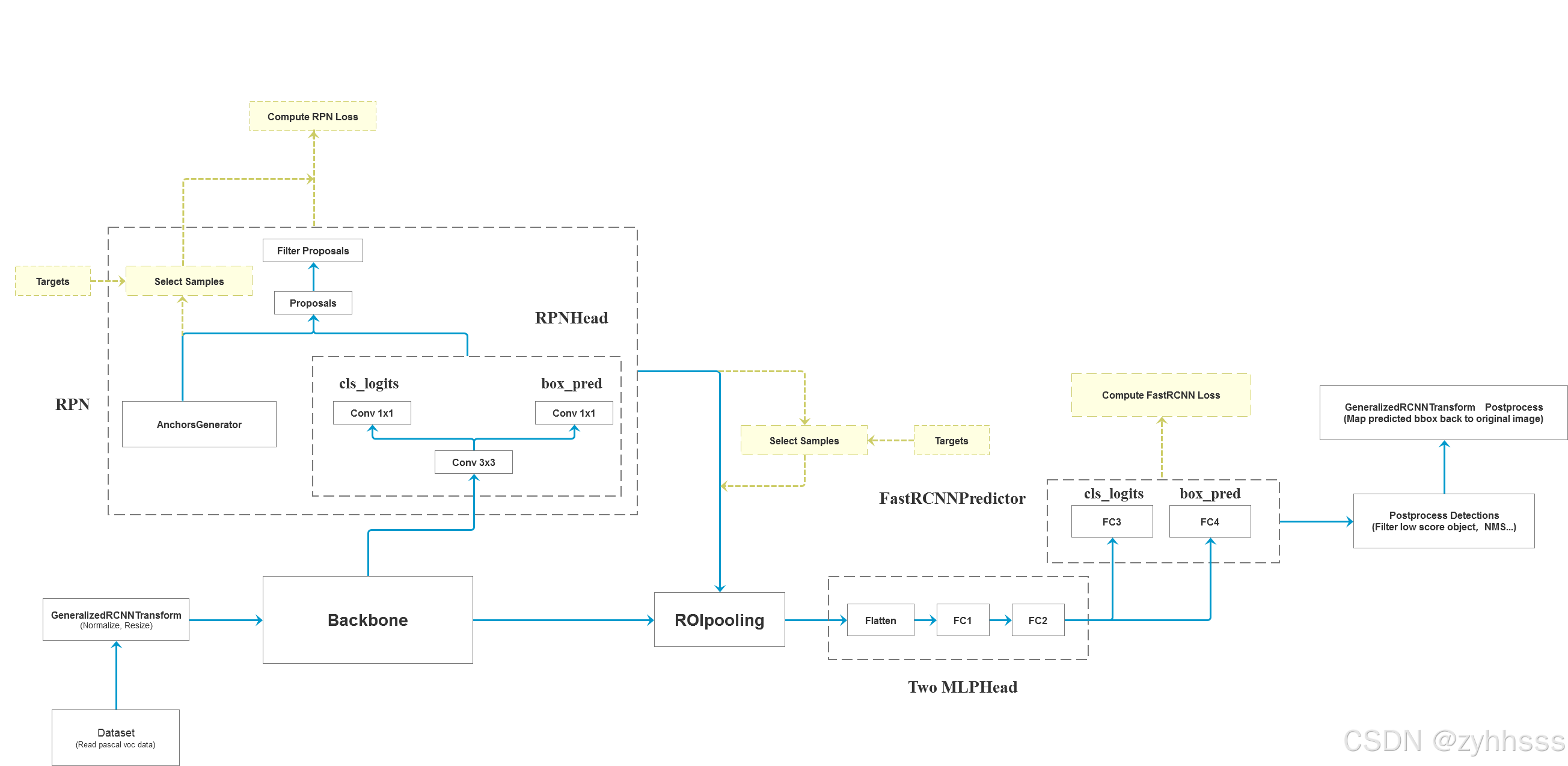
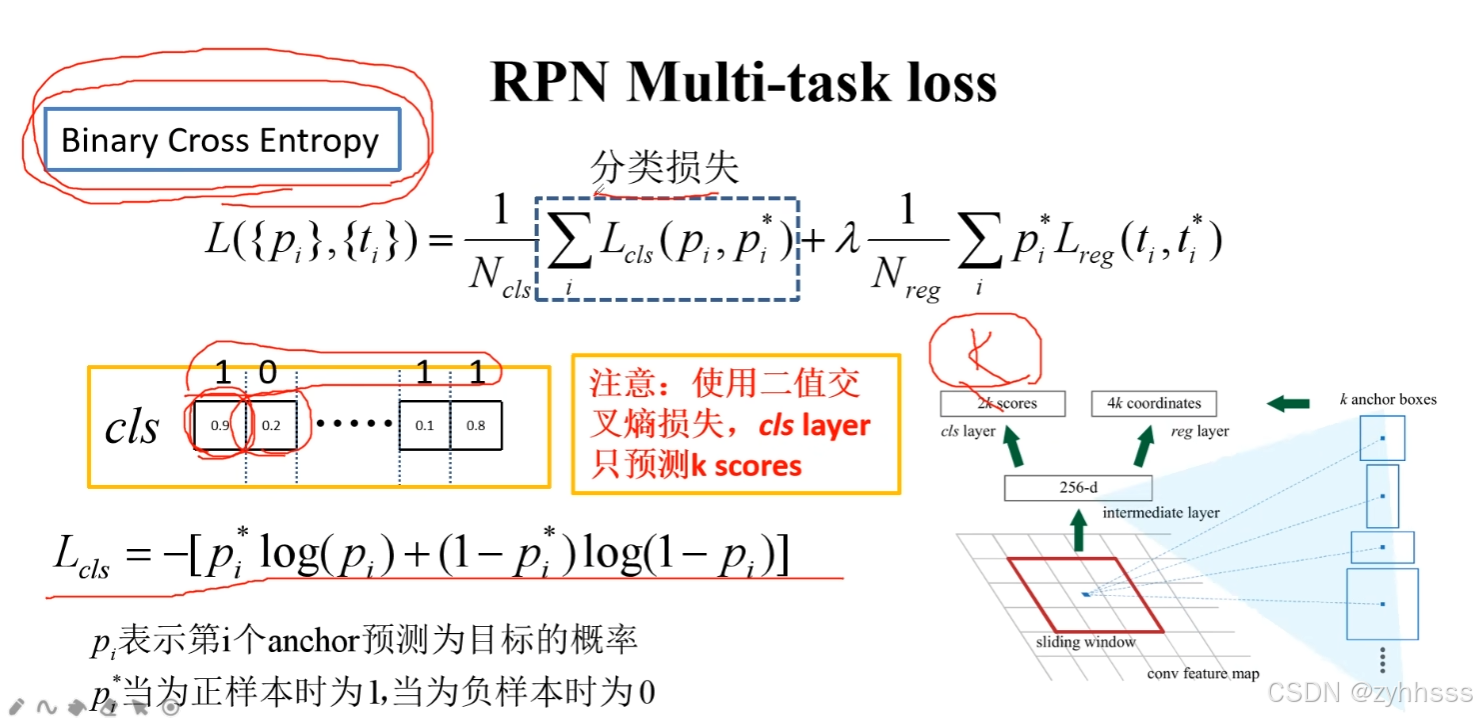
损失函数:
rpn:交叉熵+边界框回归损失
fastrcnn

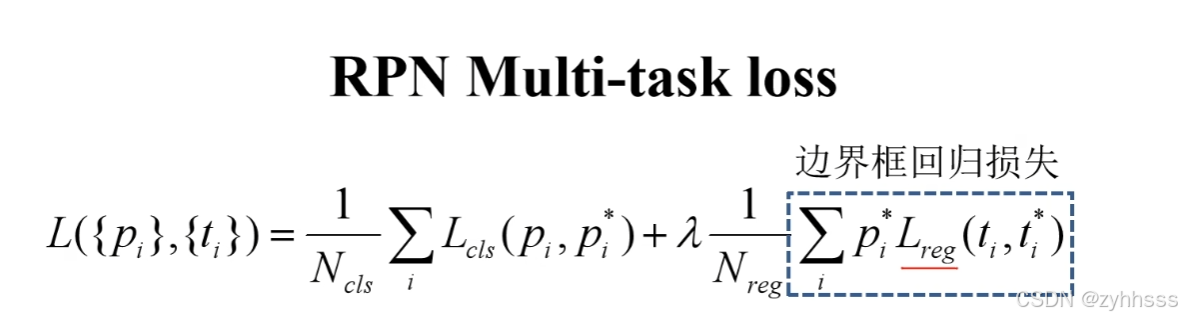

第二次复习:
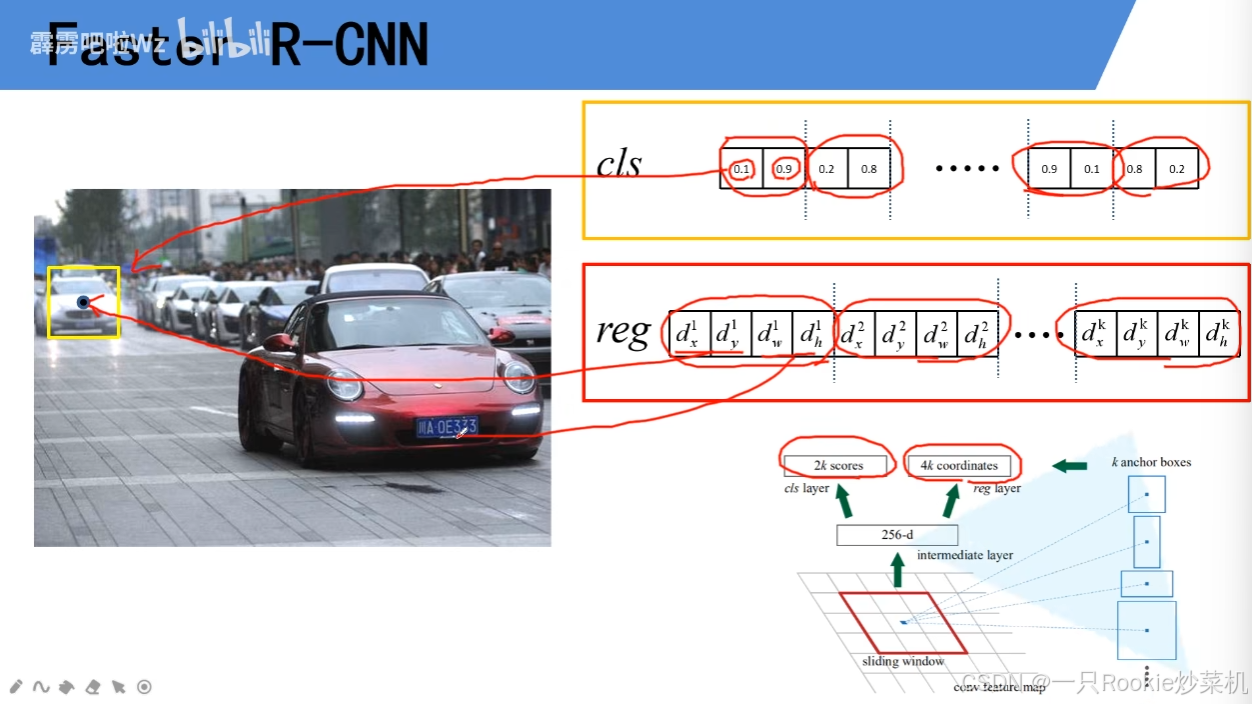
首先经过特征提取网络(zf、vgg或者别的)提取出特征图,经过一个全连接层(这里是256默认用的zf,如果是别的要看看channel数)。全连接输出cls(前景、背景概率)、reg(中心点坐标、anchor的调整值,目的是要把框调整到恰好的位置)。
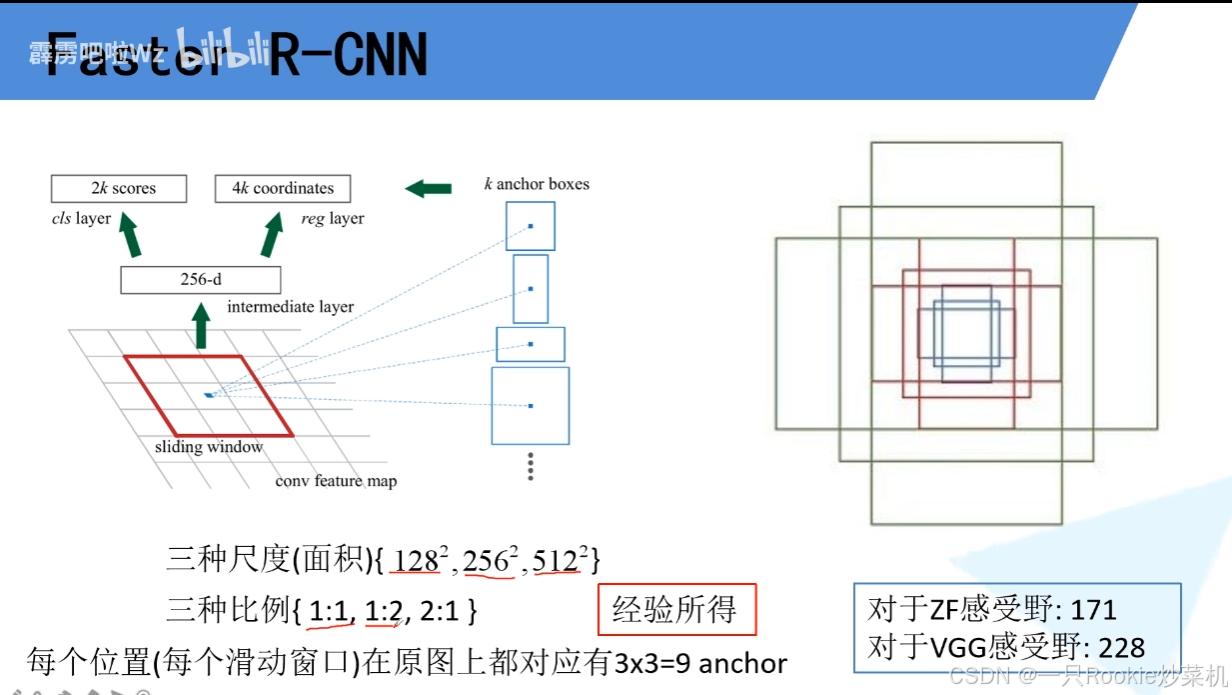
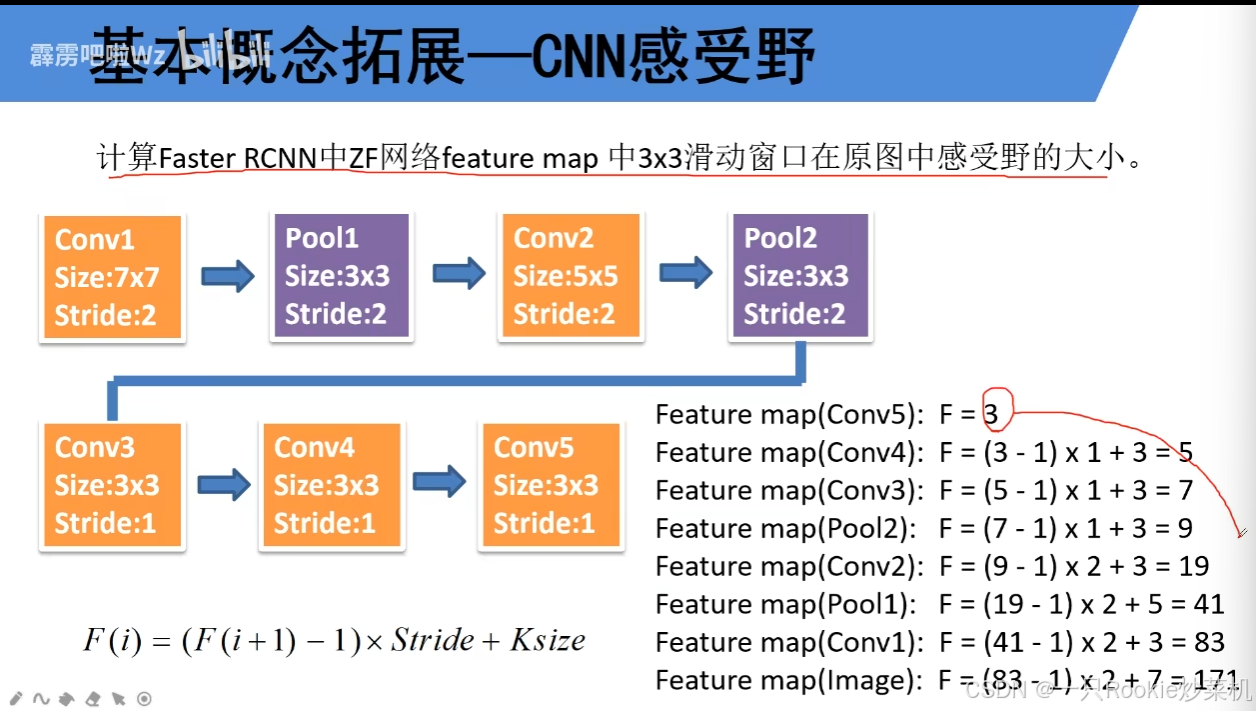
论文中有9个anchor(论文中说根据经验所得)。感受野:感受野是输出特征图上某个位置的值所依赖的输入图像区域。感受野计算:vgg网络中有:
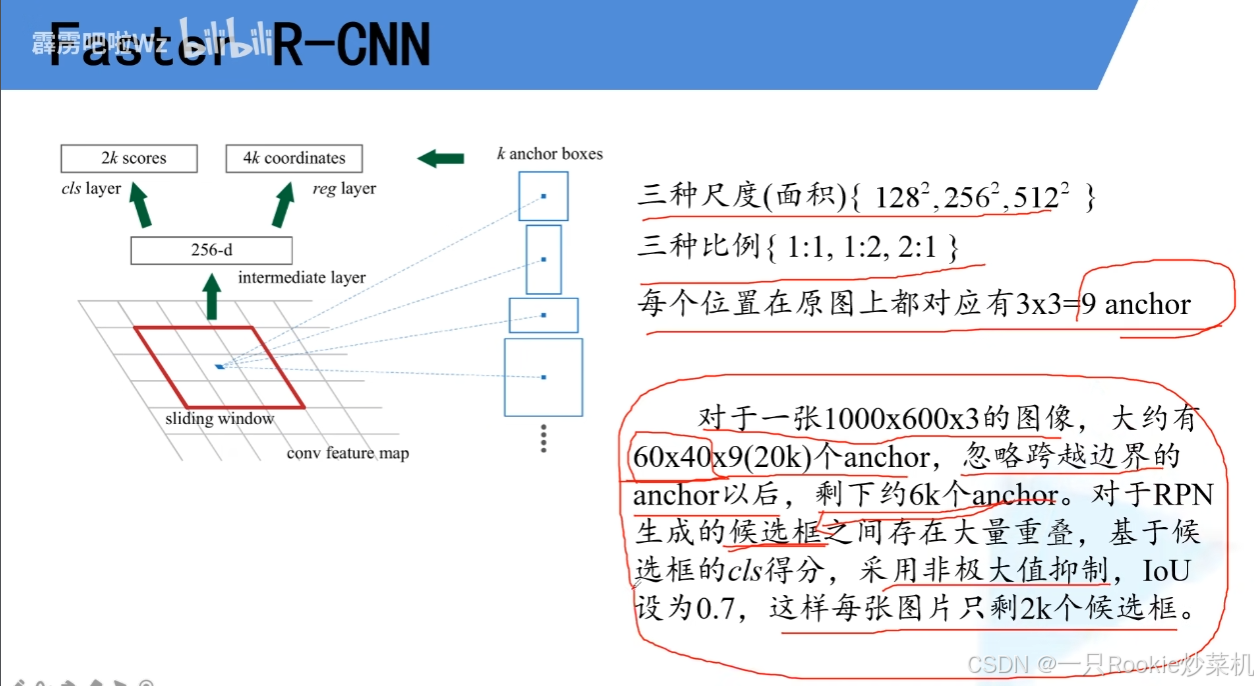
正负样本选取:正样本:anchor 计算出的iou>0.7或者 最大的iou。负样本:iou对于所有的样本小于0.3

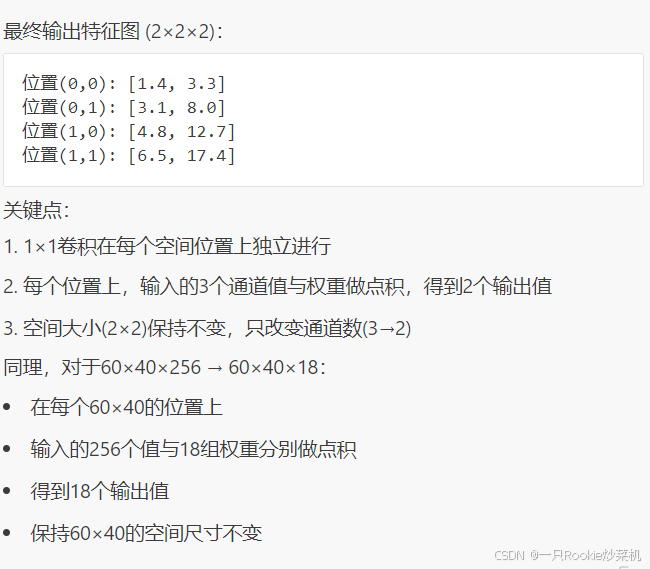
特别插入一下1000*600*3怎么变到的60*40*256



一个简单的例子看一下怎么计算卷积:

三、进一步学习

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 4
4 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)